Knowledge distillation from multi-modal to mono-modal segmentation networks
从多模态分割网络到单模态分割网络的知识提取
MICCAI 2020
论文:https://arxiv.org/abs/2106.09564
??近年来,多种成像方式联合应用于医学图像分割得到了广泛的研究。在几个应用中,相对于单模态分割,从不同模式的信息融合已经证明了提高分割精度。然而,由于医生和扫描仪数量有限,以及成本和扫描时间有限,在临床环境中获取多种模式通常是不可能的。大多数情况下,只获得一种形态。在本文中,作者提出了KD-Net,一个将知识从一个多模态网络(教师)转移到一个单模态网络(学生)的框架。该方法是对广义精馏框架的改进,其中学生网络是在教师输入(n种模式)的一个子集(1种模式)上进行训练的。作者使用BraTS 2018数据集演示了所提出的框架在脑瘤分割中的有效性。使用不同的结构,表明学生网络有效地学习教师,并始终优于基线单模态网络在分割精度方面。
问题动机、思路来源:
??采用多种方式对医学图像进行自动分割已成为多种应用的普遍做法,如脑肿瘤分割或缺血性中风病变分割。**由于不同的图像模态可以更好地强调和描述不同的组织,它们的融合可以提高分割的精度。**尽管多模态模型通常能得到最好的结果,但由于医生和扫描仪数量有限,以及成本和扫描时间有限,在临床环境中通常很难获得多种模态。在许多情况下,特别是对于有病理或紧急情况的病人,只有一种方式是获得的。
??文献中提出了两种主要的策略来处理在训练时多种模式可用,但在推理时其中一些或大部分都缺失的问题。一是训练生成模型综合缺失模态,然后进行多模态分割。在[Why Does Synthesized Data Improve Multi-sequence Classification?]中,作者已经表明,使用合成模态有助于提高脑肿瘤分类的准确性。Ben Cohen等从CT扫描中生成PET图像,以减少肝脏恶性病变检测中的假阳性数。生成一个合成的模态也被证明可以提高白质低点分割的质量。这种策略的主要缺点是它在计算上很麻烦,特别是当许多模式都缺失的时候。实际上,除了多模态分割网络之外,还需要对每个缺失的模态训练一个生成网络。
?? 第二种策略包括学习一个模态不变特征空间,该空间在训练期间编码多模态信息,并在推理过程中允许所有可能的模态组合。在第二种策略中,Havaei等人提出了HeMIS[HeMIS: Hetero-Modal Image Segmentation]模型,该模型针对每个模态训练不同的特征提取器。然后,特征图的前两个矩被计算和连接在潜在空间,从其中一个解码器被训练来预测分割地图。Dorent等人[Hetero-Modal Variational Encoder-Decoder for Joint Modality Completion and Segmentation]受到HeMIS的启发,提出了U-HVED,通过在每个降采样步骤之前考虑中间层作为特征图,引入跳跃连接。该网络在BraTS 2018数据集上的表现优于HeMIS。在[Robust Multimodal Brain Tumor Segmentation via Feature Disentanglement and Gated Fusion.]中,作者没有通过计算平均值和方差来融合图层,而是学习了一个映射函数,从多个特征映射到潜在空间。他们声称,计算矩来融合地图是不令人满意的,因为它使每个模态对最终结果的贡献相等,这与每个模态突出不同区域的事实是不一致的。在BraTS 2015数据集上得到了比HeMIS更好的结果。只有当一种或两种模态缺失时,第二种策略才会有好的结果,然而,当只有一种模态可用时,它的结果比训练于这种特定模态的模型更差。因此,这种方法不适用于通常只能获得一种治疗方式的临床环境,如术前神经外科手术或放射治疗。
