- 本文主要梳理V2V关节点估计算法的原理、网络结构、以及工程应用。
- 虽然V2V是2017年的算法,但是其3D点云处理流程和效果还是很经典的,值得作为入门3D深度学习领域的一个窗口。
1 算法部分
V2V-PoseNet基本介绍
- 发明时间:2017年
- 功能:3D关节点估计(如应用于手掌关节点估计)
- 输入数据:一张包含目标的depth图。(如用Kinect、realsense等传感器采集的的depth图)
- 输出结果:目标物体关节点的X,Y,Z坐标值。
- 两句话概括创新点:
- 第一句话:传统方法是基于2D深度图直接回归关节点坐标,而我们是把2D深度图投影到3D空间,然后用3D卷积去操作,这能解决2D深度图的透视畸变问题。(透视畸变问题见下面)
- 第二句话:我们不是直接回归关节点坐标,而是估计每个点云所属某关节点的概率值。(用热图表示)
- 所获荣誉:
- CVPR2018
- 大大领先优势,获得当年基于帧的3D手部姿态估计挑战赛第一名。
- 在当前(2021年8月)手势姿态估计领域,效果排名第3。
算法结构介绍
论文中结构图如下:
自己绘制的更详细版结构图如下:

损失函数
就是把预测的3D热图(每个关节点有一个3D热图)和标签生成的热图计算均方误差:

作者认为3D识别关节点的好处
 作者如何制作数据集的?
作者如何制作数据集的?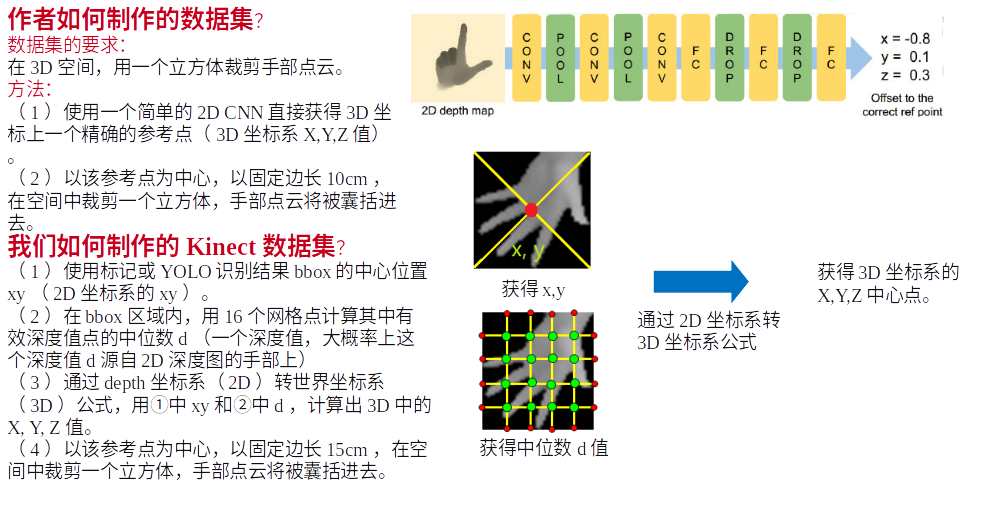
算法数据流图详情

2 工程部分
需求
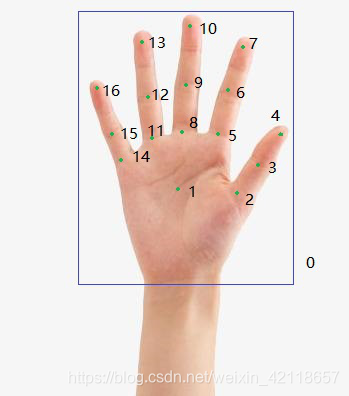
通过手势来虚拟触控激光投影,其中就需要使用V2V算法,识别手掌的16个关节点,并计算手指3关节点的空间延长线和桌面的交汇点坐标。?
16个手指关节点位置:
?
?Kinect2相机:
16位深度图转8位灰度图?
Kinect2相机采集的depth图是16位存储的,原因是depth图中包含距离信息,值在0~2000mm之间。但是实际上我们只需要手部区域的depth图用于后续的V2V做关节点估计。最简单方法是,用YOLO目标检测器训练一个depth图的手掌目标检测模型,让YOLO算法裁剪人的手掌区域。

YOLO检测的是depth区间在1200mm至1800mm高度区间的图像,得到手部区目标框位置后,我们需要基于原始16位的depth图,去找到手部区的“中心点”,这个中心点物理意义大概是手掌在空间中的几何中心,后续我们需要基于这个中心点,去在depth转3D点云图上,以这个中心点为立体中心,去裁剪一个手部区空间,并最终送到V2V网络去预测手掌关节点位置。计算出这个中心点位置的方法有很多,这里我们简单的用16个“网格点”去获取中心点的Z值,XY值就取YOLO裁剪的手部depth图的XY值。
 中心点选取方案的测试方法如下:(评估到底有多少手部点被排除在立方体之外)
中心点选取方案的测试方法如下:(评估到底有多少手部点被排除在立方体之外)
 ?
?
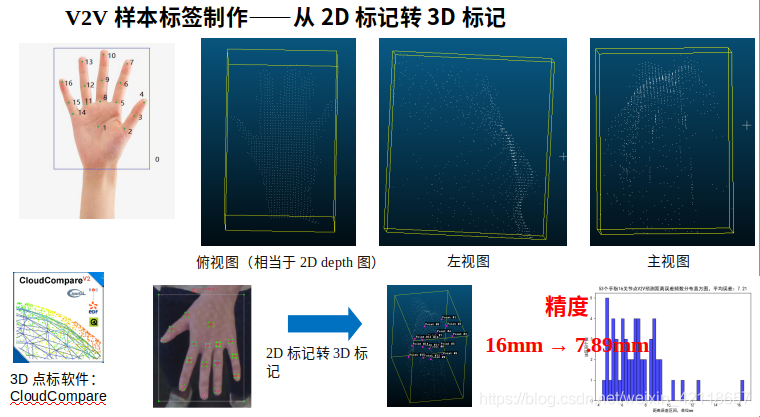
V2V样本的标注
?最开始,我们在2D RGB图上标注16个关节点,然后通过RGB图坐标转depth图坐标转3D点云坐标,来获取手掌在3D空间的XYZ标签信息。但是,这种方法导致非常大的标注误差,原因在于,depth图精度并不是特别高,而且有很多噪音。RGB图上标注的点,人眼看上去标的很准,但很可能通过公式,映射到3D空间时,这个点会落在噪音点上。
计算手指关节点的空间延长线和桌面点云的交点
V2V得到手掌16个关节点后,我们使用食指尖和食指末2个关节点的XYZ值,可以计算出其连接线射线与桌面点云的交点位置。

具体计算代码如下:

?3 效果
YOLO目标检测器检测手掌区域效果

V2V算法对手掌16关节点预测的效果?

?3D仿真
在开发过程中,我们设计了一个3D仿真程序,用于测试各模型及其语义逻辑在虚拟空间的操控效果。初版仿真程序是用一个简单的立方体来表示,后期仿真使用pyqtgraph库设计了一个更全功能的虚拟仿真,包括实时可视化如下内容:环境空间中的所有点云、RGB图、虚拟立方体(用于测试手掌非接触控制它的效果)、手指方向延长线与环境中点云的交汇点等等。
初版仿真程序如下:
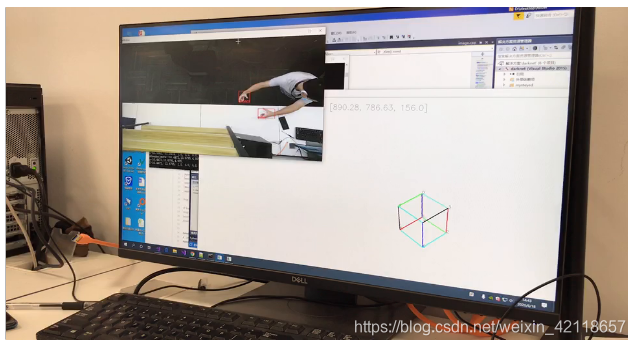
最终版仿真程序如下:
后续更新截图。
