第一章 绪论
1.1 引言
什么是“机器学习” (machine learning)
机器学习是一门研究如何通过计算的手段,利用经验改善系统自身的性能的学科
输入数据 -> 学习算法->得到模型?-> 输出结果(预测、判断等)
1.2 基本术语
1.2.1 关于数据
?????????数据集: 100个西瓜
? ? ? ? ?样本(示例):1个西瓜
? ? ? ? ?属性(特征):色泽、根蒂、敲声
? ? ? ? ?样本空间(属性空间、输入空间):属性张成的空间,例如 色泽、根蒂、敲声作为3个坐标轴张成的空间。
? ? ? ? ?特征向量:样本空间中的一个点对应一个坐标向量,例如 [青绿,卷缩,浊响] ,把这样一个示例称为一个特征向量。
? ? ? ? ?维数:每个示例由 d 个属性描述,则每个示例都是 d 维样本空间中的一个向量。 d 称为样本的维数。
? ? ? ? ?标记:关于示例结果的信息。例如 好瓜?
? ? ? ? ?样例:拥有标记信息的示例
? ? ? ? ?标记空间(输出空间): 训练样本的所有标记信息的集合。 例如 好瓜,坏瓜
1.2.2 关于学习算法
? ? ? ? ?学习(训练):在数据中学得模型的过程
? ? ? ? ?假设:学得得模型对应了关于数据的某种潜在的规律
? ? ? ? ?真相(真实):数据的潜在规律的自身
? ? ? ? ?学习过程就是为了找出或者逼近真相。
1.2.3 关于模型
? ? ? ? ?有监督学习(训练数据有标记信息)
? ? ? ? ? ? ? ? 分类:预测的是离散值
? ? ? ? ? ? ? ? ? ? ? ? ①二分类:只涉及“正类”和“负类”的分类任务
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
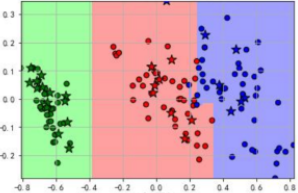
? ? ? ? ? ? ? ? ? ? ? ? ②多分类:预测任务涉及多个类别
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? 回归:预测的是连续值, 例如预测房价、股价
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ?无监督学习(训练数据没有标记信息)
? ? ? ? ? ? ? ? 聚类:对数据集自动做簇的划分,这些自动形成的簇可能对应一些潜在的概念划分,例如“浅色瓜”,“本地瓜”这些我们事先不知道,训练集也没有标记的概念。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
1.2.4 关于输出(预测)
? ? ? ? ?测试:使用学得的模型进行预测的过程称为测试
? ? ? ? ?测试样本:被预测的样本称为测试样本
? ? ? ? ?泛化能力:学得的模型适用于“新样本“的能力称为泛化能力
1.3 假设空间
? ? ? ? ?归纳:从特殊到一般的“泛化”过程,即从具体的事实归结出一般性规律
? ? ? ? ?演绎:从一般到特殊的“特化”过程,即从基础原理推演出具体状况
? ? ? ? ?假设空间:所有假设组成的空间
? ? ? ? ?版本空间:与训练集一致的“假设集合”
1.4 归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”
任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上“等效”的假设所迷惑。归纳偏好的作用,对有限个样本点组成的训练集,存在着很多条曲线与其一致,学习算法必须有某种偏好,才能产出它认为“正确”的模型。
学习算法自身的归纳偏好与问题是否相配,往往会起到决定性的作用。
“奥卡姆剃刀”(Occam’s razor)原则
学习算法的一般性的原则,若有多个假设与观察一致,则选最简单的那个。
“没有免费的午餐”定理(No Free Lunch Theorem 简称 NFL定理)
理解:在所有问题出现的机会相同、或所有问题同等重要的前提下,模型的总误差与学习算法无关。无论算法是聪明还是笨拙,它们的期望性能都是相同的。
启示:脱离具体问题,空谈“什么学习算法更好”毫无意义。
1.5-1.6 发展历程、应用现状等
略......
第二章 模型评估与选择
2.1 经验误差与过拟合
m个样本,a个样本分类错误
错误率:分类错误的样本数占样本总数的比例,即 E = a/m
精度:精度 = 1-E = 1-a/m
误差:学习器的实际预测输出与样本的真实输出之间的差异
经验误差(训练误差):学习器在训练集上的误差
泛化误差:学习器在新样本上的误差
过拟合:学习器把训练样本学得“太好”,把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,导致泛化性能下降
欠拟合:与过拟合相对,是指学习器对训练样本的一般性质还没有学好
欠拟合容易克服,过拟合无法彻底避免
2.2 评估方法
当任务具有多种学习算法可以选择时,理想的方案是对候选模型的泛化误差进行评估,选择泛化误差最小的那个模型。
通常通过实验测试来对学习器的泛化误差进行评估。
划分训练集,验证集,测试集的方法
2.2.1 留出法(hold-out)
直接将数据集 D 划分为两个互斥的集合,其中一个集合作训练集 S,另一个集合作为测试集 T
注意:保持训练集和测试集同分布,单次使用留出法得到的估计结果往往不够稳定可靠
使用留出法,一般采用多次随机划分、重复进行训练评估后取平均值作为留出法的评估结果
常用约 2/3~4/5的样本用于训练,其余样本用于测试
2.2.2 交叉验证法(cross validation)
先将数据集D划分为 k 个大小相似的互斥子集,每个子集都尽量保持数据分布的一致性,即从D中通过分层采样获得。然后每次用 k-1 个子集的并集作为训练集,余下的那个子集作为测试集。进行 k 次训练和测试,最终返回这 k 个测试结果的均值
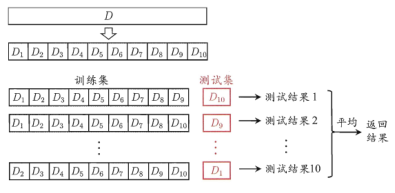
假设数据集 D 中包含 m 个样本,若令 k = m,则得到了交叉验证法的一个特例:留一法(Leave-One-Out, 简称LOO),留一法中被实际评估的模型与期望评估的用 D 训练出的模型很相似,因此留一法的评估结果往往被认为是比较准确的,但是缺陷是数据集较大时,计算的开销是巨大的。
“没有免费的午餐”定理对实验评估方法同样适用
2.2.3 自助法(bootstrapping)
给定包含 m 个样本的数据集 D,随机采样产生包含 m 个样本的数据集 D'
每次随机从 D 中抽取一个样本拷贝至 D',且保留该样本在原数据集 D 中(下次也可能抽到这个样本,即 D' 中也可能存在重复样本),进行 m 次随机抽取后,得到一个新的数据集 D'。
通过自主采样,初试数据集中大约有36.8%的样本未出现在采样数据集 D' 中。将?D' 作为训练集,D/D' 作为测试集。这样的测试结果称为“包外估计”(out-of-bag estimate)
自助法在数据集较小时,能够产生多个不用的训练集,解决了训练集/测试集难以划分的问题,对集成学习也有很大好处,但是这种方法改变了初始数据集的分布,会引入估计偏差。
当数据量充足时,常用留出法和交叉验证法
2.2.4 调参与最终模型
研究对比不同算法的泛化性能时,用测试集上的判别效果估计模型在实际使用时的泛化能力,把训练数据另外划分为训练集和验证集,基于验证集上的性能进行模型的选择和调参
2.3 性能度量
对学习器的泛化性能进行评估中衡量模型泛化能力的评价标准,就是性能度量
回归任务最常用的性能度量是“均方误差”(mean squared error)
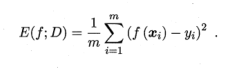
?f(x)为学习器的预测结果,y是真实标记。
对于数据分布D和概率密度函数p(.),均方误差的一般描述为
![]()
分类任务常用的性能度量有错误率与精度、查准率、查全率、F1、ROC与AUC等
2.3.1 错误率与精度
错误率:分类错误的样本数占样本总数的比例
![]()
![]()
精度:分类正确的样本数占样本总数的比例

