���ѧϰ
һ�����������
1�������ʵİ�����ϵ

2���˹���Ԫ
- �˹���Ԫ: ������Ԫ�г����������ѧģ�͡�
- M-Pģ��: �����˹���Ԫ��������ģ�͡�
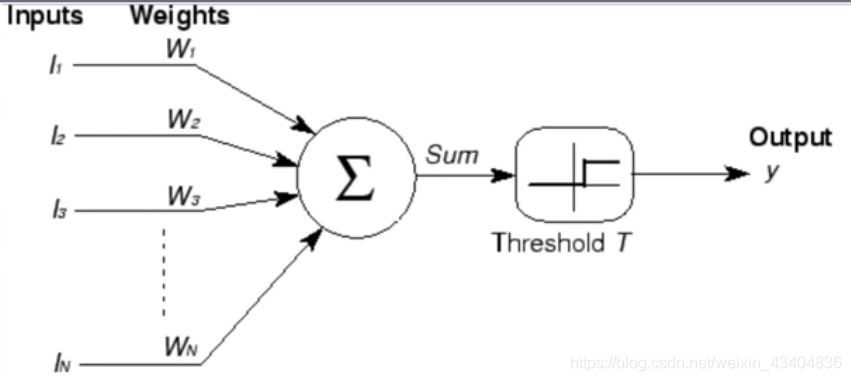
- �˹�������: ������Ԫ��ij�����ӷ�ʽ���ɵĻ���ѧϰģ�͡�
����: - ��֪��(Perceptron): ֻ������������;�����Ϊ��Ծ������
- ȱ��: ������������,�����������Ե�,��Ȼ�����������⡣
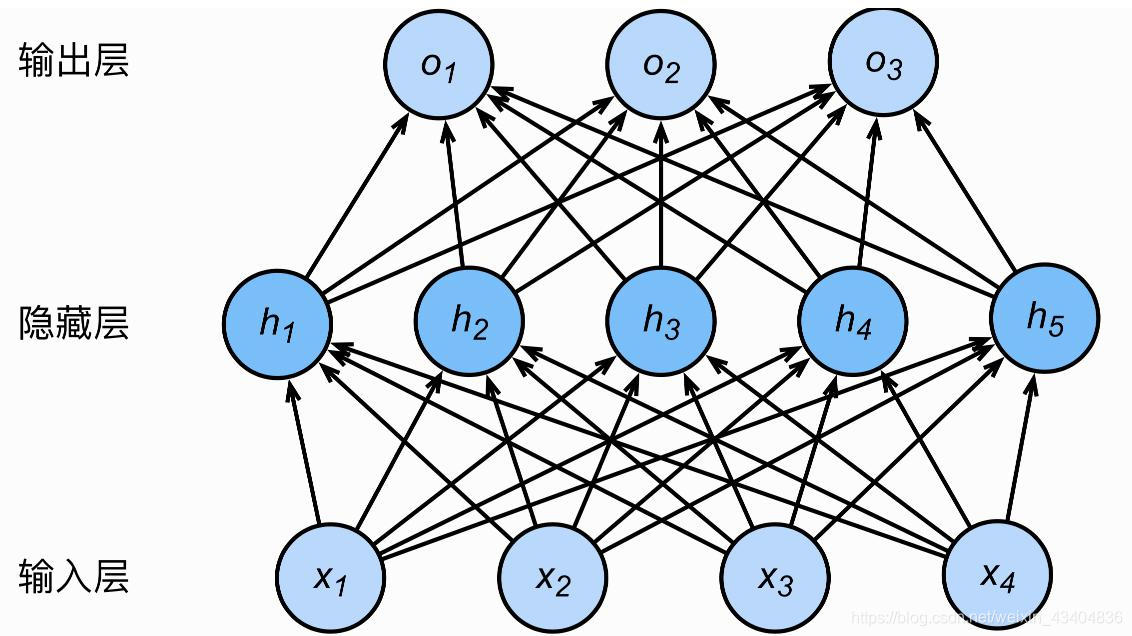
3������֪��
- ����: �ڵ������������������һ���������ز�,ʹ�������ж�����ز㡣
- ����֪����ǰ��:
I n p u t : H = �� 1 ( X w 1 ) Input:H=��_1(Xw_1) Input:H=��1?(Xw1?) O u t p u t : O = �� 2 ( H w 2 ) Output:O=��_2(Hw_2) Output:O=��2?(Hw2?)
�� ( ) ��() ��()Ϊ������� - Ϊʲô��Ҫ�����?
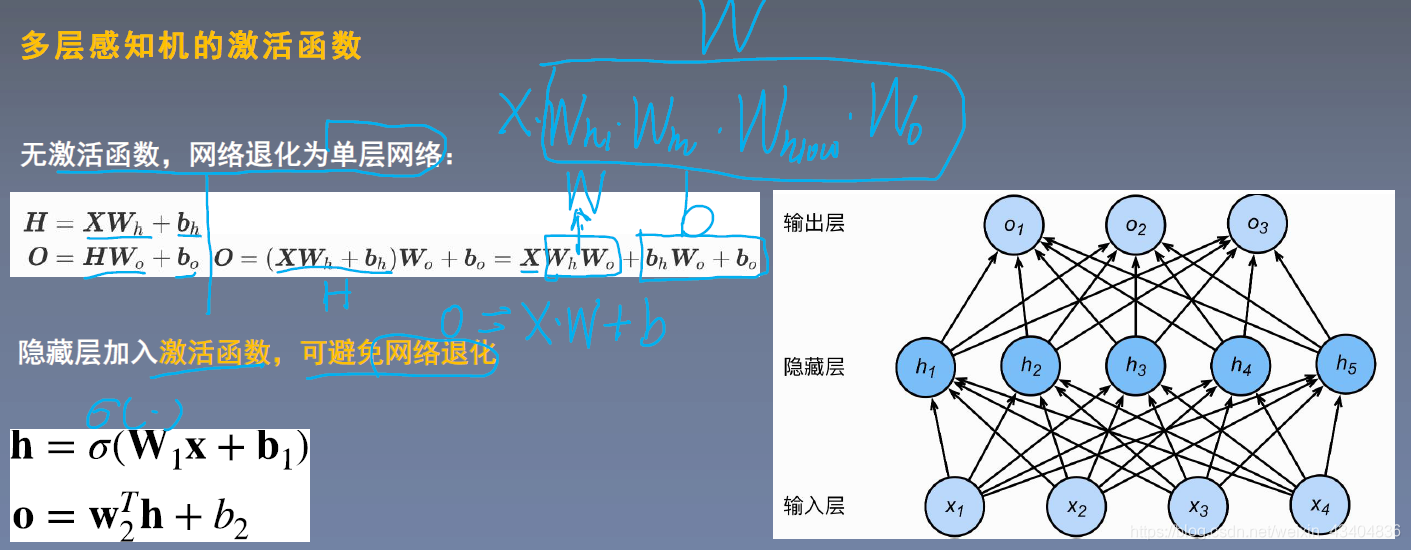
4�������
- �����������:
(1) �ö���֪����Ϊ�����Ķ��,����ȼ���һ��
(2) ���������,ʹ������Աƽ���������Ժ��� (���ܱƽ�����,ununiversal approximator)�� - �������Ҫ������:
(1) �������ɵ�(�����������ϲ��ɵ�),����������ֵ�Ż��ķ�����ѧϰ���������
(2) ��������䵼����Ҫ�����ܵ���,����������������Ч�ʡ�
(3) ������ĵ�������ֵ��Ҫ�ں���������,����̫��Ҳ����̫С,�����Ӱ��ѵ����Ч�ʺ��ȶ��ԡ� - �����ļ����:
- (1) Sigmoid����(S��):
g ( x ) = 1 1 + e ? x g(x)=\frac{1}{1+e^{-x}} g(x)=1+e?x1? g �� ( x ) = g ( x ) ? ( 1 ? g ( x ) ) g^{'}(x)=g(x)*(1-g(x)) g��(x)=g(x)?(1?g(x))

