ժҪ
????��ǰ��KG��ȫ���� ��Ҫÿ����ϵ�д�����ѵ��ʵ��(ͷβʵ���)����ʵ�������,������Ĺ�ϵ,ֻ��������ѵ��ʵ��������С������֪ʶͼ�ײ�ȫ��û�б��ܺõ��о�,���Ա��������һ���µ�С������ϵѧϰģ��FSRL:ּ�ڴ����������з����µĹ�ϵ����Ч�ش��칹ͼ�νṹ�в���֪ʶ,��С�������б���,Ϊÿ����ϵ�ο���ƥ�����Ƶ�ʵ���,�������������ݼ��ϵĴ���ʵ�����,FSRL�ı��ֳ��˳�ɫ�����ܡ�
����
????���ģ��֪ʶͼ,��YAGO (Suchanek, Kasneci, and Weikum 2007), NELL (Carlson et al. 2010), and Wikidata (Vrande��ci��c and Kr��otzsch 2014) ͨ����ͷβʵ���(�ڵ�)�Լ����ǵ�֮��Ĺ�ϵ(��)����ʽ��ʾfact������ͼ�ṹ��֪ʶ�����������ʴ�������������������Ӧ���DZز����ٵġ�Ȼ��,֪ʶͼ�����䲻������������ Ϊ��ʹKG�ܹ�ʵ���Զ���ȫ,�����(Nickel, Tresp, and Kriegel 2011; Bordes et al. 2013; Socher et al. 2013; Yang et al. 2015; Trouillon et al. 2016; Schlichtkrull et al. 2018; Dettmers et al. 2018)�Ѿ������ͨ��ѧϰ���еĹ�ϵ���ƶ�ȱʧ�Ĺ�ϵ������:RESCAL (Nickel, Tresp, and Kriegel 2011)���������ֽ�������kg�ж��ϵ���ݵ����ڽṹ��TransE (Bordes et al. 2013) ����ϵ����Ϊ��ʵ��ĵ�άǶ��ķ��������,���GCN (Schlichtkrull et al. 2018)����ͼ�����罨����ϵ�ṹģ�͡�
????����������ÿ����ϵ����Ҫ������ʵ��ԡ�Ȼ��,��ʵ�����ݼ���,��ϵ��Ƶ�ʷֲ������г�β���ܴ�һ���ֹ�ϵ��KG��ֻ�к��ٵ�ʵ��ԡ���ֻ������ʵ��ԵĹ�ϵ����Ƕ������Ҫ�;�����ս�Եġ�
????������������,Xiong et al. (2018)�����һ������ֲ��ھӱ�������ѧϰʵ��Ƕ���Gmatchingģ��,���ڵ�������ϵ������ȡ���˺ܺõ�����,������һ���ľ����ԡ�����,GMatching�������б����ھӶ�ʵ��Ƕ��Ĺ������,Ȼ�������ھӿ����в�ͬ��Ӱ�졣���,GMatching�����������ѧϰ����ͼ�ṹ��ʾ����,����ģ�͵����ܡ��ڶ�,GMatching���ڵ�����ѧϰ����������Ƶġ���Ȼ������ͨ���ڲο���������һ���ز�����ΪС����ѧϰ���趨,����һ�����������پ�ͷ�ο�ʵ��֮��Ľ���,�����˲ο����ı�ʾ������Ϊ�˽����������֮��,���������һ��С������ϵѧϰģ��(FSRL)��Ϊ��ѧϰһ��ƥ�亯��,�ú���������Ч���ƶϳ�����ÿ����ϵ��һ��С�����ο�ʵ��Լ�����ʵʵ���(��Ԥ��Ŀ��ܴ��ڸù�ϵ��ʵ���)������,���������һ�ֹ�ϵ��֪���칹�ھӱ�������ѧϰʵ��Ƕ��,�������칹ͼ�νṹ��ע�����,���ܲ���ͬ��ϵ���͵���Ϣ���ܲ������ھӵIJ�ͬӰ�졣������,���������һ��ѭ���Զ��������ۺ���������ģС����ʵ��ԵĽ�������ΪΪÿ����ϵ�����ۻ����롣���Ųο����ľۺ�Ƕ��,�������ղ���ƥ���������������ƵĹ�ϵʵ��ԡ����û���Ԫѵ�����ݶ��½�������ģ�Ͳ��������Ż�����ѧϰ��ģ�Ϳ��Խ�һ��Ӧ�����ƶ��κ��¹�ϵ����ʵʵ���,������Ҫ�κ������衣��������,���ǵ�
��Ҫ������:
1�� ���ǽ�����һ���µ�С����KG��ȫ����,����ͬ����ǰ�Ĺ���,���ʺ�ʵ�ʳ�����
2�� ���������һ��С������ϵѧϰģ�������������⡣��ģ�ͶԼ�����ѧϰ��������ģ������������Ż���
3�� ���Ƕ������������ݼ������˹㷺��ʵ�顣 �������,���ǵ�ģ���������Ƚ��Ļ���ģ�͡�
��ع���
????������,���ǵ��������������ص���������:KGS��С����ѧϰ��ϵѧϰ��
????�����С����ѧϰģ��������:(1)���ڶ����ķ���:��һ��ѵ��ʵ����ѧϰ��Ч�Ķ�������Ӧ��ƥ�亯��������,ƥ������ͨ�������������뼸�����֧�ּ����бȽ�,����Ԥ�⡣(2)����Ԫ�Ż����ķ���:Ŀ�����ڸ���С�������ݶȵ������,�����Ż�ģ�Ͳ���,һ��������ģ���ص�Ԫѧϰ������֮ǰ��ע�Ӿ���ģ��ѧϰ��ʱ�շ�������з��������С����ѧϰ�о�,��������С����ѧϰ������KGS��ȫ��
????KGS�Ĺ�ϵѧϰ(ѧ��ϵ��ʾ),������Ѿ������,�Խ�ģ��KGS�Ĺ�ϵ�ṹ���Զ���KG��ȫ������:RESCAL�������ֽ�����ģ��Ԫ��ϵ���ݵĹ��нṹ,TransE����ϵ����Ϊ��ʵ��ĵ�άǶ���ϲ����ķ��롣�����õ���������ʾʵ��,Socher et al. (2013) ������NTN,����ʵ���ʾΪ���ǹ��ɵĵ���������ƽ��ֵ������,��������˸����ӵ�ģ��,����DistMul (Yang et al. 2015) and ComplEx (Trouillon et al. 2016). ���,��������������ģ�;���R-GCG (Schlichtkrull et al. 2018) and ConvE (Dettmers et al. 2018) �������һ���Ľ�������Щ�������㹻��ѵ��ʵ����ģ�Ͳ�ͬ,Xiong et al. (2018) �����KGSһ�ι�ϵѧϰ��GMatchingģ��,�ڱ�������,�����о���һ��ʵ�õ�����������,����С�����ο���������β�������ӵĹ�ϵ��
������
�ڱ�����,������ʽ������С����֪ͼ�ײ�ȫ����,����ϸ˵������Ӧ��С��ѧϰ���á�
���ⶨ��
????һ��KG G ��ʾΪ��Ԫ��{(h,r,t)}?E��R��E,����E��R�ֱ��ʾʵ�弯��ϵ��,KG��ȫ�����Ǹ���ͷʵ��h�ĺͲ�ѯ��ϵr:(h,r,?) Ԥ��βʵ��t,���߸���ͷ��ʵ���β��ʵ��Ԥ������֮��IJ��ɼ���ϵr:(h,?,t)�����������,������ǰһ��������֮ǰ���о�����ÿ����ϵ�����㹻��ʵ��Բ�ͬ,�����������һ��ʵ�ʳ���,������ÿһ����ϵֻ�����˺��ٵ�ʵ���(�ο���)����ʽ��,���ⶨ������:
С����֪ʶͼ�ײ�ȫ
????������ϵr����С�����ο�ʵ���(hk,tk)��Rr, ���������һ������ѧϰģ��,Ϊÿ���µ�ͷ��ʵ��h��������β����ѡʵ��t,����ʵ������Լ�������ѡʵ�弯(Xiong et al. 2018),����ֻ����һ���յ�ʵ��,�������µĹ�ϵ���в��ԵĽ����漰��ʵ����ѵ�������ʵ�塣
С����ѧϰ�趨
????�������Ŀ�������һ������ѧϰģ��,��������Ԥ����С�����ο�ʵ������fact,��ѭ�����پ�ͷѧϰ����(Ravi and Larochelle 2016; Snell, Swersky, and Zemel 2017),�����趨һ��ѵ������,��������,ÿ��ѵ�������Ӧ��һ��KG��ϵr��R���Լ���ѵ��/����ʵ�������:Dr ={ Pr train, Pr test} ,���ǽ�������ʾΪԪѵ����Tmtr��Ϊ��ģ��������ڵ�С������ϵԤ��,ÿ��Pr train ֻ����С����ʵ���,(hk, tk)��Rr������Pr test = {(hi , ti , Chi,r)|(hi , r, ti) �� G}����r�����в���ʵ���,����ÿ����ѯ(hi,r)����βʵ��ti,������ĺ�ѡʵ��tj ��Chi,r ����tj��G�е�һ��ʵ��,���,ͨ��С�����ο���Pr train���Բ�ѯ(hi,r)�����к�ѡʵ���������,��ģ�Ϳ����ڴ˼����Ͻ���Ԥ�⡣���ǽ���ϵr��������ʧ��ʾΪL��(hi , ti|Chi,r, Pr train), ���Ц���ģ�Ͳ����������,ģ��ѵ����Ŀ�걻����Ϊ:
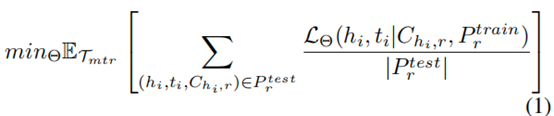
����|Pr test|��ʾPr test��Ԫ�������,��һ��,���ǽ���ϸ��������ƶ����Ż�����Ŀ�꺯����������ֵ�ѵ��,ѧϰ����ģ�Ϳ�������Ԥ��ÿ���¹�ϵr0 �� R0��fact������������Ԫ���ԡ�Ԫ�����еĹ�ϵ��Ԫѵ�����ǿ������ġ�i.e., r0�� R0 = �ա�����Ԫѵ����ϵһ��,Ԫ�����е�ÿ����ϵr0�����Լ���������ѵ������Pr0 train,�Ͳ�������Pr0 test����Щ��ϵ�γ���һ��Ԫ���Լ�,������ʾΪTmte������,���ǻ����˹�ϵ��Tmtr���Ӽ���ΪԪ��֤��Tmtv,����,��ģ�Ϳ��Է��ʱ���KG G0,����G��һ���Ӽ�,���ų������еĹ�ϵTmtr, Tmte �� Tmtv.
ģ��
????����һ��,���ǽ���ϸ����FSRL��ϸ��FSRL���������:(1)Ϊÿ��ʵ������칹�ھ�;(2)�ۺ�ÿ����ϵ��С�����ο�ʵ���;(3)�òο����Բ�ѯ�Խ���ƥ��������ϵԤ�⡣ ͼ1��ʾ��FSRL�Ŀ�ܡ�
�����칹�ھ�
????��Ȼ�������˵Ĺ���(Nickel, Tresp, and Kriegel 2011; Bordes et al. 2013; Yang et al. 2015)�Ѿ����ͨ��ʹ�ù�ϵ��Ϣ��ѧϰʵ��Ƕ��,Xiong et al. (Xiong et al. 2018) ֤������ʽ�ر���ͼ�ľֲ��ṹ�����ڹ�ϵԤ�⡣��������ھӱ����������й�ϵ�ھӵ�������ʾ��ƽ��ֵ��Ϊ����ʵ���Ƕ��,����ȡ�ýϺõ�����,�����������칹�ھӵIJ�ͬӰ��,����������ڸĽ�ʵ��Ƕ��(Zhang et al. 2019),����������,���������һ�����й�ϵ��֪�Ե��칹�ھӱ�������������˵,���Ǹ�������ͷʵ��h�Ĺ�ϵ�ھӼ�(��ϵ,ʵ��) Nh = {(ri , ti)|(h, ri , ti) �� G0},����G0�DZ���֪ʶͼ(Ǩ��ѧϰ���ҪǨ�Ƶ�֪ʶ),ri��ti��ʾh�ĵ�i����ϵ����Ӧ��β��ʵ��,�칹�����������Ӧ���ܹ�ͨ�����ǹ�ϵ�ھӵIJ�ͬӰ��(ri , ti) �� Nh������Nh,�����h��������ʾ��Ϊ��ʵ����һĿ��,����������һ��ע����ģ��,���ƶ���h��Ƕ������:
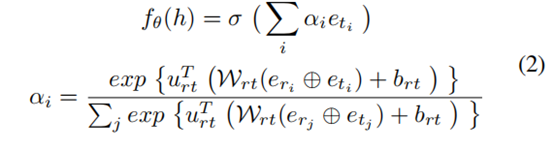
����,�ұ�ʾ���Ԫ(����ʹ��Tanh),����ʾ���������, eti , eri �� Rd��1,(d:Ԥ��ѵ����Ƕ��ά��)��Ti��RiԤѵ���ĵ�����������,, urt �� Rd��1, Wrt �� Rd��2d ��brt �� Rd��1 ���ǿ�ѧϰ�IJ�����ͼ1(B)˵�����칹�ھӱ�������ϸ�ڡ������ݵ�ʽ2,��f��(h)��ʽͨ��ע����Ȩ�ئ�i�����칹��ϵ�ھӵIJ�ͬӰ��,������ʵ��ti��ϵri�������i��

�ۺ�С�����ο���
Ŀǰ��ģ��,���ڲο����н�ģС����ʵ���Ľ���,��������ģ�͵�������������Ҫ���һ��ģ������Ч���ƶ�ÿ����ϵr�IJο���Rr�ľۺ�Ƕ�롣ͨ�����ھӱ�����f��(H)Ӧ����ÿ��ʵ���(HK,tk)��Rr,���ǿ��Եõ�ʵ���(hk��tk) �ı�ʾEhk,tk=[f��(hk)��f��(tk)]��ѧϰ�ο���Rr��С����ʵ��Եı�ʾ�Ǿ�����ս�Ե�,��Ϊ����Ҫ��ģ��ͬʵ���֮��Ľ���,���������ǵı��������������������ѧϰ����Ƕ�뷽��ij���ʵ�� (Conneau et al. 2017) ����Ȼ���Դ����;ۺϽڵ�Ƕ��(Hamilton, Ying, and Leskovec 2017) ��ͼ�������С����ǽ���������ս,��ͨ���ۺ�Rr������ʵ��Եı�ʾ����ʾRr��Ƕ��:
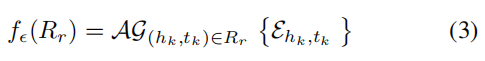
����AG��һ���ۺϺ���,�����dzػ�������ǰ��������ȡ����,�ݹ�������ۺ�������������(��ͼǶ��)��ȡ���˳ɹ�(Hamilton, Ying, and Leskovec 2017), ���������һ��ʵ������������ѭ���Զ��������ۺ����������,ʵ���Ƕ��Ehk��tk��Rr���������뵽�ݹ��Զ���������:
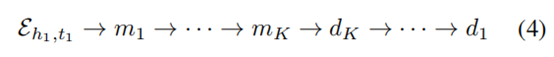
����,K�Dzο����Ĵ�С(��С������С)���������ͽ�����������״̬mk��dk�ļ��㷽��Ϊ:
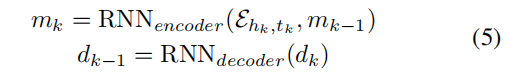
����,RNNencoder��RNNdecoder�������ֱ��ʾѭ���������ͽ�����,(e.g., LSTM (Hochreiter and Schmidhuber 1997)), �Ż��Զ����������ؽ���ʧ����Ϊ:
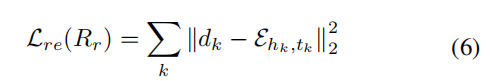
Lre�����õ���ϵ����loss��,����ϸ��ÿ��ʵ��Եı�ʾ,�����Ժ������Ϊ�˽�ģ�ο�����Ƕ����Ϣ,���Ǿۺϱ���������������״̬����ͨ�����Ӳв����Ӻ�ע������������չ����,��ʽ��, fe(Rr)�ļ��㷽��Ϊ:

����uR �� Rd��1, WR �� Rd��2d ��bR �� Rd��1 (d:�ۺ�Ƕ��ά��) ��ѧϰ������ͼ1?˵���˵ݹ��Զ��������ۺ�����ϸ�ڡ�fe(Rr)��ʽ�ۺ���Ehk��tk��Rr�����б�ʾ,��ģ���е�ÿ���������ʹ��ģ�ͻ�ø��õ�����,�������ǽ��������о�ʵ����չʾ��������
ƥ���ѯ�ԺͲο���
ͨ��ʹ���칹�ھӱ�����f�Ⱥ����ü��ۺ���fe,�������ڽ��������Ч��ƥ��ÿ����ѯʵ���(hl , tl) �� Qr (Qr�ǹ�ϵr�����в�ѯ�Եļ���) �����ü�Rrһ��ʹ�á�ͨ����f�Ⱥ�feӦ���ڲ�ѯʵ���(hl��tl)�����ü�Rr,���ǿ��Էֱ�õ�����Ƕ������Ehl,tl = [f��(hl) �� f��(tl)] and fe(Rr), Ϊ�˲�����������֮���������,����ʹ����һ���ݹ鴦����(Vinyals et al. 2016) f��ִ�жಽƥ�䡣 ��t�����̲����ƶ�Ϊ:
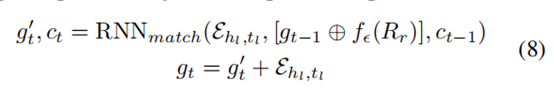
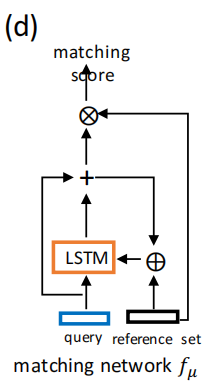
����,RNNmatch��LSTM��Ԫ��(Hochreiter and Schmid huber 1997), ��������Ehl,tl����״̬gt�͵�Ԫ��״̬ct����T������������֮������һ������״̬gT��Ϊ��ѯ��(hl,tl)�Ĵ������Ƕ�롣����ʹ��Ehl,tl��fe(Rr)֮����ڻ���Ϊ���������֡�ͼ(d)��ʾ��ƥ�䴦�����Ľṹ����ģ�������Ч�����ģ������,���ǽ��������о�ʵ����֤����
Ŀ�꺯����ģ��ѵ��
���ڲ�ѯ��ϵr,���������ȡһ��������(��)ʵ���{(hk, tk)|(hk, r, tk) �� G},

����������Ϊ�ο���Rr, ������ʵ���PEr = {(hl , tl)|(hl , r, tl) �� G �� (hl , tl) ?Rr} ��������ѯ�ԡ�����,���ǻ�ͨ��ͨ����Ⱦβ��ʵ�幹����һ�鸺(��)ʵ���N Er = {(hl , t_l^- )|(hl , r, t_l^- ) /�� G}�����,������ʧ������Ϊ:
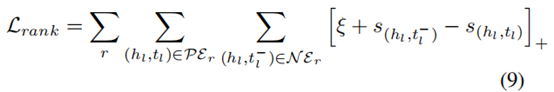
����[x]+= max[0, x]�DZ�������ʧ,�����ǰ�ȫ��Ե����,s(hl,tl)��s(hl,t_l-)�Dz�ѯ��(hl,tl/t_l-)�Ͳο���Rr֮������������֡�ͨ�����òο����ۺ������ع���ʧСֵ,���ǽ�����Ŀ�꺯������Ϊ:

���Ц���Lrank��Lre֮���Ȩ�����ӡ����ǽ�ÿһ�ֹ�ϵ��Ϊһ������,�����һ�ֻ�������������Ԫѵ�����̡�Algorithm 1���ܽ���������̵�ϸ�ڡ