前情回顾
1.attention和transformers
2.BERT和GPT
结论速递
跟着教程,阅读了HuggingFace的BERT模型,分为tokenizer和model两大部分,而model内部又细分为embedding,encoder(内分为Attention和Intermediate)和Pooler三大部分。
阅读源码的逻辑,基本上是按照BERT是如何计算的这个逻辑来进行的,但其中存在着一个position_embedding的奇怪操作,目前还是没有想明白。
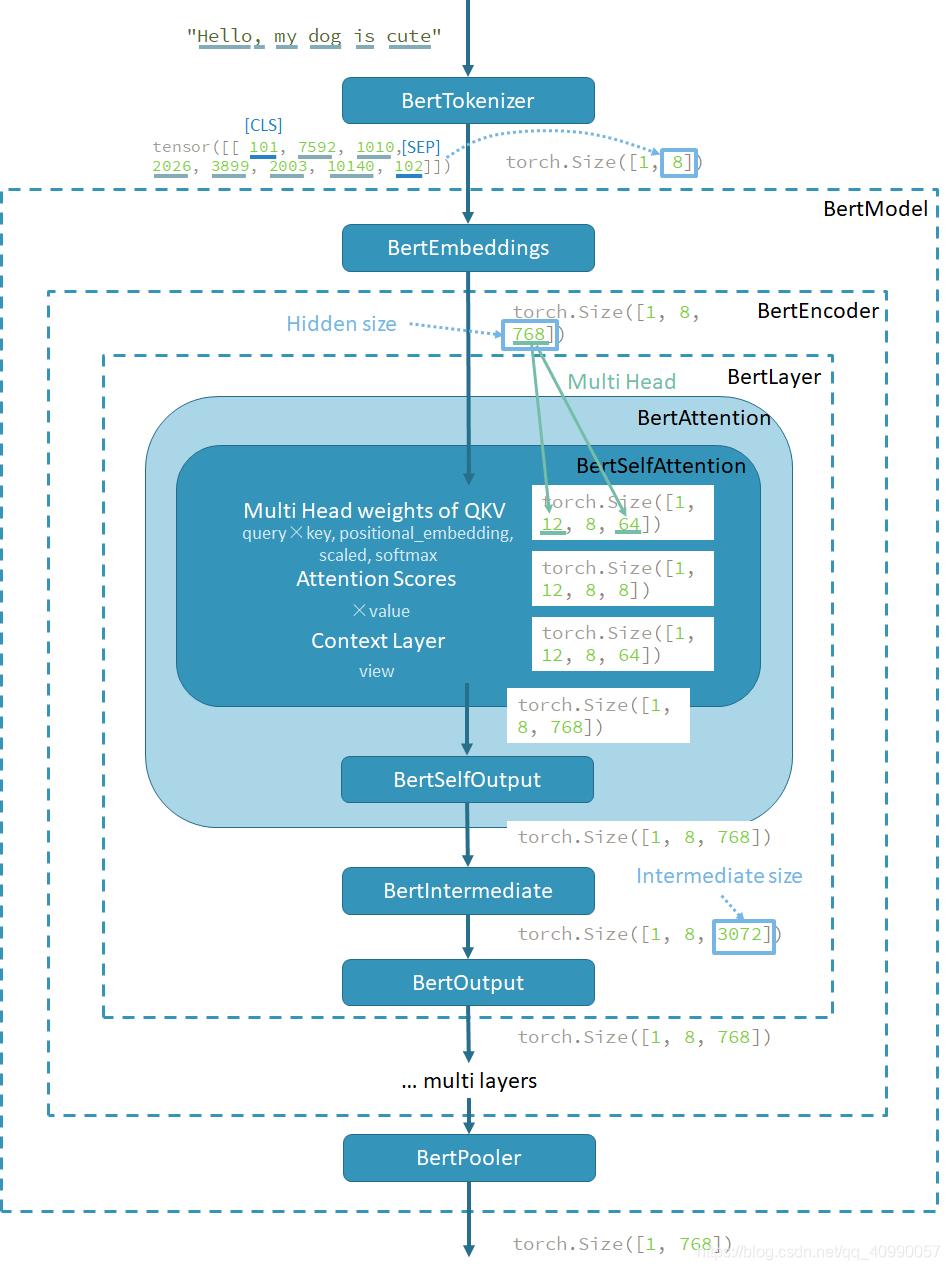
除去教程内容,本文还以"Hello, my dog is cute"这个句子为例,一步一步的跑过了每一个主要的部分,展示了其维度的变化(在第四部分中绘制了流程图),也让自己对BERT对句子的处理有了更深的理解。
1 简介
本篇章是基于HuggingFace/Transformers, 48.9k Star的学习,全部代码在huggingface bert(注意由于版本更新较快,可能存在差别,请以4.4.2版本为准),浙江大学李泺秋对这个代码进行了阅读和解构。

代码的作者是HuggingFace。
HuggingFace 是一家总部位于纽约的聊天机器人初创服务商,很早就捕捉到 BERT 大潮流的信号并着手实现基于 pytorch 的 BERT 模型。HuggingFace的Transformers项目最初名为 pytorch-pretrained-bert,在复现了原始效果的同时,提供了易用的方法以方便在这一强大模型的基础上进行各种玩耍和研究。
随着使用人数的增加,这一项目也发展成为一个较大的开源社区,合并了各种预训练语言模型以及增加了 Tensorflow 的实现,并且在 2019 年下半年改名为 Transformers。截止写文章时(2021 年 3 月 30 日)这一项目已经拥有 43k+ 的star,可以说 Transformers 已经成为事实上的 NLP 基本工具。(2021/8/22 已经50k+ 了)
教程基于 Transformers 版本 4.4.2(2021 年 3 月 19 日发布)项目中,pytorch 版的 BERT 相关代码,从代码结构、具体实现与原理,以及使用的角度进行了分析。
IrEne: Interpretable Energy Prediction for Transformers一文提供了一张一层BERT模型的解析图,还算比较能够说明问题。

参照教程及上面的图,BERT模型的构建展开如下:
- BERT Tokenization 分词模型(BertTokenizer)
- BERT Model 本体模型(BertModel)
- BertEmbeddings
- BertEncoder
- BertLayer
- BertAttention(Self-Attention)
- BertIntermediate(全连接层)
- BertOutput(输出)
- BertLayer
- BertPooler
2 分词:BertTokenizer
2.1 结构解读
和BERT 有关的 Tokenizer 主要写在
models/bert/tokenization_bert.py中。
分词(Tokenization)是自然语言处理中必备的步骤,即需要将一段长文本切割成指定的形式,然后才能进行编码(即embedding)处理。
