Ŀ¼
- ǰ��
- 0��������Ҫ�İ��ͻ�������
- 1���������
- 2��create_dataloader
- 3���Զ���DataLoader
- 4��LoadImagesAndLabels
- 5��img2label_paths
- 6��verify_image_label
- 7��load_image
- 8��augment_hsv
- 9��load_mosaic��load_mosaic9
- 10��random_perspective
- 11��box_candidates
- 12��replicate
- 13��letterbox
- 14��cutout
- 15��mixup
- 16��LoadImages��LoadStreams��LoadWebcam
- 17��hist_equalize
- 18��create_folder
- 19��flatten_recursive
- 20��extract_boxes
- 21��autosplit
- 22��dataset_stats
- �ܽ�
ǰ��
Դ��: YOLOv5Դ��.
����: ��YOLOV5-5.x Դ�뽲�⡿������Ŀ�ļ�����.
ע�Ͱ�ȫ����Ŀ�ļ����ϴ���GitHub: yolov5-5.x-annotations.
����ļ���Ҫ�ǽ���������ǿ������
0��������Ҫ�İ��ͻ�������
import glob # python�Լ�����һ���ļ��������ģ�� ���ҷ����Լ�Ŀ�ĵ��ļ�(��ģ��ƥ��)
import hashlib # ��ϣģ�� �ṩ�˶��ְ�ȫ�����hash����
import json # json�ļ�����ģ��
import logging # ��־ģ��
import math # ��ѧ��ʽģ��
import os # �����ϵͳ���н�����ģ�� �����ļ�·�������ͽ���
import random # ���������ģ��
import shutil # �ļ��С�ѹ��������ģ��
import time # ʱ��ģ�� ���ײ�
from itertools import repeat # ����ģ��
from multiprocessing.pool import ThreadPool, Pool # ���߳�ģ�� �̳߳�
from pathlib import Path # Path��strת��ΪPath���� ʹ�ַ���·�����ڲ�����ģ��
from threading import Thread # ���̲߳���ģ��
import cv2 # opencvģ��
import numpy as np # numpy�������ģ��
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt # matplotlib��ͼģ��
import torch # PyTorch���ѧϰģ��
import torch.nn.functional as F # PyTorch�����ӿ� ��װ�˺ܶ�������ػ��Ⱥ���
import yaml # yaml�ļ�����ģ��
from PIL import Image, ExifTags # ͼƬ���������ģ��
from torch.utils.data import Dataset # �Զ������ݼ�ģ��
from tqdm import tqdm # ������ģ��
from utils.general import check_requirements, check_file, check_dataset, xywh2xyxy, xywhn2xyxy, xyxy2xywhn, \
xyn2xy, segment2box, segments2boxes, resample_segments, clean_str
from utils.torch_utils import torch_distributed_zero_first
# Parameters
help_url = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
img_formats = ['bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng', 'webp', 'mpo'] # acceptable image suffixes
vid_formats = ['mov', 'avi', 'mp4', 'mpg', 'mpeg', 'm4v', 'wmv', 'mkv'] # acceptable video suffixes
num_threads = min(8, os.cpu_count()) # ������̸߳���
logger = logging.getLogger(__name__) # ��ʼ����־
1���������
\qquad �ⲿ��������������,��ʹ���������ʱ�Ż�ʹ�á�
# �������
# Get orientation exif tag
# ר��Ϊ�����������Ƭ���趨 ���Լ�¼������Ƭ��������Ϣ����������
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == 'Orientation':
break
def get_hash(paths):
# �����ļ��б���hashֵ
# Returns a single hash value of a list of paths (files or dirs)
size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
h = hashlib.md5(str(size).encode()) # hash sizes
h.update(''.join(paths).encode()) # hash paths
return h.hexdigest() # return hash
def exif_size(img):
# ��ȡ���������ͼƬ������Ϣ �����ж��Ƿ���Ҫ��ת(����������Զ�Ƕ�����)
# Returns exif-corrected PIL size
s = img.size # (width, height)
try:
rotation = dict(img._getexif().items())[orientation]
if rotation == 6: # rotation 270
s = (s[1], s[0])
elif rotation == 8: # rotation 90
s = (s[1], s[0])
except:
pass
return s
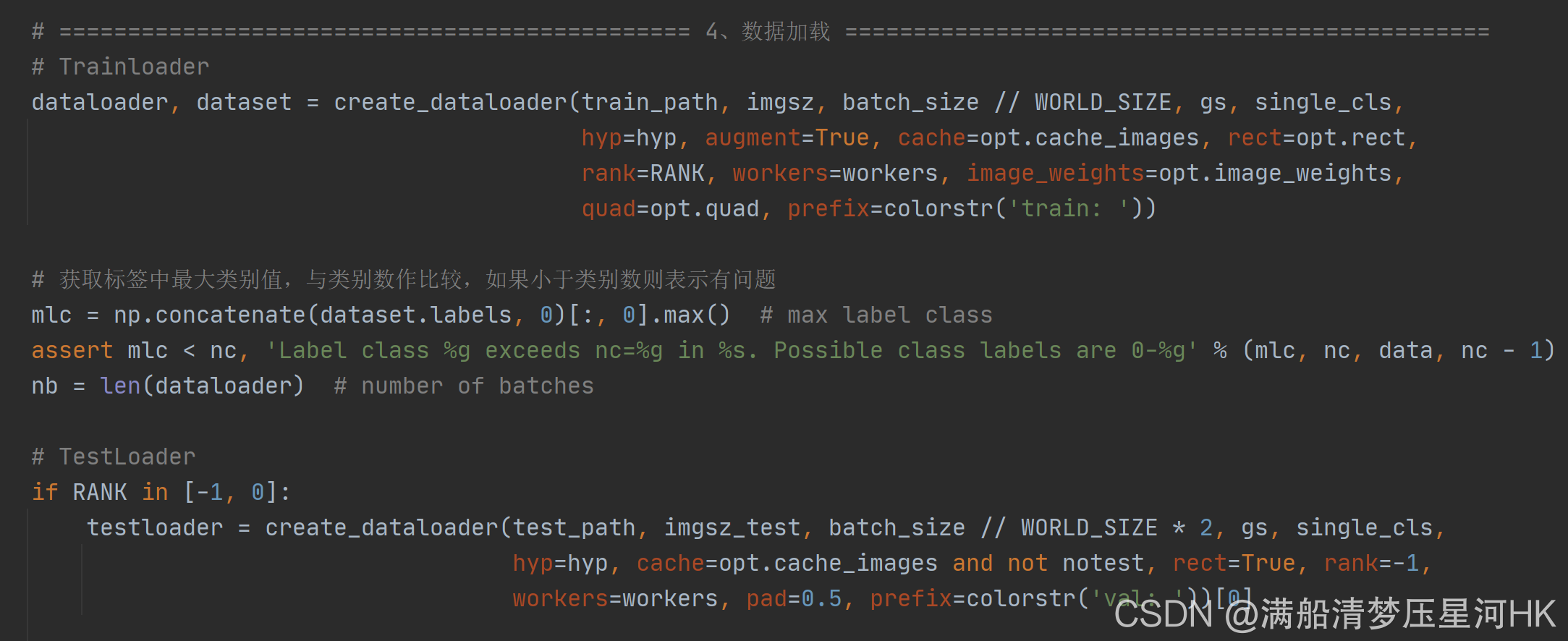
2��create_dataloader
\qquad �Զ���dataloader����: ����LoadImagesAndLabels��ȡ���ݼ�dataset(����������ǿ) + ���÷ֲ�ʽ������DistributedSampler + �Զ���InfiniteDataLoader �������ó����IJ������� + ��ȡdataloader���ؼ�������LoadImagesAndLabels(),����ļ��ĺ������д��붼��Χ�����ģ����еġ�
create_dataloaderģ�����:
def create_dataloader(path, imgsz, batch_size, stride, single_cls=False,
hyp=None, augment=False, cache=False, pad=0.0, rect=False,
rank=-1, workers=8, image_weights=False, quad=False, prefix=''):
"""��train.py�����,��������Trainloader, dataset,testloader
�Զ���dataloader����: ����LoadImagesAndLabels��ȡ���ݼ�(����������ǿ) + ���÷ֲ�ʽ������DistributedSampler +
�Զ���InfiniteDataLoader �������ó����IJ�������
:param path: ͼƬ���ݼ���·�� train/test ��: ../datasets/VOC/images/train2007
:param imgsz: train/testͼƬ�ߴ�(������ǿ���С) 640
:param batch_size: batch size ��С 8/16/32
:param stride: ģ�����stride=32 [32 16 8]
:param single_cls: ���ݼ��Ƿ��ǵ���� Ĭ��False
:param hyp: �����б�dict ����ѵ��ʱ��һЩ������,����ѧϰ�ʵ�,������Ҫ�õ�����һЩ����������ǿ(��ת��ƽ�Ƶ�)��ϵ��
:param augment: �Ƿ�Ҫ����������ǿ True
:param cache: �Ƿ�cache_images False
:param pad: ���þ���ѵ����shapeʱ���е���� Ĭ��0.0
:param rect: �Ƿ�������train/test Ĭ��ѵ�����ر� ��֤������
:param rank: �ѵ��ʱ�Ľ��̱�� rankΪ���̱�� -1��gpu=1ʱ�����зֲ�ʽ -1�Ҷ��gpuʹ��DataParallelģʽ Ĭ��-1
:param workers: dataloader��numworks ��������ʱ��cpu������
:param image_weights: ѵ��ʱ�Ƿ����ͼƬ������ʵ��ֲ�Ȩ����ѡ��ͼƬ Ĭ��False
:param quad: dataloaderȡ����ʱ, �Ƿ�ʹ��collate_fn4����collate_fn Ĭ��False
:param prefix: ��ʾ��Ϣ һ����־,��Ϊtrain/val,������ǩʱ����cache�ļ����õ�
"""
# Make sure only the first process in DDP process the dataset first, and the following others can use the cache
# ������ʵ�����ݵ�Ԥ��ȡ������,Ȼ�������ӽ�����ӻ����ж�ȡ���ݲ�����һϵ�����㡣
# Ϊ��������ݵ�����ͬ��, yolov5����torch.distributed.barrier()����ʵ���������Ĺ�����
with torch_distributed_zero_first(rank):
# �����ļ�����(��ǿ���ݼ�)
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
batch_size = min(batch_size, len(dataset)) # bs
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, workers]) # number of workers
# �ֲ�ʽ������DistributedSampler
sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
# ʹ��InfiniteDataLoader��_RepeatSampler����DataLoader���з�װ, ����ԭD�ȵ�DataLoader, �ܹ����ó����IJ�������
loader = torch.utils.data.DataLoader if image_weights else InfiniteDataLoader
# Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
dataloader = loader(dataset,
batch_size=batch_size,
num_workers=nw,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
return dataloader, dataset
\qquad
�����������train.py�����,��������Trainloader, dataset,testloader:
3���Զ���DataLoader
\qquad ��image_weights=Falseʱ(������ͼƬ������ʵ��ֲ�Ȩ����ѡ��ͼƬ)�ͻ�������������� �����Զ���DataLoader,���г����Բ������������create_dataloaderģ���б����á�
class InfiniteDataLoader(torch.utils.data.dataloader.DataLoader):
""" Dataloader that reuses workers
��image_weights=Falseʱ�ͻ�������������� �����Զ���DataLoader
https://github.com/ultralytics/yolov5/pull/876
ʹ��InfiniteDataLoader��_RepeatSampler����DataLoader���з�װ, ����ԭ�ȵ�DataLoader, �ܹ����ó����IJ�������
Uses same syntax as vanilla DataLoader
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# ����_RepeatSampler���������
object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()
def __len__(self):
return len(self.batch_sampler.sampler)
def __iter__(self):
for i in range(len(self)):
yield next(self.iterator)
class _RepeatSampler(object):
""" Sampler that repeats forever
�ⲿ���ǽ��г�������
Args:
sampler (Sampler)
"""
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
yield from iter(self.sampler)
4��LoadImagesAndLabels
\qquad �����������������(������ǿ)����,Ҳ�����Զ������ݼ�����,�̳���Dataset,��Ҫ��д__init__,__getitem()__�ȳ���,����Ŀ����һ�㻹��Ҫ��дcollate_fn����������,��������������������������ǿ(��������)������֮�ء�
4.1��init
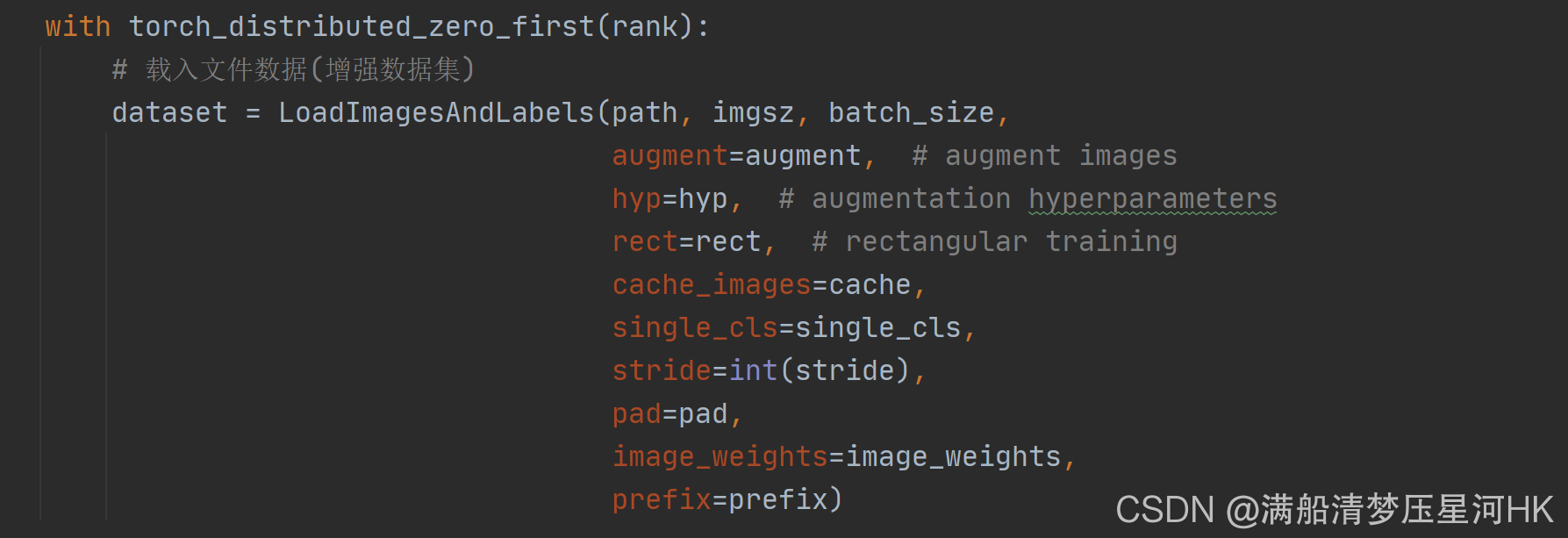
�������������������create_dataloader����:
\qquad
��ʵ��ʼ�����̲�û��ʲôʵ���ԵIJ���,������һ����������Ĺ���(self����),�Ա���__getitem()__�н���������ǿ����,�����ⲿ�ִ���ֻ��Ҫץסself�еĸ��������ĺ���������ˡ�
�ص��������º�ɫ���ִ���ʲô��˼
self.img_files: {list: N} ������������ݼ�ͼƬ�����·��
self.label_files: {list: N} ������������ݼ�ͼƬ�����·��
self.labels: ����ͼƬ������gt�����Ϣ
self.shapes: ����ͼƬ��shape
self.segments: ����ͼƬ�����еĶ����gt��Ϣ
self.batch: ������ÿ��ͼƬ�����ĸ�batch
self.n: ���ݼ�������ͼƬ������
self.indices: ����������ͼƬ��index
self.rect=Trueʱself.batch_shapes����ÿ��batch��shape(ͬһ��batch��ͼƬshape��ͬ),�ھ���ѵ��ʱ����
__init__��Ҫ����һ�¼�����:
- ��ֵһЩ������self���� ���ں�����__getitem__�е���
- �õ�path·���µ�����ͼƬ��·��self.img_files
- ����imgs·���ҵ�labels��·��self.label_files
- cache label
- Read cache ����self.labels��self.shapes��self.img_files��self.label_files��self.batch��self.n��self.indices�ȱ���
- ΪRectangular Training����: ����self.batch_shapes
- �Ƿ���Ҫcache image(һ�㲻��Ҫ,̫����)
__init__��������:
class LoadImagesAndLabels(Dataset):
# for training/testing
def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False,
image_weights=False, cache_images=False, single_cls=False, stride=32, pad=0.0, prefix=''):
"""
��ʼ�����̲�û��ʲôʵ���ԵIJ���,������һ����������Ĺ���(self����),�Ա���__getitem()__�н���������ǿ����,�����ⲿ�ִ���ֻ��Ҫץסself�еĸ��������ĺ����������
self.img_files: {list: N} ������������ݼ�ͼƬ�����·��
self.label_files: {list: N} ������������ݼ�ͼƬ�����·��
cache label -> verify_image_label
self.labels: ������ݼ�����ͼƬ��û��һ�������label labels�洢��label�Ͷ���ԭʼlabel(���������ľ���label)
��������ͼƬ����gt��label����labels ������gt(����һ�������)����segments2boxesת��Ϊ�����ľ���label
self.shapes: ����ͼƬ��shape
self.segments: ������ݼ�����ͼƬ��û��һ�������label self.segments=None
����洢���ݼ������д��ڶ����gt��ͼƬ������ԭʼlabel(�϶��ж����label Ҳ�����о�������label δ֪��)
self.batch: ������ÿ��ͼƬ�����ĸ�batch
self.n: ���ݼ�������ͼƬ������
self.indices: ����������ͼƬ��index
self.rect=Trueʱself.batch_shapes����ÿ��batch��shape(ͬһ��batch��ͼƬshape��ͬ)
"""
# 1����ֵһЩ������self���� ���ں�����__getitem__�е���
self.img_size = img_size # ����������ǿ�������ͼƬ�Ĵ�С
self.augment = augment # �Ƿ�����������ǿ һ��ѵ��ʱ�� ��֤ʱ�ر�
self.hyp = hyp # �����б�
# ͼƬ��Ȩ�ز��� True�Ϳ��Ը������Ƶ��(Ƶ�ʸߵ�Ȩ��С,������)�����в��� Ĭ��False: �����������
self.image_weights = image_weights
self.rect = False if image_weights else rect # �Ƿ���������ѵ�� һ��ѵ��ʱ�ر� ��֤ʱ�� ���Լ���
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
# mosaic��ǿ�ı߽�ֵ [-320, -320]
self.mosaic_border = [-img_size // 2, -img_size // 2]
self.stride = stride # ����²����� 32
self.path = path # ͼƬ·��
# 2���õ�path·���µ�����ͼƬ��·��self.img_files ������Ҫ�Լ�debugһ�� ����̫��
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
# ��ȡ���ݼ�·��path,����ͼƬ·����txt�ļ����߰���ͼƬ���ļ���·��
# ʹ��pathlib.Path���������ϵͳ�ص�·��,��Ϊ��ͬ����ϵͳ·���ġ�/����������ͬ
p = Path(p) # os-agnostic
# ���·��pathΪ����ͼƬ���ļ���·��
if p.is_dir(): # dir
# glob.glab: ��������ƥ����ļ�·���б� �ݹ��ȡp·���������ļ�
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
# f = list(p.rglob('**/*.*')) # pathlib
# ���·��pathΪ����ͼƬ·����txt�ļ�
elif p.is_file(): # file
with open(p, 'r') as t:
t = t.read().strip().splitlines() # ��ȡͼƬ·��,�������·��
# ��ȡ���ݼ�·�����ϼ���Ŀ¼ os.sepΪ·����ķָ���(��ͬ·���ķָ�����ͬ,os.sep���Ը���ϵͳ����Ӧ)
parent = str(p.parent) + os.sep
f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
else:
raise Exception(f'{prefix}{p} does not exist')
# ���ۺ��滻Ϊos.sep,os.path.splitext(x)���ļ�������չ���ֿ�������һ���б�
# ɸѡf�����е�ͼƬ�ļ�
self.img_files = sorted([x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in img_formats])
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in img_formats]) # pathlib
assert self.img_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\nSee {help_url}')
# 3������imgs·���ҵ�labels��·��self.label_files
self.label_files = img2label_paths(self.img_files) # labels
# 4��cache label �´���������ű���ʱ��ֱ�Ӵ�cache��ȡlabel������ȥ�ļ���ȡlabel �ٶȸ���
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache') # cached labels path
# Check cache
if cache_path.is_file():
# �����cache�ļ�,ֱ�Ӽ��� exists=True: �Ƿ��Ѵ�cache�ļ��ж�����nf, nm, ne, nc, n����Ϣ
cache, exists = torch.load(cache_path), True # load
# ���ͼƬ�汾��Ϣ�����ļ��б���hashֵ�Բ��Ϻ� ˵���������ݼ�ͼƬ��label���ܷ����˱仯 ������cache label�ļ�
if cache.get('version') != 0.3 or cache.get('hash') != get_hash(self.label_files + self.img_files):
cache, exists = self.cache_labels(cache_path, prefix), False # re-cache
else:
# �������cache_labels�����ǩ����ǩ�����Ϣ
cache, exists = self.cache_labels(cache_path, prefix), False # cache
# ��ӡcache�Ľ�� nf nm ne nc n = �ҵ��ı�ǩ����,©���ı�ǩ����,�յı�ǩ����,�ı�ǩ����,�ܵı�ǩ����
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupted, total
# ����Ѿ���cache�ļ�������nf nm ne nc n����Ϣ,ֱ����ʾ��ǩ��Ϣ msgs��Ϣ��
if exists:
d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupted"
tqdm(None, desc=prefix + d, total=n, initial=n) # display all cache results
if cache['msgs']:
logging.info('\n'.join(cache['msgs'])) # display all warnings msg
