ResNet�����
���������ڳ��νӴ��в������С��,ֻ��Ϊ�˶Բв��������Ÿ��õ����ŵ�һƪ���¡�
�������:

��ν���ѧϰ,���˶�����Ϊȷ�ʻ����ž���������Ӷ�����,�������ż���������,���˿�ʼ��������һ��56��ľ���������20��ľ���,����ʵ����ȱ����56��ľ���ȷ�ʻ�Ҫ����20��ľ���,������ʵ���������Ǹе��ܲ���,Ϊʲô���������ӷ������ᵼ��ȷ�ʽ�����?
����ͨ�������ľ����о�����,���µ�ԭ���п������ľ������������ݹ���ϵ�������ݶ��½��ĺ��,�����ݶ��½�������Щ������IJ�����ȫû���κ�����,��ô�����ľ���������һ�������������,�����ľ�����Ч���϶��Ǻܲ�ġ�
����취
����������������ֽ���취:
һ���ǵ�����ⷽ��,������õij�ʼ�������õ��ݶ��½��㷨��;
��һ���ǵ���ģ�ͽṹ,��ģ�������Ż������ı�ģ�ͽṹʵ�����Ǹı���error surface����̬��
��ôResNet�����߲����˵ڶ��ֽ���취,����ͨ���ı�ģ�͵Ľṹ������ݶ��½��İ취,��ôΪ���ø����ľ����������Ÿ��õ�Ч��,�������ͼ�����
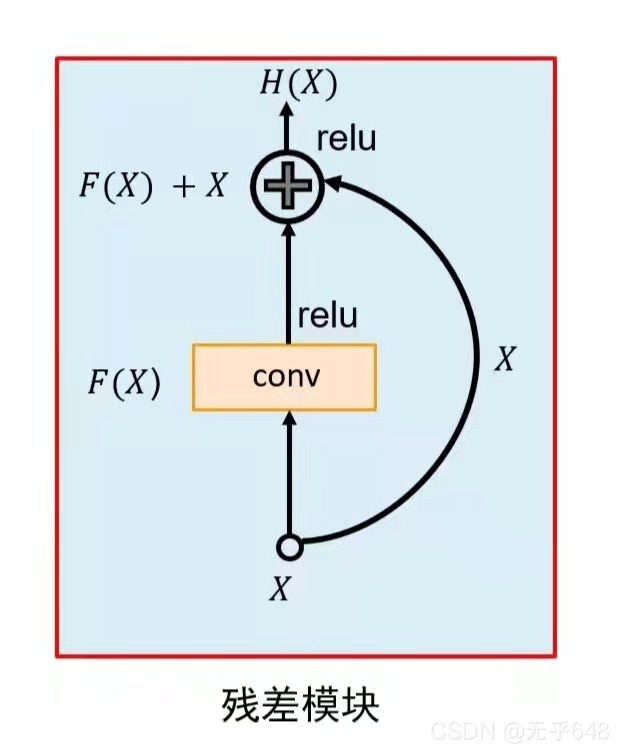
��ͼ���ձ������������в�ģ��,Ҳ����ResNet�ĺ��ļ���,
���ѵ��ļ���layer��֮Ϊһ��block,����ij��block,�������ϵĺ���ΪF(x),���������DZ��ӳ��ΪH(x),������F(x) ֱ��ѧϰDZ�ڵ�ӳ��,����ȥѧϰ�в�H(x)?x,��F(x):=H(x)?x,����ԭ����ǰ��·���Ͼͱ����F(x)+x,��F(x)+x�����H(x)��������Ϊ�������ܸ������Ż�,��Ϊ�������F(x)ѧϰ�ɺ��ӳ��,��F(x)ѧϰ��0Ҫ�������ס�������ͨ��L2����Ϳ�������ʵ�֡�����,���������block,ֻ��F(x)��0�Ϳ��Եõ����ӳ��,���ܲ�����
���մ����˵����˼����,һ��ÿ�����������ͼ���ǵ�����������һ�ε����������ͼ,֮�����ݶ��½���ը������Ϊ�����㶼���������,����������һ��,��һ���˸��ߵڶ�����,֮��ڶ���������һ���ٸ��ߵ�������,�Դ�����,ֱ���������һ���˵�ʱ��,���ܸ������ԭ���Ѿ����ྶͥ��,����ResNet������һ�˴���ģʽ,�����ڵڶ����˸��ߵ�������֮��,��һ�����ٸ���һ���������,�����������˾��յ��˵�һ���˺͵ڶ����������˵��������˼��,�����Ϳ��Ա�֤����Ч��Ҳ�ǿ���֪��ԭ������˼,���һ����Ը���ǰһ���˵�����������⡣