BertTokenizer的主类名叫BertTokenizer,它是基于BasicTokenizer和WordpieceTokenizer实现的。
在BertTokenizer对象创建时,需要指定词表vocab_file。BertTokenizer首先加载词表,存储为OrderedDict(其中key是单词,value是编号);然后对文本依次进行BasicTokenization(可选)和WordpieceTokenization。

其中
BasicTokenizer的功能是:按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。
- 对于中文字符,通过预处理(加空格)来按字分割;
- 同时可以通过never_split指定对某些词不进行分割。
WordPieceTokenizer的功能是:在词的基础上,进一步将词分解为子词(subword)。
- subword 介于 char 和 word 之间,既在一定程度保留了词的含义,又能够照顾到英文中单复数、时态导致的词表爆炸和未登录词的 OOV(Out-Of-Vocabulary)问题,将词根与时态词缀等分割出来,从而减小词表,也降低了训练难度;
For example, :obj:input = "unaffable"wil return as output :obj:["un", "##aff", "##able"]. - 是基于最大的匹配(greedy longest-match-first algorithm)。
BertTokenizer 有以下常用方法:
- from_pretrained:从包含词表文件(vocab.txt)的目录中初始化一个分词器;
- tokenize:将文本(词或者句子)分解为子词列表;
- convert_tokens_to_ids:将子词列表转化为子词对应下标的列表;
- convert_ids_to_tokens :与上一个相反;
- convert_tokens_to_string:将 subword 列表按“##”拼接回词或者句子;
- encode:对于单个句子输入,分解词并加入特殊词形成“[CLS], x, [SEP]”的结构并转换为词表对应下标的列表;对于两个句子输入(多个句子只取前两个),分解词并加入特殊词形成“[CLS], x1, [SEP], x2, [SEP]”的结构并转换为下标列表;
- decode:可以将 encode 方法的输出变为完整句子。

2.2 小示例
类定义的源码就不在此处贴出,可查看models/bert/tokenization_bert.py。
注意到BERT带了几种pre_trained后的词表,
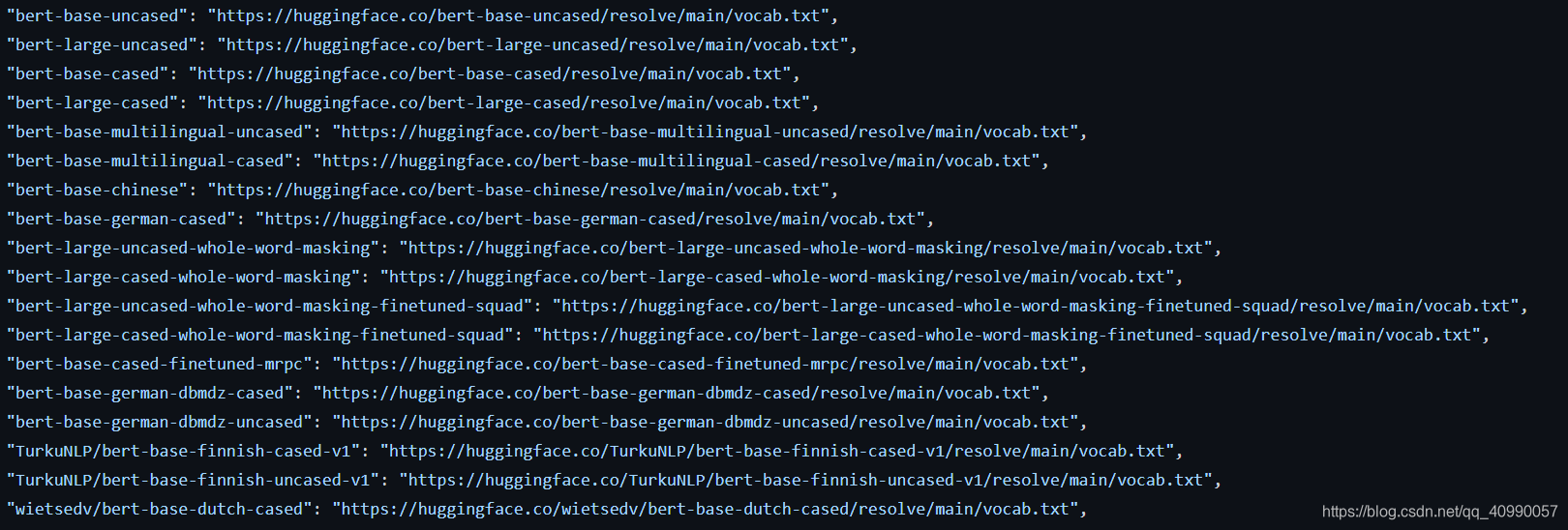
每个词表都有对应的最大词嵌入编码大小max_model_input_sizes,和是否进行do_lower_case的定义,通过全局变量的形式定义并传递。
我们使用pre_trained模型bert-base-uncased来创建对象
bt = BertTokenizer.from_pretrained('bert-base-uncased')
然后我们输入一句话进行测试
bt('I like natural language progressing!')