# ���ݼ�û�б�ǩ��Ϣ �ͷ������沢��ʾ��ǩlabel���ص�ַhelp_url
assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {help_url}'
# 5��Read cache ��cache�ж������±�������self �����forward��ʹ��
# cache�еļ�ֵ�������: cache[img_file]=[l, shape, segments] cache[hash] cache[results] cache[msg] cache[version]
# �ȴ�cache��ȥ��cache�ļ��������ؼ�ֵ��:'hash', 'version', 'msgs'�ȶ�ɾ��
[cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
# pop��results��hash��version��msgs��ֻʣ��cache[img_file]=[l, shape, segments]
# cache.values(): ȡcache������ֵ ��Ӧ����l, shape, segments
# labels: ������ݼ�����ͼƬ��û��һ�������label labels�洢��label�Ͷ���ԭʼlabel(���������ľ���label)
# ��������ͼƬ����gt��label����labels ������gt(����һ�������)����segments2boxesת��Ϊ�����ľ���label
# shapes: ����ͼƬ��shape
# self.segments: ������ݼ�����ͼƬ��û��һ�������label self.segments=None
# ����洢���ݼ������д��ڶ����gt��ͼƬ������ԭʼlabel(�϶��ж����label Ҳ�����о�������label δ֪��)
# zip ����Ϊcache������labels��shapes��segments��Ϣ���ǰ�ÿ��img�ֿ��洢��, zip�ǽ�����ͼƬ��Ӧ����Ϣ����һ��
labels, shapes, self.segments = zip(*cache.values()) # segments: ����[]
self.labels = list(labels) # labels to list
self.shapes = np.array(shapes, dtype=np.float64) # image shapes to float64
self.img_files = list(cache.keys()) # ��������ͼƬ��img_files��Ϣ update img_files from cache result
self.label_files = img2label_paths(cache.keys()) # ��������ͼƬ��label_files��Ϣ(��Ϊimg_files��Ϣ���ܷ����˱仯)
if single_cls:
for x in self.labels:
x[:, 0] = 0
n = len(shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
self.n = n # number of images
self.indices = range(n) # ����ͼƬ��index
# 6��ΪRectangular Training����
# ������Ҫ��ע��shapes������ ��һ������Ҫ ��Ϊ�����������ѵ����ô����batch����״Ҫһ�� ��Ҫ���������������batch��shape
# ���һ�Ҫ�����ݼ����ո߿��Ƚ������� �������ܱ�֤ͬһ��batch��ͼƬ����״�����ͬ ��ѡ��һ����ͬ��shape����Ҳ�Ƚ�С
if self.rect:
# Sort by aspect ratio
s = self.shapes # wh
ar = s[:, 1] / s[:, 0] # aspect ratio
irect = ar.argsort() # ���ݸ߿�������
self.img_files = [self.img_files[i] for i in irect] # ��ȡ������img_files
self.label_files = [self.label_files[i] for i in irect] # ��ȡ������label_files
self.labels = [self.labels[i] for i in irect] # ��ȡ������labels
self.shapes = s[irect] # ��ȡ������wh
ar = ar[irect] # ��ȡ������aspect ratio
# ����ÿ��batch���õ�ͳһ�߶� Set training image shapes
shapes = [[1, 1]] * nb # nb: number of batches
for i in range(nb):
ari = ar[bi == i] # bi: batch index
mini, maxi = ari.min(), ari.max() # ��ȡ��i��batch��,��С�����߿���
# �����/��С��1(w > h),��w��Ϊimg_size(��֤ԭͼ��߶Ȳ����������)
if maxi < 1:
shapes[i] = [maxi, 1] # maxi: h���ָ���߶ȵı��� 1: w���ָ���߶ȵı���
# �����/������1(w < h),��h����Ϊimg_size(��֤ԭͼ��߶Ȳ����������)
elif mini > 1:
shapes[i] = [1, 1 / mini]
# ����ÿ��batch���������shapeֵ(��������Ϊ32��������)
# Ҫ��ÿ��batch_shapes�ĸ߿�����32��������,����Ҫ�ȳ���32,ȡ���ٳ���32(����img_size�����32���������û��Ҫ��)
self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride
# 7���Ƿ���Ҫcache image һ����False ��ΪRAM��� cache label������ ����cache image��̫���� ����һ�㲻��
# Cache images into memory for faster training (WARNING: large datasets may exceed system RAM)
self.imgs = [None] * n
if cache_images:
gb = 0 # Gigabytes of cached images
self.img_hw0, self.img_hw = [None] * n, [None] * n
results = ThreadPool(num_threads).imap(lambda x: load_image(*x), zip(repeat(self), range(n)))
pbar = tqdm(enumerate(results), total=n)
for i, x in pbar:
self.imgs[i], self.img_hw0[i], self.img_hw[i] = x # img, hw_original, hw_resized = load_image(self, i)
gb += self.imgs[i].nbytes
pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB)'
pbar.close()
4.2��cache_labels
\qquad ����������ڼ����ļ�·���е�label��Ϣ����cache�ļ���cache�ļ��а�������Ϣ��:im_file, l, shape, segments, hash, results, msgs, version��,���忴����ע�͡�
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
"""����__init__������ cache���ݼ�label
����label��Ϣ����cache�ļ� Cache dataset labels, check images and read shapes
:params path: cache�ļ������ַ
:params prefix: ��־ͷ����Ϣ(�ʴ��������)
:return x: cache�б�����ֵ�
��������Ϣ��: x[im_file] = [l, shape, segments]
һ��ͼƬһ��label���Ӧ�ı��浽x, ����x�ᱣ������ͼƬ�����·����gt�����Ϣ����״shape�����еĶ����gt��Ϣ
im_file: ��ǰ����ͼƬ��path���·��
l: ��ǰ����ͼƬ������gt���label��Ϣ(������segment����α�ǩ) [gt_num, cls+xywh(normalized)]
shape: ��ǰ����ͼƬ����״ shape
segments: ��ǰ����ͼƬ����gt��label��Ϣ(����segment����α�ǩ) [gt_num, xy1...]
hash: ��ǰͼƬ��label�ļ���hashֵ 1
results: �ҵ���label����nf, ��ʧlabel����nm, ��label����ne, ����label����nc, ��img/label����len(self.img_files)
msgs: �������ݼ���msgs��Ϣ
version: ��ǰcache version
"""
x = {} # ��ʼ������cache�б�����ֵ�dict
# ��ʼ��number missing, found, empty, corrupt, messages
# ��ʼ���������ݼ�: ©���ı�ǩ(label)������, �ҵ��ı�ǩ(label)������, �յı�ǩ(label)������, �����ǩ(label)������, ���д�����Ϣ
nm, nf, ne, nc, msgs = 0, 0, 0, 0, []
desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels..." # ��־
# ����̵���verify_image_label����
with Pool(num_threads) as pool:
# ����pbar������
# pool.imap_unordered: �Դ������ݱ�������̼��� ����һ��������
# ��self.img_files, self.label_files, repeat(prefix) list�е�ֵ��Ϊ������������(һ����һ��)verify_image_label����
pbar = tqdm(pool.imap_unordered(verify_image_label, zip(self.img_files, self.label_files, repeat(prefix))),
desc=desc, total=len(self.img_files))
# im_file: ��ǰ����ͼƬ��path���·��
# l: [gt_num, cls+xywh(normalized)]
# �������ͼƬû��һ��segment����α�ǩ l�ʹ洢ԭlabel(ȫ�����������α�ǩ)
# �������ͼƬ��һ��segment����α�ǩ l�ʹ洢����segments2boxes�����õı�ǩ(�������α�ǩ������ ����α�ǩת��Ϊ���α�ǩ)
# shape: ��ǰ����ͼƬ����״ shape
# segments: �������ͼƬû��һ��segment����α�ǩ �洢None
# �������ͼƬ��һ��segment����α�ǩ �Ͱ�����ͼƬ������label�洢��segments��(���ɸ�����gt ���ɸ�����α�ǩ) [gt_num, xy1...]
# nm_f(nm): number missing ��ǰ����ͼƬ��label�Ƿ�ʧ ��ʧ=1 ����=0
# nf_f(nf): number found ��ǰ����ͼƬ��label�Ƿ���� ����=1 ��ʧ=0
# ne_f(ne): number empty ��ǰ����ͼƬ��label�Ƿ��ǿյ� �յ�=1 û��=0
# nc_f(nc): number corrupt ��ǰ����ͼƬ��label�ļ��Ƿ�������� �����=1 û����=0
# msg: ���ص�msg��Ϣ label�ļ����=���� label�ļ�����=warning��Ϣ
for im_file, l, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f # �ۼ���number missing label
nf += nf_f # �ۼ���number found label
ne += ne_f # �ۼ���number empty label
nc += nc_f # �ۼ���number corrupt label
if im_file:
x[im_file] = [l, shape, segments] # ��Ϣ�����ֵ� key=im_file value=[l, shape, segments]
if msg:
msgs.append(msg) # ��msg������msg
pbar.desc = f"{desc}{nf} found, {nm} missing, {ne} empty, {nc} corrupted" # ��־
pbar.close() # �رս�����
# ��־��ӡ����msg��Ϣ
if msgs:
logging.info('\n'.join(msgs))
# һ��label��û�ҵ� ��־��ӡhelp_url���ص�ַ
if nf == 0:
logging.info(f'{prefix}WARNING: No labels found in {path}. See {help_url}')
x['hash'] = get_hash(self.label_files + self.img_files) # ����ǰͼƬ��label�ļ���hashֵ���������ֵ�dist
x['results'] = nf, nm, ne, nc, len(self.img_files) # ��nf, nm, ne, nc, len(self.img_files)���������ֵ�dist
x['msgs'] = msgs # ���������ݼ���msgs��Ϣ���������ֵ�dist
x['version'] = 0.3 # ����ǰcache version���������ֵ�dist
try:
torch.save(x, path) # save cache to path
logging.info(f'{prefix}New cache created: {path}')
except Exception as e:
logging.info(f'{prefix}WARNING: Cache directory {path.parent} is not writeable: {e}') # path not writeable
return x
4.3��len
\qquad ��������������ݼ�ͼƬ��������
def __len__(self):
return len(self.img_files)
4.4.��getitem
\qquad �ⲿ����������ǿ����,һ��һ����ִ��batch_size�Ρ�
def __getitem__(self, index):
"""
�ⲿ����������ǿ����,һ��һ����ִ��batch_size�Ρ�
ѵ�� ������ǿ: mosaic(random_perspective) + hsv + �������ҷ�ת
���� ������ǿ: letterbox
:return torch.from_numpy(img): ���index��ͼƬ����(��ǿ��) [3, 640, 640]
:return labels_out: ���indexͼƬ��gt label [6, 6] = [gt_num, 0+class+xywh(normalized)]
:return self.img_files[index]: ���indexͼƬ��·����ַ
:return shapes: ���batch��ͼƬ��shapes ����ʱ(����ѵ��)���� ��֤ʱΪNone for COCO mAP rescaling
"""
# �������ͨ��������ʽ��ȡҪ����������ǿ��ͼƬindex linear, shuffled, or image_weights
index = self.indices[index]
hyp = self.hyp # ���� �����ڶ�������ǿ����
mosaic = self.mosaic and random.random() < hyp['mosaic']
# mosaic��ǿ ��ͼ�����4��ͼƴ��ѵ�� һ��ѵ��ʱ����
# mosaic + MixUp
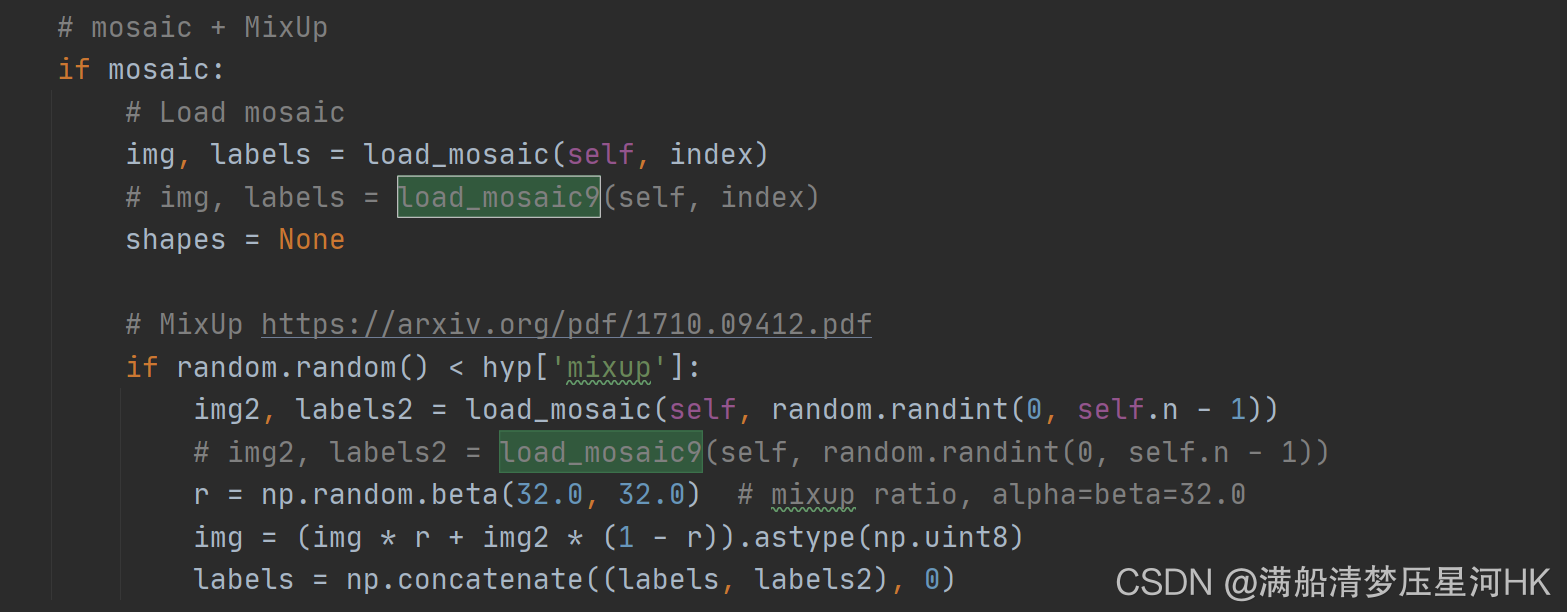
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index)
# img, labels = load_mosaic9(self, index)
shapes = None
# MixUp augmentation
# mixup������ǿ
if random.random() < hyp['mixup']: # hyp['mixup']=0 Ĭ��Ϊ0��ر� Ĭ��Ϊ1��100%��
# *load_mosaic(self, random.randint(0, self.n - 1)) ��������ݼ�����ѡһ��ͼƬ�ͱ���ͼƬ����mixup������ǿ
# img: ����ͼƬ�ں�֮���ͼƬ numpy (640, 640, 3)
# labels: ����ͼƬ�ں�֮��ı�ǩlabel [M+N, cls+x1y1x2y2]
img, labels = mixup(img, labels, *load_mosaic(self, random.randint(0, self.n - 1)))
# ���Դ��� ����MixUpЧ��
# cv2.imshow("MixUp", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
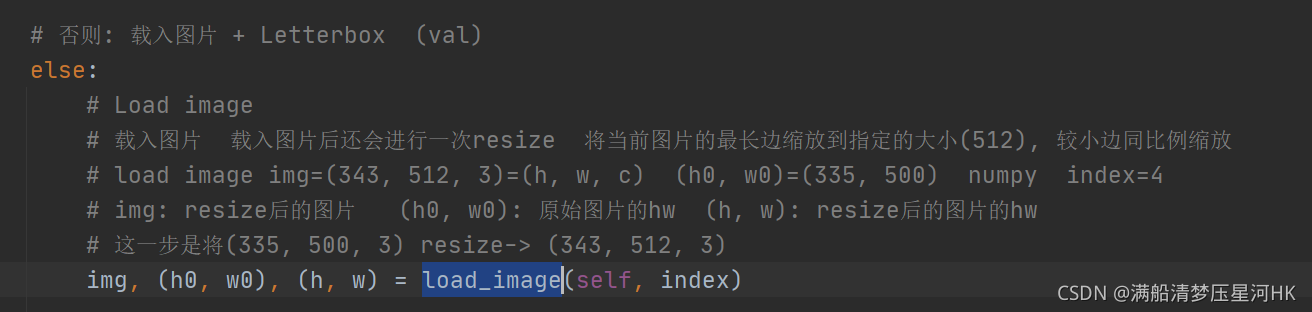
# ����: ����ͼƬ + Letterbox (val)
else:
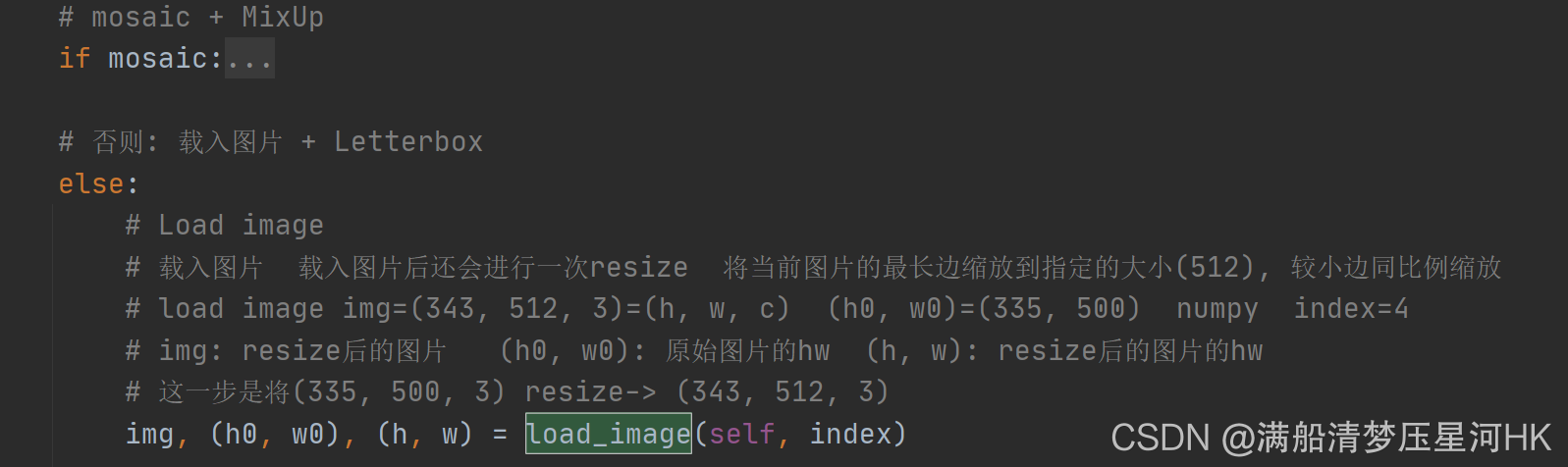
# Load image
# ����ͼƬ ����ͼƬ�����һ��resize ����ǰͼƬ��������ŵ�ָ���Ĵ�С(512), ��С��ͬ��������
# load image img=(343, 512, 3)=(h, w, c) (h0, w0)=(335, 500) numpy index=4
# img: resize���ͼƬ (h0, w0): ԭʼͼƬ��hw (h, w): resize���ͼƬ��hw
# ��һ���ǽ�(335, 500, 3) resize-> (343, 512, 3)
img, (h0, w0), (h, w) = load_image(self, index)
# ���Դ��� ����load_imageЧ��
# cv2.imshow("load_image", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
# Letterbox
# letterbox֮ǰȷ�����ŵ�ǰͼƬletterbox֮���shape �������self.rect����ѵ��shape����self.img_size
# ���ʹ��self.rect����ѵ��shape���ǵ�ǰbatch��shape ��Ϊ����ѵ���Ļ���������batch��shape����ͳһ(��__init__������6������)
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
# letterbox ��һ������һ�����ŵõ���ͼƬ�����ŵ���ǰbatch����Ҫ�ij߶� (343, 512, 3) pad-> (384, 512, 3)
# (����������Ҫһ��batch������ͼƬ��shape������ͬ,�����shape��init�����б�����self.batch_shapes��)
# ����û�����Ų���,���������ratio��Զ����(1.0, 1.0) pad=(0.0, 20.5)
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
# ͼƬletterbox֮��label������ҲҪ��Ӧ�仯 ����pad����label���� ������һ����xywh -> δ��һ����xyxy
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
# ���Դ��� ����letterboxЧ��
# cv2.imshow("letterbox", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
if self.augment:
# Augment imagespace
if not mosaic:
# ����mosaic�Ļ���Ҫ��random_perspective��ǿ ��Ϊmosaic�����ڲ�ִ����random_perspective��ǿ
# random_perspective��ǿ: �����ͼƬ������ת,ƽ��,����,�ü�,�ӱ任
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
# ɫ��ռ���ǿAugment colorspace
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# ���Դ��� ����augment_hsvЧ��
# cv2.imshow("augment_hsv", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
# Apply cutouts �������cutout��ǿ 0.5�ļ���ʹ�� ����������в���
if random.random() < hyp['cutout']: # hyp['cutout']=0 Ĭ��Ϊ0��ر� Ĭ��Ϊ1��100%��
labels = cutout(img, labels)
# ���Դ��� ����cutoutЧ��
# cv2.imshow("cutout", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img.shape) # (640, 640, 3)
nL = len(labels) # number of labels
if nL:
# xyxy to xywh normalized
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0])
# ƽ����ǿ ������ҷ�ת + ������·�ת
if self.augment:
# ������·�ת flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img) # np.flipud �����������·���ת��
if nL:
labels[:, 2] = 1 - labels[:, 2] # 1 - y_center labelҲҪӳ��
# ������ҷ�ת flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img) # np.fliplr �����������ҷ���ת
if nL:
labels[:, 1] = 1 - labels[:, 1] # 1 - x_center labelҲҪӳ��
# 6��ֵ��tensor ��ʼ����ǩ���Ӧ��ͼƬ���, ��������collate_fnʹ��
labels_out = torch.zeros((nL, 6))
if nL:
labels_out[:, 1:] = torch.from_numpy(labels) # numpy to tensor
# Convert BGR->RGB HWC->CHW
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3 x img_height x img_width
img = np.ascontiguousarray(img) # img����ڴ����������� �ӿ�����
return torch.from_numpy(img), labels_out, self.img_files[index], shapes
4.5��collate_fn
\qquad �ܶ�����Ϊд�� init �� getitem ����������ǿ��������,�����ڷ��������е�ȷд�������������Ϳ�����,��Ϊϵͳ���Ǹ�����д����һ��collate_fn������,������Ŀ����������ȴ��Ҫ��дcollate_fn����,�����һ���ϸ�Ľ�����������ԭ��(������ע��)��
�����������create_dataloader������dataloaderʱ����:

@staticmethod
def collate_fn(batch):
"""�����������create_dataloader������dataloaderʱ����:
�������� ��image��label���ϵ�һ��
:return torch.stack(img, 0): ��[16, 3, 640, 640] ����batch��ͼƬ
:return torch.cat(label, 0): ��[15, 6] [num_target, img_index+class_index+xywh(normalized)] ����batch��label
:return path: ����batch����ͼƬ��·��
:return shapes: (h0, w0), ((h / h0, w / w0), pad) for COCO mAP rescaling
pytorch��DataLoader���һ��batch�����ݼ�ʱҪ�����˺������д�� ͨ����д�˺���ʵ�ֱ�ǩ��ͼƬ��Ӧ�Ļ���,һ��batch����Щ��ǩ������һ��ͼƬ,����
[[0, 6, 0.5, 0.5, 0.26, 0.35],
[0, 6, 0.5, 0.5, 0.26, 0.35],
[1, 6, 0.5, 0.5, 0.26, 0.35],
[2, 6, 0.5, 0.5, 0.26, 0.35],]
ǰ���б�ǩ���ڵ�һ��ͼƬ, ���������ڵڶ��š�����
"""
# img: һ��tuple ��batch_size��tensor��� ����batch��ÿ��tensor��ʾһ��ͼƬ
# label: һ��tuple ��batch_size��tensor��� ÿ��tensor���һ��ͼƬ�����е�target��Ϣ
# label[6, object_num] 6�еĵ�һ��������һ��batch�еĵڼ���ͼ
# path: һ��tuple ��4��str���, ÿ��str��Ӧһ��ͼƬ�ĵ�ַ��Ϣ
img, label, path, shapes = zip(*batch) # transposed
for i, l in enumerate(label):
l[:, 0] = i # add target image index for build_targets()
# ���ص�img=[batch_size, 3, 736, 736]
# torch.stack(img, 0): ��batch_size��[3, 736, 736]�ľ���ƴ��һ��[batch_size, 3, 736, 736]
# label=[target_sums, 6] 6:��ʾ��ǰtarget������һ��ͼ+class+x+y+w+h
# torch.cat(label, 0): ��[n1,6]��[n2,6]��[n3,6]...ƴ�ӳ�[n1+n2+n3+..., 6]
# ����֮����ƴ�ӵķ�ʽ��ͬ����Ϊimgƴ�ӵ�ʱ������ÿ�����ֵ���״����ͬ��,����[3, 736, 736]
# ����label��ÿ�����ֵ���״�Dz�һ����ͬ��,ÿ��ͼ��Ŀ������Dz�һ����ͬ��(label�϶�Ҳϣ����stack,������,���Dz�������ƴ)
# ���ÿ��ͼ��Ŀ���������ͬ��,�����ǾͿ��ܲ���Ҫ��дcollate_fn������
return torch.stack(img, 0), torch.cat(label, 0), path, shapes
ע��:�������һ���ǵ�������batch_size�� getitem ������Ż����һ���������,��batch_size��ͼƬ�Ͷ�Ӧ��label���д���� ǿ�ҽ���������debug��������return�������Dz�����˵����������ġ�
4.6��collate_fn4
\qquad ������yolo-v5����ʵ���Ե�һ������ quad-collate function ��train.py��opt����quad=True �����collate_fn4����collate_fn�� ����:��4��mosaicͼƬ[1, 3, 640, 640]�ϳ�һ�Ŵ��mosaicͼƬ[1, 3, 1280, 1280]����һ��batch��ͼƬÿ���Ŵ���, 0.5�ĸ��ʽ�����ͼƬƴ�ӵ�һ�Ŵ�ͼ��ѵ��, 0.5����ֱ�ӽ�ij��ͼƬ�ϲ�������ѵ����
ͬ����create_dataloader������dataloaderʱ����:
@staticmethod
def collate_fn4(batch):
"""ͬ����create_dataloader������dataloaderʱ����:
������yolo-v5����ʵ���Ե�һ������ quad-collate function ��train.py��opt����quad=True �����collate_fn4����collate_fn
����: ��֮ǰ��collate_fn���Է���ͼƬ[16, 3, 640, 640] ����collate_fn4��ͼƬ[4, 3, 1280, 1280]
��4��mosaicͼƬ[1, 3, 640, 640]�ϳ�һ�Ŵ��mosaicͼƬ[1, 3, 1280, 1280]
��һ��batch��ͼƬÿ���Ŵ���, 0.5�ĸ��ʽ�����ͼƬƴ�ӵ�һ�Ŵ�ͼ��ѵ��, 0.5����ֱ�ӽ�ij��ͼƬ�ϲ�������ѵ��
"""
# img: ����batch��ͼƬ [16, 3, 640, 640]
# label: ����batch��label��ǩ [num_target, img_index+class_index+xywh(normalized)]
# path: ����batch����ͼƬ��·��
# shapes: (h0, w0), ((h / h0, w / w0), pad) for COCO mAP rescaling
img, label, path, shapes = zip(*batch) # transposed
n = len(shapes) // 4 # collate_fn4���������batch��ͼƬ�ĸ���
img4, label4, path4, shapes4 = [], [], path[:n], shapes[:n] # ��ʼ��
ho = torch.tensor([[0., 0, 0, 1, 0, 0]])
wo = torch.tensor([[0., 0, 1, 0, 0, 0]])
s = torch.tensor([[1, 1, .5, .5, .5, .5]]) # scale
for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
i *= 4 # ���� [0, 4, 8, 16]
if random.random() < 0.5:
# �����С��0.5��ֱ�ӽ�ij��ͼƬ�ϲ�������ѵ��
im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2., mode='bilinear', align_corners=False)[
0].type(img[i].type())
l = label[i]
else:
# ���������0.5�ͽ�����ͼƬ(mosaic���)ƴ�ӵ�һ�Ŵ�ͼ��ѵ��
im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
l = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
img4.append(im)
label4.append(l)
# ���淵�صIJ��ֺ�collate_fn�Ͳ���� ԭ��ͽ��Ͷ�д����һ�������� �Լ�debug��һ�°�
for i, l in enumerate(label4):
l[:, 0] = i # add target image index for build_targets()
return torch.stack(img4, 0), torch.cat(label4, 0), path4, shapes4
5��img2label_paths
\qquad ����ļ��Ǹ������ݼ�������ͼƬ��·���ҵ����ݼ�������labels��Ӧ��·��������LoadImagesAndLabelsģ���__init__�����С�
def img2label_paths(img_paths):
"""����LoadImagesAndLabelsģ���__init__������
����imgsͼƬ��·���ҵ���Ӧlabels��·��
Define label paths as a function of image paths
:params img_paths: {list: 50} �������ݼ���ͼƬ���·�� ����: '..\\datasets\\VOC\\images\\train2007\\000012.jpg'
=> '..\\datasets\\VOC\\labels\\train2007\\000012.jpg'
"""
# ��Ϊpython�ǿ�ƽ̨��,��Windows��,�ļ���·���ָ�����'\',��Linux����'/'
# Ϊ���ô����ڲ�ͬ��ƽ̨�϶�������,��ô·��Ӧ��д'\'����'/'��? os.sep������������ƽ̨, �Զ�������Ӧ�ķָ�����
# sa: '\\images\\' sb: '\\labels\\'
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
# ��img_paths������ͼƬ·���е�images�滻Ϊlabels
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
6��verify_image_label
\qquad ����������ڼ��ÿһ��ͼƬ��ÿһ��label�ļ��Ƿ���á�
\qquad ͼƬ�ļ�: ������ݡ���ʽ����С��������
\qquad label�ļ�: ���ÿ��gt�����Ǿ���(ÿ�ж�����5���� class+xywh) + ��ǩ�Ƿ�ȫ��>=0 + ��ǩ����xywh�Ƿ��һ�� + ��ǩ���Ƿ����ظ�������
verify_image_label��������:
def verify_image_label(args):
"""����cache_labels������
������ݼ���ÿ��ͼƬ��ÿ��laebl�Ƿ����
ͼƬ�ļ�: ���ݡ���ʽ����С��������
label�ļ�: ÿ��gt�����Ǿ���(ÿ�ж�����5���� class+xywh) + ��ǩ�Ƿ�ȫ��>=0 + ��ǩ����xywh�Ƿ��һ�� + ��ǩ���Ƿ����ظ�������
:params im_file: ���ݼ���һ��ͼƬ��path���·��
:params lb_file: ���ݼ���һ��ͼƬ��label���·��
:params prefix: ��־ͷ����Ϣ(�ʴ��������)
:return im_file: ��ǰ����ͼƬ��path���·��
:return l: [gt_num, cls+xywh(normalized)]
�������ͼƬû��һ��segment����α�ǩ l�ʹ洢ԭlabel(ȫ�����������α�ǩ)
�������ͼƬ��һ��segment����α�ǩ l�ʹ洢����segments2boxes�����õı�ǩ(�������α�ǩ������ ����α�ǩת��Ϊ���α�ǩ)
:return shape: ��ǰ����ͼƬ����״ shape
:return segments: �������ͼƬû��һ��segment����α�ǩ �洢None
�������ͼƬ��һ��segment����α�ǩ �Ͱ�����ͼƬ������label�洢��segments��(���ɸ�����gt ���ɸ�����α�ǩ) [gt_num, xy1...]
:return nm: number missing ��ǰ����ͼƬ��label�Ƿ�ʧ ��ʧ=1 ����=0
:return nf: number found ��ǰ����ͼƬ��label�Ƿ���� ����=1 ��ʧ=0
:return ne: number empty ��ǰ����ͼƬ��label�Ƿ��ǿյ� �յ�=1 û��=0
:return nc: number corrupt ��ǰ����ͼƬ��label�ļ��Ƿ�������� �����=1 û����=0
:return msg: ���ص�msg��Ϣ label�ļ����=���� label�ļ�����=warning��Ϣ
"""
im_file, lb_file, prefix = args
nm, nf, ne, nc = 0, 0, 0, 0 # number missing, found, empty, corrupt label
try:
# �������ͼƬ(���ݡ���ʽ����С��������) verify images
im = Image.open(im_file) # ��ͼƬ�ļ�
im.verify() # PIL verify ���ͼƬ���ݺ�ʽ�Ƿ�����
shape = exif_size(im) # ��ǰͼƬ�Ĵ�С image size
assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels' # ͼƬ��С�������9��pixels
assert im.format.lower() in img_formats, f'invalid image format {im.format}' # ͼƬ��ʽ������img_format��
if im.format.lower() in ('jpg', 'jpeg'): # ���jpg��ʽ�ļ�
with open(im_file, 'rb') as f:
# f.seek: -2 ƫ���� ���ļ�ͷ�������ƶ����ֽ��� 2 ���λ�� ���ļ�β��ʼƫ��
f.seek(-2, 2)
# f.read(): ��ȡͼƬ�ļ� ָ��: \xff\xd9 �������ͼƬ�Ƿ����� ����������ͷ���corrupted JPEG
assert f.read() == b'\xff\xd9', 'corrupted JPEG'
# verify labels
segments = [] # �������ͼ����gt�����Ϣ(����segments�����: labelijһ��������8)
if os.path.isfile(lb_file): # ������label·������
nf = 1 # label found
with open(lb_file, 'r') as f: # ��ȡlabel�ļ�
# ��ȡ��ǰlabel�ļ���ÿһ��: ÿһ�ж��ǵ�ǰͼƬ��һ��gt
l = [x.split() for x in f.read().strip().splitlines() if len(x)]
# any() ���������жϸ����Ŀɵ������� �Ƿ�ȫ��ΪFalse,�� False; �����һ��Ϊ True,��True
# �����ǰͼƬ��label�ļ�ijһ��������8, ����Ϊlabel�Ǵ���segment��polygon��(�����) �Ͳ��Ǿ��� ��label��Ϣ����segment��
if any([len(x) > 8 for x in l]): # is segment
# ��ǰͼƬ������gt������
classes = np.array([x[0] for x in l], dtype=np.float32)
# �������ͼ������gt���label��Ϣ(����segment����α�ǩ)
# ��Ϊsegment��ǩ�����Dz�ͬ����,��������segments��һ���б� [gt_num, xy1...(normalized)]
segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in l]
# �������ͼ������gt���label��Ϣ(������segment����α�ǩ)
# segments(�����) -> bbox(������), �õ��±�ǩ [gt_num, cls+xywh(normalized)]
l = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1)
l = np.array(l, dtype=np.float32) # l: to float32
if len(l):
# �жϱ�ǩ�Ƿ�������
assert l.shape[1] == 5, 'labels require 5 columns each'
# �жϱ�ǩ�Ƿ�ȫ��>=0
assert (l >= 0).all(), 'negative labels'
# �жϱ�ǩ����x y w h�Ƿ��һ��
assert (l[:, 1:] <= 1).all(), 'non-normalized or out of bounds coordinate labels'
# �жϱ�ǩ���Ƿ����ظ�������
assert np.unique(l, axis=0).shape[0] == l.shape[0], 'duplicate labels'
else:
ne = 1 # label empty l.shape[0] == 0��Ϊ�յı�ǩ,ne=1
l = np.zeros((0, 5), dtype=np.float32)
else:
nm = 1 # label missing �����ڱ�ǩ�ļ�,��nm = 1
l = np.zeros((0, 5), dtype=np.float32)
return im_file, l, shape, segments, nm, nf, ne, nc, ''
except Exception as e:
nc = 1
msg = f'{prefix}WARNING: Ignoring corrupted image and/or label {im_file}: {e}'
return [None, None, None, None, nm, nf, ne, nc, msg]
7��load_image
\qquad
��������Ǹ���ͼƬindex,��self���ߴӶ�ӦͼƬ·���������Ӧindex��ͼƬ ����ԭͼ��hw�нϴ�����չ��self.img_size, ��С��ͬ������չ���ᱻ����LoadImagesAndLabelsģ���__getitem__������load_mosaicģ���������Ӧindex��ͼƬ:
load_image��������:
def load_image(self, index):
"""����LoadImagesAndLabelsģ���__getitem__������load_mosaicģ����
��self���ߴӶ�ӦͼƬ·���������Ӧindex��ͼƬ ����ԭͼ��hw�нϴ�����չ��self.img_size, ��С��ͬ������չ
loads 1 image from dataset, returns img, original hw, resized hw
:params self: һ���ǵ���LoadImagesAndLabels�е�self
:param index: ��ǰͼƬ��index
:return: img: resize���ͼƬ
(h0, w0): hw_original ԭͼ��hw
img.shape[:2]: hw_resized resize���ͼƬhw(hw�нϴ�����չ��self.img_size, ��С��ͬ������չ)
"""
# ��index��self.imgs�����뵱ǰͼƬ, �������ڻ��������һ����, ��������һ�㲻����self.imgs(cache)�������е�ͼƬ
img = self.imgs[index]
# ͼƬ�ǿյĻ�, �ʹӶ�Ӧ�ļ�·����������ͼƬ
if img is None: # not cached һ�㶼����ʹ��cache���浽self.imgs��
path = self.img_files[index] # ͼƬ·��
img = cv2.imread(path) # ����BGRͼƬ (335, 500, 3) HWC
assert img is not None, 'Image Not Found ' + path
h0, w0 = img.shape[:2] # orig img hw
# img_size ���õ���Ԥ�����������ͼƬ�ߴ� r=���ű���
r = self.img_size / max(h0, w0) # ratio aspect
if r != 1: # if sizes are not equal
# cv2.INTER_AREA: �����������ع�ϵ��һ���ز������߲�ֵ��ʽ.�÷�����ͼ���ȡ����ѡ����, �����Բ������ٵIJ���
# cv2.INTER_LINEAR: ˫���Բ�ֵ,Ĭ�������ʹ�ø÷�ʽ���в�ֵ ����ratioѡ��ͬ�IJ�ֵ��ʽ
# ��ԭͼ��hw�нϴ�����չ��self.img_size, ��С��ͬ������չ
img = cv2.resize(img, (int(w0 * r), int(h0 * r)),
interpolation=cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEAR)
return img, (h0, w0), img.shape[:2] # img, hw_original, hw_resized
else:
return self.imgs[index], self.img_hw0[index], self.img_hw[index] # img, hw_original, hw_resized
����LoadImagesAndLabelsģ���__getitem__������load_mosaicģ����:
ִ��Ч��:

8��augment_hsv
\qquad ��������ǹ���ͼƬ��ɫ����ǿģ��,ͼƬ���������ƶ�,���в���Ҫ�ı�label,ֻ��Ҫ img ��ǿ���ɡ�
augment_hsvģ�����:
def augment_hsv(img, hgain=0.5, sgain=0.5, vgain=0.5):
"""����LoadImagesAndLabelsģ���__getitem__����
hsvɫ����ǿ ����ͼ��hsv,����label�����κδ���
:param img: ������ͼƬ BGR [736, 736]
:param hgain: hͨ��ɫ����� ���������µ�hͨ��
:param sgain: hͨ��ɫ����� ���������µ�sͨ��
:param vgain: hͨ��ɫ����� ���������µ�vͨ��
:return: ����hsv��ǿ���ͼƬ img
"""
if hgain or sgain or vgain:
# ���ȡ-1��1����ʵ��,����hyp�е�hsv��ͨ����ϵ�� ���������µ�hsvͨ��
r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV)) # ͼ���ͨ����� h s v
dtype = img.dtype # uint8
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype) # �����µ�hͨ��
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype) # �����µ�sͨ��
lut_val = np.clip(x * r[2], 0, 255).astype(dtype) # �����µ�vͨ��
# ͼ���ͨ���ϲ� img_hsv=h+s+v �������hsv֮���������hsvͨ��
# cv2.LUT(hue, lut_hue) ͨ��ɫ��任 ����任ǰͨ��hue �ͱ任��ͨ��lut_hue
img_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
# no return needed dst:���ͼ��
cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed hsv->bgr
\qquad ��Ҫע��������hsv��ǿ��������ɸ���ɫ�������,����ÿ����ǿ��Ч�����Dz�ͬ��:
��һ��:����

�ڶ���:�䰵

�����������LoadImagesAndLabelsģ���__getitem__������:

����,�����漰����������������hyp.yaml�����ļ�:

9��load_mosaic��load_mosaic9
\qquad ��������������mosaic������ǿ,ֻ����load_mosaic������ƴ������ͼ,��load_mosaic9������ƴ�Ӿ���ͼ��
9.1��load_mosaic
\qquad ���ģ����Ǻ�������mosaic��ǿģ��,����ѵ����ʱ������,�������������С������mAP��������������ǿ�������ѵ�, Ҳ�����м�ֵ��,mosaic�Ƿdz��dz����õ�������ǿtrick, һ��Ҫ�������ա�
load_mosaicģ�����:
def load_mosaic(self, index):
"""����LoadImagesAndLabelsģ���__getitem__���� ����mosaic������ǿ
������ͼƬƴ����һ��������ͼ���� loads images in a 4-mosaic
:param index: ��Ҫ��ȡ��ͼ������
:return: img4: mosaic������ӱ任���һ��ͼƬ numpy(640, 640, 3)
labels4: img4��Ӧ��target [M, cls+x1y1x2y2]
"""
# labels4: ���ڴ��ƴ��ͼ��(4��ͼƴ��һ��)��label��Ϣ(������segments�����)
# segments4: ���ڴ��ƴ��ͼ��(4��ͼƴ��һ��)��label��Ϣ(����segments�����)
labels4, segments4 = [], []
s = self.img_size # һ���ͼƬ��С
# �����ʼ��ƴ��ͼ������ĵ����� [0, s*2]֮�����ȡ2������Ϊƴ��ͼ�����������
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border] # mosaic center x, y
# ��dataset�����Ѱ�Ҷ��������ͼ�����ƴ�� [14, 26, 2, 16] �����ѡ����ͼƬ��index
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
# ��������ͼ�����ƴ�� 4�Ų�ͬ��С��ͼ�� => 1��[1472, 1472, 3]��ͼ��
for i, index in enumerate(indices):
# load image ÿ����һ��ͼƬ ��������ͼƬresize��self.size(h,w)
img, _, (h, w) = load_image(self, index)
# place img in img4
if i == 0: # top left ԭͼ[375, 500, 3] load_image->[552, 736, 3] hwc
# ����������ͼ�� [1472, 1472, 3]=[h, w, c]
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
# ����������ͼ���е�������Ϣ(��ͼ����䵽������ͼ����) w=736 h = 552 ������ͼ��:(x1a,y1a)���Ͻ� (x2a,y2a)���½�
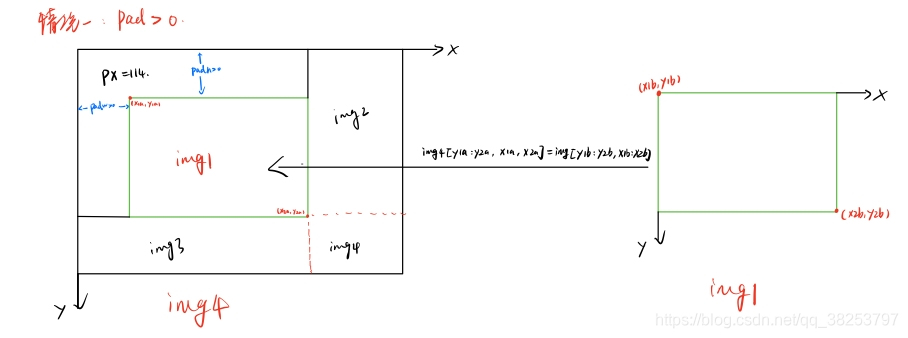
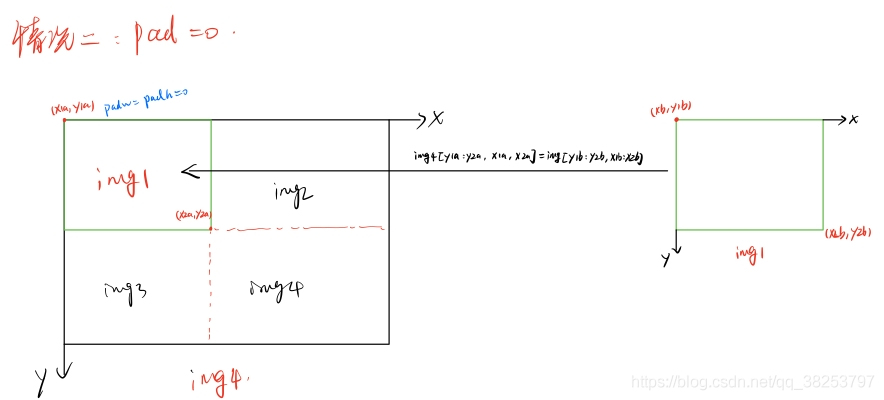
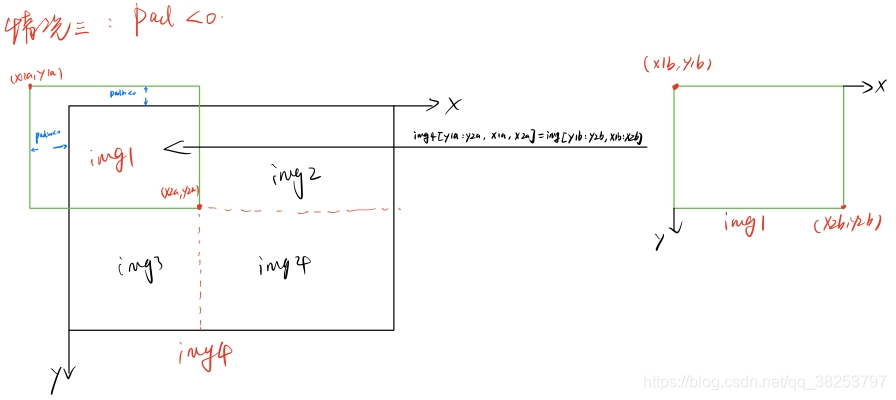
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
# �����ȡ��ͼ��������Ϣ(��xc,ycΪ��һ��ͼ������½�������䵽������ͼ����,����Խ�������) ͼ��:(x1b,y1b)���Ͻ� (x2b,y2b)���½�
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
# ����������ͼ���е�������Ϣ(��ͼ����䵽������ͼ����)
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
# �����ȡ��ͼ��������Ϣ(��xc,ycΪ�ڶ���ͼ������½�������䵽������ͼ����,����Խ�������)
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
# ����������ͼ���е�������Ϣ(��ͼ����䵽������ͼ����)
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
# �����ȡ��ͼ��������Ϣ(��xc,ycΪ������ͼ������Ͻ�������䵽������ͼ����,����Խ�������)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
# ����������ͼ���е�������Ϣ(��ͼ����䵽������ͼ����)
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
# �����ȡ��ͼ��������Ϣ(��xc,ycΪ������ͼ������Ͻ�������䵽������ͼ����,����Խ�������)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
# ����ȡ��ͼ��������䵽������ͼ�����Ӧλ�� img4[h, w, c]
# ��ͼ��img�ġ�(x1b,y1b)���Ͻ� (x2b,y2b)���½ǡ������ȡ������䵽������ͼ��ġ�(x1a,y1a)���Ͻ� (x2a,y2a)���½ǡ�����
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# ����pad(��ǰͼ��߽��������˱߽�ľ���,Խ������padw/padhΪ��ֵ) ���ں����labelӳ��
padw = x1a - x1b # ��ǰͼ����������ͼ����wά����������
padh = y1a - y1b # ��ǰͼ����������ͼ����hά����������
# labels: ��ȡ��Ӧƴ��ͼ�����������label��Ϣ(�����segments����λᱻת��Ϊ����label)
# segments: ��ȡ��Ӧƴ��ͼ������в�����label��Ϣ(����segments�����Ҳ��������gt)
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
# normalized xywh normalized to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh)
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels) # ����labels4
segments4.extend(segments) # ����segments4
# Concat/clip labels4 ��labels4([(2, 5), (1, 5), (3, 5), (1, 5)] => (7, 5))ѹ����һ��
labels4 = np.concatenate(labels4, 0)
# ��ֹԽ�� label[:, 1:]�е�����Ԫ�ص�ֵ(λ����Ϣ)������[0, 2*s]֮��,С��0���������0,����2*s�͵���2*s out: ����
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# ���Դ��� ����ǰ���mosaicЧ��
# cv2.imshow("mosaic", img4)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img4.shape) # (1280, 1280, 3)
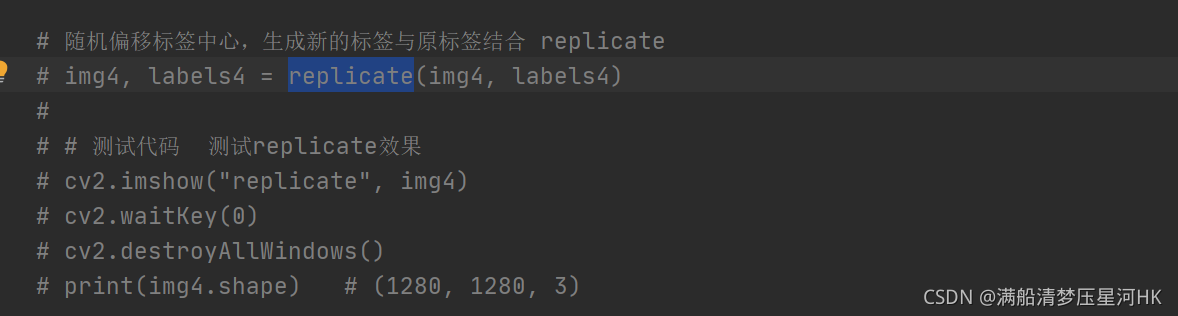
# ���ƫ�Ʊ�ǩ����,�����µı�ǩ��ԭ��ǩ��� replicate
# img4, labels4 = replicate(img4, labels4)
#
# # ���Դ��� ����replicateЧ��
# cv2.imshow("replicate", img4)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img4.shape) # (1280, 1280, 3)
# Augment
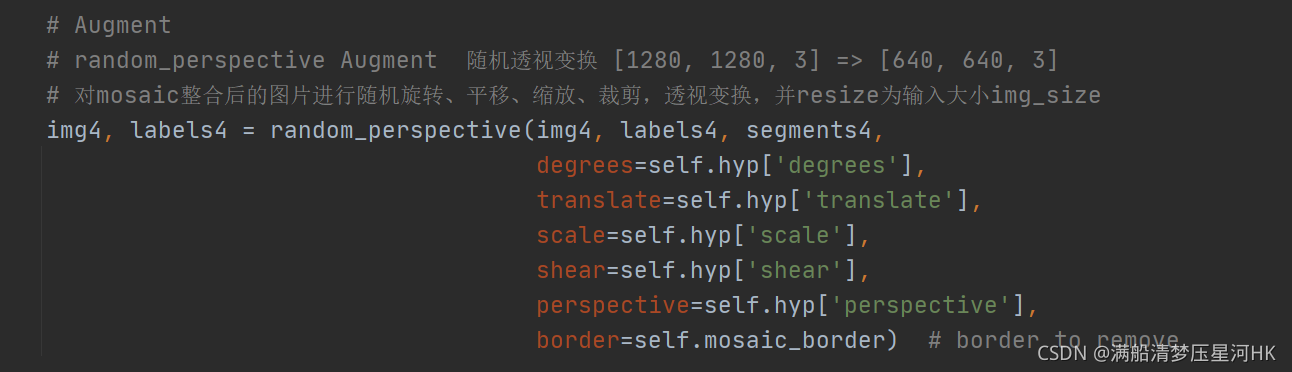
# random_perspective Augment ����ӱ任 [1280, 1280, 3] => [640, 640, 3]
# ��mosaic���Ϻ��ͼƬ���������ת��ƽ�ơ����š��ü�,�ӱ任,��resizeΪ�����Сimg_size
img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
# ���Դ��� ����mosaic + random_perspective�������任Ч��
# cv2.imshow("random_perspective", img4)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(img4.shape) # (640, 640, 3)
return img4, labels4
mosaic�㷨����:
1���� [img_size x 0.5 : img_size x 1.5] ֮�����ѡ��һ��ƴ�����ĵ�����(xc, yc)����Ҫע����������img_size��������Ҫ��ͼƬ�Ĵ�С, ��mosaic������ǿ�õ���ͼƬ��shapeӦ����2����img_size.
2���� [0, len(label)-1] ֮�����ѡ��3��ͼƬ��index, �봫���ͼƬindex��ͬ���4����Ƭ�ļ���indices.
-------------------------------------------------------------��ʼ����img4---------------------------------------------------------------------
3��for 4��ͼƬ:
3.0)������ǵ�һ��ͼƬ,�ͳ�ʼ��mosaicͼƬimg4
3.1)�� �õ�mosaicͼƬ��������Ϣ(��������������������ͼ���):���Ͻ�(x1a, y1a), (x2a, y2a)���½�
3.2)���õ���ȡ��ͼ�������������Ϣ:(x1b,y1b)���Ͻ� (x2b,y2b)���½�
3.3)����ͼ��img�ġ�(x1b,y1b)���Ͻ� (x2b,y2b)���½ǡ������ȡ������䵽������ͼ��ġ�(x1a,y1a)���Ͻ� (x2a,y2a)���½ǡ� ע:�������������ֿ��ܵ����,�������ϸ�����ۡ�
3.4)�����㵱ǰͼ��߽��������˱߽�ľ���,���ں����labelӳ��
3.5)��ƴ��4��ͼ���labels��ϢΪһ��labels4
--------------------------------------------������͵õ���img4[2 x img_size, 2 x img_size, 3]--------------------------------------
4��Concat labels4
5��clip labels4, ��ֹԽ��
-------------------------------------------�������ֵõ���labels4(���img4��)---------------------------------------------------------
6��random_perspective����ӱ任(random_perspective Augment),��img4[2 x img_size, 2 x img_size, 3]=>img4 [img_size, img_size, 3]. �����ҾͲ���ϸ�Ľ�������ӱ任��,��һ�ڻ���ϸ���ܵġ�
--------------------------------------------------������͵õ���img4[img_size, img_size, 3]--------------------------------------------
7�����retrun img4[img_size, img_size, 3] �� labels4(���img4��)
4��ͼƬ����ƴ�ӵ�ʱ��,ͨ������������������:
Ч����ʾ1:mosaic
shape = (1280, 1280, 3)

Ч����ʾ2:mosaic + random_perspective
shape = (640, 640, 3)

