本文根据网络资料与原论文整合而成,参考资料见最下
paper:R-FCN: Object Detection via Region-based Fully Convolutional Networks
提出的动机:
- 从平移不变与可变性方面的理解:作者分析了图片分类任务中需要CNN平移不变性 与 对象检测任务中需要的平移可变性的困境;作者也认为越深的网络,对于位置预测越不敏感(因为CNN的平移不变性导致的),而ROI的设计是region-specific操作,破坏了这种平移不变性,使其对位置预测有效。本文提出一个位置敏感得分map技术,将类别和位置信息融入到ROI Pooling中。
- 从计算消耗方面的理解:原始的Faster RCNN在RPN后附加一个网络用于ROI-wise(region-wise)的对象检测,这个附加的网络Batch大小是ROI数目,这样由于没有共享每个ROI的计算,从而导致的Faster RCNN的速度低,因而R-FCN意在解决这个问题。
- 主要思想:受启发于FCN,进行像素级的识别,利用群众投票的方式,对ROI Pooling后的fmaps直接获取类别和位置,相当于使得类别和位置信息的获取是cost-free,且也相当于共享了两个任务的conv层。
1. Introduction
Region Proposal Network (RPN)提出了候选RoI,然后将其应用于评分图上。所有可学习的权重层都是卷积的,并在整个图像上计算;每个RoI的计算成本可以忽略不计。
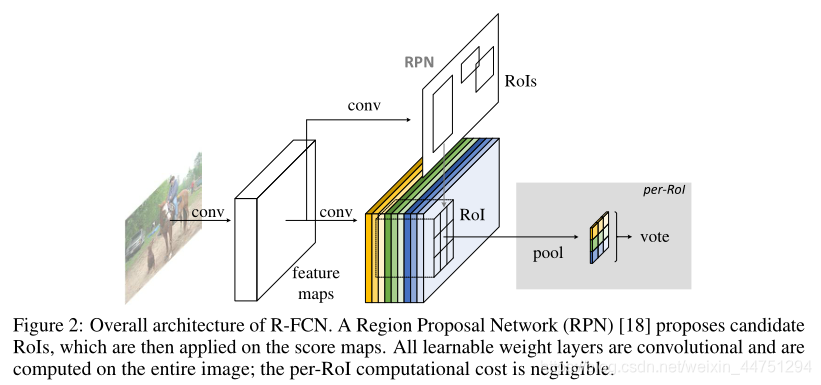
网络由backbone(ResNet-101的前100层),RPN(生成 RoIs),backbone后的跟的最后一层卷积层,这一层有两个分支,分别对应的是分类分支和回归分支,这两个分支的卷积层产生若干位置敏感的score maps,然后RPN得到的RoI在这些maps上通过位置敏感的一个RoI pooling做池化操作,得到RoI-wise的结果。上图只显示了一个分支,没有体现完善。
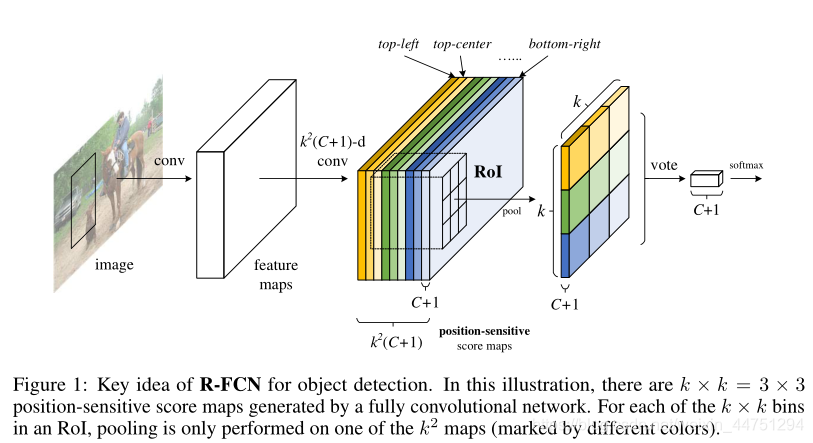
backbone后的卷积层(分类分支为例)对每个category输出k×k个 position-sensitive score maps,对于C个种类+背景就会有k×k(C+1)channels。其中,对于每个种类,其k×k个maps中,每个maps分别编码该类物体位置上的一部分,例如如果人用的k×k是3×3=9,则9个maps中每个maps分别对应人的左上,中上(头),右上,,,右下(右脚)等。
R-FCN 最后用位置敏感 RoI 池化层,给每个 RoI 1个分数。选择性池化图解:看上图的橙色响应图像 (top?left),抠出橙色方块 RoI,池化橙色方块 RoI 得到橙色小方块 (分数);其它颜色的响应图像同理。对所有颜色的小方块投票 (或池化) 得到1类的响应结果。
 R-FCN 在与 RPN 共享的卷积层后多加1个卷积层。所以,R-FCN 与 RPN 一样,输入为整幅图像。但 R-FCN 最后1个卷积层的输出从整幅图像的卷积响应图像中分割出感兴趣区域的卷积响应图像。
R-FCN 在与 RPN 共享的卷积层后多加1个卷积层。所以,R-FCN 与 RPN 一样,输入为整幅图像。但 R-FCN 最后1个卷积层的输出从整幅图像的卷积响应图像中分割出感兴趣区域的卷积响应图像。
2. Visualization
RoI 分类的可视化。RPN 刚好产生包含 person 类的 RoI。经过 R-FCN 的最后1个卷积层后产生9个相对空间位置的分数图,对 person 类的每个相对空间位置通道内的 RoI 桶平均池化得到3×33×3的池化分数,投票后送入分类器判断属于 person 类。当分类正确时,该类通道的位置敏感分数图 (中间) 的大多数橙色实线网格内的响应在整个 RoI 位置范围内最强。
当RoI与ground truth贴合时候的sore maps:

当RoI与ground truth不重合时的score maps:

这些专门的特征图预计会在物体的特定相对位置被强烈激活。例如,“顶部中心敏感”分数图在物体的顶部中心位置附近显示出高分。如果候选框与真实对象精确重叠,那么RoI中的大多数kxk bins都会被强烈激活,并且它们的投票会导致高分。相反,如果候选框没有正确地与真实对象重叠,则RoI中的一些kxk bins不会被激活,投票分数较低。
参考资料:
https://blog.csdn.net/mingshili/article/details/80549871
https://blog.csdn.net/yanghao201607030101/article/details/109998647
https://blog.csdn.net/weixin_42905141/article/details/95307597