1.逻辑回归中的梯度下降(Logistic Regression Gradient Descent )
我们讨论怎样通过计算偏导数来实现逻辑回归的梯度下降算法。它的关键点是几个
重要公式,其作用是用来实现逻辑回归中梯度下降算法。但是在本节视频中,我将使用计算
图对梯度下降算法进行计算。我必须要承认的是,使用计算图来计算逻辑回归的梯度下降算
法有点大材小用了。但是,我认为以这个例子作为开始来讲解,可以使你更好的理解背后的
思想。从而在讨论神经网络时,你可以更深刻而全面地理解神经网络。接下来让我们开始学
习逻辑回归的梯度下降算法。
假设样本只有两个特征𝑦 1 和𝑦 2 ,为了计算𝑨,我们需要输入参数𝑥 1 、𝑥 2 和𝑐,除此之外
还有特征值𝑦 1 和𝑦 2 。因此𝑨的计算公式为: 𝑨 = 𝑥 1 𝑦 1 + 𝑥 2 𝑦 2 + 𝑐
回想一下逻辑回归的公式定义如下: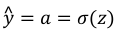
其中
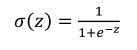
损失函数: 
代价函数: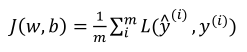
假设现在只考虑单个样本的情况,单个样本的代价函数定义如下:
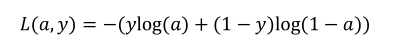
其中𝑏是逻辑回归的输出,𝑧是样本的标签值。现在让我们画出表示这个计算的计算图。
这里先复习下梯度下降法,𝑥和𝑐的修正量可以表达如下:
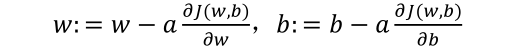

如图:在这个公式的外侧画上长方形。然后计算: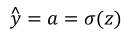
也就是计算图的下一
步。最后计算损失函数L(𝑏,𝑧)。 有了计算图,我就不需要再写出公式了。因此,为了使得
逻辑回归中最小化代价函数L(𝑏,𝑧),我们需要做的仅仅是修改参数𝑥和𝑐的值。前面我们已
经讲解了如何在单个训练样本上计算代价函数的前向步骤。现在让我们来讨论通过反向计算
出导数。 因为我们想要计算出的代价函数L(𝑏,𝑧)的导数,首先我们需要反向计算出代价函数𝑀(𝑏,𝑧)关于𝑏的导数,在编写代码时,你只需要用𝑒𝑏 来表示 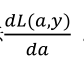
通过微积分得到:
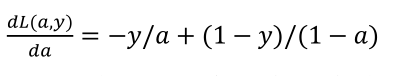
如果你不熟悉微积分,也不必太担心,我们会列出本课程涉及的所有求导公式。那么如
果你非常熟悉微积分,我们鼓励你主动推导前面介绍的代价函数的求导公式,使用微积分直
接求出L(𝑏,𝑧)关于变量𝑏的导数。如果你不太了解微积分,也不用太担心。现在我们已经计
算出𝑒𝑏,也就是最终输出结果的导数。 现在可以再反向一步,在编写 Python 代码时,你只需要用𝑒𝑨来表示代价函数𝑀关于𝑨 的导数 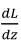
,也可以写成
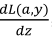
,这两种写法都是正确的。
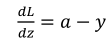
因为 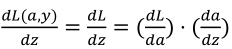
, 并且
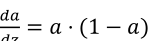
, 而
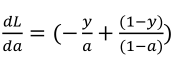
,
因此将这两项相乘,得到:
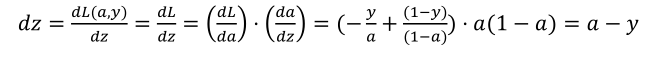
视频中为了简化推导过程,假设𝑜 𝑦 这个推导的过程就是我之前提到过的链式法则。如果
你对微积分熟悉,放心地去推导整个求导过程,如果不熟悉微积分,你只需要知道𝑒𝑨 = (𝑏 ?𝑧)已经计算好了。
现在进行最后一步反向推导,也就是计算𝑥和𝑐变化对代价函数𝑀的影响,特别地,可以用:
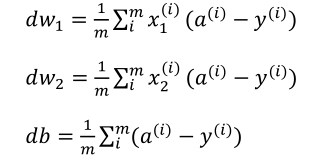
视频中, 𝑒𝑥 1 表示
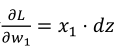
, 𝑒𝑥 2 表示
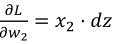
,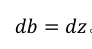
。
因此,关于单个样本的梯度下降算法,你所需要做的就是如下的事情:
使用公式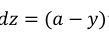
计算𝑒𝑨,
使用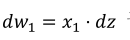
计算𝑒𝑥 1 , 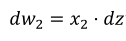
计算𝑒𝑥 2 ,
来计算𝑒𝑐,
然后: 更新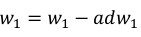
, 更新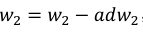
, 更新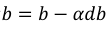
。
这就是关于单个样本实例的梯度下降算法中参数更新一次的步骤。