����������
�в����������õ���Ҫԭ�������Щ�в��ѧϰ��Ⱥ����dz�����,�ܹ���֤��������ܲ����յ�Ӱ��,�ܶ�ʱ�������������Ч��,����˵���ٲ��ή������Ч��,��˴������Ʋв�������������������ܡ�һ�����������Ľṹ���Ǽ�������������һ���ػ���,������������һ������ȫ���Ӳ㡣
������Ϊ�в������ÿһ����������һ�����ǰ�IJ�,�����ͱ�֤���ٲ�Ҳ�Ǹ���ǰ��һ����,��������˵�ġ�������һ��,��ʹ����������IJ���,��Ҳ�����ظ���ǰ�������,�����Ͳ������ƫ����,����������綼����ʵ����,�ɴ˿����в�������ʵ��������������źܴ��Ӱ�졣
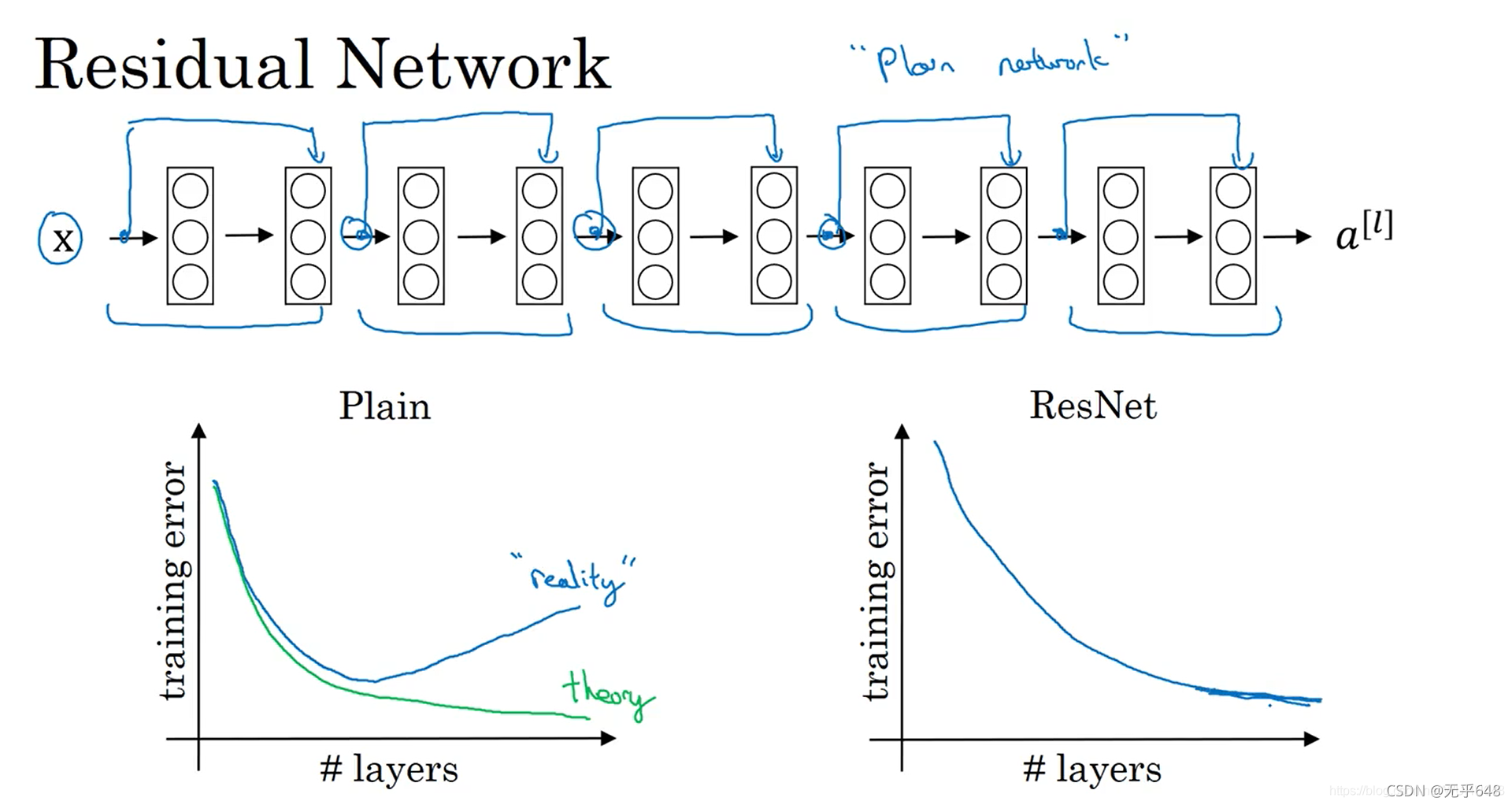
��ͼ������û�вв�����֮ǰ�Ĵ����ʻ����Ų����������ȼ�С������,ͼ�������˲в�����֮��Ĵ����ʻ����Ų���������һֱ���١�
Ϊ�˼�������,��������һ����������ͼ

����ԭͼ����Ϊ�����������ͼ,ϸ���Ǿ�������������ޚ����ͼ,������ͨ���������,�͵õ����������ͼ,���������ϸ������ͼ���һ��ȫ�ڵ�ͼ,Ҳ����û���κ�����,������ͨ���������,�õ�����ͼ��ʵ���Ǹ�ԭͼ��һ��Ч��,��������ͼ��������Ϊ�����������ɻ�����ԭͼ,��Ҳ���Dzв����������һ�������
����
ͨ���̶̵�һƪ���¾Ϳ��Դ�ŶԲв�����ĸ�������һ��������,������Щֻ�Dzв��һЩ�������,�Ͼ���в�������ô��ijɾͲ����ܼ��仰�ͽ���,��Ҫ������ѧϰ�����������ѧ����,����ȥ��һЩ�в���������Ļ��ߴ���д����ϸ�̳���Ϊ�á