InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
ICSE 2021
摘要:
? ? ? ?学习代码表示被广泛用于软件工程任务,例如,代码分类、代码搜索、注释生成和缺陷预测等。利用token、语法树、依赖图、树路径或者他们的结合表示代码已经被提出,现有的学习技术有很大限制:这些模型在有标记的数据集上训练(用于具体的下游任务),这样的代码表示不适合其他任务。即使存在一些方法从无标记的代码中生成表示,当应用于下游任务时,他们不能取得满意的效果。为了克服这些限制,这篇文章提出来InferCode,利用自监督学习从代码的抽象语法树(AST)中学习代码表示。新颖之处在于通过预测子树(从AST中自动识别的)训练代码表示。在InferCode模型中,子树被作为标签用于训练模型,不需要人工标注或者构造图结构的开销,训练得到的代码表示适用于任意具体的下游任务或代码单元。
使用Tree-Based Convolutional Neural Network(TBCNN)作为代码的encoder训练InferCode。实例。这个预训练模型可以用于下游无监督任务,例如代码聚类、克隆检测、跨语言代码搜索;或者将模型迁移到监督任务重继续训练,例如代码分类和方法名预测。与现有方法相比,例如code2vec、 code2seq、ASTNN,对于相同的下游任务,我们的预训练模型获得了更好的性能。InferCode的代码实现可以获得:https://github.com/bdqnghi/infercode。
引言:
现有的学习技术有两个主要的限制,阻碍了方法的性能和泛化:
- 大多数的代码表示模型是通过监督或半监督学习训练,对于一个具体的下游任务,需要人工标注的数据标签,训练得到中间的特征表示用于具体的任务。这样标记、特征建模、训练都是特定于一个任务,很难迁移到其他任务。
- 尽管有一些方法(Code2vec、code2seq)生成的代码表示可以迁移到不同的任务,他们的代码表示只是针对于一些固定的代码单元,例如token、语句和函数,不能灵活地生成不同代码单元的嵌入。并且这些方法可能丢失跨不同类型代码单元的有用信息,对于各种下游任务的表现可能不佳。还有一些基于图嵌入的方法也有类似的缺点,此外,还有需要额外的构造图的开销,图中可能会引入不准确的信息。
为了解决这些问题,这篇文章开发了一个新技术用于学习代码表示,其目标是:
(1)训练模型不需要人工标记;
(2)灵活地生成任意代码单元(可以被解析为语法树)的嵌入;
(3)通用的模型,生成的代码表示在各种下游任务中都可以表现很好。
利用自监督学习生成代码表示,关键思想是设计并训练a pretext task(代理任务)。获得有效代码的AST是相对容易的,识别出AST的子树也是简单的,因此使用每个子树作为代理任务的标签,预测子树在出现在AST中的概率(与Doc2vec类似)。
图1是两个冒泡排序的代码,它们对应的ASTs中有很多相同的子树,例如条件表达式“arr[j]>arr[j+1]”和“a[i]>a[i+1]”,利用这样的信息,训练模型,不再需要标签。

?基于上述观点,提出了InferCode模型,自监督学习用于表示代码,通过预测语法子树。他们是首次提出用自监督学习生成代码表示,不需要人工标记。【包含相似子树的代码片段具有相同的含义】
在五个下游任务中评估预训练的代码表示的性能。
?方法:
A. 概述
InferCode与Doc2vec类似,将AST视为文档,子树作为文档中的单词。给定ASTs集合{},
的所有子树集合{...,
,...},将
和
表示为D维向量。考虑子树
出现在
上下文中,最大化对数损失:
。
首先encode完整的AST去获得D维的向量表示,然后用它来预测子树。方法的步骤如下:
- 对于数据集中每个AST,识别出子树的集合。所有的子树被累积成子树语料库;
- 用TBCNN编码AST生成代码向量,这个向量被用于预测子树;
- encoder被训练后,将它作为预训练模型用于下游任务。
B. 识别子树
?通过遍历AST,将满足条件的节点(expr_stmt,decl_stmt,expr,condition)作为子树的根节点,识别出子树。此外,也考虑一些关键节点,例如if,for,while,这些单独的节点被作为一个子树。
没有考虑粗粒度的子树,例如if,while,for语句块,这些子树太大。作为一个单独的词,在代码库中出现不频繁,encoder很难直接学习到有意义的表示;在这些大的子树种虽然句法不同并不意味着代码的功能不同,encoder很难学习到他们的相同点。
图3显示了冒泡排序代码和识别出的子树。

?C. 学习代码表示:
使用TBCNN作为encoder,学习代码表示,它的流程如图4所示:
?

