多路召回
召回阶段业界一般会采用多路召回,多路召回就是一路一路地去召回。
- 按照兴趣召回:知道用户的长期兴趣和短期兴趣,根据用户的兴趣去查找不同的物料内容。
- 按照位置召回:根据用户的上下文,比如说位置。当前这个用户在国外旅游,将用户的位置信息生成物料。然后去查找位置类型的物料。
- 按照xx策略召回
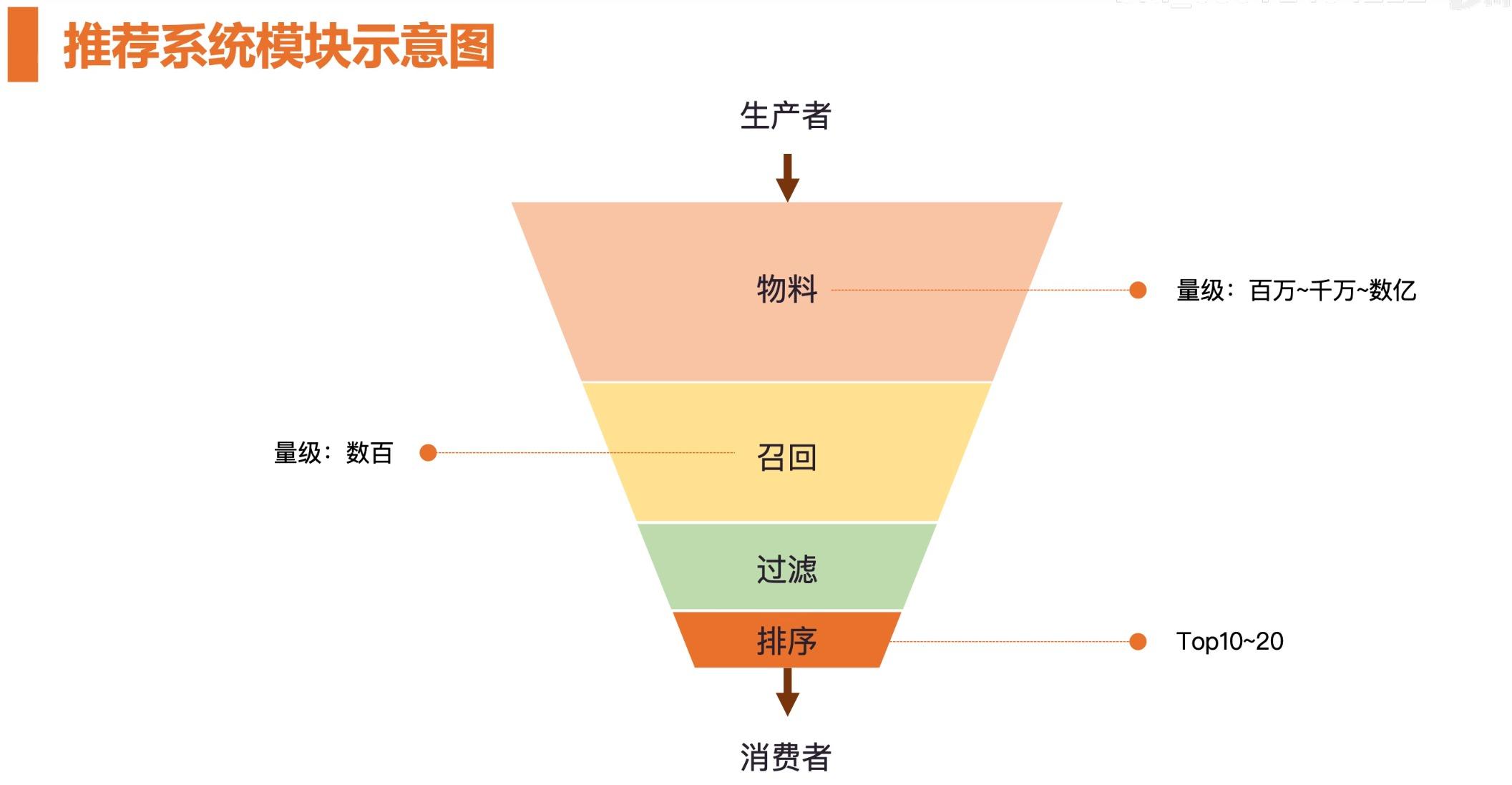
召回阶段要做的事情是:在成千上万的内容中找到用户可能关心的候选集,这里的候选集不是最终给用户的。一般来说,一路召回的数量在一百两百级别,多路召回加起来可能在五百到一千级别。
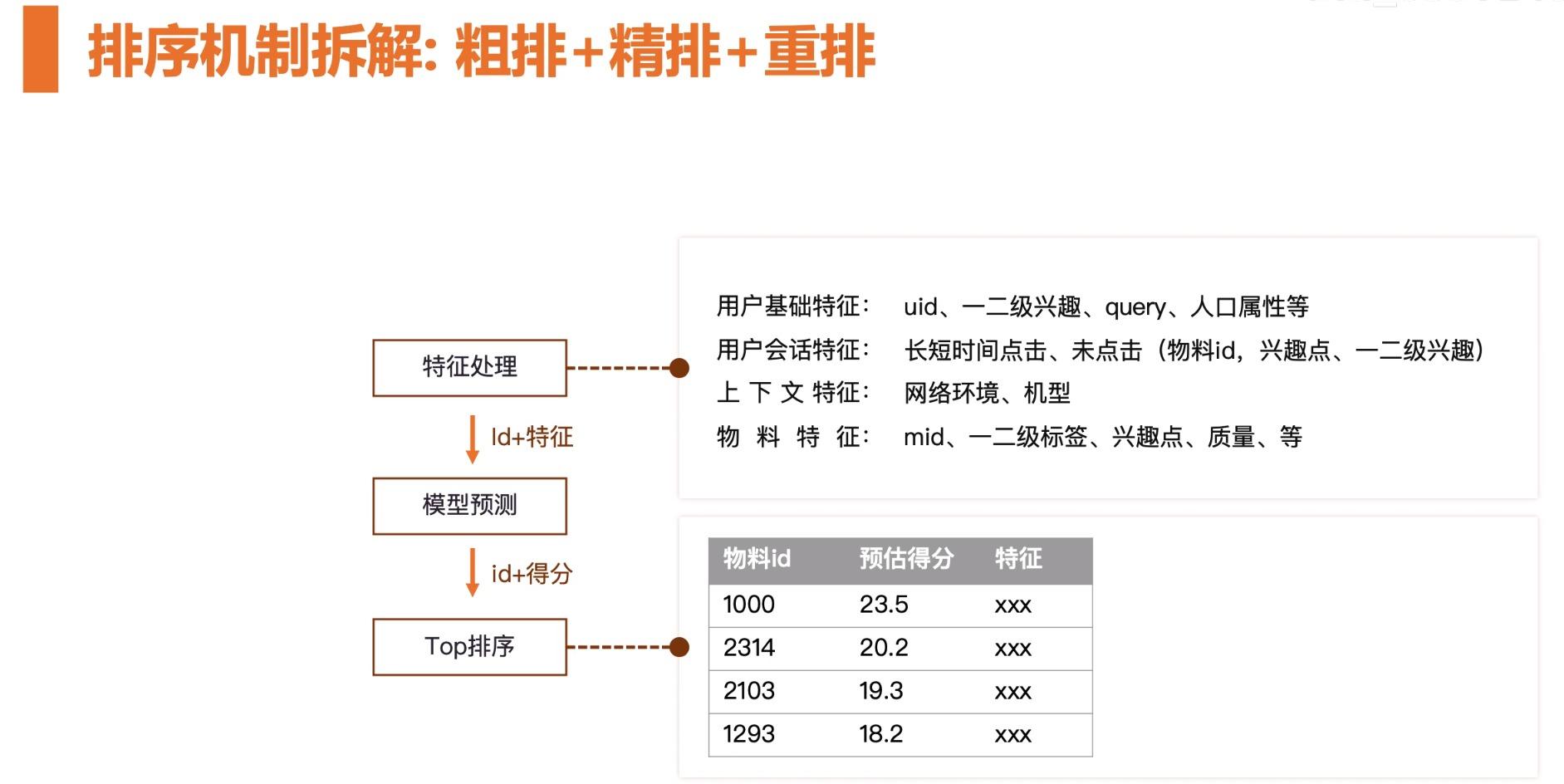
召回阶段得到候选集之后,下一步就是要做精挑细选。 精挑细选的过程也是要根据用户当前历史行为和上下文对候选集通过机器学习算法做排序。最后把排序列表推送给用户。
在物料方面,针对不同的实现方式会有不同的物料池子。
如果按照兴趣来走的话,那么就按照不同的标签将内容归类。
如果按照热点来走的话,短期用户的点击行为,用户的购买率这种方式生成相应热门的物料。
将物料召回回来之后,接下来是排序。
排序要做的事情就是通过机器学习的方式,将用户特征 X 输入到模型中预测点击概率 Y。这里的点击率针对不同的商品会有所不同,针对商品购买概率,视频的观看时长等。最后,针对得到的评分来进行排序。
最常见的信息流处理过程:
2、推荐系统
- 推荐系统需要满足哪些用户诉求?
- 如何用物料召回满足用户诉求?
- 如何挑选用户喜欢的内容 TopN?
3、机器学习
- 小白也能理解的机器学习
4、总结
实际中如何提升推荐效果等;进阶学习方向指导等。
个性化推荐 & 机器学习
―― 2.1 推荐系统之物料召回
目录
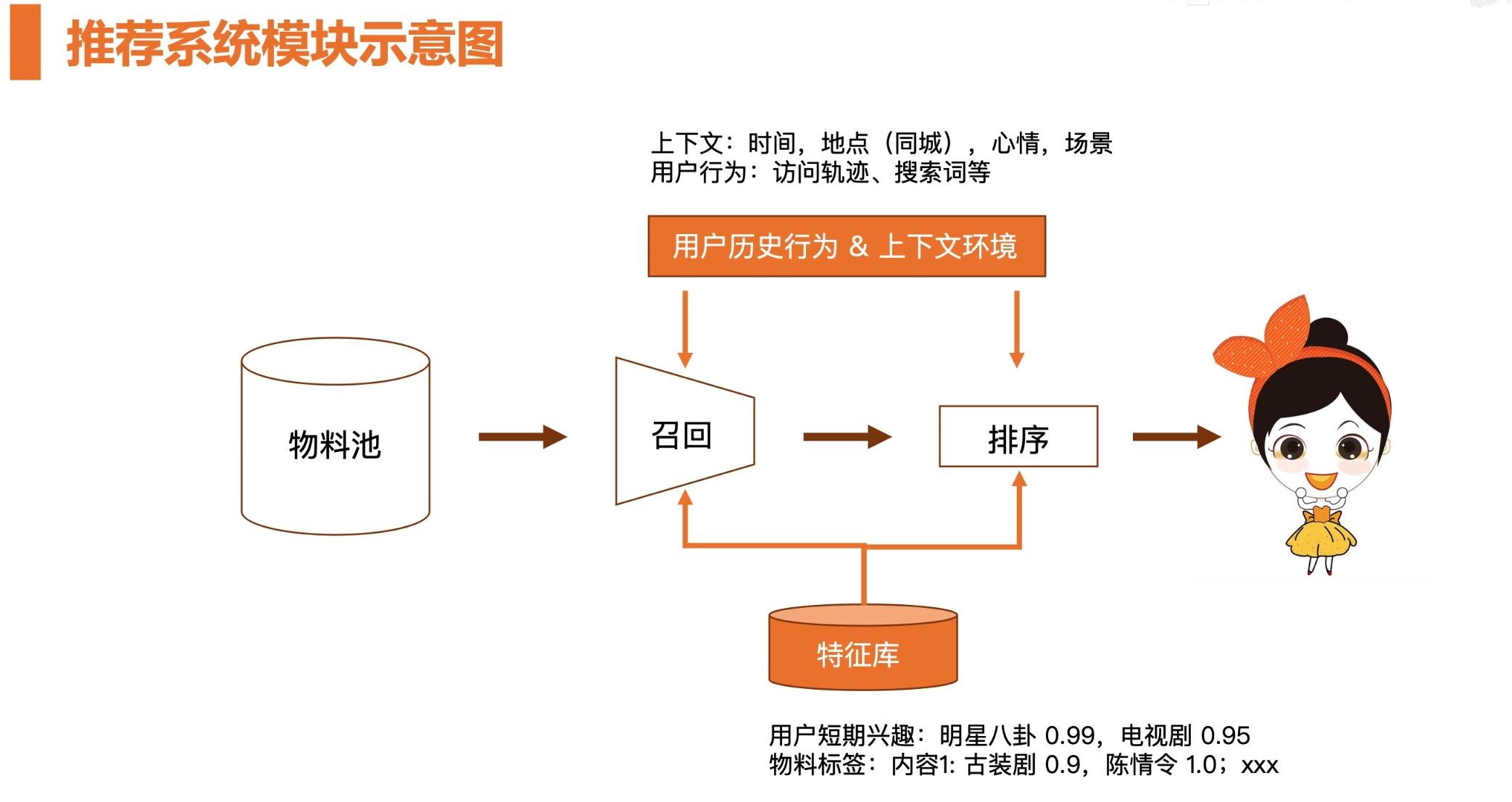
- 推荐系统模块示意图
- 行业常见召回策略 ――> 热门、兴趣标签、协同物料、向量召回
- 不同策略实现机制拆解 ――> 非程序员建议直接跳过
- 本章总结
- 本系列讲解大纲
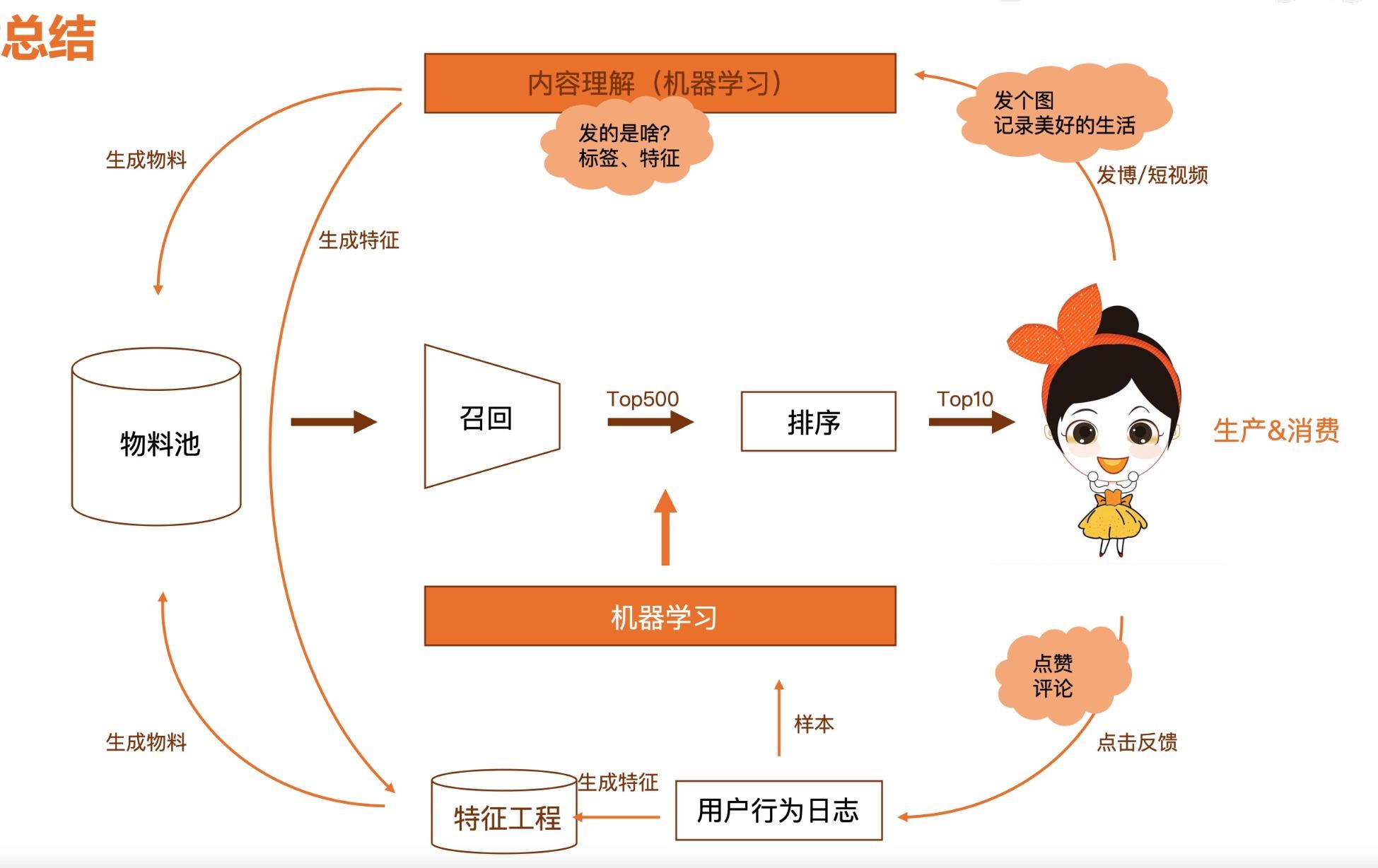
推荐分为:物料、召回、排序三大环节。 在这个过程中根据用户的历史行为数据、上下文数据来做数据内容的过滤,最终给用户精挑细选出一批物料内容。这里的物料可以是电商的商品,头条的文章、短视频的视频等内容。
推荐系统的总体流程可以看作是一个信息过滤的过程。

召回环节对时间的要求是非常苛刻的,一般会要求在几十毫秒内从千万级物料库中召回几百条候选物料。所以说,这里使用多路召回,采用的是并发的思路。多路召回还可以解决数据来源的多样性问题。
多路召回从实现机制来说,一般分为:统计类的和简单算法的。
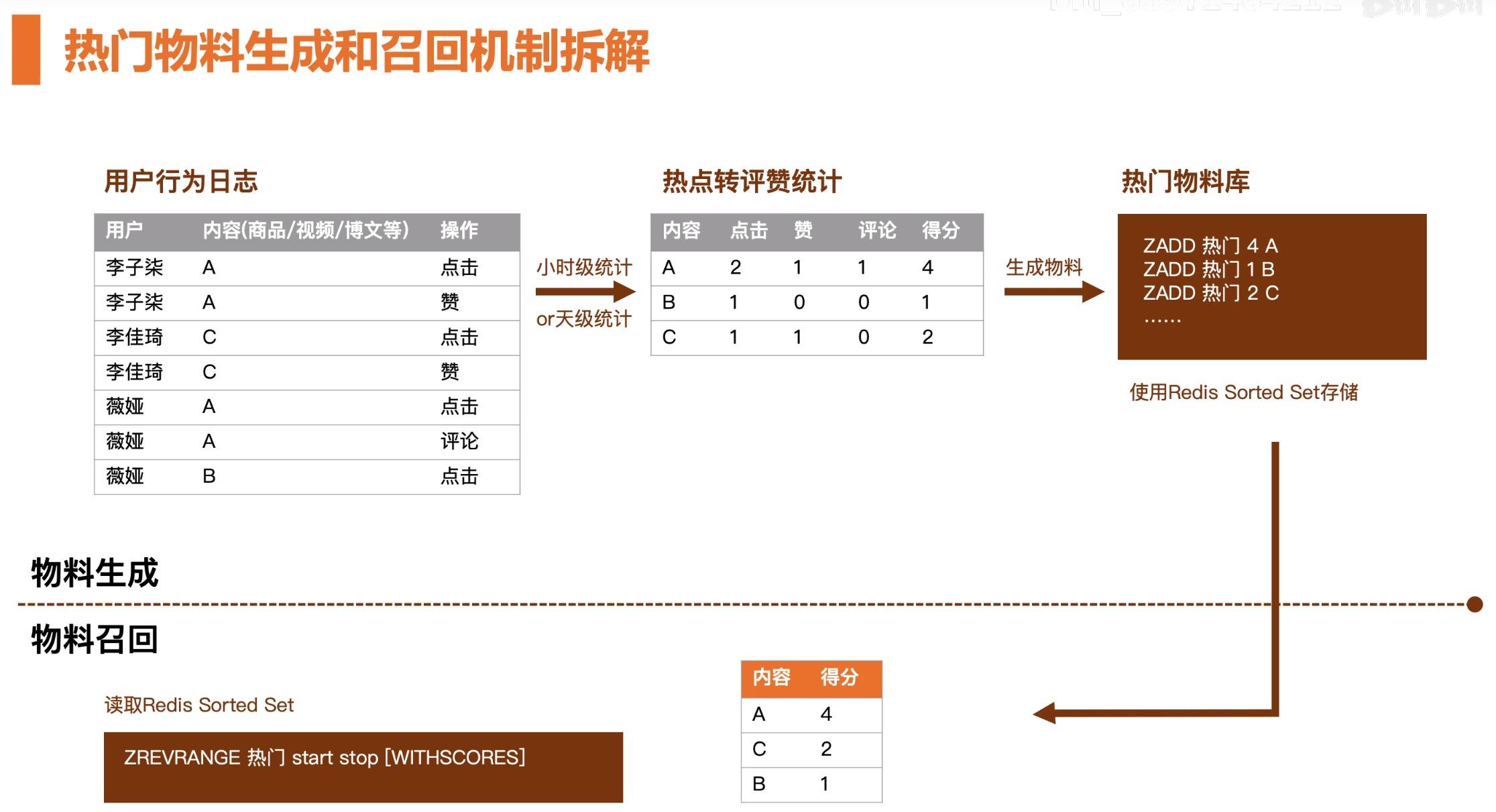
物料生成和召回往往是密不可分的,新增一种新的召回策略,比如热门类的召回策略。热门类召回策略可以细分为:小时级的物料、天级的物料。物料的生成和召回是息息相关的。
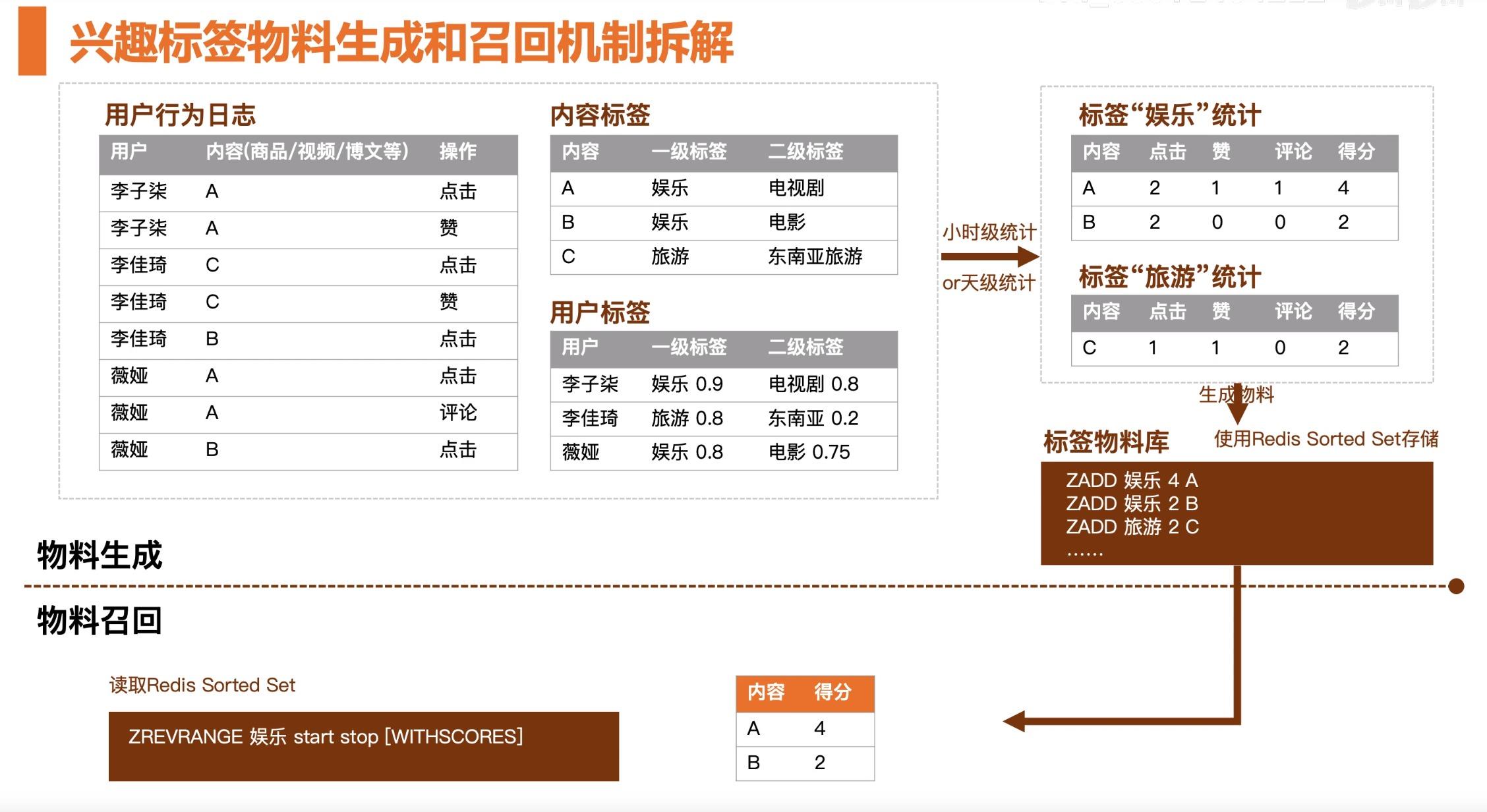
