Transformer���ԭ��
Attention
ע�������� (Attention Mechanism) �������;�ʮ���,һЩ��ѧ�����о������Ӿ�ʱ,���ֵ�һ���źŴ������ơ��˹���������Ĵ�ҵ�߰����ֻ������뵽һЩģ����,����Attention�Ѿ���Ϊ�����ڻ���ѧϰģ����Ƕ���һ������ṹ,�����Զ�ѧϰ�ͼ����������ݶ�������ݵĹ��״�С��
Ŀǰ,ע���������Ѿ���Ϊ���ѧϰ����,��������Ȼ���Դ�������,Ӧ����㷺�ġ������֮һ���������ع�ȼ��ߵ�BERT��GPT��Transformer�ȵ�ģ�ͻ�ṹ,��������ע�������ơ�1
1. seq2seqģ��
- һ�����е�����(seq2seq)ģ��,���յ�������һ��(���ʡ���ĸ��ͼ������)����,���������һ�����С�
seq2seqģ�ͽṹ�ںܶ������϶�ȡ���˳ɹ�,��:�������롢�ı�ժҪ��ͼ���������ɡ��ȸ跭���� 2016 ����ĩ��ʼʹ������ģ�͡���2ƪ�����Ե�����:Sutskever��2014�귢����Sequence to Sequence Learning with Neural Networks��Cho��2014�귢����Learning Phrase Representations using RNN Encoder�CDecoder for Statistical Machine Translation������Щģ�ͽ����˽��͡�2
seq2seqģ������������(Encoder)��������(Decoder)��ɵġ�
- ����,�������ᴦ�����������е�ÿ��Ԫ��,����Щ��Ϣת��Ϊһ������(��Ϊ������(context))��
- �����Ǵ����������������к�,��������������(context)����������,��������ʼ����������������е�Ԫ�ء�
�ڻ�������������,������(context)��һ������(��������һ����������)���������ͽ�������Transformer����֮ǰһ����õ���ѭ�������硣

��ͼ:������context��Ӧͼ���м�һ����������������������,���ǻ���ӻ���Щ����,ʹ�ø�������ɫ������ʾ���ߵ�ֵ,����ͼ�ұ���ʾ
�������,RNN ��ÿ��ʱ�䲽���� 2 ������:
- ���������е�һ��Ԫ��(�ڽ�������������,������ָ�����е�һ������,���ձ�ת����һ������)
- һ�� hidden state(���ز�״̬,Ҳ��Ӧһ������)
��ΰ�ÿ�����ʶ�ת��Ϊһ��������?
- ����ʹ��һ���Ϊ ��word embedding�� �ķ�����������ѵ���ת����һ�������ռ�,���ֱ�ʾ�ܹ�����������֮���������Ϣ(����,king - man + woman = queen)
2. Attention
������context������RNN����ģ�͵�ƿ������ʹ��ģ���ڴ������ı�ʱ���ٷdz������ս���� Bahdanau��2014������Neural Machine Translation by Jointly Learning to Align and Translate �� Luong��2015�귢����Effective Approaches to Attention-based Neural Machine Translation ��ƪ������,�����һ�ֽ���������� 2 ƪ����������Ľ���һ�ֽ���ע����attetion�ļ���,�����������˻��������������ע����ʹ��ģ�Ϳ��Ը�����Ҫ,��ע���������е���ز��֡�

ͼ:ע��������ʹ�ý������ڲ���Ӣ���֮ǰ,���Խ�ע���������� ��student�� �����(�ڷ�����,�� ��student�� ����˼)�����ִ��������зŴ�����źŵ�����,ʹ��ע����ģ��,��û��ע������ģ��,�������õĽ����
һ��ע����ģ�Ͳ�ͬ�ھ�������е�����(seq2seq)ģ��,��Ҫ������ 2 ������:
- ����,��������Ѹ�������ݴ��ݸ���������������������ʱ�䲽�� hidden state(���ز�״̬)���ݸ�������,������ֻ�������һ�� hidden state(���ز�״̬)
- �ڶ�,ע����ģ�͵Ľ������ڲ������֮ǰ,����һ������Ĵ�����Ϊ�˰�ע�������������ʱ�䲽��ص����벿�֡��������������µĴ���:
- �鿴���н��յ��ı�������hidden state(���ز�״̬)������,��������ÿ�� hidden state(���ز�״̬)����Ӧ�����������һ�����ʡ�
- ��ÿ�� hidden state(���ز�״̬)һ������(�����Ⱥ�����������ļ������)��
- ��ÿ�� hidden state(���ز�״̬)���Ծ��� softmax �Ķ�Ӧ�ķ���,�Ӷ�,�߷ֶ�Ӧ�� hidden state(���ز�״̬)�ᱻ�Ŵ�,���ͷֶ�Ӧ�� hidden state(���ز�״̬)�ᱻ��С��

�����Ȩƽ���IJ������ڽ�������ÿ��ʱ�䲽���ġ� ����,�����ǰ��������ݶ��ںϵ������ͼ��,������ע����ģ�͵���������:
- ע����ģ�͵Ľ����� RNN ���������:һ��embedding ����,��һ����ʼ���õĽ����� hidden state(���ز�״̬)��
- RNN ���������� 2 ������,����һ�������һ���µ� hidden state(���ز�״̬ h4 ����),��������ᱻ���ԡ�
- ע�����IJ���:����ʹ�ñ������� hidden state(���ز�״̬)�� h4 �������������ʱ�䲽������������(C4)��
- ���ǰ� h4 �� C4 ƴ������,�õ�һ��������
- ���ǰ������������һ��ǰ��������(��������Ǻ�����ģ��һ��ѵ����)��
- ǰ��������������ʾ���ʱ�䲽����ĵ��ʡ�
- ����һ��ʱ�䲽�ظ�1-6���衣

ͼ:attention��ע�Ĵ�(ÿ�������ʱ�䲽�й�ע������ӵ���Щ����)
ע����ģ�Ͳ�������ʶ�ذ�����ĵ�һ�����ʶ�Ӧ������ĵ�һ�����ʡ�ʵ����,����ѵ����ѧϰ������������������ж�Ӧ���ʵĹ�ϵ(�����ǵ�������,�Ƿ����Ӣ��)����ͼչʾ��ע�������Ƶ�ȷ�̶�

Transformer
2017 ��,Google ����� Transformer ģ��,�� Self Attention �Ľṹ,ȡ�������� NLP �����е� RNN ����ṹ,�� WMT 2014 Englishto-German �� WMT 2014 English-to-French�����������������϶�ȡ���˵�ʱ SOTA ��Ч����
���ģ�͵�����һ���ŵ�,����ʹ��ģ��ѵ�������ܹ����м��㡣�� RNN ��,ÿһ�� time step (ʱ�䲽)�ļ��㶼��������һ�� time step �����,���ʹ�����е� time step ���봮�л�,�����м���,����ͼ��ʾ��

���� Transformer ��,���� time step ������,���Ǿ��� Self Attention ����,ʹ������������̿��Բ��л����㡣Transformer ʹ���� Seq2Seq�����г��õĽṹ����������������:Encoder �� Decoder��һ��Ľṹͼ������ʾ��

1. �������������� Transformer
����,���ǽ�����ģ����Ϊ�ںС��ڻ�������������,����һ�����Եľ�����Ϊ����,Ȼ���䷭����������������

�м䲿�ֵ� Transformer ���Բ��Ϊ 2 ����:����DZ��벿��(encoding component),�ұ��ǽ��벿��(decoding component)��

encoder�ɶ����������,ÿ��������ڽṹ�϶���һ����,����ͬ���������Ȩ�ز����Dz�ͬ�ġ�ÿ�����������,��Ҫ���������������
- Self-Attention Layer
- Feed Forward Neural Network(ǰ��������,��дΪ FFNN)

