误差
误差来自哪
误差一般来自bias(偏差)和variance(方差)
偏差与方差这个链接里写的比较详细
最主要就是理解这个图:
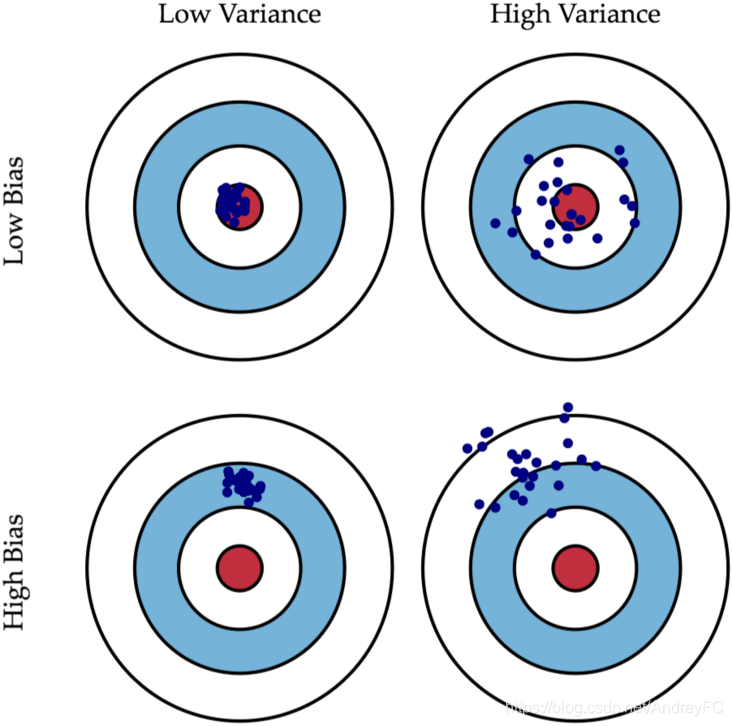
偏差与方差大分别带来的影响
偏差大即欠拟合,一般是模型的设计有问题,需要考虑重新设计模型。
方差大即过拟合,可能是数据量不够导致机器会去学习某些不普遍的特征,从而导致过拟合。
交叉验证
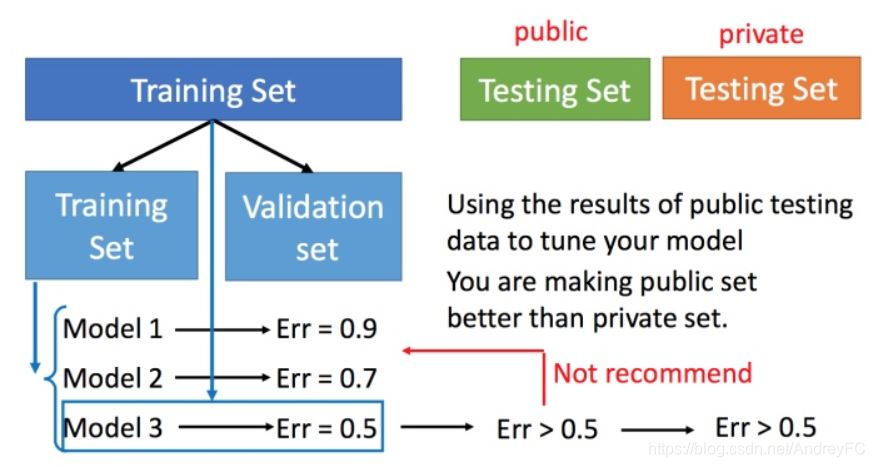
交叉验证 就是将训练集再分为两部分,一部分作为训练集,一部分作为验证集。用训练集训练模型,然后再验证集上比较,确实出最好的模型之后,再用全部的训练集训练模型,然后再用测试集进行测试。