�ص�: ��,���������ߴ���������(������0),�ݶȼ�������,�ᵼ������ѵ���Ƚ�����,�����м䲿����������,��Ϊ��������
ֵ��:(0,1) - (2) Tanh����(˫������):
t a n h ( x ) = e x ? e ? x e x + e ? x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e?xex?e?x? g �� ( x ) = 1 ? ( g ( x ) ) 2 g^{'}(x)=1-(g(x))^2 g��(x)=1?(g(x))2
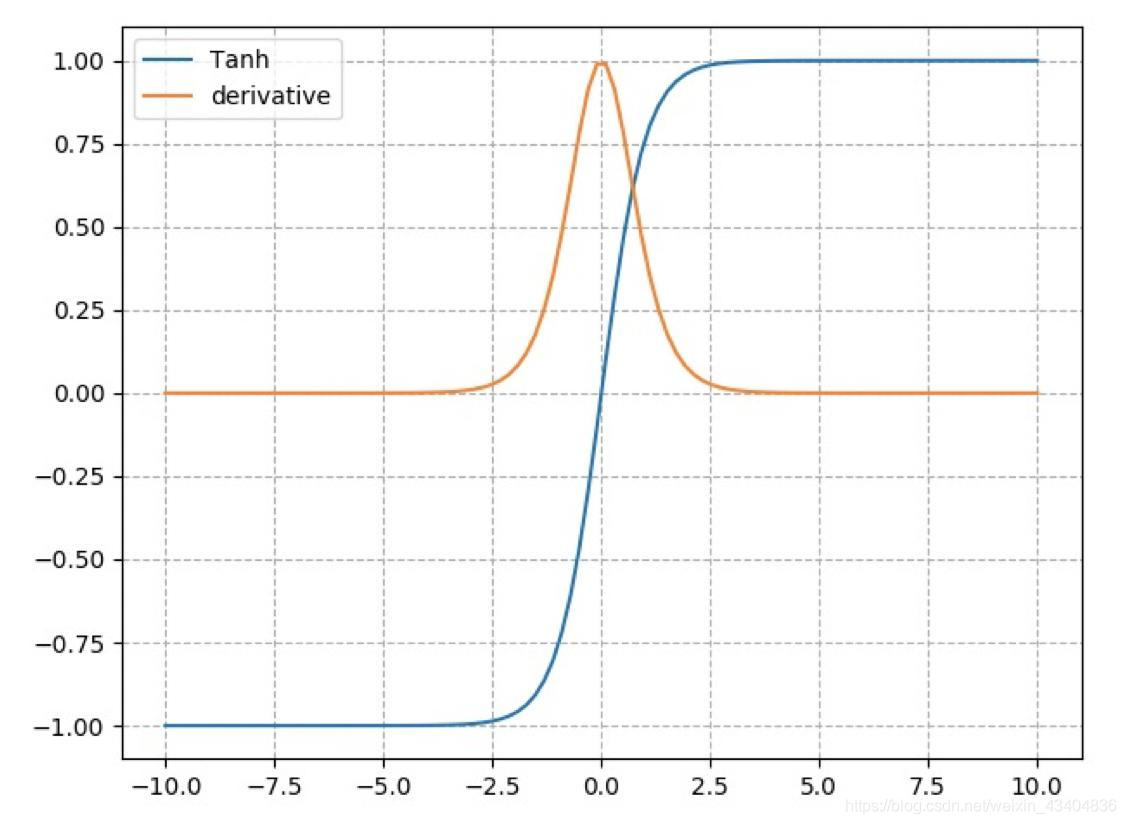
�ص�: �Գ�,Ҳͬ����������������������
ֵ��:(-1,1) - (3) ReLu����:
R e L u = m a x ( 0 , x ) ReLu=max(0,x) ReLu=max(0,x) g �� ( x ) = { 1 x>0 u n d e f i n e d x=0 0 x<0 g^{'}(x)= \begin{cases} 1& \text{x>0}\\ undefined& \text{x=0}\\ 0& \text{x<0} \end{cases} g��(x)=??????1undefined0?x>0x=0x<0?
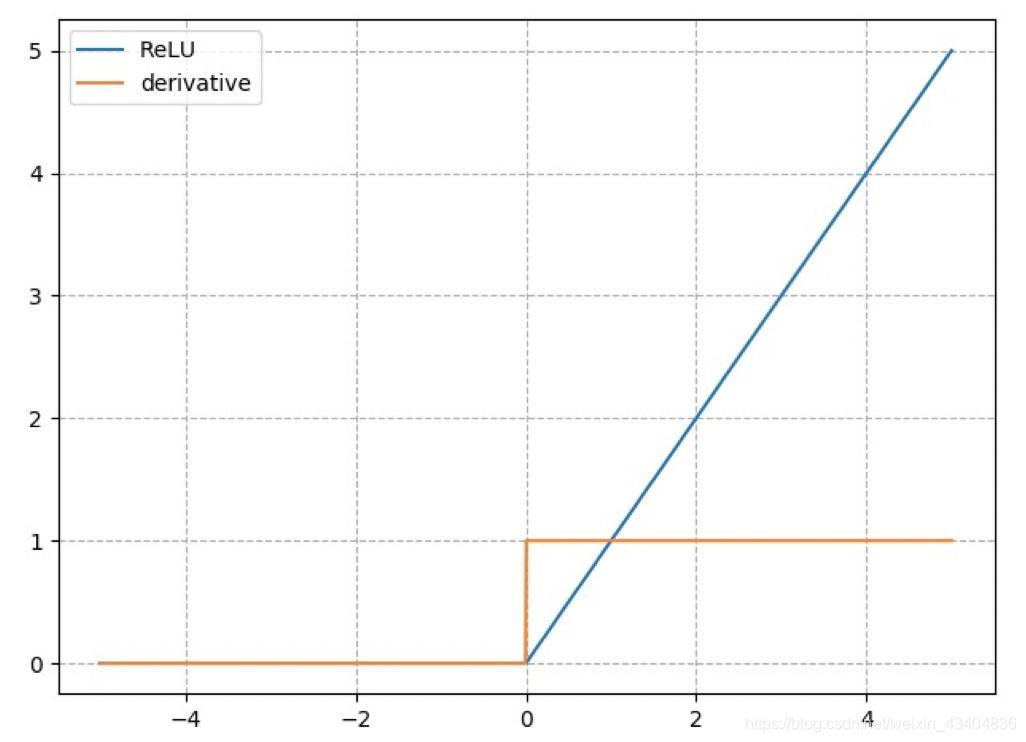
�ص�: ��Ҫ������CNN���ز���,��0�����ɵ�,������Ϊ����Ϊ0��1��
�ܽ�: ��Ϊ����:ǰ����Ϊ�������ͼ����,ReLuΪ�DZ��ͼ������
- (1) Sigmoid����(S��):
5������
-
ǰ��: ��������ݿ�ʼ��ǰ���,��������������㡣
-
����: ��ʧ������ʼ�Ӻ���ǰ,�ݶ����ݵ���һ�㡣
-
��������: ����Ȩ������,ʹ����������ӽ���ǩ��
-
����ԭ��: �����е���ʽ����: y = f ( u ) , u = g ( x ) y=f(u),u=g(x) y=f(u),u=g(x) ? y ? x = ? y ? u ? u ? x \frac{\partial y}{\partial x}=\frac{\partial y}{\partial u}\frac{\partial u}{\partial x} ?x?y?=?u?y??x?u?
-
����ʾ��ͼ:
-
���崫��:
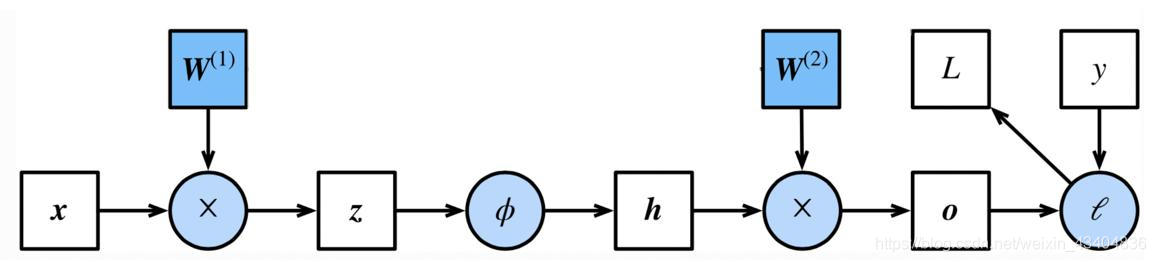
