大家好,我技术人Howzit,这是深度学习入门系列第九篇,欢迎大家一起交流!
深度学习入门系列1:多层感知器概述
深度学习入门系列2:用TensorFlow构建你的第一个神经网络
深度学习入门系列3:深度学习模型的性能评价方法
深度学习入门系列4:用scikit-learn找到最好的模型
深度学习入门系列5项目实战:用深度学习识别鸢尾花种类
深度学习入门系列6项目实战:声纳回声识别
深度学习入门系列7项目实战:波士顿房屋价格回归
深度学习入门系列8:用序列化保存模型便于继续训练
深度学习入门系列9:用检查点保存训练期间最好的模型
深度学习入门系列10:从绘制记录中理解训练期间的模型行为
待更新……
深度学习入门系列11:用Dropout正则减少过拟合
深度学习入门系列12:使用学习规划来提升性能
深度学习入门系列13:卷积神经网络
深度学习入门系列14项目实战:手写数字识别
深度学习入门系列15用图像增强改善模型性能
深度学习入门系列16:图像中对象识别项目
深度学习入门系列17项目实战:从电影评论预测情感
深度学习入门系列18:递归神经网络
通过观察训练期间的性能变化,你能更好了解神经网络和深度学习模型。在这节课中,你将学习在python中如何用Keras审视和可视化深度学习模型的性能。完成这节课后,你将了解:
- 如何检查训练期间收集的历史记录指标。
- 如何绘制训练集和验证集的准确率指标。
- 如何绘制训练和验证数据集上的模型损失指标。
10.1 Keras中查看模型训练历史记录
Keras训练深度学习模型时,提供了注册回调的能力,默认注册的回调之一是History回调。如果设置了,它记录了每次迭代训练指标,包括误差和精度(对于分类问题),对于验证集也是如此。
这个历史记录对象在调用fit() 函数时返回,这个函数在训练模型中使用。指标被存在字典中,返回的对象中包含历史记录。举个例子,在完成训练模型之后,你可以使用下面一段代码列出历史记录对象中的所收集的指标。
# list all data in history
print(history.history.keys())
举个例子,对于一个用验证集在分类问题上的模型,可能会得到下面这个结果:
['loss', 'acc', 'val_loss', 'val_acc']
我们能使用历史记录对象中收集的数据来创建图表。这个图标能为训练的模型提供有用的启示,例如:
- 迭代的收敛速度
- 这个模型是否已经收敛了(线稳定)。
- 模型是否在训练集上过度学习(验证线的变化)。
等等
10.2 在Keras中可视化训练模型记录
我们能从收集历史数据中创建图表。在下面这个例子,我们创建一个小的网络来建模pima糖尿病二分类问题。例子中收集了训练模型中返回历史数据并创建两个图表:
- 在训练集和验证集上准确率的图表。
- 在训练集和验证集损失的图表
# Visualize training history
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, activation= "relu" ))
model.add(Dense(8, activation= "relu" ))
model.add(Dense(1, activation= "sigmoid" ))
# Compile model
model.compile(loss= "binary_crossentropy" , optimizer= "adam" , metrics=[ "accuracy" ])
# Fit the model
history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history[ "accuracy" ])
plt.plot(history.history[ "val_accuracy" ])
plt.title( "model accuracy" )
plt.ylabel( "accuracy" )
plt.xlabel( "epoch" )
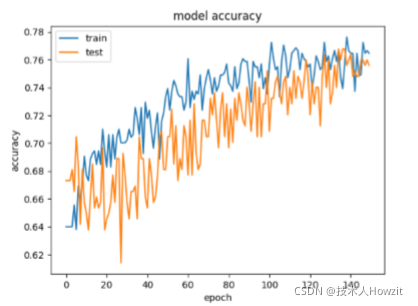
绘制图如下。验证数据集的历史记录按照惯例标记为test,因为它确实是模型的测试数据集。从准确性图可以看出,由于在最后几个时期两个数据集的准确性趋势仍在上升,因此可以对模型进行更多的训练。我们还可以看到,该模型尚未过度学习训练数据集,从图中可以看出在两个数据集上配置相当。
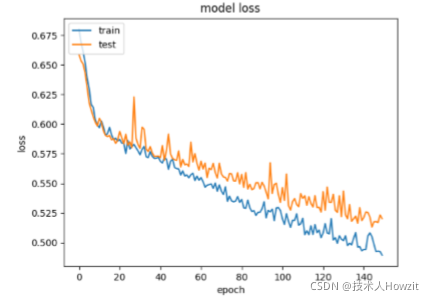
从损失图,我们能看到模型在训练集和验证集(标记为测试)上有可相当的性能。如果这些平行图开始一致偏离,则可能是在较早时期停止训练的信号。
10.3 总结
这节课,你已经发现了收集和复盘你的深度学习训练指标的重要性。你已经学到:
- 如何从训练中检查History对象,并学习已经收集的指标。
- 如何针对训练集和验证集提取准确率信息并绘制数据。
- 如何提取和绘制来自训练集和验证集的损失信息。
10.3.1 接下来
一个简单又强大的技术用于减少模型过拟合,称之为dropout。在接下来课程中你将学习Dropout技术,如何将它应用在Keras中的显示层和隐藏层,最好的实践就是在你的问题上应用它。