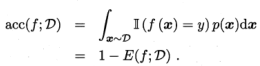
2.3.2 查准率、查全率与 F1
混淆矩阵

TP+FP+TN+FN =? 样例总数
TP (true positive):好瓜预测为好瓜? ? ? ? ?FN(false negative):好瓜预测为坏瓜
FP (false positive):坏瓜预测为好瓜? ? ? ? TN(false negative):坏瓜预测为坏瓜
查准率(precision): 预测为好瓜的样例中有多少是真的好瓜
? ? ? ? ? ? ? ? ? ? ? ??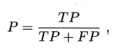
查全率(recall 召回率):好瓜有多少被预测正确了
? ? ? ? ? ? ? ? ? ? ? ??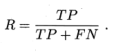
查准率和查全率是一对矛盾,此消彼长
因此为了比较学习器的性能,引入了“P-R曲线”,以查准率为纵轴、查全率为横轴作图

?比较标准:
① 一个学习器的P-R曲线将令一个学习器的P-R曲线完全包住,则说明前者性能优于后者,例如 B优于 C
② 比较 P-R 曲线下面积的大小,这在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例,但是不容易估算
③ 平衡点(Break-Even Point,简称 BEP)
?综合考虑查准率、查全率的性能度量,它是“查准率=查全率”时的取值
?④ F1 度量

参考:
《机器学习》周志华著