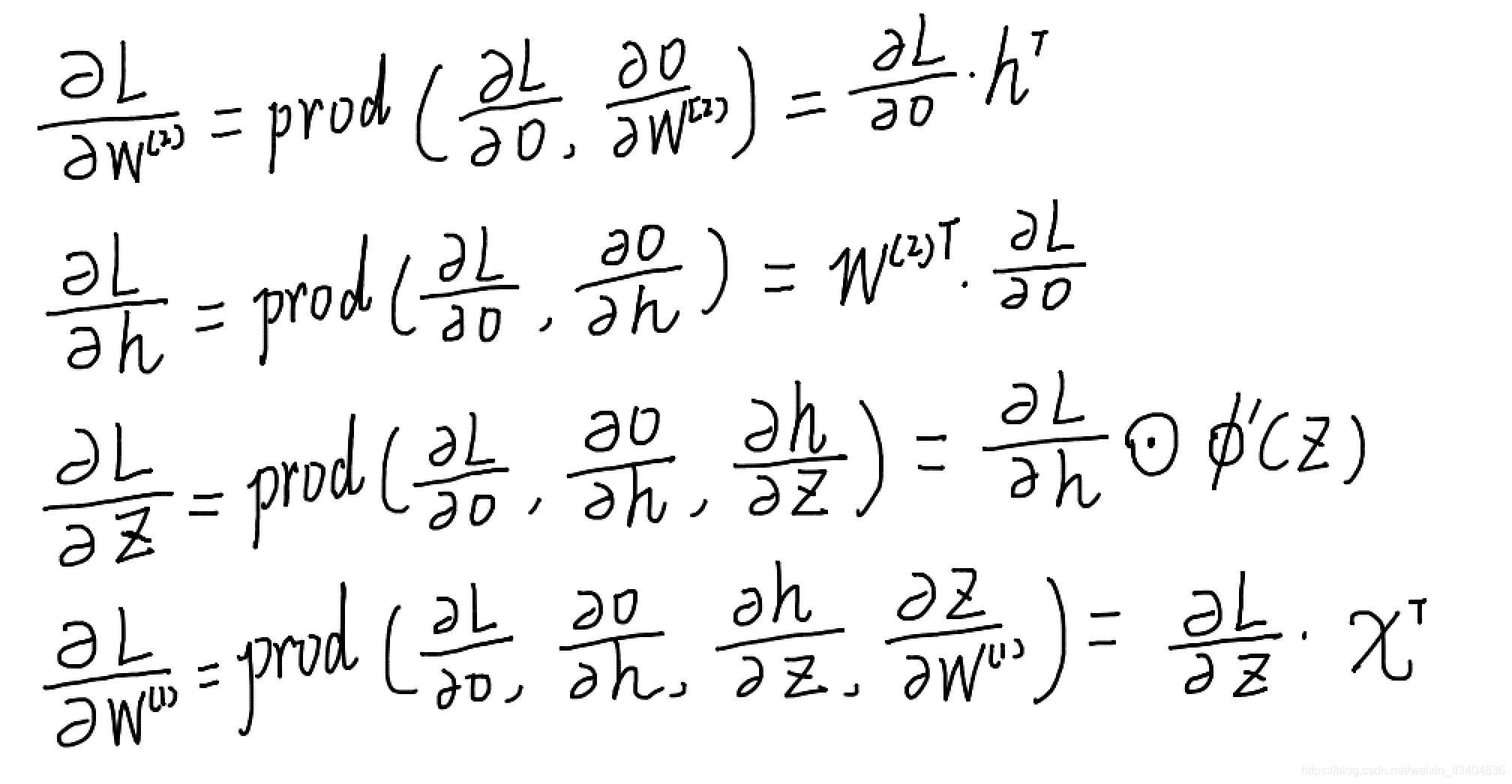
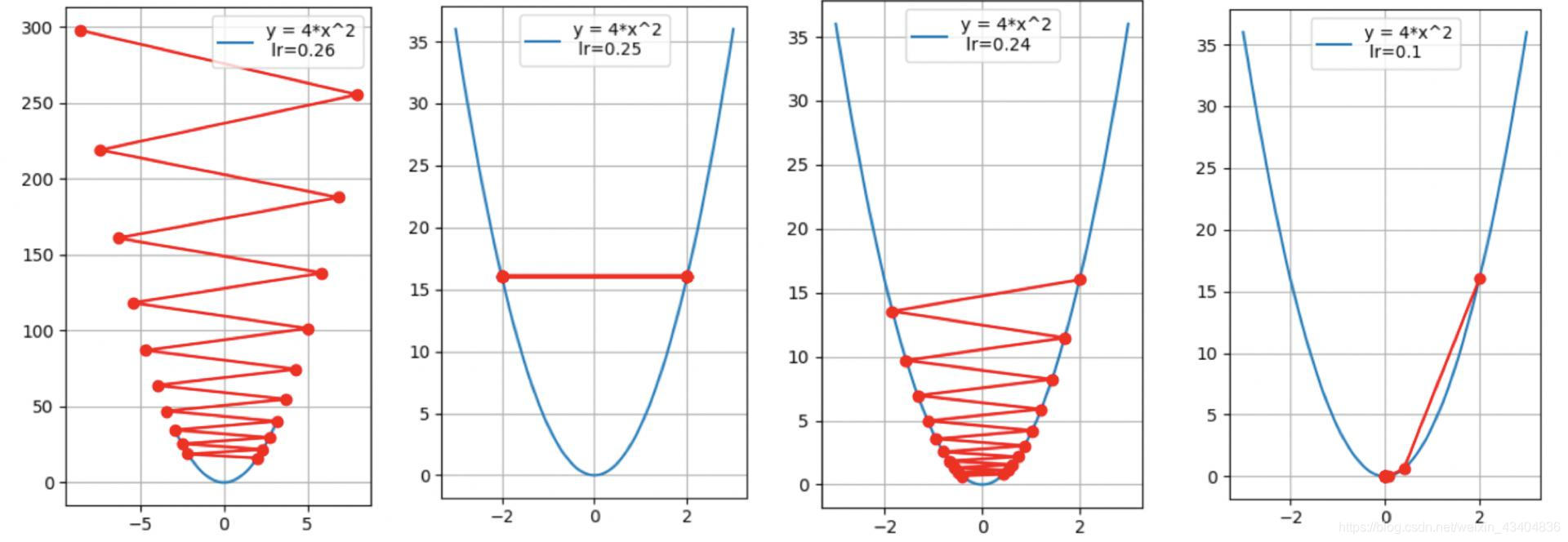
- �ݶ��½���:
Ȩֵ���ݶ�����������,ʹ����ֵ��С��
����: ������ָ���������ϵı仯�ʡ�
������: ָ�������ϵı仯��(��Ԫ����)��
�ݶ�: һ������,����Ϊ������ȡ�����ֵ�ķ��� - ѧϰ��: ���Ƹ��²�����
6����ʧ����
- ��������������:
- ��ʧ����: ����ģ����������DZ�ǩ�IJ���, L o s s f ( y , , y ) Loss f(y^,,y) Lossf(y,,y)(�������ǵ�����)��
- ���ۺ���: C o s t = 1 N �� i N f ( y i , , y i ) Cost=\frac{1}{N}\sum_i^Nf(y_i^,,y_i) Cost=N1?��iN?f(yi,?,yi?) (������������) ��
- Ŀ�꺯��: O b j = C o s t + R e g u l a r i z a t i o n T e r m Obj=Cost+Regularization Term Obj=Cost+RegularizationTerm (������������,��ֹ�����)��
- ��������ʧ����:
- MSE(�������): M S E = �� i N ( y i , ? y i p ) 2 n MSE=\frac{\sum_i^N(y_i^,-y_i^p)^2}{n} MSE=n��iN?(yi,??yip?)2?,�������ع������С�
- CE(������):
H
(
p
,
q
)
=
?
��
i
=
1
n
p
(
x
i
)
l
o
g
q
(
x
i
)
H(p,q)=-\sum_{i=1}^np(x_i)logq(x_i)
H(p,q)=?��i=1n?p(xi?)logq(xi?),Դ����Ϣ��,���ں��������ֲ��IJ���,���������������С�
p p p����ʵ�ֲ�, q q q��ģ�͡�
- ��ظ���:
- �����(�ֽ�K-Lɢ��)
D
k
l
(
P
�O
�O
Q
)
D_{kl}(P||Q)
Dkl?(P�O�OQ)��������
H
(
p
,
q
)
H(p,q)
H(p,q)����Ϣ��
H
(
x
)
H(x)
H(x)
