1.选定网络结构
自定义的网络结构很大程度上决定于数据集的特点。这次字符识别数据集为20*20的3通道图片,是中国汽车牌照图片经过预处理后的字符图片。包含包括数字、字母和汉字在内的65类字符。数据分布差异较大,一般来讲这样会出现数据项较少的类难以正确识别,这里我们先不管数据分布的问题,等网络效果不好时再调整。数据项示例和数据分布如以下两张图。
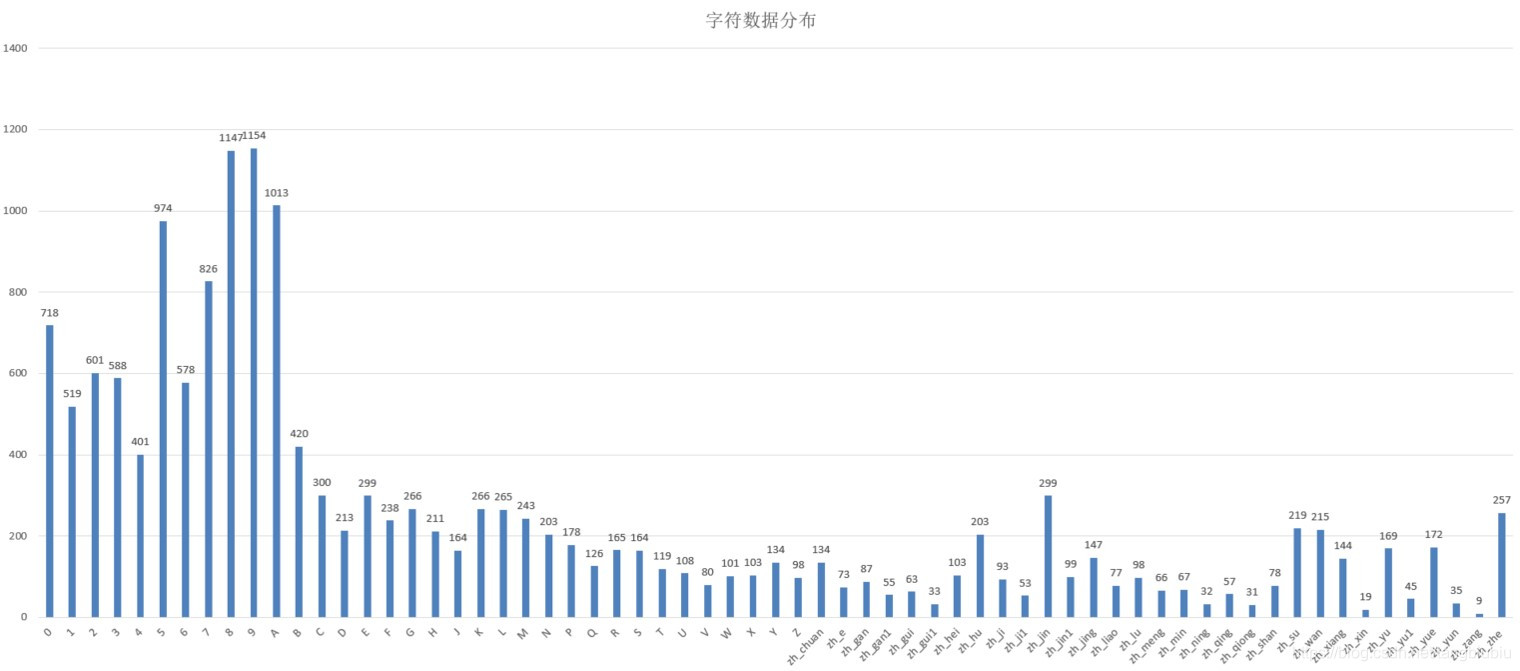
每个数据项信息较少,可使用较为简单的网络。因此定义网络如下:
input -> 3*3卷积 -> BN -> LeakyReLU -> Dropout ->
3*3卷积 -> BN -> LeakyReLU -> Dropout ->
3*3卷积 -> BN -> LeakyReLU -> Dropout ->
Linear(128*10*10, 512) ->
Linear(512, 65) ->
log_softmax
值得注意是的:
- 激活函数使用了LeakyReLU,相比ReLU能够无cost涨点(尽管涨点微乎其微),原因我目前还不太清楚,有知道的小伙伴可以评论区说一下。
- 因为input尺寸比较小,所以在激活函数后没有使用pooling层,防止特征丢失。
- 针对input尺寸小,特征较为简单,参数量过大会引起过拟合的问题,使用Dropout防止过拟合。
为了形象表达,示意图如下。
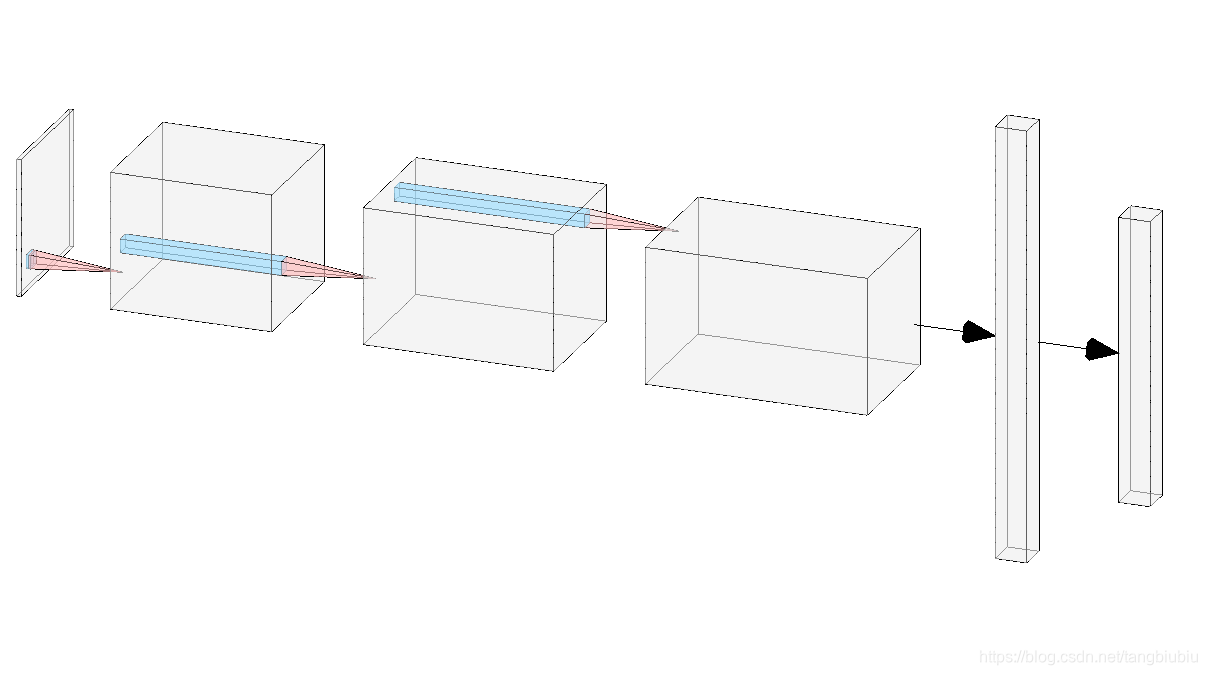
网络代码如下,一些代码上的细节我标注在注释中了:
class Net(nn.Module):
def __init__(self, num_class=65) -> None:
super(Net,self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1, stride=1),
nn.BatchNorm2d(num_features=32),
nn.LeakyReLU(inplace=True), # in-place计算可以节省内(显)存,也节省了申请和释放内存的时间
# nn.MaxPool2d(kernel_size=2,stride=1,padding=1),
nn.Dropout(0.2)
) # out -> (b,32,20,20)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1, stride=1),
nn.BatchNorm2d(num_features=64),
nn.LeakyReLU(inplace=True),
# nn.MaxPool2d(kernel_size=2,stride=1,padding=1),
nn.Dropout(0.2)
) # out -> (b,64,20,20)
self.layer3 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1, stride=2),
nn.BatchNorm2d(num_features=128),
nn.LeakyReLU(inplace=True),
# nn.MaxPool2d(kernel_size=2,stride=1,padding=1),
nn.Dropout(0.2)
