Feature Extraction
InfoGAN
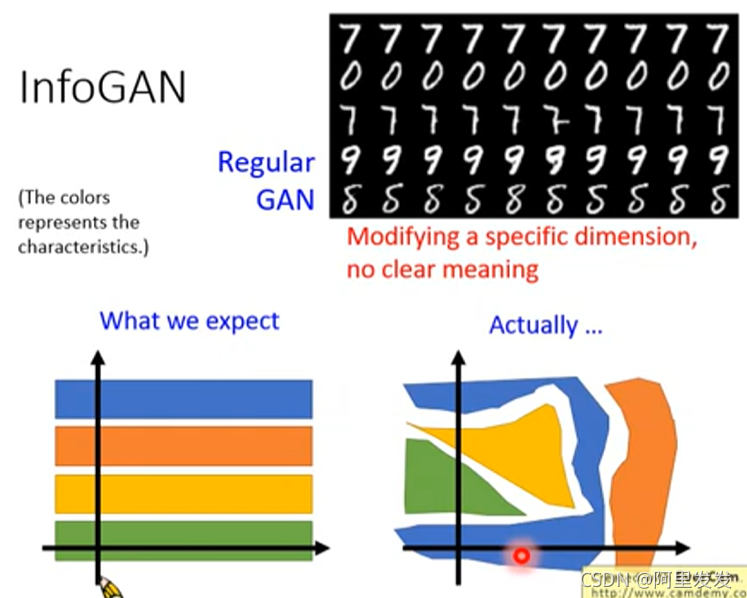
对于Regular GAN而言,我们很难从输入和输出中找到某种关联(Modifying a specific dimension, no clear meaning),例如下图中,每一列都是改变了输入的某一个维度,然后得到的结果,我们并不知道为什么第三行第六列为什么会突然多一个小尾巴。
InfoGAN就是要解决这个问题。来看它的概念:
What is InfoGAN?
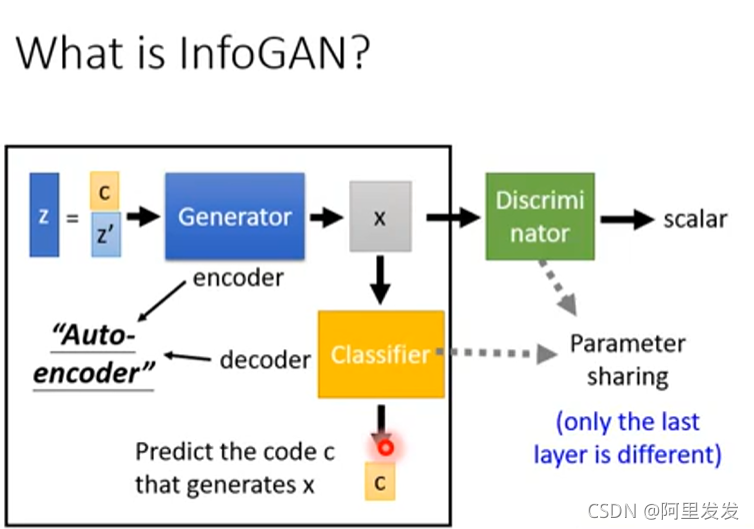
来看流程,现有一个输入z zz,和原始GAN不一样,这里把输入分为两个部分
然后经过Generator后,得到一个生成数据(图片)x ,把生成数据丢到一个分类器中,分类器要从生成数据(图片)x 中反推出原输入的c
这里可以把Generator看做是encoder,分类器Classifier看做是decoder,两个组成一个“autoencoder”,这里的autoencoder是带引号的,因为
原来我们学过的autoencoder是将图片经过encoder变成编码,然后再把编码经过decoder变回图片。
这里是将编码经过encoder变成图片,然后再把图片经过decoder变回编码。
当然,模型中还要有Discriminator,不然就不叫GAN了
