Random Forests C++ʵ��:ϸ��,ʹ����ʵ��
������ͬ����github randomforests
��ӭ����
1. ���ɭ�ּ��
1.1 �㷨���
????????���ɭ��(Random Forest, RF)�㷨��һ�༯��ѧϰ�㷨,����ͳ��ѧϰ��Ĵ�ʦ������ Leo Breiman(1928�C2005) ���[1]���������������(Randomized Tree)�����,��Щ������˴˻������,������ѵ��������ѡ���������������������������Խ������ṹ�������ϸߵķ�����ɭ���ںܶ�Ӧ�ó����¾��в�����ȷ��,���߱�һЩ��������,����,���ٵij���,��Ч��ѵ����Ԥ��,�����Ͷ����������еȡ���Щ����ʹ���㷺Ӧ���ڲ�ͬ����,���������Ӿ�,ң��,������Ϣѧ�ȡ��ر��ڼ�����Ӿ�����,���ɭ����ͼ��ָ������ʶ��Ŀ��������岿��ʶ��ȷ��涼�бȽϳɹ���Ӧ�á�
????????���IJ��������ɭ���㷨������,��Ҫ��RF�㷨����һ������ʶ����ʵ�����顣�����RF����ϸ������һ���������˽�,�Ƽ��Ķ����ļ�������[3],��ݱ���Է���ɭ�֡�����ع�ɭ�֡������ܶ�ɭ�ֵȴ��㷨��ʵ�ֽǶȽ����˽��ܡ�
1.2 �������
????????��Բ�ͬ�������ɭ��ѧϰ�㷨��������ͻع����ࡣ���ɭ����һ������������,���DZ˴˶������нϴ���졣���е����������ͳ����ع���(Classification and Regression Tree, CART) ��ѵ����ʽ������������,���Dz����м�֦(pruning)���������Ҫ��������������:(1)ѵ�����������ѡ��,��ʹ���Ծ��ز�����(Bootstrap Sampling)Ϊɭ����ÿ���������в����ѵ������,�䱾������ Bagging ����ѧϰ˼�롣Bagging �ܹ���߲��ȶ�ѧϰ�㷨�����Ԥ���ȷ��,������ѧϰ�㷨�ķ���(Variance)�����,���� Bagging�����ɽ������ṹѧϰ�㷨�ϸߵķ���[4]��(2)��һ����,�����Ҳ���������нڵ�ķ��ѷ�ʽ�С�ÿ���ڵ���з���ʱ���Ӳ����ռ������ѡ��һ���Ӽ�,������ѡ�������š��ķ��Ѳ��������������������м�������Կ��Խ������DZ˴�֮�����ض�,�Ӷ����ͼ���ѧϰ�㷨�ķ�����������[1]��
2. C++ʵ�ֺ�ʹ��
2.1 ����
????????ĿǰRandom Forest��ʵ�ִ����python��R����,C++ʵ�ִ��ڵ��Ƚ���,����֪���Һ��õĽ���opencv, ALGLIB������,����ʵ��һ����Ϊһ������ѧϰ���һ����,������Ҫ��ѧ������������,ʹ�óɱ��Ըߡ���ͼ�ܽ��˸���RFʵ�֡�
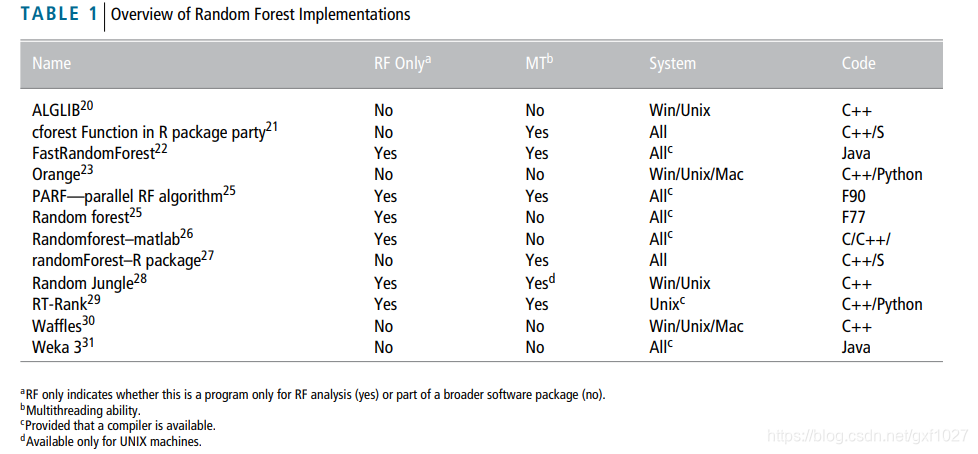
��ͼ��������:
Anne-Laure Boulesteix, Silke Janitza. Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics. WIREs Data Mining and Knowledge Discovery 2012, 2: 493�C507.
