第一篇3d检测博客,尽量做的详细。
一 核心思路
文章称该方法把point-based和voxel-based两种方法的优势结合起来,提高了3D目标检测的表现。基于体素的操作可以高效的编码多尺度特征表示并生成高质量3D提案框,基于point操作有可变的感受野故可以保留更精确的位置信息。
voxel-based(grid)优缺点:高效、但信息损失降低定位细粒度的精度(fine grained localization accuracy)
point-based优缺点:计算成本高、但可以得到更大的感受野(by the point set abstraction)

二 核心步骤

2.1 3D Voxel CNN 高效特征编码以及proposal生成

这一步的具体流程就是上图所示,是在原始点云中进行处理的,3D voxel CNN把场景划分为L×W×H的体素,非空体素的特征为点特征的均值(x,y,z,r)。
3D proposal生成把8倍降采样后的3D特征体(volume,其实就是特征向量的集合)转换成2D BEV features map,用基于anchor的方法生成提案框。每个类有2 ×L/8 × W/8个提案框(采用标签的平均尺寸)以及对于每一个BEV像素,评价两个anchor的0-90°的方向。此方法有更高的召回率。
作者在3D Voxel CNN中讨论到,目前2-stage的框架需要pooling ROI来优化提案,但8倍下采样使空间分辨率很低,如果上采样得到更大尺寸的特征体/图,便会很稀疏。在传统RoI pooling或ROI align的时候通常会用双线性插值,这就使得在3D稀疏的表达上可能得到几乎都是0的特征表示。
PointNet系列提出的set abstraction操作可在可变邻域上编码点特征,由此提出了整合3D voxel CNN和一系列set abstrction操作。具体做法为先将整个场景不同神经层的体素编码成少量的关键点,然后将关键点特征聚合到RoI网格中,以进行propoal的细化。
(set abstraction操作:(1)取样用最远点采样FPS(2)grouping构建局部特征,不用KNN而用query ball(3)用pointnet提取局部特征)
2.2 Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
整体结构下图所示,分为关键点抽样、Voxel Set Abstraction Module、扩展VSA模块以及关键点权重预测。

?2.2.1 Keypoints Sampling
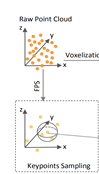
?在Voxel-to-Keypoint的结构中,首先是keypoints采样,具体做法是采用FPS算法,在原始点云P上采样出n个点(KITTI: n=2048; Waymo: n=4096)K={p1,…,pn}。
?2.2.2 Voxel Set Abstraction Module
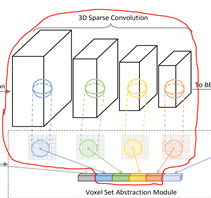
?
?2.2.3 Extended VSA Module

?2.2.4 Predicted Keypoint Weighting
?
?
?2.3 Keypoint-to-grid RoI Feature Abstraction for Proposal Refinement
?对3D voxel CNN产生的每一个3D提案(RoI),用每个RoI的特征由多尺度关键点特征聚合而成进行框优化。由此提出了keypoint-to-grid RoI feature abstraction模块,如下图所示。

?这个模块主要分为ROI-grid Pooling和3D框优化和置信度预测两个步骤。
?2.3.1 ROI-grid Pooling via Set Abstraction

?
?2.3.2 3D Proposal Refinement and Confidence Prediction

?
?2.4 Training Loss
?
三 总结
本作者提出来一个全新的融合Voxel和Point-based的方法,进一步提升了准确度,在KITTI上刷榜的存在,后续需继续阅读代码。
别人总结:
PointRCNN完全使用PointNet++做特征提取的module,包括RPN中的backbone和RCNN中的特征提取部分。
STD相比于PointCNN,加入了RoI-grid的部分。由于RCNN中使用voxel表示的,RCNN中的特征提取也变成了3D Convolution。
Part-A2Net,相比于STD,一开始就是用Voxel的表示方法,将RPN中的主干网络也换成3D Convolution。(当然还有提出了Part location的表示等等)抛开细节的特征表示不谈,我认为其实Part-A2Net就是本文中朴素的想法。
PV-RCNN解决了本文提出的Part-A2Net计算效率低的问题。
参考文献:
https://blog.csdn.net/weixin_40805392/article/details/103840540
https://blog.csdn.net/wqwqqwqw1231/article/details/104250027
https://blog.csdn.net/qq_42305950/article/details/104640838
Shi S ,? Guo C ,? Jiang L , et al. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020.