成果:
?? 与以往的方法相比,本文提出了一个将知识从多模态网络转移到单模态网络的框架。该方法基于广义知识精馏,是精馏和特权信息的结合。蒸馏最初被设计用于分类问题,使一个小网络(学生)从一个网络集合中学习,或从一个大网络(教师)学习。在[Structured Knowledge Distillation for Semantic Segmentation, Improving Fast Segmentation With Teacher-student Learning]中,它被应用于图像分割,其中教师网络和学生网络使用了相同的输入模式。在[15]中,学生向老师学习只是通过他们的输出之间的一个损失项。作者还限制了学生的中间层与教师的中间层相似。从不同的角度来看,特权信息框架旨在通过从训练数据和拥有特权和附加信息的教师模型中学习来提高学生模型的性能。在广义知识精馏中,从[Unifying distillation and privileged information]老师的特权信息中提取有用的知识。在作者的例子中,教师和学生拥有相同的架构(即相同数量的参数),但是教师可以从多个输入模式(附加信息)中学习,而学生只能从一个输入模式中学习。提出的框架是基于两个编码器-解码器网络,已证明在图像分割[nnunet]工作良好,一个为学生和一个为教师。重要的是,该框架是通用的,因为它适用于不同的编码器-解码器网络体系结构。每个编码器都将其输入空间总结为一个潜在的表示,以捕获分割的重要信息。由于教师和学生处理不同的输入,但目的是提取相同的信息,我们假设他们的第一层应该是不同的,而最后一层,特别是潜在表示(即瓶颈)应该是相似的。通过迫使学生的潜在空间模仿教师的潜在空间,我们假设学生应该从教师的附加信息中学习。据我们所知,这是第一次采用广义知识精馏策略来指导单模态学生网络和多模态教师网络的学习。使用BraTS 2018数据集展示了该方法对脑瘤分割的有效性。
主要方法:
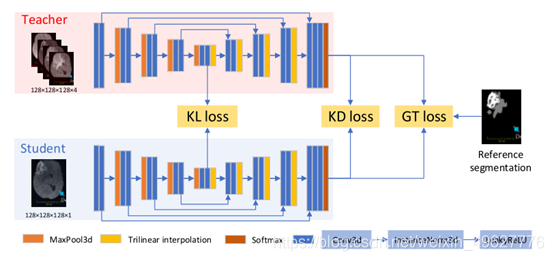
??图1、拟议框架的说明。老师和学生都有相同的架构改编自nnUNet[7]。首先,使用参考分割(GT损失)对Teacher进行训练。然后,使用所有建议的损失:KL损失、KD损失和GT损失对学生网络进行训练。
KD-Net:
?? 该框架的目标是利用来自训练有素的多模态分割网络(Teacher)的知识来训练单模态分割网络(Student)。除了输入通道的数量外,两个网络具有相同的编码器-解码器结构和跳过连接。多模态输入 是数据集的的N种模式的连接。让Et和 Dt(Es和Ed)表示“老师”的编码器和解码器部分。教师网络 接受作为输入的多种模态,而学生网络 只有一种模态 是1和N之间的固定整数。
?? 首先训练Teacher,只使用参考分割作为目标。然后,作者使用三种不同的损失训练学生:知识蒸馏术语,潜在空间之间的不相似性,参考分割损失。请注意,在训练学生期间,教师的权重是固定的,学生的错误不会反向传播到教师。
?? 前两个术语允许学生通过使用后者的软预测作为目标,并通过迫使学生的编码信息(即瓶颈)与教师的相似来向教师学习。最后一项使得Student的预测分割类似于参考分割。