?
?(1)TBCNN学习节点表示:
TBCNN的输入是AST,利用节点的类型嵌入初始化节点向量,这篇文章引入代码token信息,将类型嵌入和token嵌入通过线性层融合初始化节点向量。
将AST转换为二叉树,利用CNN学习节点向量。(具体过程查看TBCNN论文)
(2)注意力机制:
?在学习到节点向量之后,需要结合所有的节点向量得到一个向量表示代码片段。原论文是通过最大池化结合节点。然而,最大池化可能丢失很多重要信息,因此,用注意力机制代替聚合节点特征。最初,注意力机制向量被随机初始化,与网络模型一起更新。最后可以获得代码向量。
(3)预测子树:
?子树的嵌入是可学习的参数(这个地方不理解为啥是可学习的)。模型预测的分布是softmax 归一化结果,计算过程入下所示:
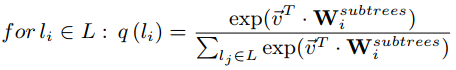
?这个公式表示一个子树出现在给定的代码片段C中的概率。
?【我的理解:将子树作为标签,通过判断是否子树存在该代码中,这样来检测从代码中学习到的向量表示是否包含了该子树的信息,通过训练学习到代码特征完美表达】
?评估:
?在五个下游任务中评估InferCode。在训练阶段使用Java-Large dataset(被Code2vec和Code2seq使用的),在测试阶段,每个任务使用不同的测试数据。解析所有文件成ASTs,并识别出子树作为标签,损失函数是softmax交叉熵训练模型。
A. 代码聚类
数据集:
OJ dataset:52000 C代码片段属于104个类别
Sorting Algorithm (SA) dataset:Java代码包含10个类别,每个类别包含1000左右代码片段
评价指标:Adjusted Rand Index:另C是ground truth,K是分类结果;a表示在C的同类集合中的元素同时也在K的相同集合中的元素个数,b是在C的不同类别中的元素同时也在K中不同类别的元素个数,RI=(A+B)/(n的2组合数)。但是,RI 分数并不能保证随机标签分配会得到接近于零的值(如果聚类数与样本数处于同一数量级),为了解决这个问题,ARI被定义:
![]()
?对比方法:Word2vec、Doc2vec、SAE、Code2vec、Code2seq
结果:InferCode表现最好,NLP方法性能比其他方法差,因为Code2vec和Code2seq捕获代码的结构信息,NLP方法仅将代码作为token文本序列。

?B. 克隆检测
?数据集:
OJClone:C/C++数据集构造了50000克隆代码对和50000非克隆代码对
BigCloneBench:一个Java数据集包含6000000克隆的代码对,260000非克隆的代码对
评价指标:Precision、?Recall、F1
对比方法(无监督方法):Deckard [61]、SourcererCC [62]、DLC [63]、Code2vec [8, 16]
结果:InferCode有最高召回率(除了SourcererCC,它的精确率低),对于f1值,均优于其他无监督方法。

?C. 跨语言代码搜索
?数据集:收集了Java、C、C++、C#特定算法实现的代码样本3000左右从Rosetta Code,对于每种语言再随机5000个代码文件从Github中。
评价指标:Mean Reciprocal Rank(MRR)
对比方法:Word2vec、Doc2vec、CLIR、ElasticSearch
结果:InferCode表现最好,ElasticSearch表现最差,因为ElasticSearch是一个简单的文本搜索方法,不能捕获代码的结构信息。

?D. 监督学习任务
?a)代码分类
数据集:OJ Dataset
评价指标:accuracy
对比方法:ASTNN、TextCNN、BiLSTM
我们随机或使用来自预训练 InferCode 的权重初始化神经模型。我们有四种设置来训练监督模型用于比较:分别用 1%、10% 或 100% 的标记训练数据微调 TBCNN 编码器,以及随机初始化的模型。仅使用 1% 或 10% 是为了证明给定预训练模型,只需要少量标记数据即可为下游任务实现合理的良好性能。
结果:在 10% 的训练数据上进行微调可以获得与 NLP方法相当的结果。 在100% 的训练数据上微调可与 ASTNN 方法(在OJ Dataset数据集上最新的代码分类模型)相媲美。