) # out -> (b,128,20,20)
self.classifier = nn.Sequential(
nn.Linear(128*10*10, 512),
nn.Linear(512, num_class)
)
def forward(self, x, test=False):
if test: # test部分不是训练用的,主要是为了输出特征图来进行分析。
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = x3.view(x3.size(0), -1)
x4 = self.classifier(x4)
x4 = F.log_softmax(x4,dim=1)
return x1,x2,x3,x4
else:
self.features = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
)
x = self.features(x)
x = x.view(x.shape[0], -1) # 注意这里要调整tensor的维度
x = self.classifier(x)
return F.log_softmax(x,dim=1) # 较新版本的torch不给dim赋值会warming,但是也能work。
其中在forward的test部分主要是为了输出特征图。特征图示例如下(原图像为字符‘W’):、


 可以看到有些特征图是几乎全白的,应该是dropout冻结了一些神经元的造成的。
可以看到有些特征图是几乎全白的,应该是dropout冻结了一些神经元的造成的。
2. 定义数据集和训练过程
这里需要定义两个DataLoader,一个训练集,另一个测试集。训练和测试过程老生常谈。
值得一说的是优化器我只试过SGD,开始使用了网上大佬们推荐的参数:lr=0.01 momentum=0.9,久久难以收敛。后来经过不断调参(瞎试),后来才确定了效果较好的参数:lr=0.001 momentum=0.8. 但是不知道这样有什么道理,有知道的大佬可以在评论区指教一下。
直接放代码:
# 定义训练集
train_dataset = LoadData(txt_path='ORCmodel/train_ORC.txt', train=True)
train_loader = dataloader.DataLoader(
dataset=train_dataset,
batch_size=4,
shuffle=True,
num_workers=4,
pin_memory=True # pin_memory是锁页内存,内存充足时可以增加读取速度,内存不足时等于False即可。(有兴趣可以了解一下锁页内存)
)
# 定义测试集
test_dataset = LoadData(txt_path='ORCmodel/test_ORC.txt', train=False)
test_loader = dataloader.DataLoader(
dataset=test_dataset,
batch_size=4,
shuffle=True, # 写博客时才发现,测试数据没必要设置为True
num_workers=4,
pin_memory=True
)
# 定义训练过程
def train(model, device, train_data, optimizer, epoch):