2.1广义知识精馏
?? 采用广义知识精馏[Unifying distillation and privileged information]策略,利用教师的软标签目标,将教师附加信息中的有用知识传递给学生。计算方法如下:
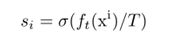
知识蒸馏损失定义为:

2.2潜在的空间:
??作者推测,“老师”和“学生”的输入不同,应该也会对第一层的信息进行不同的编码,这些信息与较低层次的图像属性有关,比如颜色、纹理和边缘。相比之下,更接近瓶颈并与更高级别属性相关的最深层应该更加相似。此外,作者假设一个编解码器网络对信息进行编码,以正确分割输入图像在其潜在空间。基于此,作者建议通过使潜在的表示尽可能接近,迫使学生从瓶颈(部分在最深层)中编码的教师的附加信息中学习。为此,作者将Kullback-Leibler (KL)散度作为教师和学生瓶颈之间的损失函数:
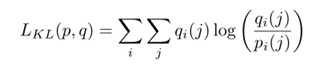
??注意,这个函数不是对称的,我们按这个顺序排列向量,因为我们希望学生瓶颈的分布与老师瓶颈的分布相似。
2.3目标函数:
??作者在目标函数中加入第三项,使预测的分割尽可能接近参考分割。它是dice损失(Dice)和二进制交叉熵(BCE)的总和,原因与第2.1节相同。作者称之为LGT:
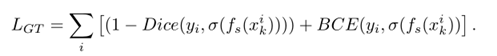
则完全目标函数为:
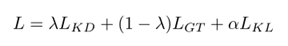
??λ∈[0,1]和α∈R+。模拟参数λ平衡了参考分割和教师软标签的影响。λ值越大,教师软标签的影响越大。相反,需要α参数来平衡KL损耗与其他两种损耗的大小。
3、结果与讨论:
3.1数据集:
?? 作者在BraTS 2018挑战赛的公开可用数据集上评估了拟议框架的性能。它包含了285名患者的四种方式的MR扫描:T1, T2, T1对比增强(T1ce)和Flair。挑战的目标是分割脑肿瘤的三个亚区域:整个肿瘤(WT),肿瘤核心(TC)和增强肿瘤(ET)。我们采用128 × 128 × 128的中心裁剪,并沿每个轴进行随机翻转以增强数据。对于每个模态,只有非零体素通过减去平均值和除以标准差被归一化。由于存储和时间的限制,对图像进行子采样,大小为64 × 64 × 64。
3.2实现细节:
?? 作者采用图1中描述的编码器-解码器体系结构。实验发现,目标函数的最佳参数为λ = 0.75, T = 5和α = 10。我们对500个epoch使用Adam优化器,学习率等于0.0001,当验证损失在50个epoch内没有减少时,学习率乘以0.2。对2018年BraTS的285个训练案例进行了三重交叉验证。在NVIDIA P100 GPU上,基线、教师或学生的培训大约需要12小时。
3.3结果:
?? 在作者的实验中,教师使用所有四种模式(T1, T2, T1ce和Flair连接),而学生只使用T1ce。作者为学生选择T1ce,因为这是术前神经外科或放射治疗中使用的标准模式。
?? **模型比较:**为了演示所提议的框架的有效性,作者首先将其与基线模型进行比较。它的架构与图1中的编码器-解码器网络相同,并且只使用T1ce模式作为输入进行训练。作者还将其与仅使用T1ce作为输入的U-HVED和HeMIS模型进行了比较。结果如表1所示。作者的方法比U-HVED和HeMIS对所有三个肿瘤成分的分割效果更好。KD-Net似乎也比[Robust Multimodal Brain Tumor Segmentation via Feature Disentanglement and Gated Fusion]中提出的方法获得了更好的结果(同样是仅使用T1ce作为输入时)。作者展示了BraTS 2015数据集的结果,因此它们不能直接与KD-Net进行比较。此外,作者无法在网上找到他们的代码。然而,HeMIS对BraTS 2015的结果表明,对BraTS 2018的观察似乎更难以分割。提出的方法在似乎更容易分割的数据集上比我们的结果更糟糕,因此BraTS 2018数据集也应该如此。
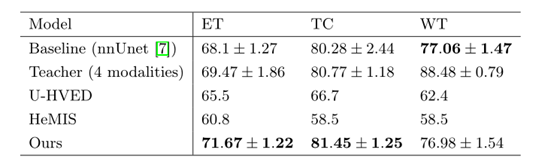
??表1:3种模型在肿瘤区域使用骰子评分进行比较。U-HVED和HeMIS的结果取自文章,文中未提供标准偏差。
消融实验:
??为了评估每个损失项的贡献,作者通过从方程5中定义的目标函数中移除每个项来进行消融术研究。
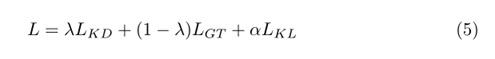
??表2显示了在Student和Teacher网络中使用0或4个跳过连接的结果。作者观察到,与基线模型相比,KL和KD损失都改善了结果,特别是对于增强的肿瘤和肿瘤核心。这也说明了所提出的框架是通用的,它适用于不同的编码器-解码器架构。更多的结果可以在补充材料中找到。
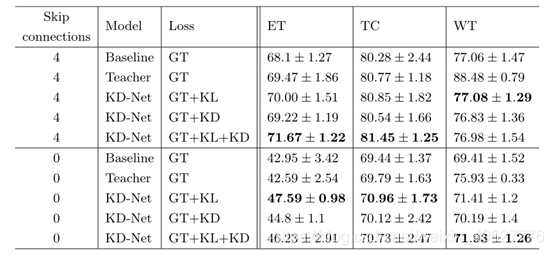
??**表2:**损失项的消融实验。
??作者比较了使用3种不同目标函数训练的模型的结果:仅使用GT损失的基线,仅使用KL项训练的KDNet和完全目标函数训练的KD-Net。还对Student和Teacher进行了0或4个跳过连接的测试。
??**定性结果:**在图2中,作者展示了提出的框架的一些定性结果,并将它们与使用基线方法获得的结果进行比较。可以看到,建议的框架允许学生丢弃一些异常值,并预测更高质量的分割标签。在实验中,学生只使用T1ce作为输入,这清楚地突出了增强的肿瘤。值得注意的是,学生似乎在这个区域学习得更多(见图2和表1)。从老师那里提取的知识似乎帮助学生在应该“更强”的地方学习得更多。更多的定性结果可以在补充材料中找到。
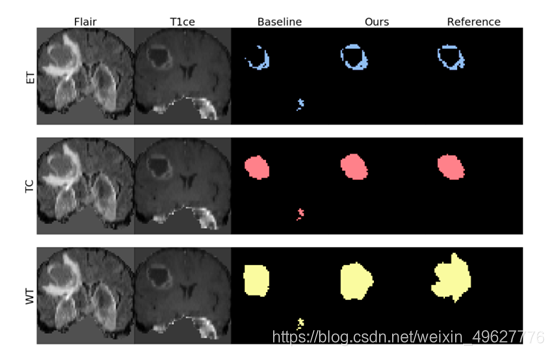
??**图2所示:**使用基线和拟议框架获得的定性结果(学生)。作者用相应的3个分割标签显示一个主题的切片。
??**观察:**值得注意的是,作者还试图扩大Student网络,首先从T1ce合成另一种模态,如Flair,然后将其与T1ce一起用于分割肿瘤标记。结果实际上比基线差,计算时间相当令人望而却步。作者还尝试在网络的最深处,在教师和学生之间分享权重,以帮助知识的传递。它背后的直觉是,由于瓶颈应该是相同的,所以最深层的信息应该被相同地处理。结果与图1中所示的建议框架获得的结果几乎相同,但稍差。在本文中,作者使用nnnet作为学生和教师的网络,但理论上任何其他的编解码器架构。
总结:
?? 提出了一个新的框架,将知识从多模态分割网络转移到单模态分割网络。为此目的,作者建议采用双重方法。作者采用了广义知识精馏的策略,此外,作者还限制了学生的潜在表示与教师的潜在表示相似。作者验证了脑肿瘤分割方法,在Brats 2018上仅使用T1ce时,取得了比最先进的方法更好的结果。该框架具有通用性,适用于任何编解码器分割网络。在分割精度和鲁棒性方面的增益由提出的框架产生的错误,使其在现实世界的临床场景中,只有一个模态在测试时间是非常有价值的。