Motivation:
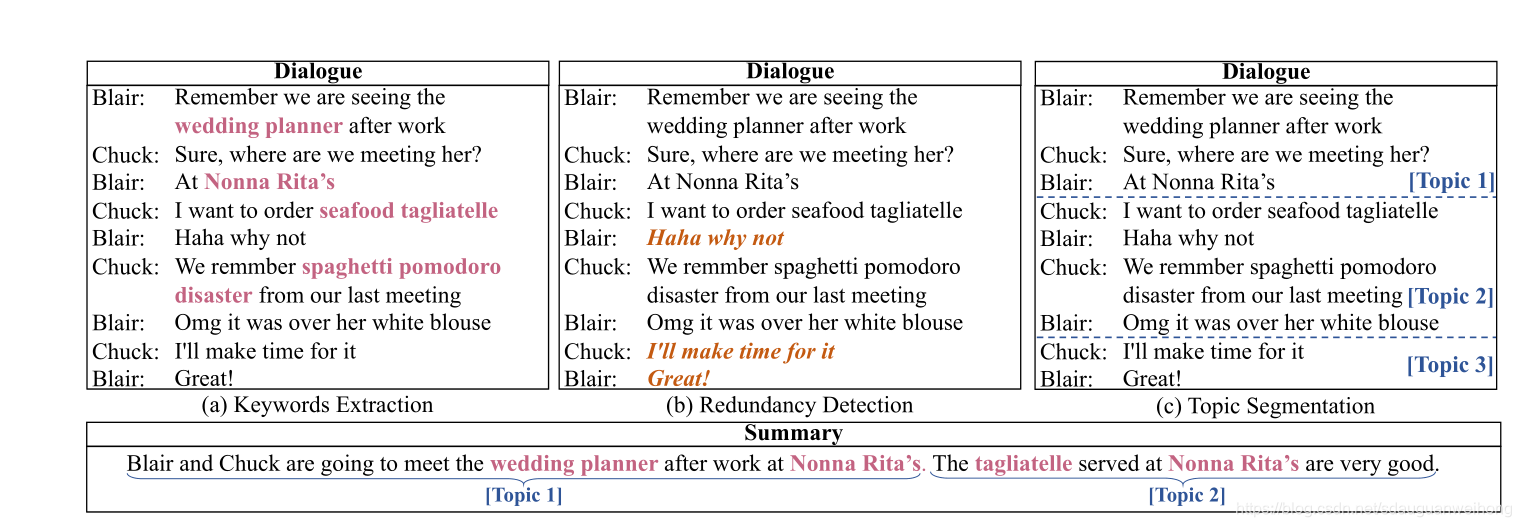
���е�����ʽ�Ի�ժҪ����������Ҫ����һЩ������Ϣ,����key words, dialog act,topic�ȵ�,��������ɵ�ժҪ����Ϣ��,�����,����ժҪ�������ԡ���Щ������Ϣ����������������һЩ��Դ�Ĺ���,��Щ���߿��ܱ�������������ڶԻ���,���ܺܺ���Ӧ�Ի����ص�,������Ҫ�������ֹ���ע�����Ľ�DialogGpt������ල��dialogue annotator,�Զ�������ֱ������,Keywords Extraction,Redundancy
Detection,Topic Segmentation,��ͼ�����������������ʾ��,keywords extraction����ȡ���Ի��еĹؼ���,redundancy detection��Ŀ���Ƿ�����������,Ҳ���Ƕ��ڶԻ���������˼û��̫���ľ���,Topic Segmentation��Ŀ���Ǹ���topic���Ի��ֳ����������ɶΡ���DialoGPT annotator��SAMSUM��AMI���ݼ����б��,Ȼ������BARTģ�ͺ�PGNģ������ժҪ��
Method
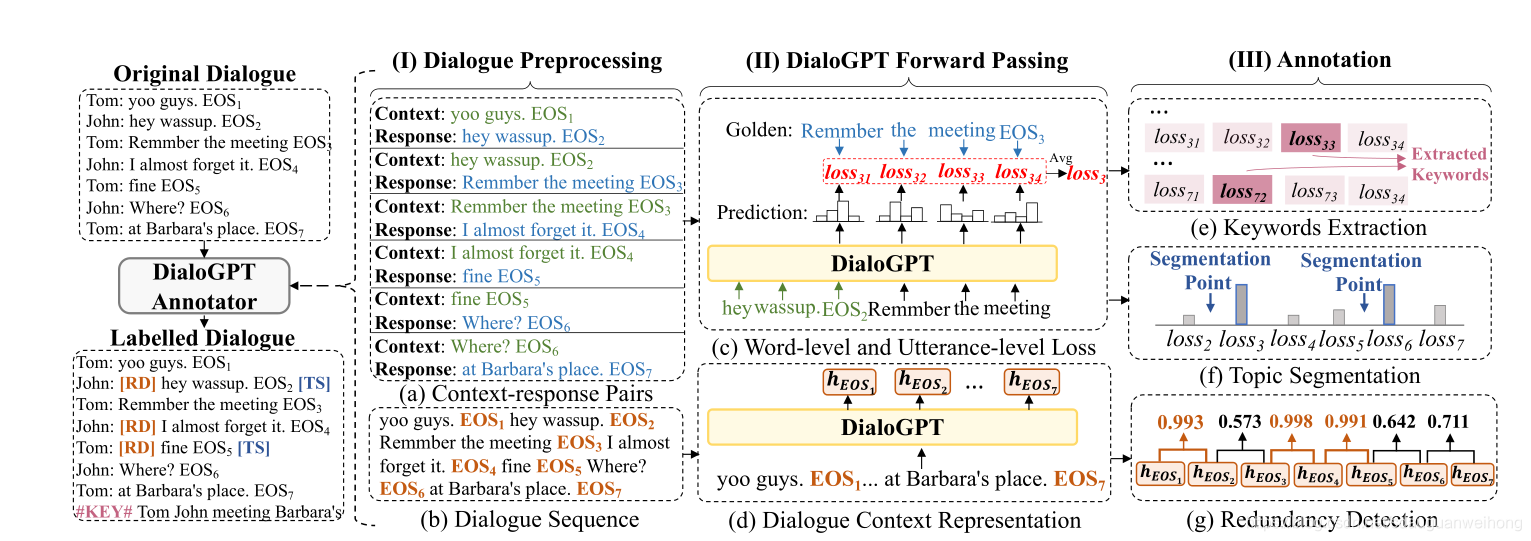
��ͼ������DialoGPT annotator������ܹ�:
Dialogue Preprocessing
���Ƚ���ԭʼ�ĶԻ�����Ԥ����,�õ�������ʽ������,һ����context-response��,��һ����dialogue sequence ,������utteranceƴ����һ��,ʹ��EOS�ָ
DialoGPT Forward Passing