D K L ( P �� Q ) = E x �� p [ log ? P ( x ) Q ( x ) ] = E x �� p [ log ? P ( x ) ? log ? Q ( x ) ] = �� i = 1 N P ( x i ) ( log ? P ( x i ) ? log ? Q ( x i ) ) \begin{aligned} D_{K L}(P \| Q)=E_{x \sim p}\left[\log \frac{P(x)}{Q(x)}\right] &=E_{x \sim p}[\log P(x)-\log Q(x)] &=\sum_{i=1}^{N} \mathrm{P}\left(\mathrm{x}_{i}\right)\left(\log P\left(\mathrm{x}_{i}\right)-\log \mathrm{Q}\left(\mathrm{x}_{i}\right)\right) \end{aligned} DKL?(P��Q)=Ex��p?[logQ(x)P(x)?]?=Ex��p?[logP(x)?logQ(x)]?=i=1��N?P(xi?)(logP(xi?)?logQ(xi?))?
H ( p , q ) = ? �� i = 1 n p ( x i ) l o g q ( x i ) H(p,q)=-\sum_{i=1}^np(x_i)logq(x_i) H(p,q)=?i=1��n?p(xi?)logq(xi?)
H ( x ) = E x �� p [ I ( x ) ] = ? E [ log ? P ( x ) ] = ? �� i = 1 N p i log ? ( p i ) H(\mathrm{x})=E_{x \sim p}[I(x)]=-E[\log P(x)]=-\sum_{i=1}^{N} p_{i} \log \left(p_{i}\right) H(x)=Ex��p?[I(x)]=?E[logP(x)]=?i=1��N?pi?log(pi?)
����֮���ϵ: ������=��Ϣ��+�����,��:
H ( p , q ) = H ( p ) + D k l ( P �O �O Q ) H(p,q)=H(p)+D_{kl}(P||Q) H(p,q)=H(p)+Dkl?(P�O�OQ)
����Ż������صȼ����Ż�����ء�
- �����(�ֽ�K-Lɢ��)
D
k
l
(
P
�O
�O
Q
)
D_{kl}(P||Q)
Dkl?(P�O�OQ)��������
H
(
p
,
q
)
H(p,q)
H(p,q)����Ϣ��
H
(
x
)
H(x)
H(x)
- ע���:
- ������:�����������ʷֲ��IJ���
- ��������������:
1 . ����ֵ�ǷǸ���
2 . ����֮�͵���1
- �����صĺû�顪��Softmax����: �����ݱ任�����ϸ��ʷֲ�����ʽ��
y i = S ( z ) i = e z i �� j = 1 C e z j , i = 1 , �� , C y_{i}=S(\boldsymbol{z})_{i}=\frac{e^{z_{i}}}{\sum_{j=1}^{C} e^{z_{j}}}, i=1, \ldots, C yi?=S(z)i?=��j=1C?ezj?ezi??,i=1,��,C - û��һ���ʺ������������ʧ����,��ʧ������ƻ��漰�㷨���͡����Ƿ����ס��������쳣ֵ�ķֲ������⡣
������ʧ�����ɵ�PyTorch��վ:https://pytorch.org/docs/stable/nn.html#loss-functions
�������: https://zhuanlan.zhihu.com/p/61379965
7��Ȩֵ��ʼ��
- ����: ѵ��ǰ��Ȩֵ������ֵ,���õ�Ȩֵ��ʼ��������ģ��ѵ����
- ע���: ȫ����ʼ��Ϊ��(��������,��ʹ�������˻�)(Ȩ��Ҳ����̫��,�����뼤����ı�����)��
- ��ʼ������:
- �����ʼ������: ��˹�ֲ������ʼ��,�Ӹ�˹�ֲ����������,��Ȩֵ���и�ֵ,����
N
?
(
0
,
0.01
)
N~(0,0.01)
N?(0,0.01)��
- ����Ӧ����: Xavier��ʼ����Kaiming��ʼ��(MSRA)��
- �����ʼ������: ��˹�ֲ������ʼ��,�Ӹ�˹�ֲ����������,��Ȩֵ���и�ֵ,����
N
?
(
0
,
0.01
)
N~(0,0.01)
N?(0,0.01)��
8��������
-
Regularization: ��С����IJ���,ͨ������Ϊ���������IJ��ԡ�
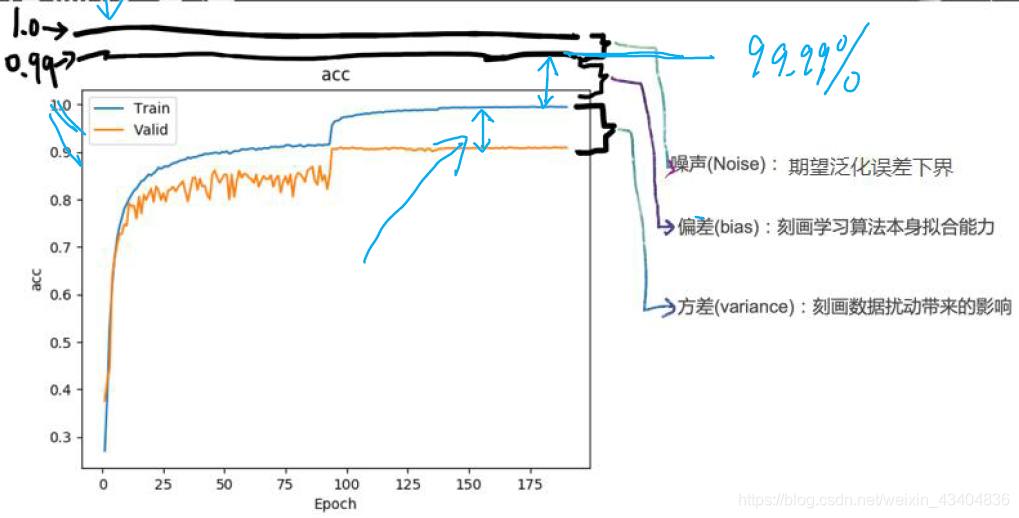
-
���=ƫ��+����+����
- ƫ��: ������ѧϰ�㷨������Ԥ������ʵ�����ƫ��̶�,���̻���ѧϰ�㷨���������������
- ����: ������ͬ����С��ѵ�����ı䶯�����µ�ѧϰ���ܵı仯,���̻��������Ŷ�����ɵ�Ӱ�졣
- ����: ��������ڵ�ǰ�������κ�ѧϰ�㷨���ܴﵽ���������������½硣
-
�����: �������,��ѵ������������,�ڲ��Լ�������⡣
-
����: L1���� �O w i �O |w_i| �Owi?�O��L2����(Ҳ��Ȩֵ˥��) w i 2 w_i^{2} wi2?:

- Ŀ�꺯��(����L2����): O b j = L o s s + �� 2 ? �� i N w i 2 Obj=Loss+\frac{\lambda}{2} * \sum_{i}^{N} w_{i}^{2} Obj=Loss+2��??��iN?wi2?
- ��������: w i + 1 = w i ? ? O b j ? w i = w i ? ? L o s s ? w i w_{i+1}=w_{i}-\frac{\partial O b j}{\partial w_{i}}=w_{i}-\frac{\partial L o s s}{\partial w_{i}} wi+1?=wi???wi??Obj?=wi???wi??Loss?
- ��������:
��
��
(
0
,
1
)
\lambda��(0,1)
����(0,1)
w i + 1 = w i ? ? O b j ? w i = w i ? ( ? L o s s ? w i + �� ? w i . ) = w i ( 1 ? �� ) ? ? L i ? w i w_{i+1}=w_{i}-\frac{\partial O b j}{\partial w_{i}}=w_{i}-(\frac{\partial L o s s}{\partial w_{i}}+\lambda^{\star} w_{i} .)=w_{i}(1-\lambda)-\frac{\partial L_{i}}{\partial w_{i}} wi+1?=wi???wi??Obj?=wi??(?wi??Loss?+��?wi?.)=wi?(1?��)??wi??Li?? - Ч���Ա�:

- ��һ��������:
- Dropout:���ʧ��
- �ŵ�: �����������ij����Ԫ,ʵ�ּ�������
- ���: dropout probability (eg:p=0.5)
- ʧ��: weight = 0
- ע������: ѵ���Ͳ��������ε����ݳ߶ȱ仯����ʱ,��Ԫ���ֵ��Ҫ����p����ͼ:

- ����������:
�ع�
��������������
1���������緢չʷ
����������(convolutional neural networks,CNN): CNN�����ͼ���������������������, ���������˵ķ�չ, ��2012��֮���ͼ������CNNͳ��,����ͼ�����,ͼ��ָ�(ͼ��ָ���ǰ�ͼ��ֳ����ɸ��ض��ġ����ж������ʵ������������ȤĿ��ļ�������),Ŀ����(Ҳ��Ŀ����ȡ,��һ�ֻ���Ŀ�꼸�κ�ͳ��������ͼ��ָ�),ͼ�����(�ı�+ͼ��)�ȡ�
- ͼ��ָ�

- Ŀ����

- �ṹ����ʷ:

2��������
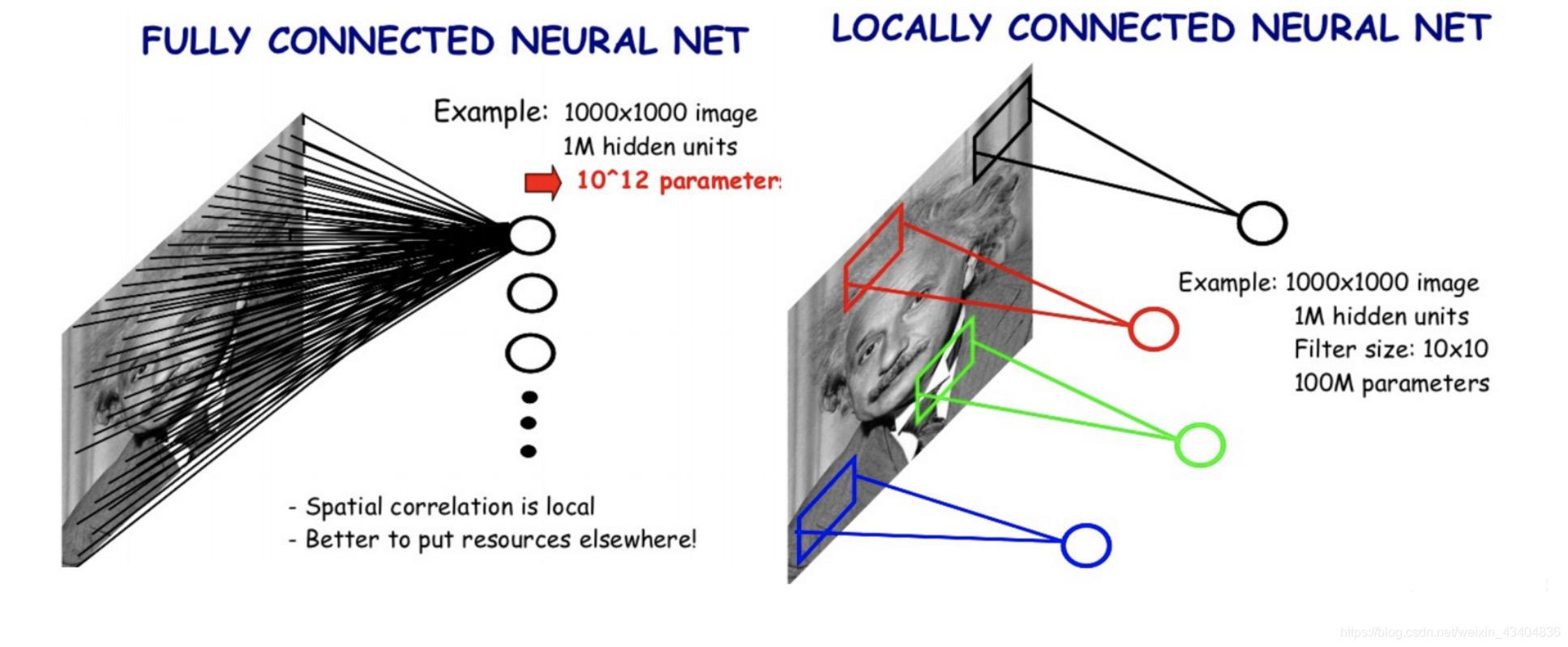
- ͼ��ʶ���ص�:
- �������оֲ���: �ϻ���Ҫ���������֡���������ͷ������
- �������ܳ������κ�λ��
- �²���ͼ��,����ı�ͼ��Ŀ��
- ��ͼ:

- CNN��ͼ��ʶ��õ�������:
- (1) �������оֲ���:������ÿ�ν�����
K
?
K
K*K
K?K����,
K
?
K
K*K
K?K�Ǿ����˳ߴ�:
- (1) �������оֲ���:������ÿ�ν�����
K
?
K
K*K
K?K����,
K
?
K
K*K
K?K�Ǿ����˳ߴ�:
- (2) �������ܳ������κ�λ��:�����˲����ظ�ʹ��(��������),��ͼ���ϻ���:

������: �߿�ѧϰ����������,���ڶ�����ͼ�����������ȡ,���ͨ����Ϊ����ͼ(feature maps):

- ���������:
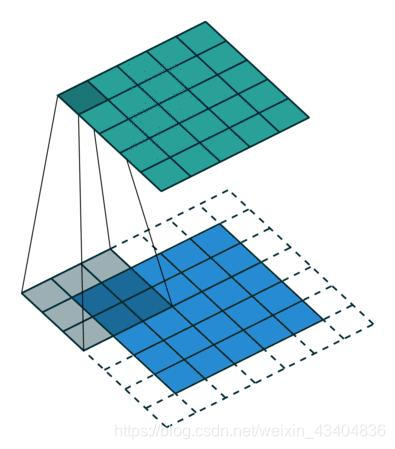
- Padding(���): ������ͼ�����Χ���Ӷ������/�С�
- ����:
- ʹ������ͼ��ֱ��ʲ���, �����������ͼ�ߴ�ı仯
- �ֲ��߽���Ϣ�� ��ʧ��
- Strike(����): �����˻�����?����������Ϊ����,�����������ͼ�Ĵ�С,�ᱻ��С1/s����
- ��μ��㾭��Padding��Strike������ͼƬ��С?
F o = �O F in? ? k + 2 p s ] + 1 \left.F_{o}=\mid \frac{F_{\text {in }}-k+2 p}{s}\right]+1 Fo?=�OsFin???k+2p?]+1
F o : �� �� �� С F_o:�����С Fo?:������С
F i n : �� �� �� С F_in:�����С Fi?n:������С
k : F i l t e r �� �� С k:Filter�Ĵ�С k:Filter����С
p : P a d d i n g �� С p:Padding��С p:Padding��С
s : S t r i k e �� С s:Strike��С s:Strike��С - ��ͨ������: RGBͼ����
3
?
h
?
w
3*h*w
3?h?w����ά������,��һ��ά��3,��ʾchannel,ͨ������
һ����������3-D����,��һ��ά������ͨ���й�
ע: �����˳ߴ�ͨ��ָ�ߡ���
- Padding(���): ������ͼ�����Χ���Ӷ������/�С�


3���ػ�����
- ������ͼ��ʶ��������ص�: �²���ͼ��,����ı�ͼ��Ŀ��:���ͼ�����,�����������ࡣ
- �ػ�: һ�����ر�ʾһ�����������ֵ, ����ͼ��ֱ��ʡ�
- ����:
- Max pooling: ȡ���ֵ
- Average Pooling: ȡƽ��ֵ
- ����ߴ�����������������
- ע��: �ػ�����ѧϰ����
 - **==�ػ�����==:** - ����������λ�õ�**��������**
- **==�ػ�����==:** - ����������λ�õ�**��������**

���������Ӱ�������仯,�ػ���Ӱ���С:

- ��������
- ����ͼ��ֱ���,�Ӷ����ٲ�����
4��Lenet-5��CNN�ṹ
-
����ṹ:

- C1��: ������ K 1 = ( 6 , 1 , 5 , 5 ) , p = 1 , s = 1 , o u t p u t = ( 6 , 28 , 28 ) K1=(6, 1, 5, 5), p=1, s=1,output=(6, 28, 28) K1=(6,1,5,5),p=1,s=1,output=(6,28,28)
- S2��: ���ػ���, �ػ����� = ( 2 , 2 ) , s = 2 , o u t p u t = ( 6 , 14 , 14 ) =(2,2),s=2,output=(6, 14, 14) =(2,2),s=2,output=(6,14,14)
- C3��: ������ K 3 = ( 16 , 6 , 5 , 5 ) , p = 1 , s = 1 , o u t p u t = ( 16 , 10 , 10 ) K3=(16, 6, 5, 5), p=1, s=1,output=(16, 10, 10) K3=(16,6,5,5),p=1,s=1,output=(16,10,10)
- S4��: ���ػ���, �ػ����� = ( 2 , 2 ) , s = 2 , o u t p u t = ( 16 , 5 , 5 ) =(2,2),s=2,output=(16, 5, 5) =(2,2),s=2,output=(16,5,5)
- FC��: 3��FC���������
-
ע��: ǰ�IJ��൱����feature��ȡ,FC���Ǹ����������з���㡣
- ������ȡ��: C1��S2��C3��S4
- ������: 3��FC��