����,��������decision forest(C++);�ոտ�Դ��tensorflow����ɭ�� (TF-DF); ����NumPyʵ�ֵĻ���ѧϰ�� numpy-ml;
�߶��Ż�,�����ڿ�Դ�������ٶ�����scikit-learn�е�sklearn.ensembleģ��,�ṩ�������ѡ������
�� ��
????????����RFʵ�ֵ����������ʵ��2012����Ѿ����,��ʱ��д��ƪ��������ɫ���(�ָ�)via Random Forest��,Ч��������������3�������Բ����㷨�ͽ����Ĵ��������Ż�,����ʮ�������ݼ�,���������н�������˱ȶ�,��֤���㷨����ȷ�ԡ�������������ʵ�ֵ�ȷ,ע�ش������������������,��˼�ࡢ���û��Ѻá������DZ�RFʵ�ֵ��ص�:
- �����ڷ���ͻع�, ֧�ֻع�Ķ�ά���
- off-the-shelf,���弴��
- �ṩ����ʹ�÷�ʽ:��������Ƕ�����(C����C++)
- �ṩpython�ӿ�(δ�����)
- ֧��3�������
- �ɱ���ѵ����ɵ�ģ�������� (XML��ʽ,�ɶ���ǿ),Ҳ�ɶ�ȡ����ģ�ͽ���Ԥ��*
ʹ��tinyxml2��֧��xml�ļ��Ķ�д
2.2 ϸ��
2.2.1 �㷨�IJ���(Hyperparameters)
- MaxDepth: ���������,�����븺ֵ��ʹ��Ĭ��ֵ40
- TreesNum: ɭ������������,�����븺ֵ��ʹ��Ĭ��ֵ200
- SplitVariables: ���ڷ��ѵĺ�ѡ��������,������븺ֵ��ʹ��Ĭ��ֵ,���ڷ�����������Ϊ n _ f e a t u r e s \sqrt{n\_features} n_features?,���ڻع���������Ϊ n _ f e a t u r e s 3 \frac {n\_features}3 3n_features?
- MinSamplesSplit: �ڵ㻹�����·��ѵ���С������
- Randomness: 1��2��3,�����������ڽڵ��������������,1Ϊ����RF(Ĭ��),3ΪEtra-Trees[4]
2.2.2 ���ڽڵ���ѷ�ʽ
????????�������ɭ���е�ÿ����,��ÿ���ڵ�ҪѰ�ҡ����š��ķ��Ѳ���,ʹѵ���������Ѻ����Ϣ����(Information Gain, IG, ʽ1)���IG�����˷���ǰ��ڵ�������������(impurity)���½����ȡ����ڷ���ɭ��,������Giniϵ��������ڵ㲻����;���ڻع�ɭ��,�����˷���(��Э����)�������ڵ㲻���ȡ�Ϊ�˷���ʵ�ֺͿ��Ƽ�����,�����ˡ���ƽ�С�(axis aligned)�ķ��ѷ�ʽ(������RF),�������ѷ�ʽ�ɼ����ļ�������[3]��
I
G
=
H
(
S
)
?
��
i
=
l
,
r
�O
S
i
�O
�O
S
�O
H
(
S
i
)
(1)
IG=H\left ( S \right )-\sum\limits_{i={l,r}} \frac{|S^{i}|}{|S|}H\left ( S^{i} \right ) \tag{1}
IG=H(S)?i=l,r��?�OS�O�OSi�O?H(Si)(1)
????????��һС�����ᵽ�IJ�����Randomness���������ƽڵ����ʱ�������,ʵ�����ǿ����˽ڵ����ʱ�����ռ�Ĵ�С,�����ռ�ԽС�����Խ��Randomness����ѡ����ֵΪ{1,2,3},��Ӧ����Ϊ:
"1": Breiman�ľ���RF,��Ѱ�ҽڵ���������ͷ���ֵʱ���û��ڿ���(quick sort)+�����֡��ļ��ٷ���,ʹʱ�临�Ӷȴ� O ( n 2 ) O(n^2) O(n2)���͵� O ( n log ? n ) O(n\log{n}) O(nlogn), n n nΪ�ﵽ�ڵ�������(ʵ����elevators���ݼ��ϼ���370��,����Ϊ[200, 40, 6, 5]);
"2": �Ӻ�ѡ���������ֵ����Сֵ֮����ȵõ� K K K(Ĭ��Ϊ50)����ѡ�ķ���ֵ,�ٴ���ѡ����ŵ������Ͷ�Ӧ�ķ���ֵ,�� K �� �� K \to \infty K����,��Ϊ����RF;
"3": �������ġ�Extremely randomized trees��[4]�ķ���,�Ӻ�ѡ���������ֵ����Сֵ֮�����ѡ��һ��ֵ��Ϊ��ѡ,Ȼ����ѡ����ŵ������Ͷ�Ӧ�ķ���ֵ��
2.2.3 ������ֹ����
������ڵ���������ɷ����������ٷ�ʱ,ֹͣ����������������˵,������������֮һʱ,ֹͣ����,RF���������м�֦��
- �ﵽ������MaxDepth;