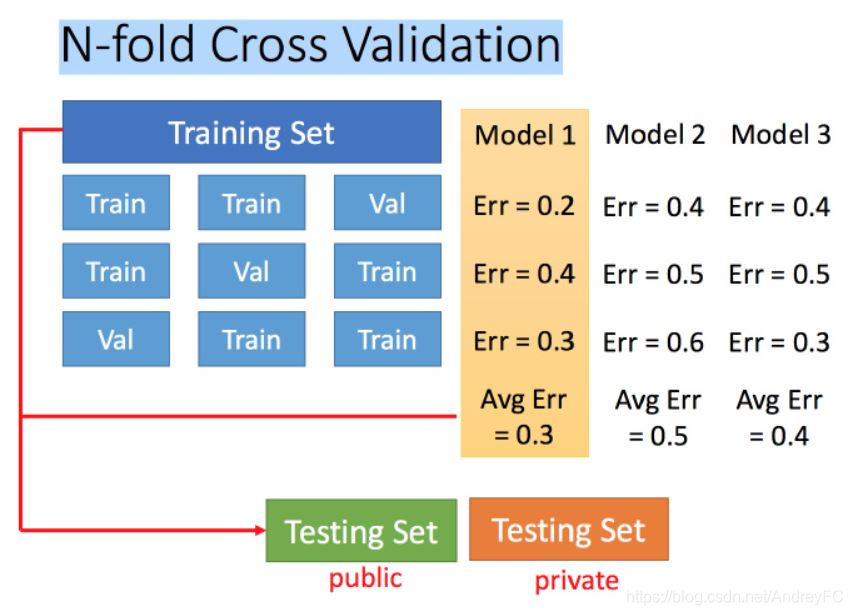
N折交叉验证
梯度下降
为什么要梯度下降
要让损失函数的值最小
步骤
- 小心调整学习率
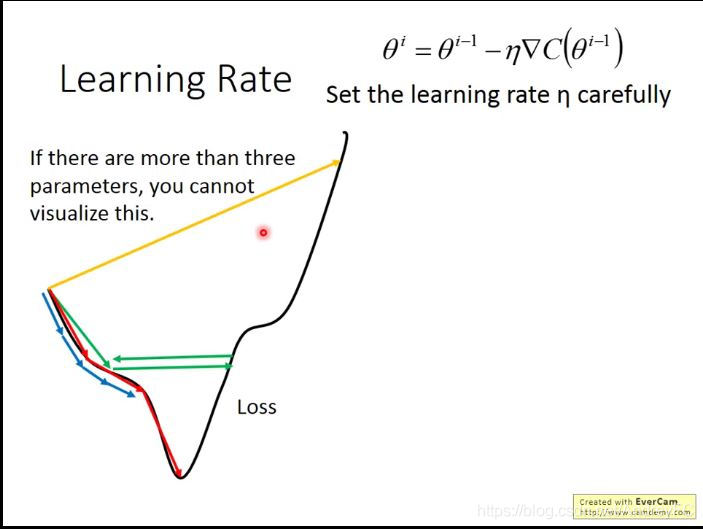
红色表示学习率调得刚刚好,那么我们就能达到最低点;
绿色表示学习率稍大,我们可能就会在两点之间反复横跳,一直找不到最低点;
黄色表示学习率过大,就可能越找越大。
当我们的参数超过2维后,我们无法将上图损失值可视化,但我们可以将参数与损失值的变化关系可视化。如下图所示:
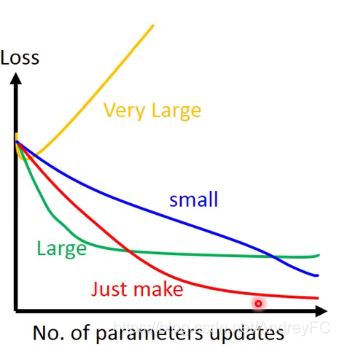
自适应学习率
一开始是随机生成的点,会离最低点比较远,所以学习率会大,后面慢慢靠近了,学习率就要减小。
学习率不能是一个值通用所有特征,不同的参数需要不同的学习率。
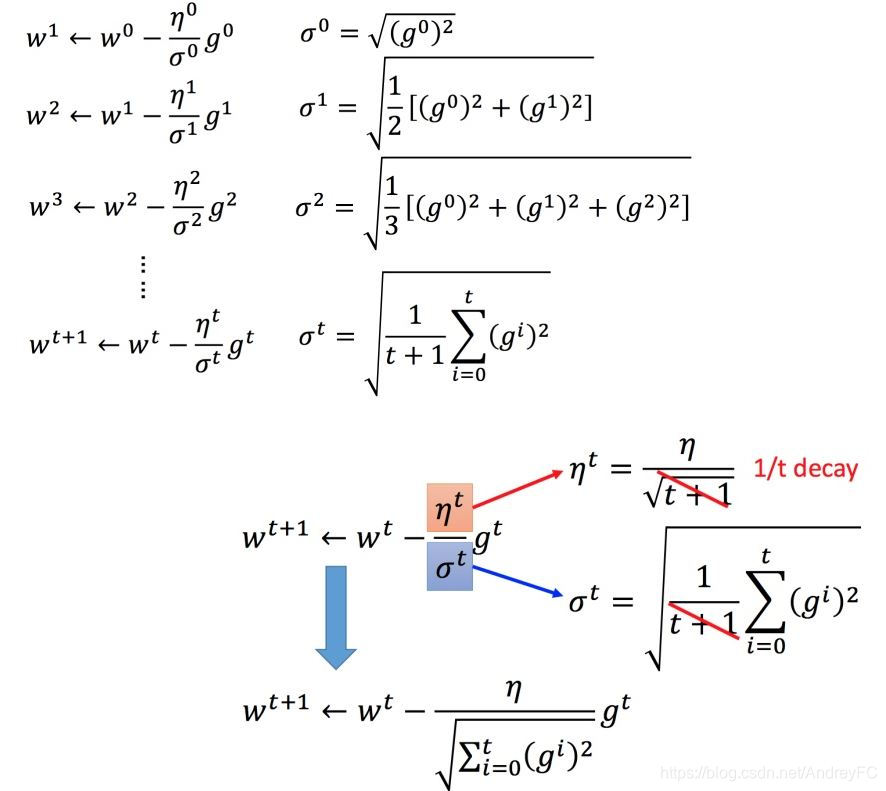
Adagrad 算法
何为Adagrad?即每个参数的学习率都把它除上之前微分的均方根。
此处参考笔记:
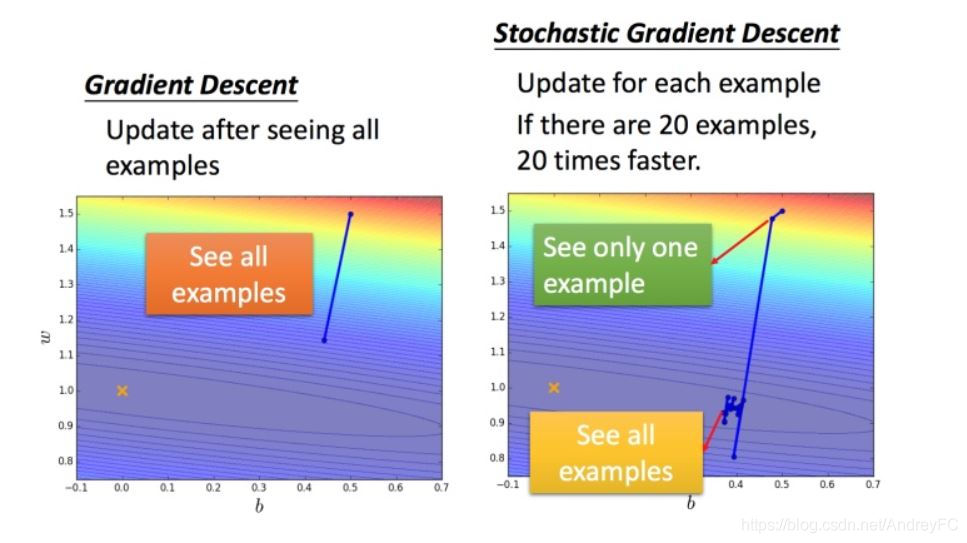
随机梯度下降法
损失函数不需要处理所有数据,只需要计算某一个例子的损失函数,就可以进行梯度更新。
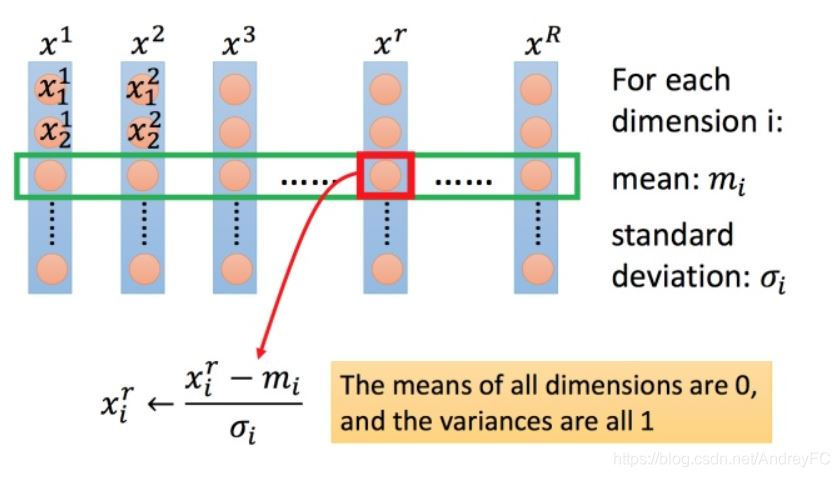
3. 特征缩放
常见的缩放方式