����Ŀ¼
������ά
��ά�����ַ�ʽ
����ѡ��
1 ����
�����а���������ر���(������������ԡ�ָ���),ּ�ڴ�ԭ���������ҳ���Ҫ������
2 ����
Filter(����ʽ):��Ҫ̽�����������ص㡢������������Ŀ��ֵ֮�����
???? �� ����ѡ��:�ͷ�����������
?? ? �����ϵ��
Embedded (Ƕ��ʽ):�㷨�Զ�ѡ������(������Ŀ��ֵ֮��Ĺ���)
????? �پ�����:��Ϣ�ء���Ϣ����
? ? ? ������:L1��L2
? ? ? ��?���ѧϰ:������
???2.1����ʽ
??????2.1.1 �ͷ�����������
???????????????ɾ���ͷ����һЩ����,ǰ�潲����������塣�ٽ�Ϸ���Ĵ�С�����������ʽ�ĽǶȡ�
???????? ? ? ?��������С:ij���������������ֵ�Ƚ����
?????? ? ? ? ?���������:ij�������ܶ�������ֵ���в��
????2.1.1.1API
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
ɾ�����еͷ�������
Variance.fit_transform(X)
X:numpy array��ʽ������[n_samples,n_features]
����ֵ:ѵ�����������threshold����������ɾ����Ĭ��ֵ�DZ������з��㷽������,��ɾ�����������о�����ֵͬ��������
����:
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
# �����а���������ر���(������������ԡ�ָ���),
# ּ�ڴ�ԭ���������ҳ���Ҫ������
# sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
# ɾ�����еͷ�������
# Variance.fit_transform(X)
# X:numpy array��ʽ������[n_samples,n_features]
# ����ֵ:ѵ�����������threshold����������ɾ����Ĭ��
# ֵ�DZ������з��㷽������,��ɾ�����������о�����ֵͬ
# ��������
#���˵���������
#1��ȡ����
data=pd.read_csv("factor_returns.csv")
data=data.iloc[:,1:-2]
# print(data.info())
#2ʵ����һ��ת������
transfer=VarianceThreshold(threshold=3)
#3����
data_new=transfer.fit_transform(data)
#4չʾ,��ά����.shape ����״
print("data_new:\n",data_new,data_new.shape)
# (2318, 8) 2318��8��
2.1.2���ϵ��
Ƥ��ѷ���ϵ��(Pearson Correlation Coefficient)
��ӳ����֮����ع�ϵ���г̶ȵ�ͳ��ָ��
from scipy.stats import pearsonr
import pandas as pd
# ���ϵ����ֵ���ڨC1��+1֮��,���C1�� r ��+1������������:
# ��r>0ʱ,��ʾ�����������,r<0ʱ,������Ϊ�����
# ��|r|=1ʱ,��ʾ������Ϊ��ȫ���,��r=0ʱ,��ʾ����
# ��������ع�ϵ
# ��0<|r|<1ʱ,��ʾ����������һ���̶ȵ���ء���|r|Խ
# �ӽ�1,�����������Թ�ϵԽ
# ����;|r|Խ�ӽ���0,��ʾ���������������Խ��
# һ��ɰ���������:|r|<0.4Ϊ�Ͷ����;0.4��|r|<0.7Ϊ
# ���������;0.7��|r|<1Ϊ�߶��������
# from scipy.stats import pearsonr
# x : (N,) array_like
# y : (N,) array_like Returns: (Pearson��s correlation coefficient, p-value)
#����ij��������֮������ϵ��
data=pd.read_csv("factor_returns.csv")
data=data.iloc[:,1:-2]
r=pearsonr(data["pe_ratio"],data["pb_ratio"])
print("���ϵ��:\n",r)
r2=pearsonr(data["revenue"],data["total_expense"])
print("revenue��total_expense�������",r2)
# scipy.stats.pearsonr(x, y)
# x��yΪ��ͬ���ȵ���������
# ����ֵ r, p-value
# r�����ϵ��,ȡֵ-1~1. ��ʾ������س̶�
# p-valueԽС,��ʾ��س̶�Խ�����������ĵ���˵��
# ��The p-values are not entirely reliable but
# are probably reasonable for datasets larger
# than 500 or so.��,
# p-value��500������ֵ�����нϸߵĿɿ���

���ɷַ���(��������һ��������ȡ�ķ�ʽ)
ʲô�����ɷַ���(PCA)?
����:��ά����ת��Ϊ��ά���ݵĹ���,�ڴ˹����п��ܻ�����ԭ�����ݡ������µı���
����:������ά��ѹ��,�����ܽ���ԭ���ݵ�ά��(���Ӷ�),��ʧ������Ϣ��
Ӧ��:�ع�������߾����������
from sklearn.decomposition import PCA
# sklearn.decomposition.PCA(n_components=None)
# �����ݷֽ�Ϊ�ϵ�ά���ռ�
# n_components:
# С��:��ʾ�����ٷ�֮���ٵ���Ϣ
# ����:���ٵ���������
# PCA.fit_transform(X) X:numpy array��ʽ������[n_samples,n_features]
# ����ֵ:ת����ָ��ά�ȵ�array
#PCA��ά
#1.��ȡ����
data=[[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
#2.ʵ����һ��ת������
transfer=PCA(n_components=2)
#3.����
data_new=transfer.fit_transform(data)
#4.չʾ
print("data_new:\n",data_new)