- ����ڵ�������IJ����ȵ�����ֵ:�ڵ��������������ͬ(�����ڷ���)��������Ŀ��ֵ�ķ���Ϊ0(�����ڷ���ع�);
- ����ڵ��������С�ڵ���MinSamplesSplit��
������������������һ,����ֹ����������
ע:���ڷ�������,���ֻ�������������,�������͵ڶ���������������ͬ,��ô����Ҫ��������������
�����������,����������������ֹ������,���Ӻ�ѡ��SplitVariables������������÷���ֵ,��ʱ���Դ��������������ѡ����ܵķ���ֵ�ķ�ʽ�����п��ܳ����ڴﵽ�ڵ�����������,��SplitVariables��С�ij���,ǡ�ɺ�ѡ������ֵ����ͬ�������Dz��ɷ���ֹͣ����������
2.2.4 ����Ԥ��
Final predictions are obtained by aggregating over the ensemble. �� G��rard Biau
-
���ڷ�������,����hard descion����soft decsion���ַ�ʽ���Ƚ��ܺ���,���ɭ��ѵ��������,�������� x x x����ÿ��������Ҷ�ӽڵ�,��ô���� x x x������� c c c�ĸ���Ϊ:
p ( c �O x ) = 1 T �� t = 1 T p t ( c �O x ) p\left ( c\mid x \right )=\frac{1}{T}\sum_{t=1}^{T}p_{t}\left ( c\mid x \right ) p(c�Ox)=T1?t=1��T?pt?(c�Ox)
����, T T TΪɭ���������������, p t ( c �O x ) p_{t}\left ( c\mid x \right ) pt?(c�Ox)ΪҶ�ӽڵ�����ֲ�����ô�� x x x���ľ���Ϊ:
c ^ = arg ? max ? c �� { 1 , ? ? , N c } p ( c �O x ) \hat{c}=\mathop{\arg\max}_{c\in \left \{ 1,\cdots,N_{c} \right \}}p\left ( c\mid x \right ) c^=argmaxc��{1,?,Nc?}?p(c�Ox)
������soft decision������Hard decision,ÿ���������Ӧ�����,Ȼ��ͳ�Ƴ����������Ϊ x x x�����,Ҳ��������ͶƱ�� -
���ڻع�����,ʹ�������������ƽ��ֵ��
2.3 ʹ��
Դ�����Դ�github������:gxf1027/randomforests
2.3.1 �����з�ʽ
��ִ���ļ���binĿ¼��,Ҳ�������б���(linux)
git clone https://github.com/gxf1027/randomforests.git
cd randomforests
# g++ (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
# train
g++ -fpermissive -std=c++11 -O2 src/RandomCLoquatForests.cpp src/RandomRLoquatForests.cpp src/UserInteraction2.cpp src/SharedRoutines.cpp src/tinyxml2/tinyxml2.cpp demo/rf_train.cpp -o rf_train
# test
g++ -fpermissive -std=c++11 -O2 src/RandomCLoquatForests.cpp src/RandomRLoquatForests.cpp src/UserInteraction2.cpp src/SharedRoutines.cpp src/tinyxml2/tinyxml2.cpp demo/rf_test.cpp -o rf_test
�����windows��,���� src��demoĿ¼,ͨ��IDE���뼴�ɡ�
ʾ��1:ѵ��
����:./rf_train -p 0 -c RF_config.xml -d dataset.data -o ClassificationForest.xml
�ع�:./rf_train -p 1 -c RF_config.xml -d dataset.data -o RegressionForest.xml
- -p: '0����ʾ��������,'1����ʾ�ع�����
- -c: RF�IJ���,ͨ��xml�ļ�ָ��
����Ϊ�����ļ���ʾ��
<?xml version="1.0" ?>
<RandomForestConfig>
<MaxDepth>40</MaxDepth>
<TreesNum>200</TreesNum>
<SplitVariables>4</SplitVariables>
<MinSamplesSplit>5</MinSamplesSplit>
<Randomness>1</Randomness>
</RandomForestConfig>
������ṩ�����ļ�,��ʹ��Ĭ�ϲ���
- -d: ѵ���������ļ�,��Ҫ��ѭ���¸�ʽ
�������������ݼ��ļ�:
��ͷ����Ϊ������(totoal_sample_num), ������(variable_num), �����(class_num)
������ÿһ��Ϊһ��ѵ������,�����ÿո�ָ�,��������Ϊ������(��0��ʼ,����ڶ���������Ϊ0, 1)
@totoal_sample_num=19020
@variable_num=10
@class_num=2
1 86.088 36.259 3.4839 0.2359 0.1337 -12.893 -56.746 -4.0291 4.158 372.98
1 76.099 18.755 2.8639 0.3461 0.2209 -90.721 -52.015 -19.577 3.46 271.43
1 62.989 22.083 3.1191 0.2258 0.1167 -85.779 48.038 19.251 7.652 246
1 19.55 10.763 2.3201 0.6077 0.3421 8.3626 -17.38 -10.092 17.368 173.39
0 67.609 26.678 2.632 0.3851 0.2462 -56.63 -57.963 19.806 79.666 227.19
1 24.909 17.432 2.632 0.3944 0.2229 7.1171 -2.3838 -8.6055 37.114 204.79
�����ع������ݼ��ļ�:
��ͷ����Ϊ������(totoal_sample_num), ������(variable_num_x), Ŀ��ά��(variable_num_y)
������ÿһ��Ϊһ��ѵ������,�����ÿո�ָ�,����ǰ��variable_num_y����ΪĿ��ֵ
@totoal_sample_num=4177
@variable_num_x=8
@variable_num_y=1
15 1 0.455 0.365 0.095 0.514 0.2245 0.101 0.15
7 1 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07
9 2 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21
10 1 0.44 0.365 0.125 0.516 0.2155 0.114 0.155
7 3 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055
8 3 0.425 0.3 0.095 0.3515 0.141 0.0775 0.12
- -o: (��ѡ)���RFģ�͵�����·��(��xml�ļ���ʽ,��ͼΪ����Ƭ��)
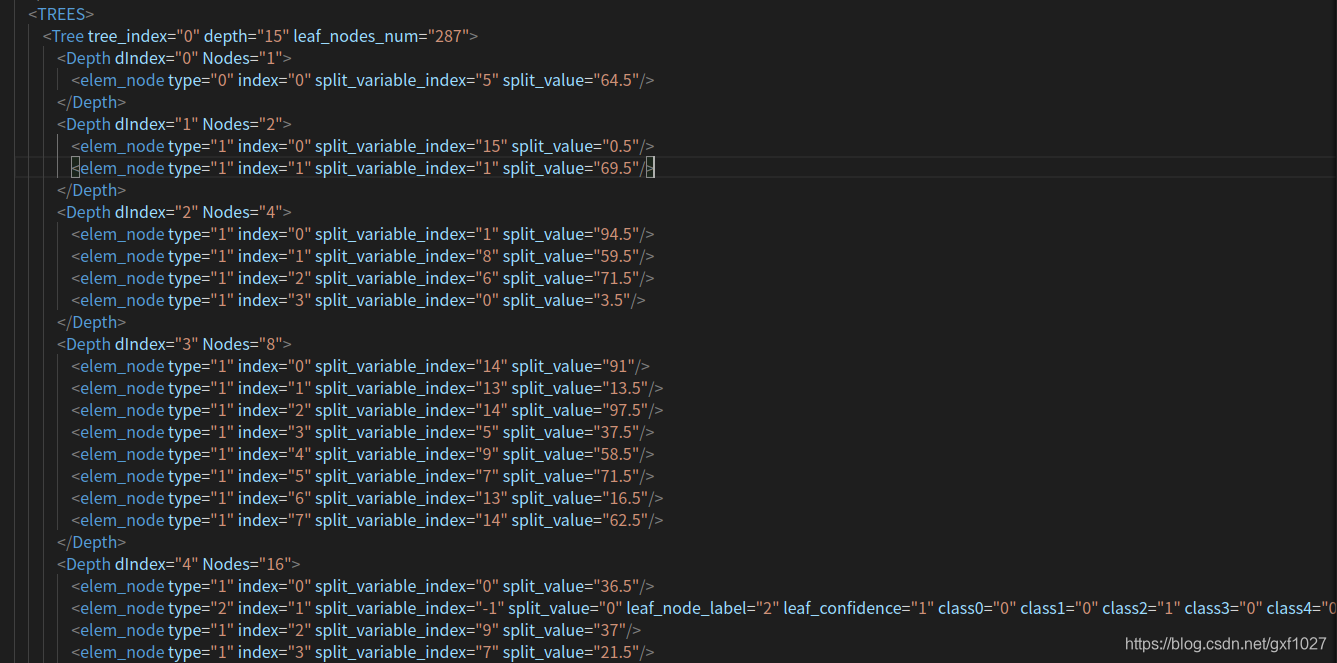
ѵ������(�Է���Ϊ��,pendigits���ݼ�)
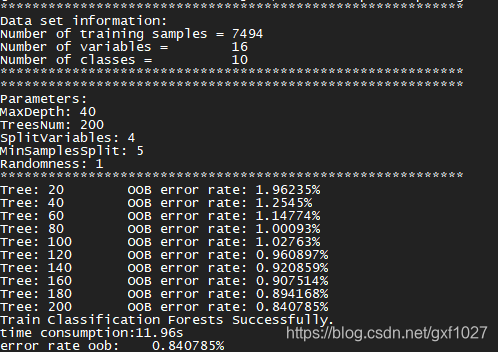
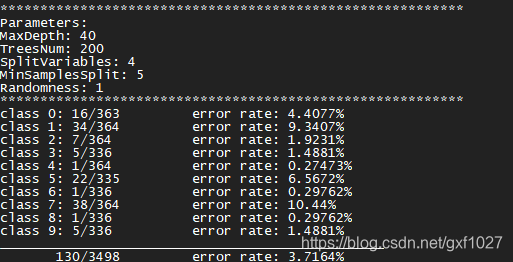
ʾ��2:����
./rf_test -p 0 -c rf_pendigits.xml -d ./DataSet/Classification/pendigits.tes -o test-pendigits.out
- -c: RFģ���ļ�,��rf_train��������ص�ģ���ļ�
- -d: �������ݼ�,��ʽ��ѵ������ͬ
- -o: ���������ļ�
2.3.2 ����Ƕ�뷽ʽ(�Ƽ�)
����srcĿ¼��Դ�ļ�,��дѵ������Ԥ����롣���������������ͷ�ļ�������ϸ˵��,�������֡����¸���ѵ����Ԥ��Ĵ���Ƭ�Ρ�
ѵ��
�ӱ��������ļ��������ݼ�����ѵ��,����oob-error(oob-mse),������forest�����ء�
(1)����ɭ��
#include <cmath>
using namespace std;
#include "RandomCLoquatForests.h"
#include "UserInteraction2.h"
int main()
{
// read training samples if necessary
char filename[500] = "./DataSet/Classification/pendigits.tra";
float** data = NULL;
int* label = NULL;
Dataset_info_C datainfo;
InitalClassificationDataMatrixFormFile2(filename, data/*OUT*/, label/*OUT*/, datainfo/*OUT*/);
// setting random forests parameters
RandomCForests_info rfinfo;
rfinfo.datainfo = datainfo;
rfinfo.maxdepth = 40;
rfinfo.ntrees = 500;
rfinfo.mvariables = (int)sqrtf(datainfo.variables_num);