输出是
{'input_ids': [101, 1045, 2066, 3019, 2653, 27673, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
可以看到生成了token_type_ids是用来指示所属的句子,同时也生成了attention_mask。长度为8,对应5个单词+1个标点+[CLS]+[SEP],且顺序与句子顺序一一对应。
也可以输入两句话
bt("Good morning!","I will learn natural language progressing today!")
输出是
{'input_ids': [101, 2204, 2851, 1012, 102, 1045, 2097, 4553, 3019, 2653, 27673, 2651, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
出现了分句的现象,即token_type_ids出现了不同。
如果输入三句。
bt("Good morning!","I will learn natural language progressing today!","I like natural language progressing!")
则输出是
{'input_ids': [101, 2204, 2851, 999, 102, 1045, 2097, 4553, 3019, 2653, 27673, 2651, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
丢掉了第三句话,因为只能处理两句。
需要注意的是,这里的一句话,是指一个字符串,如果像下面这样,就不会丢,也不会出现不同的token_type_ids。
bt("Good morning! I will learn natural language progressing today! I like natural language progressing!")
输出是
{'input_ids': [101, 2204, 2851, 999, 1045, 2097, 4553, 3019, 2653, 27673, 2651, 999, 1045, 2066, 3019, 2653, 27673, 999, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
3 本体:BertModel
3.1 结构概述
和 BERT 模型有关的代码主要写在
/models/bert/modeling_bert.py中,这一份代码有一千多行,包含 BERT 模型的基本结构和基于它的微调模型等。
BertModel 主要为 transformer encoder 结构,包含三个部分:
- embeddings,即BertEmbeddings类的实体,根据单词符号获取对应的向量表示;
- encoder,即BertEncoder类的实体;
- pooler,即BertPooler类的实体,这一部分是可选的。
BertModel 也可以配置为 Decoder。
BerModel支持注意力头剪枝操作,这是一个复杂的操作,因为涉及到K,Q,V的拼接,同时又不能乱掉。
3.2 BertEmbeddings
3.2.1 功能解读
在上一个任务中,我们有提到过,Bert的输入,是由三部分Embedding组成的

- word_embeddings,上文中 subword 对应的嵌入。
