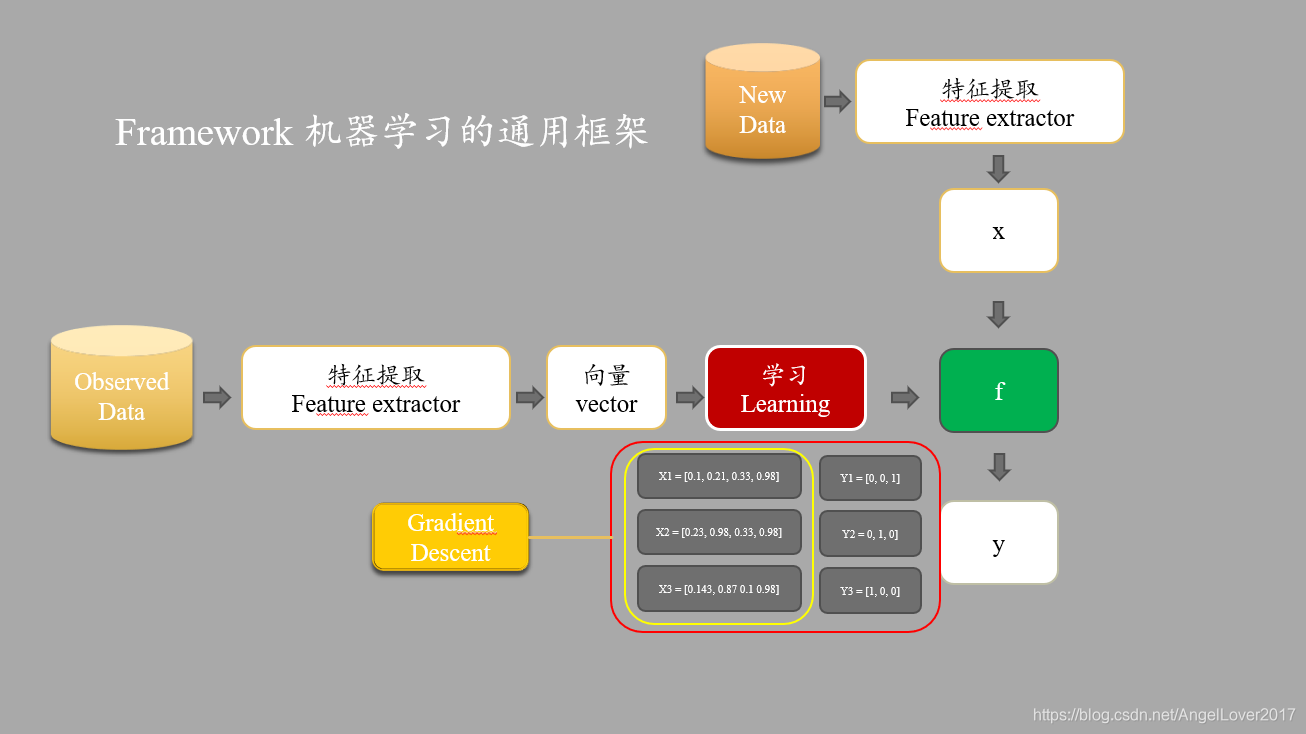
в§бд
Дг2016ФъAalphGOКсПеГіЪР,ОЊбожкШЫЕНЯждк2021ЪРНчФЇЛУ,ЮтЧЉДѓЭыРЮЗЙвбО4ФъЖрЪБМф,етЫФФъЪЧЛњЦїбЇЯА,ЩюЖШбЇЯАЕФAIжЧФмЫуЗЈХюВЊаЫЪЂЕФ4Фъ,ЮДРДдѕУДбљ,ДѓРаУЧИїгаЗжЫЕ,зїЮЊЦеЭЈШЫ,ЛЙЪЧКУКУЬЄЬЄЪЕЪЕзЅзЁГБСїЬсЩ§здМК,ВХЪЧгІЖдетФЇЛУЪРНчЕФецЕРРэЁЃБЪепНёФъбавЛ,ДгБОПЦИуЧАЖЫЕНЯждкзЊаЭИужЧФм,ЭДПргыПьРжВЂаа,НёЬьетЦЊЮФеТзїЮЊжЎКѓзЊаЭПЊЪМЕФДІХЎжЎзї,ИааЛИїЮЛЩЭЙтДЙдФзОзїЁЃ
НёЬьетЦЊЮФеТвдЯпадЛиЙщЮЊР§,ДјСьЖСепШыУХЛњЦїбЇЯАСьгђ,ЛњЦїбЇЯАЪЧAIСьгђЕФвЛИізгЗЖГы,ЫљгаПЩвдЪЕЯжЛњЦїздбЇЯАЕФЫуЗЈЖМЪєгкетИіСьгђ,ЕЋЪЧОЭФПЧАЗЂеЙРДПД,ЛњЦїбЇЯАЗНЗЈТлгавЛЬзГЩЪьЕФСїГЬЬхЯЕ,вВМДЪЧЁАбЇЯАЁБЕФКЌвх,ЪЧЛњЦїФЃФтШЫРрНјаабЇЯАЕФЙ§ГЬЁЃ
ЛњЦїбЇЯАЪЧвЛУХЖрСьгђНЛВцбЇПЦ,ЩцМАИХТЪТлЁЂЭГМЦбЇЁЂБЦНќТлЁЂЭЙЗжЮіЁЂЫуЗЈИДдгЖШРэТлЕШЖрУХбЇПЦЁЃзЈУХбаОПМЦЫуЛњдѕбљФЃФтЛђЪЕЯжШЫРрЕФбЇЯАааЮЊ,вдЛёШЁаТЕФжЊЪЖЛђММФм,жиаТзщжЏвбгаЕФжЊЪЖНсЙЙЪЙжЎВЛЖЯИФЩЦздЩэЕФадФмЁЃ ЁЊЁЊЁЊЁЊ в§здЁЖАйЖШАйПЦЁЗ
ЧјЗжгаМрЖНКЭЮоМрЖНШЮЮё
