主要看模型方法
Abstract
提出一个串行多层多头注意力针对neural speaker embedding,之前是将一帧的特征聚集起来进行表示。我们提出利用堆叠式的self-attention机制的分层架构获得更精细的特征。串行注意力机制包含一堆self-attention模块,多层堆叠可以学出更多有区别的embedding。
1 Introduction
略
2 Attention in Neural Speaker Embedding
Neural speaker embeddings是使用DNNs提取的语音话语的固定维表示,x-vector使用最广泛。在x-vector中,temporal aggregation用于将frame-level features转换为单个固定维度向量。全连接层用于将话语级别特征映射到说话人特征。但是某些frames对于辨别说话者是更独特、更重要的相比于其他帧。(It is believed that),不是给每一帧分配相同的权重,而是经常应用注意力机制。
2.1 Statistics pooling
设 h t h_t ht?是frame processor network的输出的向量,通过statistics pooling,计算 h t h_t ht?沿着时间轴的均值和方差
μ = 1 T ∑ t = 1 T h t \mu = \frac 1 T \sum _{t=1} ^{T} h_t μ=T1?t=1∑T?ht?
σ = 1 T ∑ t = 1 T h t ? h t ? μ ? μ \sigma = \frac 1 T \sqrt{\sum _{t=1}^{T}h_t\cdot ht -\mu \cdot \mu} σ=T1?t=1∑T?ht??ht?μ?μ?
. . .表示每个元素乘法,element-wise multiplication
2.2 Attentive statistics pooling
2.3 self-attentive pooling
3 Serialized Multi-head Attention
介绍所提出的串行多层多头注意力机制。由三个主要的stage组成:a frame-level feature processor, a serialized attention mechanism, and a speaker classifier。
frame-level feature processor: 使用TDNN提取高级特征。
图1的中间部分,一个序列化的注意机制被用来将可变长度的特征序列聚合成一个固定维度的表示。
图1的顶部是前馈分类层。类似于xvector,整个网络被训练成将输入序列分类成说话者类别。

3.1 Serialized attention
serialiuzed attention机制由N个相同的层堆叠而成,每层由两个堆叠一起的模块组成,self-attention module和feed forward module。每个模块周围使用residual connection。在两个模块之前使用归一化。
我们建议使用堆叠的self-attention,以串行的方式将信息从一层聚合并传播到下一层,而不是并行的multi-head attention。
最初的multi-head attention,输入序列被分成几个称为头的同质子向量。然而,更深的架构增加了特征表达能力,可以在不同级别学习和聚合更多的特征。本文提出的serialized attention mechanism中,self-attention以串行的方式执行,允许模型从更深的层中聚合具有时间上下文的信息。
3.2 Input-aware self-attention
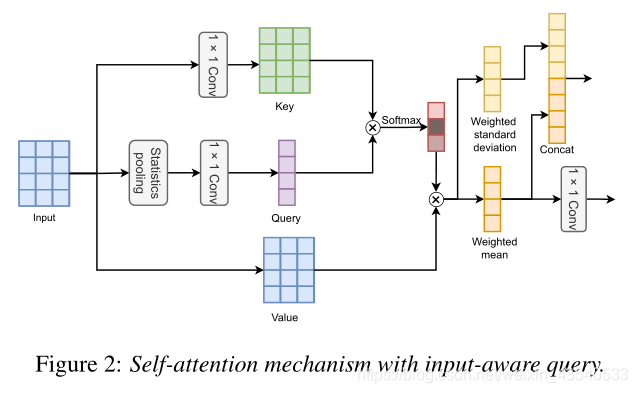
考虑到均值和标准差能捕捉整个话语的信息和语音动态,我们使用statistics pooling
输入序列 [ h 1 , h 2 , . . . , h T ] [h_1, h_2,...,h_T] [h1?,h2?,...,hT?] 用 h t ∈ R d h_t \in R^d ht?∈Rd , T T T是输入sequence的长度,q的获取
q = W q g ( h t ) q= W_qg(h_t) q=Wq?g(ht?)
g ( . ) g(.) g(.)是2.1节中说明的statistics pooling,用来计算 [ μ , σ ] [\mu ,\sigma] [μ,σ],
k t = W k h t k_t=W_kh_t kt?=Wk?ht?
3.3 Serialized multi-head embedding
feed-forward module:包括两个线性变换,中间一个R二LU激活
F F W ( h ) = W 2 f ( W 1 h + b 1 ) + b 2 FFW(h)=W_2f(W_1h+b_1)+b_2 FFW(h)=W2?f(W1?h+b1?)+b2?
串行注意力机制的embedding被送入一个全连接层和一个标准softmax层,使用交叉熵损失进行反向传播。
4.Experiment
略