Weak supervision for generating pixel-level annotations in scene text segmentation
在场景文本分割中使用弱监督来生成像素级注释
摘要:
在场景文本分割中提供像素级监督本身是一件很困难、且价格昂贵的事情,因此仅仅有少量的数据集可以用于此任务。为了面对训练集的不足,以往基于CNNs的方法,它依赖于合成数据集用来预训练。但是,合成的数据不会再现自然图片的复杂性和多样性。在这项工作里,作者提出使用一种弱监督学习方法去减少合成数据和真实数据之间的domain-shift(领域转换误差),利用基于bounding-box 监督的COCO文本数据集和MLT数据集,来生成真实图片的弱像素级监督。创建并发布了COCO文本分割数据集和MLT分割数据集。这两个数据集都是使用CNN来训练,the Segmentation Multiscale Attention Network (SMANet:分割多尺度注意力网络)专门针对场景文本分割任务的一些特定任务而设计,它在proposed 数据集上是一个端到端的训练。实验表明COCO_TS(TS:test segmentation)和MLT_S是合成五篇的有效替代品,只使用一部分训练样本就会使性能得到提升。
介绍:
场景文本分割是真实图片中文本信息提取的一个重要且具有挑战的步骤,很多文本检测的方法都是基于分割技术。文本分割的目的是对图片的每个像素进行密集预测【密集预测任务又称像素级预测任务】,已检测文本的存在。CNN在许多CV任务重已达到高水平,包括场景文本分割。但是它的训练通常是基于大量的全监督数据。对于场景文本分割的数据集有两个:(1)EICDAR-2013,(2)Total-Text。其中包含大量像素级注释图片,但不足以训练深度分割网络。
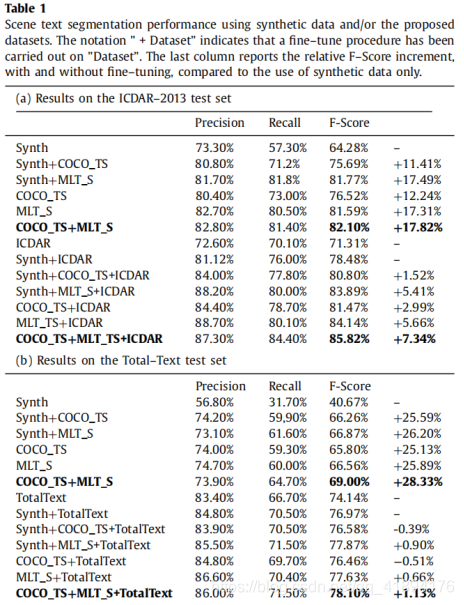
作者使用一种训练过程(如下图),利用像素的像素标签的弱注释。整体包括两个步骤:
1、在具有全像素监督的合成图像的大数据上训练背景-前景网络,目的是识别边界框中的文本。
2、在文本定位数据集山训练场景文本分割网络,利用前景-背景网络的输出实现像素级监督。
这种训练方法背后的逻辑是:训练以bounding-box为中心的分割网络比训练整张图片简单。实际上,bounding-box内,文本维度是已知的(和box的维度直接相关)、背景(非文本对象)的可变性降低。此外,box注释提供了关于文本位置的精准信息,因为未包含在框中的每个像素并不表示文本。因此,作者利用弱注释为真实图像数据集生成精准的像素级监督,从而减少合成数据和真实数据之间的域转移。特别是,利用前景-背景网络,对两个真实图像数据集COCO_T、MLT_进行了精准的像素级监控。获得监督的数据集COCO_TS、MLT_S将公开,以促进场景文本分割的研究。为了解决场景文本分割问题的特殊性,作者引入了分割多尺度注意力网络(SMANet),一种带有ResNet主干编码器的深度卷积网络。在SMANet网络结构中,卷积解码器用于恢复由于pooling和strided卷积的存在而丢失的一些优化细节。多尺度注意力机制也用于聚焦图像中信息量最大的部分。所提出来的体系结构用于实现分割数据集提取所需的背景-前景网络和场景文本分割网络。
这篇论文涉及四个主要研究课题:合成数据生成、语义分割的边界框、场景文本分割和注意力模块。
材料和方法
在下文中,对所提的方法进行概述。先介绍创建COCO_TS、MLT_S数据集所涉及的数据集。然后在描述用于生成此数据集的弱监督方法,最后介绍分割多尺度注意力网络的架构。
数据集:
对每个单词,定义一个回归框并将其放大0.3倍,然后围绕回归框裁剪图像。这些回归框用于训练后面的前景-背景网络。
COCO-Text:自然场景的实例分割图像。训练集43686张,验证集10000张,测试集10000张。和其他场景文本数据集不同,COCO-2014数据集不是专门尾题曲文本信息而收集的,因此其中一些图像不包含文本。所哟为了生成proposed的COCO_TS数据集,从COCO文本中选择了14690张图片子集,每张图像至少包含一个边界框,标记为易读、机器打印和英文书写。
MLT:是为ICDAR-2017竞赛收集的,包括带有嵌入文本的自然场景图像,如街道标志、街道广告牌。商店标志、过往车辆等。不同的用户使用不同的手机摄像头拍摄图像。由18000张图片组成,其中包含九种不同语言的文本,所有文本均在回归框级别注释。
ICDAR-2013:229张训练图片,233张测试图片。
Total-Text:1255张训练集,300张测试集。文本处于水平,文本高度多样化。
COCO_TS/MLT_S数据集
训练一个深度神经网络来分割由回归框提供的图像部分里的文本,从而将背景和前景分离。该方法的基本原理是,实现背景-背景分割,将其限制在回归框给出的小区域内,比生成整个图像的分割要简单得多。出于这个原因,作者假设,即使对合成数据进行训练,背景-前景网络也可以有效的用于分割从真实图像提取的回归框中的文本,为了训练前景-背景网络,需要对大量回归框进行像素级监督。从而成数据里提取1000000回归框裁剪以用于此目的。在训练阶段之后,背景-前景网络应用于与从COCO-Text和MLT数据集的回归框中提取区域。对于每张图片,结合图像内所有边界框的概率图(由前景-背景网络计算)获得像素级监督。一个区域可能属于多个回归框(eg:两个相邻的书写文本可能有重叠的回归框),在这种情况下,考虑前景概率值最高的预测。使用概率图prob(x,y)上的两个固定阈值th1和th2获得位置(x,y)处的最终像素注释I(x,y)。使用基于合成图片验证集的网络搜素方法,将两个阈值th1和th2分别设置为0.3、0.7。