ЛњЦїбЇЯАНЋбЇЯАШЮЮёжаЕФЪ§ОнЪЧЗёОЙ§СЫШЫЙЄБъзЂзїЮЊгаМрЖНЛђЮоМрЖНЕФБъзМЁЃОйИіР§зг,ШчЙћЮвУЧЯыИљОнвЛИіШЫЕФЩэИпЬхжиРДХаЖЯетИіШЫЪЧЪєгкЪнЛЙЪЧХж,ФЧУДЮвУЧШЫРрЯШЕУИцЫпЛњЦїЪВУДбљЕФЩэИпЬхжиЪєгкЪнЛђепХж,етЯдШЛЪєгкгаМрЖНЕФШЮЮё;ШчЙћЮвУЧЯыИљОнвЛИіАрМЖжабЇЩњЕФадИёжИБъИјбЇЩњЗжГЩМИзщ,ФЧУДЯдШЛЮвУЧШЫРрВЂВЛЛсжБНгИцЫпЛњЦїгІИУдѕУДЗжзщ,ЖјЪЧШУЛњЦїЭЈЙ§ЫуЗЈздМКНЈСЂвЛИіЗжзщ,етЪєгкЮоМрЖНШЮЮёЁЃвЛАуРДЫЕ,гаМрЖНбЇЯАЕФгІгУГЁОАЪЧвЊдЖДѓгкЮоМрЖНЕФгІгУГЁОАЕФЁЃ
ЧјЗжЛиЙщЮЪЬтгыЗжРрЮЪЬт
дкЛњЦїбЇЯАСьгђ,МИКѕЫљгаЕФгаМрЖНЮЪЬтЖМБЛЛЎЗжЮЊСЫЛиЙщКЭЗжРрЮЪЬтЁЃЫљвд,дкНјШыЛњЦїбЇЯАСьгђжаЕФЕквЛМўЪТЧщЪЧвЊбЇЛсЧјЗжвЊНтОіЕФЮЪЬтЪЧЗжРрЛЙЪЧЛиЙщЁЃДгЭЈЫзвтвхЩЯНВ,ЗжРрЪЧЪЖБ№ЫЪЧЫЕФЮЪЬт,ЖјЛиЙщЪЧдЄВтЫгаЖрЩйЕФЮЪЬтЁЃБШШч,ЖдгквЛеХУЈЛђЙЗЕФееЦЌ,вЊЗжБцЕНЕзЪЧУЈЛЙЪЧЙЗ,етЪєгкЗжРрЮЪЬт;ЖдгкИљОнМИИідТЕФЯњЪлЧщПідЄВтЯТвЛИідТЕФЯњЪлЖю,етЪєгкЛиЙщЮЪЬтЁЃЕЋЪЧгааЉЪБКђ,вЛИіЪЕМЪЮЪЬтЕФЖЈвхУЛгаФЧУДУїЯдЕФЗжРрЛђдЄВтКЌвх,етИіЪБКђОЭашвЊПДЪ§ОнЕФLabelЪЧСЌајЕФ,ЛЙЪЧРыЩЂЕФ,ШчЙћЪЧСЌајЕФОЭЪЧЛиЙщЮЪЬт,РыЩЂЕФОЭЪЧЗжРрЮЪЬтЁЃ
ЯпадЛиЙщЮЪЬт
СЫНтСЫвЛаЉЛњЦїбЇЯАжаЕФЛљБОИХФю,ЮвУЧРДПДПДЪВУДЪЧЯпадЛиЙщЮЪЬтЁЃаЮШч:
y
=
ІШ
0
+
ЁЦ
i
=
1
n
ІШ
i
x
i
g
i
v
e
n
??
y
,
x
i
(
i
=
1
,
2
,
.
.
.
,
n
)
s
o
l
v
e
??
ІШ
j
(
j
=
0
,
1
,
2
,
.
.
.
,
n
)
y = \theta_0 + \sum_{i=1}^{n}\theta_ix_i \newline given\ \ y,x_i(i=1,2,...,n) \newline solve\ \ \theta_j(j=0,1,2,...,n)
y=ІШ0?+i=1ЁЦn?ІШi?xi?given??y,xi?(i=1,2,...,n)solve??ІШj?(j=0,1,2,...,n)
етРрОљЪєгкЯпадЛиЙщЮЪЬт,жЎЫљвдГЦжЎЮЊЯпад,ЪЧвђЮЊ
y
y
yЪЧ
x
x
xЕФЯпадзщКЯЁЃПМТЧвЛЯТЯпадЛиЙщЮЪЬтЪєгкгаМрЖНЛЙЪЧЮоМрЖН?ЯдШЛЪєгкгаМрЖН,вђЮЊВЛНіга
x
x
x,ЛЙга
y
y
y,ЮвУЧИцЫпСЫФЃаЭгІИУОпгадѕУДбљЕФЪфШыКЭЪфГі,ШУФЃаЭЭЈЙ§бЇЯАЕУЕНвЛзщ
ІШ
\theta
ІШ,ЪЙЕУТњзуетбљЕФЪфШыЪфГіЁЃОйИіР§зг,БШШчЖдгкШЋЙњЕФЩЬЦЗЗПбљБОЮвУЧжЊЕРЦфШ§ИіЮЌЖШЕФаХЯЂ:ЫљдкГЧЪа(
x
1
x_1
x1?),ЫљдкЧјгђЕФШЫПкУмЖШ(
x
2
x_2
x2?),ЫљдкЧјгђЕФжааЁбЇЪ§ФП(
x
3
x_3
x3?),вдМАетИіЩЬЦЗЗПЕФМлИё(
y
y
y),ЧыФугУЯпадЛиЙщНЈФЃЮЪЬтВЂЧѓНтФЃаЭВЮЪ§ЁЃ
ДгДЋЭГЫуЗЈЕНЛљгкЭГМЦЕФЛњЦїбЇЯАЫуЗЈ
ЕБФуПМТЧНтОіЩЯЪіЯпадЛиЙщЮЪЬтЪБ,ФуЛсЗЂЯжЮвУЧКмФбДгвбгаЕФДЋЭГЫуЗЈЫМЯы(Р§Шч,ЗжжЮ,ЖЏЬЌЙцЛЎ,ЬАаФЕШ)жаевЕНвЛИіЪЪКЯНтОіетИіЮЪЬтЕФЫМЯыЁЃвђЮЊЭљЭљРДЫЕ,ДЋЭГЫуЗЈЫМЯыЪЪгУгкевОЋШЗНт,ЕЋЪЧетИіЮЪЬтЕФОЋШЗНтКмФбЧѓГіРД,ОЭБШШчЗПМлЕФдЄВтЩцМАЕНЗНЗНУцУцЕФвђЫи,вђЫиЕФзїгУгаДѓгааЁ,МДБуЪЧОбщРЯЕРЕФФкааШЅдЄВтвВЛсгаЫљЦЋВю,ЫљвддкЛњЦїбЇЯАСьгђ,ЮвУЧевЕНЕФНтЭљЭљЪЧНќЫЦНтЁЃЧѓНтНќЫЦНтЕФЗНЗЈ,вВПЩвдЪЙгУЛљгквЛЖЈЦєЗЂЪНЙцдђЕФЫуЗЈЧѓНт,ЕЋЪЧЕБЪ§ОнСПОоДѓЪБ,етжжЗНЗЈЕФаЇЙћОЭгааЉзННѓМћжт,етвВОЭЪЧНќФъРДЛњЦїбЇЯАгыЩюЖШбЇЯАХюВЊЗЂеЙЕФдвђ,Ъ§ОнСїСПМЄдіЕФЪБДњ,ДгЪ§ОнжаЭкОђЧБдкМлжЕЪЧетаЉAIЫуЗЈЕФЪЙУќЁЃ
ЛњЦїбЇЯАЕФЭЈгУПђМмПЩвдМђЕЅРэНтЮЊЫФИіВПЗж:ЬиеїЬсШЁ,ЯђСПЛЏБэеї,бЕСЗбЇЯА,ЬнЖШЯТНЕЁЃ
- ЬиеїЬсШЁ:ДгвЛЖбвђЫижаЬсШЁГіЖдФЃаЭгАЯьИќДѓЕФвЛаЉЬиеїЁЃР§Шч,ЗПМлдЄВтжагАЯьЗПМлЕФвђЫиКмЖр,ЕЋЪЧВЂВЛЪЧЫљгаЕФвђЫиЖМЪЧгагУЕФ,ПЩФмДцдкдыЩљвђЫи,ЮвУЧБиаыдкФЃаЭбЇЯАЧАЬоГ§етаЉвђЫиЁЃ
- ЯђСПЛЏБэеї:ЮвУЧЪеМЏРДЕФЪ§ОнКмДѓГЬЖШЩЯВЛЭъШЋЪЧЪ§жЕРраЭЕФ,КмЖрПЩФмЪЧзжЗћДЎБэЪОЁЃЛљгкЭГМЦЕФЛњЦїбЇЯАЫуЗЈ,жЛШЯЪЖЪ§жЕ,вђДЫЮвУЧашвЊгУЪ§жЕБэеїЬиеї,вЛИіЬиеїЕФвЛзщЪ§жЕОЭЪЧвЛИіЯђСПЁЃ
- бЕСЗбЇЯА:бЕСЗбЇЯАЪЧНЋЪ§ОнВЛЖЯЫЭШыФЃаЭ,ФЃаЭОЙ§ЖрТжбЇЯА,ВЛЖЯЕїећВЮЪ§( ІШ \theta ІШ)ЕФЙ§ГЬЁЃ
- ЬнЖШЯТНЕ:бЯИёвтвхЩЯНВ,ЬнЖШЯТНЕЪєгкбЕСЗбЇЯАЗЖГы,ЪЧбЕСЗбЇЯАВЛЖЯЕќДњЕФКЫаФЫљдкЁЃШчЙћЖСепбЇЯАЙ§ЭЙгХЛЏРэТл,ПЩФмЛсжЊЕР,етЪЧЧѓНтгХЛЏЮЪЬтЕФзюМђЕЅЕФЕќДњЗНЗЈЁЃ
ЪЕеНВПЗж
ЮвУЧНгЯТРДНЋвдвЛИіМђЕЅЕФЯпадЛиЙщР§зг,РДНВЪівЛИіЭъећЕФЛњЦїбЇЯАЙ§ГЬЁЃ
Ъ§ОнЩњГЩ
Яждк,МйЩшЮвУЧгавЛзщ(
x
,
y
x,y
x,y)Ъ§Он,вЊЪЙгУЯпадЛиЙщРДНЈФЃВЂЧѓНтЁЃЮвУЧЯШРДЮЊНгЯТРДЕФР§згЩњГЩвЛЕуЪ§ОнЁЃЮвУЧАДееШчЯТЙЋЪННјааЪ§ОнЩњГЩ:
y
=
5
x
+
100
+
ІШ
r
a
n
d
o
m
x
=
0
,
1
,
.
.
.
,
99
ІШ
r
a
n
d
o
m
ЁЪ
{
ІШ
ЈO
?
100
Ём
ІШ
Ём
100
}
y = 5x+100+\theta_{random} \newline x = 0,1,...,99 \newline \theta_{random}\in\{\theta|-100\leq\theta\leq100\}
y=5x+100+ІШrandom?x=0,1,...,99ІШrandom?ЁЪ{ІШЈO?100ЁмІШЁм100}
import random
import numpy as np
import matplotlib.pyplot as plt
def gf(a,b):
def f_(x):
return a*x + b
return f_
def generate_data(count,f_args=(3,4)):
x = np.arange(count)
f = gf(*f_args)
y = f(x) + np.array([random.randint(-100,100) for i in range(count)])
return (y,x)
y,x = generate_data(100,(5,100))
plt.scatter(x,y)
ЛцжЦГіРДЕФЩЂЕуЭМШчЯТЫљЪО:
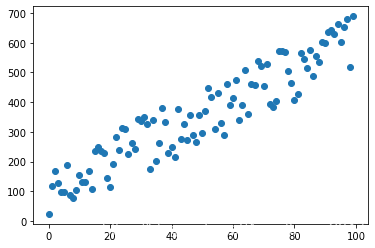
дкетИіР§згжа,ЮвУЧКіТдСЫЬиеїЬсШЁКЭЯђСПЛЏ,вђЮЊЮвУЧЩњГЩЕФЪ§ОнжБНгОЭЪЧПЩвдЪфЫЭИјФЃаЭЕФЯђСП(
x
?
,
y
?
\vec{x},\vec{y}
x,y?)ЁЃ
НЈФЃгыЧѓНтЫМТЗ
ЯпадФЃаЭ
КмЯдШЛ,дкетИіР§згжа,ЮвУЧЦкЭћЕФФЃаЭОЭЪЧ
y
=
5
x
+
100
y=5x+100
y=5x+100,ЕЋЪЧЮвУЧЯЃЭћЛњЦїПЩФмздМКбЇЯАЕУЕН,вђДЫЪзЯШНЈСЂвЛИіЯпадФЃаЭ:
h
ІШ
(
x
)
=
ІШ
0
+
ІШ
1
x
h_\theta(x) = \theta_0 + \theta_1x \newline
hІШ?(x)=ІШ0?+ІШ1?x
Ы№ЪЇКЏЪ§
гаСЫФЃаЭ,ЮвУЧЛЙашвЊвЛИіЦРМлФЃаЭКУЛЕЕФжИБъ,дѕУДжЊЕРФЃаЭФмЙЛКмКУЕФФтКЯЩЯУцетаЉЕуЕФЗжВМФи?дкЛиЙщЮЪЬтжа,ЮвУЧГЃгУЕФзюЮЊМђЕЅЕФЦРМлжИБъОЭЪЧMSE(ОљЗНЮѓВюКЏЪ§):
J
(
ІШ
0
,
ІШ
1
)
=
1
2
m
ЁЦ
i
=
1
m
(
h
ІШ
(
x
(
i
)
)
?
