������Ӿ������ѧϰϵ�в��ʹ�����
��������Ӿ������ѧϰ�����Է�����(һ)
��ʧ������̽��
�����ǻص���ʧ������һ�㶨��
L
=
1
N
��
i
L
i
(
f
(
x
i
,
W
)
,
y
i
)
L=\frac{1}{N}\sum_iL_i(f(\bm x_i,\bm W),y_i)
L=N1?i��?Li?(f(xi?,W),yi?)��ô,������һ��
W
\bm W
Wʹ����ʧ
L
=
0
L=0
L=0,���
W
\bm W
W�Ƿ�Ψһ?
�����������Է�����
f
1
(
x
,
W
1
)
=
W
1
x
,
f
2
(
x
,
W
2
)
=
W
2
x
\bm f_1(\bm x,\bm W_1)=\bm W_1 \bm x,\bm f_2(\bm x,\bm W_2)=\bm W_2 \bm x
f1?(x,W1?)=W1?x,f2?(x,W2?)=W2?x,����
W
2
=
2
W
1
\bm W_2=2 \bm W_1
W2?=2W1?,����һ������(����������ı�ǩΪcar),��֪������1�Ĵ�ֽ�����±���ʾ:
| ��ǩ | bird | cat | car |
|---|---|---|---|
| �÷� | 3.1 | -2.6 | 4.3 |
���ݶ���֧����������ʧ�Ķ���
L
i
=
��
j
��
y
i
max
?
(
0
,
s
i
j
?
s
y
i
+
1
)
L_i=\sum_{j\neq y_i}\max(0,s_{ij}-s_{y_i}+1)
Li?=j��?=yi?��?max(0,sij??syi??+1)���Ѽ����������1����ʧֵΪ0��
��
W
2
=
2
W
1
\bm W_2=2 \bm W_1
W2?=2W1?���������������2�Ĵ�ֽ��:
| ��ǩ | bird | cat | car |
|---|---|---|---|
| �÷� | 6.2 | -5.2 | 8.6 |
ͬ����,���ݶ���֧����������ʧ�Ķ���,���ǿ��Լ����������2����ʧֵҲΪ0��
����һ��,���ǾͿ��Իش����������������:������һ��
W
\bm W
Wʹ����ʧ
L
=
0
L=0
L=0,���
W
\bm W
W������Ψһ�ġ���ô,��Ȼ��������������������ͬ����ʧֵ0,Ӧ��ѡ���������������е���һ����?
������
Ϊ�˽���������������,�˴�����������ĸ������ʧ����������
L
=
1
N
��
i
L
i
(
f
(
x
i
,
W
)
,
y
i
)
+
��
R
(
W
)
L=\frac{1}{N}\sum_iL_i(f(\bm x_i,\bm W),y_i)+\lambda R(\bm W)
L=N1?i��?Li?(f(xi?,W),yi?)+��R(W)����,
1
N
��
i
L
i
(
f
(
x
i
,
W
)
,
y
i
)
\frac{1}{N}\sum_iL_i(f(\bm x_i,\bm W),y_i)
N1?��i?Li?(f(xi?,W),yi?)����������ʧ,��������ģ�͵�Ԥ������ѵ��������ʵ��ǩ֮���ƥ��̶�;
��
R
(
W
)
\lambda R(\bm W)
��R(W)����������ʧ,
R
(
W
)
R(\bm W)
R(W)��һ����Ȩֵ�йء���ѵ���������صĺ���,
��
\lambda
����һ������������ʧ������ʧ����ռ�ı��صij�����������������ʧ���Ա���ģ����ѵ������ѧϰ�á�̫�á�,�������������һ���̶��ϱ�����������,���ģ�͵ķ������ܡ�
���������ǶԳ�����
��
\lambda
���������ۡ�������ָ�����ڿ�ʼѧϰ����֮ǰ����ֵ�IJ���,��������ͨ��ѧϰ�õ�,����������ѵ����batch size��epochs��learning rate��Ҳ���dz�������������һ�㶼���ģ������������Ҫ��Ӱ�졣�����������ʧ����,��
��
=
0
\lambda=0
��=0ʱ,�Ż��������������ʧ�й�;��
��
=
��
\lambda=\infty
��=��ʱ,�Ż������������ʧ��,������Ȩ����ʧ,��ʱϵͳ���Ž�Ϊ
W
=
0
\bm W=\bm 0
W=0��
���dz��õ�������֮һ��L2�����L2������Ķ���Ϊ
R
(
W
)
=
��
k
��
l
W
k
,
l
2
R(\bm W)=\sum_k \sum_l \bm W^2_{k,l}