- token_type_embeddings,用于表示当前词所在的句子,辅助区别句子与 padding、句子对间的差异。
- position_embeddings,句子中每个词的位置嵌入,用于区别词的顺序。和 transformer 论文中的设计不同,这一块是训练出来的,而不是通过 Sinusoidal 函数计算得到的固定嵌入。一般认为这种实现不利于拓展性(难以直接迁移到更长的句子中)。
三个 embedding 不带权重相加,并通过一层 LayerNorm+dropout 后输出,其大小为(batch_size, sequence_length, hidden_size)。
教程里提供了一个知乎问答,来解答为什么使用LayerNorm而不是BatchNorm的问题。
这里提到一个比较重要的观点:
自然语言处理所处理的数据都是人工生成的(即embedding的过程),这样的话batch其实无法保证是均匀分布的。所以这个时候使用batch normalization其实是无法保证无偏的,就会带来误差。
在这个地方答主对NLP任务和CV任务进行了对比:
图像数据是自然界客观存在的,像素的组织形式已经包含了“信息”,而NLP数据不一样,网络对NLP数据学习的真正开端是从’embedding’开始的,而这个‘embedding’并不是客观存在,它也是通过网络学习出来的。
可以假设,真实世界的图像数据是服从某种分布的(很大概率是高斯分布),可以肯定的是,这个分布不是“零均值”的,也不是1标准差的。如果是放到二维坐标里,那图像数据是处在第一象限并且远离坐标原点的区域。网络的学习分“前向”和“反馈”两个过程,前向产生“信息流“,反向通过梯度更新参数。信息流由两部分组成:数据 和 网络参数图像任务中,由于图像数据的 “非零均值” 和”非1标准差”,那就需要参数去拟合这部分信息,尤其是非1标准差,必然带来学习到的参数方差大,导致模型容易过拟合不稳定。所以batch normalizaiton是在解决这个问题。
3.2.2 小示例
代码就不贴了,都在/models/bert/modeling_bert.py里头。
这边通过一个小的例子,来展示一下这个类如何使用,用到了前面生成的BertTokenizer对象,先生成Embedding对象,同时生成输入数据
config = BertConfig.from_pretrained("bert-base-uncased")
em = BertEmbeddings(config)
inputs = bt("Hello, my dog is cute", return_tensors="pt")
这里需要注意,因为BertEmbeddings处理torch.tensor对象,所以需要,在tokenization的时候,指定生成tensors。此时可以看到inputs长这样:
{'input_ids': tensor([[ 101, 7592, 1010, 2026, 3899, 2003, 10140, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
每个value都是torch.tensor了。然后我们把它输入。
em(inputs["input_ids"])
输出结果
tensor([[[ 0.0465, 0.3456, -0.1734, ..., -2.1129, -0.4718, 1.1559],
[-1.4477, -1.0822, -1.1850, ..., -0.9078, 0.6020, 0.0000],
