Conformer: Local Features Coupling Global Representations for Visual Recognition
论文: conformer论文
代码: comformer源码-torch
1. Abstract
在卷积网络中,卷积操作非常擅长捕捉局部特征信息,但是对于捕捉图像中的全局特征信息就非常困难;对于transformer,级联的self-attention机制可以捕捉到长距离的特征信息,但是又会弱化掉局部特征信息。其实这也是卷积和Transformer机制各自的优缺点,如何解决呢?论文中的思想其实很容易想到,既然单一的卷积或者Transformer机制都无法很好的获得图像的feature information,那么两个联合起来呢?于是,论文中提出一种混合网络,即Conformer,充分利用到卷积和transformer机制的优点。Conformer依赖于Feature Coupling Unit(FCU)特征耦合单元,以一种交互式的方式去融合convolutional得到的local feature和transformer得到的global feature。Conformer采用并行式结构,以获取最大程度上的local features和global features。实验结果上,在ImageNet上的Top-1相比DeiT-B高出2.3%;在COCO数据集上的检测和分割任务上,相比于ResNet-101作为backbone,分别高出3.7个点和3.6个点。
2. Introduction
这部分我就挑一些重点来讲,其他的就不过多提及。
关于卷积网络不太能够捕捉到global feature的缺点,一个直观的解决方法就是扩大其receptive field(如dilated convolution, deformable convolution等),作者说这样会破坏pooling层的操作,其实这个原因我不太赞同,因为有的网络模型是Fully convolutional的,哪来的pooling层呢?虽然使用膨胀卷积或者可变形卷积可以扩大感受野,但是卷积的本质依旧没有改变,只是相对于普通卷积,可以获得稍微多一点的global feature;最近的ViT模型,将输入图像进行拆分成nxn和patches,加上Positional Encoding得到一系列的tokens,然后多次应用Multi-head self-attention机制和MLP,可以获得长距离的feature。但是,还是那个问题,没有什么模型是绝对好的,那么ViT的问题就在于会模糊前景和背景的local feature,如下图中的c和g:

图像中的孔雀(foreground)与树叶(background)的边缘信息已经丢失了。
同样的,普通卷积所获取的global feature也是很少的,如上图中的a和e,无论是网络的浅层还是深层,图中的孔雀轮廓并没有完整的显示出来。
论文中提出的Conformer就是为了解决这种问题:convolution分支基于ResNet,transformer分支基于ViT。联合卷积分支的local feature和Transformer分支的global feature来获取更好的特征表示。到这里,另一个问题:卷积和Transformer所提取到的feature是存在差异的,不仅是shape的不匹配而且语义上也是存在差异。那么如何解决呢?使用FCU作为桥接两个分支的特征:
1)1x1 convolution用来调整channel的维度也就是C;
2) down/up sampling用来调整feature的分辨率也就是H和W;
3)Batch Norm和Layer Norm用来调整feature values。
并且,FCU模块被嵌入到网络的每个block中,更好的消除两种机制提取到的feature的语义差异。
论文的贡献在于:
1) 提出一种双向网络Conformer,最大程度上的获取local feature和global feature;
2) 提出的Feature Coupling Unit(FCU),以一种交互式的方式去fuse卷积分支得到的feature以及Transformer提取的feature;
3) 在相当可观的参数量,计算量的前提下,Conformer的性能显著优于CNN和Visual Transformer,并且有潜力成为一个通用的backbone网络。
3. Related Work
相关工作就不展开了,说来说去就那些东西。。。。
4. Conformer
4.1. Overview
局部特征和全局特征在计算机视觉任务中得到了广泛的研究。局部特征是局部图像邻域的紧凑向量表示,一直是许多计算机视觉算法的组成部分。全局表示包括轮廓表示、形状描述符和长距离上的对象表示等等。
在深度学习中,CNN通过卷积操作分层收集局部特征,并保留局部线索作为特征。Vision Transformer被认为可以通过级联的Self-Attention模块以一种soft的方式在压缩的patch embedding之间聚合全局表示。
为了利用局部特征和全局表示,作者设计了一个并发网络的结构Conformer,如下图所示。考虑两种特征的互补性,作者将来自Vision Transformer分支的全局特征送入CNN中,以增强CNN分支的全局感知能力。
类似的,将来自CNN分支的局部特征送入到Vision Transformer中,以增强Vision Transformer分支的局部感知能力。这样的过程构成了interaction的作用。
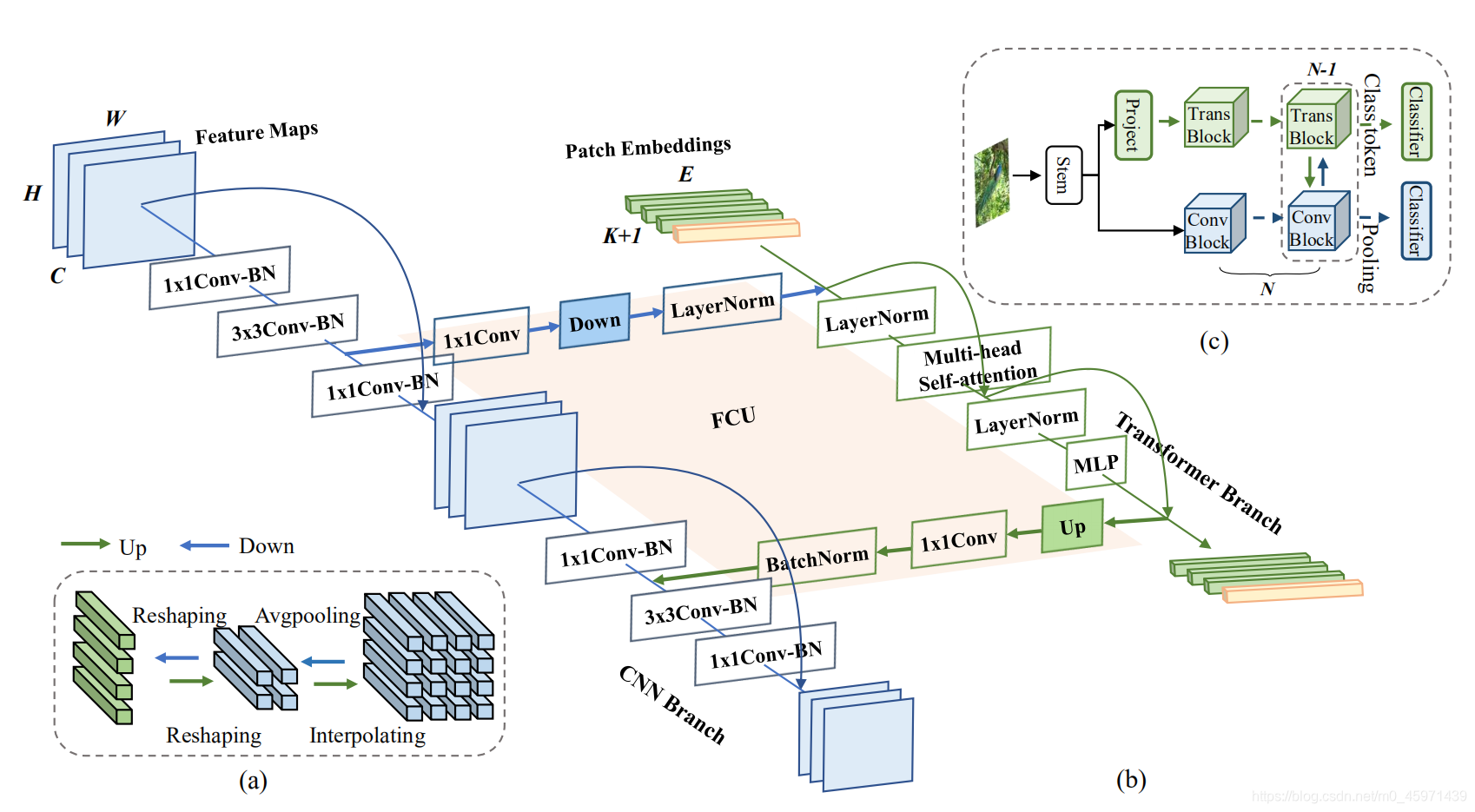
网络的整体流程图:a)对于conv feature maps和Transformer中的patch embeddings在空间维度上的转换(H, W), conv feature map通过下采样(Avg pool)得到patch embeddings,反之通过上采样(Interpolating);b)Conformer的具体细节,conv分支中每一个conv block包括:1x1 conv, 3x3conv, 1x1 conv(这里的每一个卷积都有BN+GELU高斯误差的Relu);Transformer分支中每一个Trans block包括:layer norm -> Multi-head Self-attention -> short cut -> Layer norm -> MLP -> short cut 。具体细节以及怎么实现的在代码部分作讲解。
c) 网络整体流程,输入图像经过一个stem block(s=2的7x7conv,卷积核个数为64;3x3,s=2的最大池化),进行两个并行分支网络:conv分支,Transformer分支,两个分支的最后都会有一个class head,得到两个分支的classifier。在训练时,使用两个CE loss进行BP,两个分支同时训练,并且loss的重要性程度相同;在推理时,两个分类器的预测结果进行加和。
4.2. CNN Branch
关于卷积分支,作者分为4个stage,如下表:

类似于ResNet,每个Stage中包括多个convolution block,每一个convolution block又包括nc个bottleneck,每个bottleneck中包括:1x1conv,3x3conv,1x1conv。并且只在第一个convolution block中的bottleneck数设置为1,其余的都设置为≥2。
在进行conv分支的同时,除第一个bottleneck之外,每一个的bottleneck中的3x3conv输出的特征图都会转换到Transformer分支进行feature fusion。
4.3. Transformer Branch
基于ViT模型来设计Transformer分支,包括N个Transformer blocks。如4.1中的图b,每一个Transformer blocks都包含:Multi-head Self-Attention以及MLP block(一个升维的FC层和一个降维的FC层),其中还使用Layer Norm和short cut。
关于token,对于stem block中输出的特征图进行s=4的4x4conv,卷积核个数为384,得到14x14个patch embeddings,每个embedding的维度是384,加上一个class token,由于卷积分支中的特征图会转换到transformer分支中进行feature fusion,所以不再设计PE。tensor的shape具体变换如下:
[N, 64, 56, 56] -> [N, 384, 14, 14] -> [N, 196, 384] + [N, 1, 384] -> [N, 197, 384]
关于Feature Coupling Unit:
conv分支输出的特征图shape为CxHxW,而transform分支输出的patch embedding的shape为(K+1)xE,K表示图像的patches数,1为class token,E为patch的维度。
1)当conv分支的feature map -> trans blocks
首先使用1x1卷积进行channel维度的调整,将C调整到384(或Conformer-B中的768);
再经过下采样将H和W调整到14x14(使用最大池化完成);
最后使用layer norm调整最后一个维度上的feature values也就是384所在的那个维度。
2)当transformer分支的patch embedding-> conv blocks
论文中的顺序:双线性插值进行上采样,1x1conv调整channel,Batch Norm调整feature values。
但是代码中的顺序是:1x1conv -> BN -> GELU -> Up sampling
关于实验结果的分析以及结论不再说明,感兴趣的可以去看看原论文。
题外话:关于CNN + Transformer的结合,在去年DETR出来之后,我就想到了,以后肯定会出现CNN + Transformer的结合,用来做图像分类也好,目标检测也好,亦或者是语义分割等CV任务。因为这就好比自动驾驶领域中的摄像头+LiDAR的组合,摄像头的检测虽然快,但是对于复杂环境的目标检测以及实现高精度的检测而言,仅仅靠摄像头是完成不了的;那么加入LiDAR激光雷达,可以实现高精度的复杂环境下的检测,但是检测速度又不够,因此两者的联合使用可以实现更好的检测效果。和Conformer的思想是相同的,就好比
一个瞎子背一个瘸子过马路,充分发挥各自的优点,相互依靠,相互促进。
虽然我能想到可以做这种结合,但是仅凭我一人之力是不可能完成的,后期的代码编写以及优化,实验结果的设计等等,可惜没有一个好的团队,唉。。。
后面我会继续更新Conformer源码的解析。