����Ŀ¼
- ��ʶ����ѧϰ
- ���ŷ���ع��㷨
- ��̽��ʧ����
- �����ݶ��½��㷨
- ����������
- �ܽ�
��ʶ����ѧϰ
����ѧϰ��Դ:������50���,1959����IBM������Arthur Samuel�����һ���������,����������ѧϰ������,�������ڲ��ϵĶ���������Լ���
����ѧϰ����:֧��������,�ع�,������,���ɭ��,ǿ������,����ѧϰ,���ѧϰ��
����ѧϰ����:һ���̶��Ͽ������������һЩ����Ԥ��,�Զ���,�Զ�����,���Ż��ȳ����������������
����ѧϰ ����:����һ����������ֵĶ�������,���һ���㷨,���㷨�ܹ���ȡ���������̺��Ĺ��ɡ�
ѧϰ��ʽ:
- �мලѧϰ:��������������Ǵ��б�ǩ,��֪���ݺ���һһ��Ӧ�ı�ǩ,ѵ��һ��Ԥ��ģ��,����������ӳ�䵽��ǩ�Ĺ��̡������ڷ���ͻع�����
- �ලѧϰ:�����������ޱ�ǩ��,��Ϊ���ƶϳ����ݵ�һЩ���ڽṹ�������ڹ��������ѧϰ�Լ�����
- ��ලѧϰ:�������ݲ����б�ǩ,�����ޱ�ǩ,������������Ԥ�⡣�����������мල�ķ����㷨�м����ޱ��������ʵ�ְ�ල���ࡿ
- ���ලѧϰ:���ݼ��ı�ǩ�Dz��ɿ���,��Ҫָ��Dz���ȷ�����ֱ�ǡ���Dz���֡��ֲ���ǵȡ���֪���ݺ���һһ��Ӧ������ǩ,ѵ��һ�������㷨,����������ӳ�䵽һ���ǿ�ı�ǩ�Ĺ��̡�
�ලѧϰ�IJ���:
- ���ݵĴ����ͷ���,(��ע-���ֲ��Ժ�ѵ����)
- ������ǿ(data Augmentation), һ���Ѽ������ݶ��������Ŷ���Ϣ,��Ҫ�����ݽ�����ǿ��������ǿһ�����,ͼ����ת,ƽ��,��ɫ�任,�ü�,����任
- ��������(Feature Engineering), ����������ȡ������ѡ������IJ�ͬ������ṹ��������һ������ʵ���Ͼ������ѧϰ�����µ��������̡�
- ����Ԥ��ģ�ͺ���ʧ ����ģ��Ԥ��ͱ�ǩ֮�����ʧ����,��������ʧ����(Loss Function)�н����ء��������
- ѵ��, ѡ����ʵ�ģ�ͺͳ�����,ͨ�����ʵ��Ż�����������С������ǩ֮��IJ�ࡾ�Ż�����:�ݶ��½���������֡�
- ��֤��ģ��ѡ��. ��Ҫ����ģ�Ͳ��ԡ�������֤������֤ģ���Ƿ����ȷ�صó����
- ���Ժ�Ӧ��.
������һ��ȷ��ģ��,�Ϳ��Խ���ģ�Ͳ������Ӧ�ó����С�
����ѧϰ�������ھ�ɵɵ�ֲ���:
����ѧϰ���ĵ���������ι������������ʹ�þ����Զ��Ľ�
�����ھ��Ǵ���������ȡģʽ���ض��㷨��Ӧ��,�������ھ���,�ص������㷨��Ӧ��,�������㷨������
��ϵ:�����ھ���һ������,�ڴ˹���������ѧϰ�㷨��������ȡ���ݼ��е�DZ���м�ֵģʽ��������
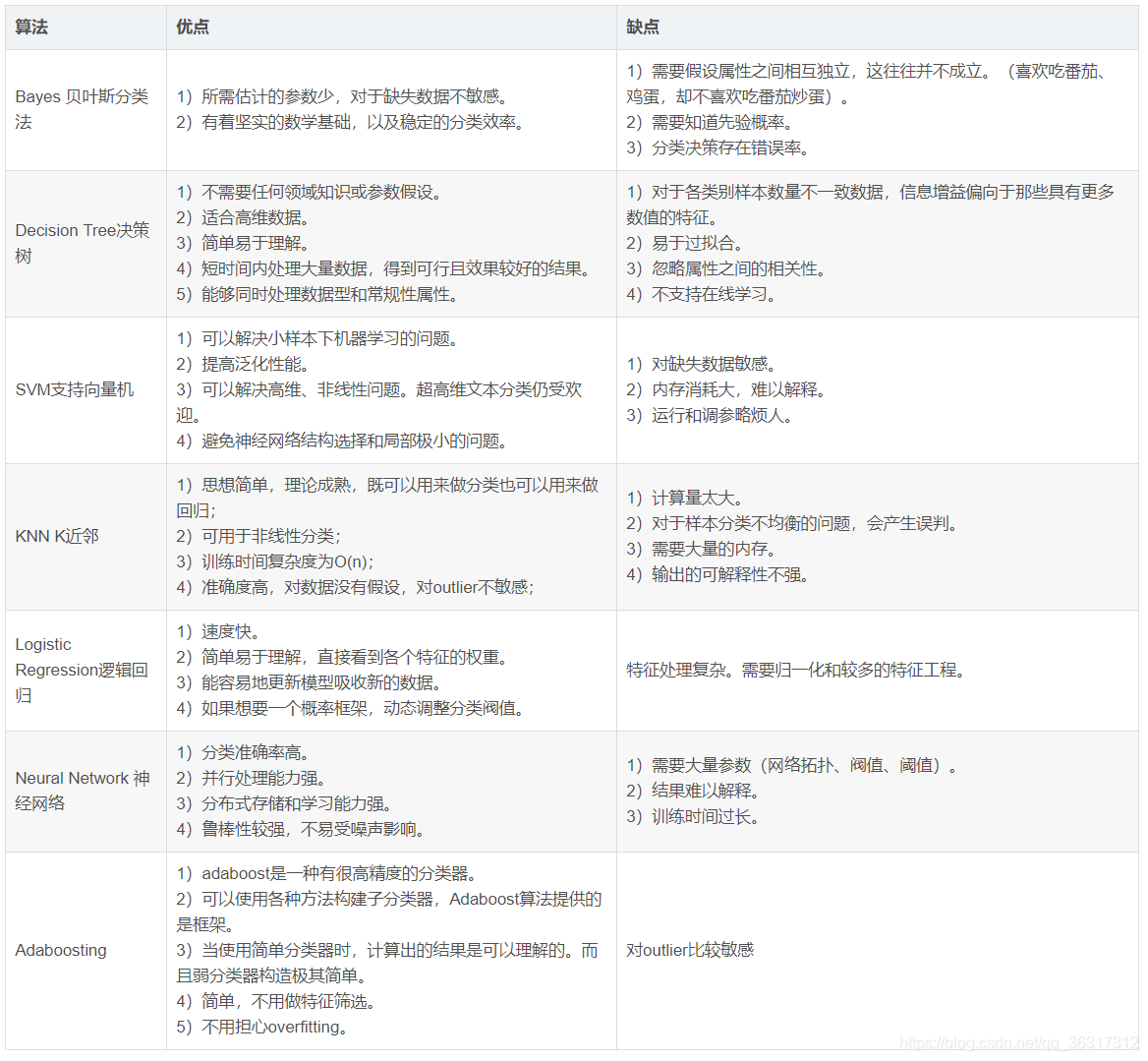
���ŷ���ع��㷨
�����㷨
����(Classification)�ǻ���ѧϰ����Ҫ����֮һ,�����㷨��һ�ֵ��͵ļලѧϰ�㷨,�������������������������ֵ����ʵ��������������˵��������ѵ������������ѵ��,�Ӷ��õ�����������������ǩ��ӳ��,�����ø�ӳ�����õ��������ı�ǩ,���մﵽ���������ֵ���ͬ����Ŀ�ġ�(��Ԫ�������⡢��Ԫ����)
�����ļ��ַ���ģ����:����ģ�͡�������ģ�͡����ر�Ҷ˹ģ�͡�BP������ģ�͵ȡ�
�ع��㷨
����ѧϰ����һ����Ҫ������ǻع�(Regression),�ع��㷨ͬ��Ҳ��һ�ּලѧϰ�㷨����������ⲻͬ����,�ڷ����㷨��,������ǩ��һЩ��ɢ��ֵ,ÿһ�ֱ�ǩ��������һ�����;Ȼ���ڻع�������,������ǩ��һЩ������ֵ���ع������Ŀ����Ԥ����������ֵ�͵�Ŀ��ֵ,����һϵ����������,Ѱ��һ�����ʺ����ݵķ��̶��ض���ֵ����Ԥ�⡣
�����ļ��ֻع�ģ����:���Իع顢�������Իع顢�������ع顢���ɭ�ֻع顢��ع顢�ݶ�������ع顢����ع顢����ع�ȡ�
ע��:���ع���Ȼ�лع��㷨,���ǻع��㷨,��һ�ַ����㷨��
�����㷨��ع��㷨����
����:**����ͻع�����Ҫ�������������Ľ����ͬ,���������Ϊ����,����ɢ������Ԥ��;���������Ϊ�ع�,������������Ԥ�⡣**����:Ԥ��һ������Сѧ������ѧ�����Ǵ�ѧ��,����һ����������;Ԥ��һ���˵������Ƕ�����,����һ���ع����⡣
��ν���ѡ��? ȡ���ڶ�����ķ���������
���÷����㷨����ȱ��?
�����㷨�������?
�����ڶ�����㷨����,��Ҫһ�����б��������㷨�ĺû�����Ҫ�����¼���ָ������������
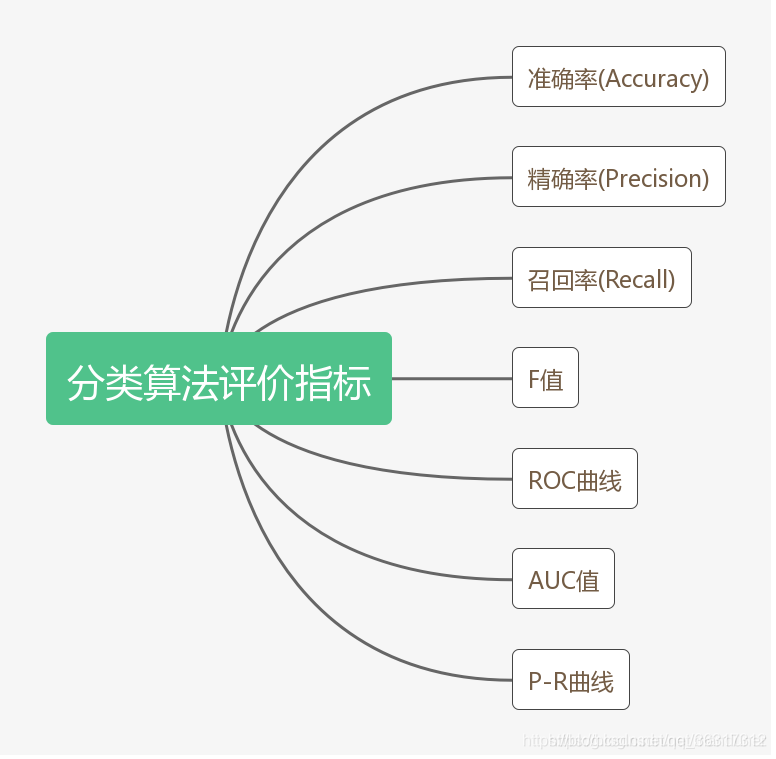
���ڶ������������,����ʵ���ֳ�����(positive)����(negative),��ʵ�ʷ����л���������������,��������ͼ��ʾ:
(1)��һ��ʵ��������,���ұ�Ԥ��Ϊ����,��Ϊ������(True Positive TP)
(2)��һ��ʵ��������,���DZ�Ԥ��Ϊ����,��Ϊ�ٸ���(False Negative FN)
(3)��һ��ʵ���Ǹ���,���DZ�Ԥ��Ϊ����,��Ϊ������(False Positive FP)
(4)��һ��ʵ���Ǹ���,���ұ�Ԥ��Ϊ����,��Ϊ�渺��(True Negative TN)
- ȷ��(Accuracy):���ڸ����IJ������ݼ�,��������ȷ���������������������֮�ȡ�
?Accuracy? = T P + T N P + N \text { Accuracy }=\frac{T P+T N}{P+N} ?Accuracy?=P+NTP+TN?