Ȼ��Ԥ������ĶԻ����뵽DialoGPT��,����forward pass������ÿ��context-response,�õ�ÿ��word��loss l o s s i , t loss_{i,t} lossi,t?��ÿ��utterance��loss l o s s t loss_t losst?������ÿ��dialogue sequence,�õ��Ի��������ı�ʾ h E O S 1 , h E O S 2 , h E O S 3 , . . h E O S D = H ( E O S ) h_{EOS1},h_{EOS2},h_{EOS3},..h_{EOSD}=H(EOS) hEOS1?,hEOS2?,hEOS3?,..hEOSD?=H(EOS)
Annotation
����Forward Pass�Ľ������Annotation,������������,Keywords Extraction,Redundancy Detection,Topic Segmentation��
Keywords Extraction
������Ϊkeywords��unpredictable�Ĵʻ�,���golden response�е�һ���ʺ��ѱ�DialoGPTԤ�����,����ʺܿ��ܰ����˸������Ϣ,��˿��Ա���Ϊkey word��
����һ���õ���ÿ��word
u
i
,
j
u_{i,j}
ui,j?��loss
l
o
s
s
i
,
j
loss_{i,j}
lossi,j?,�ӶԻ�����ȡ��loss����
r
k
e
r_{ke}
rke?�����Ĵ���Ϊkey words,ͬʱ�����е�speaker������PҲ����key words��,������һ��������
#
K
E
Y
\#KEY
#KEY,���õ���Ǻ��dialogueΪ
D
K
E
=
[
p
1
,
u
1
,
1
,
��
,
#
K
E
Y
#
,
P
,
Key
?
