Ŀ¼
˼·����
������:���Ƚ������ݷ���,���������ݱ���Ӧ����Ϣ���ݼ��ԶԱ�,�������ݽ���������;������ְ�;�������ݼ�,��ѡ�á�latin-1���ı��뷽ʽ(���¼��ݶ�),ɾȥһЩͳ�ƴ��������(����ɾ��),ɾȥ��happiness��Ŀ����,�ϲ�ѵ��������Լ�;�鿴���ݵĻ�����Ϣ��
����Ԥ����:�ȱʧֵ,�������������ݼ���Ϣ�鿴������Ӧ����˼,���ݳ�ʶ��ȱʧֵ������Ӧ�ж�(�����뷨)�������,����ȱʧֵ���������ݵ�ƽ��ֵ���������Ⱥ���ֵ���;�������ʽ�����ݽ��д���,��������������ϵ����(����:�õ���ʱ�����ݼ�ȥ������ݵõ�����,��������ֲ�,������ֵת��Ϊ��ɢֵ);�Դ���ֵ���д���,�ο��������ݼ������ݽ��к������ж�;
��������:��һ����������֮��Ĺ�ϵ,����������(����:����ȡ�����ָ��)�����ォԭ��131ά���������䵽��272ά��Ȼ��ɾȥ��ֵ�ر��ٺ�֮ǰʹ�ù�������,���õ�263��������
��������:�����������������������һ�鼴Ϊ�ոչ�����ԭʼ���ݼ�;�ڶ���Ϊ��LightGBMѡ��263������������Ҫ��49������,����ÿ����������Ҫ��,������Ҫ������,ѡ��ͼ������ǰ��49������Ҫ����;������Ϊ������Ҫ����ɢ�ͱ�������one-hot�����ϳɵ����ݼ�,��383ά��
�������ͽ�ģ:����lightgbm��xgboost�ȶ���ģ�Ͷ�ԭʼ263ά���ݽ��н�ģ,�õ�Ԥ����,Ȼ��Եõ��Ľ������ģ���ں�����ѧϰ(stacking),�õ��ںϺ��Ԥ����;�編���ƶ�����Ҫ��49ά���ݼ���one-hot������383ά���ݼ����д���,�õ����ߵ�Ԥ����;��������ά�����ݼ���Ԥ��������ģ���ں�,�õ����ս��(����������ʵ��������,�ٸ�����:����������������A��B��C,Ȼ��A��������4��ģ��ȥ��,�õ�A1��A2��A3��A4��Ԥ����,������Ԥ����ģ���ںϵõ�ASԤ����,ͬ����B��C�����ݽ��д���,�õ�BS��CSԤ����,���,��AS��BS��CS�����������ں�,�õ����ս��S)
ģ�ͱ���:���Ϊcsv�ȸ�ʽ,��������Ԥ�����ֵΪ1-5������ֵ,�������ǵ�ground truth������ֵ,����Ϊ�˽�һ���Ż����ǵĽ��,���ǶԽ������������Ľ��ƴ�����(����:ֵ����1.96,С��2.04��ֱ����Ϊ����2)
һ����������
1����������
�Ҹ�����һ�����϶���̵Ļ���,������������ķ������Ҹ�����ص����س�ǧ�������˶���,�����������,С��·�߿�����,������Ҹ��в���Ӱ�졣��Щ���۸��ӵ�������,�������ҵ����еĹ���,һ���Ҹ��е�Ҫ����?