ȱ��:������������ƽ��������,���ָ���кܴ��ȱ�ݡ�����:����һ�����������1100��ʵ��,����1000��������,ʣ��100���Ǹ��ࡣ��ʹ����ģ�ͽ�����ʵ����Ԥ��Ϊ����,AccuracyҲ��90%����,������ûʲô������. - ������(sensitivity):��ʾ�������������б��ֶԵı���,�����˷�������������ʶ��������
?recall? = T P P \text { recall }=\frac{T P}{P} ?recall?=PTP? - ������(specificity):��ʾ�������и����б��ֶԵı���,�����˷������Ը�����ʶ��������
?recall? = T N N \text { recall }=\frac{T N}{N} ?recall?=NTN? - ��ȷ��(Precision):��ȷ�������������ռ����Ϊ������ʵ�������ı���[����]
?precision? = T P T P + F P \text { precision }=\frac{T P}{T P+F P} ?precision?=TP+FPTP? - �ٻ���(recall):��ȷ�������������ռʵ�����������ı���[��ȫ��]
?recall? = T P T P + F N \text { recall }=\frac{T P}{T P+F N} ?recall?=TP+FNTP? - F1ֵ:Ϊ���ܹ����۲�ͬ�㷨����,��Precision��Recall�Ļ����������F1ֵ�ĸ���,����Precision��Recall�����������ۡ�F1�Ķ�������: F 1 = ?��ȷ��? ? ?�ٻ���? ? 2 ?��ȷ��? + ?�ٻ���? F 1=\frac{\text { ��ȷ�� } * \text { �ٻ��� } * 2}{\text { ��ȷ�� }+\text { �ٻ��� }} F1=?��ȷ��?+?�ٻ���??��ȷ��???�ٻ���??2?
- ROC����:����������(��������)Ϊ������,��1��ȥ������(��������)Ϊ��������Ƶ������������ߡ����Խ���ͬģ�Ͷ�ͬһ���ݼ���ROC��������ͬһ�ѿ�������ϵ��,ROC����Խ�������Ͻ�,˵�����Ӧģ��Խ�ɿ���Ҳ����ͨ��ROC������������(Area Under Curve, AUC)������ģ��,AUCԽ��,ģ��Խ�ɿ���
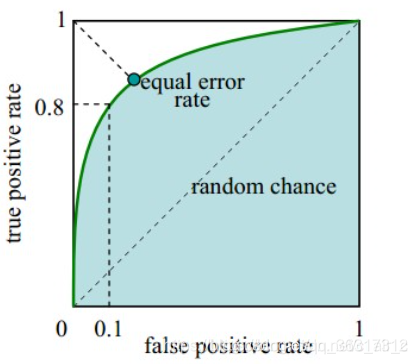
ʲô���ķ����������ŵ�?
ϣ����ָ�����ǵ�PrecisionԽ��Խ��,ͬʱRecallҲԽ��Խ�á�����������ָ����ijЩ�����ɽ��ì�ܵġ�����֮ǰ˵�ĵ���Ԥ��,��Ȼ���ܰٷְ�Ԥ�����ķ���,��ʵ�������������һ���̶ȵ���������1000��Ԥ����,����5��Ԥ�ⷢ���˵���,��ʵ�������һ�η����˵���,����4����Ϊ����ȷ����ԭ����999/1000=99.9�½�Ϊ996/1000=99.6���ٻ�����0/1=0%����Ϊ1/1=100%���Դ˽���Ϊ,��ȻԤ��ʧ����4��,����ĵ�����ǰ,��������Ԥ���,û�д���,�����ķ�����ʵ�������Ϊ�ش�,����������Ҫ�ġ������������,��һ����ȷ��ǰ����,Ҫ����������ٻ��ʾ����ߡ�
�ع����ͻ���
��������ģ�ͼ�����,�����������ͬ,���������»���:
(1)�����������,���Ƕ������Իع顣
(2)����Ƕ���ֲ�,�������ع顣
(3)����Dz���(Poisson)�ֲ�,���Dz��ɻع顣
(4)����Ǹ�����ֲ�,���Ǹ�����ع顣
(5)���ع������������Ƕ������,Ҳ�����Ƕ�����,���Ƕ�����ĸ�Ϊ����,Ҳ���������͡�����ʵ������õľ��Ƕ���������ع顣
dz�����ع�
���ع�(LR)
����:���ع���Ӧ�÷dz��㷺��һ���������ѧϰ�㷨,����������ϵ�һ��logit����(���߽���logistic����)��,�Ӷ��ܹ���ɶ��¼������ĸ��ʽ���Ԥ�⡣
ע��:�����������ع������ڷ����㷨,��õľ��Ƕ���������ع顣
�ŵ�:���ɲ��л����ɽ���ǿ
���ع�Ͷ������Իع������:�������ͬ�������������,���Ƕ������Իع�;����Ƕ���ֲ�,�������ع顿
���ع鱾��:�������ݷ�������ֲ�,Ȼ��ʹ�ü�����Ȼ�����������Ĺ���
���ع������:�ݵ����Իع�
���Իع�:���ڶ�ά�ռ��д��ڵ�������,�������������������ȥ��Ͽռ��е�ķֲ��켣
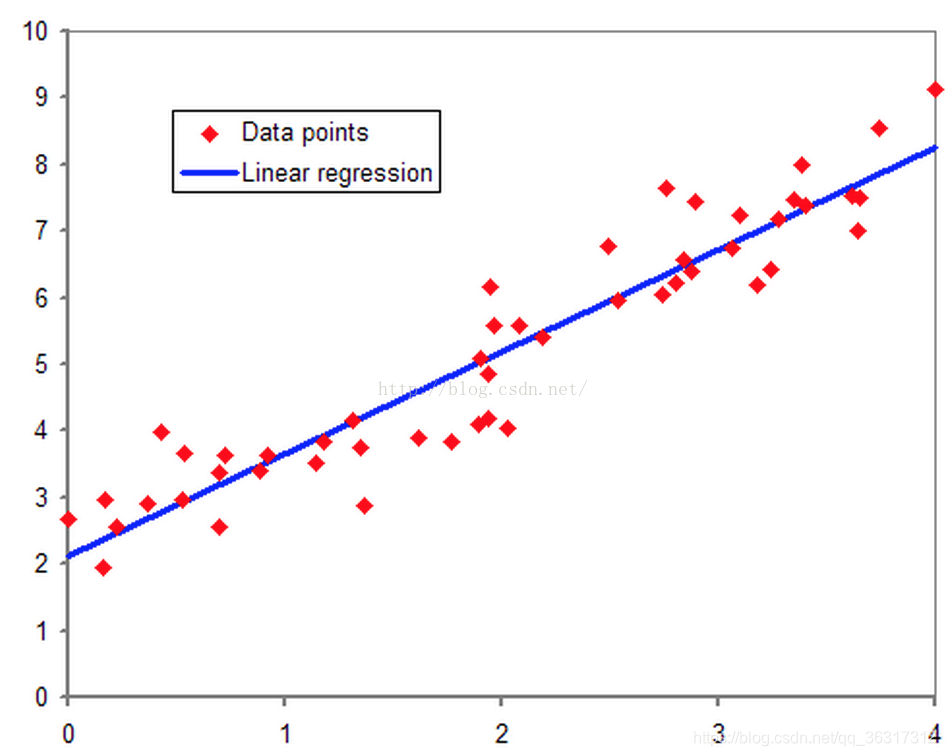
���Իع��ܶ�����ֵ�������Ԥ��,����ʵ�����г���������һ��������,�������⡣�������������Ķ��������⡣����˵ҽ����Ҫ�жϲ����Ƿ�����,����Ҫ�ж�һ���˵����ó̶��Ƿ�ﵽ���Ը��������ÿ��ij̶�,�ʼ��ռ���Ҫ�Զ����ʼ�����Ϊ�����ʼ��������ʼ��ȵȡ�
��Ȼ,������ֱ�ӵ��뷨��,��Ȼ�ܹ������Իع�Ԥ�������ֵ���,�Ǹ��ݽ���趨һ����ֵ�Dz��ǾͿ��Խ�������������?��ʵ��,���ںܱ������,ȷʵ���Ե�,������������Andrew Ng��ʦ�Ŀμ��е�����,��ͼ��XΪ���ݵ������Ĵ�С,YΪ�۲����Ƿ��Ƕ���������ͨ���������Իع�ģ��,��h��(x)��ʾ,�������Իع�ģ�ͺ�,�����趨һ����ֵ0.5,Ԥ��h��(x)��0.5����Щ��Ϊ��������,��h��(x)<0.5Ϊ����������
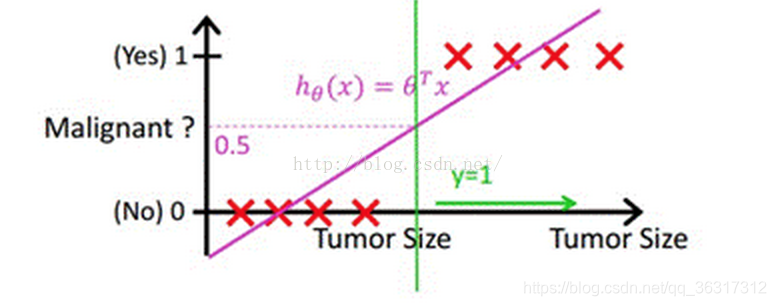
���ܶ�ʵ�ʵ������,������Ҫѧϰ�ķ������ݲ�û����ô��,����˵����������ͻȻ��һ��������·���Ƶ����ݵ����,����ͼ��ʾ:
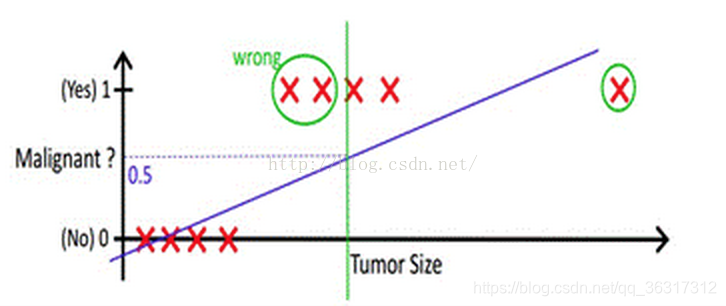
���������趨0.5,����ж���ֵ��ʧЧ��,����ʵ����ķ������������,��������������Ϊ����,�����ʱ�����ǽ��������Իع�+��ֵ�ķ�ʽ,�Ѿ��������һ��³���Ժܺõķ������ˡ�
����,���ع�͵�����,���ĺ���˼����,������Իع�Ľ�������һ������ֵ,��ֵ�ķ�Χ��������,��������û�а취��������ֵӳ��Ϊ�����������жϵĽ���ء�������������� (0,1) ��һ������ֵ,�����Ϳ��Ժ������ˡ�
���Իع������ع������
ǰ���Ѿ����ܹ�һЩ,���ڽ����ܽ�һ��
- ���Իع�����������,��������ֵ,�����ع��� ,ֻ��ȡ0��1
- ������Ϻ���Ҳ�б��ʵ�����
?���Իع�:? f ( x ) = �� T x = �� 1 x 1 + �� 2 x 2 + �� + �� n x n ?���ع�:? f ( x ) = P ( y = 1 �O x ; �� ) = g ( �� T x ) ,?����,? g ( z ) = 1 1 + e ? z ~ \begin{aligned}&\text { ���Իع�: } f(x)=\theta^{T} x=\theta_{1} x_{1}+\theta_{2} x_{2}+\ldots+\theta_{n} x_{n}\\&\text { ���ع�: } f(x)=P(y=1 \mid x ; \theta)=g\left(\theta^{T} x\right) \text {, ����, } g(z)=\frac{1}{1+e^{-\tilde{z}}} \end{aligned} ??���Իع�:?f(x)=��Tx=��1?x1?+��2?x2?+��+��n?xn??���ع�:?f(x)=P(y=1�Ox;��)=g(��Tx),?����,?g(z)=1+e?z~1??
���Կ���,���Իع����Ϻ���,�Ƕ�f(x)���������y�����,�����ع����Ϻ����Ƕ�Ϊ1�������ĸ��ʵ���ϡ�
��ô,ΪʲôҪ��1�������ĸ��ʽ��������,Ϊʲô�������������?
�� T x = 0 \theta^{T} x=0 ��Tx=0 ���൱����1���0��ľ��߽߱�:
?��? �� T x > 0 , ?��? y > 0.5 ; �� �� T x �� + �� , �� y �� 1 , �� y Ϊ 1 �� ; ?��? �� T x < 0 , ?��? y < 0.5 ; �� �� T x �� ? �� , �� y �� 0 , �� y Ϊ 0 �� ; \begin{aligned} &\text { �� } \theta^{T} x>0, \text { �� } y>0.5 ;��\theta ^{T}x\rightarrow +\infty ,��y \rightarrow 1 ,��yΪ1��; \\ &\text { �� } \theta^{T} x<0, \text { �� } y<0.5 ;�� \theta ^{T}x\rightarrow -\infty ,��y \rightarrow 0,��yΪ0��; \end{aligned} ??��?��Tx>0,?��?y>0.5;����Tx��+��,��y��1,��yΪ1��;?��?��Tx<0,?��?y<0.5;����Tx��?��,��y��0,��yΪ0��;?
���ʱ����ܿ�������,�����Իع��� �� T x \theta^{T} x ��Tx ΪԤ��ֵ����Ϻ���; �������ع��� �� T x \theta^{T} x ��Tx Ϊ���߽߱硣�±�2-3Ϊ���Իع�����ع������
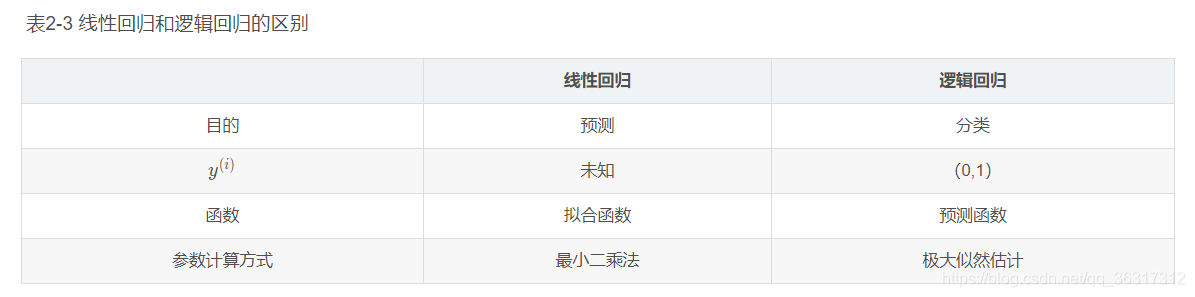
���ع鳣�沽��
- Ѱ��h����(��Ԥ�⺯��)
Logistic����(���ΪSigmoid����),������ʽΪ: g ( z ) = 1 1 + e ? z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e?z1?
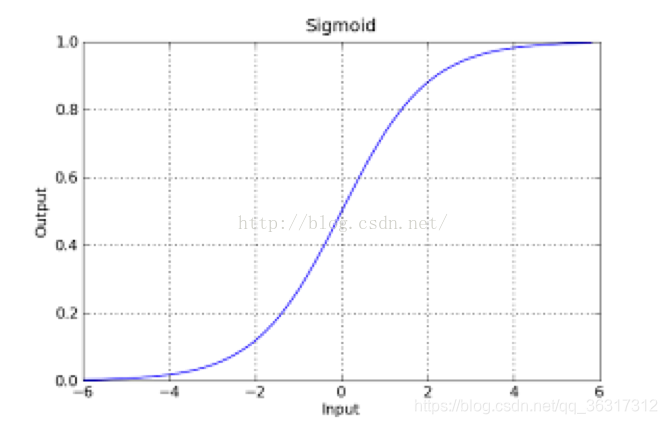
�Ӻ���ͼ�Ͽ��Կ���,����y=g(z)��z=0��ʱ��ȡֵΪ1/2,������z��С,����ֵ����0,z����ͬʱ����ֵ������1,��������һ�����ʵķ�Χ��
������ͼ��һ�����Եľ��߽߱�,��ͼ�Ƿ����Եľ��߽߱硣
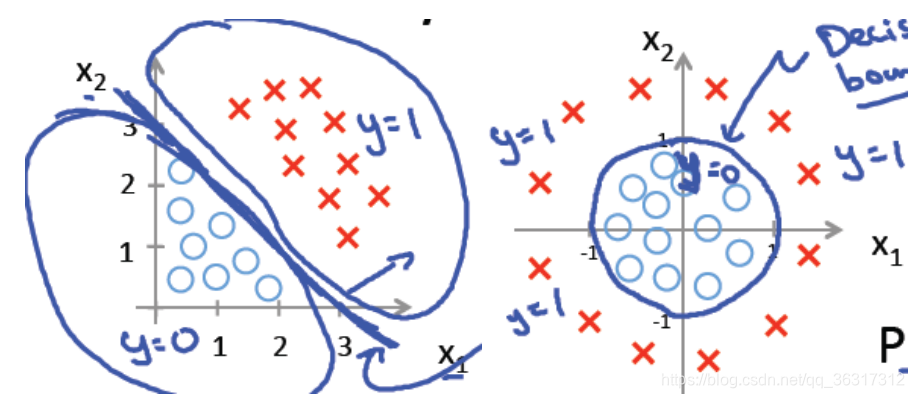
�������Ա߽�����,�߽���ʽ����:
��
0
+
��
1
x
1
+
,
��
,
+
��
n
x
n
=
��
i
=
1
n
��
i
x
i
=
��
T
x
\theta_{0}+\theta_{1} x_{1}+, \ldots,+\theta_{n} x_{n}=\sum_{i=1}^{n} \theta_{i} x_{i}=\theta^{T} x
��0?+��1?x1?+,��,+��n?xn?=i=1��n?��i?xi?=��Tx
����Ԥ�⺯��Ϊ:
h
��
(
x
)
=
g
(
��
T
x
)
=
1
1
+
e
?
��
T
x
h_{\theta}(x)=g\left(\theta^{T} x\right)=\frac{1}{1+e^{-\theta^{T} x}}
h��?(x)=g(��Tx)=1+e?��Tx1?
����
h
��
(
x
)
h_{\theta}(x)
h��?(x) ��ֵ������ĺ���,����ʾ���ȡ1�ĸ���, ��˶�������x������Ϊ���1�����0 �ĸ��ʷֱ�Ϊ:
P
(
y
=
1
�O
x
;
��
)
=
h
��
(
x
)
P
(
y
=
0
�O
x
;
��
)
=
1
?
h
��
(
x
)
\begin{aligned} &P(y=1 \mid x ; \theta)=h_{\theta}(x)\\ &P(y=0 \mid x ; \theta)=1-h_{\theta}(x) \end{aligned}
?P(y=1�Ox;��)=h��?(x)P(y=0�Ox;��)=1?h��?(x)?
3. ����J����(��ʧ����)
Cost������J��������,�����ǻ��������Ȼ�����Ƶ��õ��ġ�
Cost
?
(
h
��
(
x
)
,
y
)
=
{
?
log
?
(
h
��
(
x
)
)
?if?
y
=
1
?
log
?
(
1
?
h
��
(
x
)
)
?if?
y
=
0
J
(
��
)
=
1
m
��
i
=
1
n
Cost
?
(
h
��
(
x
(
i
)
)
,
y
(
i
)
)
=
?
1
m
��
i
=
1
n
(
y
(
i
)
log
?
h
��
(
x
(
i
)
)
+
(
1
?
y
(
i
)
)
log
?
(
1
?
h
��
(
x
(
i
)
)
)
)
\begin{gathered} \operatorname{Cost}\left(h_{\theta}(x), y\right)= \begin{cases}-\log \left(h_{\theta}(x)\right) & \text { if } y=1 \\ -\log \left(1-h_{\theta}(x)\right) & \text { if } y=0\end{cases} \\ J(\theta)=\frac{1}{m} \sum_{i=1}^{n} \operatorname{Cost}\left(h_{\theta}\left(x^{(i)}\right), y^{(i)}\right)=-\frac{1}{m} \sum_{i=1}^{n}\left(y^{(i)} \log h_{\theta}\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right) \end{gathered}
Cost(h��?(x),y)={?log(h��?(x))?log(1?h��?(x))??if?y=1?if?y=0?J(��)=m1?i=1��n?Cost(h��?(x(i)),y(i))=?m1?i=1��n?(y(i)logh��?(x(i))+(1?y(i))log(1?h��?(x(i))))?
5. ��취ʹ��J������С����ûع����(��)
ʹ���ݶ��½��������Сֵ
��
?���¹���:?
��
j
:
=
��
j
?
��
��
��
��
j
J
(
��
)
��
��
��
J
(
��
)
=
?
1
m
��
i
=
1
m
(
y
i
1
h
��
(
x
i
)
��
��
j
h
��
(
x
i
)
?
(
1
?
y
i
)
1
1
?
h
��
(
x
i
)
��
��
��
h
��
(
x
i
)
)
=
?
1
m
��
i
=
1
m
(
y
i
1
g
(
��
T
x
i
)
?
(
1
?
y
i
)
1
1
?
g
(
��
T
x
i
)
)
��
��
��
j
g
(
��
T
x
i
)
=
?
1
m
��
i
=
1
m
(
y
i
1
g
(
��
T
x
i
)
?
(
1
?
y
i
)
1
1
?
g
(
��
T
x
i
)
)
g
(
��
T
x
i
)
(
1
?
g
(
��
T
x
i
)
)
��
��
��
��
T
x
i
=
?
1
m
��
i
=
1
m
(
y
i
(
1
?
g
(
��
T
x
i
)
)
?
(
1
?
y
i
)
g
(
��
T
x
i
)
)
x
i
j
=
?
1
m
��
i
=
1
m
(
y
i
?
g
(
��
T
x
i
)
)
x
i
j
=
1
m
��
i
=
1
m
(
h
��
(
x
i
)
?
y
i
)
x
i
j
\begin{aligned} &\theta \text { ���¹���: }\\ &\begin{aligned} &\theta_{j}:=\theta_{j}-\alpha \frac{\delta}{\delta_{\theta_{j}}} J(\theta) \\ &\frac{\delta}{\delta_{\theta}} J(\theta)=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i} \frac{1}{h_{\theta}\left(x_{i}\right)} \frac{\delta}{\delta_{j}} h_{\theta}\left(x_{i}\right)-\left(1-\mathrm{y}_{i}\right) \frac{1}{1-h_{\theta}\left(x_{i}\right)} \frac{\delta}{\delta_{\theta}} h_{\theta}\left(x_{i}\right)\right) \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i} \frac{1}{g\left(\theta^{\mathrm{T}} x_{i}\right)}-\left(1-\mathrm{y}_{\mathrm{i}}\right) \frac{1}{1-g\left(\theta^{\mathrm{T}} x_{i}\right)}\right) \frac{\delta}{\delta \theta_{j}} g\left(\theta^{\mathrm{T}} x_{i}\right) \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i} \frac{1}{g\left(\theta^{\mathrm{T}} x_{i}\right)}-\left(1-\mathrm{y}_{\mathrm{i}}\right) \frac{1}{1-g\left(\theta^{\mathrm{T}} x_{i}\right)}\right) g\left(\theta^{\mathrm{T}} x_{i}\right)\left(1-g\left(\theta^{\mathrm{T}} x_{i}\right)\right) \frac{\delta}{\delta_{\theta}} \theta^{\mathrm{T}} x_{i} \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}\left(1-g\left(\theta^{\mathrm{T}} x_{i}\right)\right)-\left(1-\mathrm{y}_{\mathrm{i}}\right) g\left(\theta^{\mathrm{T}} x_{i}\right)\right) x_{i}^{j} \\ &=-\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-g\left(\theta^{\mathrm{T}} x_{i}\right)\right) x_{i}^{j} \\ &=\frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x_{i}\right)-y_{i}\right) x_{i}^{j} \end{aligned} \end{aligned}
?��?���¹���:??��j?:=��j??������j??��?J(��)����?��?J(��)=?m1?i=1��m?(yi?h��?(xi?)1?��j?��?h��?(xi?)?(1?yi?)1?h��?(xi?)1?����?��?h��?(xi?))=?m1?i=1��m?(yi?g(��Txi?)1??(1?yi?)1?g(��Txi?)1?)����j?��?g(��Txi?)=?m1?i=1��m?(yi?g(��Txi?)1??(1?yi?)1?g(��Txi?)1?)g(��Txi?)(1?g(��Txi?))����?��?��Txi?=?m1?i=1��m?(yi?(1?g(��Txi?))?(1?yi?)g(��Txi?))xij?=?m1?i=1��m?(yi??g(��Txi?))xij?=m1?i=1��m?(h��?(xi?)?yi?)xij???
\theta���¹��̿���д��:
��
j
:
=
��
j
?
��
1
m
��
i
=
1
m
(
h
��
(
x
(
i
)
)
?
y
(
i
)
)
x
j
(
i
)
\theta_{j}:=\theta_{j}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)}
��j?:=��j??��m1?i=1��m?(h��?(x(i))?y(i))xj(i)?
ʲôʱ�������ع�?
- ���ڸ���Ԥ�⡣���ڿ�����Ԥ��ʱ,�õ��Ľ���пɱ��ԡ��������ģ�ͽ���Ԥ���ڲ�ͬ���Ա��������,����ij����ij������ĸ����ж��
- ���ڷ��ࡣʵ���ϸ�Ԥ����Щ����,Ҳ�Ǹ���ģ��,�ж�ij������ij��������ij������ĸ����ж��,Ҳ���ǿ�һ��������ж��Ŀ�����������ij�������з���ʱ,����Ҫ�趨һ����ֵ����,�����Ը�����ֵ��һ��,������ֵ����һ�ࡣ
- Ѱ��Σ�����ء�Ѱ��ijһ������Σ�����صȡ�
- ���������������⡣ֻ�е�Ŀ������������Թ�ϵʱ,���������ع顣��Ӧ�����ع�ʱע������:һ�ǵ�֪��ģ���Ƿ�����ʱ,���������ع�;���ǵ�ʹ�����ع�ʱ,Ӧע��ѡ���Ŀ��Ϊ���Թ�ϵ��������
- ������֮�䲻��Ҫ����������������,�����������Ĺ��������㡣
Pythonʵ�����ع����
from sklearn.linear_model import LogisticRegression
Model = LogisticRegression()
Model.fit(X_train, y_train)
Model.score(X_train,y_train)
# Equation coefficient and Intercept
Print(��Coefficient��,model.coef_)
Print(��Intercept��,model.intercept_)
# Predict Output
Predicted = Model.predict(x_test)
��̽��ʧ����
ʲô����ʧ����?
��ʧ�������Ǻ���ģ���������ʵ��ǩ֮��IJ���,����������ģ�͵�Ԥ��ֵf(x)����ʵֵY�IJ�һ�³̶�,����һ���Ǹ�ʵֵ����,ͨ��ʹ��L(Y, f(x))����ʾ,��ʧ����ԽС,ģ�͵�³���Ծ�Խ�á�
��ʧ���������ۺ�����Ŀ�꺯�����ߵ�����
- ��ʧ����(Loss Function)
����:����һ�������������ʵ��ǩ֮��IJ���,����ʽ���� ?Loss? = f ( y ^ , y ) \text { Loss }=f(\hat{y}, y) ?Loss?=f(y^?,y) - ���ۺ���(Cost Function)
����:��������ѵ������loss��ƽ��ֵ,����ʽ���� cost ? = 1 ? N �� i N f ( y ^ i , y i ) \operatorname{cost}=\frac{1}{\mathrm{~N}} \sum_{\mathrm{i}}^{\mathrm{N}}\mathrm{f}\left(\hat{\mathrm{y}}_{\mathrm{i}}, \mathrm{y}_{\mathrm{i}}\right) cost=?N1?i��N?f(y^?i?,yi?) - Ŀ�꺯��(Objective Function)
����:�ڻ���ѧϰ�д������յ�ѵ��Ŀ��,����ʽ���¡� regularization�������� O b j = ?cost? + ?regularization? O b j=\text { cost }+\text { regularization } Obj=?cost?+?regularization?
��ʧ������Pytorchʵ�������
1����ʧ��������
�ڶ�����ʧ������ʱ��,�������Կ������Ȼ����ʧ�����ļ��������ж���,�Խ�������ʧ����Ϊ��,�����������:
criterion = torch.nn.CrossEntropyLoss()
���õĽ�������ʧ������������pytorch�Դ���ʧ����������ʽ,������Ϊ��ѧ��Ҳ��Ҫ֪������Ļ���,ֻ��Ҫ��Ctrl+ B ����,С������һ̽������
ִ����仰��ʱ��,�Ϳ��Կ���,��ʵ������ʧ��������̳�һ������,��������������_Loss,����������:
class _Loss(Module):
def __init__(self, size_average=None, reduce=None, reduction='mean'):
super(_Loss, self).__init__()
if size_average is not None or reduce is not None:
self.reduction = _Reduction.legacy_get_string(size_average, reduce)
else:
self.reduction = reduction
2��ִ�в���
loss = criterion(outputs, labels)
��仰������Ҳ������ǰ����һ����,ͬ��Ҳ�ǻ�ִ��torch.nn.Module��forward������forward������������:
def forward(self, input, target):
return F.cross_entropy(input, target, weight=self.weight,
ignore_index=self.ignore_index, reduction=self.reduction)��
�����˶���ĺ���cross_entropy,��������:
if size_average is not None or reduce is not None:
reduction = _Reduction.legacy_get_string(size_average, reduce)
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
ͨ������IJ����Լ����ù�ϵ�˽���ʧ�����Ĺ��ܺͻ���
������ʧ��������
1��nn.CrossEntropyLoss
��ѧԭ��
�����˽⽻���ء���Ϣ�ء�������صĸ���
��Ϣ��:��Ҫ��������Ϣ�IJ�ȷ���̶�,һ����Ϣ����Խ��˵��Խ��ȷ�����������������ʷֲ��IJ�ȷ���ԡ�
H
p
(
q
)
=
��
x
p
(
x
)
log
?
2
(
1
q
(
x
)
)
H_{p}(q)=\sum_{x} p(x) \log _{2}\left(\frac{1}{q(x)}\right)
Hp?(q)=x��?p(x)log2?(q(x)1?)
�����:��Ҫ�����������ֲ�֮��IJ���,�����������ֲ�֮��ľ��롣
��ע��:����غ;��뺯�����ű�������,���뺯������һ����Ҫ���ʾ��ǶԳ���,����ز�����Գ�����
D
K
L
(
P
,
Q
)
=
E
x
��
p
[
log
?
P
(
x
)
Q
(
x
)
]
=
E
x
��
p
[
log
?
P
(
x
)
?
log
?
Q
(
x
)
]
=
��
i
=
1
N
P
(
x
i
)
[
log
?
P
(
x
i
)
?
log
?
Q
(
x
i
)
]
=
��
i
=
1
N
P
(
x
i
)
log
?
P
(
x
i
)
?
��
i
=
1
N
P
(
x
i
)
log
?
Q
(
x
i
)
=
H
(
P
,
Q
)
?
H
(
P
)
\begin{aligned} \boldsymbol{D}_{K L}(\boldsymbol{P}, \boldsymbol{Q}) &=\boldsymbol{E}_{\boldsymbol{x} \sim p}\left[\log \frac{\boldsymbol{P}(\boldsymbol{x})}{\boldsymbol{Q}(\boldsymbol{x})}\right] \\ &=\boldsymbol{E}_{\boldsymbol{x} \sim p}[\log \boldsymbol{P}(\boldsymbol{x})-\log \boldsymbol{Q}(\boldsymbol{x})] \\ &=\sum_{i=1}^{N} \boldsymbol{P}\left(\boldsymbol{x}_{i}\right)\left[\log P\left(\boldsymbol{x}_{i}\right)-\log \boldsymbol{Q}\left(\boldsymbol{x}_{i}\right)\right] \\ &=\sum_{i=1}^{N} \boldsymbol{P}\left(\boldsymbol{x}_{i}\right) \log \boldsymbol{P}\left(\boldsymbol{x}_{i}\right)-\sum_{i=1}^{N} \boldsymbol{P}\left(\boldsymbol{x}_{i}\right) \log \boldsymbol{Q}\left(\boldsymbol{x}_{i}\right) \\ &=\boldsymbol{H}(\boldsymbol{P}, \boldsymbol{Q})-\boldsymbol{H}(\mathrm{P}) \end{aligned}
DKL?(P,Q)?=Ex��p?[logQ(x)P(x)?]=Ex��p?[logP(x)?logQ(x)]=i=1��N?P(xi?)[logP(xi?)?logQ(xi?)]=i=1��N?P(xi?)logP(xi?)?i=1��N?P(xi?)logQ(xi?)=H(P,Q)?H(P)?
����һ������ı���ʽ:��һ����ʽ��������صĶ���ʽ������P����ʵ�ķֲ���Q��ģ����ϵķֲ�,�������ʽ����˼������ģ����ϵķֲ�Qȥ�ƽ���ʵ�ķֲ�P��
������:������һ�����ʷֲ�pΪ��ʵ�ֲ�,��һ��Ϊ����(���)�ֲ�q,��ô�����ؾ�����q����Ϣ�������p�ֲ�����Ϣ�ء�
����ѵ��Ŀ������С�������ص�ʱ��,��ʵ������С������ء�
�����صı���ʽ����:
H
(
P
,
Q
)
=
?
��
i
=
1
N
P
(
x
i
)
log
?
Q
(
x
i
)
\mathbf{H}(\boldsymbol{P}, \boldsymbol{Q})=-\sum_{i=1}^{N} \boldsymbol{P}\left(\boldsymbol{x}_{i}\right) \log \boldsymbol{Q}\left(\boldsymbol{x}_{i}\right)
H(P,Q)=?i=1��N?P(xi?)logQ(xi?)
�����Ϣ�غ�����صı���ʽ,�ɵ����¹�ϵ
H
(
P
,
Q
)
=
D
K
L
(
P
,
Q
)
+
H
(
P
)
\mathbf{H}(\boldsymbol{P}, \boldsymbol{Q})=\boldsymbol{D}_{K L}(\boldsymbol{P}, \boldsymbol{Q})+\mathbf{H}(\boldsymbol{P})
H(P,Q)=DKL?(P,Q)+H(P)
������ʹ��
�����غ�����nn.Logsoftmax()��nn.NLLLoss()���,���н����ؼ��㡣�����nn.Logsoftmax()��������������ݽ����˹�һ������,����˸��ʷֲ�����ʽ,��ȡlog������������nn.NLLLoss()����ȡ���Ų�����
�������̵���ѧ����ʽ����,��weightʱ:
loss
?
(
x
,
?class?
)
=
?
log
?
(
exp
?
(
x
[
?class?
]
)
��
j
exp
?
(
x
[
j
]
)
)
=
?
x
[
?class?
]
+
log
?
(
��
j
exp
?
(
x
[
j
]
)
)
\operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum_{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)
loss(x,?class?)=?log(��j?exp(x[j])exp(x[?class?])?)=?x[?class?]+log(j��?exp(x[j]))
��weightʱ:
loss
?
(
x
,
?class?
)
=
?weight?
[
?class?
]
(
?
x
[
?class?
]
+
log
?
(
��
j
exp
?
(
x
[
j
]
)
)
)
\operatorname{loss}(x, \text { class })=\text { weight }[\text { class }]\left(-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)\right)
loss(x,?class?)=?weight?[?class?](?x[?class?]+log(j��?exp(x[j])))
��ʹ��CrossEntropyLoss����ʱ,����Ҫ������
weight:������loss����Ȩֵ(����ij������loss���ٳ�1.5��)
ignore_ index:����ij�����(��ij�����loss)
reduction :����ģʽ,none�������Ԫ�ؼ���;sum��������Ԫ�����,���ر���;mean������Ȩƽ��,���ر���,none/sum/mean ��ѡһ
size_average&reduce:����,����������������reduction�Ϳ��������������
ʹ��ʵ��
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 1, 1], dtype=torch.long)
loss_f_mean = nn.CrossEntropyLoss(weight=None, reduction='mean')
loss_mean = loss_f_mean(inputs, target)
������:tensor(0.5224)
2��nn.NLLLoss()
��ѧԭ��
��ѧ����ʽ:
?
(
x
,
y
)
=
L
=
{
l
1
,
��
,
l
N
}
��
,
l
n
=
?
w
y
n
x
n
,
y
n
\ell(x, y)=L=\left\{l_{1}, \ldots, l_{N}\right\}^{\prime}, \quad l_{n}=-w_{y_{n}} x_{n, y_{n}}
?(x,y)=L={l1?,��,lN?}��,ln?=?wyn??xn,yn??
������ʹ��
����:ʵ�ָ�������Ȼ�����еĸ��Ź���,Ҳ���Ƕ�����ȡ�˸����š�
����������nn.CrossEntropyLoss�IJ���һ����
ʹ��ʵ��
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_mean = nn.NLLLoss(weight=weights, reduction='mean')
loss_mean = loss_f_mean(inputs, target)
������:tensor(-2.3333)
3��nn.BCELoss()
��ѧԭ��
����ѧԭ���ͽ����ز������,�ڴ˲�����,ֱ�ӿ���ѧ����ʽ��������:
l
n
=
?
w
n
[
y
n
?
log
?
x
n
+
(
1
?
y
n
)
?
log
?
(
1
?
x
n
)
]
l_{n}=-w_{n}\left[y_{n} \cdot \log x_{n}+\left(1-y_{n}\right) \cdot \log \left(1-x_{n}\right)\right]
ln?=?wn?[yn??logxn?+(1?yn?)?log(1?xn?)]
������ʹ��
����:�����ཻ������ʧ����,�ǽ�������ʧ������һ������������ı�ǩ�Ƕ������,Ҫô��0,Ҫô��1��
BCEԭ����ÿһ����Ԫһһ��Ӧ��ȥ����loss,��������ı�ǩ���������ζ���������,ͬʱ�����������Ҳ��Ҫ��,BCEҪ���䷶Χ������0��1֮��,����ͻᱨ����������:��������inputs֮ǰҪ����sigmoid��������ӳ���һ������ֵ��
ʹ��ʵ��
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
inputs = torch.sigmoid(inputs)
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_mean = nn.BCELoss(weight=weights, reduction='mean')
loss_mean = loss_f_mean(inputs, target)
������:tensor(1.4732)
4��nn.BCEWithLogitsLoss()
����:���Sigmoid������ཻ����,Ҳ����������sigmoid����,������BCELoss���ֲ���
����Ҫ��������һ�㲻ͬ,���������������Ҫ�����Ļ�����������pos_weight,����������Ȩֵ�����������Ҫ��Ϊ�˽�����������������,����ѵ��������100����������900��������,��ô���ǵ�pos_weight�Ϳ�������Ϊ9,�Ը���ע��������loss,�Ӷ��ﵽ��ƫб��Ŀ�ġ�
5��nn.L1Loss()
��ѧԭ��
��ѧ����ʽ�ܼ�����,������ʾ
l
n
=
�O
x
n
?
y
n
�O
l_{n}=\left|x_{n}-y_{n}\right|
ln?=�Oxn??yn?�O
������ʹ��
����:����inputs��target֮��ľ���ֵ
ʹ��ʵ��
inputs = torch.ones((2, 2))
target = torch.ones((2, 2)) * 3
loss_f = nn.L1Loss(reduction='none')
loss = loss_f(inputs, target)
������:L1 loss:tensor([[2., 2.], [2., 2.]])
6��nn.MSELoss()
��ѧԭ��
��ѧ����ʽ�ܼ�����,������ʾ
l
n
=
(
x
n
?
y
n
)
2
l_{n}=\left(x_{n}-y_{n}\right)^{2}
ln?=(xn??yn?)2
������ʹ��
����:����inputs��target֮���ƽ��
ʹ��ʵ��
inputs = torch.ones((2, 2))
target = torch.ones((2, 2)) * 3
loss_f_mse = nn.MSELoss(reduction='none')
loss_mse = loss_f_mse(inputs, target)
������:MSE loss:tensor([[4., 4.], [4., 4.]])
7��nn.SoftMarginLoss()
��ѧԭ��
��ѧ����ʽ:
loss
?
(
x
,
y
)
=
��
i
log
?
(
1
+
exp
?
(
?
y
[
i
]
?
x
[
i
]
)
)
x
?
?nelement?
0
\operatorname{loss}(x, y)=\sum_{i} \frac{\log (1+\exp (-y[i] * x[i]))}{x \cdot \text { nelement } 0}
loss(x,y)=i��?x??nelement?0log(1+exp(?y[i]?x[i]))?
������ʹ��
����:����������logistic��ʧ
inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]])
target = torch.tensor([[-1, 1], [1, -1]], dtype=torch.float)
loss_f = nn.SoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
������:SoftMargin: tensor([[0.8544, 0.4032], [0.4741, 0.9741]])
8��nn.CosineEmbeddingLoss()
��ѧԭ��
����ѧ����ʽΪ
cos
?
(
��
)
=
A
?
B
��
A
��
��
B
��
=
��
i
=
1
n
A
i
��
B
i
��
i
=
1
n
(
A
i
)
2
��
��
i
=
1
n
(
B
i
)
2
\cos (\theta)=\frac{A \cdot B}{\|A\|\|B\|}=\frac{\sum_{i=1}^{n} A_{i} \times B_{i}}{\sqrt{\sum_{i=1}^{n}\left(A_{i}\right)^{2}} \times \sqrt{\sum_{i=1}^{n}\left(B_{i}\right)^{2}}}
cos(��)=��A����B��A?B?=��i=1n?(Ai?)2?����i=1n?(Bi?)2?��i=1n?Ai?��Bi??
�ڲ�����������ʽ
loss
?
(
x
,
y
)
=
{
1
?
cos
?
(
x
1
,
x
2
)
,
?if?
y
=
1
max
?
(
0
,
cos
?
(
x
1
,
x
2
)
?
margin
?
)
,
?if?
y
=
?
1
\operatorname{loss}(x, y)= \begin{cases}1-\cos \left(x_{1}, x_{2}\right), & \text { if } y=1 \\ \max \left(0, \cos \left(x_{1}, x_{2}\right)-\operatorname{margin}\right), & \text { if } y=-1\end{cases}
loss(x,y)={1?cos(x1?,x2?),max(0,cos(x1?,x2?)?margin),??if?y=1?if?y=?1?
������ʹ��
����:�����������ƶȼ�����������֮��������ԡ���Ҫ������margin,����margin��ȡֵΪ[-1, 1],�Ƽ�Ϊ[0, 0.5]��cosine���ӹ�ע���Ƿ����ϵIJ��졣
x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]])
x2 = torch.tensor([[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]])
target = torch.tensor([[1, -1]], dtype=torch.float)
loss_f = nn.CosineEmbeddingLoss(margin=0., reduction='none')
loss = loss_f(x1, x2, target)
������:Cosine Embedding Loss tensor([[0.0167, 0.9833]])
9��nn.MarginRankingLoss()
��ѧԭ��
loss ? ( x , y ) = max ? ( 0 , ? y ? ( x 1 ? x 2 ) + ?margin? ) \operatorname{loss}(x, y)=\max \left(0,-y *\left(x_{1}-x_{2}\right)+\text { margin }\right) loss(x,y)=max(0,?y?(x1??x2?)+?margin?)
��y=1ʱ,ϣ��x1��x2��,�����������ϵʱ,������loss;
��y=-1ʱ,ϣ��x2��x1��,�����������ϵʱ,������loss��
������ʹ��
����:������������������ƶ�,ͨ������������������Ǽ�����������֮��IJ���,����һ��nxn��loss����
ʹ��ʵ��
x1 = torch.tensor([[1], [2], [3]], dtype=torch.float)
x2 = torch.tensor([[2], [2], [2]], dtype=torch.float)
target = torch.tensor([1, 1, -1], dtype=torch.float)
loss_f_none = nn.MarginRankingLoss(margin=0, reduction='none')
loss = loss_f_none(x1, x2, target)
������:tensor([[1., 1., 0.],[0., 0., 0.], [0., 0., 1.]])
�����ݶ��½��㷨
��������(ֱ������)
һ���˱�����ɽ��,��Ҫ��ɽ������(�ҵ�ɽ����͵�,Ҳ����ɽ��)������ʱɽ�ϵ�Ũ���ܴ�,���¿��ӶȺܵ�;���,��ɽ��·������ȷ��,���������Լ���Χ����Ϣһ��һ�����ҵ���ɽ��·�����ʱ��,��������ݶ��½��㷨�������Լ���ɽ��
��ô����,����������ǰ��������λ��Ϊ��,Ѱ�����λ����͵ĵط�,Ȼ�����½�������һ��,Ȼ���ּ����Ե�ǰλ��Ϊ��,������͵ĵط�,����ֱ�������ʹ�;ͬ����ɽҲ�����,ֻ����ʱ��ͱ���ݶ������㷨��

�ֲ����ź�ȫ������:
ȫ������:����Ҫ���һ������,��ȫֵ��Χ�����š�ͼ���������Ž⡿
�ֲ�����:��ָ����һ������Ľ���һ����Χ�����������š�ͼ�оֲ����Ž�,��ǰ��������Χ�������Ž⡿
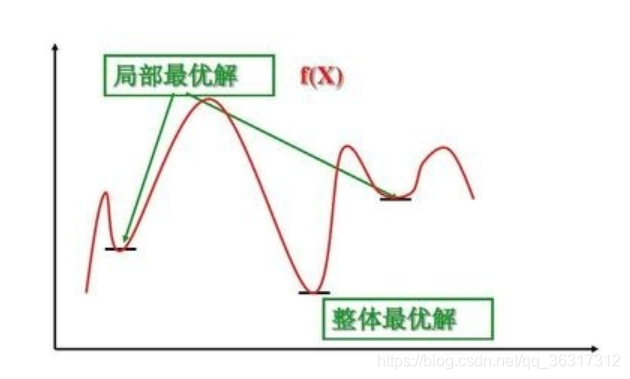
Ϊʲô��Ҫ�ݶ��½�?
�ݶ��½��ǻ���ѧϰ�г����Ż��㷨֮һ,�ݶ��½��������¼�������:
(1)�ݶ��½��ǵ�������һ��,�������������С�������⡣
(2)��������ѧϰ�㷨��ģ�Ͳ���,����Լ���Ż�����ʱ,��Ҫ���ݶ��½���(Gradient Descent)����С���˷���
(3)�������ʧ��������Сֵʱ,����ͨ���ݶ��½�����һ�����ĵ������,�õ���С������ʧ������ģ�Ͳ���ֵ��
(4)���������Ҫ�����ʧ���������ֵ,��ͨ���ݶ����������������ݶ��½������ݶ����������ת����
(5)�ڻ���ѧϰ��,�ݶ��½�����Ҫ������ݶ��½����������ݶ��½�����
�ݶ��½���ȱ��?
�ݶ��½���ȱ�������¼���:
(1)������Сֵʱ�����ٶȼ�����
(2)ֱ������ʱ���ܻ����һЩ���⡣
(3)���ܻᡰ֮���Ρ����½���
�ݶȸ���Ҳ����ע��ĵط�:
- �ݶ���һ������,���з����д�С��
- �ݶȵķ�������������ķ���
- �ݶȵ�ֵ�����������ֵ��
�ݶ��½��ĺ���˼����㷨����
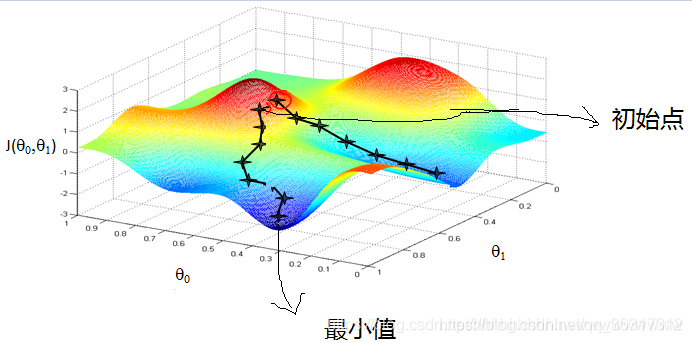
����˼��
- ��ʼ������,���ѡȡȡֵ��Χ�ڵ�������;
- ��������: a)���㵱ǰ�ݶ�; b)���µı���; c)���㳯������·�����һ��; d)�ж��Ƿ���Ҫ��ֹ,���,����a);
�㷨����
- ȷ���Ż�ģ�͵ļ��躯������ʧ������
- ��ز�����ʼ������Ҫ��ʼ�� ��i���㷨�������� �� �� ֹ �� �� ��
- �������㡣 a)���㵱ǰλ��ʱ��ʧ�������ݶ�; b)���㵱ǰλ���½��ľ���; c)�ж��Ƿ���ֹ; d)�������е� ��i ;e)���º��������a��b��c��d ����
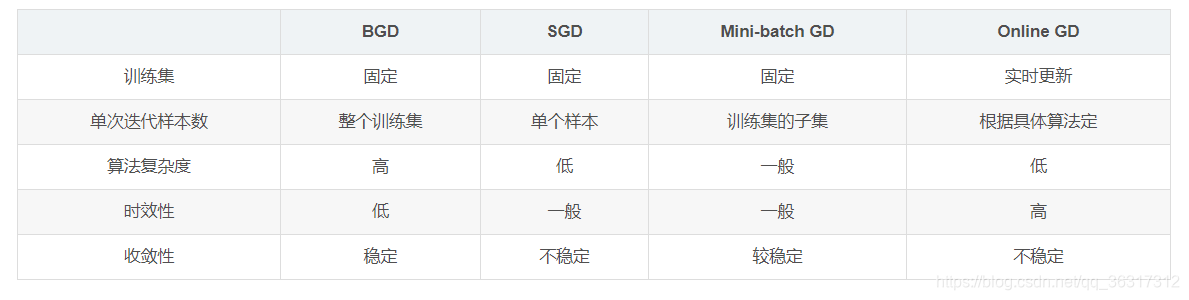
�����ݶ��½������ܱȽ�
�±��Ա�����ݶ��½�(SGD)�������ݶ��½�(BGD)��С�����ݶ��½�(Mini-batch GD)����Online GD������:
����������
��������
������:��������ǰ���һ���������Ԫ��������������
ȫ����������(FC)
- �����ֲ�:�����,�����,���ز�
- ͬһ�����Ԫ֮��û�����ӡ�
- fully connected�ĺ���:�� N ���ÿ����Ԫ�͵� N-1 ���������Ԫ������ N-1 ����Ԫ��������ǵ� N����Ԫ�����롣
- ÿ�����Ӷ���һ��Ȩֵ��
������ܹ�
�����:������Ϣ
���ز�:��������Ϣ�Ĵ��ݺͼӹ�����
�����:�õ�������Ϣ���жϽ��
�ٸ�����:����һ��è��ͼƬ��Ϊ����,ͨ�����ز����������ȡ�Լ��ӹ�,����������ʱ���ж��Ƿ�ͼƬ��è��
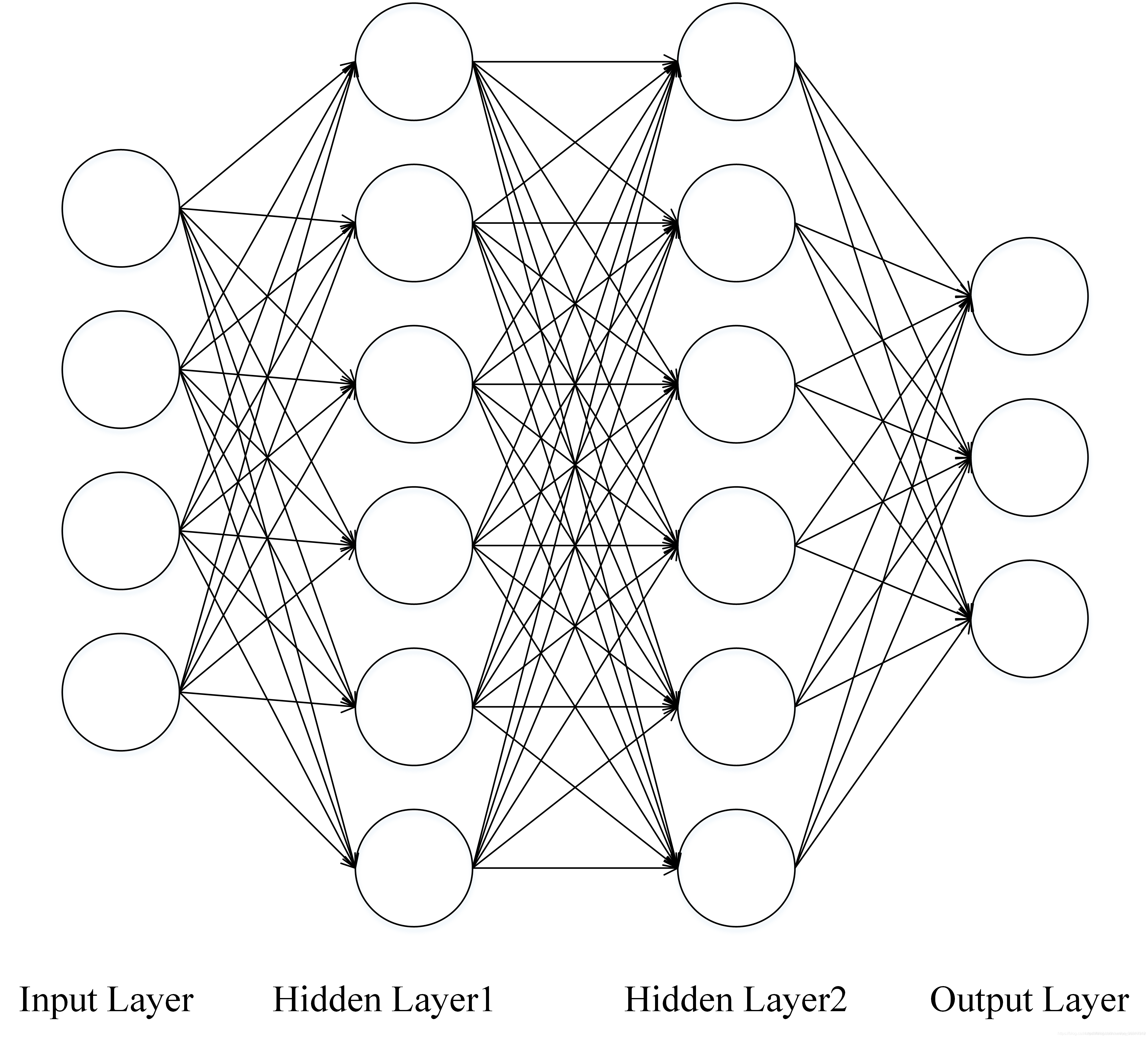
������ѵ������ʲô?
ͨ����ͼ����ܹ����Կ���,Ŀǰ��֪������(Input Layer)X�����(Output Layer)Y,δ֪����Input Layer �� Hidden Layer1 ��Hidden Layer2��Ȩ��(W)��ƫ��(b)
������Ҫ�õ��ľ���Ȩ��W��ƫ��b,����ͳ����Ϊ������IJ���
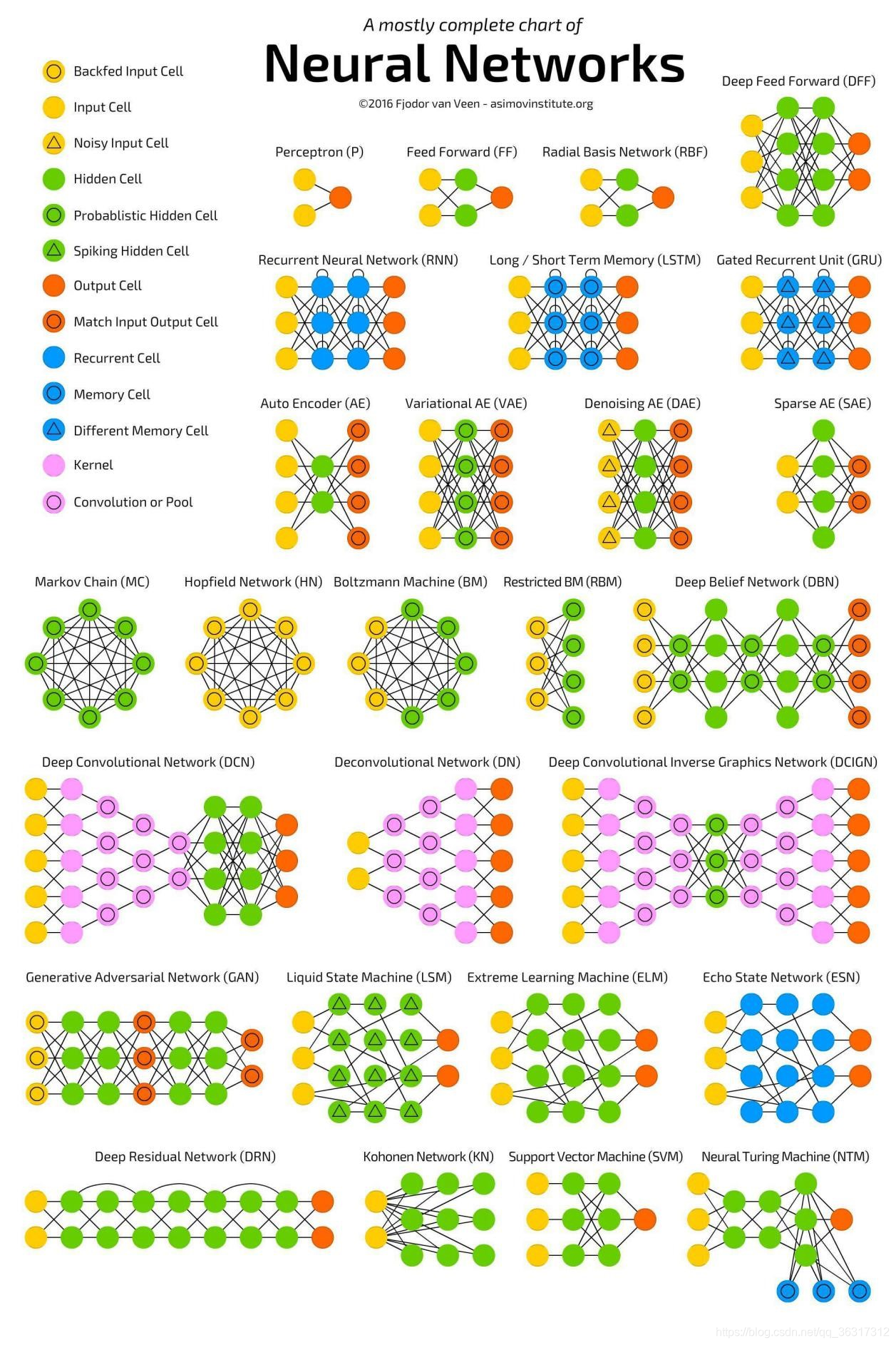
�����糣�õ�ģ�ͽṹ
�������һ��ͼ������һ��Ŀǰ���õ�ģ��
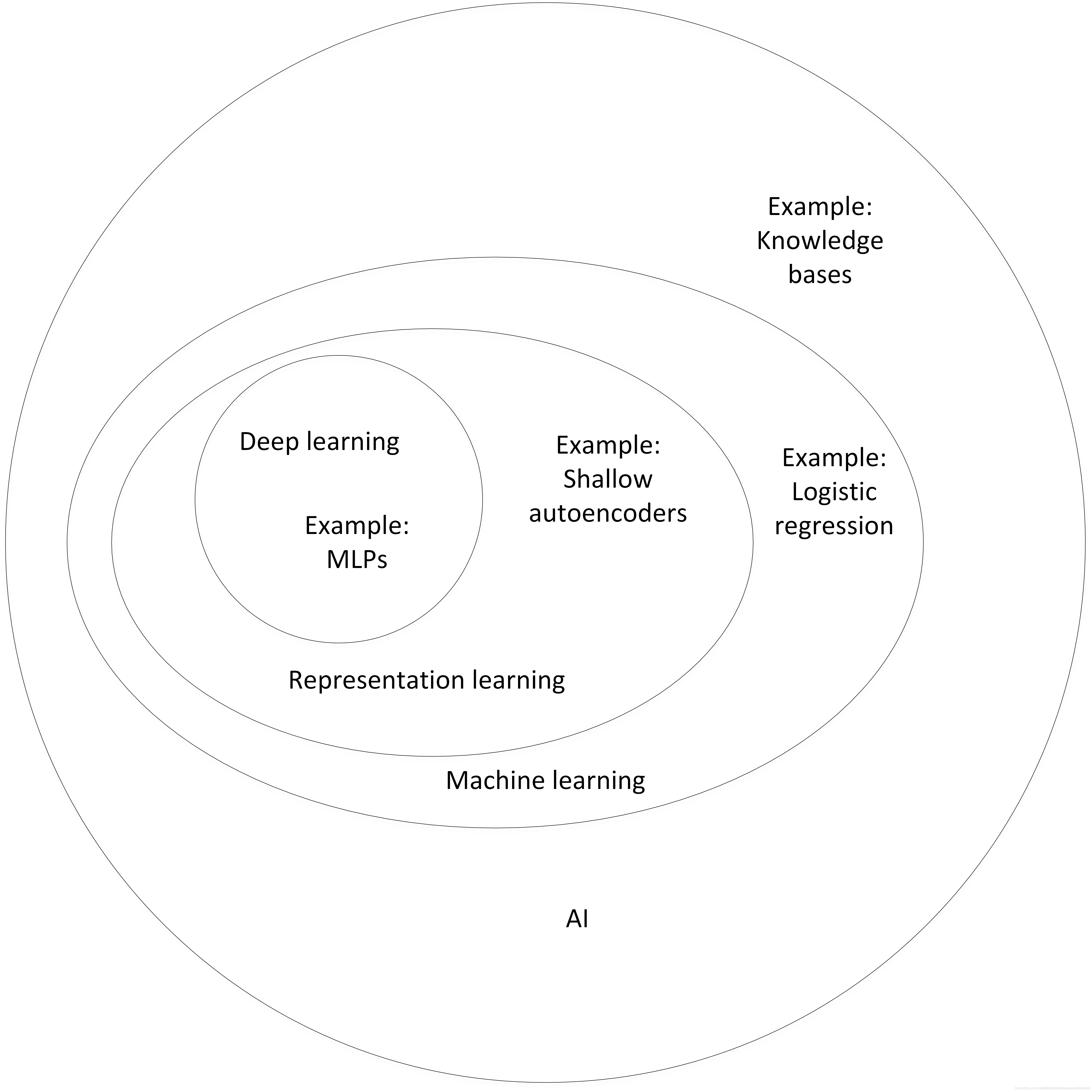
�����������ѧϰ�Ĺ�ϵ
��ͳ�Ļ���ѧϰ��Ҫ����һЩ�ֹ�����,�Ӷ���Ŀ�ĵ�ȥ��ȡĿ����Ϣ, �dz�����������������Լ����������ר�Ҿ��顣
���������������ѧϰ�ķ���,���ԴӴ���������ѧϰ������,��������ѧϰ����Ϊ���ӳ�����������,�������˹����������̡�
��ϵͼ
������Ļ���������ϸ��
��������
- ��������ṹ(ָ������㡢���ز㡢�����Ĵ�С)
���� X Ϊ�������������������,y Ϊ��ǩ�������������������Ľṹ������ʾ: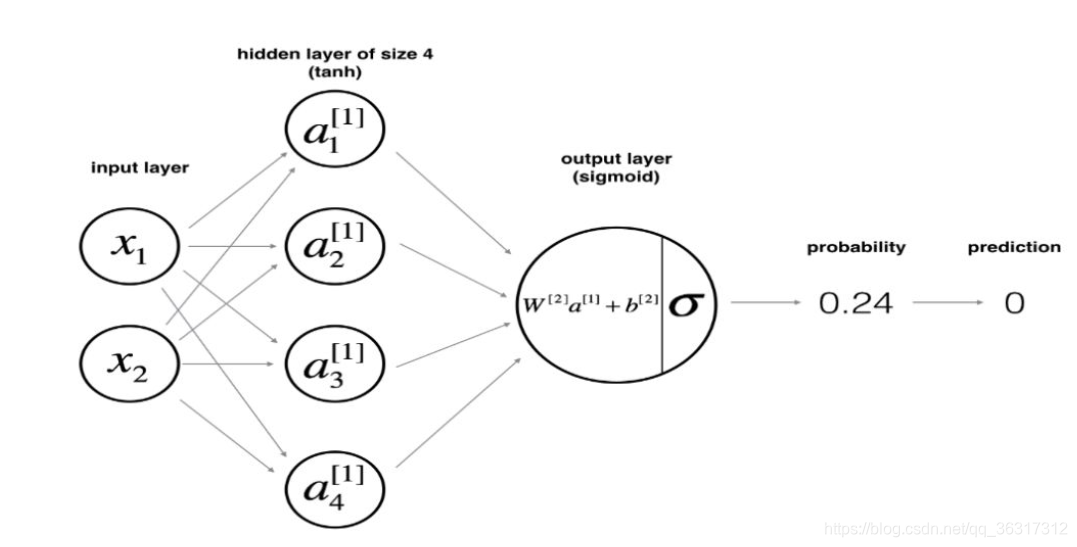
���������������Ĵ�С�ֱ��� X �� y �� shape �йء�������Ĵ�С���������ֶ�ָ������������ָ������Ĵ�СΪ4��
�Ĵ���ʵ��:
def layer_sizes(X, Y):
n_x = X.shape[0] # size of input layer
n_h = 4 # size of hidden layer
n_y = Y.shape[0] # size of output layer
return (n_x, n_h, n_y)
- ��ʼ��ģ�Ͳ���
���� W1 Ϊ����㵽�����Ȩ�����顢b1 Ϊ����㵽�����ƫ������;W2 Ϊ���㵽������Ȩ������,b2 Ϊ���㵽������ƫ�����顣
���ж�Ȩֵ�ij�ʼ������������ numpy �е������������ģ�� np.random.randn ,ƫ�õij�ʼ����ʹ���� np.zero ģ�顣
def initialize_parameters(n_x, n_h, n_y):
W1 = np.random.randn(n_h, n_x)*0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h)*0.01
b2 = np.zeros((n_y, 1))
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
����һ�ֳ��õij�ʼ�������ķ���,������ʼ��Ϊ��̬�ֲ�
for name, param in self.named_parameters():
if 'weight' in name:
nn.init.xavier_normal_(param)
- ѭ������:ִ��ǰ��/������ʧ/ִ�к���/Ȩֵ����
ǰ��:�ڶ��������ṹ����ʼ���������֮��,��Ҫ��ʼִ���������ѵ�������ˡ���ѵ���ĵ�һ������ִ��ǰ�����㡣��������ļ����Ϊ tanh ����, �����ļ����Ϊ sigmoid ������
���㵱ǰѵ����ʧ:ǰ��������ɺ�������Ҫȷ���Ե�ǰ����ִ�м����ĵ�������ǩֵ֮�����ʧ��С��
ִ�з���:��ǰ���͵�ǰ��ʧȷ��֮��,����Ҫ����ִ�з�������������Ȩֵ�ˡ�
ϸ�ڽ���
�����ͷ���
������ļ�����Ҫ������:ǰ��(foward propagation, FP)������ÿһ�������,ͨ��������õ�������;����(backward propagation, BP)��������������,ͨ�������ݶ����dz�������������
����
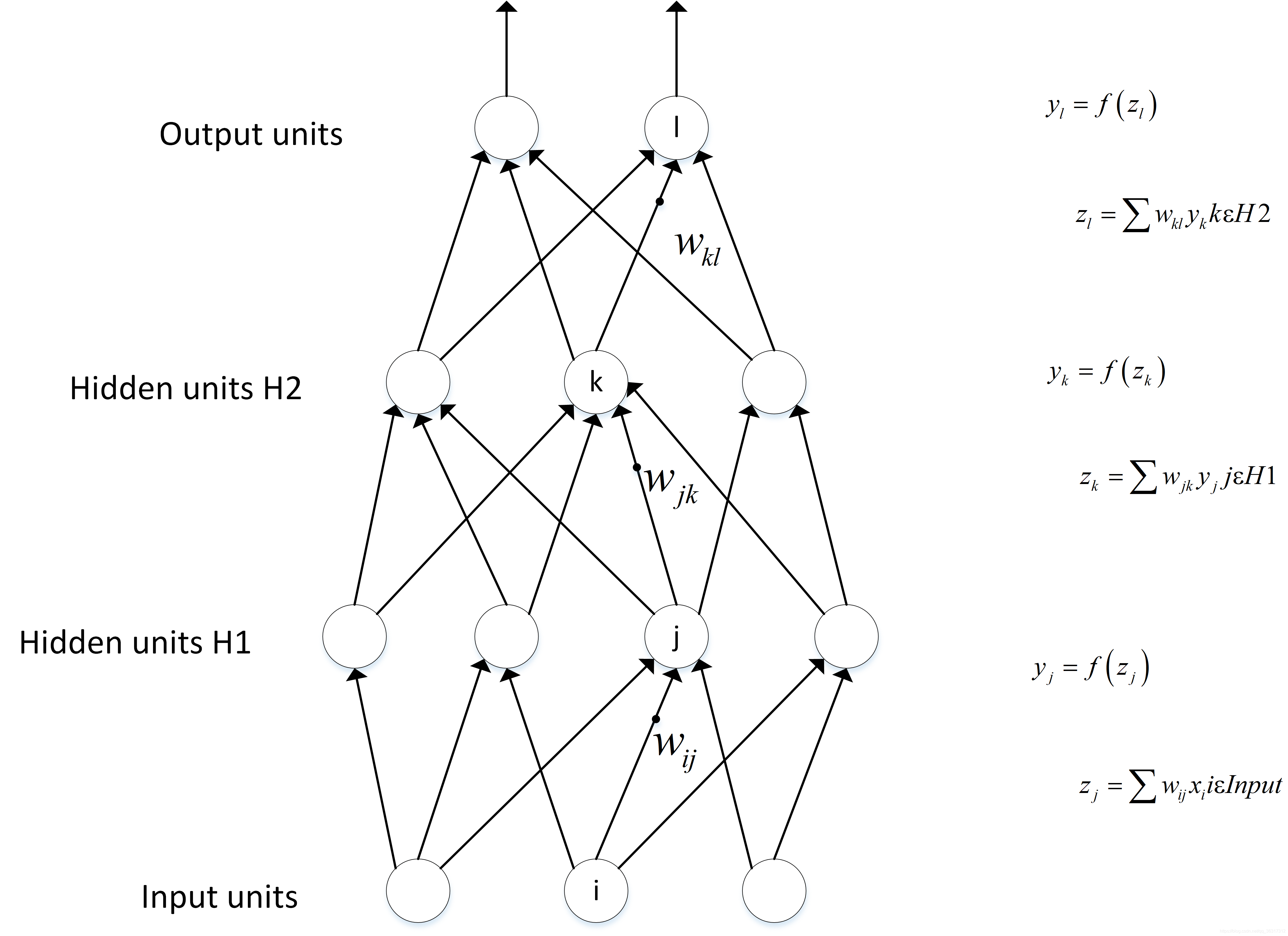
���µ���,ͨ��������input��,Ȼ��ͨ����ڵ������ӵ������w,b ,����һ�������,���õ�Outputֵ�Ľ��Y��
����
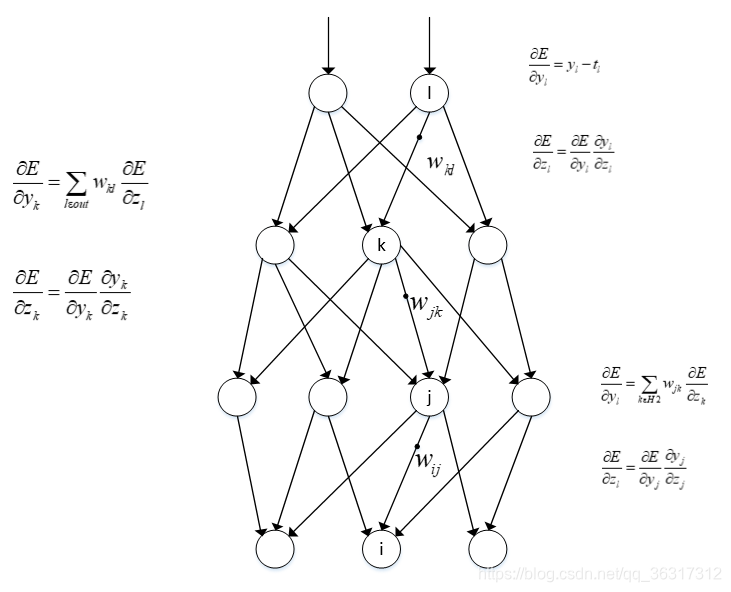
������Ŀ��:�������
����ϸ��:
���������Ϊ
E
E
E �������ļ����Ϊ���Լ����, ���������ô
E
E
E ��������ڵ�
y
l
y_{l}
yl? ��ƫ������
y
l
?
t
l
y_{l}-t_{l}
yl??tl?, ����
t
l
t_{l}
tl? ����ʵֵ,
?
y
l
?
z
l
\frac{\partial y_{l}}{\partial z_{l}}
?zl??yl?? ��ָ�����ᵽ�ļ����,
z
l
z_{l}
zl? �������ᵽ�ļ�Ȩ��,��ô��һ���
E
E
E �� ��
z
l
z_{l}
zl? ��ƫ����Ϊ
?
E
?
z
l
=
?
E
?
y
i
?
y
l
?
z
l
\frac{\partial E}{\partial z l}=\frac{\partial E}{\partial y_{i}} \frac{\partial y_{l}}{\partial z_{l}}
?zl?E?=?yi??E??zl??yl?? �� ͬ��, ��һ��Ҳ����ô����,ֻ����
?
E
?
y
k
\frac{\partial E}{\partial y_{k}}
?yk??E? ���㷽������,һֱ�����������,�����
?
E
?
x
i
�O
=
?
E
?
y
j
?
y
j
?
z
j
\frac{\partial E}{\partial x_{i}} \mid=\frac{\partial E}{\partial y_{j}} \frac{\partial y_{j}}{\partial z_{j}}
?xi??E?�O=?yj??E??zj??yj??, ��
?
z
j
?
x
i
�O
=
w
i
j
0
\frac{\partial z_{j}}{\partial x_{i}} \mid=w_{i} j_{0}
?xi??zj??�O=wi?j0? Ȼ�������Щ�����е�Ȩֵ,�ٲ��Ͻ���ǰ���ͷ����Ĺ���,���յõ�һ���ȽϺõĽ����
�����
�������ʲô?
�����(Activation functions)�����˹������� ģ��ȥѧϰ������dz����Ӻͷ����Եĺ�����˵����ʮ����Ҫ�����á����ǽ��������������뵽���ǵ������С�
��Ҫ����:Ϊ������������ģ�͵ķ�����
ΪʲôҪʹ�ü����
- �������ģ��ѧϰ������dz����Ӻͷ����Եĺ���������Ҫ���á�
- ���������������������ء������ʹ�ü����,������źŽ���һ�������Ժ��������Ժ���һ��һ������ʽ,���Է��̵ĸ��Ӷ�����,��������ѧϰ���Ӻ���ӳ���������С��û�м����,�����罫��ѧϰ��ģ�������������͵�����,����ͼ����Ƶ����Ƶ�������ȡ�
- ��������ѵ�ǰ�����ռ�ͨ��һ��������ӳ��ת������һ���ռ�,�������ܹ����õı����ࡣ
�����ļ��ּ����
�����Ĵ�ͳ�������Ҫ������:sigmoid��tanh��
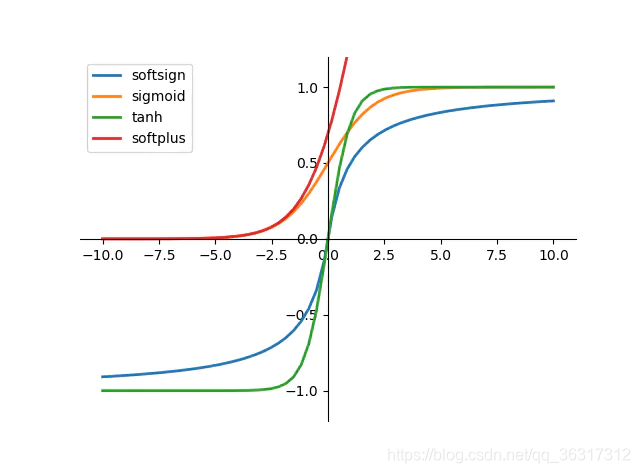
sigmoid����
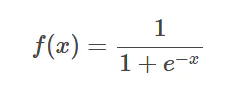
����ʹ�÷�Χ����һ�༤���,����ָ��������״,����������ӽ���Ԫ�����������Χ��(0,1)֮��,���Ա���ʾ�ɸ���,�����������ݵĹ�һ����
�ص�:���ܹ������������ʵֵ�任Ϊ0��1֮������,�ر��,����Ƿdz���ĸ���,��ô�������0;����Ƿdz��������,�������1.
ȱ��:��������������ݶȷ���ʱ�����ݶȱ�ը���ݶ���ʧ,�����ݶȱ�ը�����ĸ��ʷdz�С,���ݶ���ʧ�����ĸ��ʱȽϴ�
���ݶ���ʧ:ͨ�����ز�Ӻ���ǰ��,�ݶȻ���Խ��ԽС,����f��(x)��ýӽ���0,��ʱ,����������ѵõ���Чѵ��,��������Ϊ�ݶ���ʧ��
tanh�����
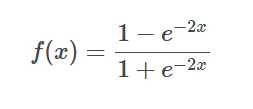
tanh������sigmoid�������,�����ֵΪ0,���ʹ���������ٶ�Ҫ��sigmoid��,�Ӷ����Լ��ٵ���������
�ŵ�:
�����Sigmoid��������������ԳƵ�����
Ҳ����Sigmoid���ŵ�ƽ��,������
ȱ��:
�������������(�����ݵ�����)
Tanh�ĵ���ͼ����Ȼ���֮���,ʹ���ݶ���ʧ������õ�һ���Ļ���,���Dz��ܸ�������������
Relu�����
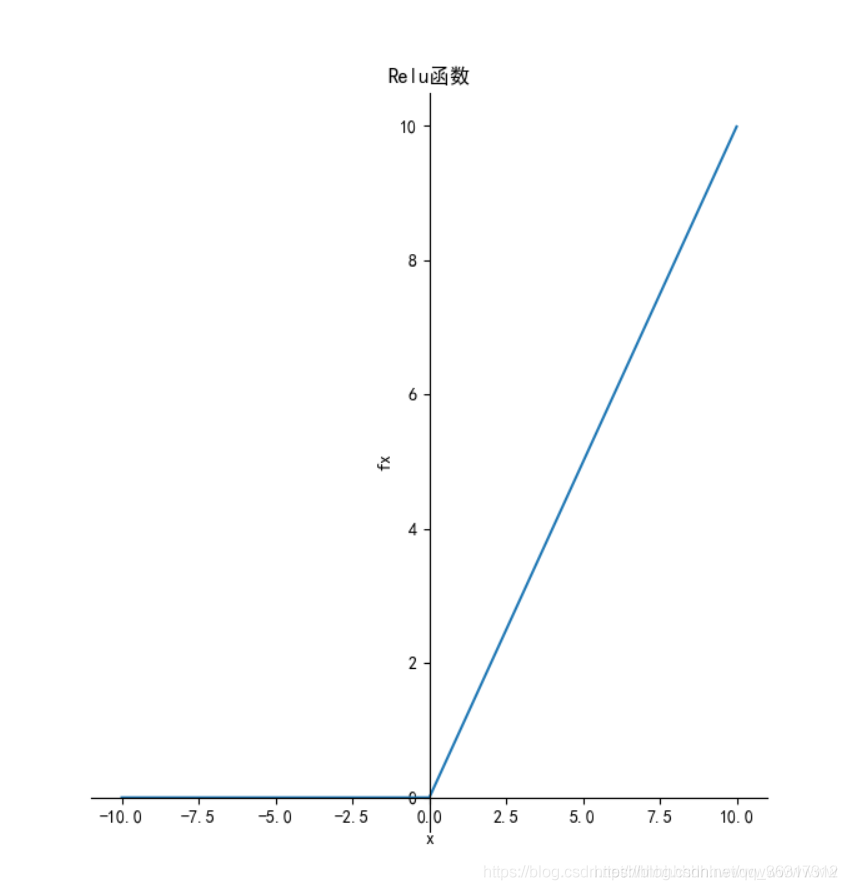
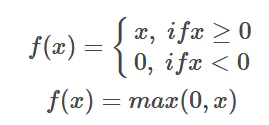
�ص�: ����x>0ʱ�����ڱ�������,�Ӷ�ʹ�����ݶȲ�˥��,�Ӷ�������ݶ���ʧ���⡣
�ŵ�:
1.�����Sigmoid��tanh,ReLU��SGD���ܹ���������,������Ϊ������(linear)���DZ���(non-saturating)����ʽ��
2.Sigmoid��tanh�漰�˺ܶ��expensive�IJ���(����ָ��),ReLU���Ը��Ӽ�ʵ�֡�
3.��Ч�������ݶ���ʧ�����⡣
4.��û���ලԤѵ����ʱ��Ҳ���нϺõı��֡�
ȱ��:
ReLU���������z��ero-centered
Dead ReLU Problem,ָ����ijЩ��Ԫ������Զ���ᱻ����,������Ӧ�IJ�����Զ���ܱ����¡�
Leaky-ReLU�����
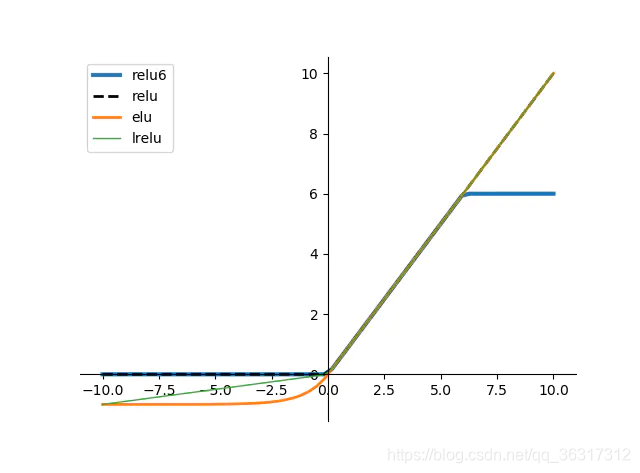
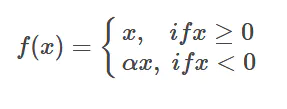
�ص�:Ϊ�˱���ReLU��x<0ʱ����Ԫ��������,������һ��������
ELU�����
������ͼ��ɫ����������,�������sigmoid��ReLU����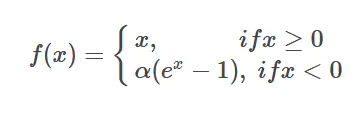
�ŵ�:
1���ں���sigmoid��ReLU,��������������,�Ҳ��ޱ����ԡ�
2���Ҳ����Բ���ʹ��ELU�ܹ������ݶ���ʧ,����������ܹ���ELU������仯��������³����
3��ELU�������ֵ�ӽ�����,���������ٶȸ��졣
���ѡ����ʵļ����?
ѡ��һ���ʺϵļ������������,��Ҫ���Ǻܶ�����,ͨ����������,�����ȷ����һ�������Ч������,�������Ƕ�����,Ȼ������֤�����߲��Լ��Ͻ������ۡ�Ȼ����һ�ֱ��ֵĸ���,��ȥʹ������
���þ���
1���������� 0��1 ֵ(����������),�������ѡ�� sigmoid ����,Ȼ�����������е�Ԫ��ѡ�� Relu ������
2����������ز��ϲ�ȷ��ʹ���ĸ������,��ôͨ����ʹ�� Relu ���������ʱ,Ҳ��ʹ�� tanh �����,�� Relu ��һ���ŵ���:���Ǹ�ֵ��ʱ��,�������� 0��
3��sigmoid �����:�����������һ�������������������������
4��tanh �����:tanh �Ƿdz������,�����ʺ����г��ϡ�
5��ReLu �����:��õ�Ĭ�Ϻ���,�����ȷ�����ĸ������,��ʹ�� ReLu ���� Leaky ReLu,��ȥ���������ļ������
6�����������һЩ������Ԫ,���ǿ���ʹ�� Leaky ReLU ������
���Ը����������þ���,���г��ԡ�
Batch_Size ������
batch_size����
Batchһ�㱻����Ϊ����,����batch_size��Ŀ����ģ����ѵ��������ÿ��ѡ�����������������д�����
Batch Sizeֱ������:һ��ѵ����ѡȡ��������
Batch Size�Ĵ�СӰ��ģ�͵��Ż��̶Ⱥ��ٶȡ�ͬʱ��ֱ��Ӱ�쵽GPU�ڴ��ʹ�����,������GPU�ڴ治��,����ֵ�������Сһ�㡣
Ϊʲô����batch_size?
���1:ѵ�����������е�ѵ������ֱ�����뵽����
ȱ��:
1����ѵ���������dz���ʱ,ֱ�ӽ���Щ�������뵽������Ļ��ᵼ�¼������dz���,ͬʱ�Լ��˼����ڴ�Ҫ��Ҳ�Ƚϸߡ�
2������������ͬʱ���뵽������ʱ,��������ȷ��һ��ȫ������ѧϰ��ʹ��ѵ��Ч����ѡ�
���2:ѵ������ÿ��ֻ��ȡһ��������Ϊ����
ȱ��:��ÿ��ѵ�������ϵõ���Ŀ�꺯��ֵ�����ܽϴ�,������ͨ����ͻ�����ƽ��ֵ�ķ������õ���Ŀ�꺯��ֵ�����Դ���ÿ��������Ҳ����˵,���ַ����õ���ģ�Ͷ������ķ��������
���,������batch_size ��һ����,ÿ��ֻ����һ��������ѵ��������ģ�ͽ���ѵ��,�����������batch_size�Ĵ�С��
�ŵ�:
1�����Գ�����ü�����IJ�������ṹ,������ݴ����ٶ�;
2��������һ����������������,���ԱȽ�ȷ�ô����ݶ��½�����
3������һ�� epoch(ȫ���ݼ�)����ĵ�����������,������ͬ�������Ĵ����ٶȽ�һ���ӿ졣
�������Batch_sizeֵ
batch��size���õIJ���̫��Ҳ����̫С,���ʵ�ʹ�������õľ���mini-batch,һ��size����Ϊ��ʮ�����١�
ע��:
1)batch��̫С,������ֱȽ϶��ʱ��,��Ŀ��ܻᵼ��loss������������,���������������Ƚϸ��ӵ�ʱ��
2)����batchsize����,������ͬ�����������ٶ�Խ�졣
3)����batchsize����,�ﵽ��ͬ��������Ҫ��epoch����Խ��Խ�ࡣ
4)���������������ص�ì��, Batch_Size ����ij��ʱ��,�ﵽʱ���ϵ����š�
5)���������������Ȼ����벻ͬ�ľֲ���ֵ,��� Batch_Size ����ijЩʱ��,�ﵽ�������������ϵ����š�
6)�����batchsize�Ľ�������������������һЩ���õľֲ����ŵ㡣ͬ��̫С��batchҲ����һЩ����,����ѵ���ٶȺ���,ѵ�������������ȡ�
7)�����batch size��ѡȡ��ѵ������������Ŀ��ء�
8)GPU��2���ݴε�batch���Է��Ӹ��ѵ�����,������ó�16��32��64��128��ʱ����Ҫ������Ϊ��10����100�ı���ʱ���ָ���
����:������BatchSize��ʱ��,����ѡ�����BatchSize��GPUռ��,�۲�Loss���������,���������,��������Ч��������BatchSize,һ�㳣��16,32,64�ȡ�
ѧϰ������
ѧϰ������
ѧϰ�� (learning rate),�ڵ��������л����ģ�͵�ѧϰ����
���ݶ��½�����,���Ǹ�����ͳһ��ѧϰ��,�����Ż������ж���ȷ���IJ������и���, �ڵ����Ż���ǰ����**,ѧϰ�ʽϴ�**,��ǰ���������ͻ�ϳ�,��ʱ�����ԽϿ���ٶȽ����ݶ��½�,���ڵ����Ż��ĺ���,��Сѧϰ�ʵ�ֵ,��С����,�������������㷨������,�����ӽ����Ž⡣
�ܽ���������:ѧϰ��Խ��,����Խ��,Խ���ܹ��ﵽ����,Խ���ӽ����Ž⡣
**����:**һ�����ó�ʼֵ ��0.002,��ѵ�������������,����������
Dropoutʹ��
ʲôʱ����Ҫ�õ�Dropout?
�ڻ���ѧϰ��ģ����,���ģ�͵IJ���̫��,��ѵ��������̫��,ѵ��������ģ�ͺ����ײ�������ϵ�����
����ϱ���:ģ����ѵ����������ʧ������С,Ԥ��ȷ�ʽϸ�;�����ڲ�����������ʧ�����Ƚϴ�,Ԥ��ȷ�ʽϵ͡�
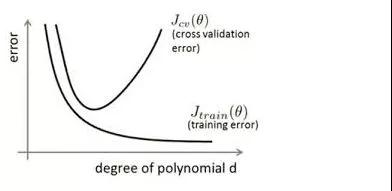
[��ͼ�������ܹ�����,ģ����ѵ�����ϱ��ֺܺ�,�����ڽ�����֤���ϱ����Ⱥú���Ҳ���ǹ���ϵ�����!]
Dropout���ԱȽ���Ч�Ļ������ϵķ���,��һ���̶��ϴﵽ����Ч����
��ʹ��:
self.drop_1 = nn.Dropout(p=0.5)
input_x = self.drop_1(input_x)
�ܽ�
����ļ��������������һ�ڼ��˽Ⲣ�����ܽ��,ϣ���ܹ�Ϊ��λС������ṩһЩ����,ͬʱҲ��¼�˵�����һ��ʼ�Ӵ�����ѧϰ��һЩ����,�����Ķ���������ݼ����,�dz��ʺ�С�׳�ѧ������������,���������������,��������ע,��������ʹ���,лл�����!
ͬʱ��Ҫע������,���ǿ��� AI�Ƶ�������������, Ҳ������Ҫ����һ��ѧϰ���ݽ���һЩ�ܽ�,�����,�����ڴ��ر��лAI��!
���Ǵ��е���ҳ:https://wanghao.blog.csdn.net/
https://wanghao.blog.csdn.net/article/details/119415450
https://wanghao.blog.csdn.net/article/details/119604015
���о������ղص�����,���ñȽϺõ�,Ҳ��������
https://blog.csdn.net/chibangyuxun/article/details/53148005
����Ȥ��С������ȥѧϰѧϰ!