现在你已经知道了怎样计算导数,并且实现针对单个训练样本的逻辑回归的梯度下降算
法。但是,训练逻辑回归模型不仅仅只有一个训练样本,而是有𝑛个训练样本的整个训练集。
2. m 个样本的梯度下降(Gradient Descent on m Examples)
在之前的视频中,你已经看到如何计算导数,以及应用梯度下降在逻辑回归的一个训练
样本上。现在我们想要把它应用在𝑛个训练样本上。

首先,让我们时刻记住有关于损失函数𝐾(𝑥,𝑐)的定义。
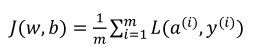
当你的算法输出关于样本𝑧的𝑏 (𝑗) ,𝑏 (𝑗) 是训练样本的预测值,即:𝜎(𝑨 (𝑗) ) = 𝜎(𝑥 𝑈 𝑦 (𝑗) +𝑐)。 所以我们在前面的幻灯中展示的是对于任意单个训练样本,如何计算微分当你只有一
个训练样本。因此𝑒𝑥 1 ,𝑒𝑥 2 和𝑒𝑐 添上上标𝑗表示你求得的相应的值。如果你面对的是我们
在之前的幻灯中演示的那种情况,但只使用了一个训练样本(𝑦 (𝑗) ,𝑧 (𝑗) )。
现在你知道带有求和的全局代价函数,实际上是 1 到𝑛项各个损失的平均。 所以它表
明全局代价函数对𝑥 1 的微分,对𝑥 1 的微分也同样是各项损失对𝑥 1 微分的平均。
但之前我们已经演示了如何计算这项,即之前幻灯中演示的如何对单个训练样本进行计
算。所以你真正需要做的是计算这些微分,如我们在之前的训练样本上做的。并且求平均,
这会给你全局梯度值,你能够把它直接应用到梯度下降算法中。
所以这里有很多细节,但让我们把这些装进一个具体的算法。同时你需要一起应用的就
是逻辑回归和梯度下降。
我们初始化𝐾 = 0,𝑒𝑥 1 = 0,𝑒𝑥 2 = 0,𝑒𝑐 = 0
代码流程:
J=0;dw1=0;dw2=0;db=0;
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));
dz(i) = a(i)-y(i);
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alphadw
b=b-alphadb
幻灯片上只应用了一步梯度下降。因此你需要重复以上内容很多次,以应用多次梯度下
降。看起来这些细节似乎很复杂,但目前不要担心太多。希望你明白,当你继续尝试并应用
这些在编程作业里,所有这些会变的更加清楚。
但这种计算中有两个缺点,也就是说应用此方法在逻辑回归上你需要编写两个for循环。
第一个 for 循环是一个小循环遍历𝑛个训练样本,第二个 for 循环是一个遍历所有特征的 for循环。这个例子中我们只有 2 个特征,所以𝑜等于 2 并且𝑜 𝑦 等于 2。 但如果你有更多特征,你开始编写你的因此𝑒𝑥 1 ,𝑒𝑥 2 ,你有相似的计算从𝑒𝑥 3 一直下去到𝑒𝑥 𝑜 。所以看来你需要一个 for 循环遍历所有𝑜个特征。
当你应用深度学习算法,你会发现在代码中显式地使用 for 循环使你的算法很低效,同
时在深度学习领域会有越来越大的数据集。所以能够应用你的算法且没有显式的 for 循环会
是重要的,并且会帮助你适用于更大的数据集。所以这里有一些叫做向量化技术,它可以允许你的代码摆脱这些显式的 for 循环。
我想在先于深度学习的时代,也就是深度学习兴起之前,向量化是很棒的。可以使你有
时候加速你的运算,但有时候也未必能够。但是在深度学习时代向量化,摆脱 for 循环已经
变得相当重要。因为我们越来越多地训练非常大的数据集,因此你真的需要你的代码变得非
常高效。所以在接下来的几个视频中,我们会谈到向量化,以及如何应用向量化而连一个 for循环都不使用。所以学习了这些,我希望你有关于如何应用逻辑回归,或是用于逻辑回归的梯度下降,事情会变得更加清晰。当你进行编程练习,但在真正做编程练习之前让我们先谈谈向量化。然后你可以应用全部这些东西,应用一个梯度下降的迭代而不使用任何for循环。