[-0.3528, -0.5460, -2.6290, ..., -0.6681, -0.2422, 2.3260],
...,
[-3.4365, -0.0000, -0.8186, ..., -1.2820, 1.9402, 0.0000],
[-0.4476, -0.8365, 0.0825, ..., -0.9675, -0.8402, 1.7759],
[-0.9798, -1.5422, -0.0000, ..., -0.0788, -0.1390, -1.1606]]],
grad_fn=<MulBackward0>)
输入大小是torch.Size([1, 8]),输出对应的大小是torch.Size([1, 8, 768])。768是hidden_size。
3.3 BertEncoder――BertLayer
3.3.1 概述
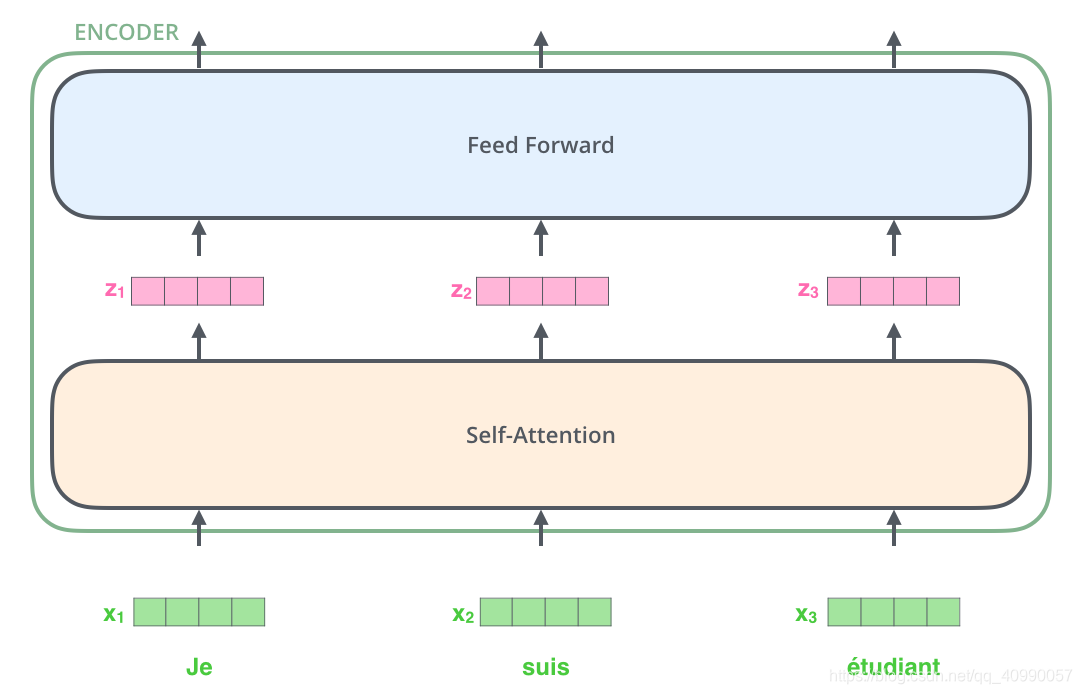
在展开更具体的叙述之前,下面这个图要铭记于心(我们在上上个任务里见过),因为,它就是这么组成的:
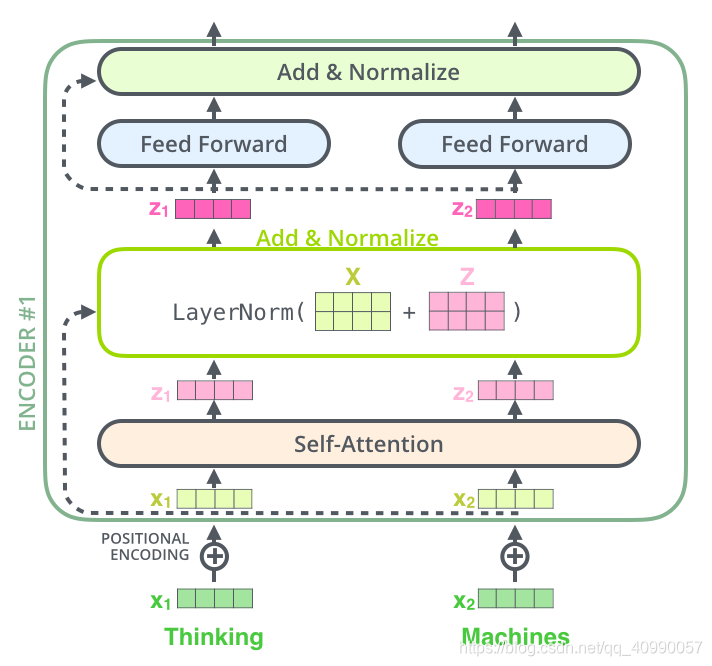
再包装一点,就是这个
3.3.2 BertAttention
3.3.2.1 结构解读
BertAttention是个套娃,它的主要功能其实在BertSelfAttention里头,然后但是同时也实现了BertSelfOutput,和pruned_heads(也就是剪枝的功能)

3.3.2.2 BertSelfAttention
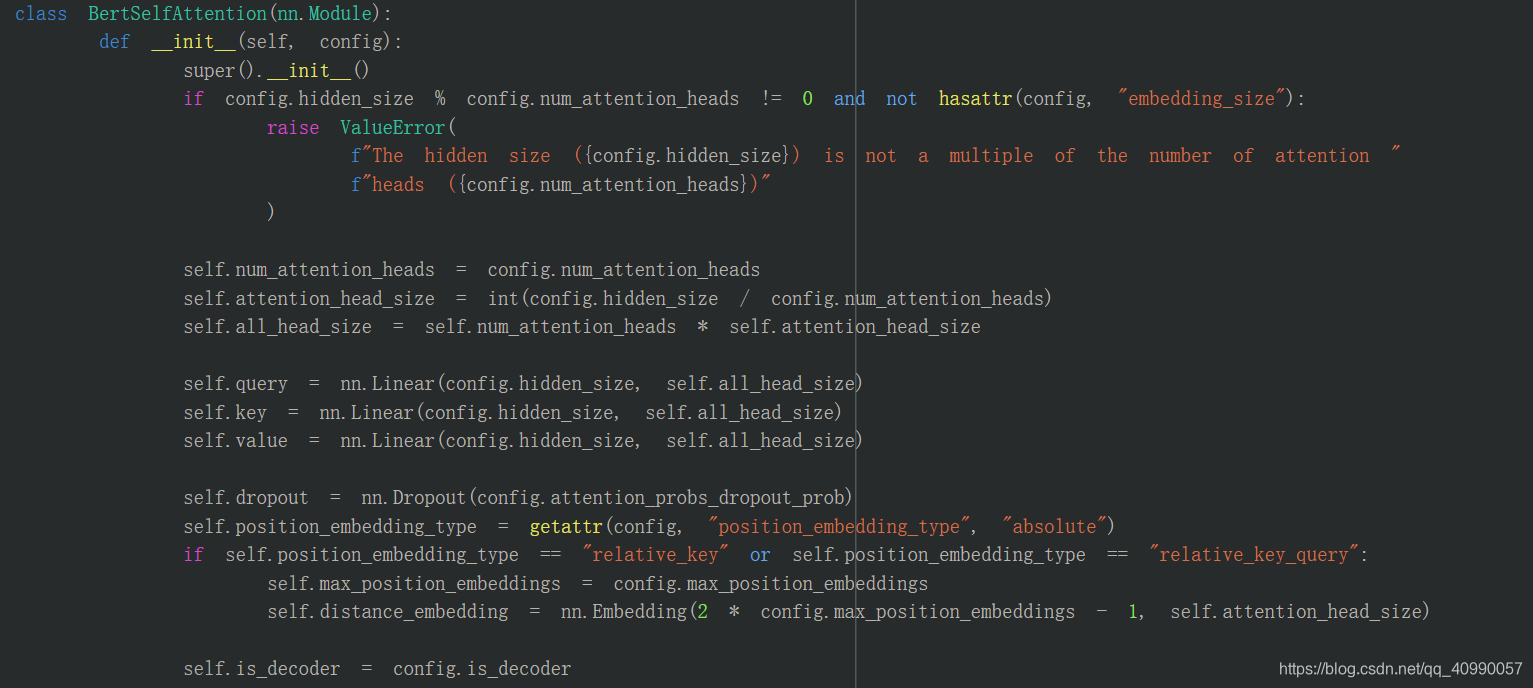
需要初始化一堆东西,包括
- Q、K、V的权重矩阵:在这个地方是多头拼接在一起的
- 跟head有关系的一些参数
- position_embedding(这是个新概念)
整个前向传播过程其实是完成了下面的这个公式的计算:
M
H
A
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
O
MHA(Q, K, V) = Concat(head_1, ..., head_h)W^O
MHA(Q,K,V)=Concat(head1?,...,headh?)WO
h
e
a
d
i
=
S
D
P
A
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
head_i = SDPA(QW_i^Q, KW_i^K, VW_i^V)
headi?=SDPA(QWiQ?,KWiK?,VWiV?)
S
D
P
A
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
(
d
k
)
)
V
SDPA(Q, K, V) = softmax(\frac{QK^T}{\sqrt(d_k)})V
SDPA(Q,K,V)=softmax((?dk?)QKT?)V
教程里提供了一个知乎问答来解释为什么Transformer 需要进行 Multi-head Attention,这张图还挺有说服力的。
(Q、K、V的权重好重要,它就是我们在反向传播要求的东西)
前向传播,首先进行的是KQ相乘。
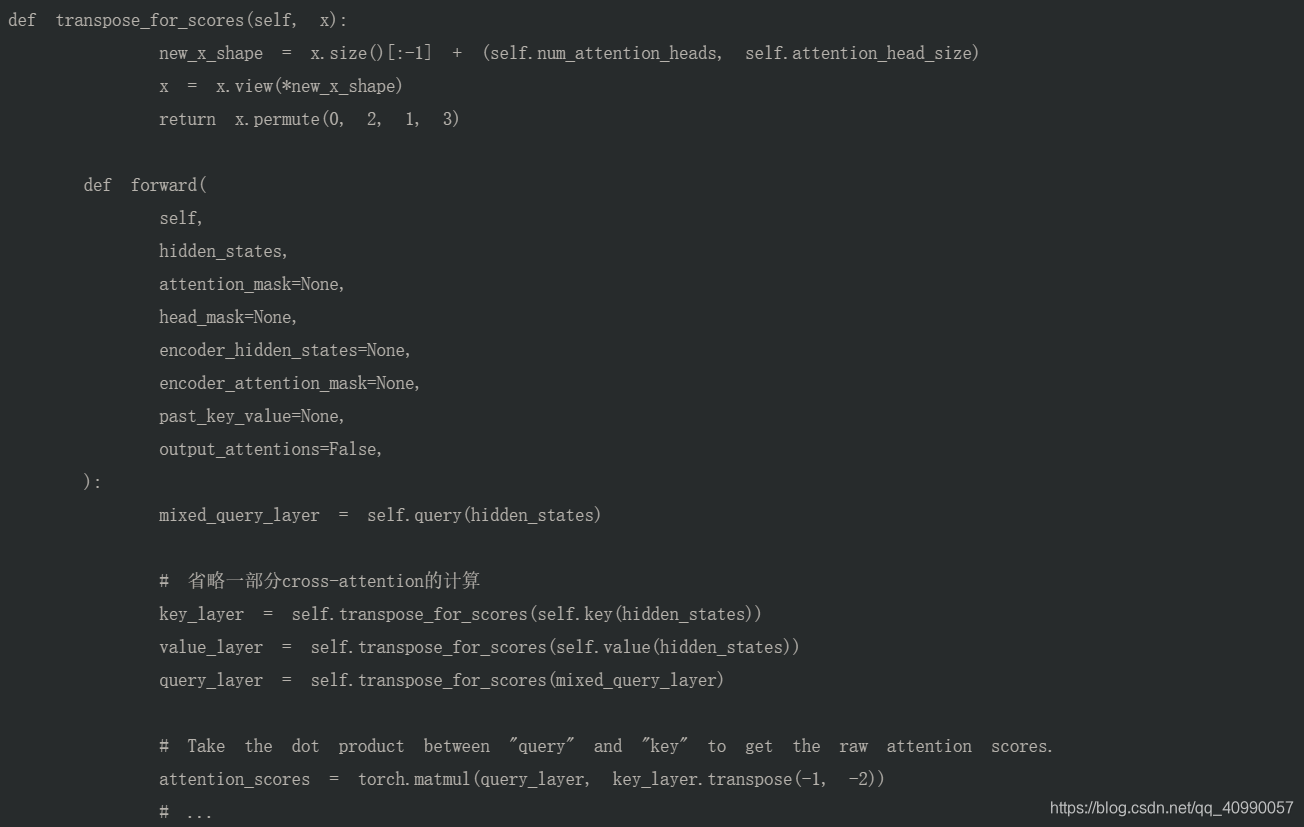
transpose_for_scores 用来把 hidden_size 拆成多个头输出的形状,并且将中间两维转置以进行矩阵相乘;
key_layer/value_layer/query_layer的形状为:(batch_size, num_attention_heads, sequence_length, attention_head_size);
attention_scores 的形状为:(batch_size, num_attention_heads, sequence_length, sequence_length),符合多个头单独计算获得的 attention map 形状。
然后一个奇怪的positional_embedding环节插入其中。
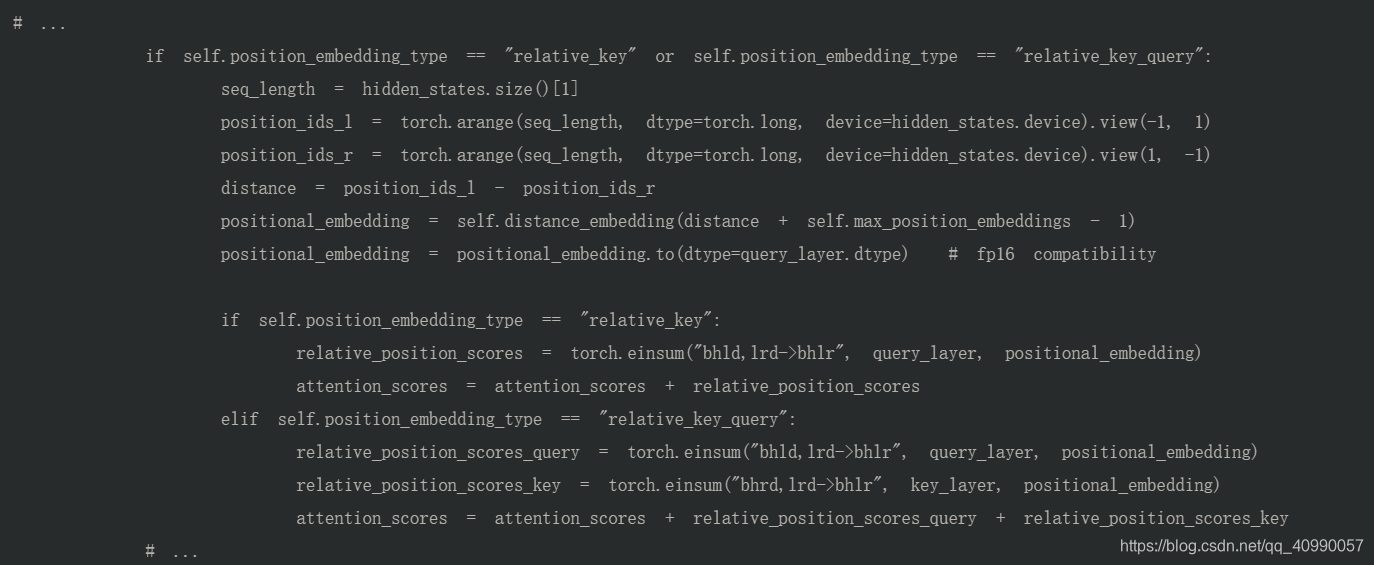
爱因斯坦求和可以看torch.einsum - PyTorch 1.8.1 documentation。
这里,真的很迷惑,为什么要拿一个key相乘的位置编码,加到attention_score上面…暂时没有明白。
然后,就回到
d
k
d_k
dk?scaling环节,并且进行softmax。
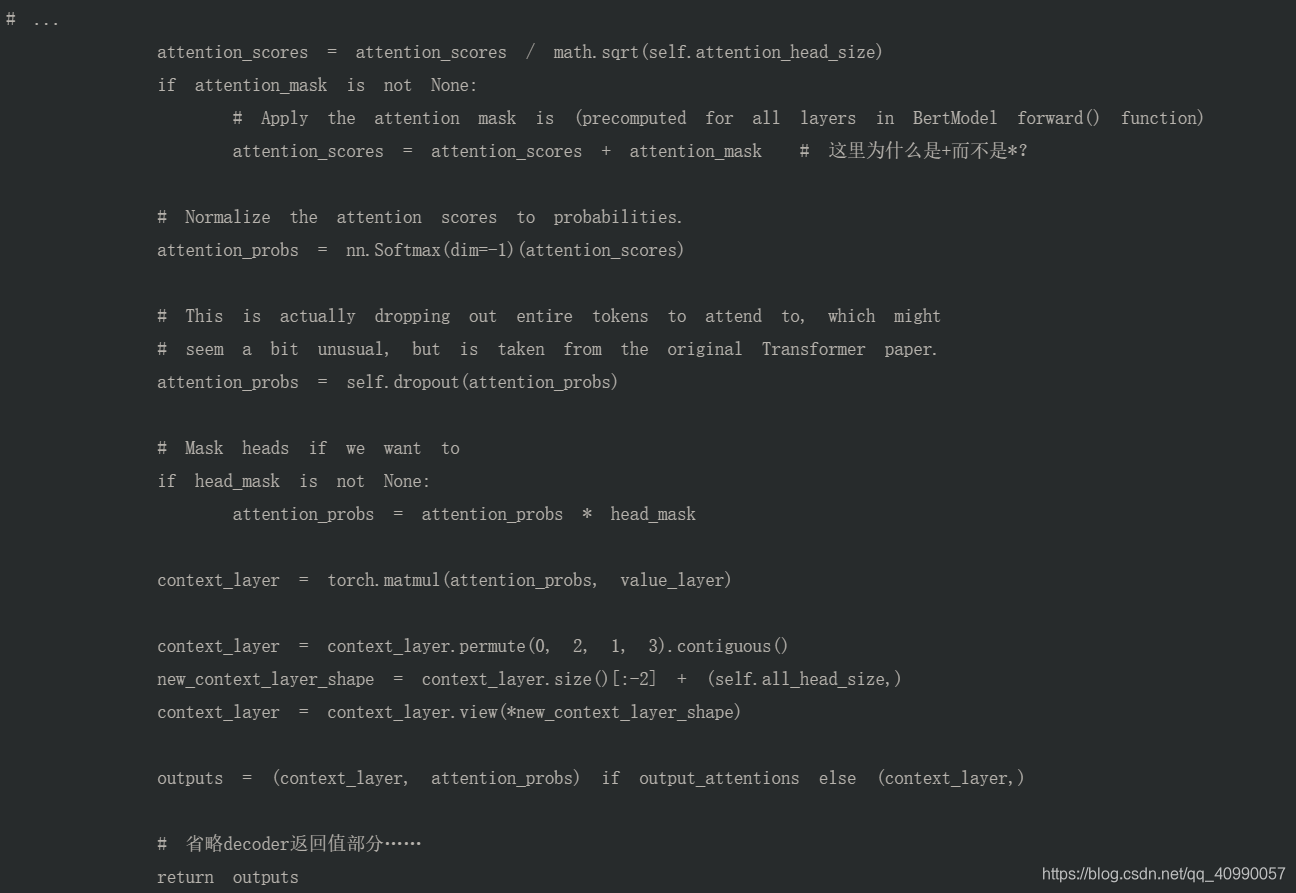
这里需要注意的是,因为此时的attention_mask已经是【将原本为 1 的部分变为 0,而原本为 0 的部分(即 padding)变为一个较大的负数,这样相加就得到了一个较大的负值】后的情况了,所以attention_scores = attention_scores + attention_mask
然后接下来计算context_layer,就是attention矩阵和value矩阵的乘积,大小是(batch_size, num_attention_heads, sequence_length, attention_head_size),需要通过转置和view变成(batch_size, sequence_length, hidden_size)。
3.3.2.3 BertSelfOutput
这里先 Dropout,进行残差连接后再进行 LayerNorm。至于为什么要做残差连接,最直接的目的就是降低网络层数过深带来的训练难度,对原始输入更加敏感。

3.3.2.4 小示例
模型原代码还是不贴了,因为太长了,都在/models/bert/modeling_bert.py里头。
在这里尝试把维度都展示出来,我们还是接着3.2.2的示例往下走,使用3.2.2的embedding对象创建输入
embedding_output = em(
input_ids=inputs['input_ids'],
token_type_ids=inputs['token_type_ids'],
)
经过BertSelfAttention是长这样的
attention = BertSelfAttention(config)
attentions = attention(embedding_output)
中间有几个比较关键的步骤我们可以输出维度
query_layer
torch.Size([1, 12, 8, 64])
key_layer
torch.Size([1, 12, 8, 64])
value_layer
torch.Size([1, 12, 8, 64])
attention_scores
torch.Size([1, 12, 8, 8])
attention_scores after position_embedding
torch.Size([1, 12, 8, 8])
context_layer
torch.Size([1, 12, 8, 64])
context_layer after view
torch.Size([1, 8, 768])
可以看出我们有12个heads,attention_head_size是768/12 = 64,序列长度是8(和前面一致)。
最后output得到的是一个tuple,原因是源代码里头的这句话
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
在这里由于我们没有选择output_attention,所以输出来的tuple长度为1。
(tensor([[[ 0.1615, -0.0821, -0.2474, ..., -0.2377, 0.4743, 0.1453],
[ 0.0598, -0.0785, -0.2833, ..., -0.2624, 0.4579, 0.1072],
[ 0.1561, -0.1007, -0.2056, ..., -0.1864, 0.4867, 0.2053],
...,
[ 0.0437, -0.1405, -0.1998, ..., -0.1890, 0.4860, 0.1330],
[-0.0178, -0.0348, -0.3290, ..., -0.2546, 0.4547, 0.1418],
[ 0.0851, -0.2451, -0.2759, ..., -0.2176, 0.2699, 0.0374]]],
grad_fn=<ViewBackward>),)
接下来再把这个放到BertSelfOutput里头,同时需要把embedding的结果也放进去,因为做LayerNorm的时候需要它。
output = BertSelfOutput(config)
outputs = output(attentions[0],embedding_output)
输出是
tensor([[[-0.1168, 0.1692, -0.3448, ..., -0.1154, -0.4698, 0.5496],
[-1.3732, -0.7462, -1.2374, ..., -0.8050, 0.5632, 0.4623],
[-0.5538, -0.2834, -2.6084, ..., -0.5942, -0.2333, 1.7766],
...,
[-3.3029, -1.8809, -0.9636, ..., -1.2198, 1.9696, -0.0968],
[-0.5714, -0.5979, -0.1277, ..., -0.8183, -0.6932, -0.4036],
[-1.1201, -1.1275, -0.4054, ..., 0.0088, -0.1156, -1.5420]]],
grad_fn=<NativeLayerNormBackward>)
3.3.3 BertIntermediate & BertOutput
3.3.3.1 结构解读
经过Attention层后,要经过一个全连接层。

- 这里的全连接做了一个扩展,以 bert-base 为例,扩展维度为 3072,是原始维度 768 的 4 倍之多
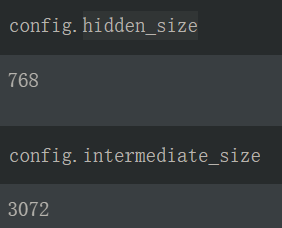
- 这里的激活函数默认实现为 gelu(Gaussian Error Linerar Units(GELUS)当然,它是无法直接计算的,可以用一个包含tanh的表达式进行近似。
关于GELU可以看这个
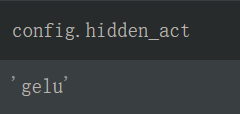
最后要经过一个BertOutput,这是一个全连接 (先把维度变回来)+dropout+LayerNorm,和BertSelfOutput基本一致
3.3.3.2 小示例
详细的模型源代码还是不贴,我们跟着3.3.2.4节的示例往下走。