1
,
K
e
y
2
,
��
?
]
\mathcal{D}_{\mathrm{KE}}=[p_{1}, u_{1,1}, \ldots, \underbrace{\# \mathrm{KEY} \#, \mathbb{P}, \operatorname{Key}_{1}, \mathrm{Key}_{2}, \ldots}]
DKE?=[p1?,u1,1?,��,
#KEY#,P,Key1?,Key2?,��?]
Redundancy Detection
ÿ��
h
E
O
S
i
h_{EOSi}
hEOSi?���Կ����ǶԻ�������
[
u
1
,
u
2...
u
i
]
[u1,u2...u_i]
[u1,u2...ui?]�ı�ʾ,������һ���µ�utterance
u
i
+
1
u_{i+1}
ui+1?,����µ�
h
E
O
S
i
+
1
h_{EOSi+1}
hEOSi+1?��ǰһ��
h
E
O
S
I
h_{EOSI}
hEOSI?����,�Ϳ�����Ϊ
u
i
+
1
u_{i+1}
ui+1?�������ٵ���Ϣ,�Ӷ���
u
i
+
1
u_{i+1}
ui+1?�������ࡣ
����������Ի������ĵı�ʾ
h
E
O
S
�O
D
�O
h_{EOS|D|}
hEOS�OD�O?��
h
E
O
S
�O
D
?
1
�O
h_{EOS|D-1|}
hEOS�OD?1�O?��ʼ,����֮������ƶ�,������ƶȵ÷ֳ���Ԥ�����ֵ,
u
D
u_{D}
uD?����һ������,���û�г�����ֵ,�ͼ�������ǰ�������ӵ����ƶ��ظ���һ����ֱ����ͷ��
��ÿ�������ľ���֮ǰ����һ�������־
[
R
D
]
[RD]
[RD],���õ���Ǻ�ĶԻ�Ϊ
D
R
D
=
[
p
1
,
[
R
D
]
,
u
1
,
1
,
��
,
EOS
?
1
,
��
,
p
�O
D
�O
,
��
,
?EOS?
�O
D
�O
]
D_{RD}=\left[p_{1},[\mathrm{RD}], u_{1,1}, \ldots, \operatorname{EOS}_{1}, \ldots, p_{|\mathcal{D}|}, \ldots, \text { EOS }_{|\mathcal{D}|}\right]
DRD?=[p1?,[RD],u1,1?,��,EOS1?,��,p�OD�O?,��,?EOS?�OD�O?]
Topic Segmentation
DialoGPT�ó�����������һ�µĶԻ�,�������һ��ظ����ѱ�DialoGPTԤ��,����Ϊ���ظ�������һ������,����������һ���ָ���
����һ���õ���ÿ��utterance��loss
l
o
s
s
i
loss_i
lossi?,ѡ��loss����ǰ
r
T
S
r_{TS}
rTS?������utterances��Ϊ����ָ�Ķϵ�,��ÿ��ѡ��ľ���֮ǰ����һ�������־
[
T
S
]
[TS]
[TS],���õ���Ǻ�ĶԻ�Ϊ
D
T
S
=
[
p
1
,
[
T
S
]
,
u
1
,
1
,
��
,
EOS
?
1
,
��
,
p
�O
D
�O
,
��
,
?EOS?
�O
D
�O
]
D_{TS}=\left[p_{1},[\mathrm{TS}], u_{1,1}, \ldots, \operatorname{EOS}_{1}, \ldots, p_{|\mathcal{D}|}, \ldots, \text { EOS }_{|\mathcal{D}|}\right]
DTS?=[p1?,[TS],u1,1?,��,EOS1?,��,p�OD�O?,��,?EOS?�OD�O?]
Summarizer
ʹ��BARTģ�ͺ�pointer-generatorģ���������յ�ժҪ,�ڴ˲���̫����ܡ