一、简述
针对YOLOV5小目标识别部分做了算法改进:
1.修改了MODEL,增加了小目标检测层
2.修改了detect.py,增加了分割检测模块,以时间换准确度。
代码已上传到GITHUB:
https://github.com/Hongyu-Yue/yoloV5_modify_smalltarget
思路主要参考引用了两个文章,如下:
修改检测层
http://www.qishunwang.net/news_show_12005.aspx
修改detect.py
https://zhuanlan.zhihu.com/p/172121380
二、MODEL修改
主要修改了检测层和检测框
# parameters
nc: 1 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [5,6, 8,14, 15,11] #4
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]], #160*160
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]], #80*80
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]], #40*40
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9 20*20
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]], #20*20
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #40*40
[[-1, 6], 1, Concat, [1]], # cat backbone P4 40*40
[-1, 3, BottleneckCSP, [512, False]], # 13 40*40
[-1, 1, Conv, [512, 1, 1]], #40*40
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3 80*80
[-1, 3, BottleneckCSP, [512, False]], # 17 (P3/8-small) 80*80
[-1, 1, Conv, [256, 1, 1]], #18 80*80
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #19 160*160
[[-1, 2], 1, Concat, [1]], #20 cat backbone p2 160*160
[-1, 3, BottleneckCSP, [256, False]], #21 160*160
[-1, 1, Conv, [256, 3, 2]], #22 80*80
[[-1, 18], 1, Concat, [1]], #23 80*80
[-1, 3, BottleneckCSP, [256, False]], #24 80*80
[-1, 1, Conv, [256, 3, 2]], #25 40*40
[[-1, 14], 1, Concat, [1]], # 26 cat head P4 40*40
[-1, 3, BottleneckCSP, [512, False]], # 27 (P4/16-medium) 40*40
[-1, 1, Conv, [512, 3, 2]], #28 20*20
[[-1, 10], 1, Concat, [1]], #29 cat head P5 #20*20
[-1, 3, BottleneckCSP, [1024, False]], # 30 (P5/32-large) 20*20
[[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(p2, P3, P4, P5)
]
增加了一个检测框,这个感觉意义不大,YOLO本身也有自适应框。
主要是参考上面网页中的方式,为小目标检测专门的增加了几个特征提取层:
在第17层后,继续对特征图进行上采样等处理,使得特征图继续扩大,同时在第20层时,将获取到的大小为160X160的特征图与骨干网络中第2层特征图进行concat融合,以此获取更大的特征图进行小目标检测。
原文提到在增加检测层后,带来的问题就是计算量增加,导致推理检测速度降低。不过对于小目标,确实有很好的改善。
不过实测来看对计算量增加的比较有限,效果有些许改善,还算值得。
三、代码修改
主要针对了detect.py做了修改,增加了图像切割层。
主要思路就是在目标分辨率太大的情况下,将目标图像分解为数个图像送入YOLOV5网络中做检测,再回收所有图像,计算坐标的相对值,集体来一次NMS。
