企业级机器学习 Pipline - 样本sample处理
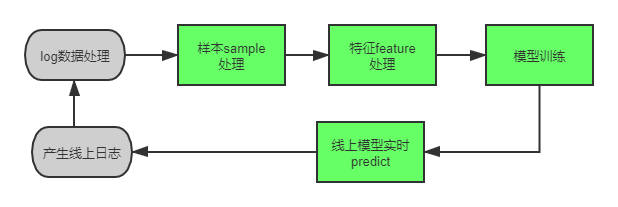
书接上文,大家都知道,我们现在常用的机器学习平台包括 离线训练 和 在线预估 2 个模块。
其中,离线部分一般负责 log数据处理,样本处理,特征处理和模型训练等。
在线部分则包括线上的进行的 实时predict 过程 (online predict,也称为在线模型的Inference)。流程图如下:
在机器学习界,有一句话是大家公认的真理:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。我也觉得这句话说的很有道理呀 -,数据对于机器学习模型来说是至关重要的。
在 样本处理 环节,则决定着使用哪些用户的哪些行为日志来训练这个模型(下文简称样本选择),以及对应着进行样本sample采样的操作。其中,使用哪些用户的行为日志训练模型,则直接决定着机器学习模型的正负样本比例,而样本的正负比例直接关系着预估模型的真实CTR或则真实CVR的打分情况,一般我们也称其为 先验CXR 。一般是true_cxr = pos / (pos + neg);而我们现在一些线上的模型产生的日志,稍微大一些的系统,模型天级别增量更新的话,每天的日志量可以达到上亿级别甚至上十亿,所以我们会做一些采样操作,一般是对负样本做负采样。但是如上面所说,做了负采样,影响了真实的CXR的值,所以我们针对相应的采样比例进行 CXR校准 操作,这个我们下文再细说。
下面我们从以下2个方面分别进行介绍:
1. 样本选择
2. sample 采样与CXR校准
1, 样本选择
上文已经说了,样本选择决定着模型选择用户的哪些行为日志来进行训练。当然我们希望选择的样本能尽可能学到模型在线上遇到数据的真实分布情况,让离线训练的数据分布尽量和线上预估数据的分布尽可能的保持一致。
同时,对于正负样本漏斗的确定,一般我们用曝光过未有点击或则下载等其他转化行为的数据作为负样本,而用曝光过并且点击(下载,激活)等行为的作为正样本。工程师在做的时候,可以用曝光行为去left join 点击行为日志,确定好唯一的key。能join上的就是正样本,否则为正样本,下面有具体的代码介绍。
而实际中遇到的数据是非常脏的,甚至还存在一些刷单数据,这些都 需要我们在深入理解数据产生的业务场景的情况下,去有针对性的做一些处理。
最简单的,现在的很多app打开之后,都有首页首屏。毋庸置疑,首页首屏有着巨大的展示类曝光流量,但是同时,也产生着大量的无效曝光。
例如:
(1)无效曝光。用户进入app之后,直接奔者别的页面去了,而在首页首屏停留的时间非常短,属于用户无意识的操作行为。在实际项目中,工程师们可以去掉有用户在首页首屏的曝光操作,但是没有任何点击或其他转化操作的样本。这只是一种做法,据我所知,在某个大型互联网公司的广告系统中,就这个简单操作线上ecpm日均增收5%以上。
(2)误触。用户无意间点开了某个页面或则某个视频,虽然进入了,但是在极短的时间立即又退出了。这种流量并不是用户的有效用户行为,量非常大而且没有太大意义的行为,在一定程度上是需要算法工程师们根据实际业务场景去进行去除的。实际操作中,工程师们可以取得用户进入某个页面到退出该页面的时间戳做一个减法,去掉进入时间过短的那部分样本sample。
(3)召回模型样本的独特性。拿什么样的样本训练召回模型,这样的基本问题,很多人还存在误区,习惯性照搬排序的方法,适得其反。如果说 排序是特征的艺术,那么召回就是样本的艺术,特别是负样本的艺术,有一句话说的好:负样本为王。排序是非常讲究所谓的“真负”样本的,即必须拿“曝光未点击”的样本做负样本。为此,还有所谓above click的作法,即只拿点击文章以上的未点击文章做负样本。一般对于召回样本的方法,是拿点击样本做正样本,拿随机采样做负样本。甚至有做法为了限制热点用户和热点操作,对每个用户只截取一定长度的样本数量来训练模型,让召回模型能个性和共性两者兼得。召回模型的样本可以做的事情非常多,这里只浅尝则止了,深入的优化过程以后看能不能详细剖析下。
样本对于一个模型的重要性这里也就不在赘述了,下文会有简单版本的代码介绍,对于一些中小型的互联网公司来说,是可以直接照搬过去使用的。工程师有公司,但是工程师的技术是大家共享的,嘿嘿~
2, sample 采样与CXR校准
样本sample 采样的技术很多,记得在葫芦娃出的那本 百面机器学习 里面,有一个章节,依稀记得是 第8章 好像,是专门讲各种采样技术的,像拒绝采样、重要性采样、吉布斯(Gibbs)采样,蒙特卡洛采样等,有需要专门争对负采样做优化的同学可以去看看。惭愧,待了几家大型的互联网公司的商业化算法团队,发觉大家最爱用的还是随机负采样~~~~ , 这就是火箭要造,可是拧螺丝也特别好使啊。
常规的随机负采样做法就是用random函数产生一个随机数,判断当前样本是负样本的话,就判断该随机书和采样率大小,然后看是否选择这个样本。这个是随机负采样。
校准呢,是在你使用采样过的样本进行模型训练之后,模型训练到的数据分布是有偏的,此时模型打分的CXR 是偏大的(因为你去掉了大量的负样本,导致正样本占比偏高),所以此时要进行CXR校准。
业界常用的校准方法都是一个校准公式:

该公式也是按比例恢复负样本对模型打分权重的一个逻辑。
该公式出自于14年facebook的论文《Practical Lessons from Predicting Clicks on Ads at Facebook》,感兴趣的可以去找原文阅读看看。
3, 代码时刻
talk is cheap, show the code !!!
上面把样本选择、随机负采样和 cxr 校准的理论部分介绍完了,下面上一份实际可操作的代码,一些公司的业务是实际可以使用的。这都是个人感兴趣写的代码,能力有限,一家之言,不喜勿喷~~~