import pandas as pd
from sklearn.decomposition import PCA
import numpy as np
# order_products__prior.csv:��������Ʒ��Ϣ
# �ֶ�:order_id, product_id, add_to_cart_order, reordered
# products.csv:��Ʒ��Ϣ
# �ֶ�:product_id, product_name, aisle_id, department_id
# orders.csv:�û��Ķ�����Ϣ
# �ֶ�:order_id,user_id,eval_set,order_number,��.
# aisles.csv:��Ʒ����������Ʒ���
# �ֶ�: aisle_id, aisle
#1.��ȡ����
order_products=pd.read_csv("./order_products__prior.csv")
products=pd.read_csv("./products.csv")
orders=pd.read_csv("./orders.csv")
aisles=pd.read_csv("./aisles.csv")
#2.�ϲ���
tabel1=pd.merge(aisles,products,on="aisle_id")
tabel2=pd.merge(tabel1,order_products,on="product_id")
tabel3=pd.merge(tabel2,orders,on="order_id")
# print(tabel3.info())
#��user_id��aisle_id���ý��������һ��
tabel=pd.crosstab(tabel3["user_id"],tabel3["aisle_id"],margins=False)
print(tabel)
#PCA��ά
transfer=PCA(n_components=0.95)
data_new=transfer.fit_transform(tabel)
print(data_new.shape)
ת������Ԥ����
һ��ת����
���ǰ��������̵Ľӿڳ�֮Ϊת����,����ת������������ô������ʽ
fit_transform
fit
transform
# ת���� - �������̵ĸ���
# 1.ʵ����(ʵ��������һ��ת������)
# 2.����fit_transform(�����ĵ����������Ƶ����,����
# ͬʱ����)
# ����:
# (x-mean) / std
# fit_transform()
# fit() ����ÿһ�е�ƽ��ֵ������
# transform() (x-mean) / std�������յ�ת��
������(sklearn����ѧϰ�㷨��ʵ��)
��sklearn��,������(estimator)��һ����Ҫ�Ľ�ɫ,��һ��ʵ�����㷨��API
1�����ڷ���Ĺ�����:
sklearn.neighbors k-�����㷨
sklearn.naive_bayes ��Ҷ˹
sklearn.linear_model.LogisticRegression ���ع�
sklearn.tree �����������ɭ��
2�����ڻع�Ĺ�����:
sklearn.linear_model.LinearRegression ���Իع�
sklearn.linear_model.Ridge ��ع�
3�������ලѧϰ�Ĺ�����
sklearn.cluster.KMeans ����
K-�����㷨
1.1 ����
���һ�������������ռ��е�k��������(�������ռ������ڽ�)�������еĴ��������ijһ�����,�������Ҳ����������
��Դ:KNN�㷨��������Cover��Hart�����һ�ַ����㷨
1.2 ���빫ʽ
���������ľ������ͨ�����¹�ʽ����,�ֽ�ŷʽ����
K-�����㷨API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
n_neighbors:int,��ѡ(Ĭ��= 5),k_neighbors��ѯĬ��ʹ�õ��ھ���
algorithm:{��auto��,��ball_tree��,��kd_tree��,��brute��},��ѡ���ڼ�������ھӵ��㷨:��ball_tree������ʹ�� BallTree,��kd_tree����ʹ�� KDTree����auto�������Ը��ݴ��ݸ�fit������ֵ����������ʵ��㷨�� (��ͬʵ�ַ�ʽӰ��Ч��)
����:Ԥ��ǩ��λ��
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
# train.csv,test.csv
# row_id:�Ǽ��¼���ID,���ر�ĺ���,�������
# xy:����
# accuracy:��λȷ��
# time:ʱ���
# place_id:ҵ���ID,������Ԥ���Ŀ��,ǩ����
#1.��ȡ����
from sklearn.preprocessing import StandardScaler
data=pd.read_csv("./train.csv")
#2.���ݴ���
#��С���ݷ�Χ query("")
data=data.query("x<2.5 & x>2 & y<1.5 & y>1.0")
#����ʱ���,pd.to_datetime()ת��Ϊ������ʱ���� unit="s"��������λ
time_value=pd.to_datetime(data["time"],unit="s")
#DatetimeIndex()���ж��ʱ���������
date=pd.DatetimeIndex(time_value)
print(date)
#������
data["day"]=date.day#����
data["weekday"]=date.weekday#���ڼ�
data["hour"]=date.hour#Сʱ
#����ǩ�������ٵĵص�
#����"place_id"����,����ͬ��place_id�鵽һ��ȥ,
# Ȼ������м���
place_count=data.groupby("place_id").count()["row_id"]#ȡ"row_id"��һ��
print(place_count)
place_count=place_count[place_count>3]#ȡplacce_id��������place_id,��ǩ����������εĵط�
#place_count ��Series���͵�,����index��"place_id",����isin����ӵ���index
data_final=data[data["place_id"].isin(place_count.index)]
print(data_final)
#ɸѡ����ֵ��Ŀ��ֵ
x=data_final[["x","y","accuracy","day","weekday","hour"]]
y=data_final["place_id"]
#���ݼ�����
x_train,x_test,y_train,y_test=train_test_split(x,y)
#����
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#KNN������
estimator=KNeighborsClassifier()
param_dict={"n_neighbors":[1,3,5,7,9,11]}
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=10)
estimator.fit(x_train,y_train)
#ģ������
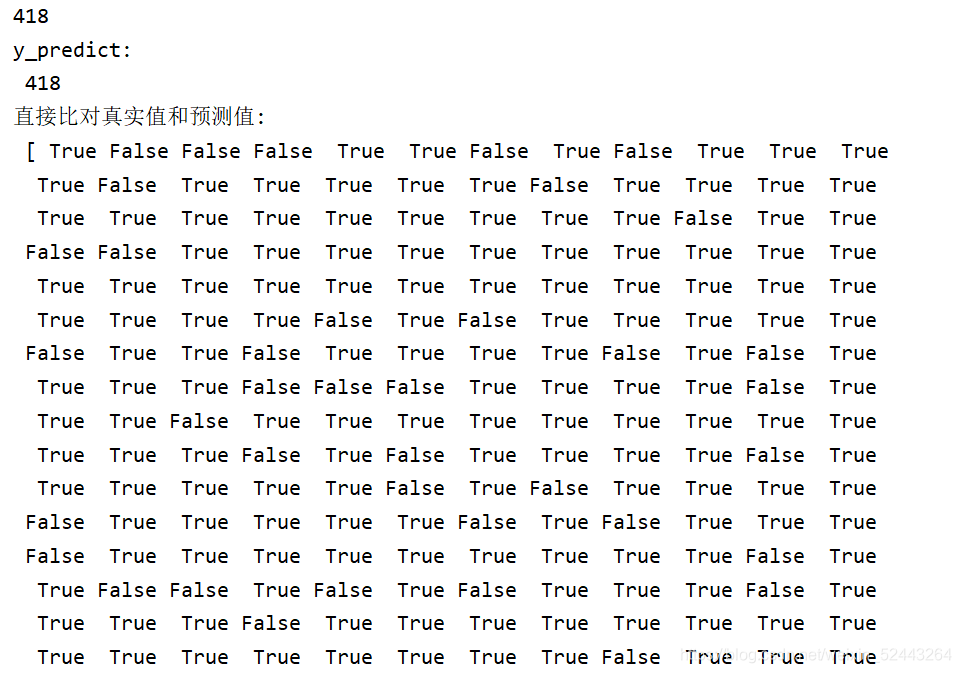
#����1:ֱ�ӱȶ���ʵֵ��Ԥ��ֵ
y_predict=estimator.predict(x_test)
print("y_predict\n",y_predict)
print("ֱ�ӱȶ���ʵֵ��Ԥ��ֵ:\n",y_test==y_predict)
#������
score=estimator.score(x_test,y_test)
print("ȷ��Ϊ:\n",score)
"""
DataFrame.isin(self, values)
DataFrame�е�ÿ��Ԫ���Ƿ������ֵ�С�
����:values:iterable, Series, DataFrame��dict
������б�ǩ��ƥ��,��������ij��λ��Ϊtrue��
���values��Series,�Ǿ���������
��� values��һ��dict,��������DZ���ƥ���������
���ֵ��DataFrame,��������ǩ���б�ǩ������ƥ�䡣
����ֵ:DataFrame
"""
#print(place_count[place_count>3].values)
# print(date.index)
ģ��ѡ�������
API
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
�Թ�������ָ������ֵ�����꾡����
estimator:����������
param_grid:����������(dict){��n_neighbors��:[1,3,5]}
cv:ָ�����۽�����֤
fit:����ѵ������
score:ȷ��
�������:
bestscore:�ڽ�����֤����֤����ý��_
bestestimator:��õIJ���ģ��
cvresults:ÿ�ν�����֤�����֤��ȷ�ʽ����ѵ����ȷ�ʽ��
����:�β��ģ�͵���
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# iris������������iris.data,iris.target��
# data��һ������,ÿһ�д�������Ƭ��ij���,
# һ��4��,ÿһ�д���ij�����������βֲ��,һ��
# ������150����¼��
# target��һ������,�洢��data��ÿ����¼������һ���
# βֲ��,��������ij�����150,����Ԫ�ص�ֵ��Ϊ����3
# ���βֲ��,���Բ�ֵֻͬ��3��������Ϊɽ�β����ɫ�
# ���������
#1.��ȡ���ݼ�
iris=load_iris()
#2.���ݼ��Ļ���
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=66)
#3.��������:����
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)#��x_trainһ����ƽ��ֵ�ͷ������ת��
#4.KNN�㷨Ԥ����
estimator=KNeighborsClassifier()
#�������������ͽ�����֤
#������
param_dict={"n_neighbors":[1,3,5,7,9,11]}
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=10)
estimator.fit(x_train,y_train)
#5.ģ������
#����1:ֱ�ӱȶ���ʵֵ��Ԥ��ֵ
y_predict=estimator.predict(x_test)
print("y_predict\n",y_predict)
print("ֱ�ӱȶ���ʵֵ��Ԥ��ֵ:\n",y_test==y_predict)
#������
score=estimator.score(x_test,y_test)
print("ȷ��Ϊ:\n",score)
#��Ѳ���:best_params_
print("��Ѳ���\n" , estimator.best_params_)
#��ѽ��:best_score_
print("��ѽ��:\n",estimator.best_score_)
#��ѹ�����
print("��ѹ�����:\n",estimator.best_estimator_)
#������֤���:cv_results_
print("������֤���:\n", estimator.cv_results_)
# print(x_train.shape)
# print(x_test.shape)
# print(y_train.shape)
# print(y_test.shape)
# print(iris)

���ر�Ҷ˹�㷨
API
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
���ر�Ҷ˹����
alpha:������˹ƽ��ϵ��
from sklearn.datasets import fetch_20newsgroups
# ���ϸ���:�����������,����������ͬʱ�����ĸ���
# ����:P(A,B)
# ����:P(A, B) = P(A)P(B)
# ��������:�����¼�A������һ���¼�B�Ѿ����������µ�
# ��������
# ����:P(A|B)
# ����:P(A1,A2|B) = P(A1|B)P(A2|B)
# ע��:���������ʵij���,������A1,A2������Ľ��
# (����)
#�����:���P(A,B)=P(A)P(B),����¼�A���¼�B
# �����,����������ij�Ҫ����
#����:���Ǽ�������������֮�������
# ���ر�Ҷ˹�㷨:
# ���� + ��Ҷ˹
# Ӧ�ó���:
# �ı�����
# ����������
# ������˹ƽ��ϵ��
# sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
# ���ر�Ҷ˹����
# alpha:������˹ƽ��ϵ��
#��ȡ����
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
news=fetch_20newsgroups(subset="all")
#�������ݼ�
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target)
#��������
transfer=TfidfVectorizer()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#���ر�Ҷ˹�㷨Ԥ����������
estimator=MultinomialNB(alpha = 1.0)
estimator.fit(x_train,y_train)#����ѵ������
#ģ������
#����1:ֱ�ӱȶ���ʵֵ��Ԥ��ֵ
y_predict=estimator.predict(x_test)
print("y_predict\n",y_predict)
print("ֱ�ӱȶ���ʵֵ��Ԥ��ֵ:\n",y_test==y_predict)
#������
score=estimator.score(x_test,y_test)
print("ȷ��Ϊ:\n",score)
# �ŵ�:
# ���ر�Ҷ˹ģ�ͷ�Դ�ڹŵ���ѧ����,���ȶ��ķ���Ч�ʡ�
# ��ȱʧ���ݲ�̫����,�㷨Ҳ�Ƚϼ�,�������ı����ࡣ
# ����ȷ�ȸ�,�ٶȿ�
# ȱ��:
# ����ʹ�����������Զ����Եļ���,����������������й���ʱ��Ч������
# data_home : str, default=None
# Specify a download and cache folder for the datasets. If None,
# all scikit-learn data is stored in '~/scikit_learn_data' subfolders.
#alpha��Ĭ��ֵ��1
# sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
# ���ر�Ҷ˹����
# alpha:������˹ƽ��ϵ��
�������㷨
������API
class sklearn.tree.DecisionTreeClassifier(criterion=��gini��, max_depth=None,random_state=None)
������������
criterion:Ĭ���ǡ�gini��ϵ��,Ҳ����ѡ����Ϣ������ء�entropy��
max_depth:������ȴ�С
random_state:���������
���л���Щ������:max_depth:������ȴ�С
�������������ǻ������ɭ�ֽ���
�þ��������β�����з���
from pandas.core.common import random_state
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier,export_graphviz
import graphviz
#��Ϊ��sklearn���ݼ�,�Ѿ������˺ܺõ����ݴ�����,���ԾͲ�����Ϊ�Ľ������ݴ���
#�������㷨���ü������,���ԾͲ��ö����ݽ��б���
#1.��ȡ���ݼ�
iris=load_iris()
#2.�������ݼ�
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target)
#3.������Ԥ���� criterion:Ĭ���ǡ�gini��ϵ��,Ҳ����ѡ����Ϣ������ء�entropy��
#max_depth:������ȴ�С,������Ϊ��������Ȳ������,����û��Ҫ����,Ĭ�Ͼͺ�
estimator=DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train,y_train)#��������,����ѵ��,�ó�ģ��
#4.���������ӻ� feature_names:��������,irir���������
export_graphviz(estimator,out_file='iris_tree.dot',feature_names=iris.feature_names)
#��ȡ������ͼƬ
with open("iris_tree.dot") as f:
dot_graph=f.read()
graphviz.Source(dot_graph)
#5.ģ������
#����1:ֱ�ӱȶ���ʵֵ��Ԥ��ֵ
y_predict=estimator.predict(x_test)
print("y_predict\n",y_predict)
print("ֱ�ӱȶ���ʵֵ��Ԥ��ֵ:\n",y_test==y_predict)
#������
score=estimator.score(x_test,y_test)
print("ȷ��Ϊ:\n",score)

����:̩̹��˺ų˿�����Ԥ��
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
#1.��ȡ����
from sklearn.tree import DecisionTreeClassifier, export_graphviz
train=pd.read_csv("train(1).csv")
test=pd.read_csv("test.csv")
y_test=pd.read_csv("gender_submission.csv")
y_test=list(y_test['Survived'])#���Լ���Ŀ��ֵ,Ҫת��Ϊ�б�
print(len(y_test))
#2.���ݴ���
#(1)����ȱʧ����
#Age�еĿ�ֵ����ƽ�����������
train['Age'].fillna(train['Age'].mean(),inplace=True)
#Embarked�еĿ�ֵ���õ�½�ۿ��������
train["Embarked"].fillna("S",inplace=True)
#cabin�е�����ȱʧ̫����,�Ͳ������
#Age�еĿ�ֵ����ƽ�����������
test['Age'].fillna(test['Age'].mean(),inplace=True)
#Embarked�еĿ�ֵ���õ�½�ۿ��������
test["Embarked"].fillna("S",inplace=True)
#3.����ѡ��,ѡ��Է������йؼ����õ�����
features=['Pclass','Sex','Age']
train_features=train[features]#ѵ����������ֵ
train_target=train['Survived']#ѵ������Ŀ��ֵ
test_features=test[features]#���Լ�������ֵ
#������ֵת��Ϊ�ֵ�
train_features=train_features.to_dict(orient ='records')
test_features=test_features.to_dict(orient ='records')
#�ֵ�������ȡ
# ʵ����һ��ת������
transfer = DictVectorizer(sparse=False)
#����
x_train=transfer.fit_transform(train_features)#�ֵ�������ȡת��
x_test=transfer.transform(test_features)
#������
estimator=DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train,train_target)#��������,����ѵ��,�ó�ģ��
#5.ģ������
#����1:ֱ�ӱȶ���ʵֵ��Ԥ��ֵ
y_predict=estimator.predict(x_test)
print("y_predict:\n",len(y_predict))
print("ֱ�ӱȶ���ʵֵ��Ԥ��ֵ:\n",y_test==y_predict)
#4.���������ӻ� transfer.get_feature_names()��ȡ��������
export_graphviz(estimator,out_file='titanic.dot',feature_names=transfer.get_feature_names())
#print(train.info())
# print(test.info())
#print(train['Embarked'].value_counts())
# S 644
# C 168
# Q 77
# Name: Embarked, dtype: int64
"""
pandas ��value_counts()�������Զ�Series�����
ÿ��ֵ���м�����������
value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
����:
1.normalize : boolean, default False��Ĭ��false,��Ϊtrue,���ٷֱȵ���ʽ��ʾ
2.sort : boolean, default True��Ĭ��Ϊtrue,��Խ����������
3.ascending : boolean, default False��Ĭ�Ͻ�������
4.bins : integer, ��ʽ(bins=1),���岻��ִ�м���,���ǰ����Ƿֳɰ뿪�ŵ����ݼ���,ֻ��������������
5.dropna : boolean, default True��Ĭ��ɾ��naֵ
"""
"""
DataFrame.to_dict(*self*,orient='dict',into=)
����ת��Ϊ�ֵ�,��������ʽ��ͬ:
orient='dict',Ĭ��,�ֵ����ֵ�:{column:{index:value}}
orient ='list' ,�ֵ�����Ϊ�б�:{column:[values]}
orient ='series',�ֵ���Ϊseries��ʽ:{column: Series(values)}
orient ='split',�ֵ��������ݶ�Ӧ�б�:{'index':[index],'columns':[columns],'data': [values]}
orient ='records',ת������ list��ʽ:[{column: value},...,{column:value}]
orient ='index',�ֵ�����ͬ�����ֵ�:{index:{column:value}}
"""
�������ܽ�
�ŵ�:
������ͽ���,��ľ���ӻ���
ȱ��:
������ѧϰ�߿��Դ������ܺܺõ��ƹ����ݵĹ��ڸ��ӵ���,�ⱻ��Ϊ����ϡ�
�Ľ�:
��֦cart�㷨(������API�����Ѿ�ʵ��,���ɭ�ֲ�����������ؽ���)
���ɭ��
����ѧϰ����֮���ɭ��
ʲô�����ɭ��
�ڻ���ѧϰ��,���ɭ����һ����������������ķ�����,�����������������ɸ������������������������
API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=��gini��, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
���ɭ�ַ�����
n_estimators:integer,optional(default = 10)ɭ�������ľ����120,200,300,500,800,1200
criteria:string,��ѡ(default =��gini��)�ָ������IJ�������
max_depth:integer��None,��ѡ(Ĭ��=��)���������� 5,8,15,25,30
max_features="auto��,ÿ���������������������
If "auto", then max_features=sqrt(n_features).
If "sqrt", then max_features=sqrt(n_features) (same as "auto").
If "log2", then max_features=log2(n_features).
If None, then max_features=n_features.
bootstrap:boolean,optional(default = True)�Ƿ��ڹ�����ʱʹ�÷Żس���
min_samples_split:�ڵ㻮������������
min_samples_leaf:Ҷ�ӽڵ����С������
������:n_estimator, max_depth, min_samples_split,min_samples_leaf
�����ɭ�ֶ�̩̹��˺Ž���Ԥ��
1�� ʲô�Ǽ���ѧϰ����
����ѧϰͨ����������ģ����ϵ��������һԤ�����⡣
���Ĺ���ԭ�������ɶ��������/ģ��,���Զ�����ѧϰ
������Ԥ�⡣��ЩԤ������ϳ����Ԥ��,���������
��һ�������������Ԥ�⡣
2�� ʲô�����ɭ��
�ڻ���ѧϰ��,���ɭ����һ����������������ķ�����,
#���� �������������ɸ������������������������
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
#1.��ȡ����
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier, export_graphviz
train=pd.read_csv("train(1).csv")
test=pd.read_csv("test.csv")
y_test=pd.read_csv("gender_submission.csv")
y_test=list(y_test['Survived'])#���Լ���Ŀ��ֵ,Ҫת��Ϊ�б�
print(len(y_test))
#2.���ݴ���
#(1)����ȱʧ����
#Age�еĿ�ֵ����ƽ�����������
train['Age'].fillna(train['Age'].mean(),inplace=True)
#Embarked�еĿ�ֵ���õ�½�ۿ��������
train["Embarked"].fillna("S",inplace=True)
#cabin�е�����ȱʧ̫����,�Ͳ������
#Age�еĿ�ֵ����ƽ�����������
test['Age'].fillna(test['Age'].mean(),inplace=True)
#Embarked�еĿ�ֵ���õ�½�ۿ��������
test["Embarked"].fillna("S",inplace=True)
#3.����ѡ��,ѡ��Է������йؼ����õ�����
features=['Pclass','Sex','Age']
train_features=train[features]#ѵ����������ֵ
train_target=list(train['Survived'])#ѵ������Ŀ��ֵ
test_features=test[features]#���Լ�������ֵ
#������ֵת��Ϊ�ֵ�
train_features=train_features.to_dict(orient ='records')
test_features=test_features.to_dict(orient ='records')
#�ֵ�������ȡ
# ʵ����һ��ת������
transfer = DictVectorizer(sparse=False)
#����
x_train=transfer.fit_transform(train_features)#�ֵ�������ȡת��
x_test=transfer.transform(test_features)
#���ɭ��
ran=RandomForestClassifier()
#�������������ͽ�����֤
#������
param_dict={"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
estimator=GridSearchCV(ran,param_grid=param_dict,cv=3)
estimator.fit(x_train,train_target)
#5.ģ������
#����1:ֱ�ӱȶ���ʵֵ��Ԥ��ֵ
y_predict=estimator.predict(x_test)
print("y_predict:\n",len(y_predict))
print("ֱ�ӱȶ���ʵֵ��Ԥ��ֵ:\n",y_test==y_predict)
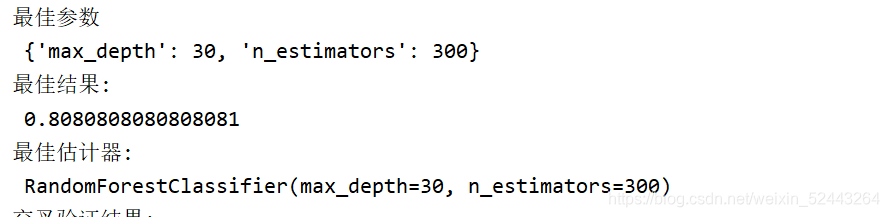
#��Ѳ���:best_params_
print("��Ѳ���\n" , estimator.best_params_)
#��ѽ��:best_score_
print("��ѽ��:\n",estimator.best_score_)
#��ѹ�����
print("��ѹ�����:\n",estimator.best_estimator_)
#������֤���:cv_results_
print("������֤���:\n", estimator.cv_results_)
���Իع�
�����빫ʽ
���Իع�(Linear regression)�����ûع鷽��(����)��һ�������Ա���(����ֵ)�������(Ŀ��ֵ)֮���ϵ���н�ģ��һ�ַ�����ʽ��
�ص�:ֻ��һ���Ա����������Ϊ�������ع�,����һ���Ա�������Ľ�����Ԫ�ع�
���Իع�API
sklearn.linear_model.LinearRegression(fit_intercept=True)
ͨ�����淽���Ż�
fit_intercept:�Ƿ����ƫ��
LinearRegression.coef_:�ع�ϵ��
LinearRegression.intercept_:ƫ��
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
SGDRegressor��ʵ��������ݶ��½�ѧϰ,��֧�ֲ�ͬ��loss���������ͷ�����������Իع�ģ�͡�
loss:��ʧ����
loss=��squared_loss��: ��ͨ��С���˷�
fit_intercept:�Ƿ����ƫ��
learning_rate : string, optional