y
(
i
)
)
2
J(\theta_0,\theta_1) = \frac{1}{2m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2
J(ІШ0?,ІШ1?)=2m1?i=1ЁЦm?(hІШ?(x(i))?y(i))2
етРяжЎЫљвдЪЧ
1
2
m
\frac{1}{2m}
2m1?,ЖјВЛЪЧ
1
m
\frac{1}{m}
m1?ЕФдвђЪЧ,ЮЊСЫаое§MSEЧѓЕМКѓЕФЖрГіРДЕФЯЕЪ§
2
2
2ЁЃетРяЕФЦРМлжИБъКЏЪ§вВГЃГЃБЛГЦжЎЮЊLossКЏЪ§,ЛђепCostКЏЪ§ЁЃЪТЪЕЩЯ,етИіжИБъКтСПСЫецЪЕжЕ(
y
y
y)гыФЃаЭИјГіЕФдЄВтжЕ(
h
ІШ
(
x
)
h_\theta(x)
hІШ?(x))жБНгЕФЦНОљЮѓВюЁЃКмШнвзРэНт,ЮвУЧЯЃЭћетИіЮѓВюдНаЁдНКУ,вђЮЊдНаЁОЭБэЪОЮвУЧЕФФЃаЭИќФмЬљНќецЪЕЕФЪ§ОнЁЃ
def MSE_Loss(x,y,fn):
m = len(x)
y_hat = fn(x)
loss = (1/(2*m)) * (np.sum((y_hat-y)**2))
return loss
ЬнЖШЯТНЕ
Ыљвд,ЮвУЧКмШнвзРћгУЭЙгХЛЏРэТл,НЋетИіЮЪЬтзЊЛЛЮЊвЛИігХЛЏЮЪЬтЁЃ
ІШ
?
=
a
r
g
?
m
i
n
ІШ
J
(
ІШ
)
,
ІШ
=
[
ІШ
0
,
ІШ
1
]
T
\theta^* = arg\ \mathop{min}\limits_{\theta} J(\theta) , \theta = [\theta_0,\theta_1]^T
ІШ?=arg?ІШmin?J(ІШ),ІШ=[ІШ0?,ІШ1?]T
ЧѓНтетИігХЛЏЮЪЬт,ПЩвдЪЙгУЬнЖШЯТНЕЗНЗЈ,ЬнЖШЯТНЕЙЋЪНШчЯТ:
ІШ
n
=
ІШ
n
?
1
?
ІС
?
J
(
ІШ
n
?
1
)
?
ІШ
n
?
1
\theta^{n} = \theta^{n-1} - \alpha\frac{\partial J(\theta^{n-1})}{\partial\theta^{n-1}}
ІШn=ІШn?1?ІС?ІШn?1?J(ІШn?1)?
ЮвУЧПЩвдМђЕЅРэНтвЛЯТЬнЖШЯТНЕЕФецЪЕКЌвхЁЃ
ІС
\alpha
ІСДњБэОЭЪЧlearning rate(бЇЯАТЪ),ГЃЩшЮЊ0.1~0.001жЎМфЕФГЃЪ§ЁЃ
ІШ
n
\theta^{n}
ІШnКЭ
ІШ
n
?
1
\theta^{n-1}
ІШn?1ЗжБ№ДњБэБОДЮЕќДњЕУЕНЕФаТЕФВЮЪ§ЯђСПКЭЩЯДЮЕќДњЕФВЮЪ§ЯђСПЁЃзюЙиМќЕФЪЧЬнЖШ(
?
J
(
ІШ
n
?
1
)
?
ІШ
n
?
1
\frac{\partial J(\theta^{n-1})}{\partial\theta^{n-1}}
?ІШn?1?J(ІШn?1)?)ЕФКЌвхЁЃВЛбЯИёЕФЫЕ,ЮвУЧПЩвдАбЬнЖШРэНтЮЊЕМЪ§,Р§ШчЖўДЮКЏЪ§
f
(
x
)
f(x)
f(x)ЕФзюЕЭЕуЪЧЮвУЧЯывЊЕНДяЕФФПЕФЕи,ДЫПЬЮвдкзюЕЭЕуЕФзѓБпКЏЪ§ЧњЯпЩЯ,ЮвЯывЊЭљзюЕЭЕузп,ОЭвЊЯђзХЕМЪ§ЕФИКЗНЯђзпВХЪЧе§ШЗЕФЗНЯђ,ЗДгІЕНЪ§жЕЩЯОЭЪЧЮвЯТвЛДЮИќаТЕФВЮЪ§гІИУдіДѓ,ЖјВЛЪЧМѕаЁЁЃФЧУДдіДѓЖрЩйФи?ЯдШЛЪЧ
ІС
\alpha
ІСГЫвдЕМЪ§,етУДДѓЁЃФуРэНтСЫТ№?