rfinfo.minsamplessplit = 5;
rfinfo.randomness = 1;
// train forest
LoquatCForest* loquatCForest = NULL;
TrainRandomForestClassifier(data, label, rfinfo, loquatCForest /*OUT*/, 50);
float error_rate = 1.f;
OOBErrorEstimate(data, label, loquatCForest, error_rate /*OUT*/);
// save RF model
SaveRandomClassificationForestModelToXML2("Modelfile.xml", loquatCForest);
// clear the memory allocated for the entire forest
ReleaseClassificationForest(&loquatCForest);
// release money: data, label
for (int i = 0; i < datainfo.samples_num; i++)
delete[] data[i];
delete[] data;
delete[] label;
return 0;
}
(2)�ع�ɭ��
#include "RandomRLoquatForests.h"
#include "UserInteraction2.h"
using namespace std;
int main()
{
// read training samples if necessary
char filename[500] = "./DataSet/Regression/Housing_Data_Set-R.txt";
float** data = NULL;
float** target = NULL;
Dataset_info_R datainfo;
InitalRegressionDataMatrixFormFile2(filename, data /*OUT*/, target /*OUT*/, datainfo /*OUT*/);
// setting random forests parameters
RandomRForests_info rfinfo;
rfinfo.datainfo = datainfo;
rfinfo.maxdepth = 40;
rfinfo.ntrees = 200;
rfinfo.mvariables = (int)(datainfo.variables_num_x / 3.0 + 0.5);
rfinfo.minsamplessplit = 5;
rfinfo.randomness = 1;
// train forest
LoquatRForest* loquatRForest = NULL;
TrainRandomForestRegressor(data, target, rfinfo, loquatRForest /*OUT*/, false, 20);
float* mean_squared_error = NULL;
MSEOnOutOfBagSamples(data, target, loquatRForest, mean_squared_error /*OUT*/);
delete[] mean_squared_error;
// save RF model
SaveRandomRegressionForestModelToXML2("Modelfile-R.xml", loquatRForest);
// clear the memory
ReleaseRegressionForest(&loquatRForest);
// release money: data, target
for (int i = 0; i < datainfo.samples_num; i++)
{
delete[] data[i];
delete[] target[i];
}
delete[] data;
delete[] target;
}
˵��
- ���ϴ����Ϊ����,ʵ��ʹ����Ժ�������ֵ�����жϡ�
- RF�ṹ�����loquatForest���ڴ���TrainRandomForestClassifier /TrainRandomForestRegressor �������,��ReleaseClassificationForest /ReleaseRegressionForest �ͷ��ڴ�,�û���������������ͷ�
- OOBErrorEstimate ����out-of-bag���������,�������data, label������ѵ��ʱ��ͬ,MSEOnOutOfBagSamples��ͬ
- InitalClassificationDataMatrixFormFile2/InitalRegressionDataMatrixFormFile2 �ӱ����ļ���ȡ���ݼ�,�ļ���ʽ���������з�ʽ������ͬ��Ҳ����������ѵ������,�Ϳ��Բ���������������
Ԥ��
// ����ɭ��:label_index���ڷ���Ԥ������
EvaluateOneSample(data, loquatForest, label_index /*OUT*/, 1);