代码样本选择和随机负采样部分使用scala spark 来实现,cxr校准部分会贴上一个java 函数,详情如下:
@ 欢迎关注微信公众号:算法全栈之路
package Data
import org.apache.hadoop.io.compress.GzipCodec
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.control.Breaks
object GenerateLogSamplesWithSelectAndSample {
case class LogItem(imei: String, timestamp: String, posid: String, triggerid: String, adid: String, event: String, label: String)
def main(args: Array[String]): Unit = {
val Array(logPath, outputPath, positionId, sampleRate) = args
val sparkConf = new SparkConf().setAppName("GenerateLogSamplesWithSelectAndSample")
val sc = new SparkContext(sparkConf)
val positionIdStr = positionId.split(",").toSet
val positionIdIdSet = sc.broadcast(positionIdStr)
// 聚合得到曝光数据
val expose_data = sc.textFile(logPath)
.filter(x => x != null)
.map(e => {
val eles = e.split("\t")
val timestamp = eles(0)
val imei = eles(1)
val posid = eles(2)
val triggerid = eles(3)
val adid = eles(4)
val event = eles(5)
var label = null;
(imei, LogItem(imei, timestamp, posid, triggerid, adid, event, label))
})
// 过滤出固定广告为的曝光行为日志
.filter(e => positionIdIdSet.value.contains(e._2.posid) && e._2.event == "expose")
//根据 用户 imei 聚合各个用户行为
.groupByKey()
.mapValues(e => {
// 根据triggerid, posid , adid 去重复
val distinct_list = e.map(e => (e.triggerid + "$" + e.posid + "$" + e.adid, e))
.groupBy(_._1)
.map(e => e._2)
.map(e => e.toArray
.sortBy(_._2.timestamp)
.last
._2
)
distinct_list
})
.persist(StorageLevel.MEMORY_AND_DISK_SER)
// 点击行为数据
val click_data = sc.textFile(logPath)
.filter(x => x.nonEmpty)
.map(e => {
val eles = e.split("\t")
val timestamp = eles(0)
val imei = eles(1)
val posid = eles(2)
val triggerid = eles(3)
val adid = eles(4)
val event = eles(5)
val label = null
(imei, LogItem(imei, timestamp, posid, triggerid, adid, event, label))
})
.filter(e => positionIdIdSet.value.contains(e._2.posid) && e._2.event == "expose") // 过滤出点击行为
.groupByKey()
.persist(StorageLevel.MEMORY_AND_DISK_SER)
// 曝光行为 left join click 行为, 能join 上的为正样本,不能join上的为负样本
// 给样本打标签
val labeled_data = expose_data.leftOuterJoin(click_data)
.mapValues(e => {
val exposeArray = e._1.toArray
if (e._2 != null && e._2.nonEmpty) {
val clickArray = e._2.get.toArray
if (exposeArray.size > 0 && clickArray.size > 0) {
for (i <- 0 to exposeArray.size - 1) {
val expose = exposeArray(i).asInstanceOf[LogItem]
val breaker = new Breaks
breaker.breakable {
for (j <- 0 to clickArray.size - 1) {
val exposeTriggerId = expose.triggerid
val exposePosId = expose.posid
val click: LogItem = clickArray(j).asInstanceOf[LogItem]