R(W)=k��?l��?Wk,l2?������һ������
x
=
[
1
1
1
1
]
\bm x=\begin{gathered}\begin{bmatrix} 1 \\ 1 \\ 1 \\ 1 \end{bmatrix}\end{gathered}
x=?????1111???????������1
W
1
T
=
[
1
0
0
0
]
\bm W_1^T=\begin{gathered}\begin{bmatrix} 1 & 0 & 0 & 0 \end{bmatrix}\end{gathered}
W1T?=[1?0?0?0?]?������2
W
2
T
=
[
0.25
0.25
0.25
0.25
]
\bm W_2^T=\begin{gathered}\begin{bmatrix} 0.25 & 0.25 & 0.25 & 0.25 \end{bmatrix}\end{gathered}
W2T?=[0.25?0.25?0.25?0.25?]?���������
W
1
x
=
W
2
x
=
1
\bm W_1 \bm x=\bm W_2 \bm x=1
W1?x=W2?x=1����ʧ����������������������������ʧ����ȵġ�Ϊ�˱Ƚ�������������,���ǿ��Լ������ǵ�������ʧ���ɶ���ɵ�
R
(
W
1
)
=
1
2
+
0
2
+
0
2
+
0
2
=
1
R(\bm W_1)=1^2+0^2+0^2+0^2=1
R(W1?)=12+02+02+02=1
R
(
W
2
)
=
0.2
5
2
+
0.2
5
2
+
0.2
5
2
+
0.2
5
2
=
0.25
R(\bm W_2)=0.25^2+0.25^2+0.25^2+0.25^2=0.25
R(W2?)=0.252+0.252+0.252+0.252=0.25������2��������ʧ��СһЩ,��������1������ʧ���ڷ�����2,�������ѡ�������2��
L2���Դ���ֵȨֵ���гͷ�,��ɢȨֵ,����������������ά�ȵ�������������,����ǿ�ҵ���������������ά��������������ģ������ƫ�á�
����L2������֮��,���õ�����������L1������
R
(
W
)
=
��
k
��
l
�O
W
k
,
l
�O
R(\bm W)=\sum_k \sum_l |\bm W_{k,l}|
R(W)=k��?l��?�OWk,l?�O�͵������� (Elastic net) ������
R
(
W
)
=
��
k
��
l
��
�O
W
k
,
l
�O
+
��
W
k
,
l
R(\bm W)=\sum_k \sum_l \alpha|W_{k,l}|+\beta \bm W_{k,l}
R(W)=k��?l��?���OWk,l?�O+��Wk,l?
�����Ż�
����ģ����˵,������ʧ���� L L L��һ������� W \bm W W�йصĺ���,���Բ����Ż���Ŀ������ҵ�ʹ��ʧ���� L L L�ﵽ���ŵ�������� W \bm W W����ֱ�ӵķ�������ʹ ? L ? W = 0 \frac{\partial L}{\partial \bm W}=0 ?W?L?=0��ͨ�� L L L����ʽ�Ƚϸ���,����ͨ����ʽֱ����� W \bm W W����һ����ⷽ����ʹ���ݶ��½��㷨�������� W \bm W W���ݶ��½�����һ���㷺��������С��ģ�����IJ����Ż��㷨���ݶ��½���ͨ����ε���,����ÿһ������С���ɱ�����������ģ�͵IJ������ݶ��½����㷨����Ϊ:
while True:
????Ȩֵ���ݶ� �� �����ݶ�(��ʧ, ѵ������, Ȩֵ)
????Ȩֵ �� Ȩֵ - ѧϰ�� �� Ȩֵ���ݶ�
����������һ��ɽ��,���ٵ���ɽ�ŵ�һ�����Ծ���������ķ������¡��ݶ��½��е�һ����Ҫ������ÿһ���IJ���,��ȡ���ڳ�����ѧϰ�� (learning rate)�����ѧϰ��̫��,�㷨��Ҫ���������ĵ�����������,�⽫��ķѴ�����ʱ�䡣������˵,���ѧϰ��̫��,�ᵼ���㷨��ɢ��
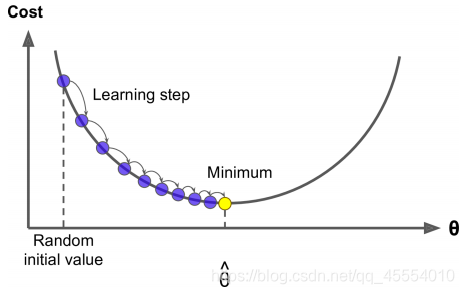
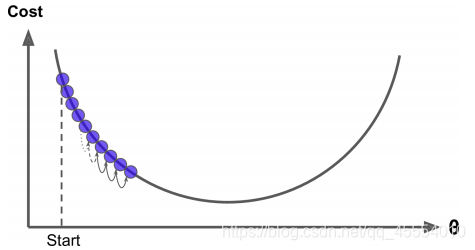
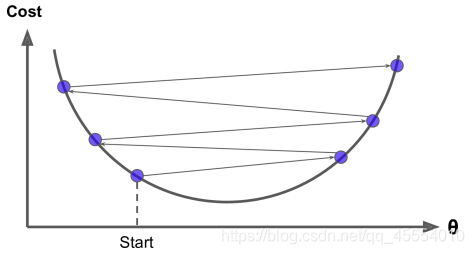
�����ݶ������ַ�������һ�ַ�������ֵ��
d
L
(
w
)
d
w
=
lim
?
h
��
0
L
(
w
+
h
)
?