如果没有Discriminator,Generator为了让Classifer辨识出c cc,直接就可以把c cc贴到x xx中,这样根本就没有训练到。所以加上Discriminator可以让输出的图片像真实图片。
在实作上由于Classifier和Discriminator都是吃同样的参数,所以,它们两个通常会share参数,只不过一个输出的是code,一个是scalar。
那么为什么加了Classifier可以work?因为只有在训练Generator的过程中,学习到了c影响x的关系,Classifier才能正确的从x中分辨出c来。
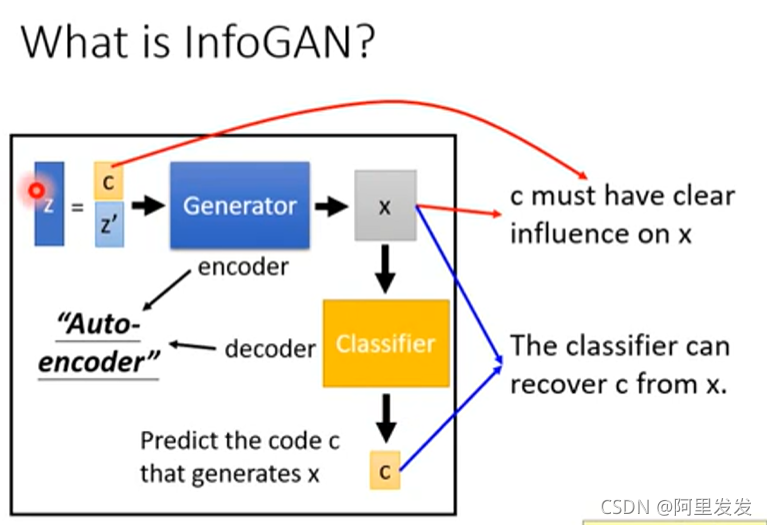
在图中我们看到还有一个z ′ ,这个东西代表一些随机的东西,就是我们也不知道这些东西影响输出的那些方面。
这里的c不是预先划分好的,而是因为我们设置了c,才训练出c影响了那些特征。

VAE-GAN
Anders Boesen, Lindbo Larsen, S?ren Kaae S?nderby, Hugo Larochelle, Ole Winther, “Autoencoding beyond pixels using a learned similarity metric”, ICML. 2016
模型如下图所示,VAE部分的z应该还有一个normal分布的constraint没有画出来。
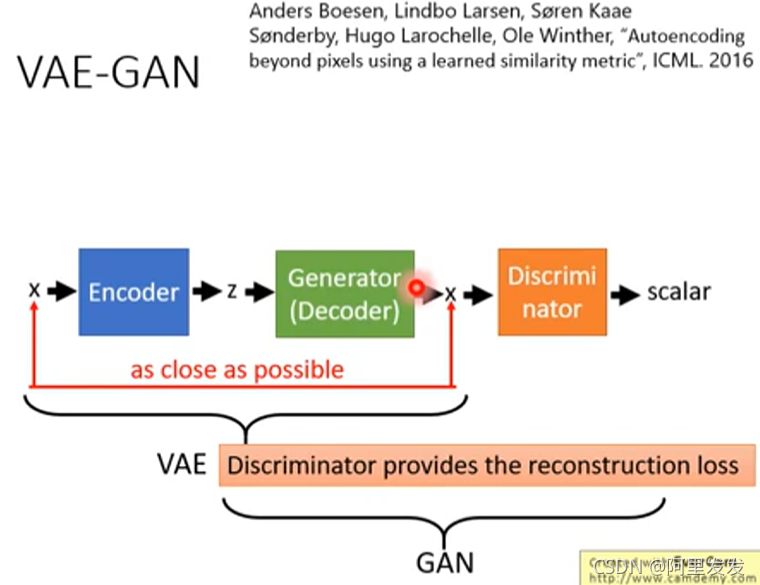