首先我们会拿到用户的行为日志,上一章节我们提到,当用户刷新操作产生购买行为的时候,服务端会将用户的行为日志记录。对行为日志作一个简单的统计,比如对内容做转评赞的统计,得到统计得分之后,我们将结果存入 Redis 内存序库中。
物料生成过程是个离线的行为,一般来说,物料生成是由线下做定时的物料挖掘,比如几个小时、甚至是几天往物料库中持续不断的更新内容。
物料召回是个在线行为,是实时的。比如当我们在 APP 上刷新的时候,会调用对应接口,接口会访问推荐引擎,推荐引擎会调用物料召回这个模块。
按照”热门“关键词查询得到数据,由于Redis 内存序库中是按照得分排序的,这样就很容易就拿到了 TopN 的数据。这样我们就很容易从大量的物料中做数据的筛选,其实本质上就是一个排序的问题。这样就实现了物料的召回过程。
以上就是热门物料生成和物料召回的实现机制。
接下来分析兴趣类的物料生成和召回:
兴趣类的物料生成和召回和热门类的类似。区别是热门类的操作是对数据的统计,兴趣类的会考虑两点。在物料生成的环节我们要考虑的是内容是什么样子的,会对每个内容做标签划分。当我们发布新的内容时,我们会对内容打一些标签,来划分它是娱乐类的、旅游的还是财经时政等不同的标签。
在不考虑用户的情况下,当我们点击 APP 的时候,会有一些垂直的频道。比如说娱乐类的、财经类的、汽车类的等等。这些不同的频道就是按照标签来做召回的。
根据不同的一级标签做数据统计和热门的处理是类似的,根据”娱乐“和”旅游“两个不同标签做统计就生成了两个物料库。这两个物料库的 Key 是不同的。以上就是物料生成环节,那么在线怎么使用呢?