引用作者原文如下:
小目标检测效果不好主要原因为小目标尺寸问题。
以网络的输入608608为例,yolov5中下采样使用了5次,因此最后的特征图大小是1919,3838,7676。
三个特征图中,最大的7676负责检测小目标,而对应到608608上,每格特征图的感受野是608/76=8*8大小。
即如果原始图像中目标的宽或高小于8像素,网络很难学习到目标的特征信息。
另外很多图像分辨率很大,如果简单的进行下采样,下采样的倍数太大,容易丢失数据信息。但是倍数太小,网络前向传播需要在内存中保存大量的特征图,极大耗尽GPU资源,很容易发生显存爆炸,无法正常的训练及推理。
这种情况可以使用分割的方式,将大图先分割成小图,再对每个小图检测,可以看出中间区域很多的汽车都被检测出来:不过这样方式有优点也有缺点: 优点:准确性 分割后的小图,再输入目标检测网络中,对于最小目标像素的下限会大大降低。
比如分割成608608大小,送入输入图像大小608608的网络中,按照上面的计算方式,原始图片上,长宽大于8个像素的小目标都可以学习到特征。
缺点:增加计算量 比如原本19201080的图像,如果使用直接大图检测的方式,一次即可检测完。
但采用分割的方式,切分成4张912608大小的图像,再进行N次检测,会大大增加检测时间。
分割并分别检测的代码功能块如下所示,
全部代码见github:
mulpicplus = "3" #1 for normal,2 for 4pic plus,3 for 9pic plus and so on
assert(int(mulpicplus)>=1)
if mulpicplus == "1":
pred = model(img,
augment=augment,
visualize=increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False)[0]
else:
xsz = img.shape[2]
ysz = img.shape[3]
mulpicplus = int(mulpicplus)
x_smalloccur = int(xsz / mulpicplus * 1.2)
y_smalloccur = int(ysz / mulpicplus * 1.2)
for i in range(mulpicplus):
x_startpoint = int(i * (xsz / mulpicplus))
for j in range(mulpicplus):
y_startpoint = int(j * (ysz / mulpicplus))
x_real = min(x_startpoint + x_smalloccur, xsz)
y_real = min(y_startpoint + y_smalloccur, ysz)
if (x_real - x_startpoint) % 64 != 0:
x_real = x_real - (x_real-x_startpoint) % 64
if (y_real - y_startpoint) % 64 != 0:
y_real = y_real - (y_real - y_startpoint) % 64
dicsrc = img[:, :, x_startpoint:x_real,
y_startpoint:y_real]
pred_temp = model(dicsrc,
augment=augment,
visualize=increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False)[0]
pred_temp[..., 0] = pred_temp[..., 0] + y_startpoint
pred_temp[..., 1] = pred_temp[..., 1] + x_startpoint
if i==0 and j == 0:
pred = pred_temp
else:
pred = torch.cat([pred, pred_temp], dim=1)
# Apply NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
四、运行结果
修改前:
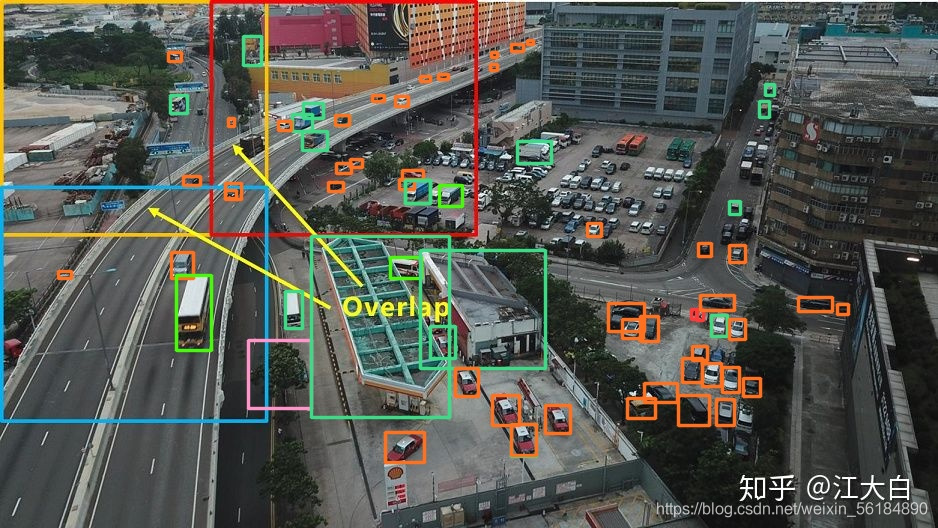

修改后:
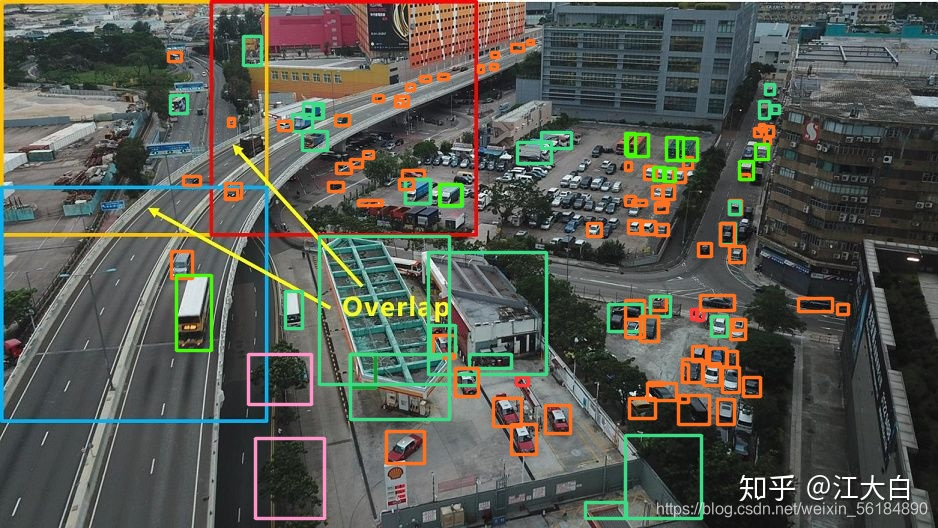

效果还是非常明显的,我这个DEMO图是将原图分成了3*3个子图,送到修改后的MODEL中去做的检测,在算力足够的情况下,确实可以有效改善小目标检测的效果。
算力不够怎么办?
建议可以使用更小的YOLO网络,并且将分成33改为分成22,可以测试一下,看看效果和直接使用大网络比哪个好。