ѧϰ�����
'constant': eta = eta0
'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
'invscaling': eta = eta0 / pow(t, power_t)
power_t=0.25:���ڸ��൱��
����һ������ֵ��ѧϰ����˵,����ʹ��learning_rate=��constant�� ,��ʹ��eta0��ָ��ѧϰ�ʡ�
SGDRegressor.coef_:�ع�ϵ��
SGDRegressor.intercept_:ƫ��
���Իع�֮��ʿ�ٷ���Ԥ��
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_squared_error
def liner1():
#��ȡ����
boston=load_boston()
#�������ݼ�
x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target)
#����,��Ϊ�е����ݹ���Ļ��ͻᵼ��Ȩ�ؼ���IJ�ȷ
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#Ԥ����
estimator=LinearRegression()
estimator.fit(x_train,y_train)
#�ó�ģ��
print("���淽��Ȩ��ϵ��Ϊ:\n",estimator.coef_)
print("���淽��ƫ��Ϊ:\n",estimator.intercept_)
#ģ������
y_predict=estimator.predict(x_test)
print("Ԥ�ⷿ��:\n",y_predict)
error=mean_squared_error(y_test,y_predict)
print("���淽��-�������Ϊ:\n",error)
return None
def liner2():
#��ȡ����
boston=load_boston()
#�������ݼ�
x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target)
#����,��Ϊ�е����ݹ���Ļ��ͻᵼ��Ȩ�ؼ���IJ�ȷ
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
#Ԥ����
estimator=SGDRegressor()
estimator.fit(x_train,y_train)
#�ó�ģ��
print("�ݶ��½�Ȩ��ϵ��Ϊ:\n",estimator.coef_)
print("�ݶ��½�ƫ��Ϊ:\n",estimator.intercept_)
#ģ������
y_predict = estimator.predict(x_test)
print("Ԥ�ⷿ��:\n", y_predict)
#���Իع���������
error = mean_squared_error(y_test, y_predict)
print("�ݶ��½�-�������Ϊ:\n", error)
if __name__=="__main__":
liner1()
liner2()


Ƿ���������
����
�����:һ��������ѵ���������ܹ���ñ�����������õ����, �����ڲ������ݼ���ȴ���ܺܺõ��������,��ʱ��Ϊ�����������˹���ϵ�����(ģ���ڸ���)
Ƿ���:һ��������ѵ�������ϲ��ܻ�ø��õ����,�����ڲ������ݼ���Ҳ���ܺܺõ��������,��ʱ��Ϊ������������Ƿ��ϵ�����(ģ���ڼ�)
ԭ���Լ�����취
Ƿ���ԭ���Լ�����취
ԭ��:ѧϰ�����ݵ���������
����취:�������ݵ���������
�����ԭ���Լ�����취
ԭ��:ԭʼ��������,����һЩ��������, ģ���ڸ�������Ϊģ�ͳ���ȥ��˸����������ݵ�
����취:
����
��������Իع�,����ѡ�����������Ƕ�����������ѧϰ�㷨������㷨��˵Ҳ���������������,����һЩ�㷨��������֮��(��������������),���Ǹ����Ҳ��ȥ�Լ�������ѡ��,����֮ǰ˵��ɾ�����ϲ�һЩ����
�������
L2����
����:����ʹ������һЩW�Ķ���С,���ӽ���0,����ij��������Ӱ��
�ŵ�:ԽС�IJ���˵��ģ��Խ��,Խ��ģ����Խ�����ײ������������
Ridge�ع�
L1����
����:����ʹ������һЩW��ֱֵ��Ϊ0,ɾ�����������Ӱ��
LASSO�ع�
��ع�
��ع�,��ʵҲ��һ�����Իع顣ֻ�������㷨�����ع鷽��ʱ��,������������,�Ӷ��ﵽ�������ϵ�Ч��
API
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
����l2�������Իع�
alpha:��������,Ҳ�� ��
��ȡֵ:0~1 1~10
solver:����������Զ�ѡ���Ż�����
sag:������ݼ����������Ƚϴ�,ѡ�������ݶ��½��Ż�
normalize:�����Ƿ���б���
normalize=False:������fit֮ǰ����preprocessing.StandardScaler��������
Ridge.coef_:�ع�Ȩ��
Ridge.intercept_:�ع�ƫ��
��ع�֮��ʿ�ٷ���Ԥ��
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,Ridge
from sklearn.metrics import mean_squared_error
# ��ȡ����
boston = load_boston()
# �������ݼ�
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target)
# ����,��Ϊ�е����ݹ���Ļ��ͻᵼ��Ȩ�ؼ���IJ�ȷ
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# Ԥ����
estimator = Ridge()
estimator.fit(x_train, y_train)
# �ó�ģ��
print("��ع�Ȩ��ϵ��Ϊ:\n", estimator.coef_)
print("��ع�ƫ��Ϊ:\n", estimator.intercept_)
# ģ������
y_predict = estimator.predict(x_test)
print("Ԥ�ⷿ��:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("��ع�-�������Ϊ:\n", error)
���ع�
# ���ع�(Logistic Regression)�ǻ���ѧϰ�е�һ
# �ַ���ģ��,���ع���һ�ַ����㷨,��Ȼ�����д�
# �лع�,��������ع�֮����һ������ϵ�������㷨��
# ��Ч,��ʵ����Ӧ�÷dz��㷺
# 4.4 �����㷨-���ع��������
# 4.4.1 ���ع��Ӧ�ó���
# ������� �Ƿ�ᱻ���
# �Ƿ�Ϊ�����ʼ�
# �Ƿ�
# �Ƿ�Ϊ����թƭ
# �Ƿ�Ϊ����˺�
# ���� / ����(������)
# 4.4.2 ���ع��ԭ��
# ���ͻع����� ���� ���ع� �� ����
# �����(�����������뼤������з���)
# sigmoid���� [0, 1](�����趨������ֵ������������,С����ֵ�Ͳ�����������)
# [0,1]���Կ����Ǹ���ֵ,��������Ա������ĸ����ʷ�Χ
# 1/(1 + e^(-x))(x���־ʹ���h(w))
# ���躯��/����ģ��
# 1/(1 + e^(-(w1x1 + w2x2 + w3x3 + ���� + wnxn + b)))
# ��Ҫ������Ǿ��ǵõ�������Ȩ�غ�ƫ��
# ��ʧ����
# (y_predict - y_true)ƽ����/����
# ���ع����ʵֵ/Ԥ��ֵ--> �Ƿ�����ij�����
# ������Ȼ��ʧ
# log 2 x
# �Ż���ʧ
# �ݶ��½�
���ع�֮��֢Ԥ��
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
#1.��ȡ����
from sklearn.model_selection import train_test_split
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
#������Ԫ��,ԭ���ݼ�û������pd.read_csv(names=)
data=pd.read_csv("breast-cancer-wisconsin.csv",names=column_name)
#2.ȱʧֵ����
#(1)��'?'�滻Ϊnan
data=data.replace(to_replace='?',value=np.nan)
#(2)dropna()ɾ����NaN��ǵ�����
data.dropna(inplace=True)
#3.�������ݼ�
#print(data.head())
#(1)ɸѡ����ֵ��Ŀ��ֵ
x=data.iloc[:,1:-1]#ѡ��һ��(ȡ��)�����һ��(ȡ����)
y=data["Class"]#�Ƿ�Ϊ��֢
# print(x)
x_train,x_test,y_train,y_test=train_test_split(x,y)
#4.����,��Ϊ���ع�ģ�ͻ����б�Ҫ������
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)#ѵ����
x_test=transfer.transform(x_test)#���Լ�
#5.���ع��Ԥ��������
estimator=LogisticRegression()
estimator.fit(x_train,y_train)#����ѵ�������ݵó�ģ��
#6.�鿴���ع��ģ�Ͳ���
print("�ع�ϵ��:\n",estimator.coef_)
print("ƫ��:\n",estimator.intercept_)
#7.ģ������
#����1:ֱ�ӱȶ���ʵֵ��Ԥ��ֵ
y_predict=estimator.predict(x_test)
print("y_predict\n",y_predict)
print("ֱ�ӱȶ���ʵֵ��Ԥ��ֵ:\n",y_test==y_predict)
#������
score=estimator.score(x_test,y_test)
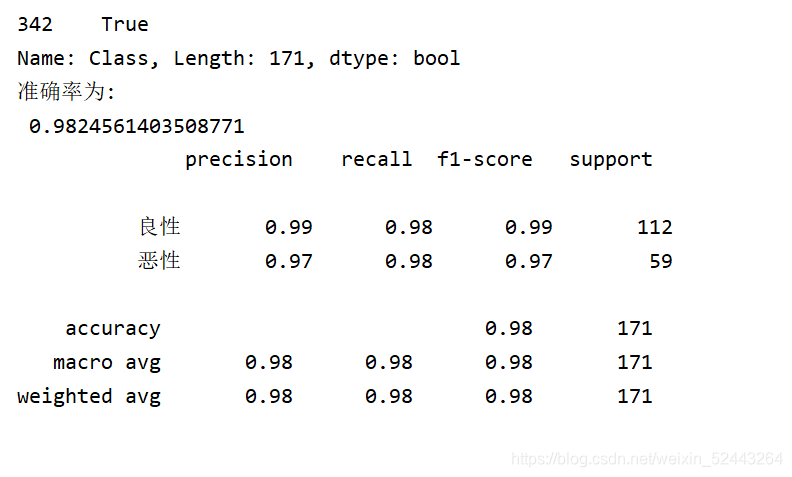
print("ȷ��Ϊ:\n",score)
#�鿴��ȷ�ʺ��ٻ���,2���������������,4����������Ƕ���
#y_test����ʵֵ y_predict��Ԥ��ֵ labels��ÿ�������ʲô���ֱ�ʾ��
report=classification_report(y_test,y_predict,labels=[2,4],target_names=["����","����"])
print(report)
#F1-score,��ӳ��ģ�͵��Ƚ���
#support ��������
"""
data��DataFrame���͵�����,���Ҫ�滻����ĸ������ݿ�����
replace()����
replace(self, to_replace=None, value=None,
inplace=False, limit=None, regex=False,
method='pad', axis=None)
data.isnull().any()�鿴ÿһ�е��Ƿ���ȱʧֵ
3 F1-score ģ�͵��Ƚ���
�ܹ���100����,���99��������֢,1�������ǰ�֢ - ����������(�������ð�֢����������,��������û�ð�֢��������������)
����������ȫ��Ԥ������(Ĭ�ϰ�֢Ϊ����) - �������ε�ģ�� ȷ��:99%
�ٻ���:99/99 = 100%(��ʵΪ��֢��������Ԥ����Ϊ��֢����)
��ȷ��:99%
F1-score: 2*99%/ 199% = 99.497%
"""