根据用户标签查找用户标签对应的最新的热门信息是什么,以上过程可以看作标签匹配过程。
在个性化推荐过程中,先得到用户的短时的兴趣标签反查物料库中对应的物料数据。每个物料库中都有 TopN 内容,这样我们把这些物料库中的 TopN 内容拉取过来就实现了兴趣标签的召回。
总结:热门和兴趣标签类的物料生成和召回其实都是基于统计的机制。
协同过滤物料生成和召回机制拆解
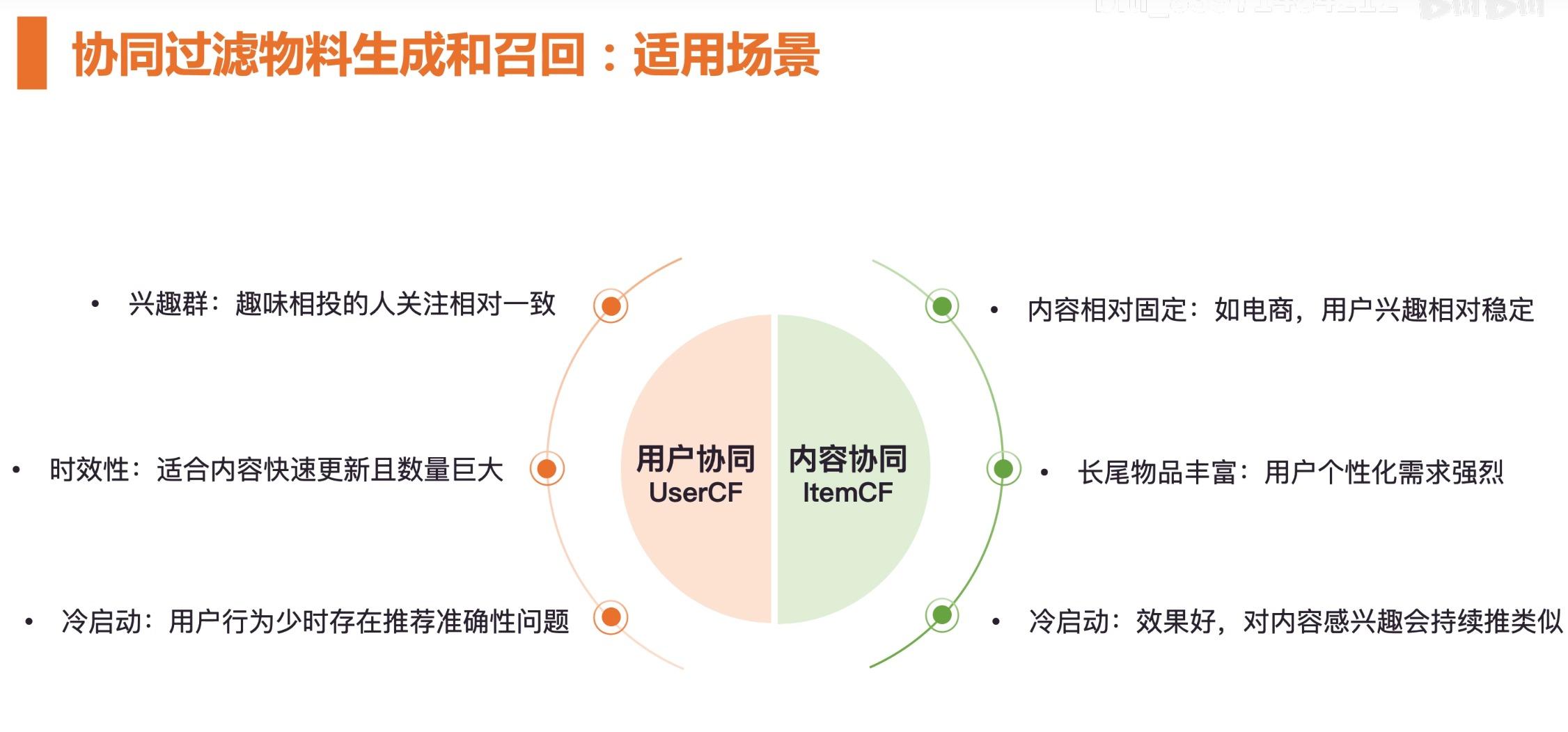
协同过滤是一种非常经典有效的实现物料召回的机制。他的实现原理是:基于用户的行为查询两类内容。第一类:基于用户;第二类:基于内容。
从实际效果上来看,基于协同过滤方式是非常有效的一种物料召回的机制。

协同过滤物料生成和召回:适用场景
个性化推荐 & 机器学习 ―― 2.2 推荐系统之过滤排序
目录
- 推荐系统模块示意图
- 常见过滤策略 ――> 过滤已读、黑/白名单、相似度过滤…
- 排序机制拆解:粗排+精排+重排 ――> 系统过程
- 常见重排策略 ――> 人工重排过程、提权/降权策略
- 本章总结
- 本系列讲解大纲
常见过滤策略
- 垃圾内容:垃圾内容
- 太多单一内容:维持多路召回物料比例,控制数量和比例,提升推荐多样性。
- 重复内容:过滤掉与当前内容相似度极高/重复的内容,常用于后推荐(如:猜你喜欢)
- 黑名单:过滤掉已经屏蔽和拉黑的用户(如:博主/UP主/主播)、内容等。
- 已读:过滤掉已读数据。
| 常见策略 | 说明 |
|---|---|
| 过滤已读 | 过滤掉已读 |
| 黑名单-用户 | 过滤用户屏蔽和拉黑的博主、UP主、主播等 |
| 黑名单-内容 | 过滤用户屏蔽和拉黑的内容 |
| 相似度过滤 | 过滤掉与当前内容相似度极高/重复的内容,常用与后推荐(猜你喜欢) |
| 比例平衡 | 维持多路召回物料比例,控制数量和比例,提升推荐多样性 |
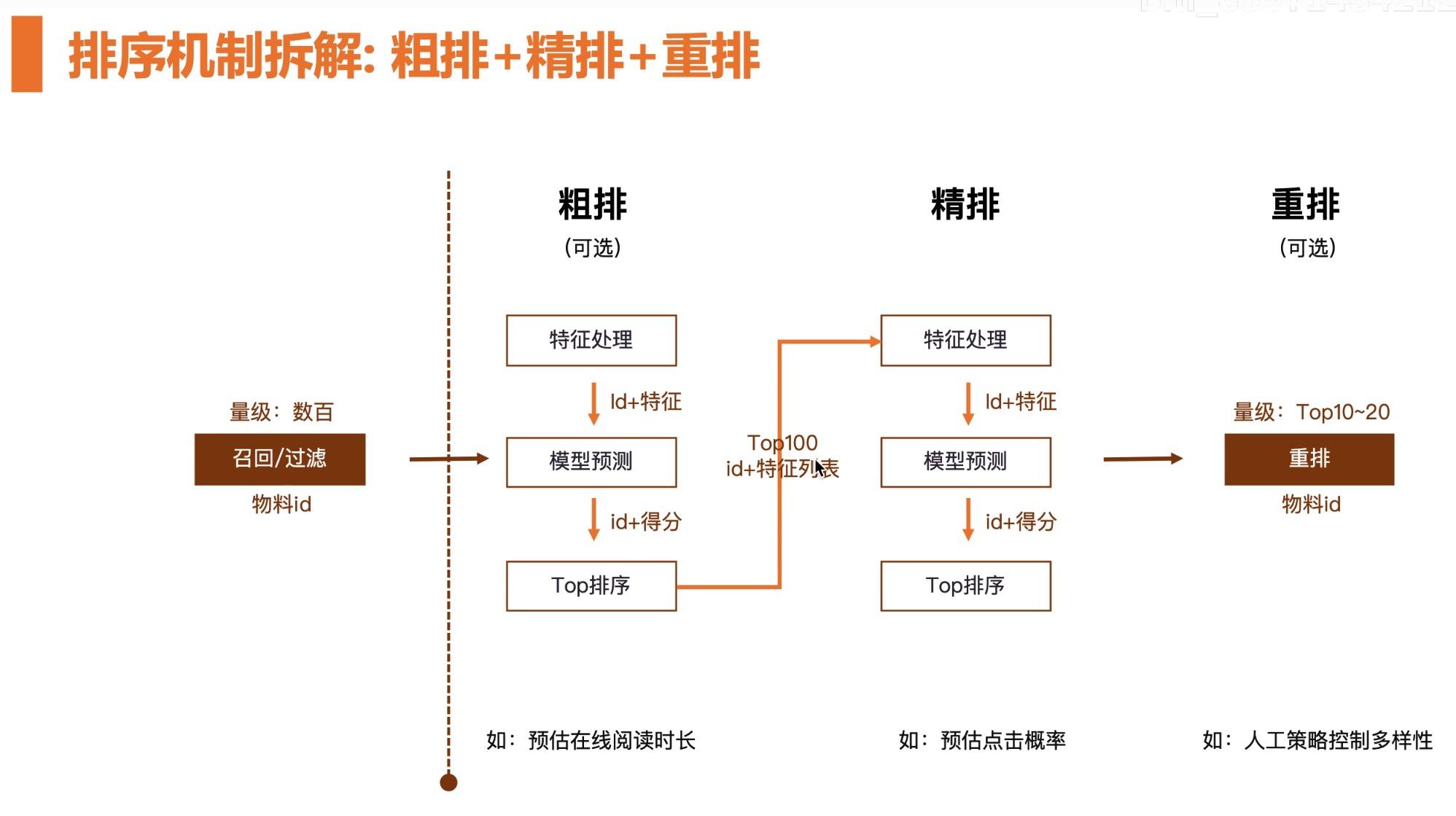
排序机制拆解:粗排+精排+重排

个性化推荐 & 机器学习 ―― 机器学习
目录
- 机器学习的基础
- 有关机器学习的最大误解
- 离线/在线机器学习推荐引擎架构
- 本系列讲解大纲
推荐系统常见的算法:LR、FM、FMM、DeepFM、DNN
有关机器学习的最大误解
- 算法: 10%