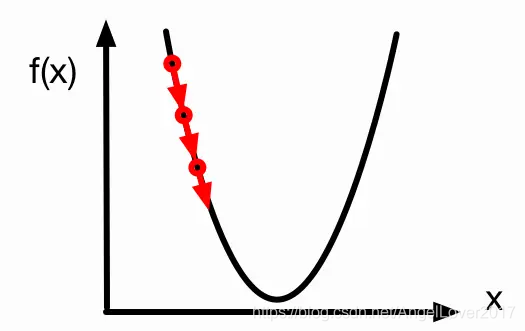
зюКѓашвЊзЂвтЕФЕиЗНЪЧ,дкзюПЊЪМ,ЛњЦїЯдШЛВЂВЛжЊЕРе§ШЗЕФВЮЪ§(
ІШ
0
,
ІШ
1
\theta_0,\theta_1
ІШ0?,ІШ1?)ЪЧЖрЩй,вђДЫЕквЛДЮЮвУЧПЩвдЫцЛњГѕЪМЛЏвЛИі
ІШ
0
\theta_0
ІШ0?КЭ
ІШ
1
\theta_1
ІШ1?,жЎКѓОЭАДееЬнЖШЯТНЕЖдВЮЪ§НјааИќаТМДПЩЁЃ
def gradient_descent(arg,lr,grad):
return arg - lr * grad
ЧѓЕМЙ§ГЬ
?
J
(
ІШ
n
?
1
)
?
ІШ
n
?
1
\frac{\partial J(\theta^{n-1})}{\partial\theta^{n-1}}
?ІШn?1?J(ІШn?1)? ОпЬхдѕУДЧѓНтФи?вђЮЊЛњЦїздМКВЛЛсЧѓЕМ,вђДЫетВПЗжЛЙашвЊЮвУЧздМКЪжЖЏШЅЭЦЕМ,ВЂзЊЛЛГЩДњТыЁЃетРяЮвУЧЪЙгУСДЪНЧѓЕМЗЈдђ,ЯШЖд
h
h
hЧѓЦЋЕМ,дкЖд
ІШ
\theta
ІШЧѓЦЋЕМЁЃ
?
J
(
ІШ
0
,
ІШ
1
)
?
ІШ
0
=
?
J
?
h
?
h
?
ІШ
0
=
1
m
ЁЦ
i
=
1
m
(
h
ІШ
(
x
(
i
)
)
?
y
(
i
)
)
?
J
(
ІШ
0
,
ІШ
1
)
?
ІШ
1
=
?
J
?
h
?
h
?
ІШ
1
=
1
m
ЁЦ
i
=
1
m
(
h
ІШ
(
x
(
i
)
)
?
y
(
i
)
)
x
(
i
)
\frac{\partial J(\theta_0,\theta_1)}{\partial\theta_0} = \frac{\partial J}{\partial h}\frac{\partial h}{\partial\theta_0} = \frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})\newline \frac{\partial J(\theta_0,\theta_1)}{\partial\theta_1} =\frac{\partial J}{\partial h}\frac{\partial h}{\partial\theta_1} =\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x^{(i)} \newline
?ІШ0??J(ІШ0?,ІШ1?)?=?h?J??ІШ0??h?=m1?i=1ЁЦm?(hІШ?(x(i))?y(i))?ІШ1??J(ІШ0?,ІШ1?)?=?h?J??ІШ1??h?=m1?i=1ЁЦm?(hІШ?(x(i))?y(i))x(i)
def mse_linear_gradient(x,y,fn):
m = len(x)
y_hat = fn(x)
a_grad,b_grad = (1/m) * np.sum((y_hat-y)*x) , (1/m) * np.sum((y_hat-y))
return (a_grad,b_grad)
ФЃаЭБраД
гаСЫЩЯУцЕФЫМТЗКЭЛљДЁ,ОЭЭђЪТОуБИ,жЛЧЗЖЋЗчСЫЁЃЮвУЧжЛашвЊАбЬнЖШЯТНЕЕќДњЕФЙ§ГЬгУДњТыБэДяГіРДОЭПЩвдСЫЁЃЮЊСЫЪЙЕУНгПкИќЭЈгУ,ПЩвдЩшжУСНИіГЌВЮЪ§max_iterКЭlr,ЗжБ№БэЪОзюДѓЕќДњДЮЪ§КЭбЇЯАТЪЁЃ
class linear_model:
def __init__(self,max_iter=100,lr=0.01):
self.max_iter = max_iter
self.lr = lr
def fit(self,data):
x,y = data
# ГѕЪМдйвЛЖЈЗЖЮЇФкЫцЛњ a,b
a,b = [random.randint(-1,1) for i in range(2)]
f = gf(a,b)
# ЪЙгУЬнЖШЯТНЕгХЛЏ + MSE_Loss ЕќДњЧѓНтЯпадФЃаЭЕФВЮЪ§
for i in range(self.max_iter):
# МЦЫуLoss
loss = MSE_Loss(x,y,f)
print("loss",loss)
# МЦЫуЬнЖШ
a_grad,b_grad = gradient(x,y,f)
# ЬнЖШЯТНЕ,ИќаТВЮЪ§
a = gradient_descent(a,self.lr,a_grad)
b = gradient_descent(b,self.lr,b_grad)
print(a,b)
# ИќаТФЃаЭ
f = gf(a,b)
return f
ФЃаЭбЕСЗгыбщжЄ
ПЩвдПДЕН,ОЙ§300ДЮЕФЕќДњ,зюжеЕУЕНСЫвЛЬѕЛЙЫуВЛДэЕФКЏЪ§,ДѓжТЗДгІСЫЪ§ОнЕуЕФЗжВМЧїЪЦЧщПіЁЃЯИаФЕФЖСепПЩФмЛсЗЂЯжетеХЭМжа
x
,
y
x,y
x,yЕФЪ§жЕЗЖЮЇБЛЗХЫѕЕНСЫ
[
0
,
1
]
[0,1]
[0,1]жЎМф,ЖдгІЕФВйзїОЭЪЧminmax_normalize,етОЭЪЧЛњЦїбЇЯАжаГЃгУЕНЕФЙщвЛЛЏВйзїЁЃетВНВйзїЕФФПЕФгаКмЖр,Р§Шч,ЙщвЛЛЏПЩвдЪЙЕУЬнЖШГЏзХзюгХНтЗНЯђ,НјЖјМгПьбАгХЫйЖШ;ЙщвЛЛЏЛЙПЩвдНЋВЛЭЌСПИйЕФЪ§ОнЗХЫѕЕНЭЌвЛСПИйФк,ЪЙЕУИїИіЬиеїШЈжиЗжВМКЯРэ;ЙщвЛЛЏЛЙгавЛИігХЕу,ОЭЪЧЗРжЙЬнЖШБЌеЈКЭЬнЖШЯћЪЇ,етвВЪЧетИіР§згжаВЛЕУВЛНјааЙщвЛЛЏЕФдвђ,ЮвНЋдкЯТвЛНкЯъЯИВћЪіетИіЪТЧщЁЃЕНФПЧАЮЊжЙ,ЮвУЧгУвЛИіЯпадЛиЙщЕФМђЕЅР§зг,НВЪіСЫЛњЦїбЇЯАЕФЭЈгУЕФПђМмВНжш,ВЛжЊЕРФуУїАзСЫТ№?
# Normalization
def minmax_normalize(x):
return (x-np.min(x))/(np.max(x)-np.min(x))
model = linear_model(max_iter=300)
# Ъ§ОнЙщвЛЛЏ MinMax
x,y = minmax_normalize(x),minmax_normalize(y)
f = model.fit((x,y))
plt.scatter(x,y)
plt.plot(x,f(x))
plt.show()
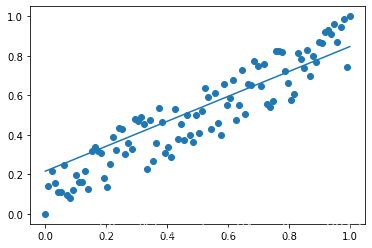
ЮДЙщвЛЛЏЕМжТЕФЬнЖШБЌеЈ
ШчЙћФуГЂЪдНЋетИіР§згжаЙщвЛЛЏВйзїШЅЕє,ВЂАбmax_iterИФЮЊ100,ОЭЯёетбљЁЃ
model = linear_model(max_iter=100)
f = model.fit((x,y))
plt.scatter(x,y)
plt.plot(x,f(x))
plt.show()
ФЧЮвУЧЛсЕУЕНвЛИіЗЫвФЫљЫМЕФНсЙћЁЃ
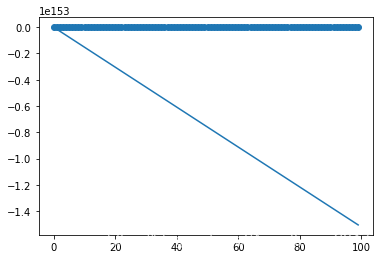
ВщПДжаМфЕФlossЪфГівдМА
a
,
b
a,b
a,bЕФИќаТ,ЮвУЧЛсЗЂЯжlossВЛМѕЗДді,ЩѕжСдіДѓЕНСЫ
3.7
e
+
302
3.7e+302
3.7e+302етбљЕФЪ§СПМЖ,
a
,
b
a,b
a,bвВЪЧЭЌбљЧщПіЁЃШчЙћЮвУЧМЬајдіДѓmax_iterЕН300,ЮвУЧЛсЗЂЯжlossЕФЪфГіжаЖрСЫКмЖрinfКЭnanЁЃinfЪЧpythonжаЕФЮоЧюДѓЕФБэЪОЗНЗЈ,вВМДЬнЖШдіДѓЕНСЫЮоЧюДѓЁЃnanБэЪО Not A Number,ВњЩњnanЕФЧщПігаКмЖр,БШШч
i
n
f
/
i
n
f
,
i
n
f
?
i
n
f
inf/inf,inf-inf
inf/inf,inf?infЕШЖМЛсВњЩњnanжЕЁЃвђДЫзлКЯРДПД,ЮвУЧЕФФЃаЭЗЂЩњСЫЬнЖШБЌеЈ,вВМДЬнЖШдкМЦЫуЕФЙ§ГЬжаДѓЕФРыЦзЁЃ
ЮвУЧРДПДПД,ЬнЖШБЌеЈЪЧШчКЮВњЩњЕФЁЃЯТУцЪЧЮДОЙщвЛЛЏЕФЪ§ОндкбЕСЗЙ§ГЬжаЕФвЛзщжЕ,
y
_
h
y\_h
y_h БэЪОФЃаЭЕБЧАдЄВтжЕ,
y
y
yБэЪОдЪМЪ§ОнжаЕФжЕ,ОЙ§вЛДЮЬнЖШЕФМЦЫу,ЮвУЧЗЂЯжЬнЖШЕФЪ§СПМЖвбОЕНСЫЧЇЭђСПМЖЁЃетбљДѓЕФЬнЖШЛсЕМжТВЮЪ§ЕФИќаТвВЗЂЩњМЋДѓЕФИФБф,НјвЛВНЕМжТ
y
_
h
y\_h
y_hжаЕФжЕЗЖЮЇБфЕУИќДѓ,етбљЯТвЛДЮМЦЫуЬнЖШЛсИќДѓ,вРДЮЖёааЕќДњ,ЕМжТLossЕФжЕдНРДдНДѓ,ЬнЖШвВдНРДдНДѓ,зюжеДѓЕНЮоЧюДѓЛђЮоЧюаЁ,ЮоЗЈМЬајМЦЫу,БуЛсЕУЕНnanжЕЁЃ
y_h = np.array([-76,-166,-256,-346,-436,-526,-616,-706,-796,-886,-976 ,-1066
,-1156 ,-1246 ,-1336 ,-1426 ,-1516 ,-1606 ,-1696 ,-1786 ,-1876 ,-1966 ,-2056 ,-2146
,-2236 ,-2326 ,-2416 ,-2506 ,-2596 ,-2686 ,-2776 ,-2866 ,-2956 ,-3046 ,-3136 ,-3226
,-3316 ,-3406 ,-3496 ,-3586 ,-3676 ,-3766 ,-3856 ,-3946 ,-4036 ,-4126 ,-4216 ,-4306
,-4396 ,-4486 ,-4576 ,-4666 ,-4756 ,-4846 ,-4936 ,-5026 ,-5116 ,-5206 ,-5296 ,-5386
,-5476 ,-5566 ,-5656 ,-5746 ,-5836 ,-5926 ,-6016 ,-6106 ,-6196 ,-6286 ,-6376 ,-6466
,-6556 ,-6646 ,-6736 ,-6826 ,-6916 ,-7006 ,-7096 ,-7186 ,-7276 ,-7366 ,-7456 ,-7546
,-7636 ,-7726 ,-7816 ,-7906 ,-7996 ,-8086 ,-8176 ,-8266 ,-8356 ,-8446 ,-8536 ,-8626
,-8716 ,-8806 ,-8896 ,-8986])
y = np.array([145 ,129 ,78 ,107 ,48 ,178 ,55 ,151 ,229 ,169 ,145 ,81 ,231 ,210 ,128 ,88 ,242 ,259
,95 ,217 ,188 ,280 ,131 ,157 ,182 ,302 ,174 ,262 ,251 ,210 ,342 ,248 ,246 ,337 ,318 ,261
,335 ,360 ,212 ,244 ,316 ,263 ,229 ,378 ,324 ,344 ,417 ,306 ,353 ,378 ,346 ,257 ,354 ,393
,321 ,431 ,382 ,436 ,458 ,295 ,426 ,479 ,462 ,458 ,484 ,497 ,495 ,489 ,437 ,484 ,484 ,537
,469 ,389 ,438 ,393 ,471 ,432 ,550 ,504 ,582 ,496 ,555 ,539 ,607 ,523 ,431 ,632 ,548 ,537
,585 ,586 ,584 ,624 ,610 ,477 ,534 ,587 ,527 ,501])
np.sum((y_h-y)*x)
# output : -32103025
зюКѓЛЎИіжиЕу: ШчЙћбЕСЗЙ§ГЬжагіЕНЬнЖШЛђLossжЕДѓЕФРыЦз,ЩѕжСГіЯжinfЛђnanжЕЪБ,ОЭПЩвдПМТЧгІИУЪЧЗЂЩњЬнЖШБЌеЈСЫ,ЙщвЛЛЏжЛЪЧНтОіЬнЖШБЌеЈЕФВпТджЎвЛ,ЛЙгаЦфЫћЗНЗЈ,ЖСепПЩвдздааВщдФЁЃ
ИааЛЖСЭъећЦЊЮФеТ,ШчгаВЛЖдЕФЕиЗН,ЭћЦРТлжИГіЁЃШчЙћОѕЕУгаЫљЪеЛё,ИјЮвРДИіШ§СЌАЩ!