目标检测之Mask R-CNN:小白动手实现项目Pytorch
引言
- 首先声明本项目的运行环境。操作系统为Windows,编写环境为Anaconda3 + Jupyter Notebook。Pytorch版本为 torch 1.7.1+cu110 、torchvision版本为 0.8.2+cu110,cuda版本为cu100,显卡为Nvidia 2060。
- 我是目标检测领域的小白,刚刚完成了Pytorch的相关入门学习任务,所以我认为学习本篇博客的基础要求是:熟练的python技巧、初步接触Pytorch、了解基本tensor运算以及卷积网络的知识。
- 本篇博客的代码部分并非全部原创,对领域小白来说自己搭建框架,寻找合适的模型和数据集都比较困难,因此我参照Pytorch官方文档来进行学习。我会尽力针对每一句代码书写自己的理解,写博客的目的是帮助自己整理思路同时也能给志同道合的初学者们一点点经验建议。
- 本博客参照的Pytorch官方文档为:Mask R-CNN项目官方文档
- 简单叙述一下本项目的主要内容:PennFudanPed是一个搜集行人步态信息的数据集,我们想要通过训练模型实现检测图像中的人物,不仅仅局限于边界框检测,我们想要针对每个检测人物生成掩码图片,进而分割图像。我们采用 Mask R-CNN模型来完成这一工作。

Mask R-CNN原理简述
- 目标检测领域的深度学习算法可以分为两类,一阶段算法代表为YOLO,二阶段算法代表为R-CNN。阐述一下二阶段算法和一阶段算法的区别,二阶段算法首先生成候选区域(提议区域),然后针对候选区域进行筛选和预测。一阶段算法并没有单独的步骤用来生成候选区域,而是将候选区域的生成、筛选与预测同步进行。
- R-CNN 中文名字是区域提议卷积网络,其发展大体经历了R-CNN、Fast R-CNN、Faster R-CNN到Mask R-CNN的过程。每一种新模型都是在旧模型的基础上优化改善而得。总体来说优化的目的都是在于,提高模型的计算速度,以及优化模型的计算精读。
- R-CNN大体经过了以下步骤:1.通过选择性搜索算法得到大量提议区域。2.针对每一个提议区域使用卷积网络提取特征,计算特征图。3.针对每一个特征图训练SVM实现类别预测。4.针对每一个特征图训练边框回归,实现边框坐标偏移量预测。
- Fast R-CNN针对于R-CNN中存在的大量卷积计算进行了优化。Fast R-CNN首先针对全图进行卷积网络特征提取,然后同样使用选择性搜索算法生成大量提议区域,使用RoIPooling算法针对每一个提议区域从全图特征中挑选特征值,并调整维度。标签值与偏移量的预测与R-CNN相同。
- Faster R-CNN针对提议区域的生成方式进行了修改。Faster R-CNN采用RPN网络的方式生成提议区域,接受全图特征图作为输入,筛选提议区域,极大减少了提议区域的生成数量。
- Mask R-CNN为了实现像素级别的分类进行了优化。使用RoIAlign代替RoIPooling,将多尺寸提议区域进行特征对齐,原RoIPooling算法无法支持高精度的像素级别的图像分类。除了标签值和边界框偏移量的预测以外,单独开设一个分支通过全卷积网络实现像素级别分类。
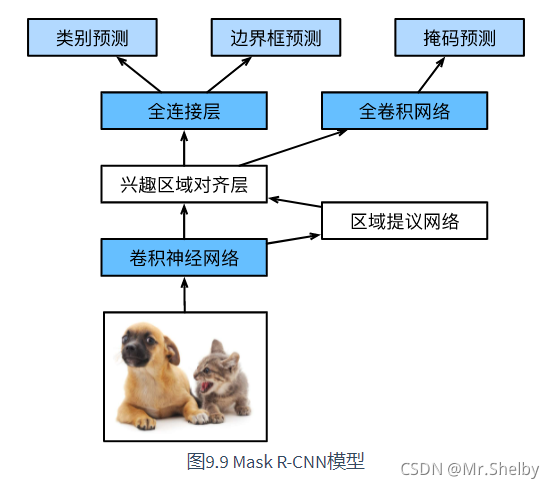
代码、注释及详细解释
1.安装COCOAPI(pycocotools)
- Linux操作系统下COCOAPI的安装十分简单,具体方法百度即可。因此大部分的深度学习模型与平台也都部署在Linux系统下。
- Windows操作系统的设计目的就是为了让更多的计算机非专业人士能够更简单直接地操作计算机,而针对于计算机从业人员来说,Linux系统有其独特地优势是我们绕不开地话题。
- 言归正传COCOAPI在Windows系统下安装需要进行一些特殊操作。具体内容请见CSDN博客在 Windows 下安装 COCO API(pycocotools)
2.下载PennFudan数据集
3.初步查看数据集图片
- 注意第一点的是,本博客中所有路径都需要更改成自己的路径。具体方法只需要建立对应文件夹,存放好数据集和图片即可。本文均采用绝对路径,有关绝对路径与相对路径的区别请自行学习。
- Image.open()读取的图片有多种模式,每种模式有不同的作用并且拥有相对应可调用的函数,这里也不做赘述,感兴趣的可以自行查阅。下面代码中读取的mask默认为“L”模式,需要转换为“P”模式才可以调用调色板函数putpalette()。
- 我们对掩码图片进行一下了解。普通图片的矩阵元素是一个RGB数值,当然有三个通道。而掩码图片的矩阵元素是0,1,2,3…的类别序号。掩码矩阵可以理解为像素级别的分类结果,如果掩码图片上实体只有一个那么就是二色掩码图,矩阵元素只有0(背景)、1(实体);下图所示的掩码图片实体不唯一,那么就是多色掩码图。掩码图片可能有三个通道也可能只有一个通道,具体情况请.shape分析一下。
from PIL import Image
Image.open(r'C:\Users\HP\Anaconda3\envs\pytorch\data\PennFudanPed\PNGImages\FudanPed00001.png')
mask = Image.open(r'C:\Users\HP\Anaconda3\envs\pytorch\data\PennFudanPed\PedMasks\FudanPed00001_mask.png')
mask = mask.convert("P")
mask.putpalette([
0, 0, 0,
255, 0, 0,
255, 255, 0,
255, 153, 0,
])
mask

4.编写针对PennFudan的数据集类
- 我们知道深度学习的训练函数,一般是接受DataLoader的实例作为输入,而DataLoader则需要接受自定义的数据集类实例作为输入。因此本章节就用来完成数据集接口的编写。
- PennFudanDataset类一共有三个函数,四个属性。首先介绍四个属性,self.root是根路径,后面跟上训练集或测试集的文件夹便可以得到最终路径,无论是训练集还是测试集,都需要变形参数self.transforms,也都有普通图片self.img和掩码图片self.masks。
- 三个函数中重点在于__getitem__()函数。该函数的功能是根据图片编号,获得对应的图片信息。该函数需要返回两个变量:

import os
import torch
import numpy as np
import torch.utils.data
from PIL import Image
class PennFudanDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def __getitem__(self, idx):
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = Image.open(img_path).convert("RGB")
mask = Image.open(mask_path)
mask = np.array(mask)
obj_ids = np.unique(mask)
obj_ids = obj_ids[1:]
masks = mask == obj_ids[:, None, None]
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["masks"] = masks
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
5.测试数据集接口
- 测试结果如下图所示,完全符合上一环节介绍的返回格式。我们可以对照下面的结果图再加深一下对这些变量的认识(包括含义及维度)。
dataset = PennFudanDataset(r'C:\Users\HP\Anaconda3\envs\pytorch\data\PennFudanPed/')
dataset[0]

6.Faster R-CNN模型的两种定义方式
- 第一种模型定义方式是FineTuning(微调)。这是一种深度学习中常用的方法,适用于本问题的数据集太少无法支持大规模模型的训练,因此我们使用在其他大型数据集上预训练的模型,通过修改最后几层来解决自己的问题。下面这段代码采用在COCO数据集上预训练的RESNET50模型,然后将最后的预测器部分修改为FastRCNNPredictor。
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 2
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
- 第二种模型定义方法是通过替换现有Faster R-CNN框架的骨干网络部分实现。骨干网络部分指的是深度学习模型中的特征提取部分,深度学习模型可以分为特征提取部分+预测器部分。默认的骨干网络RESNET50可能对于大部分数据集来说参数过多,模型过于复杂,不易部署并且容易过拟合,因此采用替换骨干网络部分的方法可以使模型更适合本问题。
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
backbone.out_channels = 1280
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
7.定义本项目Mask R-CNN模型
- Mask R-CNN模型是在Faster R-CNN模型的基础上改变得来,其中最大的改变就是添加了一个掩码mask的预测分支,独立于标签、边界框的预测。
- 本文实现Mask R-CNN模型采用的是上一章节的第一种方法――微调(FineTuning)。我们首先准备预训练模型,然后获取相应的预测器层的输入输出维度,将边界框预测器box_predictor和掩码预测器mask_predictor统统都换成适合于本问题维度的预测器。
- 通过观察我们可以发现,其实目前大部分的深度学习模型我们都可以进行调用,并不需要我们完成模型具体代码的书写。这一特点给我们提出了两大要求,第一是熟练掌握常用模型的调用方法以及修改方法,第二是同时也要了解模型的原理以及实现过程,以便于未来自己动手设计模型。
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_instance_segmentation_model(num_classes):
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model
8.下载references\detection工具包
- 搜索下载references\detection工具包,该工具包中还有很多目标检测相关的函数,比如模型评估函数、损失计算函数等等。
- 下载之后将工具包复制到该项目的依赖位置,我的依赖位置仅供参考C:\Users\HP\Anaconda3\envs\pytorch\Lib\site-packages。
9.定义函数实现获取变形参数
- 之前在生成一个PennFudanDataset实例时,我们需要传入变形参数,并且PennFudanDataset也有一个内部属性self.transforms。当前数据集实例用于训练还是测试,不同的应用环境决定了不同的变形参数。
- 无论是训练集还是测试集,读入的PIL图片都需要转换为Tensor格式才能参与计算,因此这一步都有。本实验数据集较为充分,因此只需要针对训练集进行简单的数据扩充即可,针对训练集加入随机水平翻转的变形参数,针对测试集则不需要。
- 数据扩充对于计算机视觉任务来说至关重要,可以起到扩充数据集、防止过拟合的效果,还可以过滤抵消掉图像中的无关信息,比如位置、方向等等。数据扩充的方式有很多种,水平翻转、垂直翻转、裁剪、缩放、改变颜色等等。有兴趣的同学可以详细研究一下。
import utils
import transforms as T
from engine import train_one_epoch, evaluate
def get_transform(train):
transforms = []
transforms.append(T.ToTensor())
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
10.设定参数、开始训练
- 这一步的运行我遇到了很多的困难,报错的截图我没有保存,但总结问题的原因就是,cuda、pytorch、torchvision版本不匹配。我的cuda安装的更早,采用的版本是cu100,后来安装了pytorch与torchvision,这两个包均采用的是最新的版本,三个版本之间的不匹配导致了错误。
- 最后查阅资料得知了可以正常使用的版本组合:cu110、torch1.7.1+cu110 、torchvision0.8.2+cu110。我将torch与torchvision均升级到了正确版本,但是cuda并没有改动,原因是cuda的卸载与安装十分麻烦。我抱着试试看的心态运行了一下代码,没想到运行成功了,看来以上版本也可以适配cu100,不过初学者第一次安装配置环境还是最好安装上述版本。
dataset = PennFudanDataset(r'C:\Users\HP\Anaconda3\envs\pytorch\data\PennFudanPed/', get_transform(train=True))
dataset_test = PennFudanDataset(r'C:\Users\HP\Anaconda3\envs\pytorch\data\PennFudanPed/', get_transform(train=False))
torch.manual_seed(1)
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-50])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:])
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=0,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=0,
collate_fn=utils.collate_fn)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
num_classes = 2
model = get_instance_segmentation_model(num_classes)
model.to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
- 训练过程可能会长达5-10分钟(具体时间由电脑性能决定)。在第一次完成训练之后,我们将need_training变量调为False,这样就不需要每次都训练了。后续我们会将模型存储,每次使用之前只需要载入模型即可。
