BERT的背景
BERT在2018年出现。2018 年是机器学习模型处理文本(或者更准确地说,自然语言处理或 NLP)的转折点。在 BERT 的论文发布后不久,这个团队还公开了模型的代码,并提供了模型的下载版本,这些模型已经在大规模数据集上进行了预训练。这是一个重大的发展,因为它使得任何一个构建构建机器学习模型来处理语言的人,都可以将这个强大的功能作为一个现成的组件来使用,从而节省了从零开始训练语言处理模型所需要的时间、精力、知识和资源。
使用BERT 两个步骤:
- 下载预训练好的模型(这个模型是在无标注的数据上训练的)
- 模型微调
举例:用在句子分类
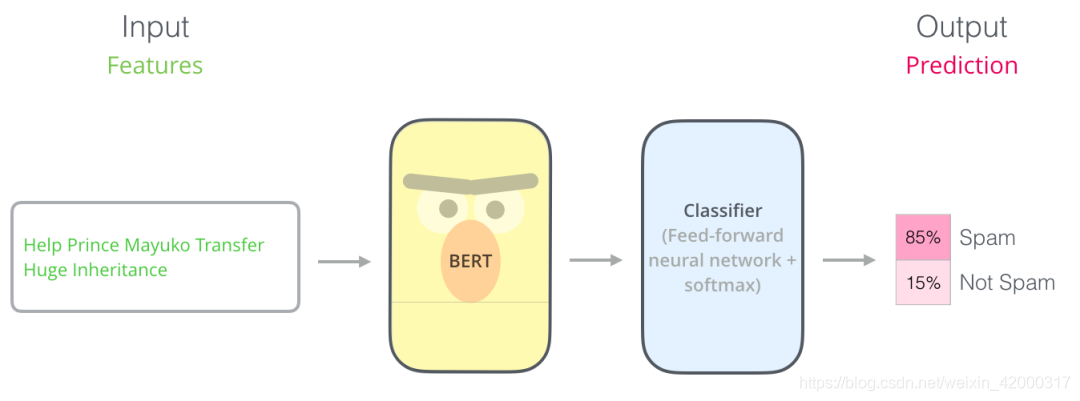
训练这个句子分类的模型,主要训练分类器(Classifier),在训练过程中几乎不用改动BERT模型。当讨论分类时,属于监督学习领域,需要带有标签的数据集来训练这样的一个模型。
模型架构
- BERT BASE - 与 OpenAI 的 Transformer 大小相当,以便比较性能
- BERT LARGE - 一个非常巨大的模型,它取得了最先进的结果
- 还有后缀为cased/uncased,cased有大小写,uncased全小写
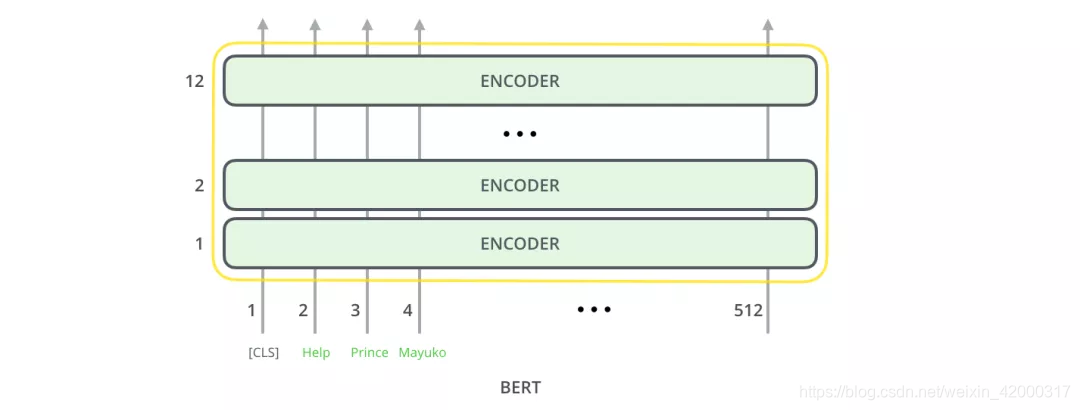
BERT(Bidirectional Encoder Representation from Transformers),即相当于训练好的Transformer的Encoder。
