使用决策树预测泰坦尼克号幸存者实例
代码来自《scikit-learn机器学习:常用算法原理及编程实战》P122
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
一、数据获取
数据集来自 https://www.kaggle.com/c/titanic
导入训练集和测试集:train.csv、test.csv
二、数据探索
数据质量分析(缺失值、异常值、一致性)
查看训练数据前5行
train.head()
 查看数据各列是否有缺失值
查看数据各列是否有缺失值
train.info()
 可以看出age和cabin列有缺失
可以看出age和cabin列有缺失
查看数据整体异常情况
train.describe()
 发现Age列不仅有缺失,且最小值为0.42,不符合常规
发现Age列不仅有缺失,且最小值为0.42,不符合常规
分析特征
PassengerId:乘客的ID号,这是个顺序编号,用来唯一地标识一名乘客。这个特征与幸存与否无关,我们不使用这个特征
Survived:1表示幸存,0表示遇难。这个是我们的标注数据
Pclass:仓位等级,是很重要的特征。看过电影的读者都知道,高仓位登记的乘客能更快的到达甲板,从而更容易获救
Name:乘客名字,具有可解释性,这个和幸存与否无关,我们会丢弃这个特征
Sex:乘客性别,看过电影的读者都知道,由于救生艇数量不够,船长让妇女和儿童先上救生艇。所以这也是个很重要的特征
Age:乘客年龄,儿童会优先上救生艇,身强力壮者幸存概率也会更高一些
SibSp:兄弟姐妹同在船上的数量
Parch:同船的父辈人员数量
Ticket:乘客票号
Fare:乘客的体热指标
Cabin:乘客所在的船舱号。实际上这个特征和幸存与否有一定关系,比如最早被水淹没的船舱位置,其乘客的幸存概率要低一些。但由于这个特征有大量的丢失数据,而且没有更多的数据来对船舱进行归类,因此我们丢弃这个特征的数据。
Embarked:乘客登船的港口。我们需要把港口数据转换为数值型数据
三、数据预处理
通过数据探索,我们需要对数据进行一些预处理,包括:
- 提取Surived列的数据作为模型的标注数据
- 丢弃不需要的特征数据
- 对数据进行转换,以便模型处理。比如性别数据,我们需要转换为0和1
- 处理缺失数据,比如年龄这个特征,有很多缺失的数据
- 处理异常数据,比如年龄,如果出现小数一律向下取整处理
def read_dataset(fname):
#指定第一列作为行索引
data = pd.read_csv(fname,index_col=0)
#丢弃无用的数据
data.drop(['Name','Ticket','Cabin'],axis=1,inplace=True)
#处理性别数据
data['Sex'] = (data['Sex']=='male').astype('int')
#处理年龄数据
data['Age'] = np.floor(data['Age'])
#处理登船港口数据
labels = data['Embarked'].unique().tolist()
data['Embarked'] = data['Embarked'].apply(lambda n:labels.index(n))
#处理缺失数据
data = data.fillna(0)
return data
train = read_dataset('../input/titanic/train.csv')
预处理完后,如图

四、数据建模
首先,把Survived列提取出来作为标签,然后在原数据集中将其丢弃。同时把数据集分为训练数据集和交叉验证数据集。
from sklearn.model_selection import train_test_split
y = train['Survived'].values
X = train.drop(['Survived'],axis=1).values
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
print('train dataset:{0};test dataset:{1}'.format(X_train.shape,X_test.shape))
结果如图
 接下来,使用scikit-learn的决策树模型对数据进行拟合
接下来,使用scikit-learn的决策树模型对数据进行拟合
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(X_train,y_train)
train_score = clf.score(X_train,y_train)
test_score = clf.score(X_test,y_test)
print('train score:{0};test score:{1}'.format(train_score,test_score))
输出结果
 从输出数据中可以看出,针对训练样本评分很高,但针对交叉验证数据集评分比较低,两者差距较大。很明显,这是过拟合的特征。解决决策树过拟合的方法是剪枝,包括前剪枝和后剪枝。不幸的是,scikit-learn不支持后剪枝,但提供一系列的模型参数b进行前剪枝。例如,我们通过max_depth参数限定决策树的深度,当决策树达到限定的深度时,就不再进行分裂了。这样就可以在一定程度熵避免过拟合。
从输出数据中可以看出,针对训练样本评分很高,但针对交叉验证数据集评分比较低,两者差距较大。很明显,这是过拟合的特征。解决决策树过拟合的方法是剪枝,包括前剪枝和后剪枝。不幸的是,scikit-learn不支持后剪枝,但提供一系列的模型参数b进行前剪枝。例如,我们通过max_depth参数限定决策树的深度,当决策树达到限定的深度时,就不再进行分裂了。这样就可以在一定程度熵避免过拟合。
五、优化模型参数
问题来了,难道我们要手动一个个地去试参数,然后找出最优的参数吗?一个最直观的解决办法就是选择一系列参数的值,然后分布计算用指定参数训练出来的模型的评分数据。还可以把两者的关系画出来,直观地看到参数值与模型准确度的关系。
以模型深度max_depth为例,我们先创建一个函数,它使用不同的模型深度训练模型,并计算评分数据
#参数选择 max_depth
def cv_score(d):
clf = DecisionTreeClassifier()
clf.fit(X_train,y_train)
tr_score = clf.score(X_train,y_train)
cv_score = clf.score(X_test,y_test)
return (tr_score,cv_score)
接着构造参数范围,在这个范围内分别计算模型评分,并找出评分最高的模型所对应的参数。
depths = range(2,15)
scores = [cv_score(d) for d in depths]
tr_score = [s[0] for s in scores]
cv_score = [s[1] for s in scores]
#找出交叉验证数据集评分最高的索引
best_score_index = np.argmax(cv_scores)
best_score = cv_scores[best_score_index]
best_param = depths[best_score_index]
print('best param:{0};best score:{1}'.format(best_param,best_score))
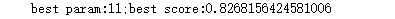
可以看出,最优参数是11,最优分数是0.8268
我们可以将模型参数和模型评分画出来,直观地观察其变化规律
#将模型参数和模型评分画出来,直观地观察其变化规律
plt.figure(figsize=(6,4),dpi=144)
plt.grid()
plt.xlabel('max depth of decision tree')
plt.ylabel('score')
plt.plot(depths,cv_scores,'.g-',label='cross-validation score')
plt.legend()

同理,参数min_impurity_split也可如此;
但,我们介绍的模型参数优化方法有两个问题。
其一,数据不稳定,每次对数据集划分后,选择出来的模型参数就不是最优的了。
其二,不能一次选择多个参数,例如,我们想要把max_depth和min_samples_leaf两个结合起来的最优参数就没法实现。
对于问题一,我们可以多次计算,求平均值来解决。对于问题二,可以使用scikit-learn的sklearn.model_selection包中的模型选择和评估的工具,例如GridSearchCV。这里不做过多阐述。