need_training = True
num_epochs = 10
if need_training == True:
for epoch in range(num_epochs):
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
lr_scheduler.step()
evaluate(model, data_loader_test, device=device)
11.存储并加载训练好的模型
- 模型的训练归根结底还是训练的参数,因此模型的保存根本上也就是保存训练好的模型参数的值。保存模型,下次使用的时候加载模型即可。
PATH = r"C:\Users\HP\Anaconda3\model\mask2.pt"
if need_training == True:
torch.save(model, PATH)
else:
model = torch.load(PATH)
12.测试掩码预测功能
- 测试集共50张图片,通过之前定义的数据集类和数据集读取类,我们可以实现通过索引读取图片。
PATH = r"C:\Users\HP\Anaconda3\model\mask2.pt"
model2 = torch.load(PATH)
img2, _ = dataset_test[30]
model2.eval()
with torch.no_grad():
prediction = model2([img2.to(device)])
- 读取出的图片是Tensor格式。mul(255)是为了将0-1的相对RGB数值调整到0-255。permute(1,2,0)是将三个维度调整,也就是将通道维调整到最后一位。byte()是将单个元素的类型调整为unit8。最后将Tensor格式的数值调整为numpy,调用Image.fromarray()即可读取numpy格式的RGB数值,从而显示图片。
Image.fromarray(img2.mul(255).permute(1, 2, 0).byte().numpy())
- 有关预测结果prediction的具体内容,这个是由我们模型设定的MaskRCNNPredictor决定的,网上相关介绍较少我们只能通过打印中间值的方式来简单学习了解。prediction是一个列表,每一个元素代表一个实体种类,由于本项目实体只有一种person,因此列表元素只有一个。prediction[0]是一个字典,内部包含字段masks、scores、boxes、labels。prediction[0][‘mask’][0,0]是一个二维矩阵,其中[0,0]中第一个0表示本张图片的第一个掩码,第二个0表示第一个通道(在这里掩码只有一个通道)。之后的操作与上面相同,唯一不同的是调用cpu()将变量转到cpu设备上。
Image.fromarray(prediction[0]['masks'][0, 0].mul(255).byte().cpu().numpy())

13.使用掩码截取图片
- 接下来的部分就属于我自己的探索部分,学习本项目的目的是为了实现将一张图片中的所有人物识别并单独抠出来。因此接下来我们在原图片和掩码图片的基础上,生成切片图片。
- 实现该功能需要用到opencv的工具包cv2,下载安装方法与之前相同,同学们需要自行完成。下面的代码我们简单测试一下功能。
- 本项目的掩码图片只有两种元素0或1,0就代表黑色,1就代表透明。因此根据掩码生成切片图片,实际上就是原图片和掩码图片之间做“与”操作,掩码图片的0将原图片RGB数值置为0,掩码图片的1不改变原图片的RGB数值。
- 发现了一个很有意思的现象,一开始读取的原图片色彩都是偏蓝的,明显不是正常的图片效果。研究后发现,正常图片的通道顺序是RGB,而cv2的读取顺序是BGR,因此需要进行一步交换通道顺序的操作。
import cv2
a = cv2.imread(r'C:\Users\HP\Anaconda3\envs\pytorch\img\catdog.jpg', 1)
b = np.zeros(a.shape, dtype=np.uint8)
b[10:100, 20:200] = 255
a = cv2.cvtColor(a,cv2.COLOR_BGR2RGB)
c = cv2.bitwise_and(a, b)
cv2.imwrite('b.jpg', b)
cv2.imwrite('c.jpg', c)
Image.fromarray(a)
Image.fromarray(b)
Image.fromarray(c)

- 下面使用本项目获得的掩码以及原图片进行测试,需要注意的是我们需要将读取到的PIL图片转为numpu格式并且将其通道顺序调整为BGR。我们获得的掩码只有一个通道,而bitwise函数默认将同维度的原图片和掩码图片进行与操作,因此我们需要将掩码图片拓展为三个通道。
cur_img = img2.mul(255).permute(1, 2, 0).byte().numpy()