- 工程:40%
- 实验:50%
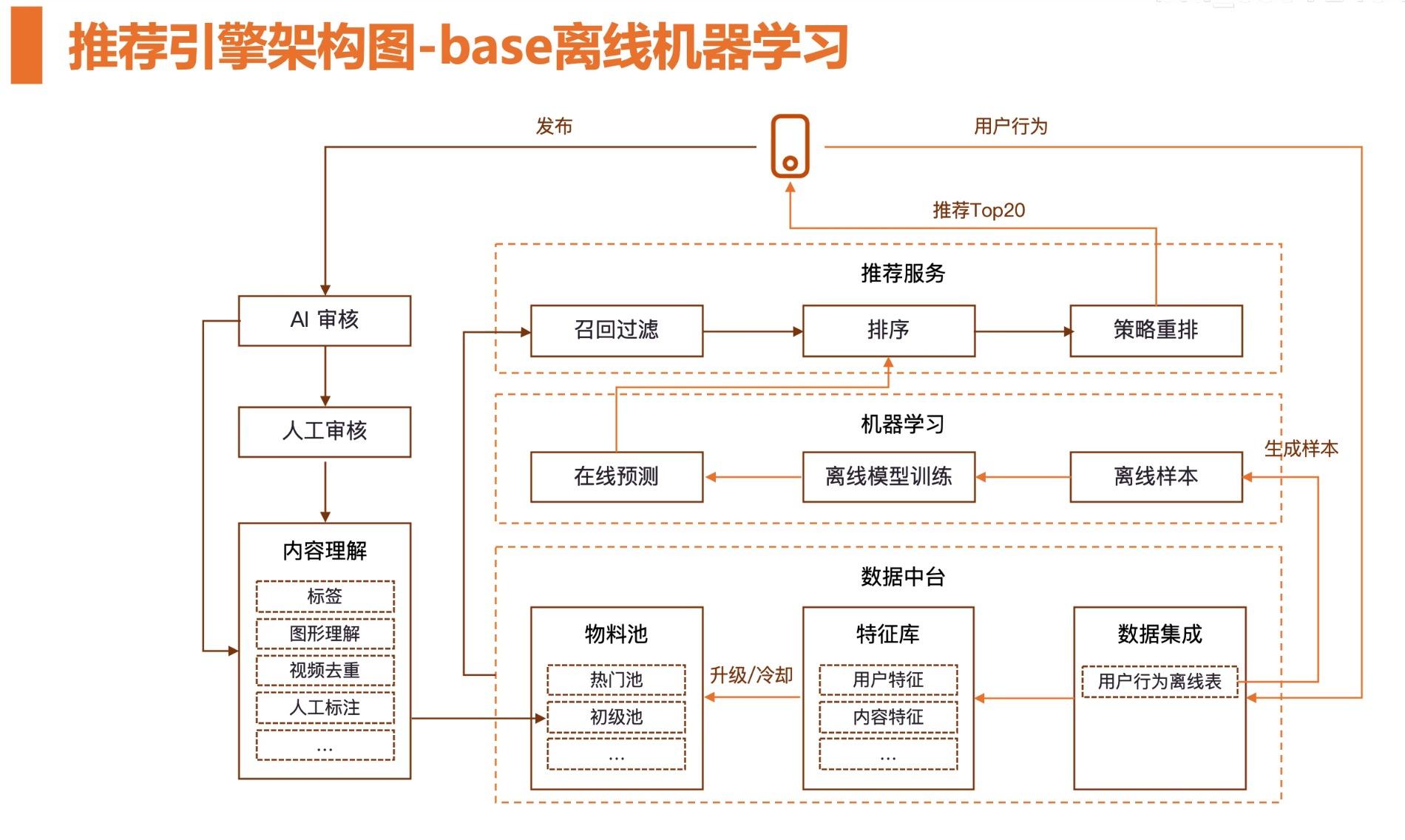
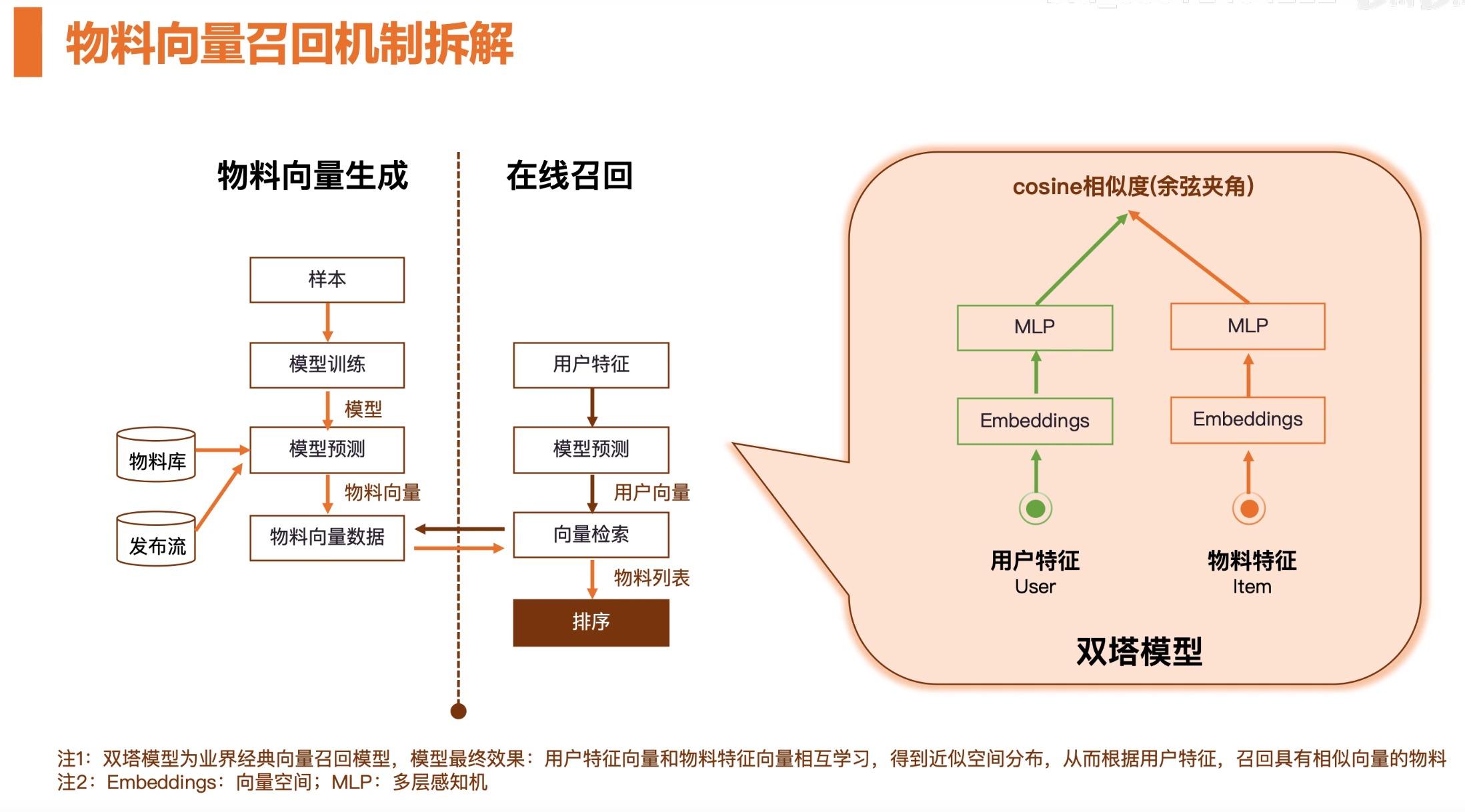
对用户发布的内容做内容理解,这里会涉及到不同的机器学习算法模型。使用自然语言处理、计算机视觉、语音识别之类的技术生成文本、视频、语音对应的特征,这些特征就会存入到特征库中。挖掘完的物料会根据不同的召回方式生成不同的物料池。
用户的行为会被记录到系统中,在业内一般会将用户行为日志存储到数据仓库中。常见的是以 Hadoop、Hive 表这种方式大数据形式的存储的离线数据。基于用户行为离线表可以做很多事情,前面提到的召回策略,召回物料的挖掘等都可以基于用户行为日志来做的。基于用户行为日志可以生成相应的用户特征和内容的特征。
机器学习是怎么实现在召回和排序过程中的服务?
首先分为 3 打环节,第 1 环节要生成离线样本,我们可以理解为拼接相关的数据给机器学习算法模型。这里一般会使用 SQL,比如大数据中的 Hive SQL 、Spark SQL 这种 SQL 的方式生成离线的样本。生成离线的样本后,接下来开始进行模型训练。模型训练就是要将大量数据灌进模型中,在一般的互联网公司,一个模型一天需要数千万数亿的样本数据来训练是很正常的。训练完模型之后,给线上提供服务。
这时候离线服务就变成了在线服务。在线是指:将模型加载到机器学习的推理机中,当我们在推荐服务里面拿到用户的信息后会拼接一个样本,然后调用在线接口。一般是个 RPC 或者 HTTP 这种形式的接口,得到预测得分,然后针对得分进行排序。排序完后,进行策略重排,最后推送出去。
机器学习很重要的一部分工作是在离线样本、离线模型训练、在线预测部分的。推荐系统中最简单、最常见的一个算法模型是逻辑回归。逻辑回归接受一堆的特征信息,比如说 100 个特征,使用回归的方法拟合。
这个过程中,样本的生成是非常重要的,样本的生成往往是基于很多的数据表,可能不仅仅是一个用户行为日志表。比如说,我们会将用户的特征、内容的特征一起拼接到样本中。
离线模型训练过程会涉及到大规模模型训练问题,从目前工业的发展来看,单机基本上是跑不动的。从经验来看,如果样本达到亿级别,哪怕是很简单的 LR 其实效果还是很不错的。
现在比较流行的在线机器学习。为什么会有在线机器学习?