放进BertIntermediate。
Inter = BertIntermediate(config)
inter = Inter(outputs)
输出是
tensor([[[-0.1037, 0.7917, -0.1693, ..., -0.1463, -0.1669, -0.1694],
[-0.1699, 0.8264, -0.1685, ..., 0.0187, 0.1326, 0.0893],
[-0.1101, 0.1149, -0.0637, ..., -0.1592, -0.1195, -0.1042],
...,
[-0.1512, 1.3281, -0.0801, ..., 0.3684, 0.1983, 0.1093],
[-0.0487, 0.1220, -0.0693, ..., -0.1396, 0.1584, 0.3964],
[-0.1116, -0.1188, -0.0879, ..., -0.1677, 0.4005, -0.0474]]],
grad_fn=<GeluBackward>)
输出的维度是
torch.Size([1, 8, 3072])
再放进BertOutput
output2 = BertOutput(config)
outputs2 = output2(inter,outputs)
输出结果是
tensor([[[-0.1167, 0.1714, -0.1957, ..., -0.1154, -0.5001, 0.7819],
[-1.3913, -0.6122, -1.2364, ..., -0.7952, 0.6087, 0.8476],
[-0.1640, -0.2795, -2.6277, ..., -0.2519, -0.1051, 1.8898],
...,
[-3.3535, -1.6633, -0.6847, ..., -1.5806, 2.0562, -0.0803],
[-0.4254, -0.4370, -0.1962, ..., -0.6597, -0.8291, -0.0311],
[-0.9852, -1.1030, -0.7360, ..., -0.0358, -0.0903, -1.1273]]],
grad_fn=<NativeLayerNormBackward>)
输出的维度是
torch.Size([1, 8, 768])
可以看到维度变回来了。
3.4 BertPooler
3.4.1 结构解读
这一层其实对应了后面的微调了,就是对应下面这张图(但是还没有接最后的softmax)
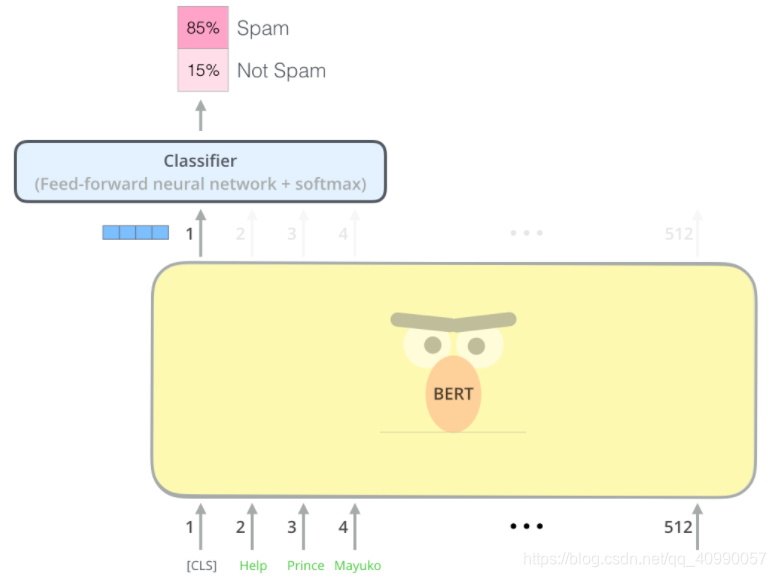
这一层只是简单地取出了句子的第一个token,即[CLS]对应的向量,然后过一个全连接层和一个激活函数后输出:(这一部分是可选的,因为pooling有很多不同的操作)
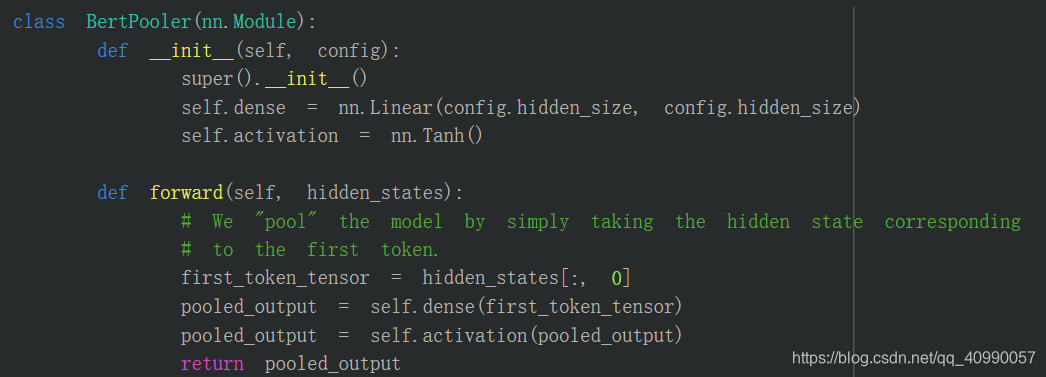
3.4.2 小示例
让我们接着上面3.3.3.2的示例往下走,把输出的结果输入到一个BertPooler里头。
po = BertPooler(config)
result = po(outputs2)
输出结果的维度是
torch.Size([1, 768])
至此我们的句子"Hello, my dog is cute",就经过了Embedding,单层的Encoder,得到了最终的结果。
4 流程小结
以"Hello, my dog is cute"为例,绘制了流程图,展示了BERT模型中的计算流程。