从VAE的角度来看:如果只是VAE追求输入x和decoder还原的x之间的reconstruction error的最小化,那么得到结果是不真实的(很模糊),具体可以看之前的VAE的讲解,那么加上Discriminator之后,可以促使生成的图片更加接近真实图片(否则不能通过Discriminator的分辨)。
从GAN的角度来看:Generator是看过真实的图片,并且要以还原真实图片为目标的,它并不单单是想要骗过Discriminator这么简单,所以加了VAE的GAN会比较稳。
上图中的三个东西的目标如下表:
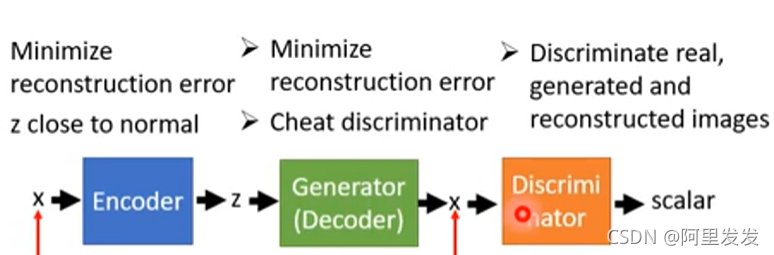
具体算法
? Initialize E n , D e , D i s初始化三个东西(都是network,有参数需要初始化)
? In each iteration:

这里的Discriminator是二分类(区分真实和生成图片),还有一种做法是做成三分类的分类器
BiGAN
先把VAE部分拆开,变成:
拆开之后的Encoder和Decoder是完全分开的,Decoder的输入不是根据Encoder的输出来的,而是从一个正态分布中生成图片,两个东西最后如何训练?通过Discriminator:
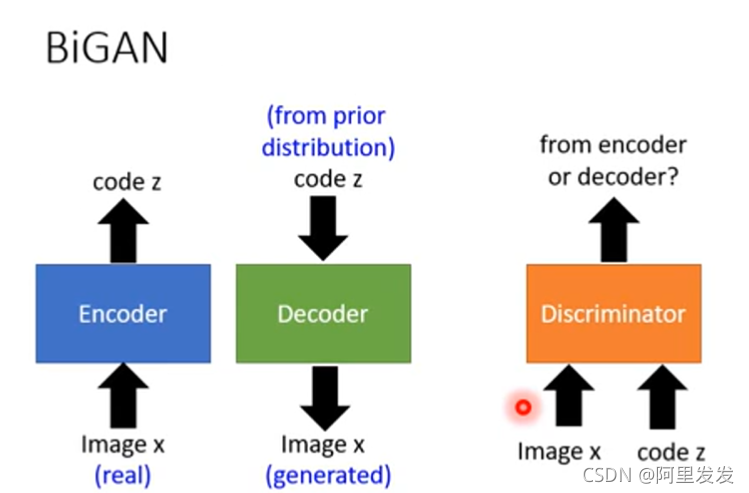
把图像和代码分别丢到Discriminator中,Discriminator判别是Encoder还是Decoder。


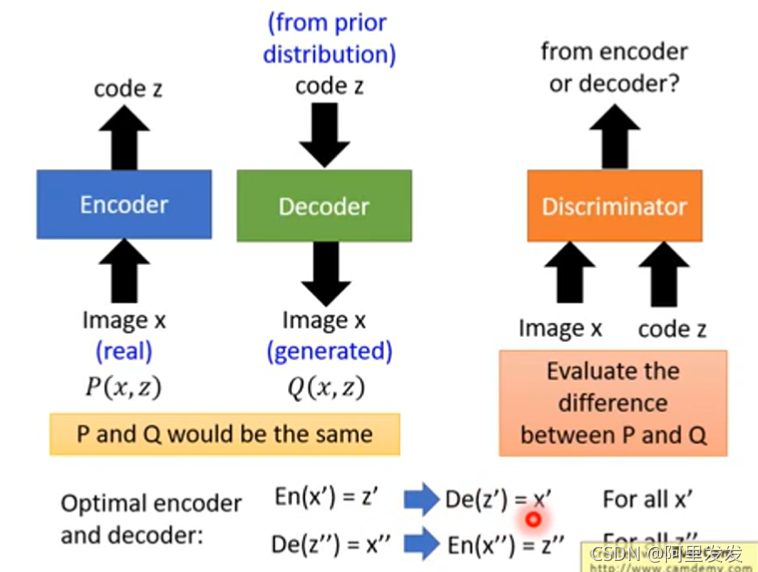
既然Discriminator存在的是为了使得Encoder和Decoder输入和输出的分布相同,那么能否使用如下模型:
用VAE,左边是输入图片还原图片,右边是输入code还原code(反向AE),两边的目的都是使得reconstruction error越小越好。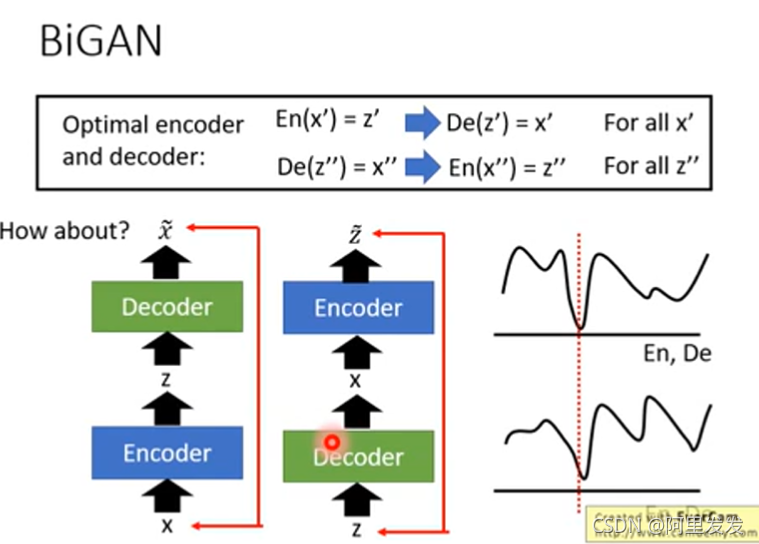
从结果上看两个VAE的结果是模糊的(因为优化的结果会有误差,reconstruction error不可能为0),输入一只鸟得到一只同样的模糊的鸟,而BiGAN输入一只鸟,得到另外一只鸟。
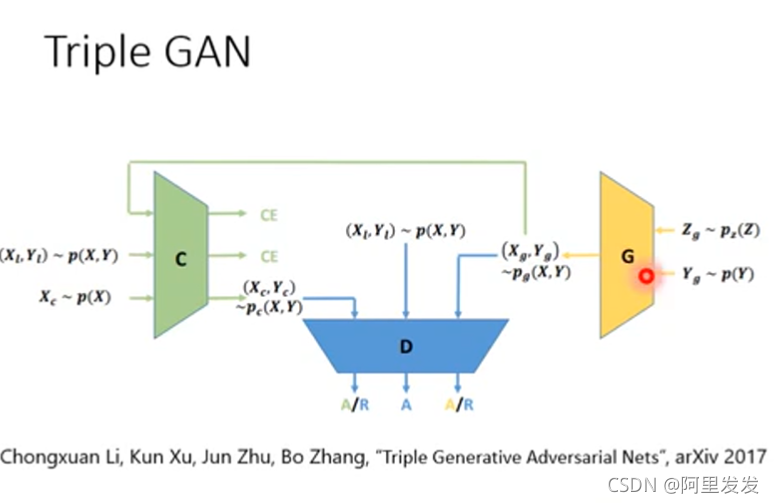
Triple GAN

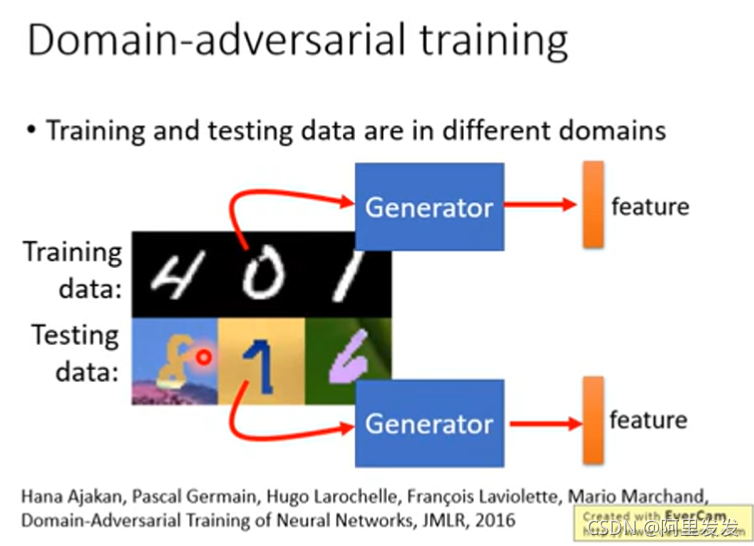
Domain-adversarial training
This is a big network, but different parts have different goals.
这里注意一下,虽然论文中是三个模块(network)一起train的,但是分开迭代train会比较稳(先训练Domain Classifer,再训练feature extractor)。
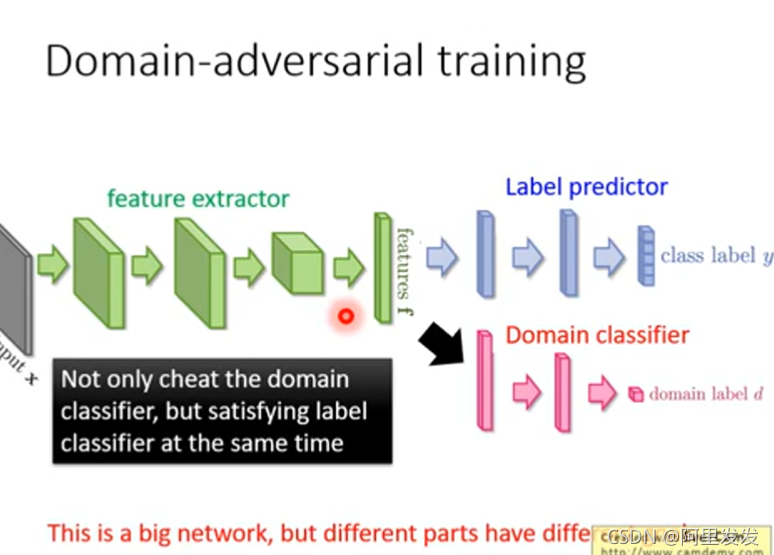
用这个技术可以用来实现下面这个技术:Feature Disentangle
Feature Disentangle
为了讲清楚这个东西,我们用语音为例,这个技术也可以用在图像处理等方面。
假设我们训练一个语音的AE,Original Seq2seq Auto-encoder
把一段声音信息压缩为code,在把code还原回声音信号。目标是input和ouput越接近越好。中间抽取出来的code我们希望它能够代表这段声音信息的特征,但是这个是不可能的,因为这一段声音信息还包含了其他信息,如:说话人的信息、环境的信息。
因此我们想要知道在这个code中那些维度代表了发音的信息,不包含其他信息。这里就是要用到Feature Disentangle的技术。
从字面上理解Disentangle是解开的意思,各种信息的特征交织打结在一起,要把它解开。这样我们就知道那些维度代表发音的信息,哪些维度代表语者的信息。
具体做法:
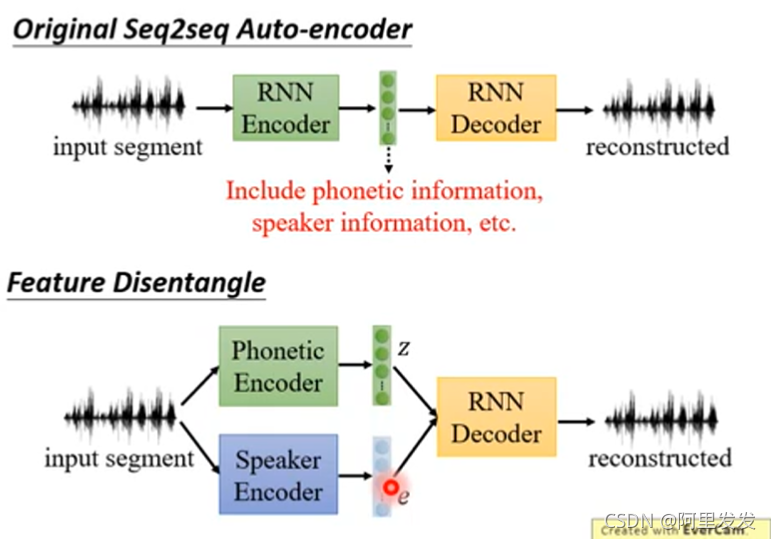
train两个Encoder,一个学习语音信息,一个学习语者信息。这样训练出来的语音Encoder可以处理与人无关的语音,直接提取出语音特征;训练出来的语者Encoder可以用来做为识别语者身份的声纹特征。
如何分布训练上面两个Encoder?
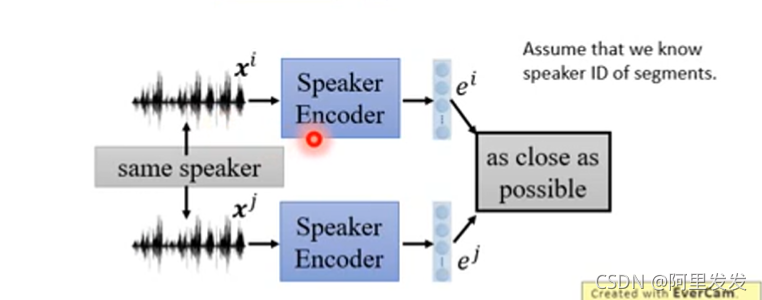
先看训练语者信息的Encoder,这个时候Assume that we know speaker ID of segments.
我们假设我们知道那些声音信号是来自同一个语者,这个很好弄,可以把同一个人说的话切开,变成几个小段语音,就得到同一个人说的不同语音。
如果两个语音来自相同的人(说的语音内容不一样,但是说话的人是同一个),我们希望下图中两个语者信息的Encoder的输出越接近越好:
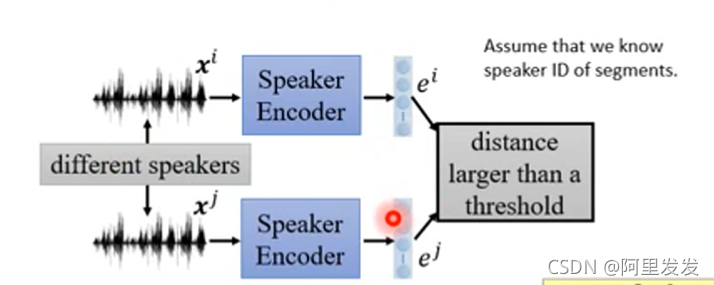
如果两个语音来自不同的人(说话的人不是同一个),我们希望下图中两个语者信息的Encoder的输出越不同越好(接近某个阈值):

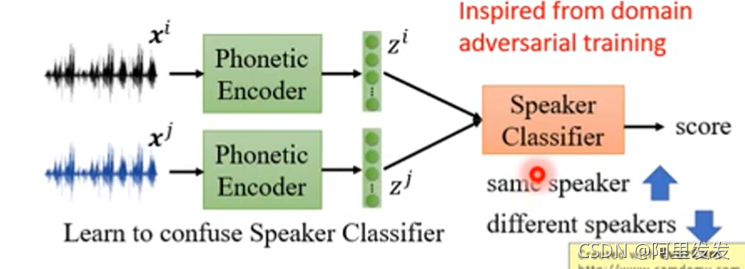
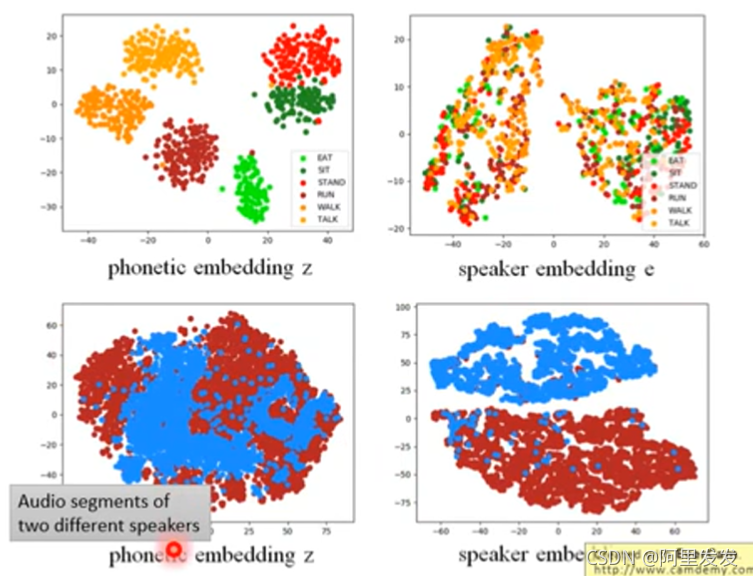
论文的结果如下图,、左边两个是针对语音,右边两个是针对语者。
Intelligent Photo Editing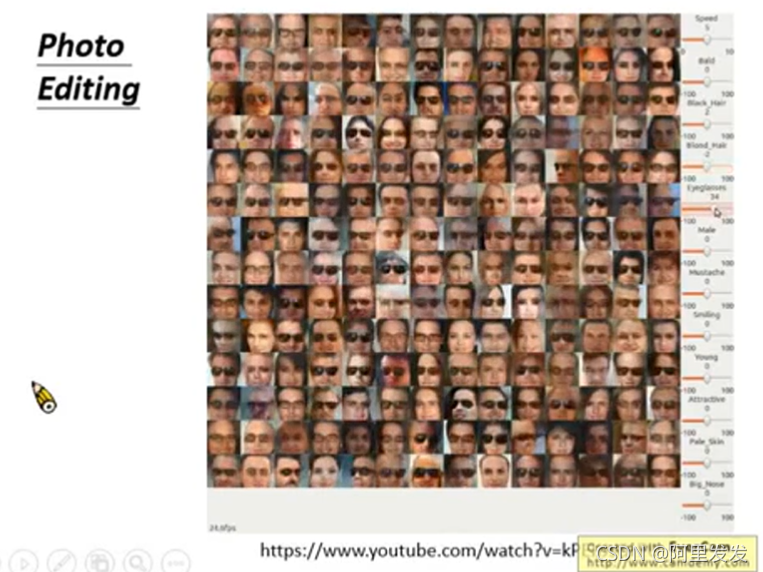
右边的bar是调整各种属性,例如:头发颜色,头发浓密,胡子,性别,皮肤颜色、笑的表情等,左边就会根据特定的属性值生成对应的图片。这节就是来学习这个demo的原理:Photo Editing
之前学习GAN,我们知道,可以用一组随机向量来生成一个图片:
这个向量每一个维度实际上是对应了图片中不同的特征的,例如:
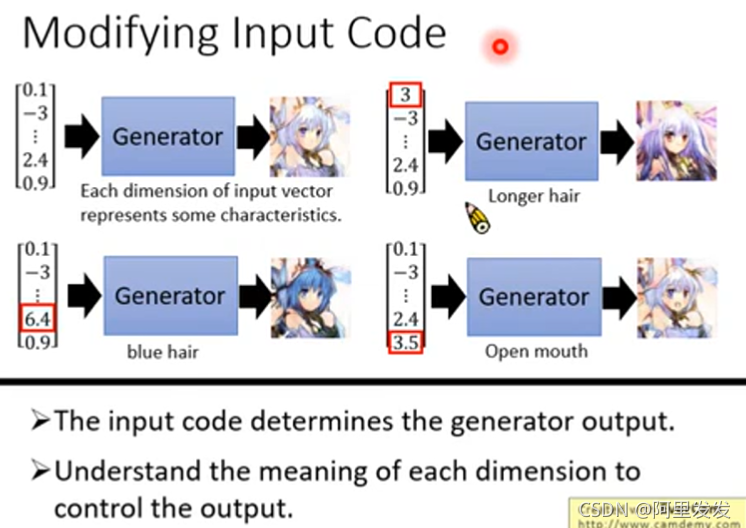
我们如果能知道每个维度对应图片哪个特征,就可以控制生成图片的输出。
具体实现
1.GAN+Autoencoder
? We have a generator (input z, output x)
通常我们可以训练一个generator,通过随机向量z来生成图片x

? However, given x, how can we find z?