// �ع�ɭ��:target_predicted���ڷ���Ԥ���Ŀ��ֵ
EvaluateOneSample(data, loquatForest, target_predicted /*OUT*/);
- �ṩ���������ķ���/�ع�ӿ�,���������ݼ�����ѭ�������
- ����ɭ�ֵ����һ��������ʾԤ�ⷽʽ,1:hard,0:soft decision��
3. Python�ӿ�
����
4. ʵ��
4.1 ���ݼ�
| ���� | ����/�ع� | ��Դ | ������ | ������ | ����� |
|---|---|---|---|---|---|
| chess-krvk | classification | UCI | 28056 | 6 | 18 |
| Gisette | classification | UCI | 6000/1000 | 5000 | 2 |
| ionosphere | classification | UCI | 351 | 34 | 2 |
| mnist | classification | libsvm | 60000/10000 | 780 | 10 |
| MAGIC_Gamma_Telescope | classification | UCI | 19020 | 10 | 2 |
| pendigits | classification | UCI | 7494/3498 | 16 | 10 |
| spambase | classification | UCI | 4601 | 57 | 2 |
| Sensorless_drive_diagnosis | classification | UCI | 58509 | 48 | 11 |
| Smartphone Human Activity Recognition | classification | UCI | 4242 | 561 | 6 |
| waveform | classification | UCI | 5000 | 40 | 3 |
| satimage | classification | UCI | 6435 | 36 | 6 |
| abalone | regression | UCI | 4177 | 8 | ���� |
| airfoil_self_noise | regression | UCI | 1503 | 5 | ���� |
| Bike-Sharing1 | regression | UCI | 17379 | 14 | ���� |
| Combined_Cycle_Power_Plant | regression | UCI | 9568 | 4 | ���� |
| elevators | regression | openml | 16599 | 18 | ���� |
| Housing | regression | kaggle | 506 | 13 | ���� |
| Parkinsons_Telemonitoring2 | regression | UCI | 5875 | 19 | ���� |
| Superconductivty | regression | UCI | 21263 | 81 | ���� |
| YearPredictionMSD | regression | Million Song Dataset/ UCI | 515345 | 90 | ���� |
- Bike-Sharing: ԭ���ݼ�ȥ����1��2��
- Parkinsons_Telemonitoring: Ԥ�����(output)��2ά�ġ���ԭ���ݼ���1��(subject number)ȥ��,UCI��վ�ϼ�¼��Number of Attributes:26�����������ص����ݼ�ֻ��22ά(����2άoutput)
4.2 ����
????????ʹ��2.2�в���,��һС�ڱ����С���������Ϊ [TreesNum, SplitVariables, MaxDepth, MinSamplesSplit] (randomness��Ϊ1,������RF)��ʵ�鲢û�жԲ������е���,���Ǹ��ݾ���ѡȡ�˸�����Ϊ�ȽϺ����IJ�����ϡ�ʵ��Ŀ��һ������Ϊ����֤�㷨ʵ�ֵ���ȷ��,��һ����Ҳ��˵��RF�Բ������жȽϵ�(���SVM)��
Clearly, some algorithms such as glmnet and svm are much more tunable than the others,
while ranger(random forest) is the algorithm with the smallest tunability.[6]
4.3 ���
????????���û������˵��,����ͻع������ʵ�����ֱ�ͨ��out-of-bag���������(%)��out-of-bag �������(Mean Square Error (MSE))��ͳ��,�������10��ȡƽ���ͱ�����Կ���,��������ݼ���������Ĭ�ϵIJ���,Ҳ�ܴﵽ������Ч����
The out-of-bag (oob) error estimate
��This has proven to be unbiased in many tests[2].