for idx, (data, target) in enumerate(train_data):
data, target = data.to(device), target.to(device)
pred = model(data)
loss = F.nll_loss(pred, target) # 因为前面用的是log_softmax,所以这里用nll_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx % 100 == 0 :
print(f'Epoch:{epoch} Interation: {idx}, Loss: {loss.item()}')
# 定义测试过程
def test(model, device, test_data):
total_loss = 0.
correct = 0.
with torch.no_grad():
for idx, (data, target) in enumerate(test_loader):
data, target = data.to(device), target.to(device)
output = model(data)
total_loss += F.nll_loss(output, target, reduction='mean').item()
pred = output.argmax(dim = 1)
correct += pred.eq(target.view_as(pred)).sum().item()
total_loss /= len(test_data.dataset)
acc = correct / len(test_data.dataset)
print(f'Test Loss: {total_loss} Accuracy: {acc:.2%}')
return total_loss
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Net().to(device)
momentum = 0.8
lr = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr = lr, momentum = momentum)
num_epoch = 50
if __name__ == "__main__":
for epoch in range(num_epoch):
train(model, device, train_loader, optimizer, epoch)
lo = test(model, device, test_loader)
torch.save(model.state_dict(), f'ORCmodel/log/Epoch {epoch} total_loss {lo}.pt')
3. 测试结果
总的准确率为:total_acc= 0.9693809088136627。接近96.94%的准确率还是比较满意的。
上文所说的类别间不平衡导致的准确率较低的问题也没有出现,所以不再进行调整。各类别准确率如下图:
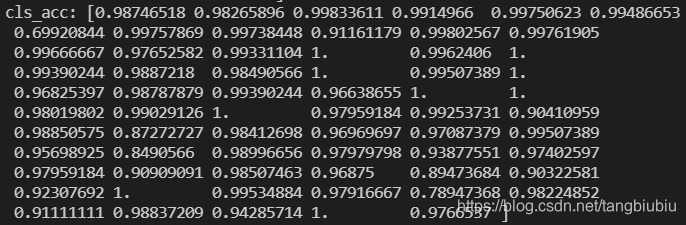
单张检测的效果也算是满意:
