НЛВцбщжЄМЏ
ЦНЪБЮвУЧГЃгУЕФЪЧАбЪ§ОнМЏЗжГЩбЕСЗМЏКЭВтЪдМЏ,ЕЋЪЧУПбЕСЗвЛДЮОЭгУВтЪдМЏВтЪдвЛДЮ,ШчЙћВтЪдНсЙћВЛКУЛЙвЊдйбЕСЗ,етбљОЭБШНЯТщЗГ,вђДЫОЭвЊгУЕННЛВцбщжЄМЏСЫ,ФЧУДЪВУДЪЧНЛВцбщжЄМЏФи?
ШчЯТЭМ,АбдРДЕФбЕСЗМЏЗжГівЛаЁВПЗжзїЮЊбщжЄМЏ,дкбщжЄЪБЪЙгУбЕСЗМЏКЭбщжЄМЏжаЕФЫљгаЪ§Он,ФЧУДетСНВПЗжЪ§ОнМЏзщКЯдквЛЦ№ОЭНаНЛВцбщжЄМЏЁЃ
ЮвЕФРэНтЪЧ,бЕСЗМЏЕФОЋЖШИп,ДњБэбЕСЗЕФЦЋВюаЁ,бщжЄМЏЕФОЋЖШИп,ЫЕУїЗНВюаЁ,вВОЭЪЧТГАєадКУЁЃвЛАуРДЫЕЮвУЧПЯЖЈЯЃЭћЦЋВюЛЙЗНВюЖМаЁ,ЕЋЪЧЗНВюКЭЦЋВюЕФБфЛЏЪЧвЛИіЗДЯђЙиЯЕ,ЦЋВюаЁСЫ,ЗНВюОЭДѓСЫ,ОЭКУЯёбЕСЗКЏЪ§ЪЧзЈУХЮЊЕБЧАбЕСЗМЏЖЈжЦЕФ,ЛЛвЛЗнВЛЭЌЕФбЕСЗМЏаЇЙћОЭЛсБфВю,ЩѕжСКмВю,вВОЭЪЧГЃЫЕЕФЙ§ФтКЯЮЪЬтЁЃЗДжЎ,ШчЙћЗНВюаЁСЫ,ЦЋВюОЭЛсдіДѓ,ЕБЗНВюКмаЁ,ЦЋВюКмДѓЪБ,ОЭЪЧЧЗФтКЯЕФЯыЯѓЁЃЮЊДЫашвЊдкетСНепжЎМфевЕНвЛИіЦНКт,етвВЪЧНЛВцбщжЄМЏЕФвтвхЫљдк,ЫћЕФНсЙћМШЗДгІСЫЦЋВю,гжЗДгГСЫЗНВю,етЪЧВтЪдМЏЫљВЛФмзіЕНЕФЁЃ
зЊзд:https://www.bilibili.com/video/BV1rq4y1p7nJ?p=21
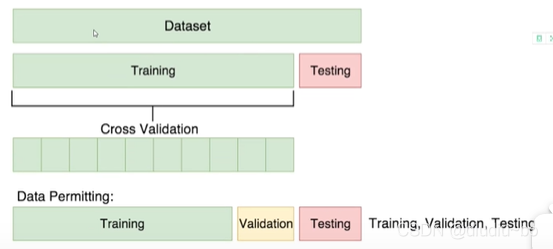
ФЧУДЛЎЗжбЕСЗМЏКЭбщжЄМЏШчКЮЛЎЗжФи?ШчЯТЭМ,ПЩвдАбНЛВцбщжЄМЏЛЎЗжГЩnЗн,бЁдёЦфжаЕФвЛЗнзїЮЊбщжЄМЏЁЃ
вђЮЊНЛВцбщжЄМЏЕФзїгУжївЊЪЧгУРДЕїВЮЕФ,ЫљвдВтЪдвЛДЮЁЂЕїећвЛДЮЁЂбЕСЗвЛДЮКмЗБЫі,ДЫЪБПЩвджаsklearnПтжаЕФsklearn.model_selection.cross_val_score()КЏЪ§,ИУКЏЪ§гаКмЖрВЮЪ§,ПЩвдЩшжУбЕСЗбщжЄЕФЕќДњДЮЪ§,бЁдёЪВУДбљЕФжИБъЕШЕШЁЃ
ИУКЏЪ§ПЩвдздЖЏЧаЗжНЛВцбщжЄМЏ,ШчЙћжиИДДЮЪ§cv=3,ФЧУДИУКЏЪ§ОЭАбЫќЧаЗжГЩ3Зн,УПДЮбЁдёЦфжа1ЗнзїЮЊбщжЄМЏ,ШЛКѓШЁШ§ИіScoreЕФЦНОљзїЮЊзюКѓЕФбщжЄНсЙћЁЃ(зЂвт:Ъ§ОнМЏЕФЫГађвЊДђТв,БмУтЪ§ОнМЏЕФЯрСкЪ§ОнгаЯрЙиад;ШчЙћЯывЊЪжаДДњТыЪЕЯжcross_val_scoreКЏЪ§ЕФЙІФм,дкЧаЗжЪ§ОнМЏЪБвЛЖЈвЊЩшжУЫцЛњжжзг,БЃжЄУПДЮЧаЗжЕФНсЙћЖМЪЧвЛбљЕФ,ЗёдђНсЙћОЭУЛгавтвхСЫ)
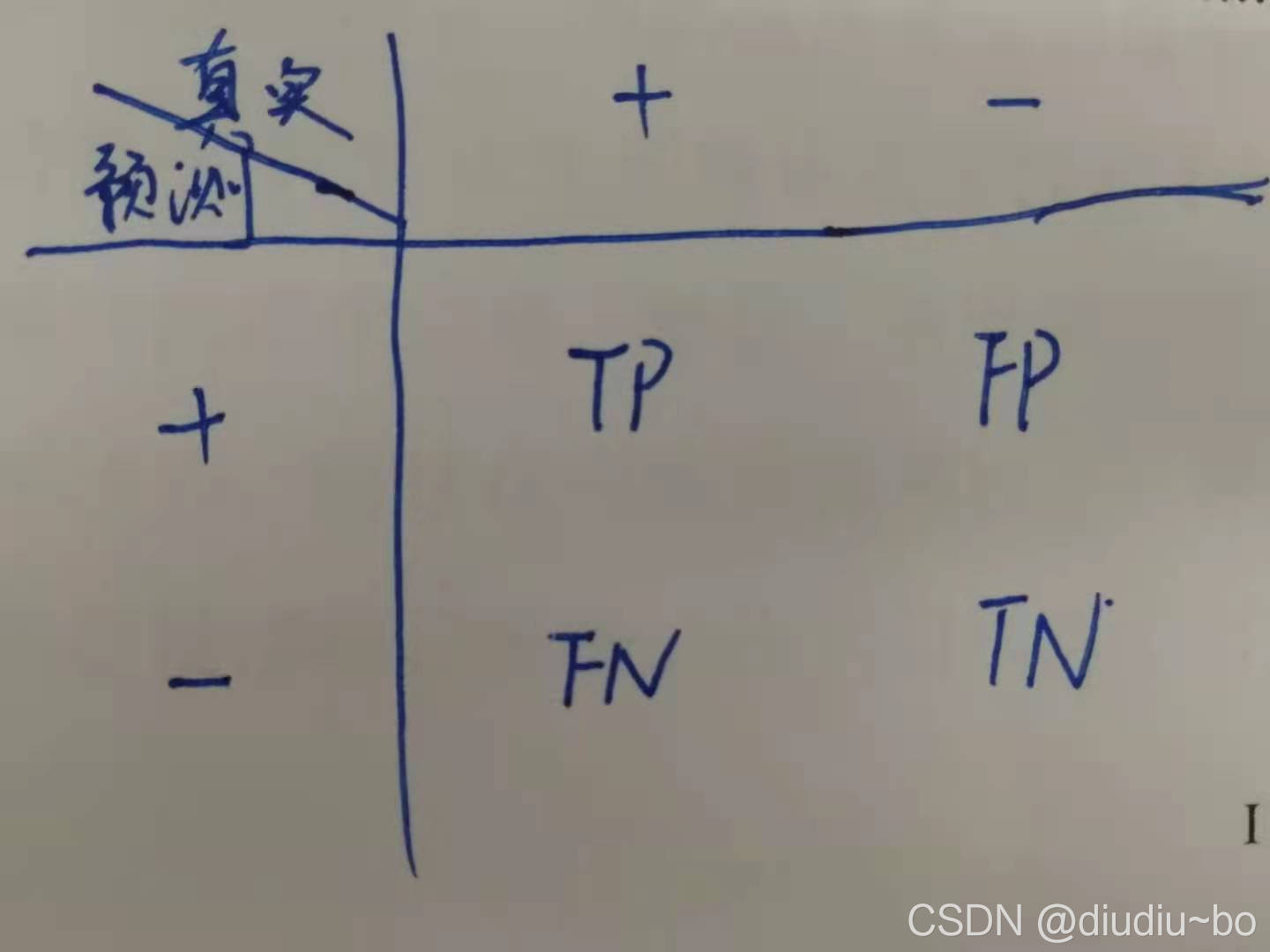
ЛьЯ§Оиеѓ(confusion matrix)
ШчЯТЭМ,АбецЪЕНсЙћКЭдЄВтНсЙћЗХЕНвЛеХБэРя,TPКЭTNЗжБ№ДњБэдЄВте§ШЗЕФе§бљБОКЭИКбљБО,FPКЭFNЗжБ№ДњБэдЄВтДэЮѓЕФе§бљБОКЭИКбљБОЁЃ
ЦРМлжИБъ
1.ОЋЖШ:precision
precision = TP/(TP + FP)
2.ейЛиТЪ:recall
recall = TP/(TP+FN)
3.F1 Score
F1 ScoreЪЧОЋЖШКЭейЛиТЪЕФЕїКЭЦНОљ
F1 = 2 / (1/precision + 1/recall)
уажЕЖдНсЙћЕФгАЯь
УПИібљБООЙ§бЕСЗ/дЄВтКѓЖМЛсгавЛИіЗжЪ§,ЛђепНаИХТЪ,уажЕОЭЪЧНЋбљБОЛЎЗжЮЊе§бљБОКЭИКбљБОЕФЗжНчЯп,Р§Шч,ЕБуажЕЮЊ0ЪБ,ЫљгабљБОЖМБЛШЯЮЊЪЧе§бљБО,ЕБуажЕЮЊ0.5ЪБ,Дѓгк0.5ЕФбљБОШЯЮЊЪЧе§бљБО,аЁгк0.5ЕФБЛШЯЮЊЪЧИКбљБОЁЃуажЕдНДѓ,precisionдНИп,recalдНЕЭ;уажЕдНаЁ,precisionдНаЁ,recallдНИпЁЃ
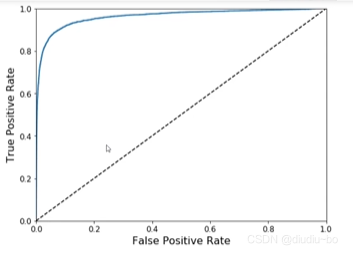
ЯТЭМЪЧROCЧњЯп,МДВЛЭЌуажЕЯТЕФTPКЭFP,КсжсЮЊFP,знжсЮЊTP,РэЯыЧщПіЪЧFPКмаЁ,TPКмДѓ,ЖдгІзХROCЧњЯпЕФзѓЩЯНЧ,МДзѓЩЯНЧдННгНќгк1ЪБ,ФЃаЭаЇЙћдНКУЁЃ(ROCЧњЯпЯТЕФУцЛ§НазіAUC,AUCдННгНќгк1ЪБаЇЙћдНКУ)
зЊзд:https://www.bilibili.com/video/BV1rq4y1p7nJ?p=27