离线机器学习在训练完模型之后,再发布到线上往往会有数小时或数天的间隔周期。这种情况下,会存在一个严重的问题。特别是以信息流为主的产品,比如说今日头条、微博等。由于用户的兴趣变化以及内容的发布是非常频繁的,拿微博来说,这种热点变化非常快。我们如何捕获用户行为并且能够实时掌握线上环境中用户的兴趣分布?所以,加快模型的迭代速度才能提升模型的实时处理能力。才能及时反馈线上用户行为,并且能够细粒度地刻画用户。通过离线的方式是不太能现实的,一般会将用户的行为实时地落到”用户行为实时流“队列里面,比如消息队列 Kafka。我们将这种实时流数据生成实时的样本,一般会使用 Flink 和 Storm 技术来实现。目前大部分公司会使用 Flink 。
比如说我们会一个小时拼接一次样本,那么我们在训练模型的时候,就会拿这一个小时的样本去训练模型。训练完后会将最新的模型再实时上线。整个过程叫做在线机器学习。
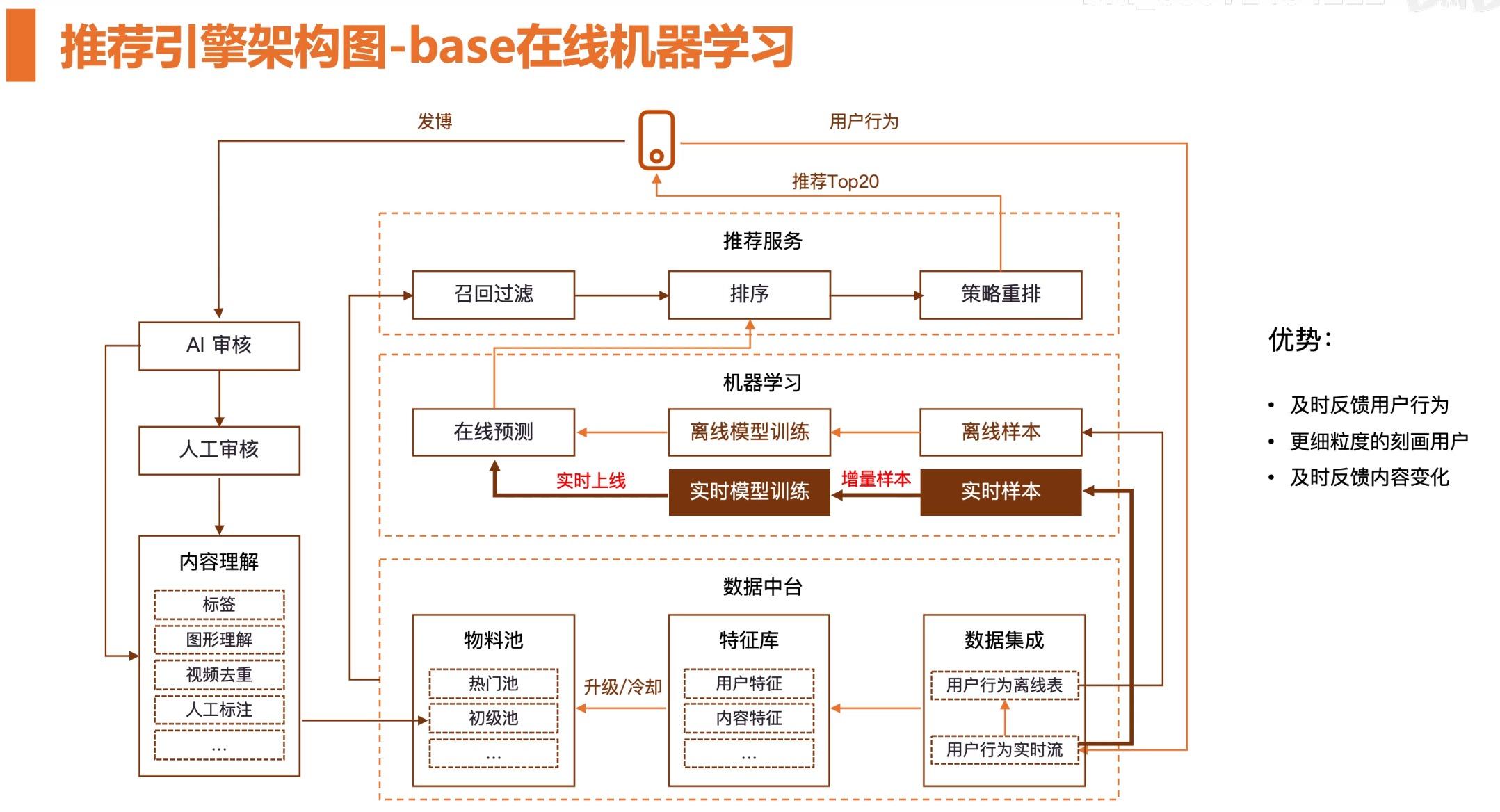
引入实时处理,会带来性能和准确度的提升,但是也会增加资源的消耗。
推荐系统召回工程 ―― 矩阵分解
目录
- 概述
- 使用场景
- 实现流程
- 特点
- 小结
矩阵分解是协同过滤算法的实现机制,前面介绍的协同过滤算法使用统计的方法实现。协同过滤算法还可以基于矩阵分解。
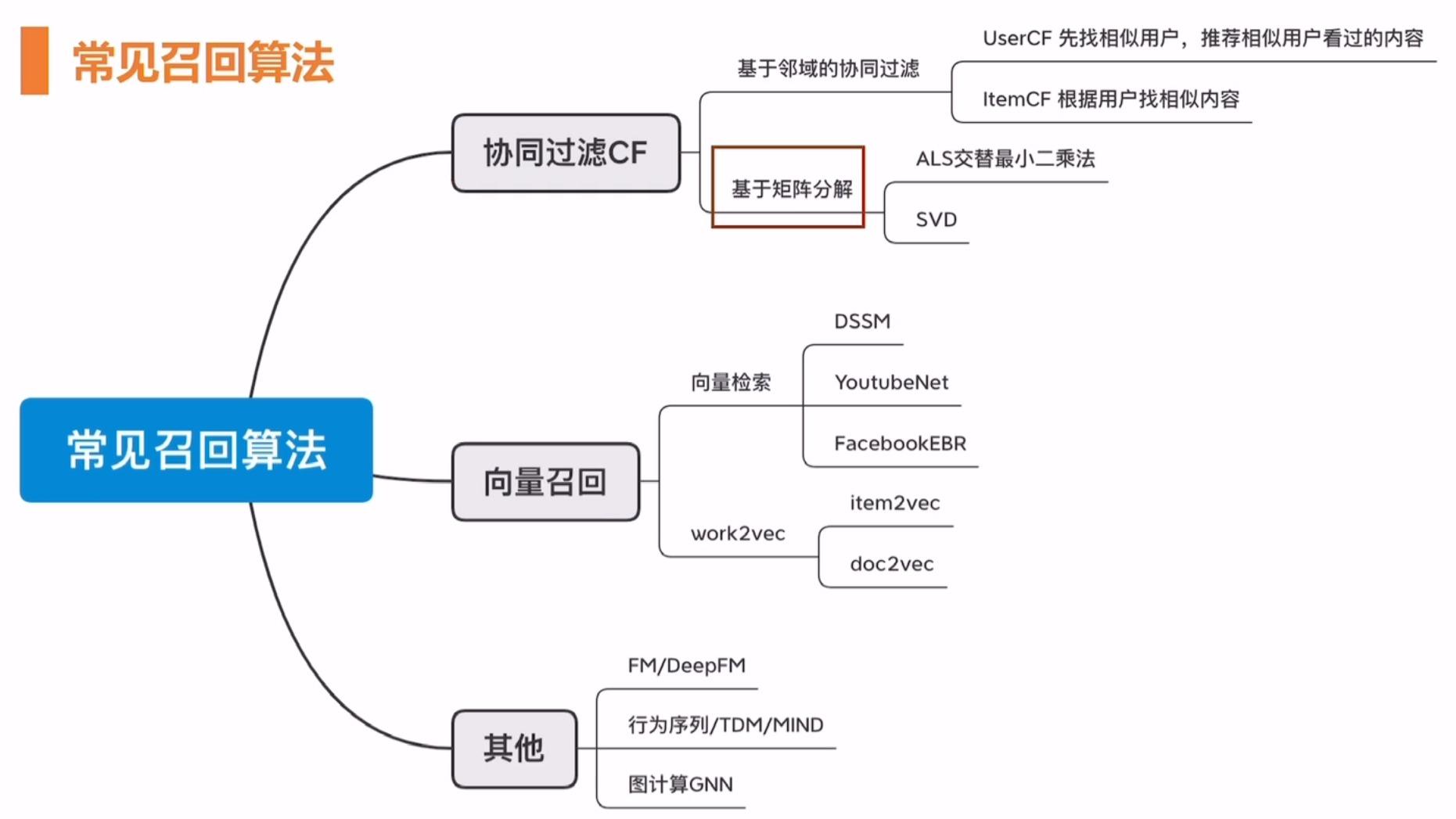
使用场景
- 经典的使用场景:U2I:计算用户可能喜欢的内容 TopN,将 TopN 作为召回结果。
- 内容相关推荐:I2I:计算内容相关的内容,将最相似的 TopN 作为召回结果,如实现相关视频推荐。
- UP主相关推荐:U2U2I:基于用户和 UP主的用户行为,计算 UP 主相似度,将最相似的 TopN 的 UP 主作为召回结果。
流程
模型训练一般使用 Spark ml 或 Flink ml,简单数十行代码就可以实现。将生成训练样本 als_uid_vid 这张表的数据通过模型的训练会分解为两个特征表:用户特征 u_vector和内容特征 v_vector 这两张表。分别对应用户向量和内容向量,也称为 embedding。