| ���ݼ� | ���� | oob error(%)/mse | ����/�ع� |
|---|---|---|---|
| chess-krvk | [500, 2*, 40, 5] | 16.46636��0.07493 | C |
| Gisette | [200, 70*, 40, 5] | 2.932105��0.10090(oob) 3.010��0.13333(test set) | C |
| ionosphere | [200, 5*, 40, 5] | 6.325��0.213 | C |
| mnist | [200, 27*, 40, 5] | 3.307166��0.02863 | C |
| MAGIC_Gamma_Telescope | [200, 3*, 40, 5] | 11.8559��0.04347 | C |
| pendigits | [200, 4*, 40, 5] | 0.880822��0.03428(oob) 3.670668��0.049843(test set) | C |
| spambase | [200, 7*, 40, 5] | 4.514335��0.10331 | C |
| satimage | [500, 6*, 40, 5] | 8.102018��0.057777 | C |
| Sensorless_drive_diagnosis | [200, 6*, 40, 5] | 0.1468151��0.005843 | C |
| Smartphone Human Activity Recognition | [200, 23*, 40, 5] | 7.39415��0.1159 | C |
| waveform | [500, 6*, 40, 5] | 14.70493��0.19792 | C |
| abalone | [500, 3#, 40, 5] | 4.58272��0.008826 | R |
| airfoil_self_noise | [200, 2/5, 40, 5] | 3.83345��0.034283 | R |
| Bike-Sharing | [500, 5#, 40, 5] | 29.7227��0.84333 | R |
| Combined_Cycle_Power_Plant | [200, 2/4, 40, 5] | 9.94693��0.031153 | R |
| elevators | [200, 10/18, 40, 5] | 7.1859E-06��3.15264E-08 | R |
| Housing | [200, 4#, 40, 5] | 10.077��0.1923 | R |
| Parkinsons_Telemonitoring3 | [200,19,40,5] | [1.437, 2.523]��[0.01706, 0.03033] | R |
| Superconductivty | [200, 27#, 40, 5] | 81.4527��0.2781 | R |
| YearPredictionMSD | [100, 30#, 40, 50] | 83.1219��0.05236 | R |
*: ��ʾʹ�÷���ɭ��Ĭ�ϵ�
v
a
r
i
a
b
l
e
_
n
u
m
\sqrt{variable\_num}
variable_num?��ΪSplitVariables����;
#:��ʾʹ�ûع�ɭ��Ĭ�ϵ�??
v
a
r
i
a
b
l
e
_
n
u
m
_
x
3
\frac {variable\_num\_x}3
3variable_num_x?��ΪSplitVariables����
3: Parkinsons_Telemonitoring��Ԥ�������2ά��,���㷨�����ǰ����ֽ�Ϊ���������ع�����,����ֱ��ʹ�ö�ά������ݽ���ѵ����
5. ����
5.1 ����Ӱ��
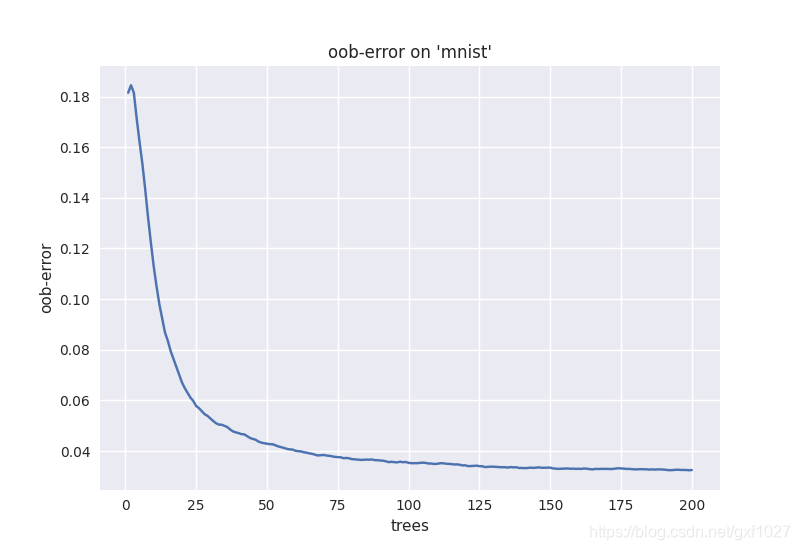