从图片x中可以得到相应的特征标记,例如:头发颜色,头发浓密,胡子,性别,皮肤颜色、笑的表情等,如果我们能知道是什么样的z生成的x,就可以吧x中的某些维度和图片的特征联系起来。
? Learn an encoder (input x, output z)
要知道z,就是要训练一个Encoder ,输入一张图片x,得到z,z经过上图中的Generator后可以还原回图片x。典型的Autoencoder结构:
、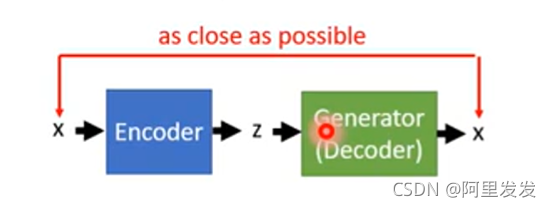
训练Encoder的时候,由于是要反推z,所以这里Generator中的参数是固定不变的。由于Encoder在上图中和Discriminator的功能相似,所以在实际计算的时候,可以用Discriminator来对Encoder进行初始化。
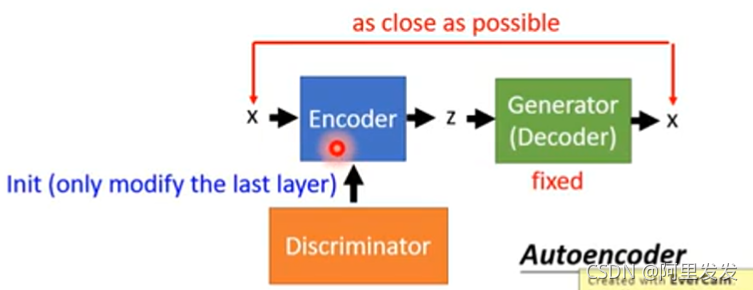
2.Attribute Representation
完成上面的工作,我们就训练好了一个Encoder,这个Encoder可以把图片还原为一个向量。也就是用这个Encoder可以找到生成某个图片的向量。
接下来把数据库中的图片整出来:
丢到Encoder中,得到这些图片对应的向量(注意蓝色和绿色的点就是向量)

对于左边的图片是长发,右边是短发,把两簇向量取平均后得到长短发的代表,然后相减:
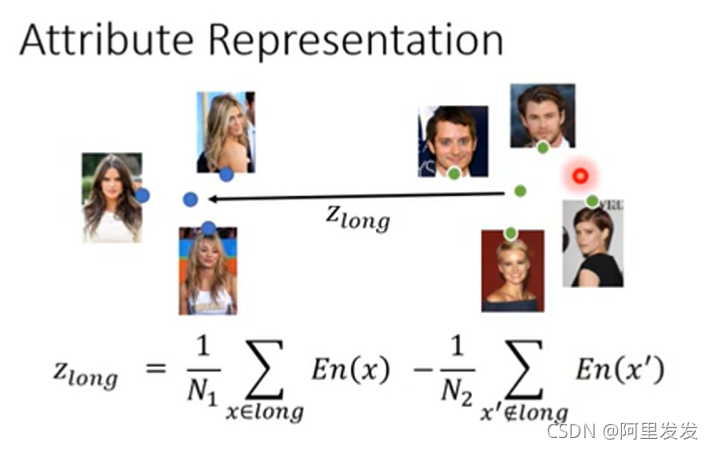
其中En是Encoder,long代表长发。如果现在有一张短发的图片x,我们可以通过下面的步骤把其变成长发:
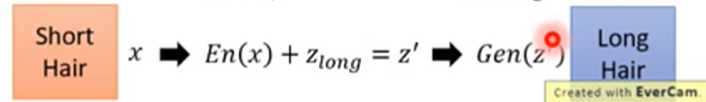

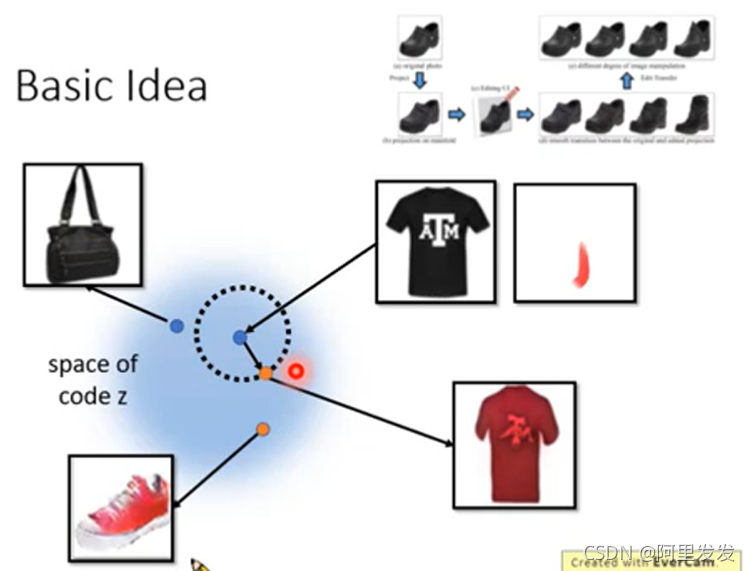
我们能找到生成商品图片的向量都是从z的向量空间中取的,那么如果我们将生成图片的z在一个小的范围内进行移动,这个商品的图片肯定不会变化太多,如果再加上编辑的约束,就会使得图片变成我们想要的样子。
Back to z