����,������ѧ����,�Ҹ��е��о�ռ����Ҫ��λ�á�����漰����ѧ������ѧ�����ѧ������ѧ�ȶѧ�ƵĻ��⸴�Ӷ���Ȥ;ͬʱ��������ϢϢ���,ÿ���˶��Ҹ��ж����Լ��ĺ�����������ܷ���Ӱ���Ҹ��еĹ���,�������Dz��ǽ���һЩ��Ȥ;������ҵ�Ӱ���Ҹ��е���������,�����Ż���Դ����������������Ҹ��С�Ŀǰ����ѧ�о�ע�ر����Ŀɽ����Ժ�δ�����ߵ����,��Ҫ���������Իع�����ع�ķ���,�����롢������ְҵ���罻��ϵ�����з�ʽ�Ⱦ����˿�����;�Լ�������������۾��û�����˰���Ⱥ������������һϵ�е��Ʋ�ͷ��֡�
�ð���Ϊ�Ҹ���Ԥ����һ�������,ϣ������������ѧ�о���������ά�ȵ��㷨����,��϶�ѧ�Ƹ�������,�ھ�DZ�ڵ�Ӱ������,���ָ���ɽ��͡����������ع�ϵ��
������˵,�ð�������һ�������ھ����͵ı��������Ҹ���Ԥ���baseline��������˵,������Ҫʹ�ð����������(�Ա����䡢����ְҵ��������������������ò�ȵ�)����ͥ����(��ĸ����ż����Ů����ͥ�ʱ��ȵ�)�����̬��(��ƽ�����á���������ȵ�)��139ά�ȵ���Ϣ��Ԥ������Ҹ��е�Ӱ�졣
���ǵ�������Դ�ڹ��ҹٷ��ġ��й��ۺ�������(CGSS)���ļ��еĵ������е�����,������Դ�ɿ���������
2��������Ϣ
����Ҫ��ʹ������ 139 ά������,ʹ�� 8000 �������ݽ��ж��ڸ����Ҹ��е�Ԥ��(Ԥ��ֵΪ1,2,3,4,5,����1�����Ҹ������,5�����Ҹ������)�� ��Ϊ���ǵ����������϶�,���ֱ������ϵ����,���ݷ�Ϊ������;�������ࡣ�ɴӾ����������Ϥ�����,ʹ���������ھ������Ϣ����������ֱ��ʹ��������������ݡ�����Ҳ������index�ļ��а���ÿ��������Ӧ���ʾ���Ŀ,�Լ�����ȡֵ�ĺ���;survey�ļ���Ϊԭ���ʾ�,��Ϊ�����Է����������ⱳ����
3������ָ��
���յ�����ָ��Ϊ�������MSE,��:
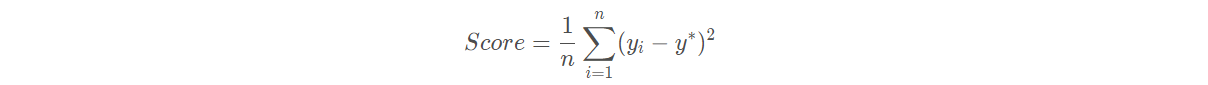
��������������
import os
import time
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from datetime import datetime
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score, roc_curve, mean_squared_error,mean_absolute_error, f1_score
import lightgbm as lgb
import xgboost as xgb
from sklearn.ensemble import RandomForestRegressor as rfr
from sklearn.ensemble import ExtraTreesRegressor as etr
from sklearn.linear_model import BayesianRidge as br
from sklearn.ensemble import GradientBoostingRegressor as gbr
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import LinearRegression as lr
from sklearn.linear_model import ElasticNet as en
from sklearn.kernel_ridge import KernelRidge as kr
from sklearn.model_selection import KFold, StratifiedKFold,GroupKFold, RepeatedKFold
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn import preprocessing
import logging
import warnings
warnings.filterwarnings('ignore') #����warning
ע�����ﰲװlightgbmʱ,Ҫָ���汾��Ϊ2.0.3
pip install lightgbm==2.0.3
�������ݵ��뼰Ԥ����
1�����ݵ���
#�������ݼ�
#latin-1���¼���ASCII
train = pd.read_csv("train.csv", parse_dates=['survey_time'],encoding='latin-1')
test = pd.read_csv("test.csv", parse_dates=['survey_time'],encoding='latin-1')
#ɾȥ�쳣���� ɾȥ"happiness" Ϊ-8����
train = train[train["happiness"]!=-8].reset_index(drop=True)
train_data_copy = train.copy()
target_col = "happiness" #Ŀ����
#�����Ŀ����ʲô?