cur_img = cv2.cvtColor(cur_img,cv2.COLOR_RGB2BGR)
cur_mask = prediction[0]['masks'][0,].mul(255).byte()
cur_mask = torch.cat((cur_mask, cur_mask, cur_mask), axis = 0)
cur_mask = cur_mask.permute(1,2,0)
cur_mask = cur_mask.cpu().numpy()
cur_cut = cv2.bitwise_and(cur_img, cur_mask)
cv2.imwrite(r'C:\Users\HP\Anaconda3\envs\pytorch\img\cur_mask.jpg', cur_mask)
cv2.imwrite(r'C:\Users\HP\Anaconda3\envs\pytorch\img\cur_cut.jpg', cur_cut)

14.将黑底切片图片转换为透明背景PNG图片
- 在得到黑底切片图片之后,进一步我们想获得透明背景的PNG图片(注意:透明背景图片格式必须是PNG)。
- 最终结果显示大体功能实现了,但透明背景图片的边缘过于模糊,还需要未来进一步调整细化。
def transparent_back(img):
img = img.convert('RGBA')
L, H = img.size
color_0 = img.getpixel((0,0))
for h in range(H):
for l in range(L):
dot = (l,h)
color_1 = img.getpixel(dot)
if color_1 == color_0:
color_1 = color_1[:-1] + (0,)
img.putpixel(dot,color_1)
return img
img=Image.open(r'C:\Users\HP\Anaconda3\envs\pytorch\img\cur_cut.jpg')
img=transparent_back(img)
img.save(r'C:\Users\HP\Anaconda3\envs\pytorch\img\cur_cut_new.png')

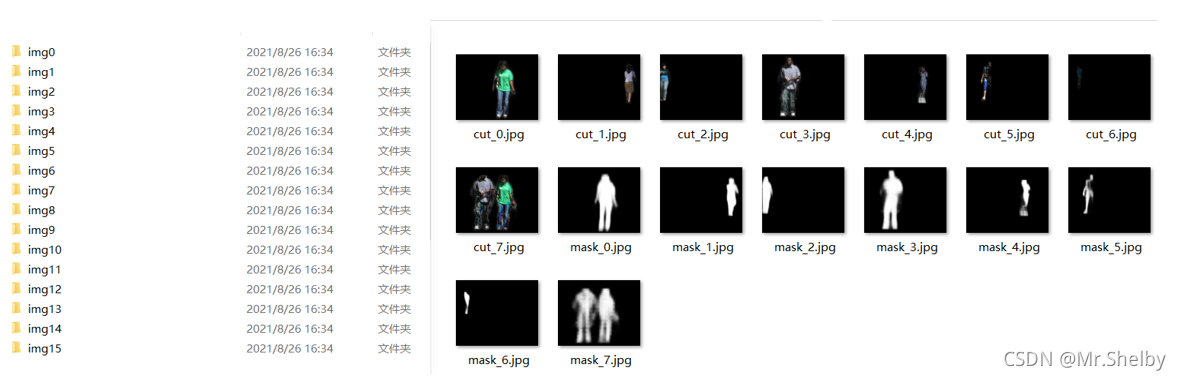
15.将测试集的所有图片全转换为一张掩码图片+一张黑底图片
PATH = "C:\\Users\\HP\\Anaconda3\\envs\\pytorch\\img\\pennfudan\\"
img=Image.open(r'C:\Users\HP\Anaconda3\envs\pytorch\img\cur_cut.jpg')
img=transparent_back(img)
mydir = PATH + 'img'+ str(1)
if not os.path.exists(mydir):
os.makedirs(mydir)
filename= '\cur_cut_' + str(1) + '.png'
img.save(mydir + filename)
num_test = len(dataset_test)
model.eval()
for i in range(num_test):
img, _ = dataset_test[i]
cur_dir = PATH + 'img' + str(i)
if not os.path.exists(cur_dir):
os.makedirs(cur_dir)
with torch.no_grad():
prediction = model([img.to(device)])
num_masks = prediction[0]['masks'].shape[0]
for j in range(num_masks):
cur_mask = prediction[0]['masks'][j,].mul(255).byte()
cur_mask = torch.cat((cur_mask, cur_mask, cur_mask), axis = 0)
cur_mask = cur_mask.permute(1,2,0)
cur_mask = cur_mask.cpu().numpy()
cur_img = img.mul(255).permute(1, 2, 0).byte().numpy()
cur_img = cv2.cvtColor(cur_img,cv2.COLOR_RGB2BGR)
cur_cut = cv2.bitwise_and(cur_img, cur_mask)
mask_name = '\mask_' + str(j) + '.jpg'
cv2.imwrite(cur_dir + mask_name, cur_mask)
cut_name = '\cut_' + str(j) + '.jpg'
cv2.imwrite(cur_dir + cut_name, cur_cut)
|