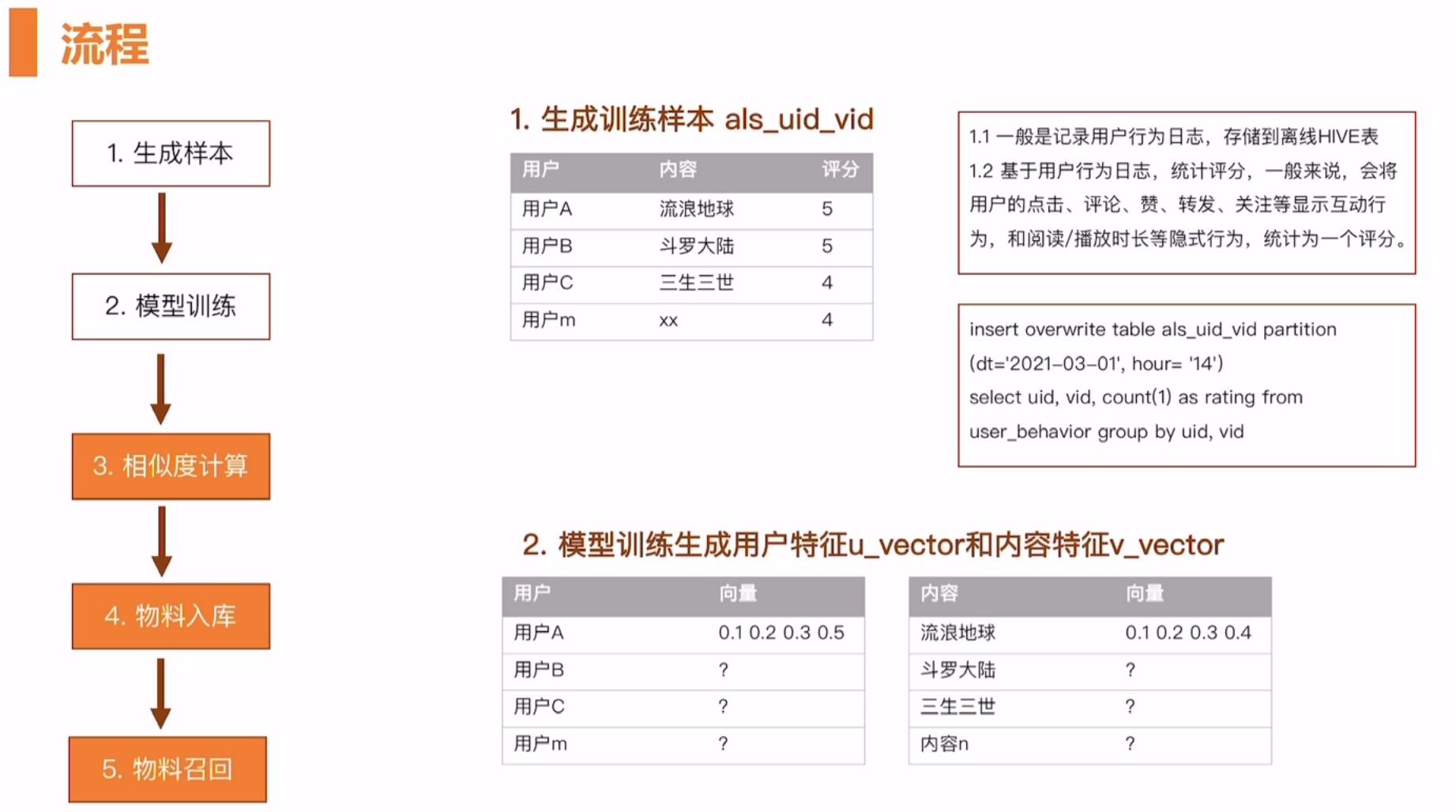

物料库常见的是 Key-Value 的形式,在业内叫做倒排索引。一般存储在内存或者固态硬盘中。物料入库及以上的部分可以看作是离线部分,物料召回部分可以看作是在线部分。如果是 U2I 的模式,Key 就是 user_id,如果是 I2I 模式,Key 就是 iterm_id。Value 就是待召回的内容清单列表。
推荐系统实时通过物料库 id、key(用户id/内容id)召回一批物料。

矩阵分解的特点
- 良好效果
- 矩阵分解结合了隐语义和机器学习的特性,能够挖掘更深层的用户和物品间的联系,因此预测的精度比较高,预测准确率要高于基于领域的协同过滤以及基于内容的推荐算法。
- 实现简单
- 矩阵分解有成熟的实现方法,如 SparkML ALS,FlinkML ALS,具有较低时间和空间复杂度。离线计算存储用户和内容低纬特征,节省空间。
- Embedding 化
- 由于矩阵分解的特点是隐式特征语义的学习,挖掘了用户和内容的关联。
- 获得用户和内容的隐式特征语义特征 UV。
- 可以通过 U 和 V 进行更多的相似检索,如 VV,UV,UU等。
- 可以作为深度神经网络的输入。
矩阵分解的缺点
- 延迟
- 模型训练比较耗时。
- 样本一般是 T+1,加大训练资源,可提升到小时级(小时拼样本+训练)
- 可解释性
- 可解释性不强,将用户和物品映射到了隐因子空间(k),这些隐含特征无法和现实生活中的概念来对应,难以解释。
- 其他
- 缺少当前的上下文环境 context,例如时间、地点等。
- 仅仅用户和物品特征,难以精准捕获用户兴趣。
矩阵分解小结
- 优秀的基础推荐算法
- 基于内容的推荐算法、基于近邻的协同过滤以及基于矩阵分解的协同过滤算法可以说是三大基础推荐算法。矩阵分解作为成熟的基础算法,在实际生产中,特别是新产品的初期阶段可以快速应用出效果。
- 流程简单可靠
- 样本生成、训练、相似计算、入物料库、线上实时召回,整个过程相对清晰,简单。
- 由于线上仅仅依赖于物料库(KV系统),边界清晰简单,可靠性高。
- 大部分工作是离线工作,相对来说时效性和稳定性要求较低。
矩阵分解算法――ALS介绍
称为交替最小二乘法。