9.2��load_mosaic9
\qquad ���ģ�������ߵ�ʵ��ģ��,������ͼƬƴ����һ��������ͼ���С�����������̺�load_mosaic4����һ��,������load_mosaic4�ٿ�����ͺܼ��ˡ�
load_mosaic9ģ�����:
def load_mosaic9(self, index):
"""����LoadImagesAndLabelsģ���__getitem__���� �滻mosaic������ǿ
������ͼƬƴ����һ��������ͼ���� loads images in a 9-mosaic
:param self:
:param index: ��Ҫ��ȡ��ͼ������
:return: img9: mosaic�ͷ�����ǿ���һ��ͼƬ
labels9: img9��Ӧ��target
"""
# labels9: ���ڴ��ƴ��ͼ��(9��ͼƴ��һ��)��label��Ϣ(������segments�����)
# segments9: ���ڴ��ƴ��ͼ��(9��ͼƴ��һ��)��label��Ϣ(����segments�����)
labels9, segments9 = [], []
s = self.img_size # һ���ͼƬ��С(Ҳ�����������ͼƬ��С)
# ��dataset�����Ѱ�Ҷ��������ͼ�����ƴ�� [14, 26, 2, 16] �����ѡ����ͼƬ��index
indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
for i, index in enumerate(indices):
# Load image ÿ����һ��ͼƬ ��������ͼƬresize��self.size(h,w)
img, _, (h, w) = load_image(self, index)
# ���������load_mosaic�����IJ������� ���ǽ�ȡ����imgͼƬǶ��img9��(�������Ƕ�� �����ҵ���Ӧ��λ��)
# place img in img9
if i == 0: # center
img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
h0, w0 = h, w
c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
elif i == 1: # top
c = s, s - h, s + w, s
elif i == 2: # top right
c = s + wp, s - h, s + wp + w, s
elif i == 3: # right
c = s + w0, s, s + w0 + w, s + h
elif i == 4: # bottom right
c = s + w0, s + hp, s + w0 + w, s + hp + h
elif i == 5: # bottom
c = s + w0 - w, s + h0, s + w0, s + h0 + h
elif i == 6: # bottom left
c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
elif i == 7: # left
c = s - w, s + h0 - h, s, s + h0
elif i == 8: # top left
c = s - w, s + h0 - hp - h, s, s + h0 - hp
padx, pady = c[:2]
x1, y1, x2, y2 = [max(x, 0) for x in c] # allocate coords
# ������load_mosaic�����IJ������� �ҵ�mosaic9��ǿ���labels9��segments9
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
labels9.append(labels)
segments9.extend(segments)
# ���ɶ�Ӧ��img9ͼƬ(����Ӧλ�õ�ͼƬǶ��img9��)
img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
hp, wp = h, w # height, width previous
# Offset
yc, xc = [int(random.uniform(0, s)) for _ in self.mosaic_border] # mosaic center x, y
img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
# Concat/clip labels
labels9 = np.concatenate(labels9, 0)
labels9[:, [1, 3]] -= xc
labels9[:, [2, 4]] -= yc
c = np.array([xc, yc]) # centers
segments9 = [x - c for x in segments9]
for x in (labels9[:, 1:], *segments9):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img9, labels9 = replicate(img9, labels9) # replicate
# Augment ͬ������ ����ӱ任
img9, labels9 = random_perspective(img9, labels9, segments9,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img9, labels9
�÷���mosaicһ��,ֱ���滻����:
����Ȥ�����ѿ�������,�����õĺ����Ǻܶ�,Ч��ûmosaic�á�
10��random_perspective
\qquad ��������ǽ�������ӱ任,��mosaic���Ϻ��ͼƬ���������ת�����š�ƽ�ơ��ü�,�ӱ任,��resizeΪ�����Сimg_size��
random_perspective��������:
def random_perspective(img, targets=(), segments=(), degrees=10, translate=.1,
scale=.1, shear=10, perspective=0.0, border=(0, 0)):
"""�������������load_mosaic������mosaic����֮��
����ӱ任 ��mosaic���Ϻ��ͼƬ���������ת�����š�ƽ�ơ��ü�,�ӱ任,��resizeΪ�����Сimg_size
:params img: mosaic���Ϻ��ͼƬimg4 [2*img_size, 2*img_size]
���mosaic���ͼƬû��һ������α�ǩ��ʹ��targets, segmentsΪ�� �����һ������α�ǩ��ʹ��segments, targets��Ϊ��
:params targets: mosaic���Ϻ�ͼƬ����������label��ǩlabels4(�������Ļ�ͨ��segments2boxes������α�ǩת��Ϊ������ǩ) [N, cls+xyxy]
:params segments: mosaic���Ϻ�ͼƬ�����в�����label��Ϣ(����segments�����Ҳ��������gt) [m, x1y1....]
:params degrees: ��ת�����ž������
:params translate: ƽ�ƾ������
:params scale: ���ž������
:params shear: ��������
:params perspective: �ӱ任����
:params border: ����ȷ����������ͼƬ��С һ�����[-img_size, -img_size] ��ô��������ͼƬ��СΪ [img_size, img_size]
:return img: ͨ���ӱ任/����任���img [img_size, img_size]
:return targets: ͨ���ӱ任/����任���img��Ӧ�ı�ǩ [n, cls+x1y1x2y2] (ͨ��ɸѡ���)
"""
# �趨���ͼƬ�� H W
# border=-s // 2 �������ͼƬ�Ĵ�Сֱ�Ӽ��� [img_size, img_size, 3]
height = img.shape[0] + border[0] * 2 # # �������ͼ���H
width = img.shape[1] + border[1] * 2 # �������ͼ���W
# ============================ ��ʼ�任 =============================
# ��Ҫע�����,��ʵopencv��ʵ���˷���任��, ��������Ҫ�����ɷ���任����M
# Center ��������ƽ�ƾ���
C = np.eye(3)
C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
# Perspective �����ӱ任����
P = np.eye(3)
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
# Rotation and Scale ������ת�����ž���
R = np.eye(3) # ��ʼ��R = [[1,0,0], [0,1,0], [0,0,1]] (3, 3)
# a: ���������ת�Ƕ� ��Χ��(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
a = random.uniform(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
# s: ���������ת��ͼ������ű��� ��Χ��(1 - scale, 1 + scale)
# s = 2 ** random.uniform(-scale, scale)
s = random.uniform(1 - scale, 1 + scale)
# s = 2 ** random.uniform(-scale, scale)
# cv2.getRotationMatrix2D: ��ά��ת���ź���
# ���� angle:��ת�Ƕ� center: ��ת����(Ĭ�Ͼ���ͼ�������) scale: ��ת��ͼ������ű���
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear ���ü��о���
S = np.eye(3) # ��ʼ��T = [[1,0,0], [0,1,0], [0,0,1]]
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Translation ����ƽ�ƾ���
T = np.eye(3) # ��ʼ��T = [[1,0,0], [0,1,0], [0,0,1]] (3, 3)
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
# Combined rotation matrix @ ��ʾ����˷� ���ɷ���任����M
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
# ������任����M������ͼƬ��
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if perspective:
# �ӱ任���� ʵ����תƽ�����ű任���ƽ���߲���ƽ��
# ����������warpAffine����
img = cv2.warpPerspective(img, M, dsize=(width, height), borderValue=(114, 114, 114))
else:
# ����任���� ʵ����תƽ�����ű任���ƽ��������ƽ��
# image changed img [1472, 1472, 3] => [736, 736, 3]
# cv2.warpAffine: opencvʵ�ֵķ���任����
# ����: img: ��Ҫ�仯��ͼ�� M: �任���� dsize: ���ͼ��Ĵ�С flags: ��ֵ���������(int ����!)
# borderValue: (�ص�!)�߽����ֵ Ĭ�������,��Ϊ0��
img = cv2.warpAffine(img, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
# Visualize ���ӻ�
# import matplotlib.pyplot as plt
# ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
# ax[0].imshow(img[:, :, ::-1]) # base
# ax[1].imshow(img2[:, :, ::-1]) # warped
# Transform label coordinates
# ͬ����Ҫ������ǩ��Ϣ
n = len(targets)
if n:
# �ж��Ƿ����ʹ��segment��ǩ: ֻ��segments��Ϊ��ʱ�����ݼ����ж����gtҲ������gtʱ����ʹ��segment��ǩ use_segments=True
# �������ֻ������gtʱsegmentsΪ�� use_segments=False
use_segments = any(x.any() for x in segments)
new = np.zeros((n, 4)) # [n, 0+0+0+0]
# ���ʹ�õ���segments��ǩ(��ǩ�к��ж����gt)
if use_segments: # warp segments
# �ȶ�segment��ǩ�����ز���
# ����˵segment����ֻ��100��,ͨ��interp�����������Ϊn��(Ĭ��1000)
# [n, x1y2...x99y100] ��������-> [n, 500, 2]
# ��������ת,�ӱ任�Ȳ���,������Ҫ�Զ�������нǵ㶼���б任
segments = resample_segments(segments)
for i, segment in enumerate(segments): # segment: [500, 2] ����ε�500��������xy
xy = np.ones((len(segment), 3)) # [1, 1+1+1]
xy[:, :2] = segment # [500, 2]
# �Ըñ�ǩ����ε����ж������������/����任
xy = xy @ M.T # transform
xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
# ����segment������,ȡxy����������Сֵ,�õ��߿������ clip
new[i] = segment2box(xy, width, height) # xy [500, 2]
# ��ʹ��segments��ǩ ʹ�������ľ��εı�ǩtargets
else: # warp boxes
# ֱ�Ӷ�box��/����任
# ��������ת,�ӱ任�Ȳ���,������Ҫ���ĸ��ǵ㶼���б任
xy = np.ones((n * 4, 3))
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform ÿ���ǵ������
xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip ȥ��̫С��target(target���ܵ�ͼ��ȥ��)
new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
# filter candidates ����target ɸѡbox
# ���Ϳ��������wh_thr������ �ü���С�Ŀ�(���С�ڲü�ǰ��area_thr) �����ȷ�Χ��(1/ar_thr, ar_thr)֮�������
# ɸѡ��� [n] ȫ��True��False ʹ�ñ���: box1[i]���ɵõ�i�����е���True�ľ��ο� False�ľ��ο�ȫ��ɾ��
i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
# �õ���������������targets
targets = targets[i]
targets[:, 1:5] = new[i]
return img, targets
�������������load_mosaic������mosaic����֮������ӱ任/����任:
��������IJ�������hyp�е�5������:

Ч����ʾ1:mosaic
shape = (1280, 1280, 3)
Ч����ʾ2:mosaic + random_perspective
shape = (640, 640, 3)
11��box_candidates
\qquad �����������random_perspective��,�Ƕ��ӱ任���ͼƬlabel����ɸѡ,ȥ�����ü���С�Ŀ�(���С�ڲü�ǰ��area_thr) ���г��Ϳ��������wh_thr������,�ҳ����ȷ�Χ��(1/ar_thr, ar_thr)֮������ơ�
box_candidatesģ�����:
def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.1, eps=1e-16):
"""����random_perspective�� ���ӱ任���ͼƬlabel����ɸѡ
ȥ�����ü���С�Ŀ�(���С�ڲü�ǰ��area_thr) ���г��Ϳ��������wh_thr������,�ҳ����ȷ�Χ��(1/ar_thr, ar_thr)֮�������
Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
:params box1: [4, n]
:params box2: [4, n]
:params wh_thr: ɸѡ���� ������ֵ
:params ar_thr: ɸѡ���� ���߱ȡ��߿������ֵ��ֵ
:params area_thr: ɸѡ���� �����ֵ
:params eps: 1e-16 �ӽ�0���� ��ֹ��ĸΪ0
:return i: ɸѡ��� [n] ȫ��True��False ʹ�ñ���: box1[i]���ɵõ�i�����е���True�ľ��ο� False�ľ��ο�ȫ��ɾ��
"""
w1, h1 = box1[2] - box1[0], box1[3] - box1[1] # �������box1���ο�Ŀ��� [n] [n]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1] # �������box2���ο�Ŀ��� [n] [n]
ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # �������box2���ο�Ŀ��߱Ⱥ߿��ȵĽϴ��� [n, 1]
# ɸѡ����: ��ǿ��w��hҪ����2 ��ǿ��ͼ������ǿǰͼ�������ֵ����area_thr ���߱ȴ���ar_thr
return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
12��replicate
\qquad ������������ƫ�Ʊ�ǩ����,�����µı�ǩ��ԭ��ǩ��ϡ���������load_mosaic����mosaic����֮�� random_perspective����֮ǰ, ����Ĭ���ǹرյ�, �Լ�����ʵ��һ��Ч����
replicateģ�����:
def replicate(img, labels):
"""��������load_mosaic����mosaic����֮�� random_perspective����֮ǰ ����Ĭ���ǹرյ� �Լ�����ʵ��һ��Ч��
���ƫ�Ʊ�ǩ����,�����µı�ǩ��ԭ��ǩ��� Replicate labels
:params img: img4 ��Ϊ������mosaic����֮�� ����size=[2*img_size, 2*img_size]
:params labels: mosaic���Ϻ�ͼƬ����������label��ǩlabels4(�������Ļ�ͨ��segments2boxes������α�ǩת��Ϊ������ǩ) [N, cls+xyxy]
:return img: img4 size=[2*img_size, 2*img_size] ����ͼƬ�ж���һ��Ľ�Сgt����
:params labels: labels4 ��������������һ��Ľ�Сlabel [3/2N, cls+xyxy]
"""
h, w = img.shape[:2] # �õ�ͼƬ�ĸߺͿ�
boxes = labels[:, 1:].astype(int) # �õ�����gt��ľ������� xyxy [N, xyxy]
x1, y1, x2, y2 = boxes.T # ���Ͻ�: x1 y1 ���½�: x2 y2 [N]
s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels) [N] �õ�N��gt�� (w+h)/2 ��������gt��Ĵ�С
# ����ԭ��ǩ����һ����±�ǩ s.size����ndarray��Ԫ������
for i in s.argsort()[:round(s.size * 0.5)]: # ���ؽ�С(s��С)��һ��gt���index��Ϣ
x1b, y1b, x2b, y2b = boxes[i] # �õ���һ���Сgt���������Ϣ ���Ͻ�x1b y1b ���½�x2b y2b
bh, bw = y2b - y1b, x2b - x1b # �õ���һ���Сgt��ĸ߿���Ϣ
# ���ƫ�Ʊ�ǩ���ĵ� y��Χ��[0, ͼƬ��-gt���] x��Χ��[0, ͼƬ��-gt���]
yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
# ����������һ���gt��������Ϣ(ƫ�ƺ�)
x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
# ��ͼƬ����ʵ��gt��ƫ�Ƶ���Ӧ���ɵ�����(һ���С��ƫ�� �ϴ�IJ�ƫ��)
img[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# append ԭ����labels��ǩ + ƫ���˵ı�ǩ
labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
return img, labels
������load_mosaicload_mosaic����mosaic����֮�� random_perspective����֮ǰ(һ���ر� ���廹Ҫ������ʵ��):
ִ��Ч��

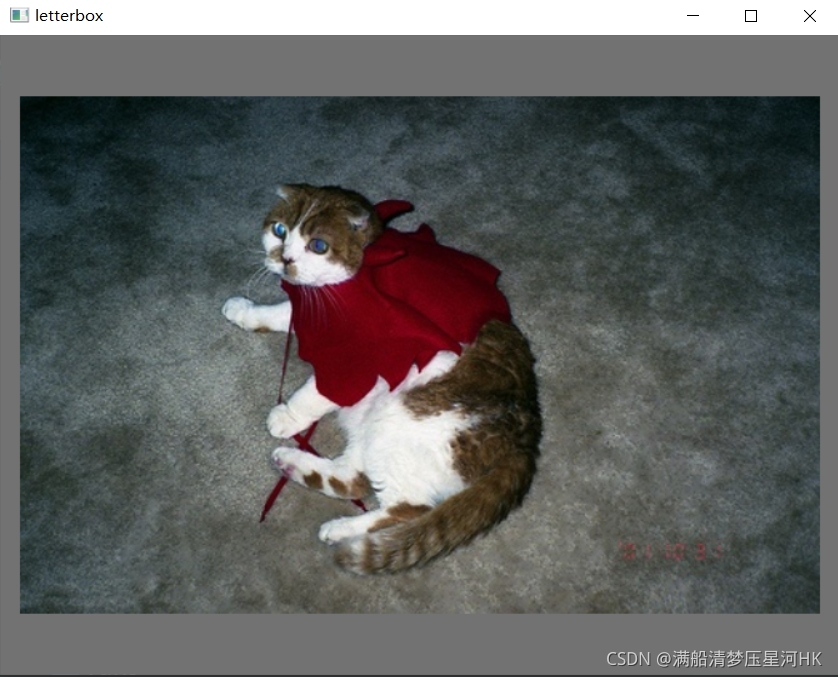
13��letterbox
letterbox ��imgת������
\qquad ��ʱ:auto=False(��Ҫpad), scale_fill=False, scale_up=False��
\qquad ��Ȼ,�ⲿ����Ҫ����,��Ϊ����֮ǰ��load_image�����Ѿ����Ź���(��ߵ���ָ����С,�϶̱ߵȱ�������),��ô��letterboxֻ��Ҫ�������С����Ҫ����pad, �ٽ���С������pad����Ӧ��С(ÿ��batch��Ҫÿ��ͼƬ�Ĵ�С,�����С�Dz���ͬ��)���ɡ�
Ҳ���Խ���һ�������ͼ�����������letterbox����:
letterboxģ�����:
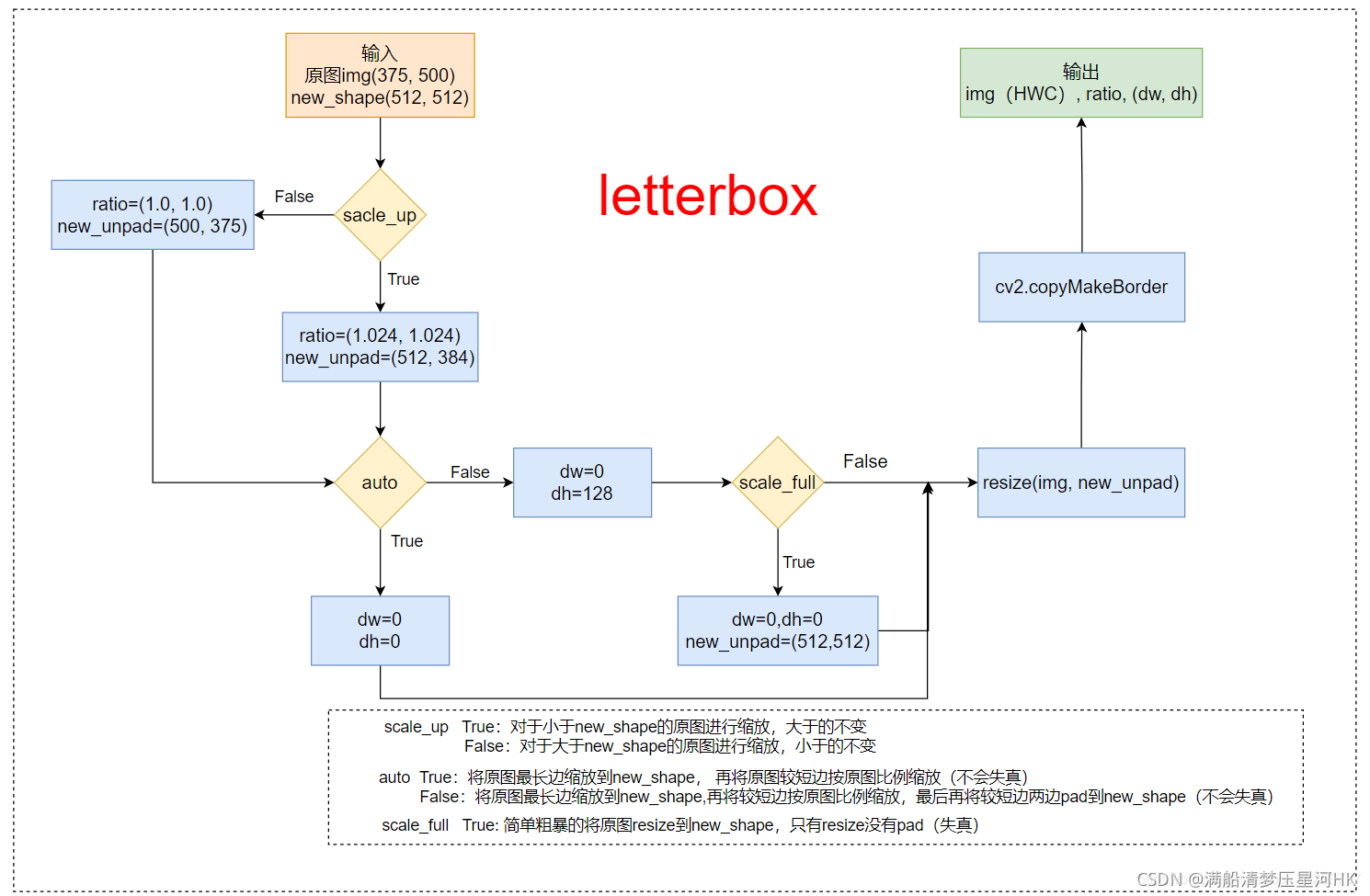
def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
"""����LoadImagesAndLabelsģ���__getitem__���� ֻ��valʱ�Ż�ʹ��
��ͼƬ���ŵ�����ָ����С
Resize and pad image while meeting stride-multiple constraints
https://github.com/ultralytics/yolov3/issues/232
:param img: ԭͼ hwc
:param new_shape: ���ź����ߴ�С
:param color: pad����ɫ
:param auto: True ��֤���ź��ͼƬ����ԭͼ�ı��� �� ��ԭͼ������ŵ�ָ����С,�ٽ�ԭͼ�϶̱߰�ԭͼ��������(����ʧ��)
False ��ԭͼ������ŵ�ָ����С,�ٽ�ԭͼ�϶̱߰�ԭͼ��������,��϶̱�����pad�������ŵ���ߴ�С(����ʧ��)
:param scale_fill: True �ֱ��Ľ�ԭͼresize��ָ���Ĵ�С �൱�ھ���resize û��pad����(ʧ��)
:param scale_up: True ����С��new_shape��ԭͼ��������,���ڵIJ���
False ���ڴ���new_shape��ԭͼ��������,С�ڵIJ���
:return: img: letterbox���ͼƬ HWC
ratio: wh ratios
(dw, dh): w��h��pad
"""
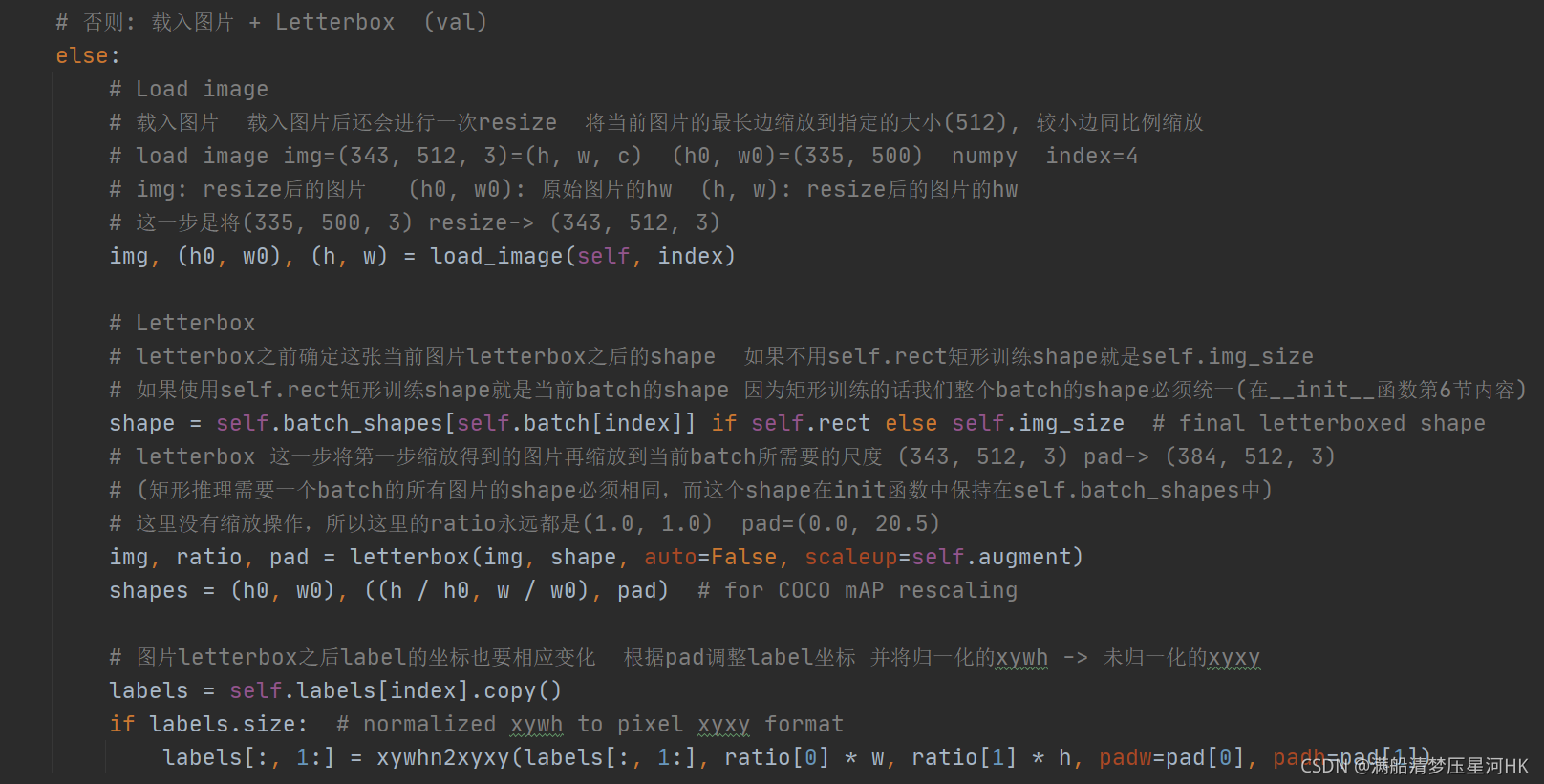
shape = img.shape[:2] # ��һ��resize��ͼƬ��С[h, w] = [343, 512]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape) # (512, 512)
# scale ratio (new / old) 1.024 new_shape=(384, 512)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) # r=1
# ֻ�����²��� ��Ϊ�ϲ�������ͼƬģ��
# (for better test mAP) scale_up = False ���ڴ���new_shape(r<1)��ԭͼ��������,С��new_shape(r>1)�IJ���
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios (1, 1)
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # wh(512, 343) ��֤���ź�ͼ���������
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding dw=0 dh=41
if auto: # minimum rectangle ��֤ԭͼ��������,��ͼ���������ŵ�ָ����С
# �����ȡ��������Ա�֤padding���ͼƬ��32��������(416x416),�����(512x512)���Ա�֤��64��������
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding dw=0 dh=0
elif scaleFill: # stretch �ֱ��Ľ�ͼƬ���ŵ�ָ���ߴ�
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
# �ڽ�С�ߵ��������pad, ��������һ��pad
dw /= 2 # divide padding into 2 sides ��padding�ֵ�����,�������� dw=0
dh /= 2 # dh=20.5
# shape:[h, w] new_unpad:[w, h]
if shape[::-1] != new_unpad: # resize ��ԭͼresize��new_unpad(������ͬ,������ͬ����ͼ)
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) # �������������padding # top=20 bottom=21
left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) # �������������padding # left=0 right=0
# add border/pad
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
# img: (384, 512, 3) ratio=(1.0,1.0) ����û�����Ų��� (dw,dh)=(0.0, 20.5)
return img, ratio, (dw, dh)
__getitem__��letterbox ��labelת������
�ܽ�����valʱ������Ҫ������������:
- load_image��ͼƬ���ļ��м��س���,��resize����Ӧ�ijߴ�(��ߵ���������Ҫ�ijߴ�,��̱ߵȱ�������);
- letterbox��֮ǰresize���ͼƬ��pad����������Ҫ�ķŵ�dataloader��(collate_fn����)�ijߴ�(����ѵ��Ҫ��ͬһ��batch�е�ͼƬ�ijߴ���뱣��һ��);
- ��label�����ԭͼ�ߴ�(ԭ�ļ���ͼƬ�ߴ�)���ŵ����letterbox pad���ͼƬ�ߴ硣��Ϊǰ�����ֵ�ͼƬ�ߴ緢���˱仯,ͬ�������ǵ�labelҲ��Ҫ������Ӧ�ı仯��
ִ��Ч��
14��cutout
\qquad cutout������ǿ,��ͼƬ������������С�ķ������� ,Ŀ������߷���������³���ԡ���������: https://arxiv.org/abs/1708.04552��
\qquad ����ԭ��ϸ���뿴����:��YOLO v4����trick 8��Data augmentation: MixUp��Random Erasing��CutOut��CutMix��Mosic��
\qquad ����Ҫ��Ҫʹ��,�����Ƕ��ٿ����Լ�ʵ�顣
cutoutģ�����:
def cutout(image, labels):
"""����LoadImagesAndLabelsģ���е�__getitem__��������cutout��ǿ v5Դ������Ĭ����û��������� ����Ȥ�Ŀ��Բ���һ��
cutout������ǿ, ��ͼƬ������������С�ķ������� Ŀ������߷���������³����
ʵ��:���ѡ��һ���̶���С������������,Ȼ�����ȫ0����OK��,��ȻΪ�˱������0ֵ��ѵ����Ӱ��,Ӧ��Ҫ�����ݽ������Ĺ�һ������,norm��0��
����: https://arxiv.org/abs/1708.04552
:params image: һ��ͼƬ [640, 640, 3] numpy
:params labels: ����ͼƬ�ı�ǩ [N, 5]=[N, cls+x1y1x2y2]
:return labels: ɸѡ�������ͼƬ�ı�ǩ [M, 5]=[M, cls+x1y1x2y2] M<N
ɸѡ: ���������ɵ�������ԭʼ��gt���ཻ����ռgt��̫�� ��ɸ�����gt��label
"""
h, w = image.shape[:2] # ��ȡͼƬ�ߺͿ�
def bbox_ioa(box1, box2):
"""����cutout��
����box1��box2�ཻ�����box2����ı���
Returns the intersection over box2 area given box1, box2. box1 is 4, box2 is nx4. boxes are x1y1x2y2
:params box1: ��������������� box [4] = [x1y1x2y2]
:params box2: ����ͼƬԭʼ��label��Ϣ [n, 4] = [n, x1y1x2y2]
:return [n, 1] ����һ�����ɵ�����box��n��ԭʼlabel���ཻ�����bԭʼlabel�ı�ֵ
"""
box2 = box2.transpose()
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
# ��box1��box2���ཻ���
inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
(np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
# box���
box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + 1e-16
# ����box1��box2�ཻ��� �� box2���֮��
return inter_area / box2_area
# ����cutout����������scale create random masks
scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
for s in scales:
# ����������� ����
mask_h = random.randint(1, int(h * s))
mask_w = random.randint(1, int(w * s))
# ����������� box
xmin = max(0, random.randint(0, w) - mask_w // 2)
ymin = max(0, random.randint(0, h) - mask_h // 2)
xmax = min(w, xmin + mask_w)
ymax = min(h, ymin + mask_h)
# ���������ɫ������ apply random color mask
image[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
# ����û��������label return unobscured labels
if len(labels) and s > 0.03:
box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32) # ������ɵ�����box
# �������ɵ�һ������box������ͼƬ������gt��box������ inter_area/label_area [n, 1]
ioa = bbox_ioa(box, labels[:, 1:5])
# remove>60% obscured labels �����е�̫�� ioa < 0.60 ����cutout�����ڵ�С��60%�ı�ǩ
labels = labels[ioa < 0.60]
return labels
��LoadImagesAndLabelsģ���е�__getitem__��������cutout��ǿ:
ִ��Ч��:

mixup��ǿ�ɳ���hyp[��mixup��]����,0��ر� Ĭ��Ϊ1��100%��(�Լ�ʵ���ж�):

15��mixup
\qquad ��������ǽ���mixup������ǿ:�������ں�����ͼƬ������:https://arxiv.org/pdf/1710.09412.pdf��
\qquad ����ԭ��ϸ���뿴����:��YOLO v4����trick 8��Data augmentation: MixUp��Random Erasing��CutOut��CutMix��Mosic��
\qquad ����Ҫ��Ҫʹ��,�����Ƕ��ٿ����Լ�ʵ�顣
mixupģ�����:
def mixup(im, labels, im2, labels2):
"""����LoadImagesAndLabelsģ���е�__getitem__��������mixup��ǿ
mixup������ǿ, �������ں�����ͼƬ Applies MixUp augmentation
����: https://arxiv.org/pdf/1710.09412.pdf
:params im:ͼƬ1 numpy (640, 640, 3)
:params labels:[N, 5]=[N, cls+x1y1x2y2]
:params im2:ͼƬ2 (640, 640, 3)
:params labels2:[M, 5]=[M, cls+x1y1x2y2]
:return img: ����ͼƬmixup��ǿ���ͼƬ (640, 640, 3)
:return labels: ����ͼƬmixup��ǿ���label��ǩ [M+N, cls+x1y1x2y2]
"""
# �����beta�ֲ��л�ȡ����,range[0, 1]
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
# ���ձ����ں�����ͼƬ
im = (im * r + im2 * (1 - r)).astype(np.uint8)
# ������ͼƬ��ǩƴ�ӵ�һ��
labels = np.concatenate((labels, labels2), 0)
return im, labels
��LoadImagesAndLabelsģ���е�__getitem__��������mixup��ǿ:
ִ��Ч��:

mixup��ǿ�ɳ���hyp[��mixup��]����,0��ر� Ĭ��Ϊ1��100%��(�Լ�ʵ���ж�):
16��LoadImages��LoadStreams��LoadWebcam
\qquad load �ļ����е�ͼƬ/��Ƶ + �õ����� load web��ҳ�е����ݡ�
ȫ������:
class LoadImages: # for inference
"""��detect.py��ʹ��
load �ļ����е�ͼƬ/��Ƶ
��������� ����detect.py
"""
def __init__(self, path, img_size=640, stride=32):
p = str(Path(path).absolute()) # os-agnostic absolute path
# glob.glab: ��������ƥ����ļ�·���б� files: ��ȡͼƬ����·��
if '*' in p:
# ���p�Dz���������ʽ��ȡͼƬ/��Ƶ, ����ʹ��glob��ȡ�ļ�·��
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
# ���p��һ���ļ���,ʹ��glob��ȡȫ���ļ�·��
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p):
# ���p���ļ���ֱ�ӻ�ȡ
files = [p] # files
else:
raise Exception(f'ERROR: {p} does not exist')
# images: Ŀ¼������ͼƬ��ͼƬ�� videos: Ŀ¼��������Ƶ����Ƶ��
images = [x for x in files if x.split('.')[-1].lower() in img_formats]
videos = [x for x in files if x.split('.')[-1].lower() in vid_formats]
# ͼƬ����Ƶ����
ni, nv = len(images), len(videos)
self.img_size = img_size
self.stride = stride # �����²�����
self.files = images + videos # ����ͼƬ����Ƶ·����һ���б�
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv # �Dz���video
self.mode = 'image' # Ĭ���Ƕ�imageģʽ
if any(videos):
# �ж���û��video�ļ� �������video�ļ�,���ʼ��opencv�е���Ƶģ��,cap=cv2.VideoCapture��
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nf > 0, f'No images or videos found in {p}. ' \
f'Supported formats are:\nimages: {img_formats}\nvideos: {vid_formats}'
def __iter__(self):
"""������"""
self.count = 0
return self
def __next__(self):
"""��iterһ����?"""
if self.count == self.nf: # ���ݶ�����
raise StopIteration
path = self.files[self.count] # ��ȡ��ǰ�ļ�·��
if self.video_flag[self.count]: # �жϵ�ǰ�ļ��Ƿ�����Ƶ
# Read video
self.mode = 'video'
# ��ȡ��ǰ֡����,ret_valΪһ��bool����,ֱ����Ƶ��ȡ���֮ǰ��ΪTrue
ret_val, img0 = self.cap.read()
# �����ǰ��Ƶ��ȡ����,���ȡ��һ����Ƶ
if not ret_val:
self.count += 1
self.cap.release()
# self.count == self.nf��ʾ��Ƶ�Ѿ���ȡ����
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1 # ��ǰ��ȡ��Ƶ��֡��
print(f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: ', end='')
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
assert img0 is not None, 'Image Not Found ' + path
print(f'image {self.count}/{self.nf} {path}: ', end='')
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB and HWC to CHW
img = np.ascontiguousarray(img)
# ����·��, resize+pad��ͼƬ, ԭʼͼƬ, ��Ƶ����
return path, img, img0, self.cap
def new_video(self, path):
# ��¼֡��
self.frame = 0
# ��ʼ����Ƶ����
self.cap = cv2.VideoCapture(path)
# �õ���Ƶ�ļ��е���֡��
self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
def __len__(self):
return self.nf # number of files
class LoadStreams:
"""
load �ļ�������Ƶ��
multiple IP or RTSP cameras
��������� ����detect.py
"""
def __init__(self, sources='streams.txt', img_size=640, stride=32):
self.mode = 'stream' # ��ʼ��modeΪimages
self.img_size = img_size
self.stride = stride # ����²�������
# ���sourcesΪһ�������˶����Ƶ�����ļ� ��ȡÿһ����Ƶ��,����Ϊһ���б�
if os.path.isfile(sources):
with open(sources, 'r') as f:
sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
else:
# ��֮,ֻ��һ����Ƶ���ļ���ֱ�ӱ���
sources = [sources]
n = len(sources) # ��Ƶ������
# ��ʼ��ͼƬ fps ��֡�� �߳���
self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
self.sources = [clean_str(x) for x in sources] # clean source names for later
# ����ÿһ����Ƶ��
for i, s in enumerate(sources): # index, source
# Start thread to read frames from video stream
# ��ӡ��ǰ��Ƶindex/����Ƶ��/��Ƶ����ַ
print(f'{i + 1}/{n}: {s}... ', end='')
if 'youtube.com/' in s or 'youtu.be/' in s: # if source is YouTube video
check_requirements(('pafy', 'youtube_dl'))
import pafy
s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam ��������ͷ
# s='0'��������ͷ,�������Ƶ����ַ
cap = cv2.VideoCapture(s)
assert cap.isOpened(), f'Failed to open {s}'
# ��ȡ��Ƶ�Ŀ��ͳ�
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# ��ȡ��Ƶ��֡��
self.fps[i] = max(cap.get(cv2.CAP_PROP_FPS) % 100, 0) or 30.0 # 30 FPS fallback
# ֡��
self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
# ��ȡ��ǰ����
_, self.imgs[i] = cap.read() # guarantee first frame
# �������̶߳�ȡ��Ƶ��,daemon��ʾ���߳̽���ʱ���߳�Ҳ����
self.threads[i] = Thread(target=self.update, args=([i, cap]), daemon=True)
print(f" success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
self.threads[i].start()
print('') # newline
# check for common shapes
# ��ȡ����resize+pad֮���shape,letterbox����Ĭ��(����auto=True)�ǰ��վ��������������
s = np.stack([letterbox(x, self.img_size, stride=self.stride)[0].shape for x in self.imgs], 0) # shapes
self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
if not self.rect:
print('WARNING: Different stream shapes detected. For optimal performance supply similarly-shaped streams.')
def update(self, i, cap):
# Read stream `i` frames in daemon thread
n, f = 0, self.frames[i]
while cap.isOpened() and n < f:
n += 1
# _, self.imgs[index] = cap.read()
cap.grab()
# ÿ4֡��ȡһ��
if n % 4: # read every 4th frame
success, im = cap.retrieve()
self.imgs[i] = im if success else self.imgs[i] * 0
time.sleep(1 / self.fps[i]) # wait time
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
cv2.destroyAllWindows()
raise StopIteration
# Letterbox
img0 = self.imgs.copy()
img = [letterbox(x, self.img_size, auto=self.rect, stride=self.stride)[0] for x in img0]
# Stack ����ȡ��ͼƬƴ�ӵ�һ��
img = np.stack(img, 0)
# Convert
img = img[:, :, :, ::-1].transpose(0, 3, 1, 2) # BGR to RGB and BHWC to BCHW
img = np.ascontiguousarray(img)
return self.sources, img, img0, None
def __len__(self):
return 0 # 1E12 frames = 32 streams at 30 FPS for 30 years
class LoadWebcam: # for inference
"""�õ����� load web��ҳ�е�����"""
def __init__(self, pipe='0', img_size=640, stride=32):
self.img_size = img_size
self.stride = stride
if pipe.isnumeric():
pipe = eval(pipe) # local camera
# pipe = 'rtsp://192.168.1.64/1' # IP camera
# pipe = 'rtsp://username:password@192.168.1.64/1' # IP camera with login
# pipe = 'http://wmccpinetop.axiscam.net/mjpg/video.mjpg' # IP golf camera
self.pipe = pipe
self.cap = cv2.VideoCapture(pipe) # video capture object
self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if cv2.waitKey(1) == ord('q'): # q to quit
self.cap.release()
cv2.destroyAllWindows()
raise StopIteration
# Read frame
if self.pipe == 0: # local camera
ret_val, img0 = self.cap.read()
img0 = cv2.flip(img0, 1) # flip left-right
else: # IP camera
n = 0
while True:
n += 1
self.cap.grab()
if n % 30 == 0: # skip frames
ret_val, img0 = self.cap.retrieve()
if ret_val:
break
# Print
assert ret_val, f'Camera Error {self.pipe}'
img_path = 'webcam.jpg'
print(f'webcam {self.count}: ', end='')
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB and HWC to CHW
img = np.ascontiguousarray(img)
return img_path, img, img0, None
def __len__(self):
return 0
��detect.py��ʹ��:
17��hist_equalize
\qquad ������������ڶ�ͼƬ����ֱ��ͼ���⻯����,������yolov5�в�û���õ����������,ѧϰ�˽��¾ͺ�,�����ص㡣
hist_equalizeģ�����:
def hist_equalize(img, clahe=True, bgr=False):
"""yolov5��û��ʹ��ֱ��ͼ���⻯����ǿ���� �����Լ�����
ֱ��ͼ���⻯��ǿ���� Equalize histogram on BGR image 'img' with img.shape(n,m,3) and range 0-255
:params img: Ҫ����ֱ��ͼ���⻯��ԭͼ
:params clahe: �Ƿ�Ҫ��������Ӧ���⻯ͼƬ Ĭ��True �����False������ȫ�־��⻯ͼƬ
:params bgr: �����imgͼ���Ƿ���bgrͼƬ Ĭ��False
:return img: ���⻯֮���ͼƬ ��С���� ��ʽRGB
"""
# ͼƬBGR/RGB��ʽ -> YUV��ʽ
yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
if clahe:
# cv2.createCLAHE��������Ӧ���⻯ͼ��
c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
yuv[:, :, 0] = c.apply(yuv[:, :, 0])
else:
# ȫ�־��⻯
yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
����ʵ��:
if __name__ == '__main__':
img1 = cv2.imread("F:\yolo_v5\datasets\coco128\images\\train2017\\000000000036.jpg")
img2 = hist_equalize(img1)
cv2.imshow("hist_equalize_before", img1)
cv2.imshow("hist_equalize_after", img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
ʵ����:

18��create_folder
\qquad create_folder�������ڴ���һ���µ��ļ��С������������flatten_recursive�����С�
create_folder��������:
def create_folder(path='./new'):
"""����flatten_recursive������
�����ļ��� Create folder
"""
# ���path�����ļ���,���Ƴ�
if os.path.exists(path):
shutil.rmtree(path) # delete output folder
# �ٴ����½�����ļ���
os.makedirs(path) # make new output folder
19��flatten_recursive
\qquad ���ģ���ǽ�һ���ļ�·���е������ļ����Ƶ���һ���ļ����� ����image�ļ���label�ļ��ŵ�һ�����ļ����С�
flatten_recursiveģ�����:
def flatten_recursive(path='../../datasets/coco128'):
"""û�õ� ���Ǻ���Ҫ �Լ����þ���
��һ���ļ�·���е������ļ����Ƶ���һ���ļ����� ����image�ļ���label�ļ��ŵ�һ�����ļ�����
Flatten a recursive directory by bringing all files to top level
"""
new_path = Path(path + '_flat') # '..\datasets\coco128_flat'
create_folder(new_path)
for file in tqdm(glob.glob(str(Path(path)) + '/**/*.*', recursive=True)):
# shutil.copyfile: �����ļ�����һ���ļ�����
shutil.copyfile(file, new_path / Path(file).name)
�Լ���:
if __name__ == '__main__':
flatten_recursive()
��:

20��extract_boxes
\qquad ���ģ���ǽ�Ŀ�������ݼ�ת��Ϊ�������ݼ� ,��������: ��Ŀ�������ݼ��е�ÿһ��gt�� �����洢����Ӧ���ļ����С�
def extract_boxes(path='../../datasets/coco128'):
"""����ʹ�� ���ɷ������ݼ�
��Ŀ�������ݼ�ת��Ϊ�������ݼ� ��������: ��Ŀ�������ݼ��е�ÿһ��gt�� �����洢����Ӧ���ļ�����
Convert detection dataset into classification dataset, with one directory per class
ʹ��: from utils.datasets import *; extract_boxes()
:params path: ���ݼ���ַ
"""
path = Path(path) # images dir ���ݼ��ļ�Ŀ¼ Ĭ��'..\datasets\coco128'
# remove existing path / 'classifier' �ļ���
shutil.rmtree(path / 'classifier') if (path / 'classifier').is_dir() else None
files = list(path.rglob('*.*')) # �ݹ����path�ļ��µ�'*.*'�ļ�
n = len(files) # number of files
for im_file in tqdm(files, total=n):
if im_file.suffix[1:] in img_formats: # �������ͼƬ�ļ�
# image
im0 = cv2.imread(str(im_file)) # BGR
im = im0[..., ::-1] # BGR to RGB
h, w = im.shape[:2] # �õ�����ͼƬh w
# labels ��������ͼƬ��·���ҵ�����ͼƬ��label·��
lb_file = Path(img2label_paths([str(im_file)])[0])
if Path(lb_file).exists():
with open(lb_file, 'r') as f:
lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # ��ȡlabel�ĸ���: ��Ӧ����gt����
for j, x in enumerate(lb): # ����ÿһ��gt
c = int(x[0]) # class
# ������'file_name path\classifier\class_index\image_name'
# ��: 'F:\yolo_v5\datasets\coco128\images\train2017\classifier\45\train2017_000000000009_0.jpg'
f = (path / 'classifier') / f'{c}' / f'{path.stem}_{im_file.stem}_{j}.jpg' # new filename
# f.parent: 'F:\yolo_v5\datasets\coco128\images\train2017\classifier\45'
if not f.parent.is_dir():
# ÿһ�����ĵ�һ����Ƭ���ȥ֮ǰ �ȴ�����Ӧ����ļ���
f.parent.mkdir(parents=True)
b = x[1:] * [w, h, w, h] # box normalized to ������С
# b[2:] = b[2:].max() pad: rectangle to square
b[2:] = b[2:] * 1.2 + 3 # pad
b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int) # xywh to xyxy
# ��ֹb���� clip boxes outside of image
b[[0, 2]] = np.clip(b[[0, 2]], 0, w)
b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
assert cv2.imwrite(str(f), im0[b[1]:b[3], b[0]:b[2]]), f'box failure in {f}'
����ʹ��:
if __name__ == '__main__':
extract_boxes()
���ɽ��:

�������ݼ�λ��:

����ֺ�:

person��(0��):
21��autosplit
\qquad ���ģ���ǽ����Զ��������ݼ�����ʹ���Լ����ݼ�ʱ,���������ģ��������л������ݼ���
autosplitģ�����:
def autosplit(path='../../datasets/coco128/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
"""����ʹ�� ���л������ݼ�
�Զ������ݼ�����Ϊtrain/val/test������ path/autosplit_*.txt files
Usage: from utils.datasets import *; autosplit()
:params path: ���ݼ�imageλ��
:params weights: ����Ȩ�� Ĭ�Ϸֱ���(0.9, 0.1, 0.0) ��Ӧ(train, val, test)
:params annotated_only: Only use images with an annotated txt file
"""
path = Path(path) # images dir
# ��ȡimages�����е�ͼƬ image files only
files = sum([list(path.rglob(f"*.{img_ext}")) for img_ext in img_formats], [])
n = len(files) # number of files
random.seed(0) # ���������
# assign each image to a split ����(train, val, test)Ȩ�ػ���ԭʼͼƬ���ݼ�
# indices: [n] 0, 1, 2 �ֱ��ʾ���ݼ���ÿһ��ͼƬ�����ĸ����ݼ� �ֱ��Ӧ��(train, val, test)
indices = random.choices([0, 1, 2], weights=weights, k=n) #
txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
[(path.parent / x).unlink(missing_ok=True) for x in txt] # remove existing txt
print(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
for i, img in tqdm(zip(indices, files), total=n):
if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
with open(path.parent / txt[i], 'a') as f:
f.write('./' + img.relative_to(path.parent).as_posix() + '\n') # add image to txt file
����ʹ��:
if __name__ == '__main__':
autosplit()
���ֽ��:

22��dataset_stats
\qquad ���ģ����ͳ�����ݼ�����Ϣ����״̬�ֵ䡣����: ÿ������ͼƬ���� + ÿ������ʵ��������
dataset_statsģ�����:
def dataset_stats(path='../data/coco128.yaml', autodownload=False, verbose=False):
"""yolov5���ݼ�û���� ����ʹ��
���ģ����ͳ�����ݼ�����Ϣ����״̬�ֵ� ����: ÿ������ͼƬ���� ÿ������ʵ������
Return dataset statistics dictionary with images and instances counts per split per class
Usage: from utils.datasets import *; dataset_stats('coco128.yaml', verbose=True)
:params path: ���ݼ���Ϣ data.yaml
:params autodownload: Attempt to download dataset if not found locally
:params verbose: print���ӻ���ӡ
:return stats: ͳ�Ƶ����ݼ���Ϣ ��ϸ���ܿ�����
"""
def round_labels(labels):
# Update labels to integer class and 6 decimal place floats
return [[int(c), *[round(x, 6) for x in points]] for c, *points in labels]
with open(check_file(path), encoding='utf-8') as f:
data = yaml.safe_load(f) # data dict # coco.yaml�����ֵ�
data['path'] = "../../datasets/coco128" # ���ݼ���ַ
check_dataset(data, autodownload) # ������ݼ��Ƿ���� download dataset if missing
nc = data['nc'] # ���ݼ���� number of classes
stats = {'nc': nc, 'names': data['names']} # statistics dictionary
for split in 'train', 'val', 'test': # ��train��val��testͳ�����ݼ���Ϣ
if data.get(split) is None:
stats[split] = None # i.e. no test set
continue
x = []
dataset = LoadImagesAndLabels(data[split], augment=False, rect=True) # load dataset
if split == 'train': # ѵ����ֱ�Ӷ�ȡ��Ӧλ�õ�label.cache�ļ� ֱ�ӾͿ��Զ������ݼ���Ϣ
cache_path = Path(dataset.label_files[0]).parent.with_suffix('.cache') # *.cache path
# ͳ�����ݼ�ÿ��ͼƬlabel��ÿ�����gt��ĸ���
# x: {list: img_num} ÿ��list[class_num] ÿ��ͼƬ��label��ÿ�����gt��ĸ���
for label in tqdm(dataset.labels, total=dataset.n, desc='Statistics'):
x.append(np.bincount(label[:, 0].astype(int), minlength=nc))
x = np.array(x) # list to numpy���� [img_num, class_num]
# �ֱ�ͳ��train��val��test�������ݼ���������Ϣ
# ����: 'image_stats': �ֵ�dict ͼƬ����total û�б�ǩ���ļ�����unlabelled ���ݼ�ÿ������gt����[80]
# 'instance_stats': �ֵ�dict ���ݼ�������ͼƬ������gt����total ���ݼ���ÿ������gt����[80]
# 'labels': �ֵ�dict key=���ݼ���ÿ��ͼƬ���ļ��� value=ÿ��ͼƬ��Ӧ��label��Ϣ [n, cls+xywh]
stats[split] = {'instance_stats': {'total': int(x.sum()), 'per_class': x.sum(0).tolist()},
'image_stats': {'total': dataset.n, 'unlabelled': int(np.all(x == 0, 1).sum()),
'per_class': (x > 0).sum(0).tolist()},
'labels': [{str(Path(k).name): round_labels(v.tolist())} for k, v in
zip(dataset.img_files, dataset.labels)]}
# Save, print and return ͳ����Ϣstats
with open(cache_path.with_suffix('.json'), 'w') as f:
json.dump(stats, f) # save stats *.json
if verbose: # print���ӻ�
print(json.dumps(stats, indent=2, sort_keys=False))
# print(yaml.dump([stats], sort_keys=False, default_flow_style=False))
return stats
����ʹ��:
if __name__ == '__main__':
dataset_stats()
ִ��Ч��:

�ܽ�
\qquad ����ļ���Ҫ���е���������ǿ����������1-7С���Ǻ�train.py��������������+������ǿ����;2-15�Ǿ����������ǿʵ�ֺ���;16������������ģ��,���� load �ļ����е�ͼƬ/��Ƶ + �õ����� load web��ҳ�е�����;���һ�����������ݼ�����չ���ܡ�����ѧϰǰ����������,������������ѧϰ�˽��¼��ɡ�
�C2021.08.28 21.54