一、引言
GoogleNet是2014年分类任务与检测任务的冠军得主。设计的初衷是为了提高在网络里面的计算资源的利用率。
该网络权衡了算法效率即精确率和内存占用。
众所周知,获得高质量模型最保险的做法是:增加模型深度(层数)或宽度(层核或神经元个数),但一般情况下,更深或更宽的网络会出现:
- 参数过多,易过拟合;若训练集有限,这个问题更突出
- 网络越大,计算复杂度越大,难以应用
- 网络越深,越容易梯度消失,难以优化模型
GoogleNet网络关键点:
- 保证算力的情况下加大深度与宽度
- 宽度:利用Inception结构同时执行多个网络结构
- 深度:利用辅助分类器防止梯度消失
- 多尺度训练和预测
二、Inception结构
首要需要解决的问题是参数问题:
- 参数越多―>计算压力更大―>需要的计算资源多
- 参数越多―>模型越大―>越容易过拟合
- 模型越大―>所需训练数据越多―>但高质量的数据很宝贵
GoogleNet认为根本方法是将全连接层甚至一般卷积都转化为稀疏连接。传统的网络使用了随机稀疏连接,而计算机软硬件对非均匀稀疏数据的计算效率很低。基于保持神经网络结构的稀疏性,又能充分利用密集矩阵的高性能出发点,依据将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,GoogleNet给出两个解决方案:
- 深度方面,22层,2个辅助分类器避免梯度消失。
- 采用Inception结构,这是一个网中网结构。
提出Inception结构,降低参数量:
- 用全局平均池化层代替全连接层(VGG90%的参数量来自全连接层)
- 使用大量1×1卷积核
Inception结构如下图所示,左图是原始版本,右图是降维版本:

1.原始版本
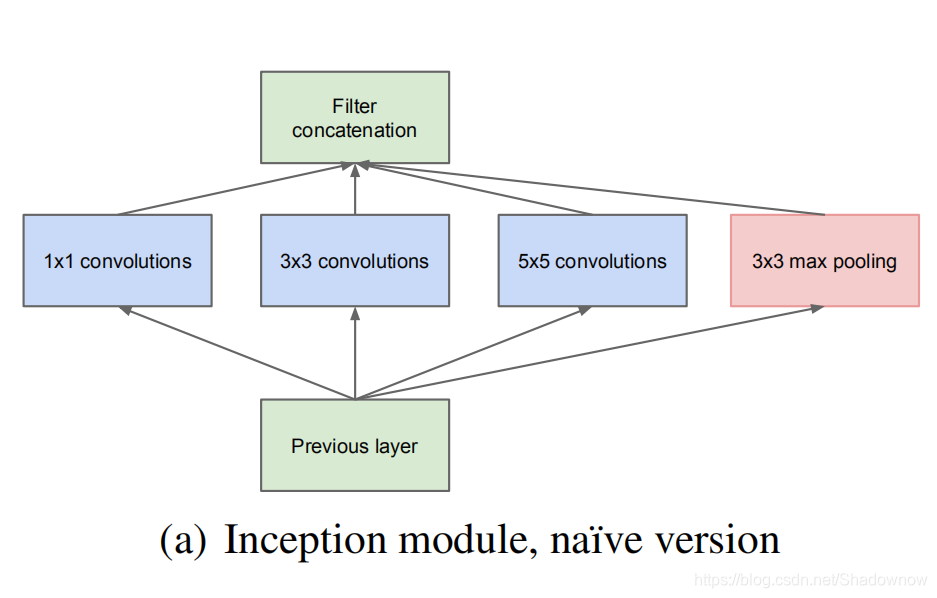
原始版本就是将上一层的输出作为输入,分别进行3个不同大小的卷积和1个最大池化,将四个输出拼接在一起作为整体的输出。