同样的,现在要考虑如何找到图片对应的code。
有三种方法:
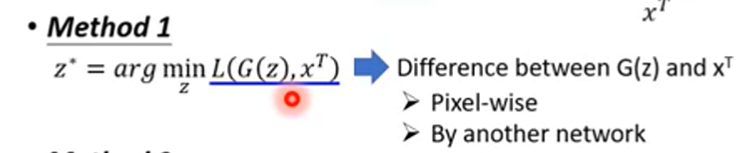
第一种
把寻找code的过程看做最优化的过程

第二种
就是本课中用的方法,训练一个Encoder来找z
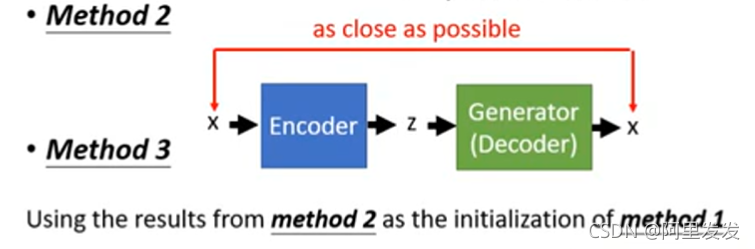
第三种
将第一种和第二种方法相结合。
Using the results from method 2 as the initialization of method 1
这样可以避免GD过程中遇到局部最优点。
Editing Photos
可以找到图片对应的z之后,我们继续来看如何进行编辑,假设现在有一个图片(左边),和一个用户编辑的约束(右边):

其中第一项:U代表用户做的编辑约束,这里要使得图片尽量的满足用户的编辑约束,例如用户用的红色点了一下,生成的新图片就是要红色基调,这里如何定义一个图片满足某个约束的函数由我们自己来弄。
第二项:是使得新生成的图片不能脱离原图片太远。
第三项:使得新生成的图片越真实越好。
其他应用
高清图片处理Image super resolution
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi, “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”, CVPR, 2016

左一传统处理方法:不行
左二普通NN处理:效果可以,但是头饰,项圈细节还是模糊
左三GAN:效果可以,头饰,项圈细节清晰,但是这些细节和原图不一样,因为这些细节是GAN模型自己生成的,只要能骗过discriminator即可。
最后是原图
这个模型的数据比较好处理,就是找一堆高清图,处理模糊后就有数据了,因为图片清晰变模糊好弄。
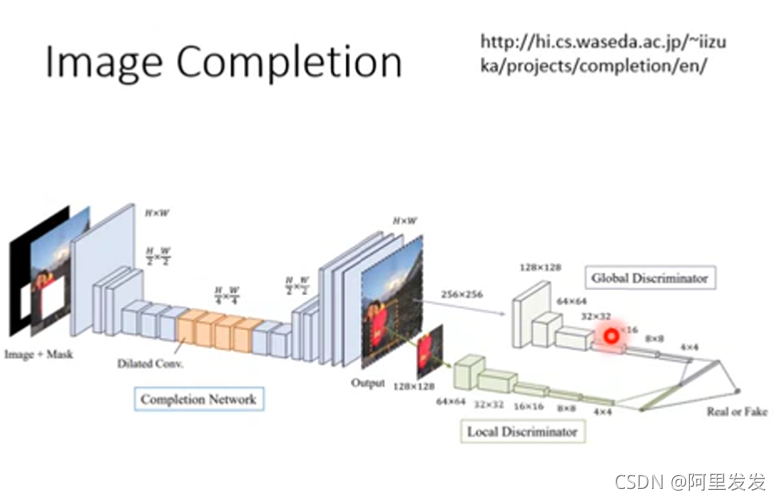
图像补全Image Completion
这个模型的训练数据也好处理,随便找图片,然后挖空就有了。