����ѧϰѵ��Ӫ-�������ع�ķ���Ԥ��ѧϰ�ʼ�
��ѧϰ�ʼ�Ϊ�������������ƻ�����ѧϰѵ��Ӫ��ѧϰ����,ѧϰ����
ѧϰ֪ʶ���Ҫ
- �˽����ع������
- �������ع��sklearn��������,��Ӧ�õ��β�����ݼ�Ԥ��
- �����ݶ��½�,ʵ��һ�ּ����ع�ģ��
ѧϰ����
-
�������ع��Ǽලѧϰ�������������⡣����ڻع�����,�������������ǻ���һЩ���Ϊ��ɢֵ�����⡣����,���ݸ�������Ԥ�ⷿ�ݼ۸��ǻع�����,�����ݸ�������Ԥ����Ƿ���ij�ּ����Ƿ������⡣
-
���ʹ��ʹ�����Իع�����������,�����ܵ�����������Ӱ��ʹ�÷������ϴ�,�����Իع������ᳬ��[0,1]�ķ�Χ
-
ʹ��logistic�ع�,����躯������:
h �� ( x ) = g ( �� T x ) g ( z ) = 1 1 + e ? z h_{\theta}(x)=g(\theta^Tx) \\g(z)=\frac{1}{1+e^{-z}} h��?(x)=g(��Tx)g(z)=1+e?z1?
���� g ( z ) g(z) g(z)��ΪSigmoid�����ûع麯���������������Ϊ P ( y = 1 �O x ; �� ) P(y=1|x;\theta) P(y=1�Ox;��)
-
ʹ��h(x)=0.5��x��������߽���,���Ǽ��躯��������,ȡ���ڲ����������ݼ���
-
ʹ���ݶ��½������Ե������ع�IJ���,�������Ϊ
J ( �� ) = 1 m �� i = 1 m c o s t ( h �� ( x ( i ) , y ( i ) ) ) J(\theta)=\frac{1}{m}\sum^{m}_{i=1}cost(h_{\theta}(x^{(i)},y^{(i)})) J(��)=m1?i=1��m?cost(h��?(x(i),y(i)))
����cost��������(ʹJΪ����)
c o s t ( h �� ( x ) , y ) = { ? log ? ( h �� ( x ) ) y = 1 ? log ? ( 1 ? h �� ( x ) ) y = 0 cost(h_\theta(x),y)= \begin{cases} -\log(h_\theta(x)) & y=1\\ -\log(1-h_\theta(x)) & y=0 \end{cases} cost(h��?(x),y)={?log(h��?(x))?log(1?h��?(x))?y=1y=0?
����yֻ����0����1,��cost�����ֿ���д��
c o s t ( h �� ( x ) , y ) = ? y log ? ( h �� ( x ) ) ? ( 1 ? y ) log ? ( 1 ? h �� ( x ) ) cost(h_\theta(x),y)=-y\log(h_\theta(x))-(1-y)\log(1-h_\theta(x)) cost(h��?(x),y)=?ylog(h��?(x))?(1?y)log(1?h��?(x))��ʽʹ�ü�����Ȼ���Ƶõ�
��logistic�ļ��躯���ʹ��ۺ��������ݶ��½��Ĺ�ʽ,��,�����Իع���ݶ��½���ʽһ��:
�� j : = �� j ? �� 1 m �� i = 1 m ( h �� ( x ( i ) ) ? y ( i ) ) x j ( i ) \theta_j := \theta_j - \alpha\frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})x^{(i)}_j ��j?:=��j??��m1?i=1��m?(h��?(x(i))?y(i))xj(i)? -
������ݶ��½���,���и����Ż��㷨,��ʾ����ʹ�õ�L-BFGS�㷨,�ܹ��Զ�����ѧϰ��,���������ظ��졣�����㷨ϸ�����Ժ����ۡ�
sklearn�е����ع�ģ��+L-BFGS�㷨
## ����������
import numpy as np
import pandas as pd
## ���뻭ͼ��
import matplotlib.pyplot as plt
import seaborn as sns
## ��������
from sklearn.datasets import load_iris
## �������ع�ģ�ͺ���
from sklearn.linear_model import LogisticRegression
## Ϊ����ȷ����ģ������,�����ݻ���Ϊѵ�����Ͳ��Լ�,����ѵ������ѵ��ģ��,�ڲ��Լ�����֤ģ�����ܡ�
from sklearn.model_selection import train_test_split
## ��sklearn�е������ع�ģ��
from sklearn.linear_model import LogisticRegression
data = load_iris() # �õ���������
iris_target = data.target # �õ����ݶ�Ӧ�ı�ǩ
iris_features = pd.DataFrame(
data=data.data, columns=data.feature_names) # ����Pandasת��ΪDataFrame��ʽ
## ���Լ���СΪ20%, 80%/20%��
x_train, x_test, y_train, y_test = train_test_split(iris_features,
iris_target,
test_size=0.2,
random_state=2020)
## ���� ���ع�ģ��
clf = LogisticRegression(random_state=0, solver='lbfgs')
## ѵ��ģ��
clf.fit(x_train, y_train)
## �鿴���Ӧ��w
print('the weight of Logistic Regression:', clf.coef_)
## �鿴���Ӧ��w0
print('the intercept(w0) of Logistic Regression:', clf.intercept_)
## ��ѵ������Ԥ��
train_predict = clf.predict(x_train)
## �ڲ��Լ���Ԥ��
test_predict = clf.predict(x_test)
from sklearn import metrics
## ����accuracy(ȷ��)��Ԥ����ȷ��������Ŀռ��Ԥ��������Ŀ�ı���������ģ��Ч��
print('The accuracy of the Logistic Regression is:',
metrics.accuracy_score(y_train, train_predict))
print('The accuracy of the Logistic Regression is:',
metrics.accuracy_score(y_test, test_predict))
�Լ�д��һ�������ݶ��½������ع�ģ��
## ����������
import numpy as np
import pandas as pd
## ���뻭ͼ��
import matplotlib.pyplot as plt
import seaborn as sns
## ��������
from sklearn.datasets import load_iris
## �������ع�ģ�ͺ���
from sklearn.linear_model import LogisticRegression
## Ϊ����ȷ����ģ������,�����ݻ���Ϊѵ�����Ͳ��Լ�,����ѵ������ѵ��ģ��,�ڲ��Լ�����֤ģ�����ܡ�
from sklearn.model_selection import train_test_split
## �����Լ���ģ��
from my_module import logistic_regression
data = load_iris() # �õ���������
iris_target = data.target # �õ����ݶ�Ӧ�ı�ǩ
iris_features = pd.DataFrame(
data=data.data, columns=data.feature_names) # ����Pandasת��ΪDataFrame��ʽ
## ���Լ���СΪ20%, 80%/20%��
x_train, x_test, y_train, y_test = train_test_split(iris_features,
iris_target,
test_size=0.2,
random_state=2020)
## �Զ������ع�ģ��
clf2 = logistic_regression(3, x_train, y_train, 0.03, 1500)
## ѵ��ģ��
clf2.fit()
## �鿴�Զ���ع�ģ�͵IJ���
print('the theta of my logistic regression:', clf2.theta)
## �鿴�ݶ��½�Ч��
e = np.arange(clf2.episode)
for i in range(np.shape(clf2.cost)[0]):
plt.subplot(1, 3, i + 1)
plt.xlabel('episode')
plt.ylabel('cost')
plt.title('class' + str(i))
plt.plot(e, clf2.cost[i, :])
plt.show()
## ��ѵ����Ԥ��
my_train_predict = clf2.predict(x_train)
## �ڲ��Լ�Ԥ��
my_test_predict = clf2.predict(x_test)
from sklearn import metrics
## ����accuracy(ȷ��)��Ԥ����ȷ��������Ŀռ��Ԥ��������Ŀ�ı���������ģ��Ч��
print('The accuracy of my logistic regression is:',
metrics.accuracy_score(y_train, my_train_predict))
print('The accuracy of my logistic regression is:',
metrics.accuracy_score(y_test, my_test_predict))
from matplotlib.pyplot import show
import numpy as np
import math
from numpy.core.fromnumeric import shape
def calCost(theta, x, y, costFunction):
J = 0
m = np.shape(x)[0]
for i in range(m):
J = J + costFunction(theta, x[i, :], y[i])
J = J / m
return J
def gradientDescent(theta, x, y, alpha, episode, costFunction):
new_theta = theta.copy()
m = np.shape(x)[0]
cost = np.zeros(shape=[1, episode])
for i in range(episode):
new_theta = new_theta - alpha / m * (np.dot(x.T, (np.dot(x, new_theta) - y)))
cost[0, i] = calCost(new_theta, x, y, costFunction)
return new_theta, cost
class logistic_regression:
def __init__(self, classify_num, data, target, alpha, episode):
self.num = classify_num
self.alpha = alpha
self.episode = episode
self.cost = np.zeros(shape=[classify_num, episode])
self.theta = np.zeros(shape=[np.shape(data)[1] + 1, classify_num])
self.x = np.concatenate((np.ones(shape=[np.shape(data)[0], 1]), data),
axis=1)
self.y = np.stack((target, target, target), axis=1)
for i in range(np.shape(target)[0]):
for j in range(classify_num):
if self.y[i, j] != j:
self.y[i, j] = 0
else:
self.y[i, j] = 1
def fit(self):
for i in range(self.num):
self.theta[:, i], self.cost[i, :] = gradientDescent(
self.theta[:, i], self.x, self.y[:, i], self.alpha,
self.episode, self.costFunction)
def predict(self, data):
m = np.shape(data)[0]
x = np.concatenate((np.ones(shape=[m, 1]), data), axis=1)
y = np.dot(x, self.theta)
p = np.zeros(shape=[m, 1])
for i in range(m):
p[i, 0] = np.argmax(y[i, :])
return p
@staticmethod
def costFunction(theta, x, y):
h = 1 / (1 + math.exp(np.dot(-x, theta)))
cost = -y * math.log(h) - (1 - y) * math.log(1 - h)
return cost
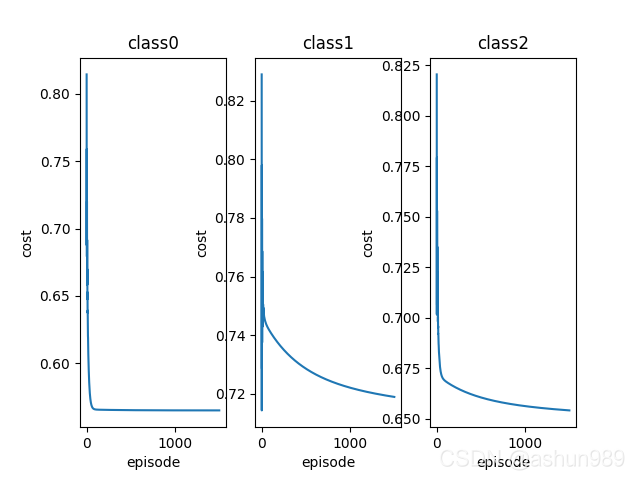
��ģ����Ҫ�ֶ�����ѧϰ��,���ƵĴ��ۺ�������������ı仯ͼ��������ݶ��½�ģ���Ѿ���������
Ԥ����ȷ�ʵ������Ա�
�������ﻮ�ַ�����������,��Ҫ����������
| L-BFGSģ��\���� | 1 | 2 | 3 | 4 | 5 | ƽ�� |
|---|---|---|---|---|---|---|
| ѵ���� | 0.975 | 0.983 | 0.975 | 0.975 | 0.975 | 0.977 |
| ���Լ� | 1.000 | 0.867 | 1.0 | 1.0 | 0.967 | 0.967 |
| �ݶ��½�ģ��\���� | 1 | 2 | 3 | 4 | 5 | ƽ�� |
|---|---|---|---|---|---|---|
| ѵ���� | 0.842 | 0.875 | 0.875 | 0.833 | 0.842 | 0.853 |
| ���Լ� | 0.833 | 0.700 | 0.733 | 0.833 | 0.833 | 0.786 |
ѧϰ��������
-
L-BFGS���㷨ԭ����ʵ����������?ΪʲôҪ��w��w0�ֿ�?�۲�������,
# L-BFGS [[ 9.28640502 2.93982978 -12.2262348] [-0.42811624 0.22521439 0.20290185] [ 0.90216543 -0.31280638 -0.58935906] [-2.35892743 -0.04278544 2.40171287] [-1.01037377 -0.76316802 1.77354179]] # �ݶ��½� [[ 0.06767668 0.5332828 -0.2890481 ] [ 0.06512361 0.1378264 -0.09343083] [ 0.26193529 -0.35682446 0.14645065] [-0.22339017 0.1606885 0.04149944] [-0.06379443 -0.44162421 0.47936581]]��Ȼ��w0�ϲ��ܴ�,�ݶ��½�������һ���ֲ�����
ѧϰ˼�����ܽ�
Ŀǰpythonʹ�û����Ǻ�����,���ü��顣���ڻ���ѧϰ,���ǹ��п���,��Ҫ���ѧϰ��