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同长宽的特征,然后这些特征就可以直接拼接在一起了;
- 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
但这个原始版本会有缺点:
- pooling分支的输出和输入维度完全相同,拼接之后会导致输出的维度越来越大;
- 上一个问题会导致后面3×3、5×5的计算量很大(因为输入维度很大的话,这两个卷积的卷积参数量会很大)
所以延伸出了降维结构。
2.降维版本

降维版本就是在原始版本的基础上,在3×3卷积、5×5卷积前面加了1×1卷积降维,在最大池化后进行降维,则可弥补原始版本的缺陷。好处如下:
- 在3×3、5×5之前加1×1降维,使维度变得可控,减少后面的计算量(即使被降维成低维度也可以包含大量的信息)
- 加入1×1后的ReLU激活函数可以增强网络的非线性表达能力
- 此结构可以提取多尺度特征(因为卷积核的尺度不一样)
- 比没有Inception结构的网络快2~3倍(因为提高了计算性能)
3.两个版本参数比较
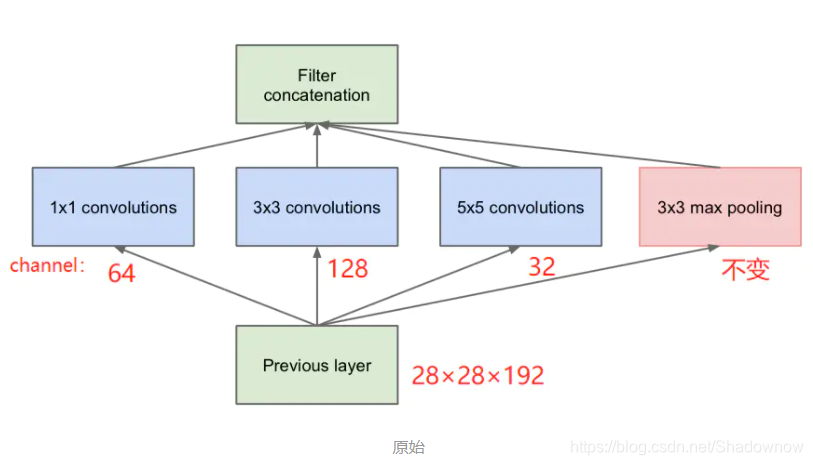
假设输入28×28×192:
- 1×1卷积:pad=0,stride=1,输出28×28×64;
- 3×3卷积:pad=1,stride=1,输出28×28×128;
- 5×5卷积:pad=2,stride=1,输出28×28×32;
- 3×3最大池化:pad=1,stride=1,输出28×28×192;
- 堆叠一起后:28×28×(64+128+32+192)=28×28×416。
参数量:
1×1×192×64+3×3×192×128+5×5×192×32=153600
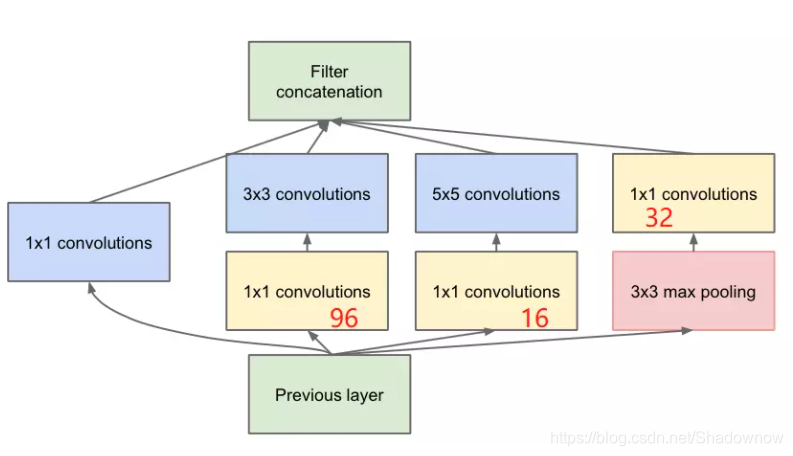
输入28×28×192:
- 1×1卷积:pad=0,stride=1,输出28×28×64;
- 1×1卷积+3×3卷积:pad=1,stride=1,输出28×28×128;