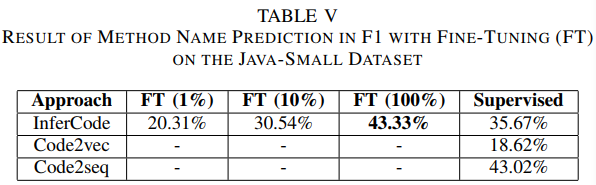
b)方法名预测
数据集:Java-Small
评价指标:Precision、?Recall、F1
对比方法:Code2vec、Code2seq
我们通过使用 1%、10% 和 100% 的标记训练数据对模型进行微调与代码分类任务相同的评估方法。
?结果:当在100% 标记数据上微调时,我们得到了与 Code2seq 相当的结果。
E. 总结
?在5个下游任务中InferCode优于其他基线方法,但这并不意味着 InferCode 中的 TBCNN 编码器优于 ASTNN、Code2vec 或 Code2seq,因为这些模型也可以用作 InferCode 中的编码器。 这仅意味着使用自监督学习预测子树在大型未标记数据上预训练模型可以产生更多可迁移的模型,同时此类模型在各种代码学习任务中可以获得较好的性能。
使用不同的编码器可以进一步提高自监督学习模型的性能。
分析:
A. 可视化
为了帮助理解为什么 InferCode 生成的向量比其他模型生成的向量表现更好,我们将 OJ 数据集中用于代码聚类的程序向量可视化。 我们为 OJ 数据集的前 9 个类选择 Doc2vec、Code2vec 和 InferCode 生成的嵌入,然后我们使用 T-SNE [69] 将向量的维数减少到二维空间并进行可视化。如图6所示:

(1) InferCode 产生的向量将相似的代码片段分组到同一个簇中,边界更清晰
?(2) Doc2vec 和 Code2vec 产生的簇之间的边界不太清楚,这使得 K-means 算法更难进行聚类?
?此外,也可以观察到,即使在来自 InferCode 的向量中,一些标记为相同颜色(例如红色)的点彼此之间也有些远,而根据基本事实,它们应该是接近的。 这可能表明在未来的工作中可以进一步改进 Infercode。
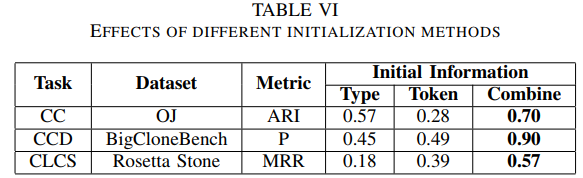
B. TBCNN 中文本信息的影响
TBCNN中AST节点的初始化仅利用节点的类型信息,我们将类型信息和节点token融合初始化节点向量,为了证明这种融合的性能,我们通过在 Java-Large 数据集上使用不同的初始化信息训练 InferCode 进行消融实验,并对三个无监督任务进行评估:代码聚类 (CC)、代码克隆检测 (CCD) ) 和跨语言代码到代码搜索 (CLCS)。结果如下所示,可以看到仅使用类型或token信息,三个任务的性能都低于两种信息结合的表现。
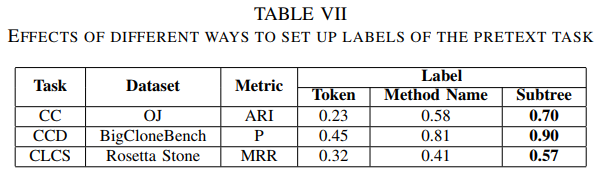
?C. 代理任务标签选择
?在InferCode中选择了子树作为标签,其他选择有,代码token、方法名称,通过消融实验评估不同的标签类型对代码学习的性能影响。如下表所示。使用子树作为标签的性能最好,而使用token作为标签的性能最差。 虽然使用方法名可以获得合理的性能,但仍然不能优于子树。因为预测方法名称,模型可能会学习一些不正确的模式,因为代码库中存在相似名称的代码,而实际上却完全不同。
终于写完了,第一次看论文写这么详细的笔记,因为这篇是要求精读的,其他的论文可能不会记录这么多了。因为水平有限,大家发现错误或者一些建议可以在评论区告诉我哦~有任何问题可以一起交流。。。