文章目录
一、local minima 和 saddle point
- loss不下降是什么原因?梯度为0(critical point)
- 但local minima 的情况很少,一般saddle point
1.1 如何知道是卡在local minima 还是 saddle point
- 用泰勒级数模拟Loss在该点附近的形状

2. 根据Hessian判断形状:如果H正定则是local minima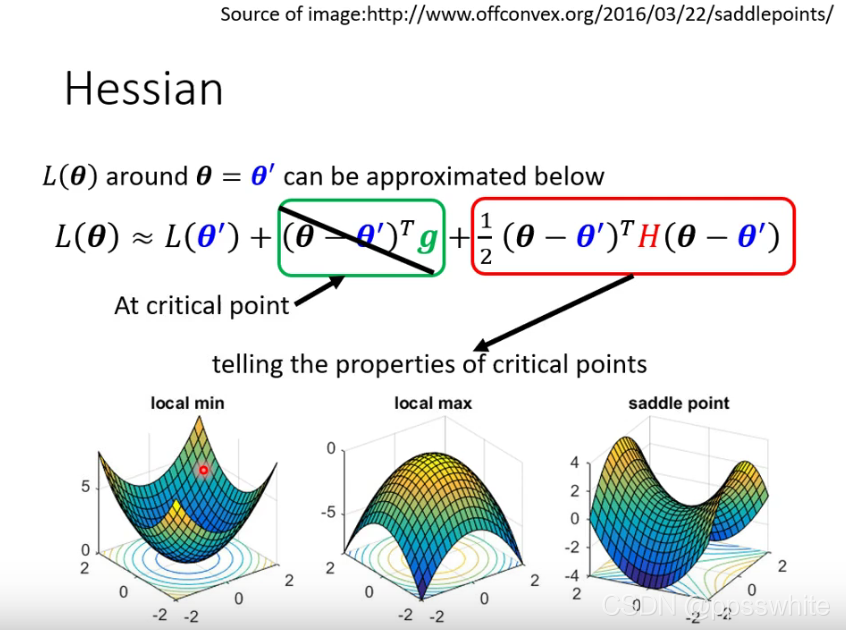

1.2 H可能能告诉我们更新参数的方向

二、 Batch 和 Momentum
2.1 batch
- 实际中把所有的data分成一个一个batch,算完一个epoch后shuffle,让每次的batch都不一样
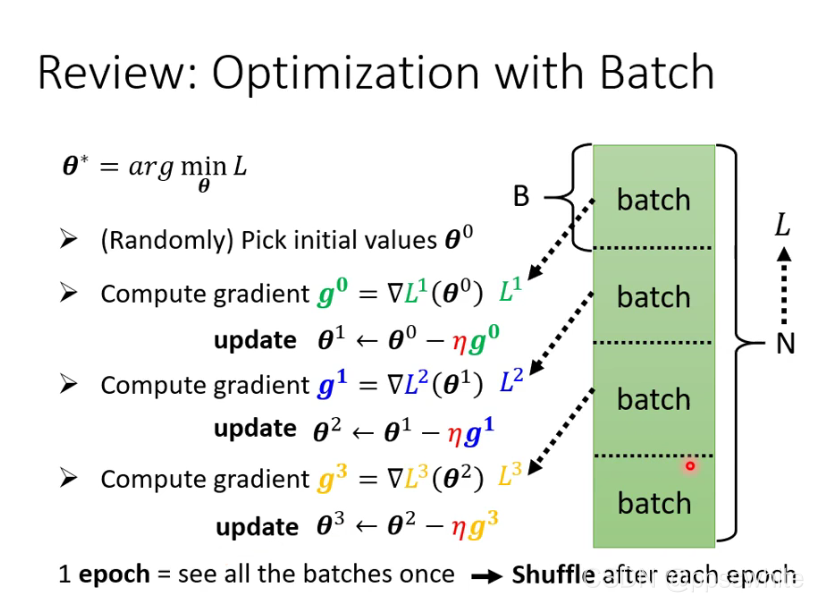
- 为什么要用batch? powerful,虽然冷却时间长,但是可以用GPU平行计算来解决
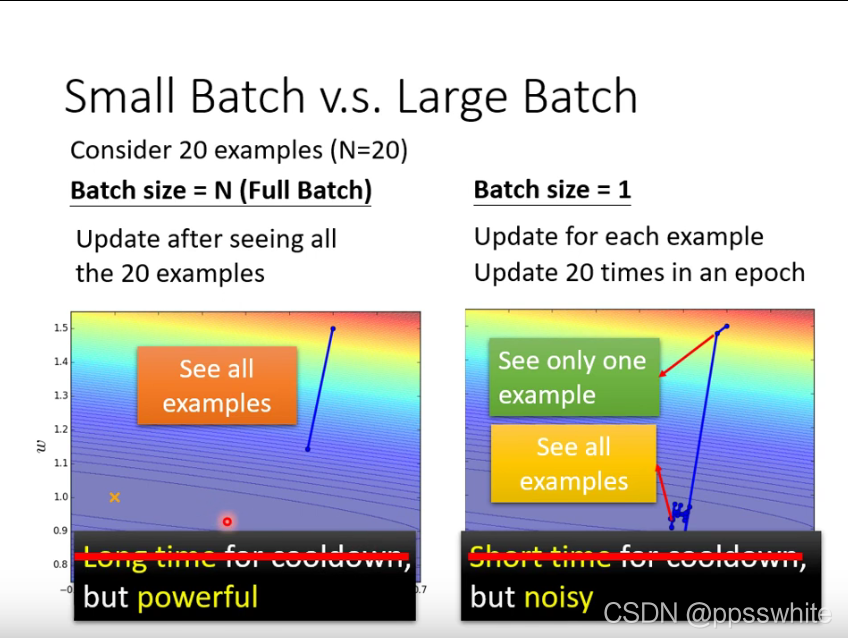
- small batch vs large batch
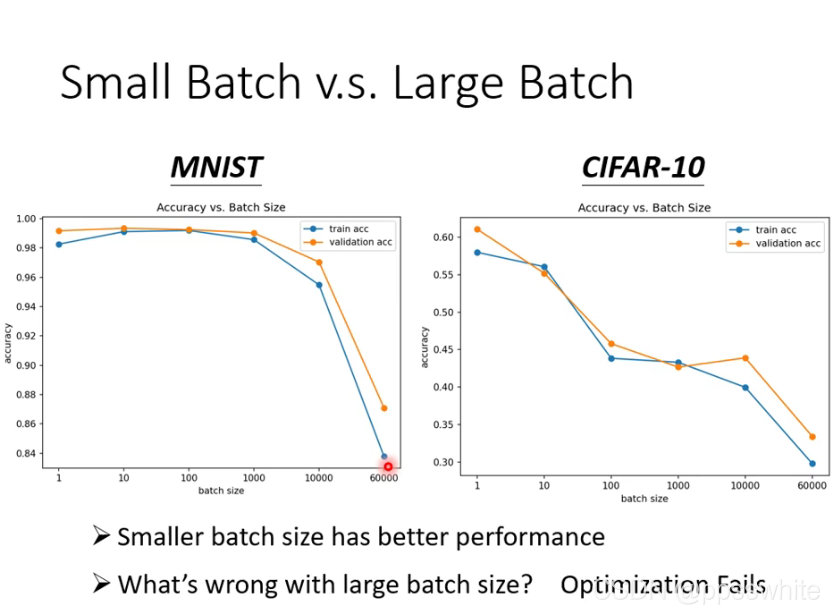
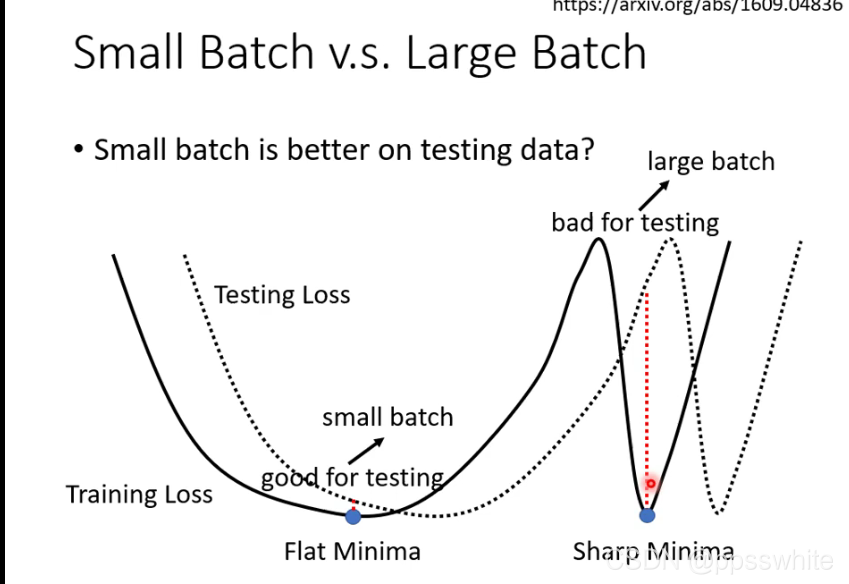
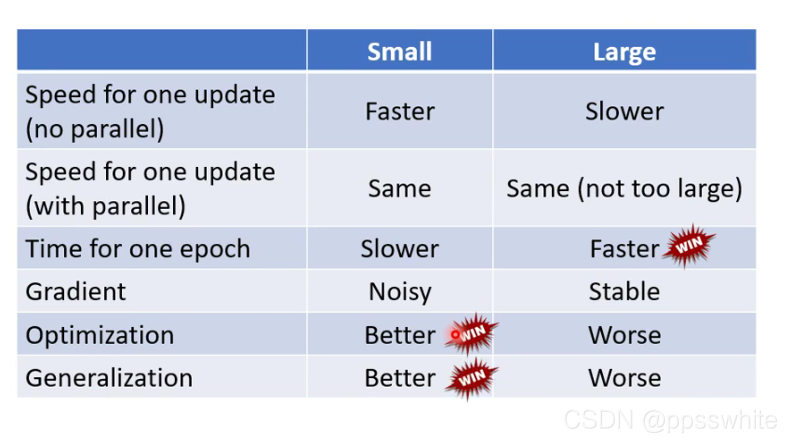
- 鱼与熊掌兼得?可以
2.2 Momentum
-
在移动参数时,加上前一步移动的方向综合决定

-
其实考虑进去了所有移动的总和
三、自动调整学习率
- loss不再下降的时候,gradient不一定很小。
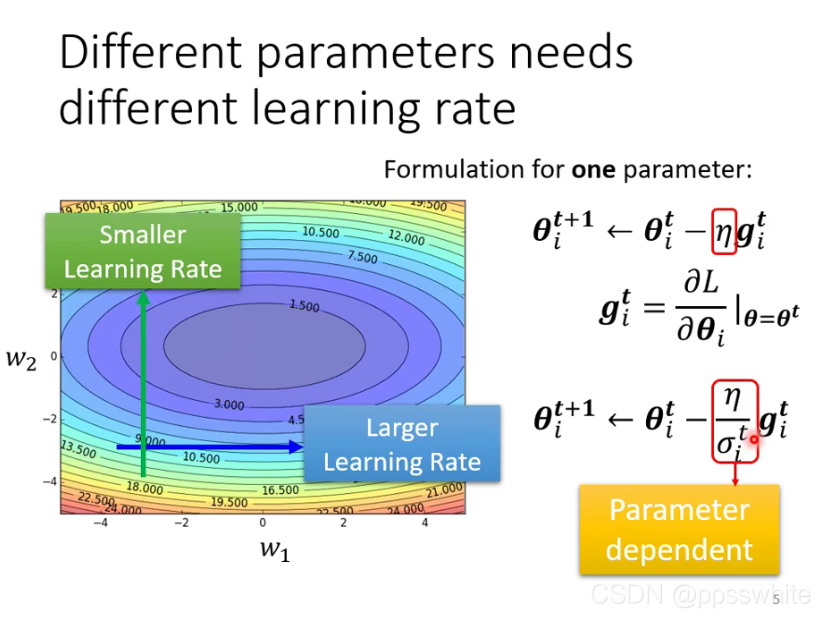
- 自动调整学习率
- Adagrad

4. RMSProp
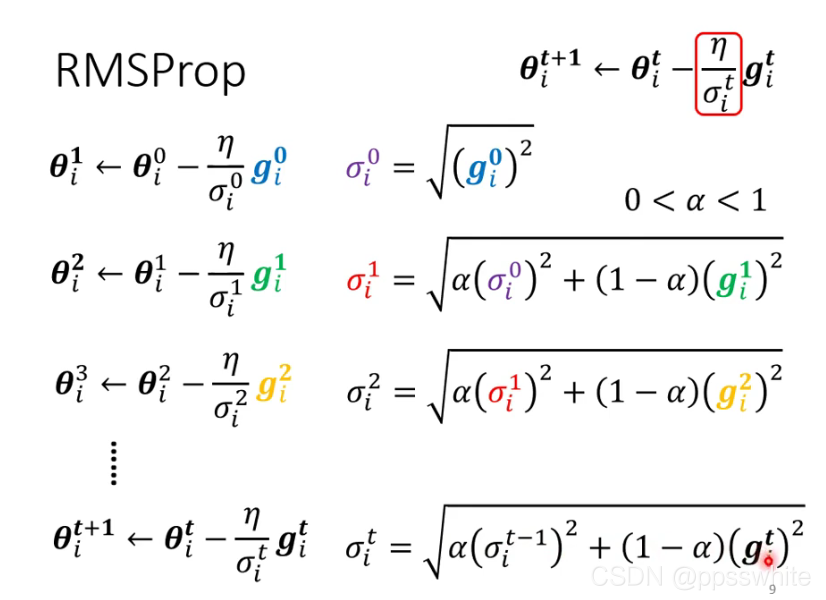
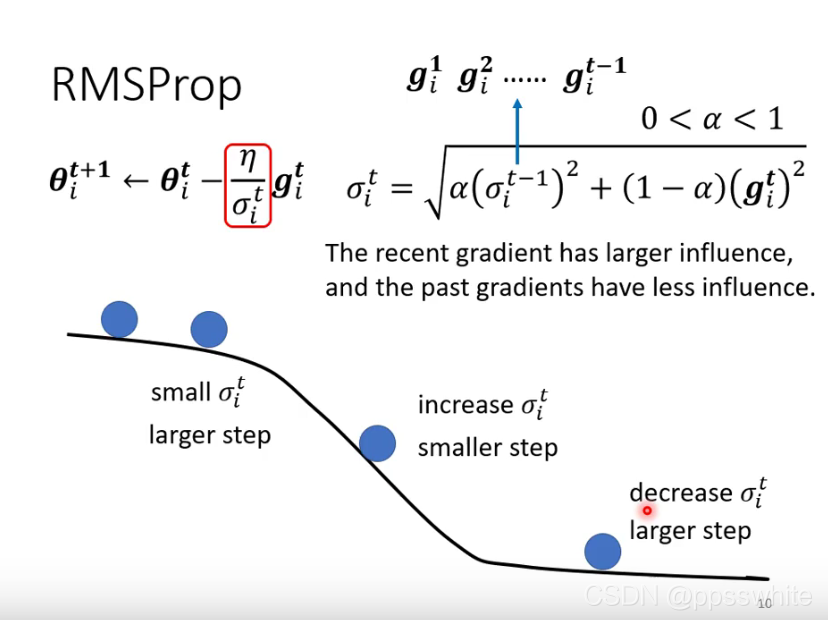
5. Adam
- Warm Up: 先变大后变小
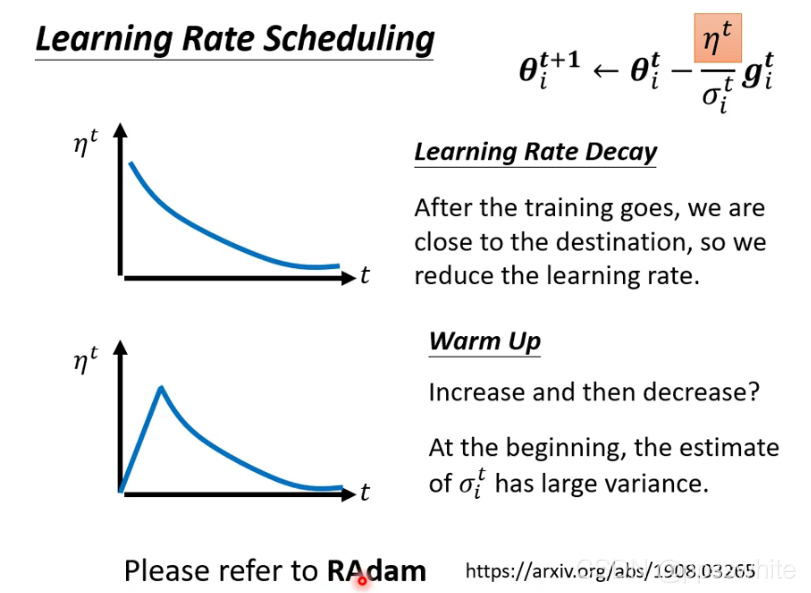
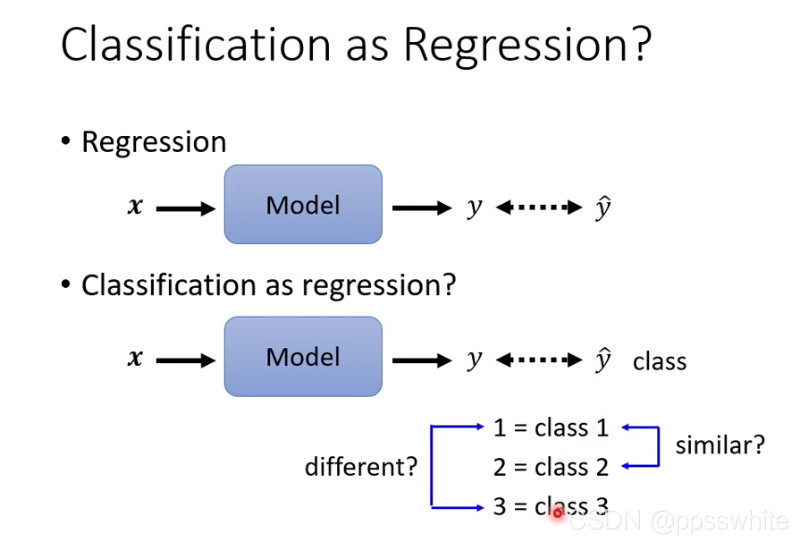
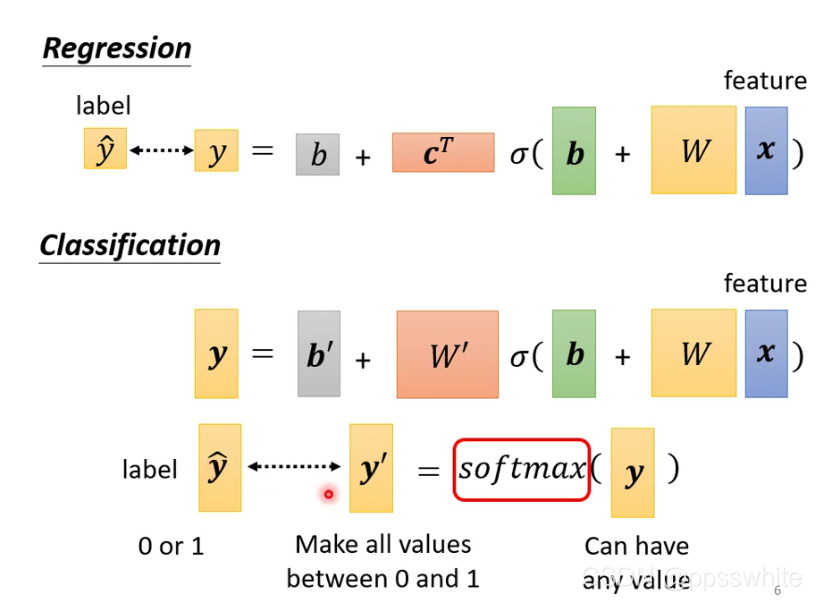
四、 Classification
4.1 classification as regression
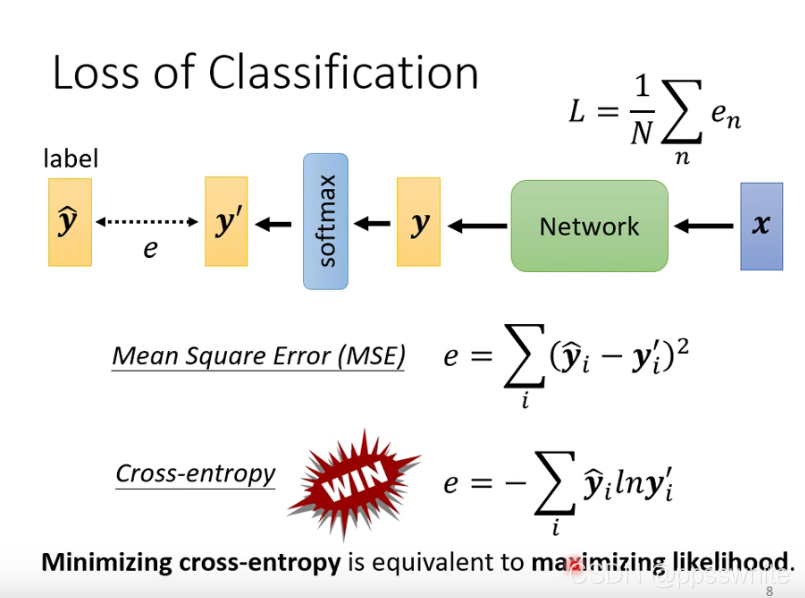
4.2 loss of classification
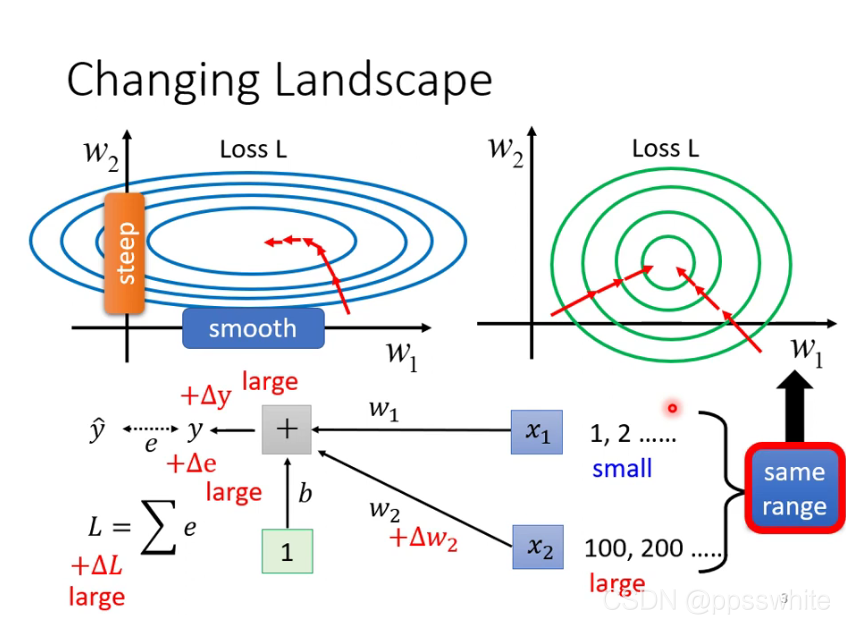
五、批次标准化(Batch Normalization)
- “把山铲平”的方法
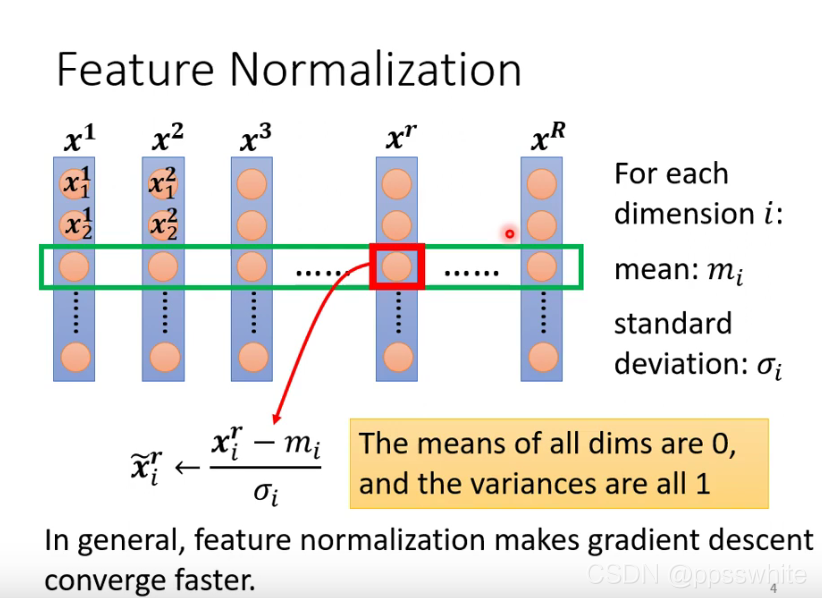
5.1 Feature Normalization
- 标准化
5.2 Considering Deep Learning
-
标准化的时机在激活前和激活后差异不大,这里对z做
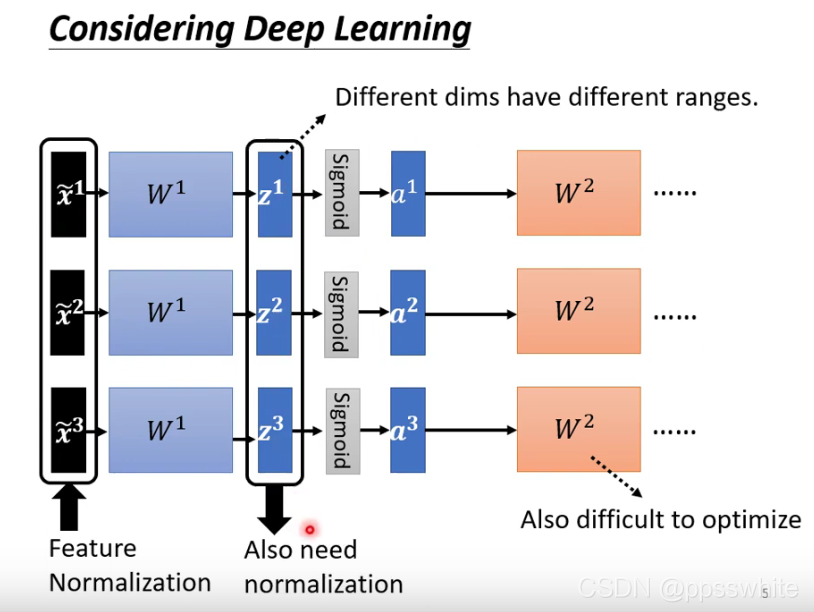
-
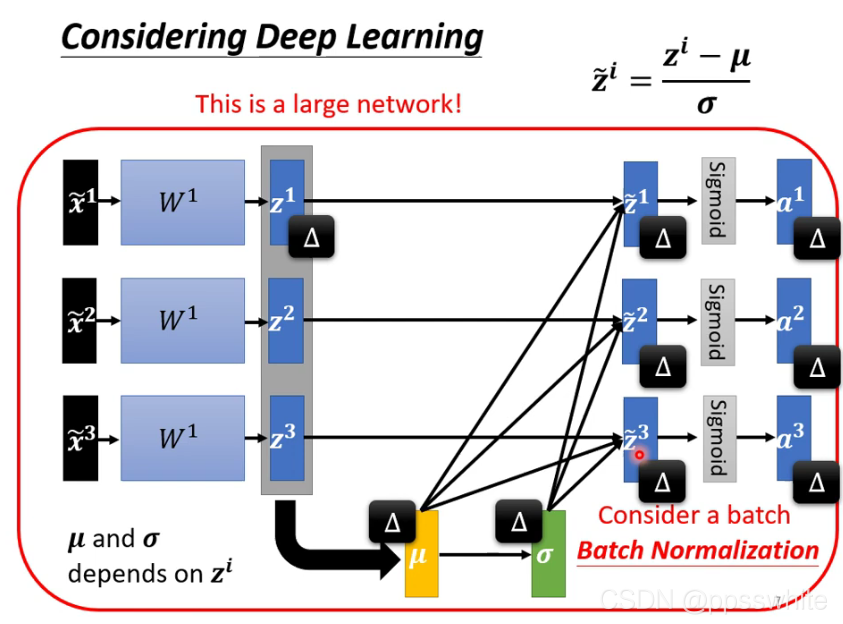
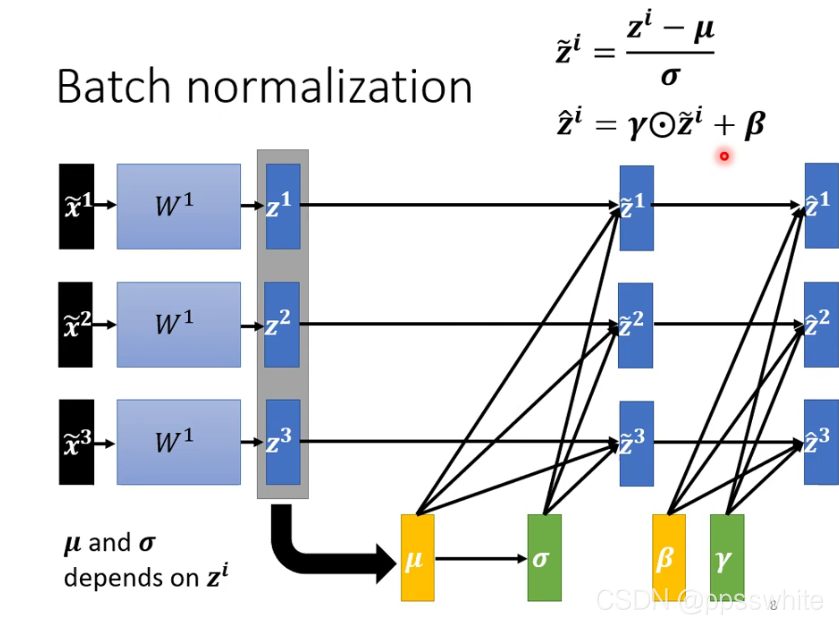
5.3 Batch Normalization
1.training
2. testing