- 1×1卷积+5×5卷积:pad=2,stride=1,输出28×28×32;
- 3×3最大池化+1×1卷积:pad=1,stride=1,输出28×28×32;
- 堆叠一起后:28×28×(64+128+32+32)=28×28×256。
参数量:
1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32)+1×1×192×32=163328
虽然参数量在这一层结构有少量的提升,但是可以大大降低后面层的参数量,因此整体参数是下降的。
4. 1×1卷积的作用
- 用于降维,以打破计算瓶颈,否则网络规模受限,因此既可以加深又可以加宽,而不造成明显的性能下降。
- 1×1卷积层后的激活函式可以增加网络的非线性表达能力
三、GoogleNet网络结构
如下图与下表所示,GoogleNet总共具有22层,9个inception mudule。
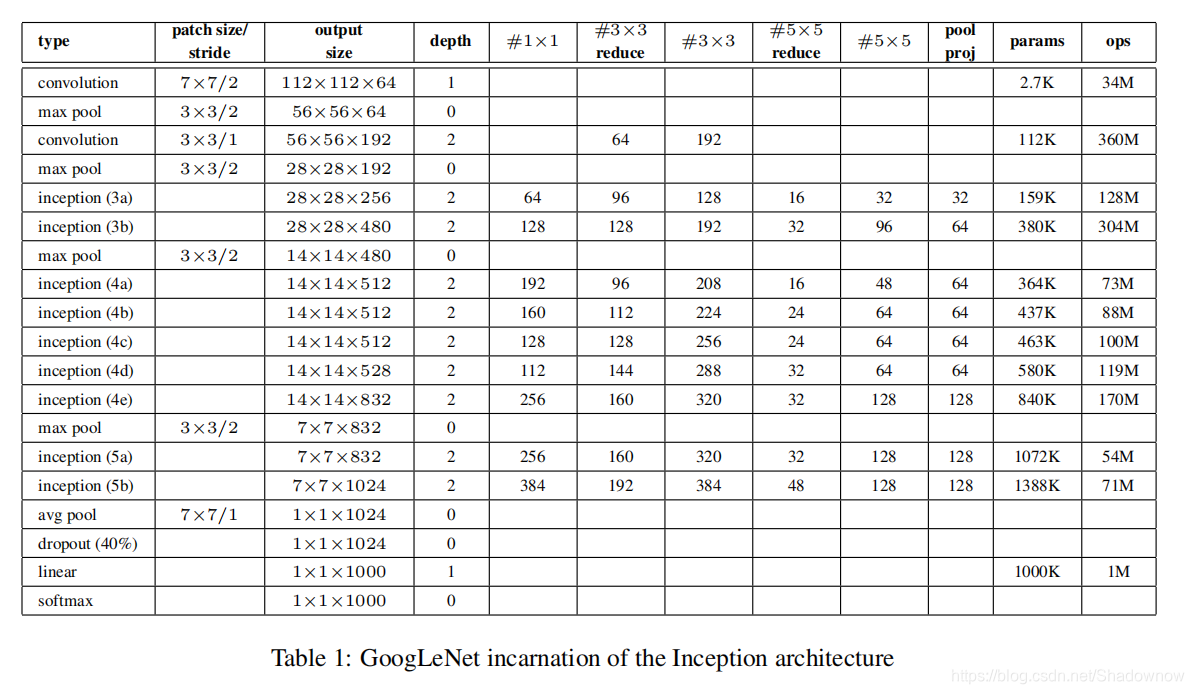
1.前几层
在最开始的几层没为什么没有使用inception结构是因为:
最开始的输入特征映射尺度通常很大,使用单独的卷积层和池化层能降低特征映射大小,减少参数,防止过拟合。
2.辅助分类器
在4(a)和4(d)的输出,添加了两个辅助分类器。
这些分类器采用较小的卷积网络形式,训练过程中,他们的偏差以0.3的权重加到总偏差中。在预测过程中无用。

目的:
- 增加低层网络的分类能力
- 防止梯度消失
- 增加正则化
四、总结
- 采用不同大小的卷积核,意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合
- 卷积核大小1,3,5,设定stride=1,pad=0,1,2。则可以得到相同维度的特征,拼接在一起。
- 许多文章表明池化有效,因此结构中也嵌入了pooling
- 网络越往后,特征越抽象,而且每个特征所涉及的感受野更大,因此随着层数的增加,3×3、5×5的比例也要增加
- 使用1×1卷积进行降维,减少计算量,增加非线性表达能力。