������������ı�����,���Ȼᾭ��һ�� Self Attention ��,����㴦��һ���ʵ�ʱ��,������ʹ������ʱ�������Ϣ,Ҳ��ʹ�þ����������ʵ���Ϣ(��������Ϊ:�����Ƿ���һ���ʵ�ʱ��,������ֻ��ע��ǰ�Ĵ�,Ҳ���ע����ʵ������ĵ������ʵ���Ϣ)��������,Self Attention �������ᾭ��ǰ�������硣
ͬ��,������Ҳ����������,�����������м仹������һ�� Encoder-Decoder Attention ��,������ܰ����������۽���������ӵ���ز���(������ seq2seq ģ�� �е� Attention)��

2. ��ϸ�������� Transformer
2.1 Transformer������
��ͨ���� NLP ����һ��,�������Ȼ�ʹ�ô�Ƕ���㷨(embedding algorithm),��ÿ����ת��Ϊһ����������ʵ��������һ���� 256 ���� 512 ά��
��ô��������ľ�����һ�������б�,������ 3 ������������ʵ����,ÿ�����ӵij��Ȳ�һ��,���ǻ�ȡһ���ʵ���ֵ,��Ϊ�����б��ij��ȡ����һ�����Ӵﲻ���������,��ô�����ȫΪ 0 �Ĵ�����;������ӳ����������,�����ضϡ����ӳ�����һ��������,ͨ����ѵ�����еľ��ӵ����
2.2 Encoder(������)
������(Encoder)���յ����붼��һ�������б�,���Ҳ�Ǵ�Сͬ���������б�,Ȼ�����������һ����������
- ��һ ��/�� �������������Ǵ�����,������ı���������������һ���������������
- ÿ������ת����һ������֮��,����self-attention��,ÿ��λ�õĵ��ʵõ�������,Ȼ��������FFN�����硣
- ÿ��λ�õĴʶ����� Self Attention ��,�õ���ÿ�������������������ǰ���������,ÿ������������ǰ�������綼��һ����
2.3 Self-Attention ��������
���� Self-Attention �ľ�����ơ�
����������Ҫ����ľ�����:
The animal didn��t cross the street because it was too tired
��������е� it ��һ��ָ����,��ô it ָ����ʲô��?����ָ animal ����street?������������˵,�Ǻܼ�,���Ƕ��㷨��˵��������ô���ס�
��ģ���ڴ���(����)it ��ʱ��,Self Attention�����ܹ���ģ�Ͱ�it��animal����������
ͬ��,��ģ�ʹ��������е�ÿ����ʱ,Self Attention����ʹ��ģ�Ͳ����ܹ���ע���λ�õĴ�,�����ܹ���ע����������λ�õĴ�,��Ϊ��������,�������Ը��õر��뵱ǰλ�õĴʡ�
�������Ϥ RNN,����һ��:RNN �ڴ���һ����ʱ,�ῼ��ǰ�洫������hidden state,��hidden state�Ͱ�����ǰ��Ĵʵ���Ϣ���� Transformer ʹ��Self Attention����,����������ʵ��������봦����ǰ�ĵ��ʡ�

����ͼ���ӻ�ͼ��ʾ,�������ڵ�����������(���벿���е����һ�������)���롰it��ʱ,��һ����ע���������ڡ�The animal����,���Ұ��������ʵ���Ϣ�ںϵ���"it"��������С�
2.3 Self-Attention ��ϸ��
2.3.1 ����Query ����,Key ����,Value ����
���������ȿ������ʹ������������ Self Attention,Ȼ���ٿ������ʹ�þ�����ʵ�� Self Attention��(��������ķ�ʽ,ʹ�� Self Attention �ļ����ܹ����л�,��Ҳ�� Self Attention ���յ�ʵ�ַ�ʽ)��
���� Self Attention �ĵ� 1 ����:�������������ÿ��������,������ 3 ������,�ֱ���:Query ����,Key ����,Value �������� 3 �������Ǵ������ֱ�� 3 ��������˵õ���,���������������Ҫѧϰ�IJ�����
ע��,�� 3 ���µõ�������һ���ԭ���Ĵ������ij��ȸ�С�������� 3 �������ij�����
d
k
e
y
d_{key}
dkey?,��ԭʼ�Ĵ�����������������������ij����� 512(�� 3 �������ij���,�������������������,���б�����ϵ��)������ Multi-head Attention,��������ʵ�ʴ��롣����Ϊ�˼�,����ֻ��һ�� head �� Self-Attention��

��ͼ��,������������:Thinking �Ĵ����� x1 �� Machines �Ĵ����� x2���� x1 Ϊ��,X1 ���� WQ �õ� q1,q1 ���� X1 ��Ӧ�� Query ������ͬ��,X1 ���� WK �õ� k1,k1 �� X1 ��Ӧ�� Key ����;X1 ���� WV �õ� v1,v1 �� X1 ��Ӧ�� Value ������
2.3.2 ���� Attention Score(ע��������)
�� 2 ��,�Ǽ��� Attention Score(ע��������)�������������ڼ����һ���� Thinking �� Attention Score(ע��������),��Ҫ���� Thinking �����,�Ծ����е�����ÿ���ʶ�����һ����������Щ���������������ڱ���Thinking�����ʱ,��Ҫ�Ծ���������λ�õ�ÿ���ʷ��ö��ٵ�ע������
��Щ����,��ͨ������ ��Thinking�� ��Ӧ�� Query ����������λ�õ�ÿ���ʵ� Key �����ĵ��,���õ��ġ�������Ǽ�������е�һ��λ�õ��ʵ� Attention Score(ע��������),��ô��һ���������� q1 �� k1 ���ڻ�,�ڶ����������� q1 �� k2 �ĵ����
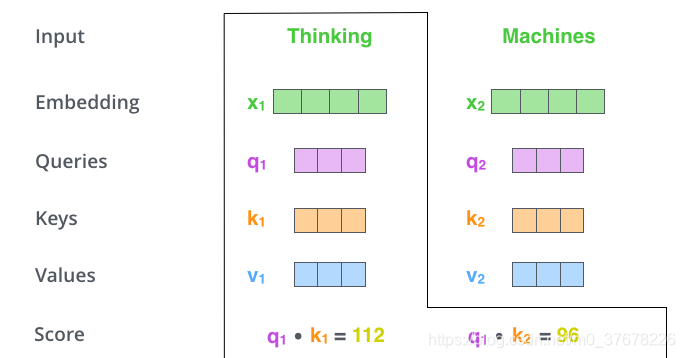
�� 3 �����ǰ�ÿ����������
(
d
k
e
y
)
\sqrt(d_{key})
(?dkey?) (
d
k
e
y
d_{key}
dkey?�� Key �����ij���)����Ҳ���Գ���������,����һ������Ϊ���ڷ���ʱ,��ȡ�ݶȸ����ȶ���
�� 4 ��,���Ű���Щ��������һ�� Softmax ��,Softmax���Խ�������һ��,����ʹ�÷��������������Ҽ��������� 1��
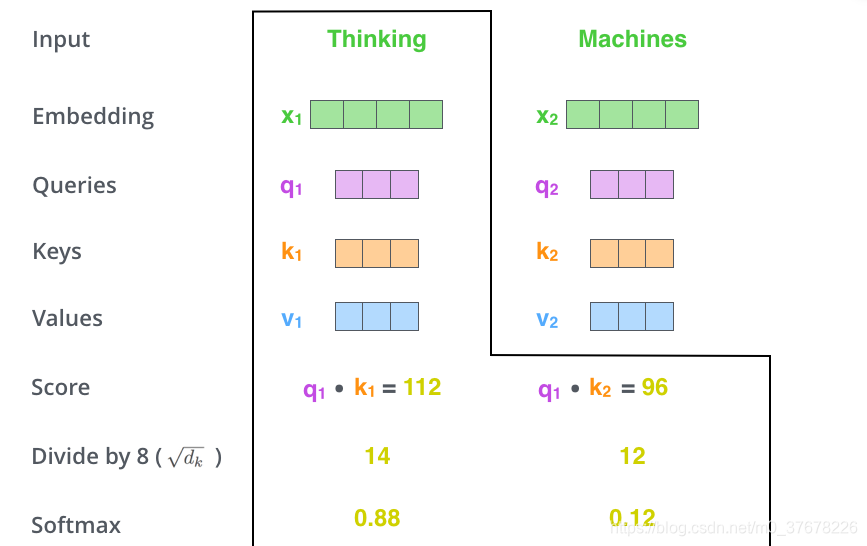
��Щ�����������ڱ��뵱ǰλ��(����������ǵ�һ��λ��)�Ĵ�ʱ,������λ�õĴʷֱ��ж��ٵ�ע������������,����ͼ��������,��ǰλ��(����������ǵ�һ��λ��)�Ĵʻ�����ߵķ���,����ʱ,��ע������λ������صĴ�Ҳ�����á�
�� 5 ��,�õ�ÿ��λ�õķ�����,��ÿ�������ֱ���ÿ�� Value ������ˡ��������������ֱ���������:���ڷ����ߵ�λ��,��˺��ֵ��Խ��,���ǰѸ����ע�����ŵ�����������;���ڷ����͵�λ��,��˺��ֵ��ԽС,��Щλ�õĴʿ���������Բ����,�������Ǿͺ�������Щλ�õĴʡ�
�� 6 ���ǰ���һ���õ����������,�͵õ��� Self Attention �������λ��(����������ǵ�һ��λ��)�������
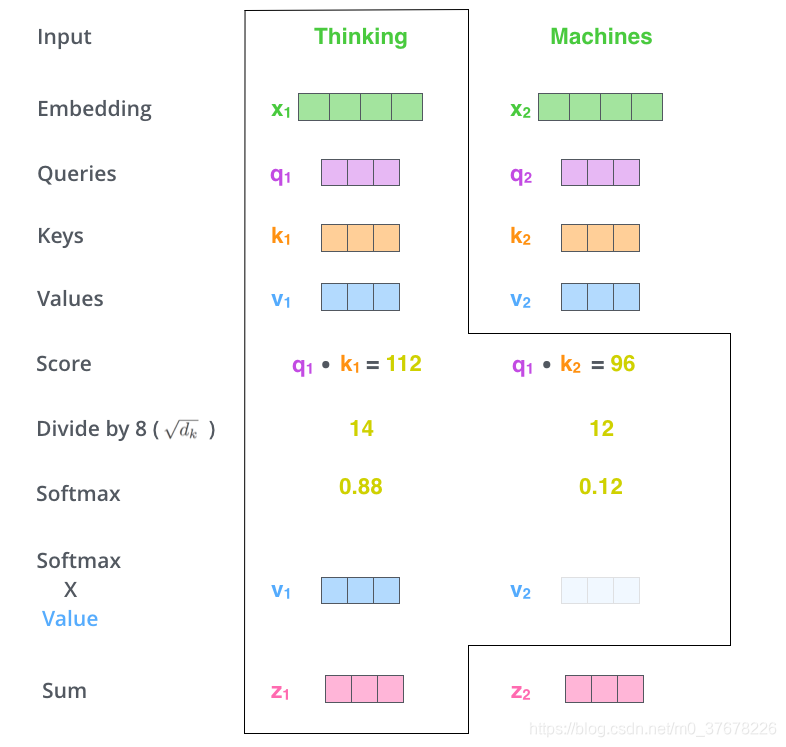
��������ͼ,������ Self Attention ��ȫ����,���յõ��ĵ�ǰλ��(����������ǵ�һ��λ��)�����������뵽ǰ�������硣������ÿ��ֻ�ܼ���һ��λ�õ��������,��ʵ�ʵĴ���ʵ����,Self Attention �ļ��������ʹ�þ�����ʵ�ֵ�,�������Լ��ټ���,һ�ξ͵õ�����λ�õ������������������������,���ʹ�þ�������������λ�õ����������
2.3.3 ʹ�þ������ Self-Attention
[1] : ע�������Ƶ�����ʲô�������ڳ�ʶ�Ļ����ṹ����
[2] : ͼ��Attention
[3] : ͼ��Transformer