为了熟悉torch的tensor操作和基本函数,我实现了一个卷积的流程。有兴趣的同学可以看看,熟悉下流程和接口。代码如下:
import torch
from torch import nn
import numbers
def cpu_correlation(X, K, s=(1, 1), p=(1, 1)):
"""基于cpu的相关操作"""
kch, kh, kw = K.shape # 卷积核尺寸
ich, ih, iw = X.shape # 输入的通道数,行,列
assert ich == kch
oh = (ih - kh + 2 * p[0]) // s[0] + 1
ow = (iw - kw + 2 * p[1]) // s[1] + 1
Y = torch.zeros((1, oh, ow), dtype=torch.float32)
# pad输入
padded_X = torch.zeros((ich, ih+2*p[0], iw+2*p[1]), dtype=torch.float32)
padded_X[:, p[0]:ih+p[0], p[1]:iw+p[1]] = X[:, :, :]
for i in range(0, oh):
for j in range(0, ow):
Y[0, i, j] = (padded_X[:, i*s[0]:i*s[0]+kh, j*s[1]:j*s[1]+kw] * K).sum()
return Y
class CPUConv2D(nn.Module):
"""
CPU_2D_CONV
"""
def __init__(self, i_ch, o_ch, k, s, p, bias=False):
super(CPUConv2D, self).__init__()
self.k = (k, k) if isinstance(k, numbers.Number) else k
self.s = (s, s) if isinstance(s, numbers.Number) else s
self.p = (p, p) if isinstance(p, numbers.Number) else p
self.o_ch = o_ch
self.weight = nn.ParameterList(
[nn.Parameter(torch.randn(i_ch, self.k[0], self.k[1])) for _ in range(o_ch)]
)
self.bias = bias
if self.bias:
self.bias = nn.Parameter(torch.randn(1))
def test_init(self):
""" 初始化权重,用于测试"""
for i in range(self.o_ch):
nn.init.constant_(conv1.weight[i], 1)
if self.bias:
nn.init.constant_(conv1.bias, 0)
def forward(self, X):
for i in range(self.o_ch):
Y = cpu_correlation(X, self.weight[i], self.s, self.p)
Y = Y + self.bias if self.bias else Y
out = Y if i == 0 else torch.cat((out, Y), 0)
return out
来测试一下流程,看能不能跑通 ;}
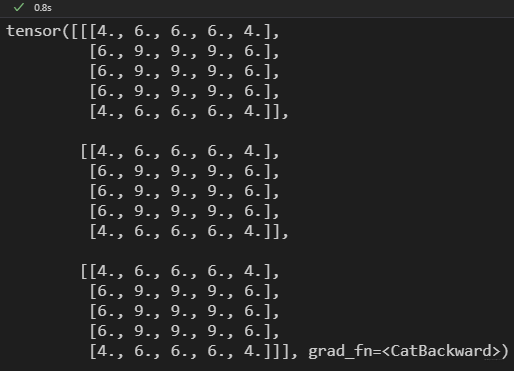
"""测试"""
X = torch.ones((1, 5, 5), dtype=torch.float32)
conv1 = CPUConv2D(i_ch=1, o_ch=3, k=3, s=1, p=1)
conv1.test_init() # 将权重都置为1
Y = conv1(X)
print(Y)
这里,输入特征大小是(1, 5, 5),输出要求3通道,核尺寸为(3, 3), strides两个方向都为1,做same padding,卷积核权重元素都为1。我们可以看到,输出的shape和值是没问题的。
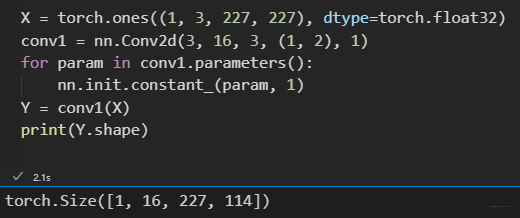
然后,我们测试一下尺寸比较大的输入和输出:
"""测试"""
X = torch.ones((3, 227, 227), dtype=torch.float32)
conv1 = CPUConv2D(i_ch=3, o_ch=16, k=3, s=(1, 2), p=1)
conv1.test_init() # 将权重都置为1
Y = conv1(X)
print(Y.shape)
这次,我们输入是(3, 227, 227), 要求得到16通道的输出; 核尺寸还是(3, 3),这次strides在宽度方向变成了2,依然还是做same padding。 查看输出,结果是没问题的。但是,在我CPU上用了26.9s,很慢哈。
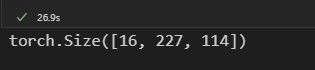
同样的操作,官方实现的cpu版本,只要2.1s: