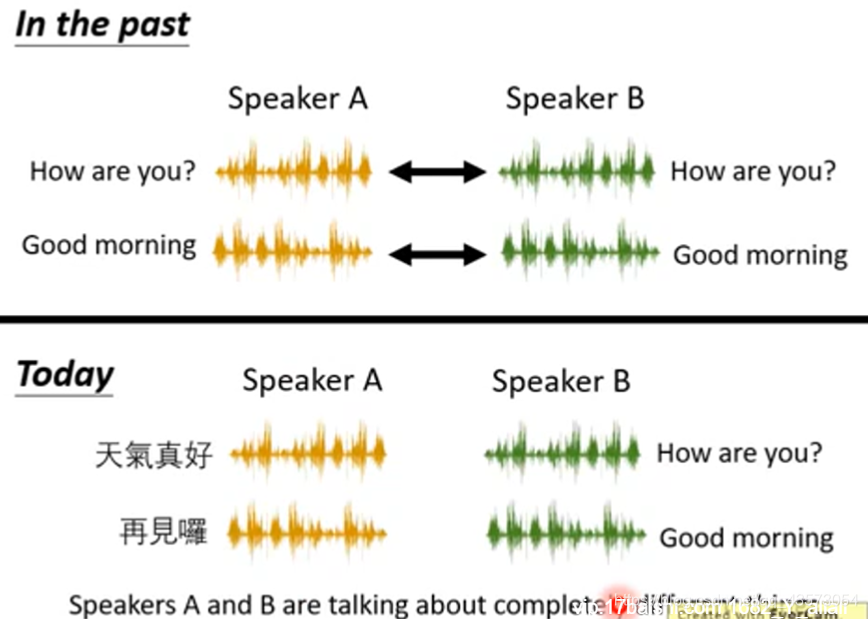
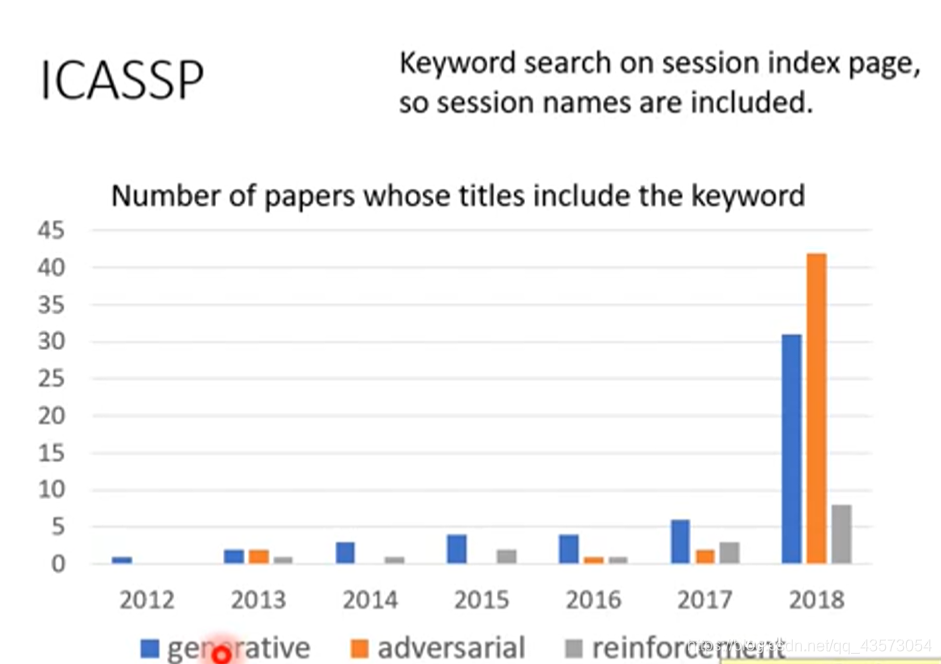
Generative Adversarial Network
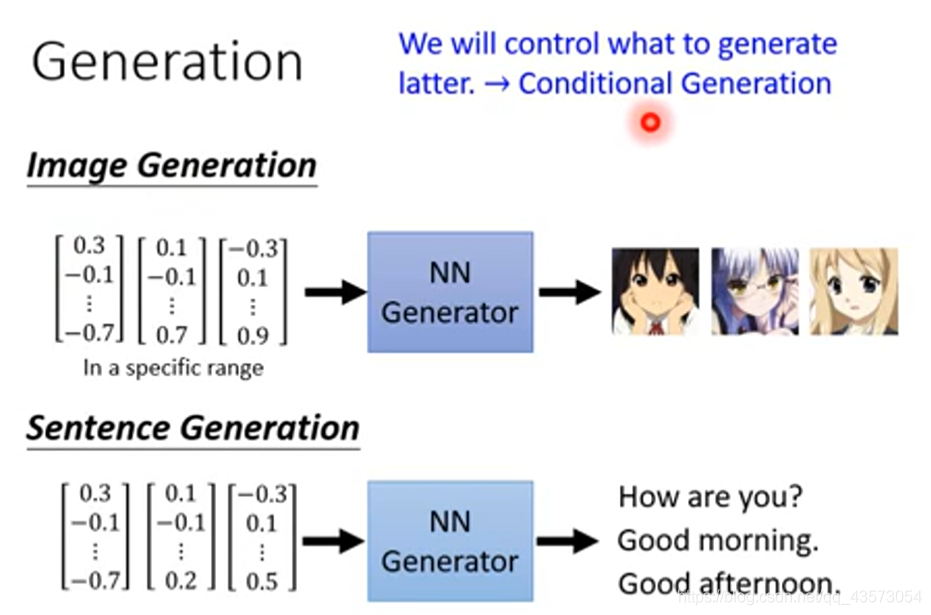
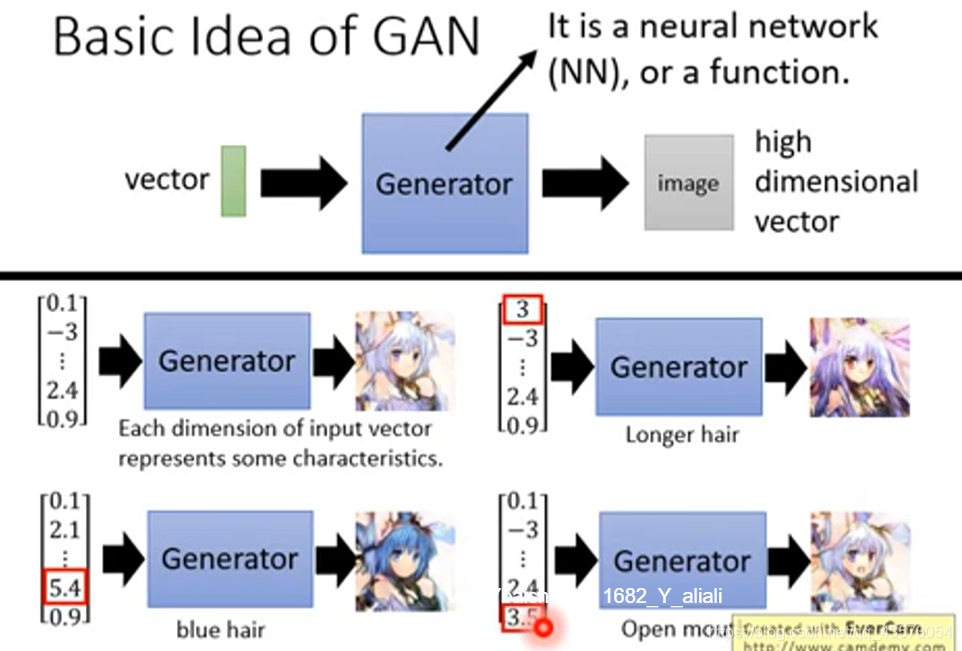
正如我们前面所说的,GAN里面有两个重要的东西,其中一个就是Generator,Generator可以是一个NN。它的输入是一个vector,它的输出是一个更高维的vector,也就是我们所需要产生的东西,在这里就是一张图片啦。输入向量每一个维度都对应生成对象的某些特征。Each dimension of input vector represents some characteristics.例如:
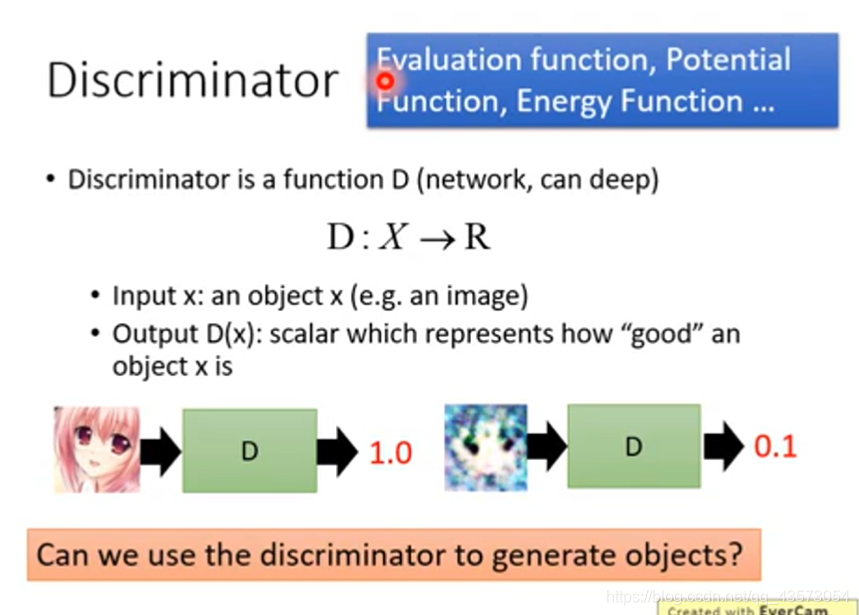
Discriminator也可以是一个NN。但注意它的输入和上面的Generator的不同。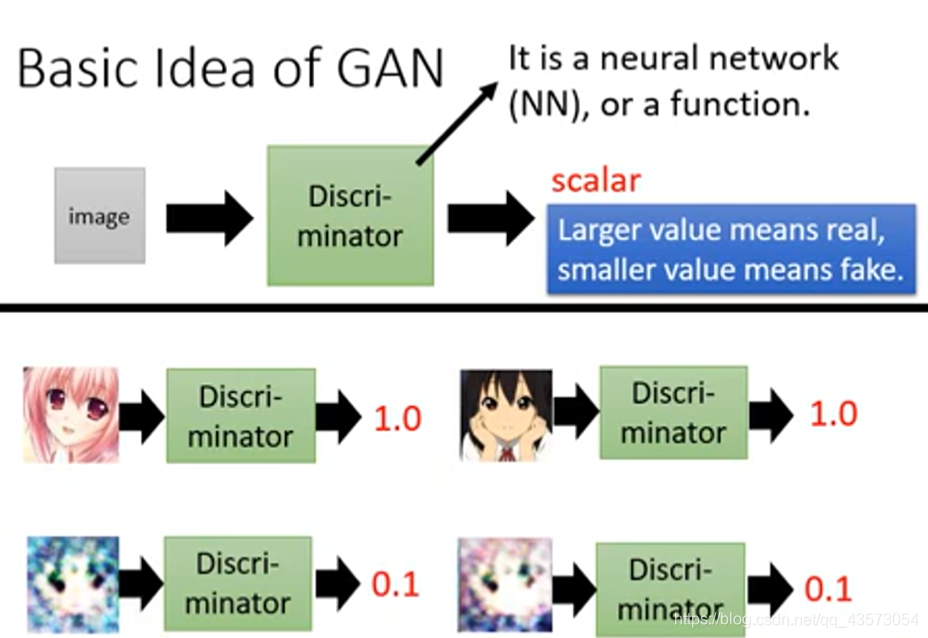
Discriminator的输入是一张图片,输出是一个scalar,scalar用于判断这张图片的质量。
当这个输出值越高,则越像真实图片
当这个输出值越低,则越不像真实图片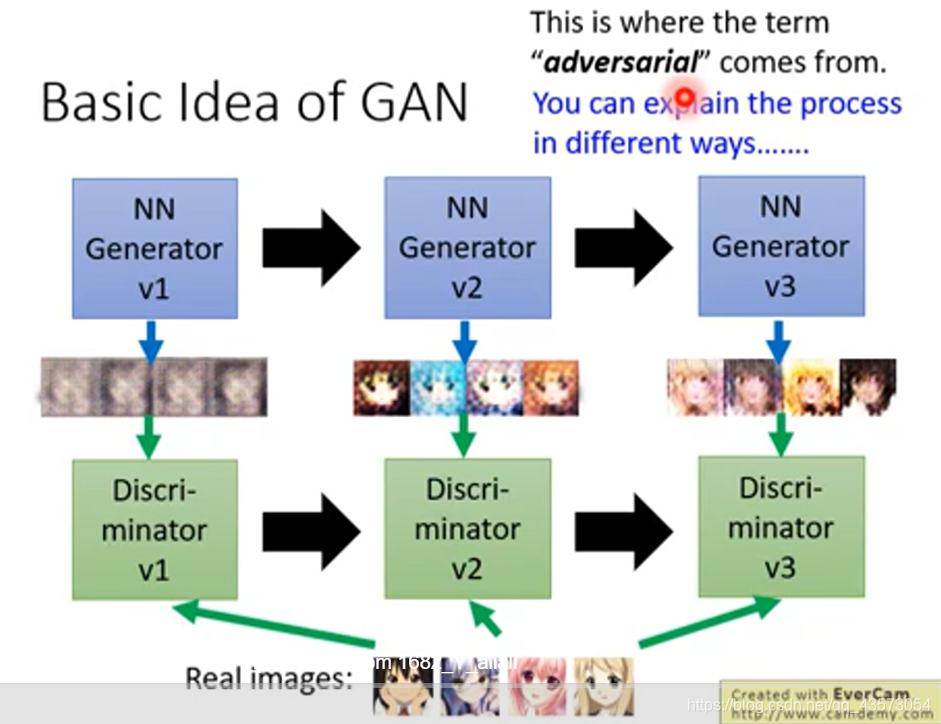
会对生成器所产生的假目标做惩罚和对真目标进行奖励,这样鉴别器就知道什么目标是不好的假目标,什么目标是好的真目标,而生成器则是希望通过进化,产生比上一次更好的假目标,使鉴别器对自己的惩罚更小
算法
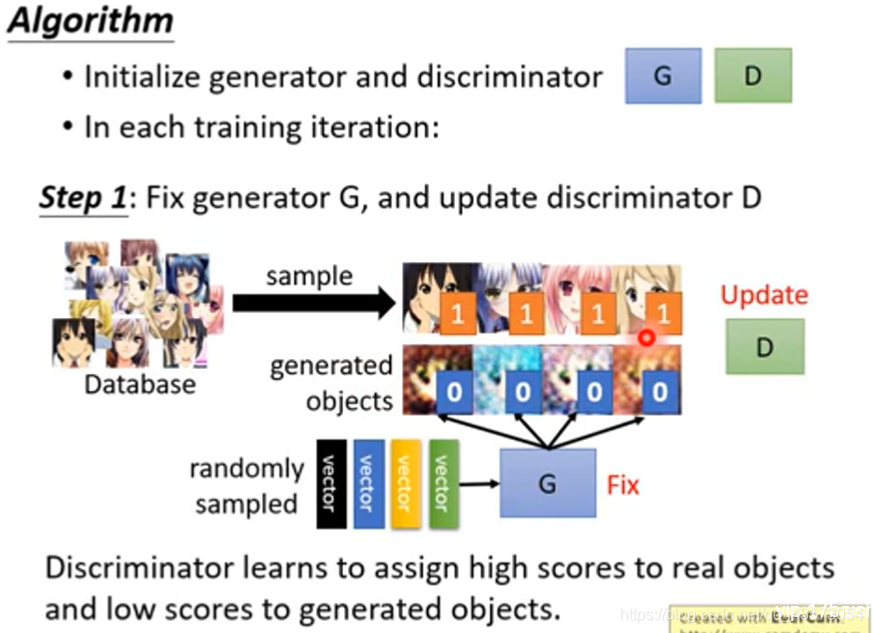
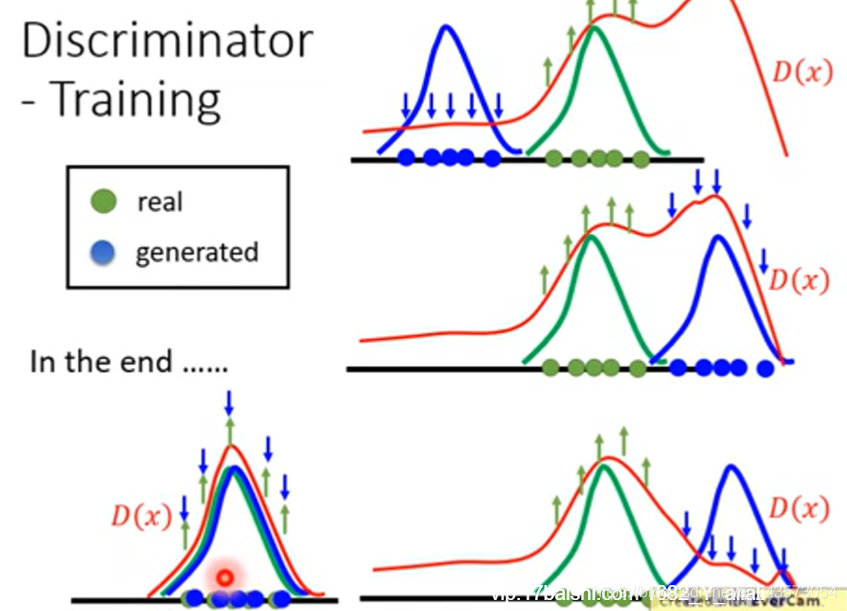
第一件事情:固定generator,然后只训练discriminator(看到好的图片给高分,看到不好的图片给低分)。从一个资料库(都是二次元的图片)随机取样一些图片输入 discriminator,对于discriminator来说这些都是好的图片。因为generator的参数都是随机给定的,所以给generator一些向量,输出一些根本不像二次元的图像,这些对于generator来说就是不好的图片。接下来就可以教discriminator若看到上面的图片就输出1,看到下面的图片就输出0。训练discriminatro的方式跟我们一般训练neuron network的方式是一样的。
第二件事情:固定discriminator,然后只训练generator。一般我们训练network是minimize 人为定义的loss function,在训练generator时,generator学习的对象不是人为定义而是discriminator。你可以认为discriminator就是定义了某一种loss function,等于机器自己学习的loss function。
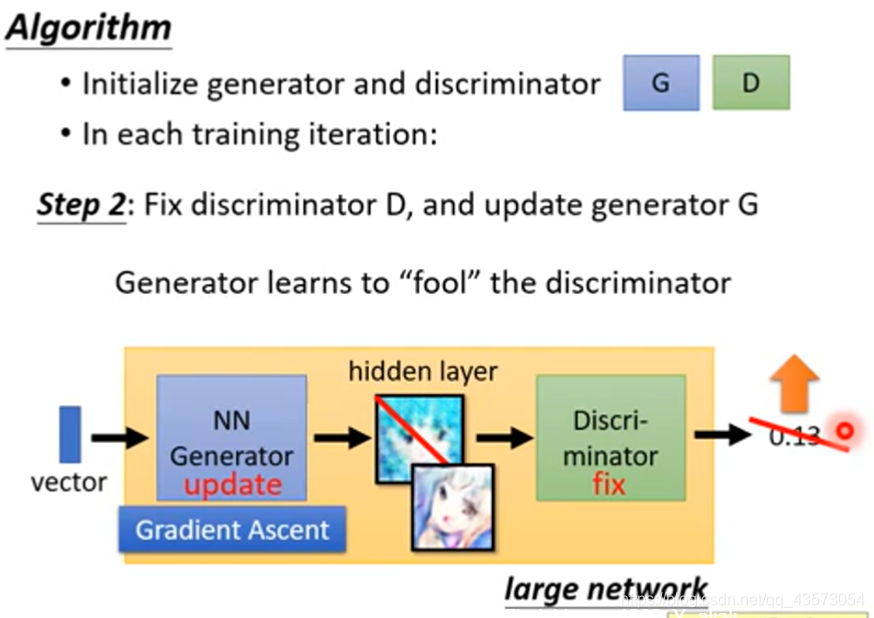
我们训练的目标是让输出越大越好,训练时依然会做backpropagation,只是要固定住discriminator对应的维度,只是调整generator对应的维度。调整完generator后输出会发生改变,generator新的输出会让discriminator给出高的分数。

上面的步骤很好的解释了我们刚才对于GAN的解释:首先,我们又一个第一代的Generator,然后他产生一些图片,然后我们把这些图片和一些真实的图片丢到第一代的Discriminator里面去学习,让第一代的Discriminator能够真实的分辨生成的图片和真实的图片,然后我们又有了第二代的Generator,第二代的Generator产生的图片,能够骗过第一代的Discriminator,此时,我们在训练第二代的Discriminator,依次类推。
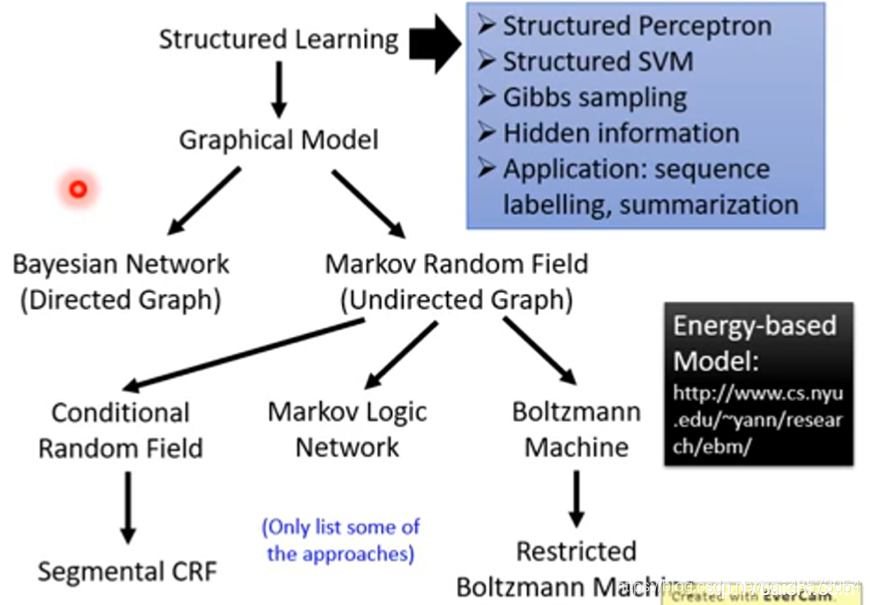
structured learning and application
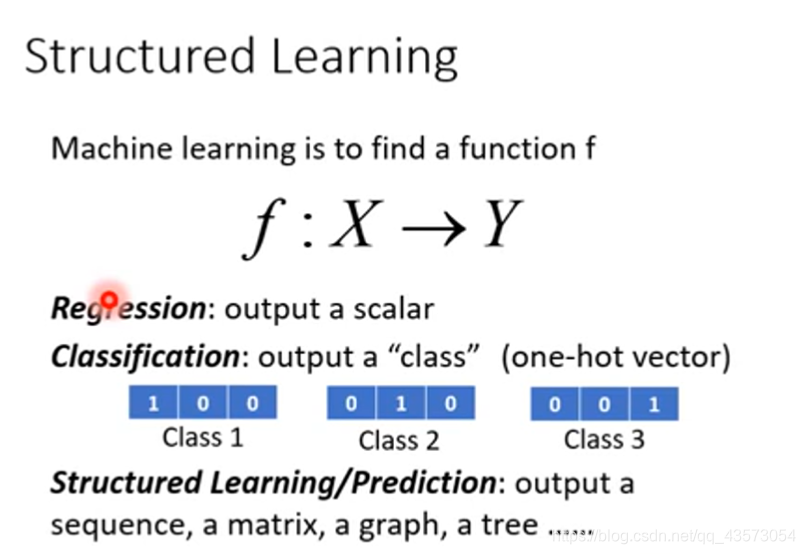
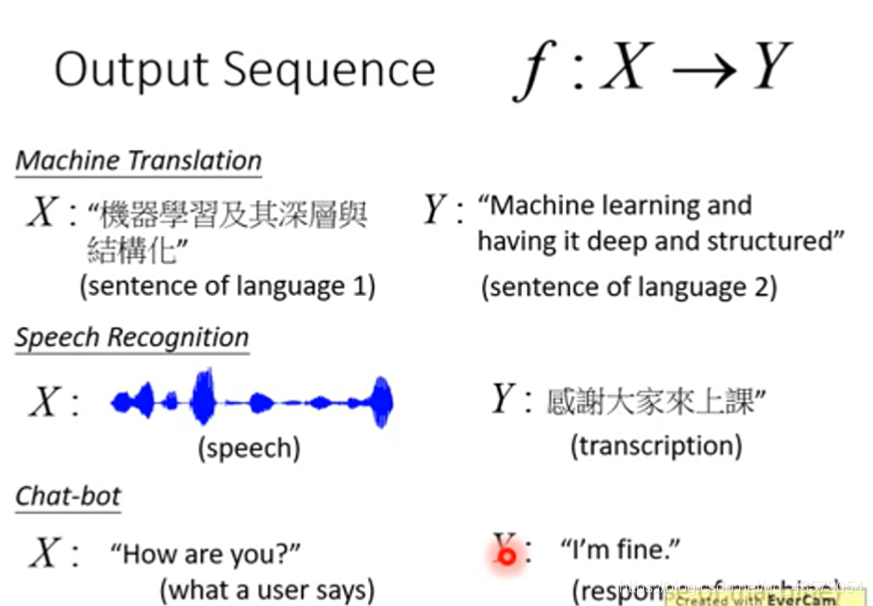
结构化学习的输入和输出多种多样,可以是序列(sequence)到序列,序列到矩阵(matrix),矩阵到图(graph),图到树(tree)等等。这样,GAN的应用就十分广泛了。例如,机器翻译(machine translation),语音识别(speech recognition)以及聊天机器人(chat-bot):

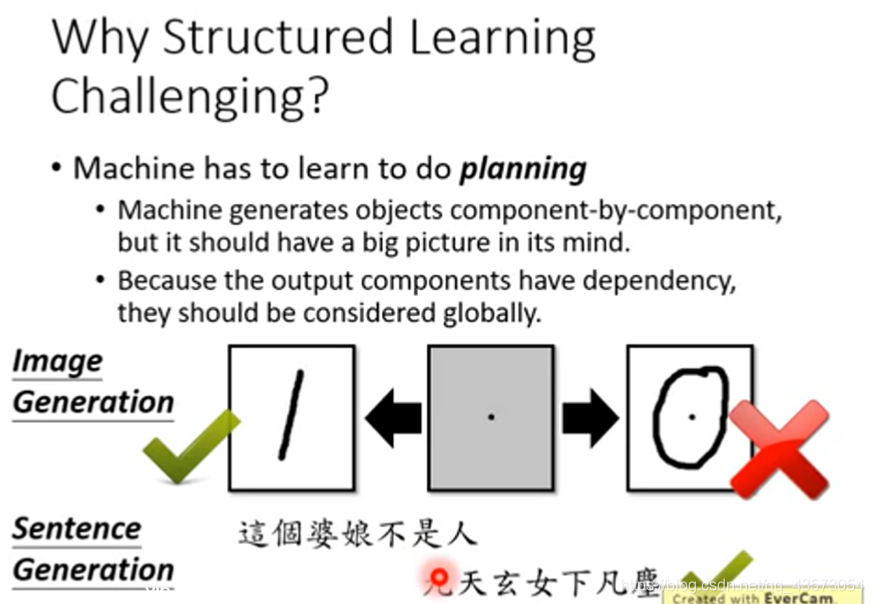
One-shot/Zero-shot Learning:就是训练数据中可能没有或者只有很少的某个类别的数据,而要求模型生成对应的东西。另外,机器需要有大局观。机器逐个组件地生成对象,但是它应该具有广阔的前景。由于输出组件具有依赖性,因此应全局考虑它们。
例如在图像生成的时候,每次生成一个像素,但是所有像素合起来要像一个人脸。不能人脸有三个眼睛,两个嘴巴,因此在Structured Learning中生成不是最重要的,重要的是component与component之间的关系。

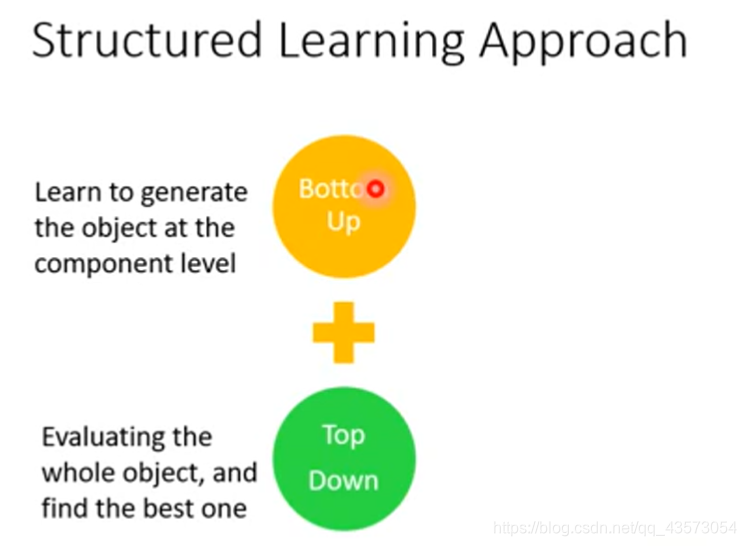
我们可以把Generator看做Structured Learning中生成很小的component的部分,Discriminator看做整体的评估方法。二者合起来,就是GAN.
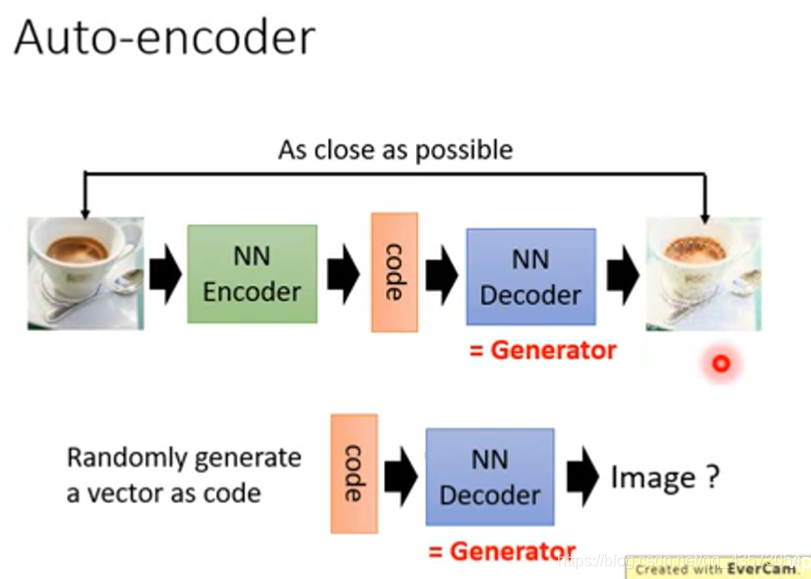
Generator就是一个NN,输入一个向量,生成一个图片,如果现在是做生成手写数字,那么就是输入一个向量,得到一个手写数字。输入不同的向量,得到不同的数字。如果我们用不同的向量来代表不同的手写数字
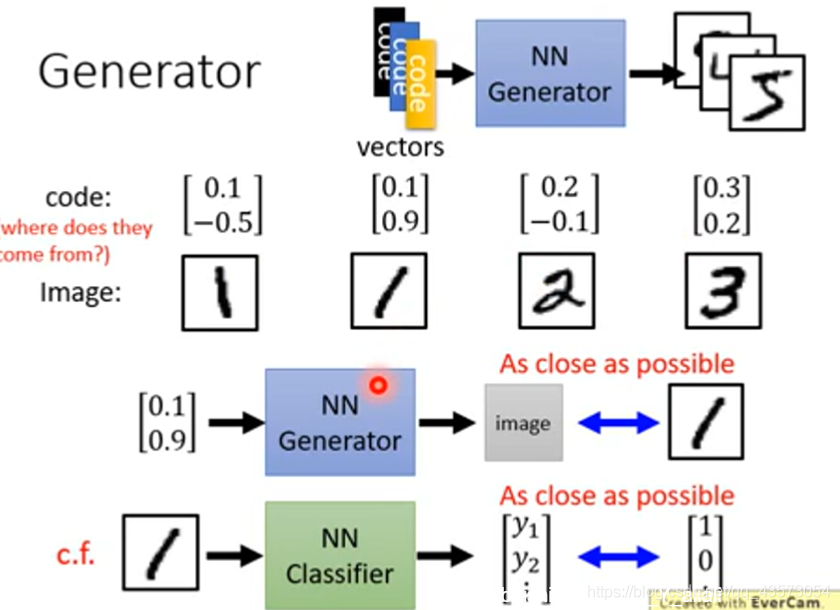
如何训练这个生成器呢?可以用监督学习的方法来进行训练:
在传统的监督学习中,给NN一个输入和输出的pairs,就这样一直train下去就好。比如有一系列的图片,随便给他一个code,然后训练即可,使输出和label越接近越好。这就和我们训练分类器的过程一样。现在的问题是表示图片的code从哪里来?随机?不行啊,因为当输出类似的时候,输入由于是随机的,有很大差别,这样很难训练出一个网络。例如:
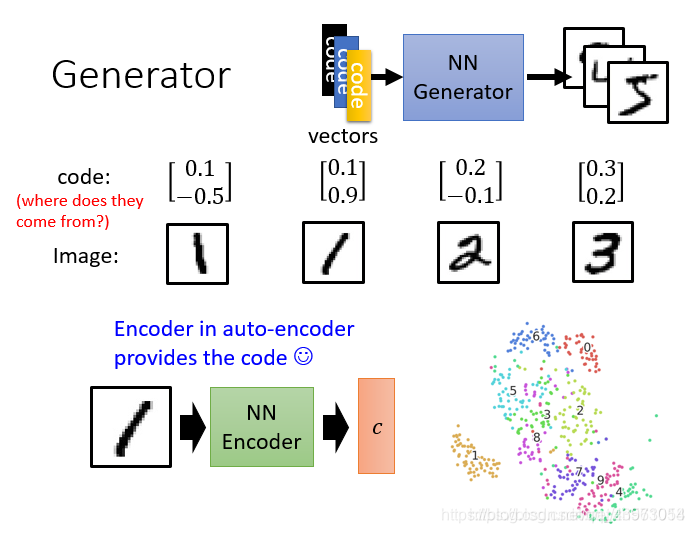
Auto-encoder
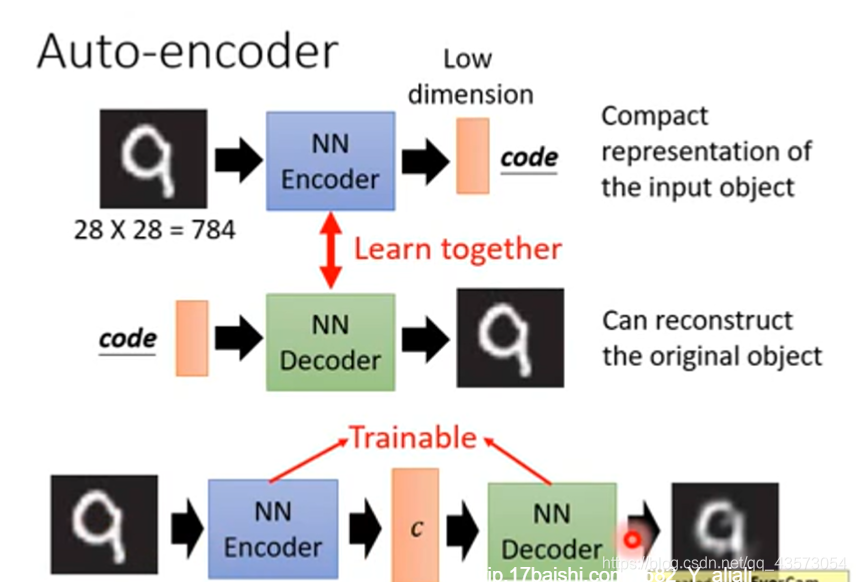
分析上面的结构,发现Auto-encoder的Decoder就是根据c(向量)生成图片,这不就是和Generator干的事情是一样的吗?
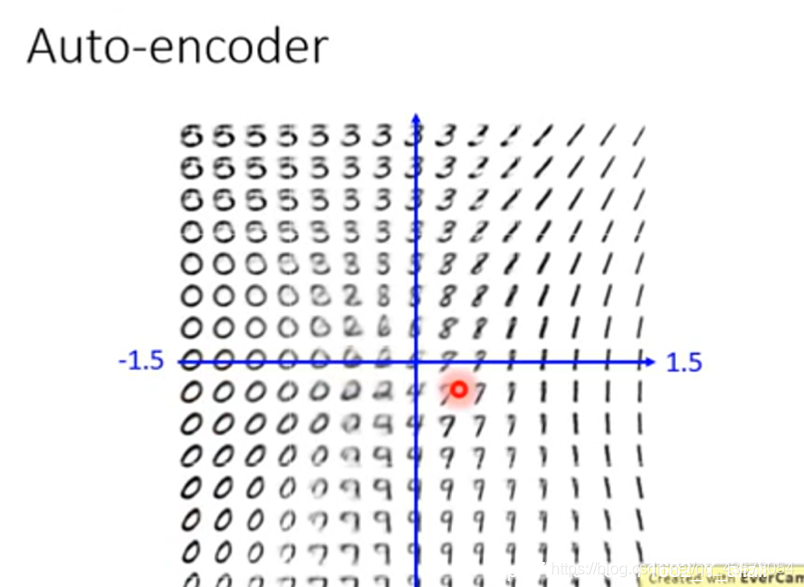
通过上面的实验,我们可以下如下结论:
如果有两个向量a和b,那么我们可以分别生成两个手写数字:
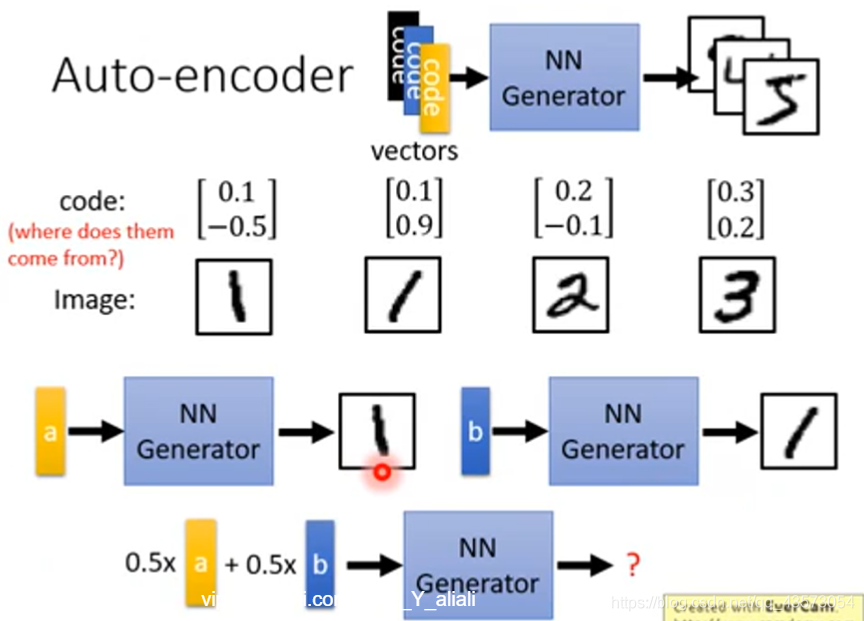
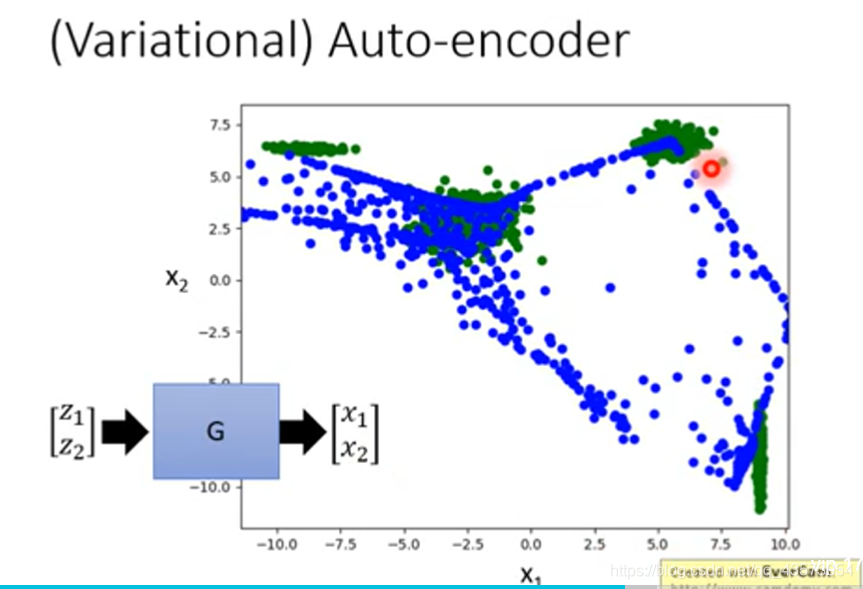
但是存在一个问题:你的training data里面的image是有限的,当生成器在看到a的情况下生成偏左的1,在看到b的情况下也生成偏右1,当a和b 的平均,会产生什么样的图片呢?事实是由于网络是非线性的,得到的不一定是正的1,也可能是噪声。可以使用VAE来解决!
VAE不仅产生一个code(m1,m2,m3)还会产生每一个维度的方差;然后将方差和正态分布中抽取的噪声进行相乘,之后加上code上去,相当于加上noise的code;之后输入到decoder中就得到图片;这样情况下,decoder不只是看到a或b产生一些数字,当看到a或b加上一些noise也要产生数字;这样使decoder更加鲁棒
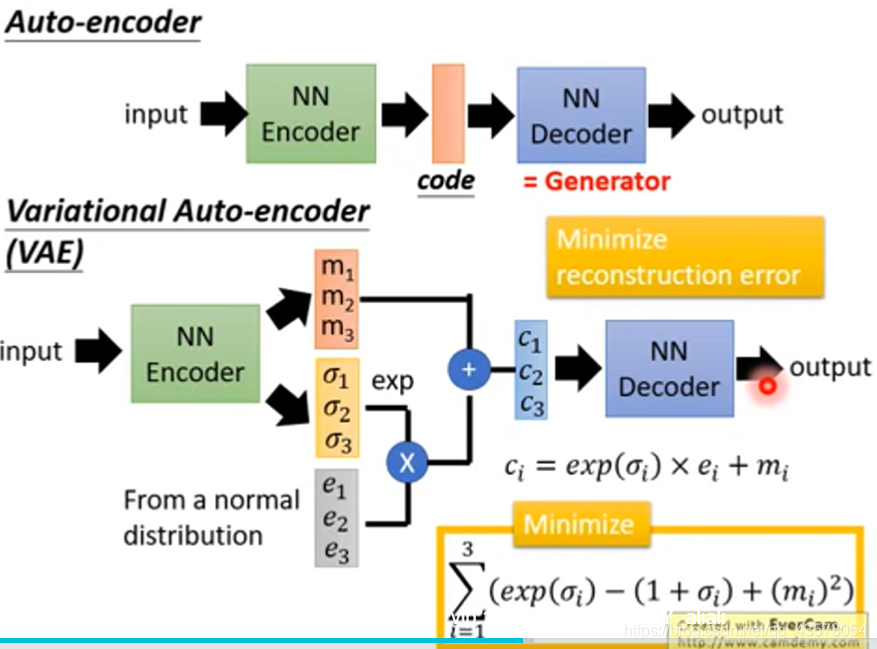
但是这种VAE和decoder的生成器少了什么东西?生成器在train的时候,我们希望的是最终生成器生成的图片和我们给定的图片在像素级别上越像越好。但是肯定会产生一些mistake。
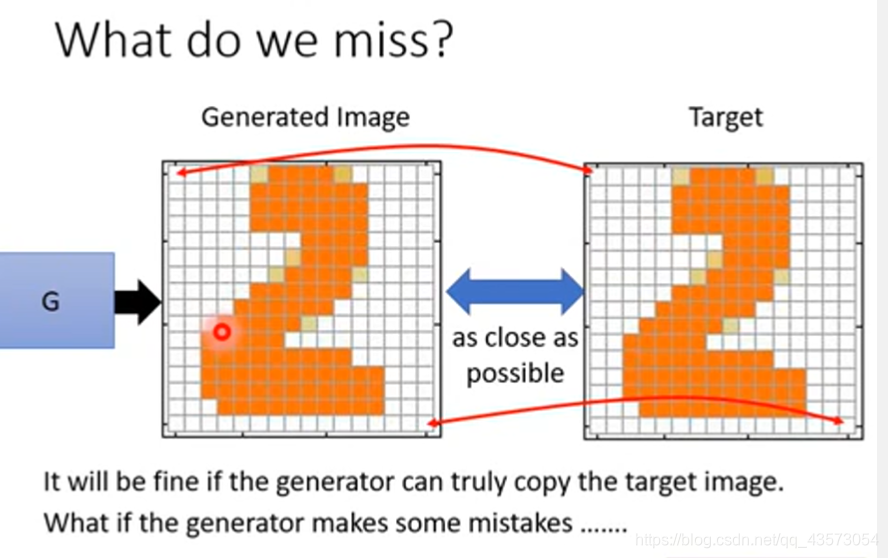

我们需要structure 来约束这个事情。就是在后面在加几个隐藏层,就可以调整第L层的神经元输出。也就是说理论上,VAE要想获得GAN的效果,它的网络要比GAN要深才行。

Discriminator
鉴别器是给定一个输入,输出一个[0,1]的置信度,越接近1则置信越高,越接近0则置信度越低,如图所示:
对于单纯的生成器,想要去判别不同像素之间的关联是很困难的;但鉴别器的优势在于它可以很轻易地捕捉到元素之间的相关性,例如自编码器中出现的像素问题就不会在鉴别器中出现,因为你是把输出好的图片丢给判别器的,然后去评价它好不好。
假如说已经有了一个判别器,它能够鉴别一个图片是好的还是不好的,我们就可以用这个判别器去生成图片。穷举所有的输入x,看看判别器给它的分数,找到最大的就是判别器生成的。

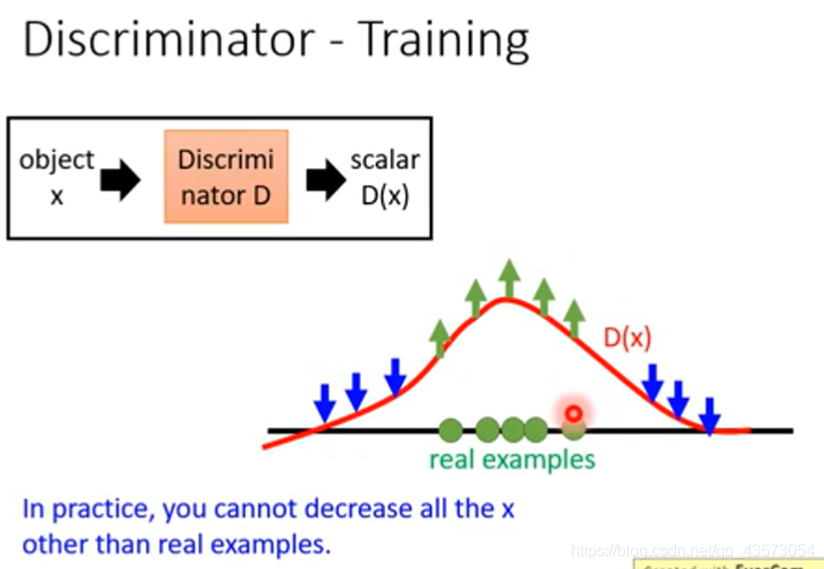
现在我们手上只有真实的对象,因此仅仅用这个东西来训练,得到的Discriminator会比较笨,看什么都是真实的。

因此我们需要一些负样本来进行训练。一个办法是直接在真实对象上加noise,让它成为负样本(图:左二):

1). 你的判别器需要做的就是去给正样本高的分数,负样本低的分数
2). 当你学出一个判别器后,再用判别器去做生成(就是一个argmax的过程,具体怎么做,不知道呀),生成一堆它觉得好的的图片,之后作为负样本重复 1)过程
GAN就是取代了这个argmax的过程;现在我们用生成器去得到好的负样本来取代argmax D(x);因为生成器在train的时候就是去学一些image,是可以躲过判别器的(给高分的)




从生成器角度出发,虽然在生成图片过程中的像素之间依然没有联系,但是它的图片好坏是由有大局观的判别器来判断的。从而能够学到有大局观的生成器。
从鉴别器的角度出发,利用生成器去生成样本,去求解argmax问题
Text-to-Image
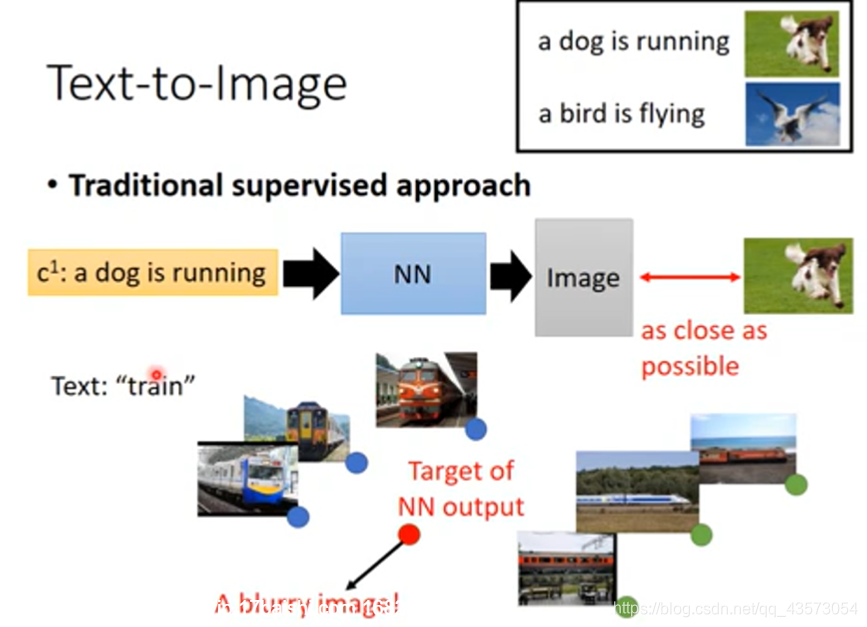
这样做有什么问题?我们来看一下,例如文字:train对应的图片有很多张。例如下面的火车有正面,有侧面的,如果用传统的NN来训练,模型会想让火车长得像左边,又像一个右边的,这样的结果是不好的。模型会想产生多张图像的平均,结果就会很模糊。
Conditional GAN 的意思就是有条件的GAN
conditional GAN 可以让 GAN 产生的结果符合一定的条件,即可以通过人为改变输入的向量,控制最终输出的结果。这种网络与普通 GAN 的区别在于输入加入了一个额外的 condition(比如在 text-to-image 任务中的描述文本),并且在训练的时候使得输出的结果拟合这个 condition。
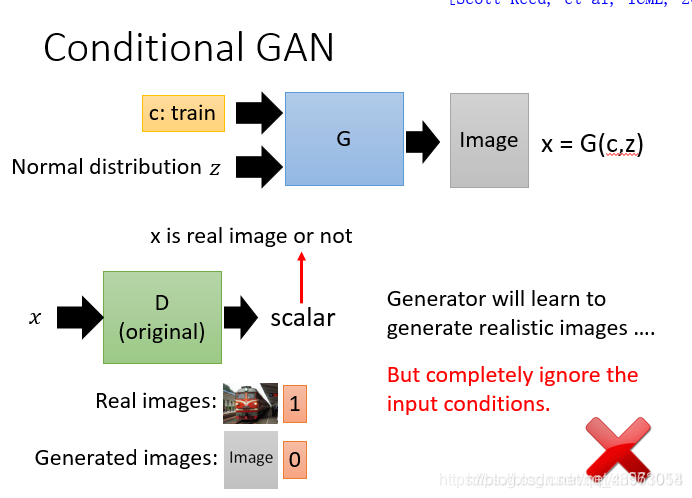
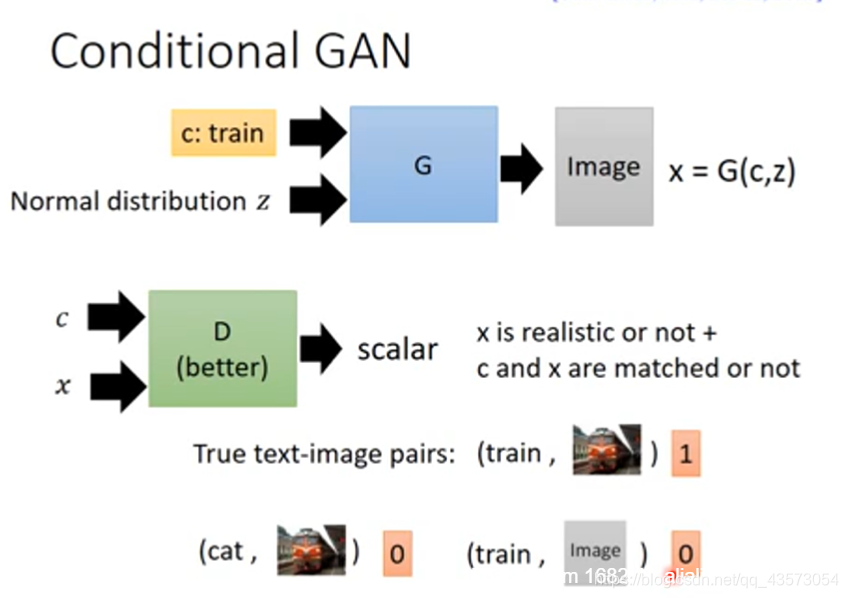
这时候判别器有两个任务:
图片质量好不好(图片是不是真实的)
图片是否和输入的条件匹配。就算质量高但是不匹配的话,也是低分。

Conditional GAN - Discriminator
具体设计条件GAN判别器,有两种方式:
1.图片x经过一个网络变成一个code,一句话经过网络也变成一个code;把这两种code组合在一起丢到网络里面,输出一个数值。
2.首先让图片经过一个网络,输出一个分数(用于判断图片是否真实),同时这个网络也输出一个code,这个code和一句话结合起来丢到另外一个网络里,也输出一个分数(图片和文字是否匹配);其实两种分数拆开比较合理
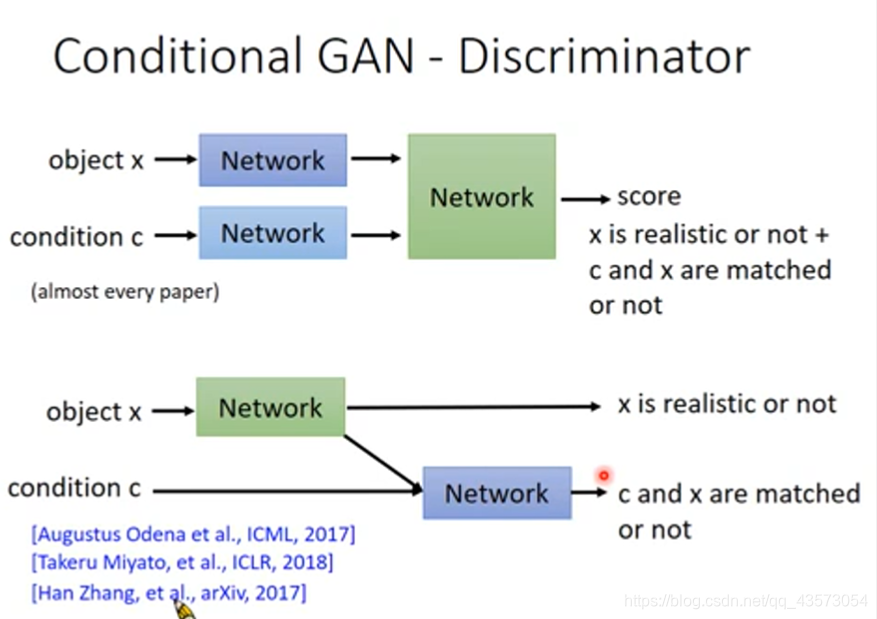
前者更为常用,但李宏毅老师认为后者更加合理,它用两个神经网络分别对输出结果的质量以及条件符合程度独立进行判别。
Stack GAN
1.提出了一种新的叠加生成对抗网络(stackgan),用于从文本描述中合成照片般逼真的图像。它将生成高分辨率图像的困难问题分解为更多可管理的子问题-----解决细节缺失问题,分辨率变高。
2.提出了一种新的条件增强技术(CA)来稳定条件GAN的训练,同时也提高了条件GAN训练的多样性。
3.广泛的定性和定量实验证明整体模型设计的有效及单个组件的效果。
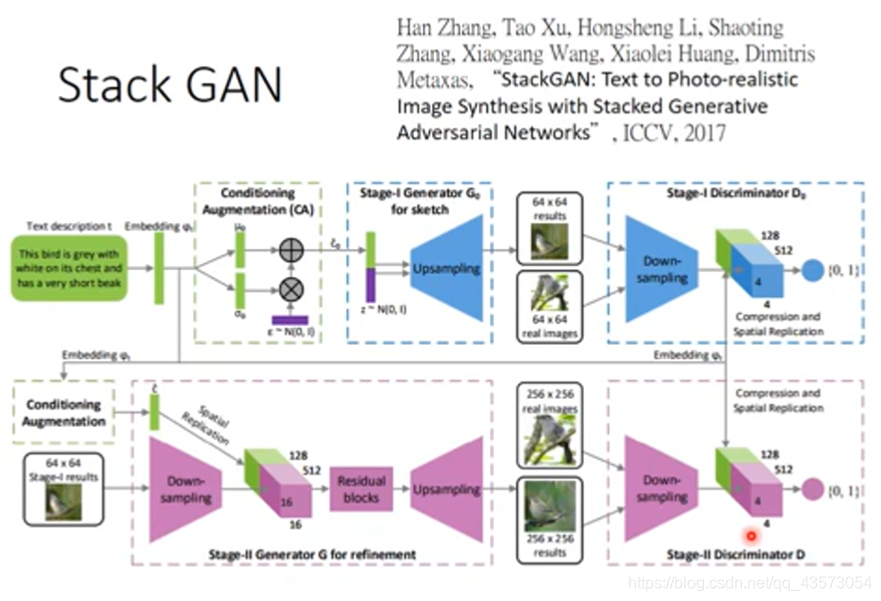
Image-to-image
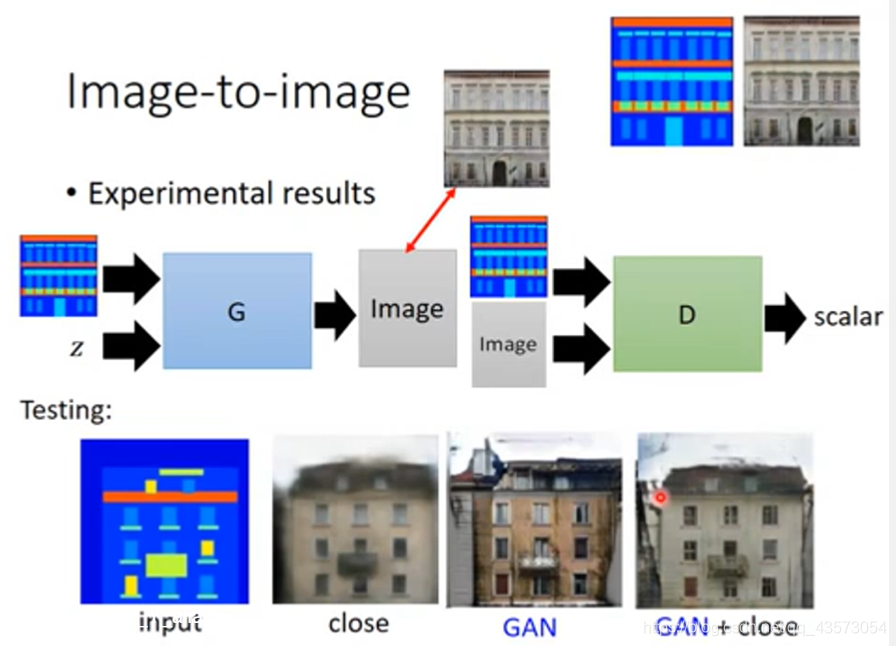
Generator会吃一个从分布中抽取的vector和一个input,其中input作为条件,output是一个image。
传统做法中,仅仅使image和真实的image接近,会发现生成的图像比较模糊,即下面第二张图片。这个我们在前面都有提及。在Gan中,Discriminator会输入产生的image和input(也就是condition),从而输出一个scalar。
GAN+close是一个好的解决办法!在GAN+close中,我们对generator生成的image加上限制,要使得生成的image与真实对象越接近越好。通过训练,可以得到下面第四张图片,此时,生成的image不仅清晰而且也基本符合要求了!
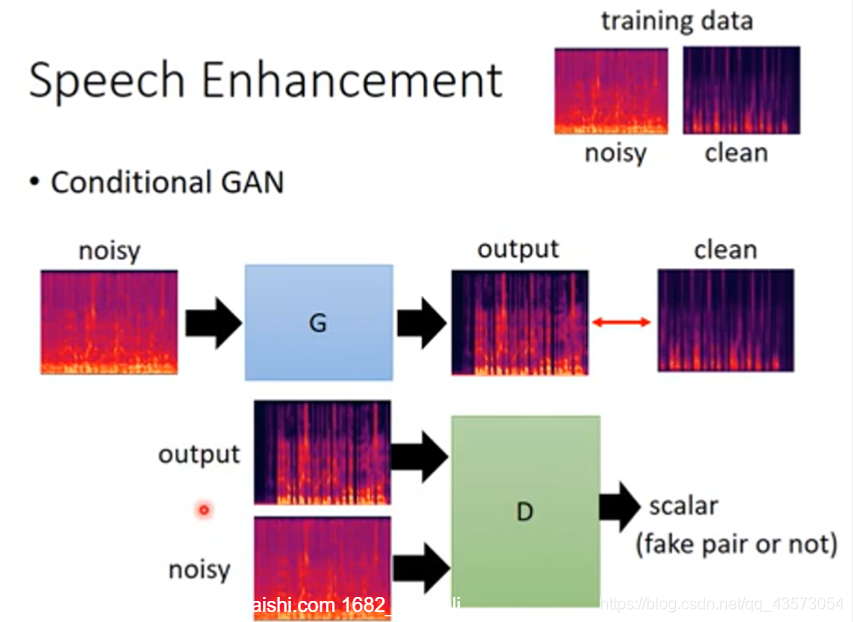
Speech Enhancement
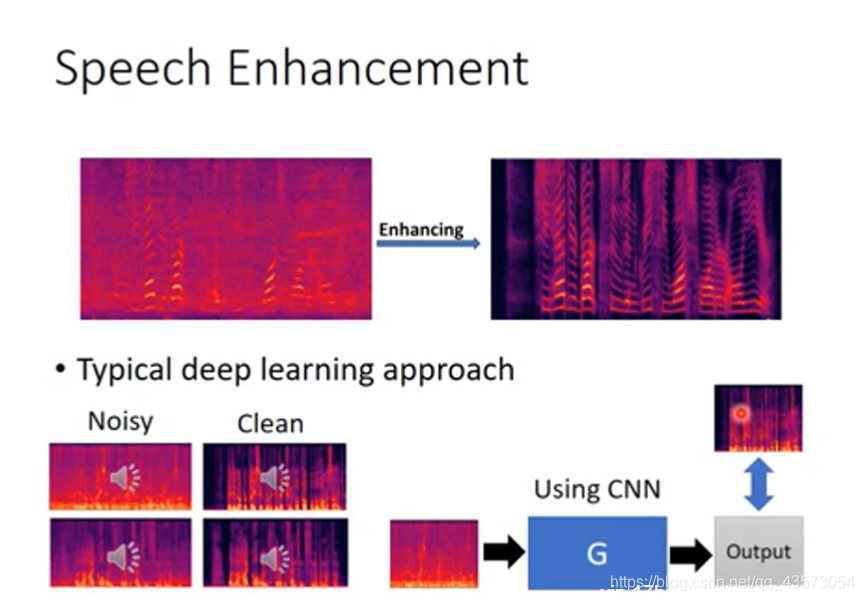
先要有数据,然后训练一个NN,注意这里会直接套CNN。然后使output和真正clean的结果越接近越好。这样做效果当然不好。
Video Generation
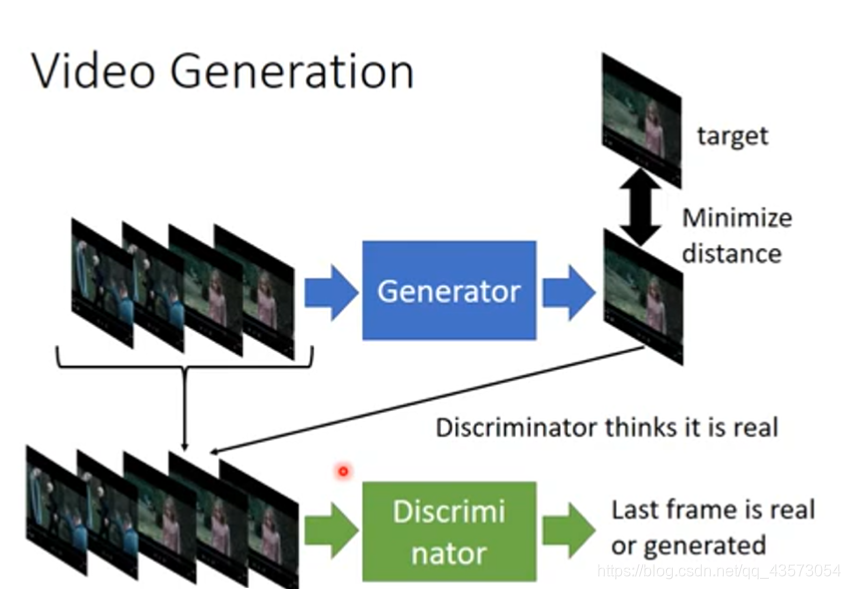
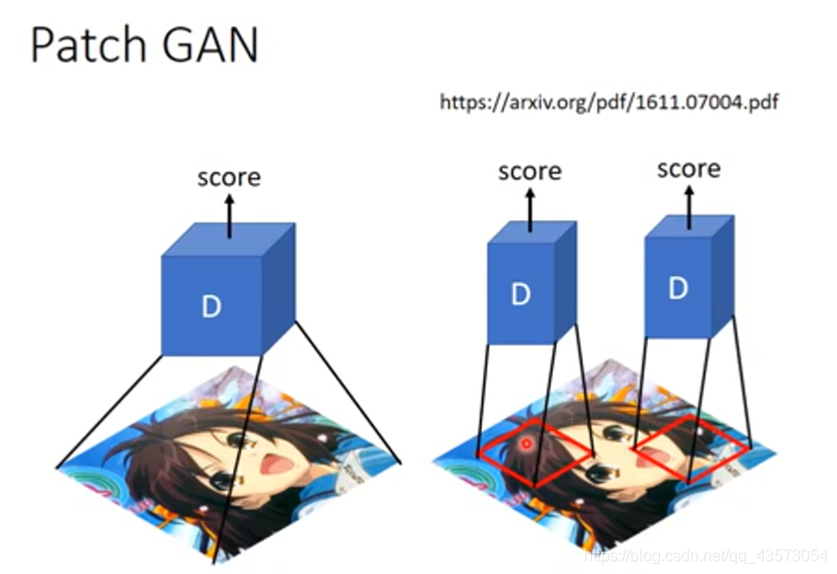
Conditional GAN主要应用在Image-to-Image、Text-to-Image、Speech Enhancement和Video Generation上,而Conditional GAN也有许多变种,针对训练不稳定的问题,提出了Stack GAN,针对Discriminator评估大张的图片容易训练过久和过拟合问题提出了Patch GAN,用多个Discriminator来进行评估。
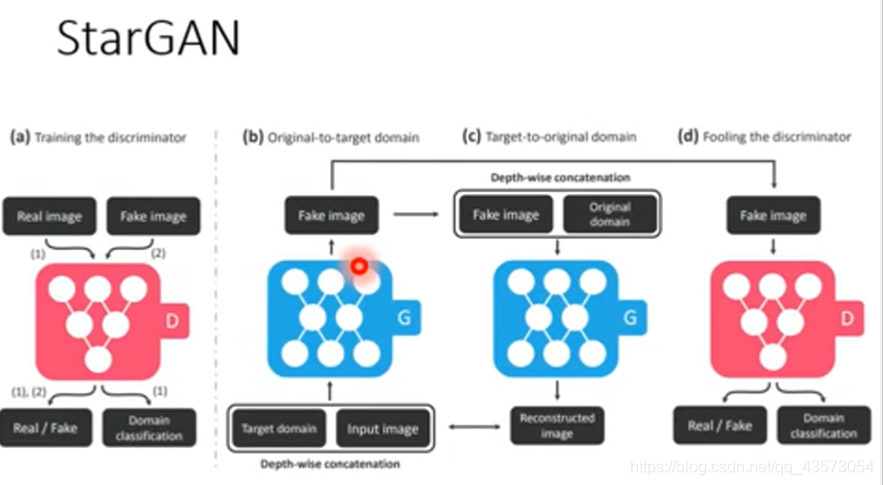
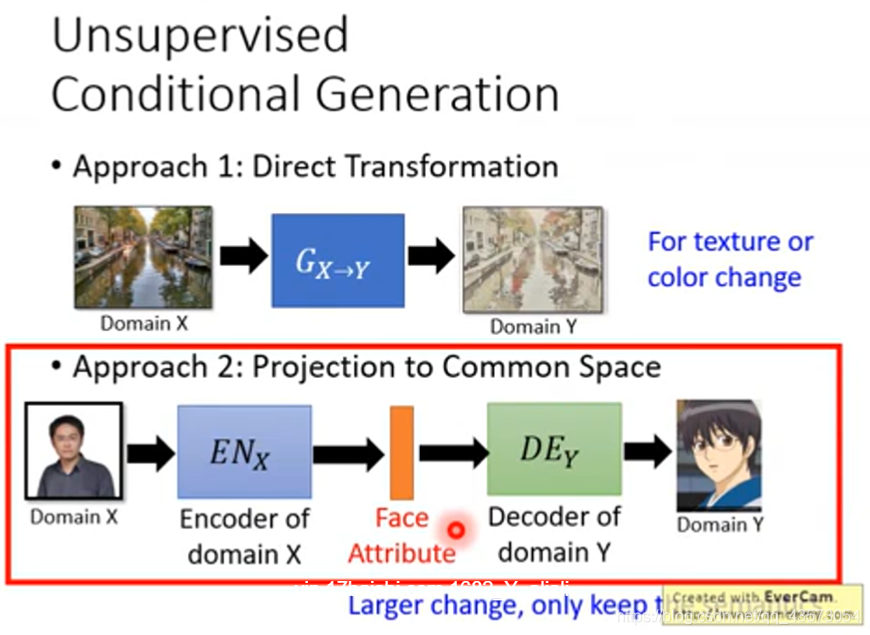
Unsupervised Condition GAN
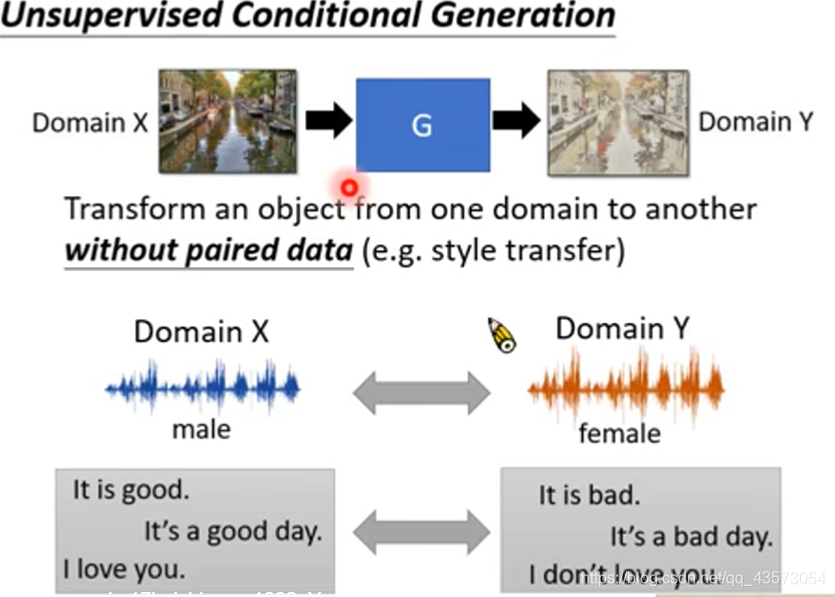
有两大类的做法:
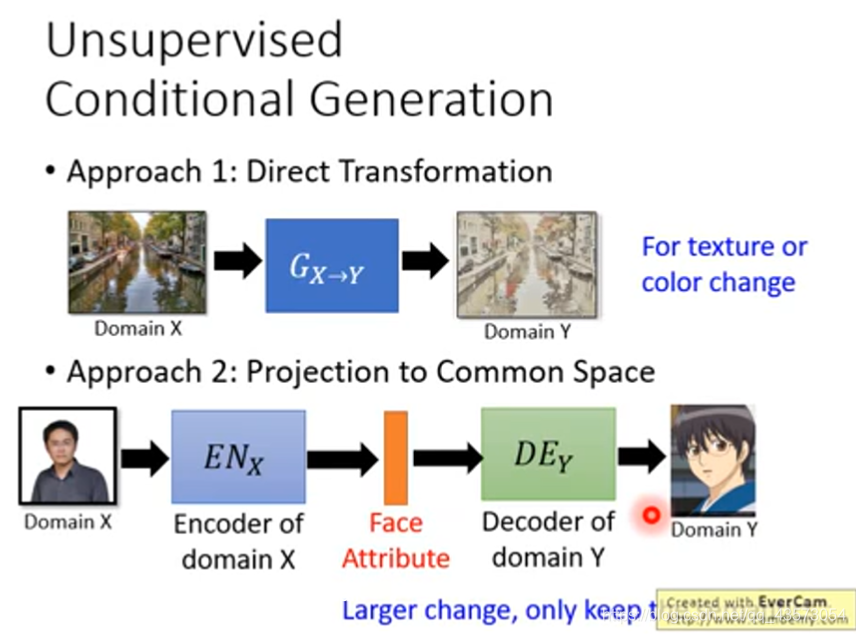
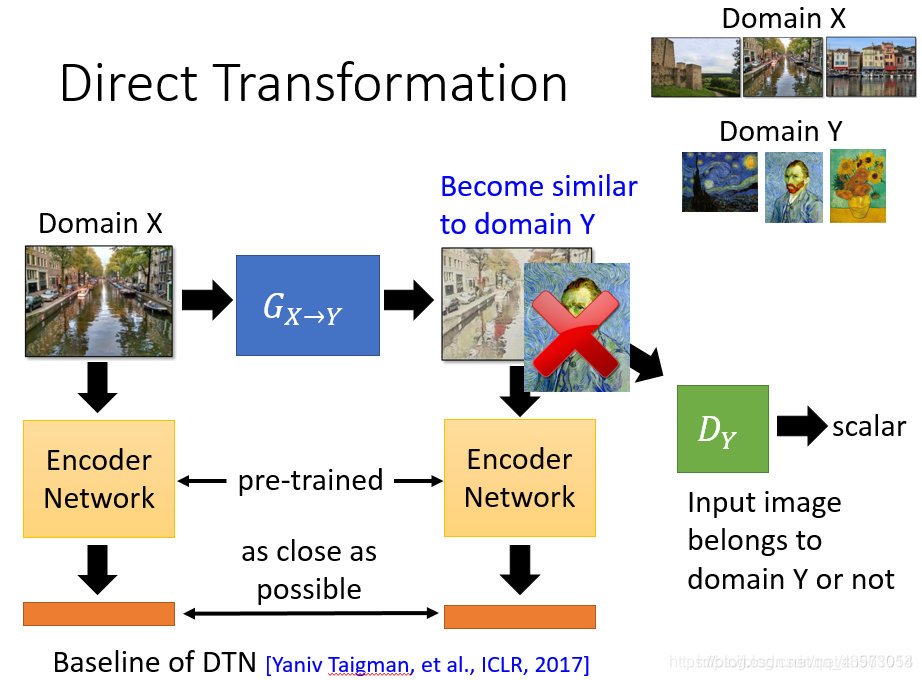
直接转:直接学习一个生成器,可以将domainX转换为domainY的东西
投影到公共空间:你先学习一个domain X的encoder,将特征抽出来;之后输入domain Y的decoder,将特征转换为想要的东西
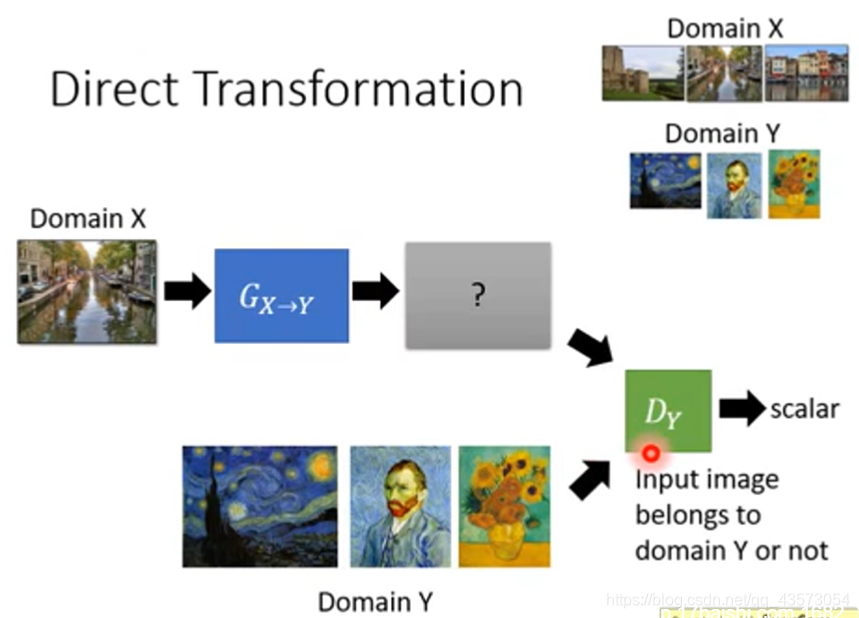
需要一个Y domain的判别器,这个判别器他看过很多Y domian的图片,所以给它一张image,他可以鉴别这个image是不是Y domian的image
生成器要做的就是想办法去骗过判别器,这样就生成Y domain的东西
但是还要注意生成器生成的东西要与输入有关
利用一个判别器,判断生成器输出的图片属于 x domain 或者 y domain,从而训练 生成器使得其输出的图片尽可能贴近于 y domain。但这样的问题是生成器可能输出和输入不相关的图像。
最简单粗暴的方法就是直接无视,因为直接转换下,生成器的深度不足以产生和输入图像相差过大的输出结果。也就是说如果你的生成器网络很浅,输入和输出会特别像,这时候就不需要额外的处理;如果你的生成器网络很深,输入和输出会真的很不一样,这时候就需要额外的处理;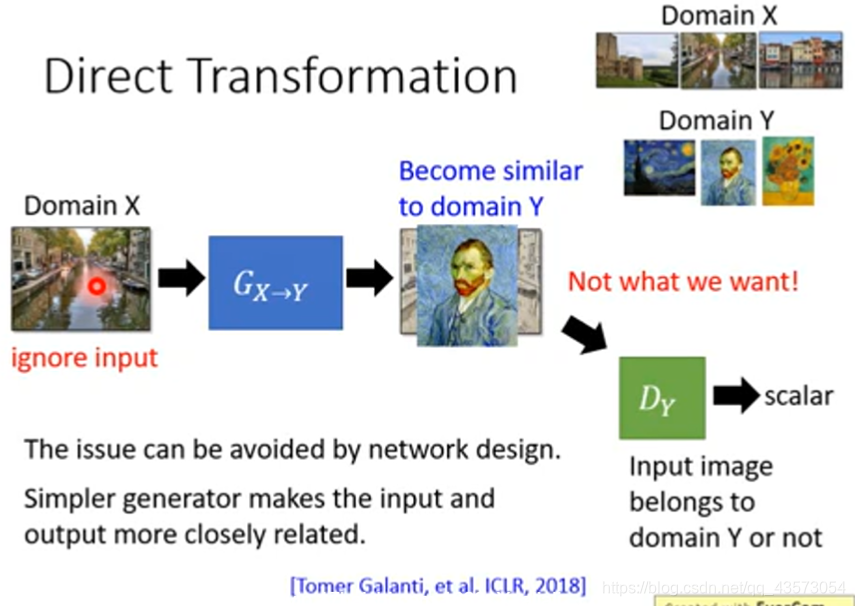
用一个已训练好的网络,如VGG;把生成器的输入和输出image,统统丢给这个pre-train好的网络,就会输出两个embedding vector;接下来在训练的时候,一方面生成器要骗过判别器,同时希望两个embedding的vector不要差太多。
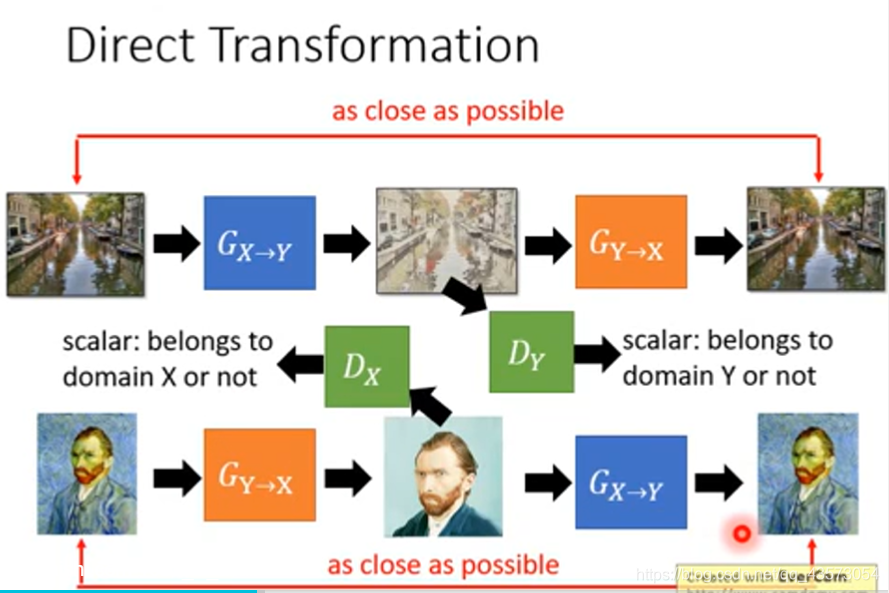
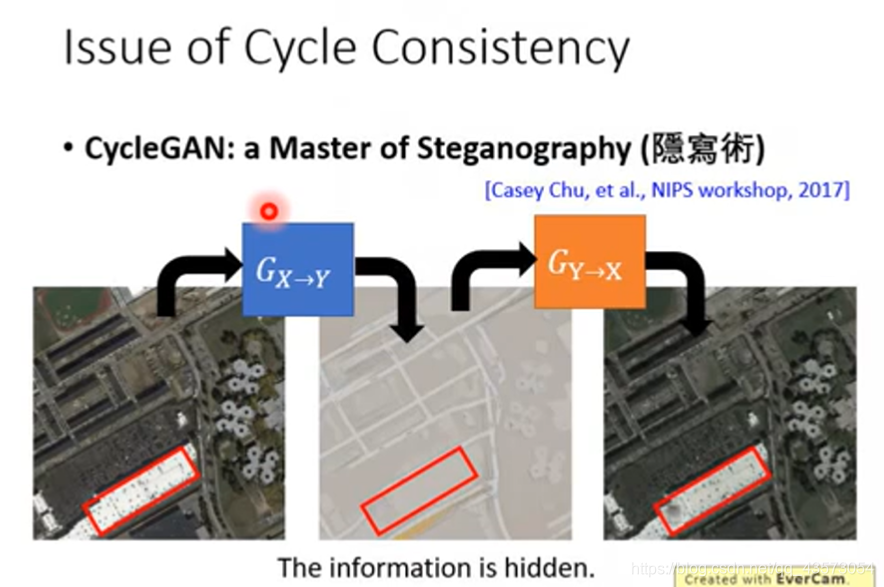
如果你想train一个X domain到Y domain的生成器,你需要同时train一个Y domain到X domain的生成器;第一个生成器用于将风景画变成复古画,第二个用于将复古画还原为原来一模一样的图;然后目标是两次转换以后的图越接近越好。(这个路径叫做cycle consistency)
同时训练Y domain的判别器;
重复上面的X domain转换为Y domain;我们再训练一个Y domain到X domain同样的结构;
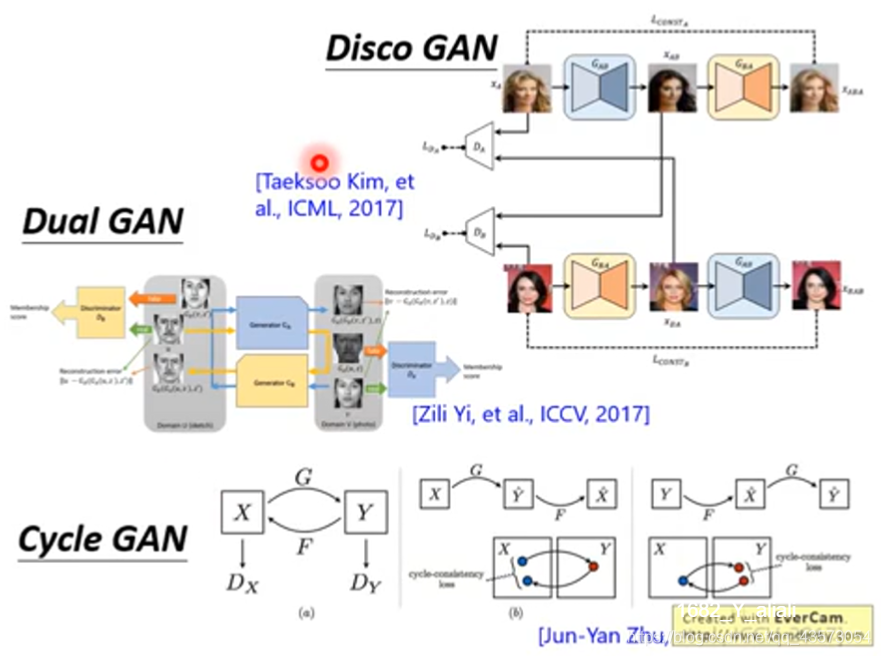

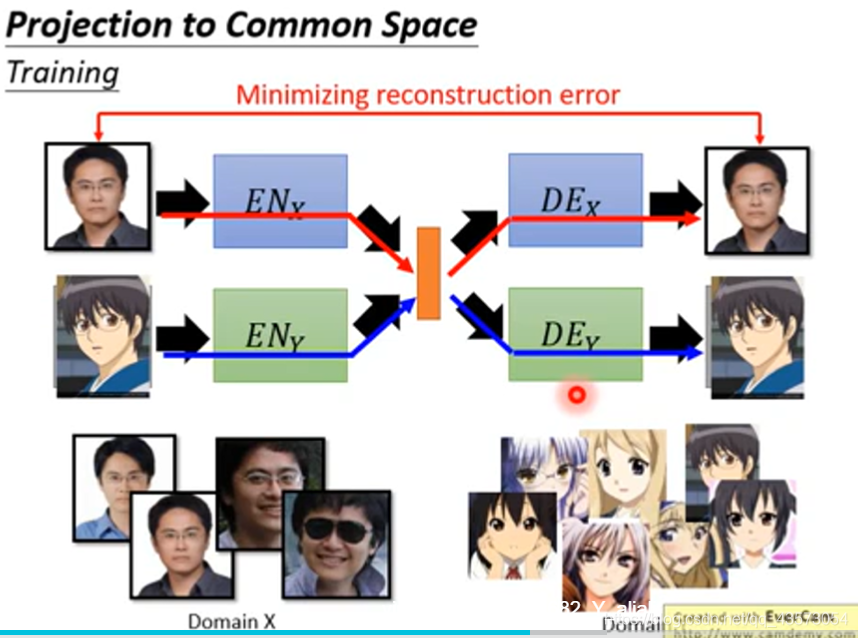
Projection to Common Space
真人图片丢到ENx,可以抽出真人的特征到latent vector(橙色),然后经过二次元的DEx,得到对应的二次元图片;二次元图片丢到ENy,可以抽出二次元的特征到latent vector(橙色),然后经过真人的DEy得到对应的真人图片。
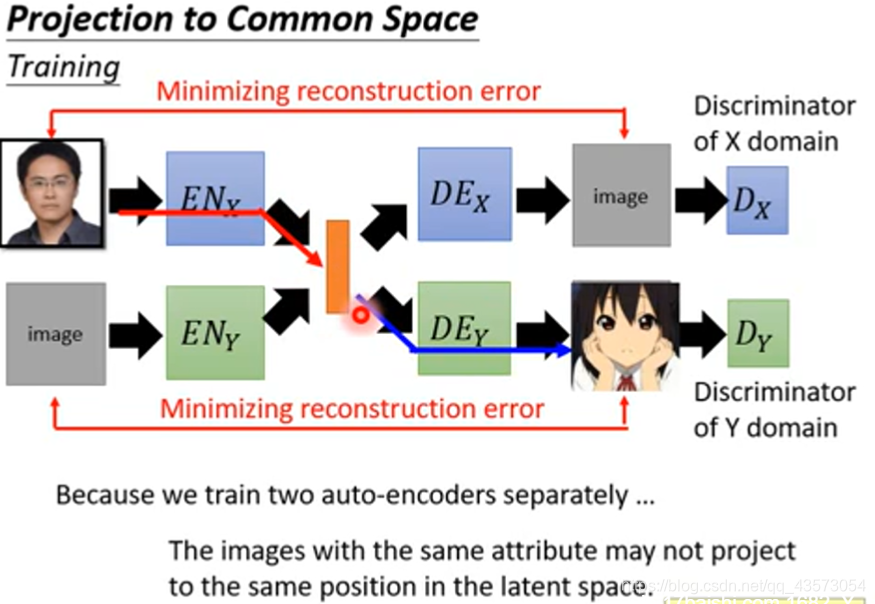
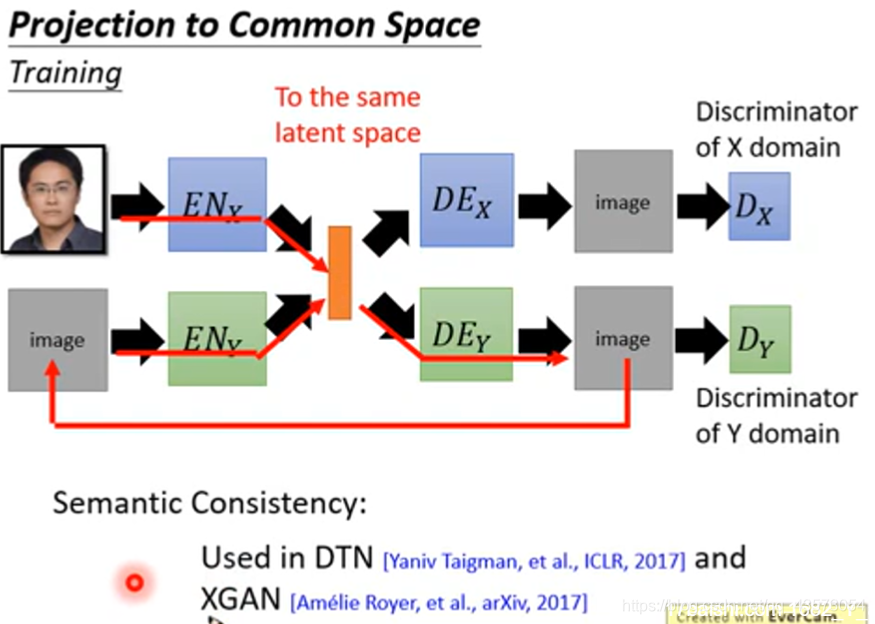
由于两个auto-encoder是分开train的,所以两者之间是没有关联的;例如当你丢个X domain的人脸进去,变成一个vector,当输入Y domain的encoder中时,可能出现一个截然不同的卡通人物。因为是分开训练的,所以在latent space中每个维度的表示属性是不一样的,如上面的auto-encoder用第一维代表性别,而下面一组则用其他代表性别;
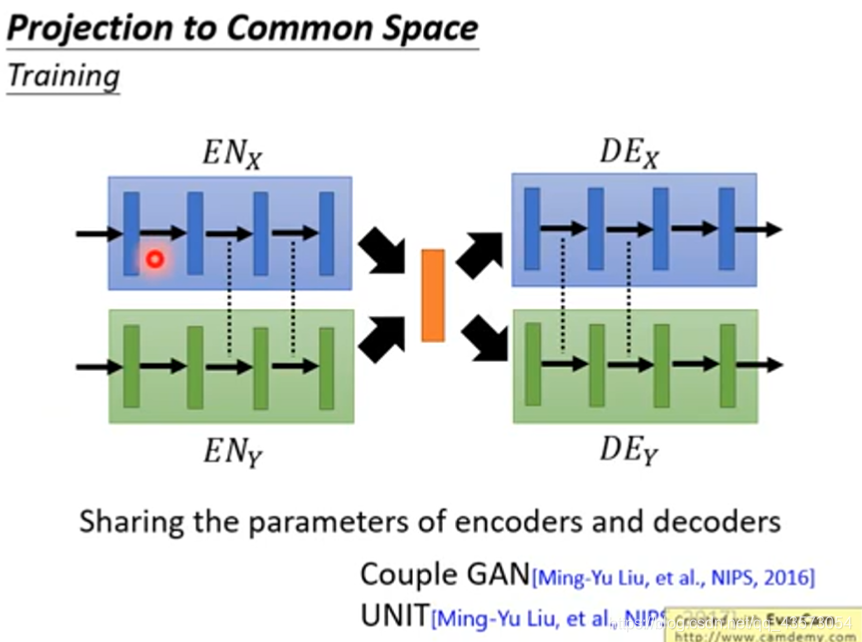
共享参数
让不同domain的decoder的最后几个hidden layer和encoder的最前面几个hidden layer的参数是共用的;通过共享参数,可能会是不同domain的image压缩到同一个latent space(潜在的空间),即同样的dimension 表示同样的属性。这样的技术被用在couple GAN 和UNIT里面。
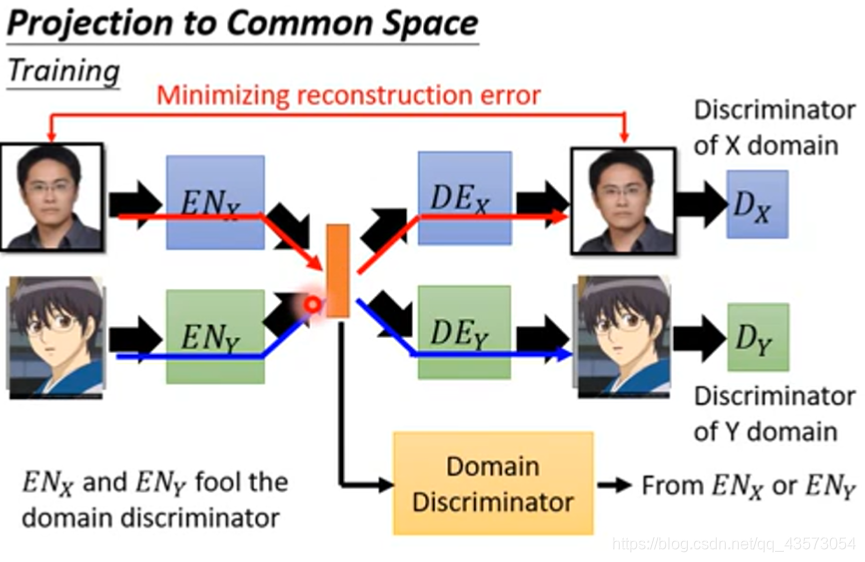
增加判别网络
原来X domain和Y domain都是自己搞自己的东西,现在,用一个domain 判别器来判断这个vector是来自于X domain的image还是来自于Y domain的image。两个encoder的作用是骗过这个domain 判别器。当无法判断的时候,就是说明两者被encode到同一个空间。
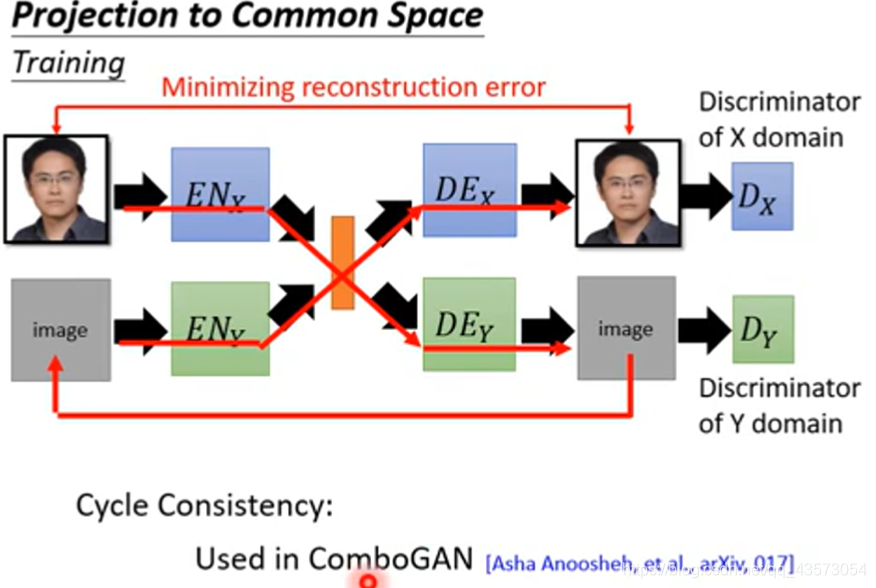
Combo GAN(Cycle Consistency)
将一张image经过X encoder变成code;再经过Y docoder把它解回来;然后再丢给Y domain的encoder,再透过X domain的decoder把它解回来;然后希望input和output越接近越好。
Voice Conversion
过去,用的监督学习的方法,要有一堆对应的声音:然后训练一个seq2seq的模型就可以了,但是这个模型是有缺陷的,例如我想要变声为张学友,那很难请到张学友跟我一起念同样的句子,然后来训练
如今,我们只要收集两组声音,不用讲一样的内容就可以进行训练