????????ͨ��RF��Ĭ�ϲ����趨��Ҳ��ȡ�ý������Ч��,ͨ���Բ���(��2.2��)���ſ��Ի�ø��ѵķ���/�ع�Ч����һ����Զ�TreesNum��SplitVariables���е��š�ͨ����Ϊ����TreesNum��ʹ��������½�(��ȻҲ������)������ͼ,չʾ������������,oob error�����½������ơ�
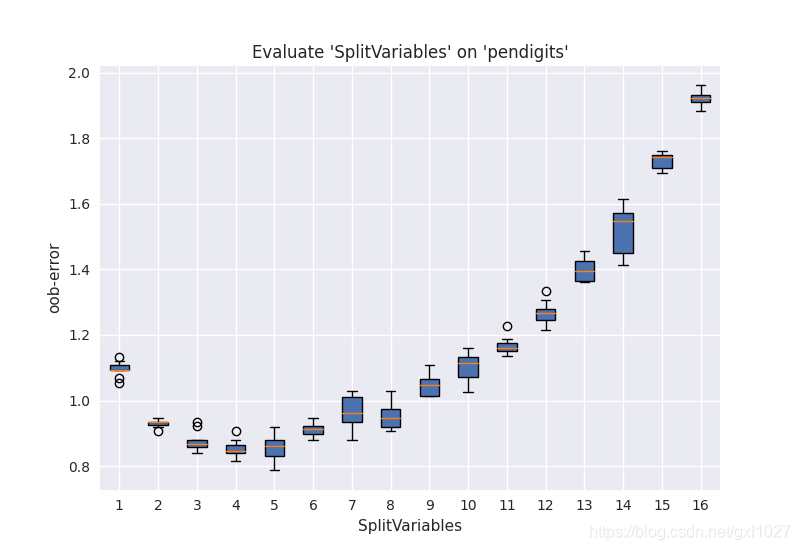
????????SplitVariables�ǿ���RF����Ե���Ҫ����,��������ʱ��֮��Ĺ�����Ҳ��֮����,�����������ӻᵼ�·���/�ع�������[2]���ӿɵ���(Tunability)�Ƕȿ���,����SplitVariables�����������Ĺ��������ġ���SplitVariablesѡ��Ĭ���趨ʱ,ͨ��Ҳ��ȡ�ò�����Ч����
The correlation between any two trees in the forest. Increasing the correlation increases the forest error rate.[2]
In ranger(random forest) mtry is the most tunable parameter which is already common knowledge and is implemented in software packages such as caret.[6]
��ͼΪpendigits���ݼ���,��ͬSplitVariables(����Ϊ16ά,TreesNum=500)�����µķ���oob error��
5.2 ������Ҫ��
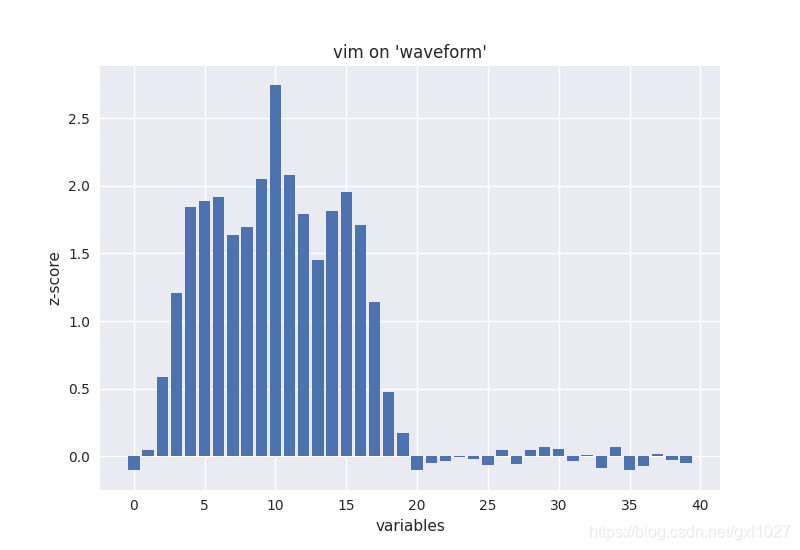
????????������Ҫ��(variable importance)��������RF���Դ�����һ�����ԡ�����oob���ݵ�������������ķ���������������Ҫ�ԡ��������ݼ�"waveform",�������ͼ��ʾ,�ɼ���һ����������Ҫ�Լ���Ϊ0,������Ϊwaveform�ĺ�19ά�������������,���variable importance�������������������
�����
[1]. Breiman, L. Random Forests . Machine Learning 45, 5�C32, 2001.
[2]. Leo Breiman, Adele Cutler. Random Forest Homepage on berkeley website.
[3]. Antonio Criminisi, Ender Konukoglu, Jamie Shotton. Decision Forests for Classification, Regression, Density Estimation, Manifold Learning and Semi-Supervised Learning. MSR-TR-2011-114, 2011.
[4]. P. Geurts, D. Ernst, and L. Wehenkel. Extremely randomized trees . Machine Learning, 63(1), 2006: 3-42.
[5]. Manuel Fern��ndez-Delgado, Eva Cernadas, Sen��n Barro, Dinani Amorim. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? Journal of Machine Learning Research, 15(90):3133?3181, 2014.
[6]. Philipp Probst, Anne-Laure Boulesteix, Bernd Bischl. Tunability: Importance of Hyperparameters of Machine Learning Algorithms. Journal of Machine Learning Research, 20(53):1?32, 2019.