生成的监督的质量评估,其中黑色为背景,红色为前景,黄色为不确定区域。

分割多尺度注意力网络结构
为了解决场景文本分割,作者提出了分割多尺度注意力网络,它由三个主要组件组成:ResNet编码器、多尺度注意力模块、卷积解码器。编码器基于PSPNet网络,用于语义分割,
是一种深度卷积神经网络,用于重新使用最初为图像分类设计的ResNet。在PSPNet中,一组扩展卷积(即萎缩卷积)取代了ResNet主干中的标准卷积,以扩大神经网络的感受野。为了收集上下文信息,PSPNet利用不同内核大小的金字塔池。SMANet采用相同的基于ResNet的PSPNet主干:在作者实验中,由于GPU内存限制,使用了ResNet50。尽管PSPNet在自然图像分割中被证明是非常有效的,但场景文本分割是一项特殊的任务,有其自身的特点。特别的,自然图像中的文本可能具有高度的尺度和尺寸变化性。为了更好处理窄小文本的存在,作者修改了网络结构,添加两级卷积解码器。多尺度注意力机制也被用来关注图像中的文本。
多尺度注意力模块
目前先进模型采用不同的策略从不同比例的图像中收集信息。例如PSPNet使用空间金字塔池化,其中包括将CNN编码器的最后特征映射与不同比例的内核相结合。为了获得相同大小的特征映射,将合并的映射双线性插值到编码特征映射的原始大小。相反,DeepLab依赖于一个atrous特征金字塔池化模块,该模块以多种速率探测具有扩展卷积的编码器特征图,从而以多种尺度捕获对象。然而,扩展的卷积可能对特征图的局部一致性有害,而PSP模块在不同规模的合并操作中会丢失像素精度。然而为了解决这个问题,作者引入了一种集中注意力机制,为ResNet编码器提取的特征提供像素级的注意力。注意力模块的架构如图:
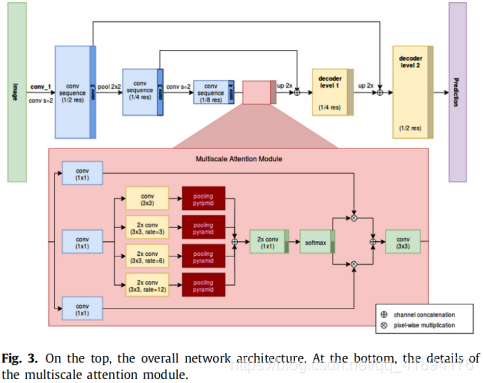
具体来说,CNN编码的表示通过卷积层,然后作为输入提供给SMANet注意力模块,该模块输出注意图。这些图与CNN编码表示进行像素相乘,之前通过1*1卷积层以方便地减少特征图的维度。如下图由所提出的多尺度注意模块产生的注意图的一些示例。我们可以观察到注意力机制学习关注区域包含文本。

解码
在低维特征映射‘cov_2’和‘cov_3’(图三)分别是原始分辨率的1/2和1/4处的ResNet编码器的最后卷积层。在这些低层特征图上应用1*1卷积以减少通道数量。SMANet注意力模块输出首先以2的倍数进行双线性上采样,然后以相同的空间分辨率(cov_2)与相应的低级特征串联。然后,在连接的特征映射之后是两个卷积层,并再次以2的因子进行上采样。生成的特征映射与cov_3连接,最后,两个卷积层和最后一个上采样产生像素级预测。通过在卷积编码器中串联低维特征,解码器可以恢复由于下采样而丢失的空间细节信息。实验表明,两级卷积编码器和多尺度注意力模块的使用都提高了SMANet相对于基线PSPNet的有效性。
实验
用tensorflow实现SMANet。两个网络的CNN编码器利用ResNet50模型。实验的实现是依据下面说明的训练过程。就背景-前景网络而言,在保持原始纵横比的同时,将图片裁剪(crops)的大小调整为最小边尺寸185像素。训练期间使用185*185的随机crops(基于验证集可提前停止)。在训练和测试期间采用多尺度方法。验证阶段,两个网络都采用滑动窗口策略。Adam优化器,学习率10e-4、用于网络训练。
由于收集大量像素级监督图像非常困难,只有很少的公共数据集可以用于场景文本分割。为了解决这个问题,可以采用合成数据生成。然而,由于域迁移,无法保证基于合成数据训练的网络也能很好的推广到真实图像。COCO_TS和MLT_S数据集实际上包含真实图像,因此,作者预计在用于网络训练时,域迁移将会减少。为了验证这个假设,SMANet用于场景文本分割,ICDAR-2013和Total-text测试集(提供像素级注释)用于性能评估。