val clickTriggerId = click.triggerid
val clickPosId = click.posid
// 根据 triggerId, posId, adid 来join 曝光和点击,能join 上的 打标签为label正样本 1,否则为负样本
if (exposeTriggerId.equals(clickTriggerId) && !exposeTriggerId.equals("null") && !clickTriggerId.equals("null"))
if (exposePosId.equals(clickPosId) && !exposePosId.equals("null") && !clickPosId.equals("null"))
if (expose.adid != null && click.adid != null && expose.adid == click.adid) {
LogItem(expose.imei, expose.timestamp, expose.posid, expose.triggerid, expose.adid, null, "1")
breaker.break
}
} // end for
}
} // end for
}
}
// join不上的 曝光
for (i <- 0 to exposeArray.size - 1) {
val expose = exposeArray(i).asInstanceOf[LogItem]
if (expose.label == null)
LogItem(expose.imei, expose.timestamp, expose.posid, expose.triggerid, expose.adid, null, "0")
}
exposeArray
})
.flatMapValues(e => e)
.persist(StorageLevel.MEMORY_AND_DISK_SER)
// 以上的所有过程均为给样本打标签的过程,曝光样本 left join 点击样本的操作
// 样本清洗流程,去掉有曝光,但是在首屏首页没有点击行为的样本的triggerid
val noSenseTriggerIds = labeled_data.map(e => (e._2.posid + "$" + e._2.triggerid, (1, e._2.label)))
.reduceByKey((r1, r2) => (r1._1 + r2._1, r1._2 + r2._2)) // 曝光次数,点击次数
//一个广告位置上 , 一次triggerid 对应会有多个广告,会有对应多个曝光,聚合的是广告曝光个数和点击个数
// 此处让首屏有10个广告, 注意 自定义修改
.filter(x => x._2._1 <= 10 && x._2._2 == 0) // 且无点击 ,此处可以改为别的转化行为
.map(e => e._1.split("\\$")(1))
.collect()
.toSet
val noSenseTriggerIdsBC = sc.broadcast(noSenseTriggerIds)
val final_sample_data = labeled_data
// 样本清洗过程
.filter(x => !noSenseTriggerIdsBC.value.contains(x._2.triggerid))
// 负采样过程
.map(e => {
if (e._2.label.equals("1") || ((e._2.label.equals("0") && math.random <= sampleRate.toDouble))) {
// 正样本全部通过,负样本 部分通过
e
} else null
})
.filter(e => e != null)
.mapValues(e => {
val imei = e.imei
val triggerid = e.triggerid
val timestamp = e.timestamp
val adid = e.adid
val posid = e.posid
val label = e.label
label +"t"+imei +"t"+triggerid +"t"+adid +"t"+posid +"t"+timestamp
})
val outputPartNum = math.ceil(final_sample_data.count() / 400000).toInt
final_sample_data.repartition(outputPartNum).saveAsTextFile(outputPath,classOf[GzipCodec])
}
}
上面给出了一套实际工程可用的样例代码,包括了过滤给定广告位置的用户行为日志、给用户行为日志打label、简单的基于具体业务的负样本过滤、以及负采样等操作。下面是CxR的校准部分代码:
@ 欢迎关注微信公众号:算法全栈之路
public static double ctrResetAfterSample(double probability, double samplingRate) {
Double score = 0.0D;
if (samplingRate > 0.0D && samplingRate < 1.0D) {
score = probability / (probability + (1.0D - probability) / samplingRate);
} else {
score = probability;
}
return score;
}
到这里,整个样本处理部分就介绍完了,可以使用上面的方法进行符合自己业务的代码改写,觉得有用就点赞和分享吧~
欢迎扫码关注作者的公众号: 算法全栈之路