推荐系统召回工程 ―― word2vec
目录
- 概述
- 使用场景
- 实现流程
- 特点
- 小结
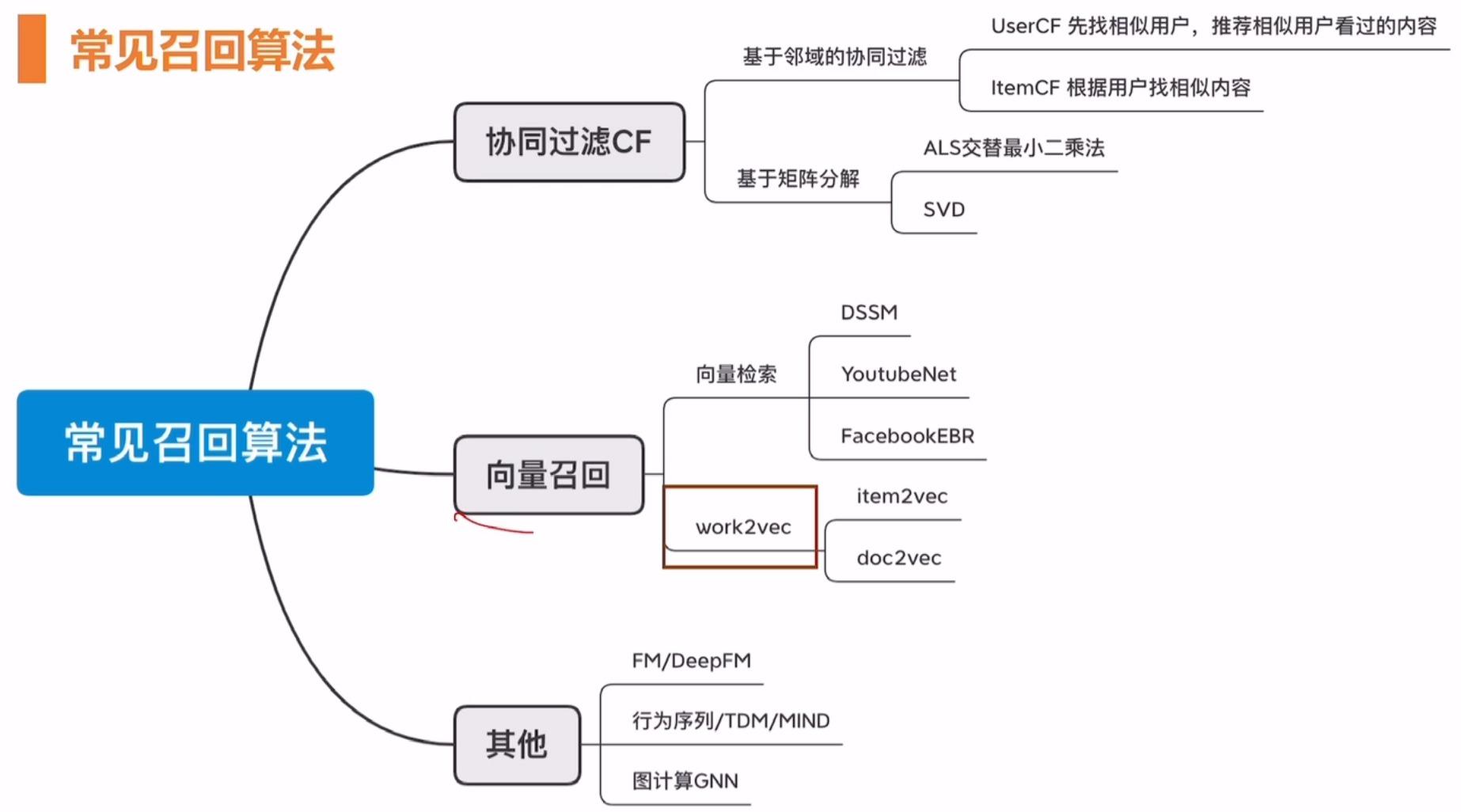
word2vec 会衍生出 item2vec和doc2vec等方法。
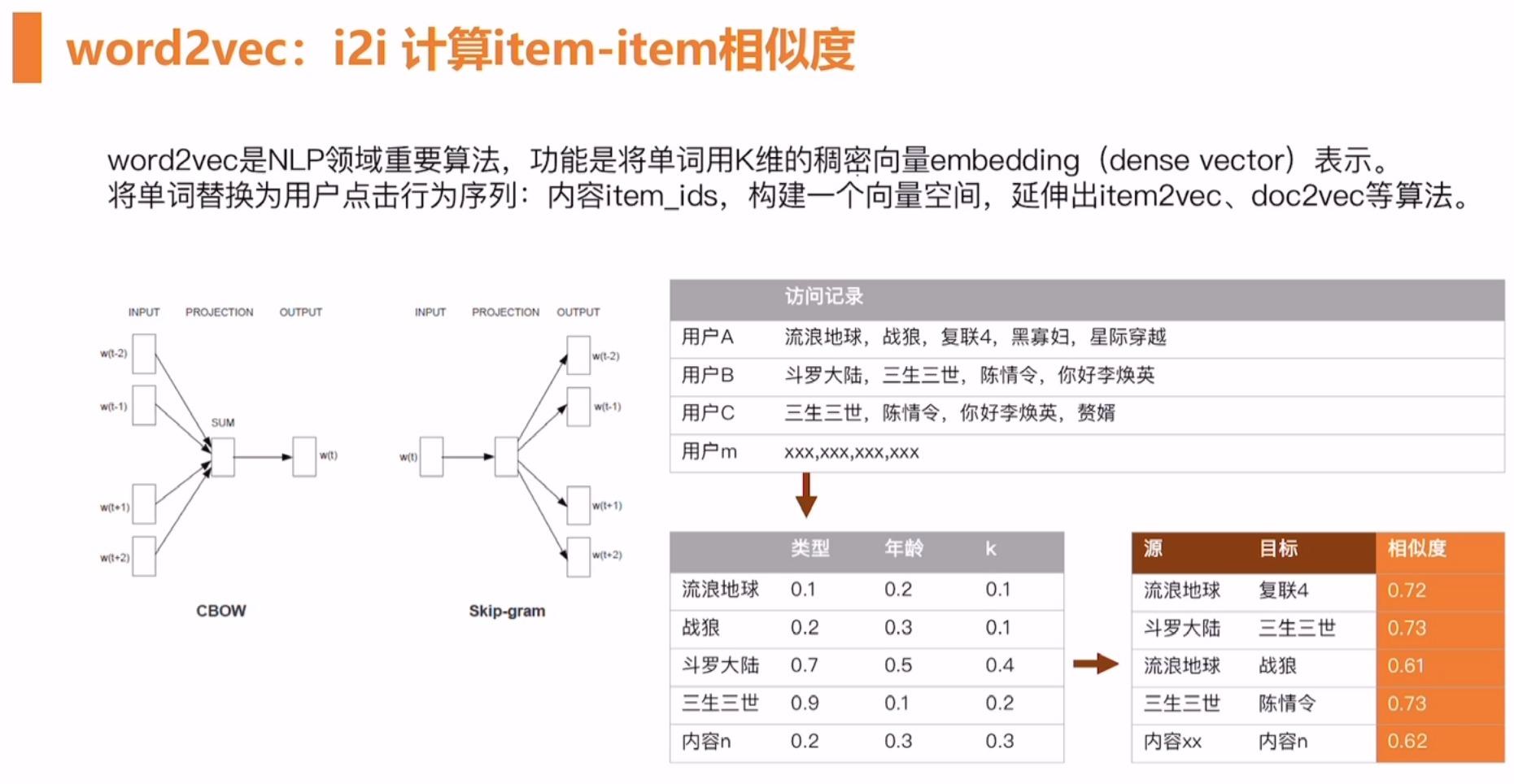
word2vec 使用场景
- 内容相关推荐 I2I:
- 计算内容相关的内容,将最相似的 TopN 作为召回结果,如实现相关视频推荐,点击 vid2vid。
- 可以组成序列的 sequence 都可以用 word2vec 学习其 embedding 表示。
- 用户行为序列相关推荐 U2I2I:
- 根据用户的行为(近期访问内容),捕获其兴趣,寻找内容相关的内容。
- 用户-行为序列 sequence ,获取兴趣表达,寻找类似兴趣的内容。
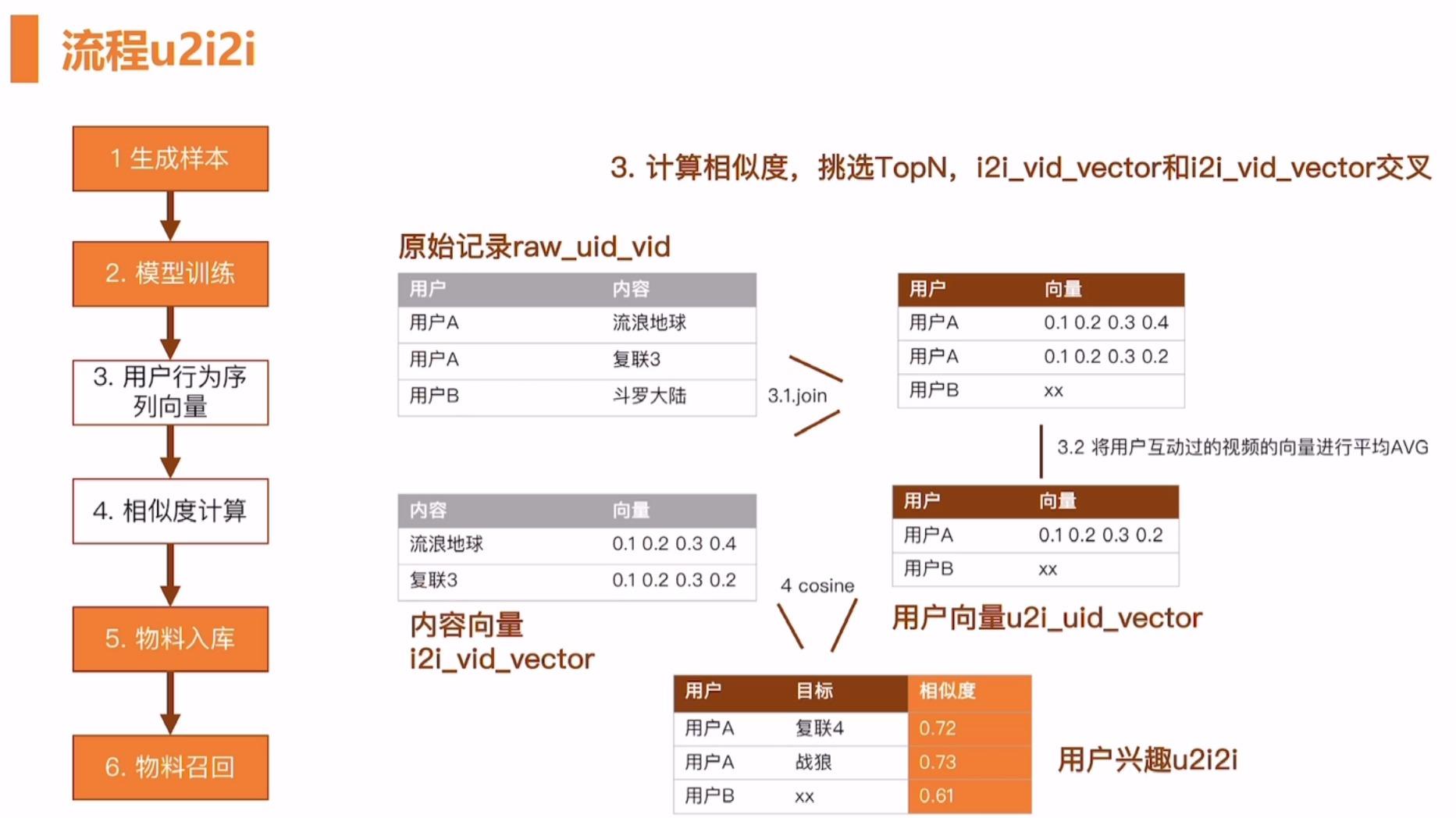
工业生产中的实际流程

和矩阵分解需要的数据不同,矩阵分解的中样本数据包括用户id 和内容,word2vec 中需要的是一个序列。这个序列就是用户的点击或者互动序列。
使用离线的 Spark Hive 就可以实现了。
模型训练过程



word2vec 的特点
- 良好的效果
- 相比于矩阵分解构建的向量空间,对热门的内容有偏向不同,word2vec 更聚焦于内容的相似性。
- 引入用户行为序列特征,更精准捕获个人的兴趣。
- 实现简单
- Word2vec 有成熟的实现方法,如 SparkML、FlinkML,具有较低时间和空间复杂度。
- 离线计算存储用户和内容低纬特征,节省空间。
- Embedding 化
- 与矩阵分解类似,也是隐式特征语义的学习,挖掘了内容和内容的关联。

word2vec 小结
- 优秀的推荐算法
- 在实际生产中,特别是新产品的初期阶段可以快速应用出效果
- 流程简单可靠
- 样本生成、训练、相似计算、入物料库、线上实时召回,整个过程相对清晰、简单。
- 由于线上仅仅依赖于物料库(KV系统),边界清晰简单,可靠性高。
- 大部分工作是离线工作,相对来说时效性和稳定性要求较低。