2 种不同大小规模的 BERT 模型都有大量的 Encoder 层(论文里把这些层称为 Transformer Blocks)- BASE 版本由 12 层 Encoder,Large 版本有 20 层 Encoder。同时,这些 BERT 模型也有更大的前馈神经网络(分别有 768 个和 1024 个隐藏层单元)和更多的 attention heads(分别有 12 个和 16 个),超过了原始 Transformer 论文中的默认配置参数(原论文中有 6 个 Encoder 层, 512 个隐藏层单元和 8 个 attention heads)。
模型输入
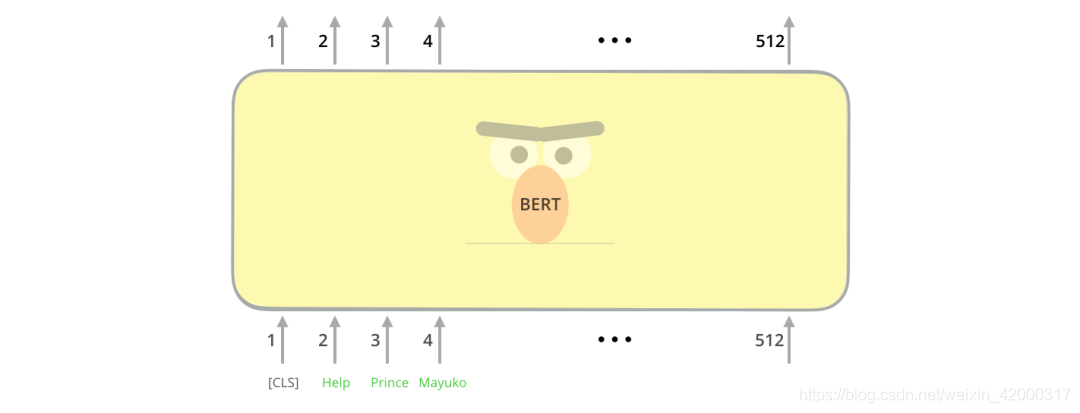
第一个输入的 token 是特殊的 [CLS],是分类(class的缩写)。
就像 Transformer 中普通的 Encoder 一样,BERT 将一串单词作为输入,这些单词在 Encoder 的栈中不断向上流动。每一层都会经过 Self Attention 层,并通过一个前馈神经网络,然后将结果传给下一个 Encoder。
模型输出
每个位置输出一个大小为 hidden_size(在 BERT Base 中是 768)的向量。对于上面提到的句子分类的例子,我们只关注第一个位置的输出(输入是 [CLS] 的那个位置)。这个输出的向量现在可以作为后面分类器(Feed-forward neural network + softmax)的输入。论文里用单层神经网络作为分类器,取得了很好的效果。
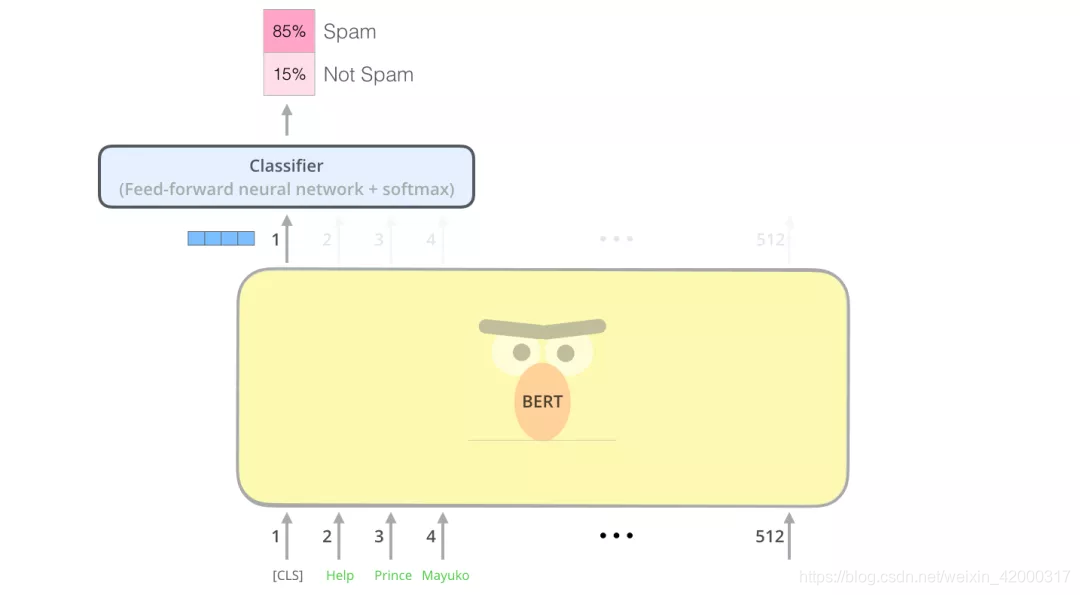
如果需要多分类,只需要调整分类器的神经网络,增加输出的神经元个数,再经过softmax。
未完待补充