L
(
w
)
h
\frac {\mathrm{d}L(w)}{\mathrm{d}w}=\lim_{h��0} \frac{L(w+h)-L(w)}{h}
dwdL(w)?=h��0lim?hL(w+h)?L(w)?����
h
h
h��һ����С����������,���㺯��
L
(
w
)
=
w
2
L(w)=w^2
L(w)=w2��
w
=
1
w=1
w=1�����ݶ�
d
L
(
w
)
d
w
=
lim
?
h
��
0
L
(
w
+
h
)
?
L
(
w
)
h
��
L
(
1
+
0.0001
)
?
L
(
1
)
0.0001
=
2.0001
\frac {\mathrm{d}L(w)}{\mathrm{d}w}=\lim_{h��0} \frac{L(w+h)-L(w)}{h}��\frac{L(1+0.0001)-L(1)}{0.0001}=2.0001
dwdL(w)?=h��0lim?hL(w+h)?L(w)?��0.0001L(1+0.0001)?L(1)?=2.0001����,ʹ����ֵ�������ݶȼ��������Ҳ���ȷ�����ǻ�����ʹ�õڶ��ַ��������������������ݶȡ�
���Լ��㺯��
L
(
w
)
=
w
2
L(w)=w^2
L(w)=w2��
w
=
1
w=1
w=1�����ݶ�Ϊ��
��
L
(
w
)
=
2
w
\triangledown L(w)=2w
��L(w)=2w
��
w
=
1
L
(
w
)
=
2
\triangledown _{w=1}L(w)=2
��w=1?L(w)=2���������ص��Ǿ�ȷ���ٶȿ�,���ǵ��������Ƶ����׳�����
����ʵӦ����,����ͨ��ʹ�ý������������ݶ�,���Ⲣ����ζ����ֵ��û������֮�ء���ֵ�������ݶ�һ�����ڽ����������ݶȵ���ȷ��У�顣
�����������������ʧ����
L
(
W
)
=
1
N
��
i
=
1
N
L
i
(
x
i
,
y
i
,
W
)
+
��
R
(
W
)
L(\bm W)=\frac{1}{N}\sum_{i=1}^{N}L_i(\bm x_i,y_i,\bm W)+\lambda R(\bm W)
L(W)=N1?i=1��N?Li?(xi?,yi?,W)+��R(W)�������ݶ�Ϊ
��
W
L
(
W
)
=
1
N
��
i
=
1
N
��
W
L
i
(
x
i
,
y
i
,
W
)
+
��
��
W
R
(
W
)
\triangledown _{\bm W}L(\bm W)=\frac{1}{N}\sum_{i=1}^{N}\triangledown_{\bm W}L_i(\bm x_i,y_i,\bm W)+\lambda \triangledown_{\bm W}R(\bm W)
��W?L(W)=N1?i=1��N?��W?Li?(xi?,yi?,W)+����W?R(W)
�ݶ��½��㷨��Ȼ��ȷ,���ǵ�
N
N
N�ܴ�ʱ,Ȩֵ���ݶȵļ������ܴ�����ݶ��½��㷨��һ����֮�෴�ļ��ˡ�����ݶ��½��㷨ÿһ����ѵ���������ѡ��һ������,���ҽ����ڸ������������ݶ�,��:
while True:
????���� �� ��ѵ�����ݲ���(ѵ������, 1)
????Ȩֵ���ݶ� �� �����ݶ�(��ʧ, ����, Ȩֵ)
????Ȩֵ �� Ȩֵ - ѧϰ�� �� Ȩֵ���ݶ�
�������㷨�ĵ����ٶȿ��˺ܶ�,���������㷨���������,����������ѵ�����ܻ�����ܶ�����,������ÿһ�ε����������������Ż�����,���Dz��ϵ���������,�����������������������½�,���ջ�dz��ӽ���Сֵ������ʹ����������Сֵ,���ɻ����������,��Զ����ֹͣ������ݶ��½��㷨ͣ�����IJ���ֵ�϶����㹻�õ�,�����������ŵġ�
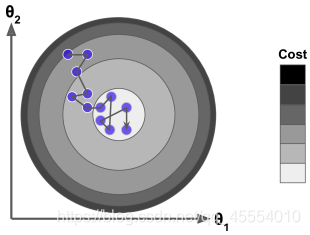
С�����ݶ��½��㷨����һ���ݶ��½��㷨����ÿһ����,��ͬ�������ݶ��½�(����������ѵ����)������ݶ��½�(������ijһ������),С�����ݶ��½�ÿ�����ѡ��
m
m
m���������С���������ݼ�,������ʧ�������ݶ�,��:
while True:
????���� �� ��ѵ�����ݲ���(ѵ������, ������С)
????Ȩֵ���ݶ� �� �����ݶ�(��ʧ, ����, Ȩֵ)
????Ȩֵ �� Ȩֵ - ѧϰ�� �� Ȩֵ���ݶ�
����� m m mͬ����һ��������,ͨ��ʹ��2��������Ϊ������С,��32��64��128�ȡ