#��:Ŀ���DZ����ظ�����,����train��test����������ϲ�
target = train_data_copy[target_col]
del train_data_copy[target_col]
# ����ϲ�
data = pd.concat([train_data_copy,test],axis=0,ignore_index=True)
data.shape
(10956, 139)
train.happiness.describe()

2������Ԥ����
2.1���쳣ֵ����
#make feature +5
#csv���и���ֵ:-1��-2��-3��-8,��������Ϊ�����������,���Dz�ɾȥ
def getres1(row):
return len([x for x in row.values if type(x)==int and x<0])
def getres2(row):
return len([x for x in row.values if type(x)==int and x==-8])
def getres3(row):
return len([x for x in row.values if type(x)==int and x==-1])
def getres4(row):
return len([x for x in row.values if type(x)==int and x==-2])
def getres5(row):
return len([x for x in row.values if type(x)==int and x==-3])
#�������
data['neg1'] = data[data.columns].apply(lambda row:getres1(row),axis=1)
data.loc[data['neg1']>20,'neg1'] = 20 #ƽ������,������20��
data['neg2'] = data[data.columns].apply(lambda row:getres2(row),axis=1)
data['neg3'] = data[data.columns].apply(lambda row:getres3(row),axis=1)
data['neg4'] = data[data.columns].apply(lambda row:getres4(row),axis=1)
data['neg5'] = data[data.columns].apply(lambda row:getres5(row),axis=1)
�������:
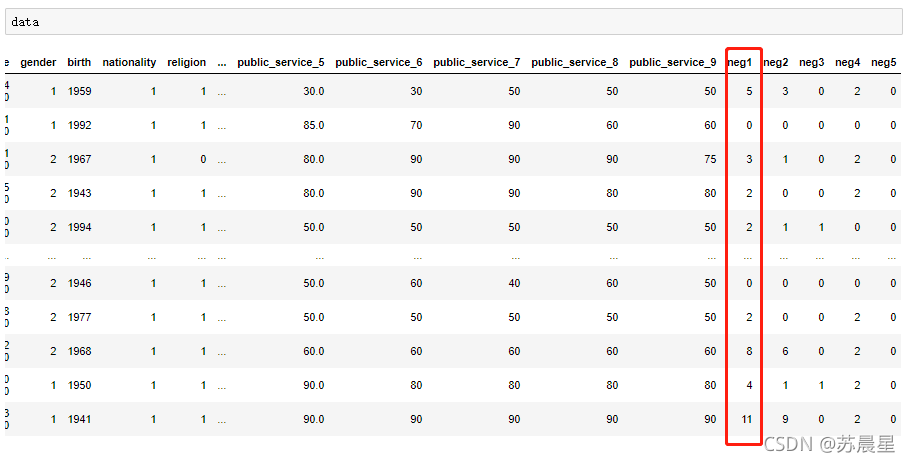
#���ȱʧֵ ��25�� ȥ��4�� ���21��
#���µ��ж���ȱʡ��,������
data['work_status'] = data['work_status'].fillna(0)
data['work_yr'] = data['work_yr'].fillna(0)
data['work_manage'] = data['work_manage'].fillna(0)
data['work_type'] = data['work_type'].fillna(0)
data['edu_yr'] = data['edu_yr'].fillna(0)
data['edu_status'] = data['edu_status'].fillna(0)
data['s_work_type'] = data['s_work_type'].fillna(0)
data['s_work_status'] = data['s_work_status'].fillna(0)
data['s_political'] = data['s_political'].fillna(0)
data['s_hukou'] = data['s_hukou'].fillna(0)
data['s_income'] = data['s_income'].fillna(0)
data['s_birth'] = data['s_birth'].fillna(0)
data['s_edu'] = data['s_edu'].fillna(0)
data['s_work_exper'] = data['s_work_exper'].fillna(0)
data['minor_child'] = data['minor_child'].fillna(0)
data['marital_now'] = data['marital_now'].fillna(0)
data['marital_1st'] = data['marital_1st'].fillna(0)
data['social_neighbor']=data['social_neighbor'].fillna(0)
data['social_friend']=data['social_friend'].fillna(0)
data['hukou_loc']=data['hukou_loc'].fillna(1) #����Ϊ1,��ʾ����
data['family_income']=data['family_income'].fillna(66365) #ɾ������ֵ���ƽ��ֵ
#144+1 =145
#��������������н������ݴ���
#��happiness_index.xlsx
data['survey_time'] = pd.to_datetime(data['survey_time'], format='%Y-%m-%d',errors='coerce')#��ֹʱ���ʽ��ͬ�ı���errors='coerce��
data['survey_time'] = data['survey_time'].dt.year #������year,�����������
data['age'] = data['survey_time']-data['birth']
# print(data['age'],data['survey_time'],data['birth'])
#����ֲ� 145+1=146
bins = [0,17,26,34,50,63,100]
data['age_bin'] = pd.cut(data['age'], bins, labels=[0,1,2,3,4,5])
#�ԡ��ڽ̡�����
data.loc[data['religion']<0,'religion'] = 1 #1Ϊ�������ڽ�
data.loc[data['religion_freq']<0,'religion_freq'] = 1 #1Ϊ����û�вμӹ�
#�ԡ������̶ȡ�����
data.loc[data['edu']<0,'edu'] = 4 #����
data.loc[data['edu_status']<0,'edu_status'] = 0
data.loc[data['edu_yr']<0,'edu_yr'] = 0
#�ԡ��������롯����
data.loc[data['income']<0,'income'] = 0 #��������
#�ԡ�������ò������
data.loc[data['political']<0,'political'] = 1 #��Ϊ��Ⱥ��
#�����ش���
data.loc[(data['weight_jin']<=80)&(data['height_cm']>=160),'weight_jin']= data['weight_jin']*2
data.loc[data['weight_jin']<=60,'weight_jin']= data['weight_jin']*2 #���˵��뷨,������,û��60��ij����˰�
#�����ߴ���
data.loc[data['height_cm']<150,'height_cm'] = 150 #�����˵�ʵ�����
#�ԡ�����������
data.loc[data['health']<0,'health'] = 4 #��Ϊ�DZȽϽ���
data.loc[data['health_problem']<0,'health_problem'] = 4
#�ԡ���ɥ������
data.loc[data['depression']<0,'depression'] = 4 #һ���˶��Ǻ��ٰ�
#�ԡ�ý�塯����
data.loc[data['media_1']<0,'media_1'] = 1 #���ǴӲ�
data.loc[data['media_2']<0,'media_2'] = 1
data.loc[data['media_3']<0,'media_3'] = 1
data.loc[data['media_4']<0,'media_4'] = 1
data.loc[data['media_5']<0,'media_5'] = 1
data.loc[data['media_6']<0,'media_6'] = 1
#�ԡ����л������
data.loc[data['leisure_1']<0,'leisure_1'] = 1 #���Ǹ����Լ����뷨
data.loc[data['leisure_2']<0,'leisure_2'] = 5
data.loc[data['leisure_3']<0,'leisure_3'] = 3
data.loc[data['leisure_4']<0,'leisure_4'] = data['leisure_4'].mode() #ȡ����
data.loc[data['leisure_5']<0,'leisure_5'] = data['leisure_5'].mode()
data.loc[data['leisure_6']<0,'leisure_6'] = data['leisure_6'].mode()
data.loc[data['leisure_7']<0,'leisure_7'] = data['leisure_7'].mode()
data.loc[data['leisure_8']<0,'leisure_8'] = data['leisure_8'].mode()
data.loc[data['leisure_9']<0,'leisure_9'] = data['leisure_9'].mode()
data.loc[data['leisure_10']<0,'leisure_10'] = data['leisure_10'].mode()
data.loc[data['leisure_11']<0,'leisure_11'] = data['leisure_11'].mode()
data.loc[data['leisure_12']<0,'leisure_12'] = data['leisure_12'].mode()
data.loc[data['socialize']<0,'socialize'] = 2 #����
data.loc[data['relax']<0,'relax'] = 4 #����
data.loc[data['learn']<0,'learn'] = 1 #�Ӳ�,��������
#�ԡ��罻������
data.loc[data['social_neighbor']<0,'social_neighbor'] = 0
data.loc[data['social_friend']<0,'social_friend'] = 0
data.loc[data['socia_outing']<0,'socia_outing'] = 1
data.loc[data['neighbor_familiarity']<0,'social_neighbor']= 4
#�ԡ���ṫƽ�ԡ�����
data.loc[data['equity']<0,'equity'] = 4
#�ԡ����ȼ�������
data.loc[data['class_10_before']<0,'class_10_before'] = 3
data.loc[data['class']<0,'class'] = 5
data.loc[data['class_10_after']<0,'class_10_after'] = 5
data.loc[data['class_14']<0,'class_14'] = 2
#�ԡ��������������
data.loc[data['work_status']<0,'work_status'] = 0
data.loc[data['work_yr']<0,'work_yr'] = 0
data.loc[data['work_manage']<0,'work_manage'] = 0
data.loc[data['work_type']<0,'work_type'] = 0
#�ԡ���ᱣ�ϡ�����
data.loc[data['insur_1']<0,'insur_1'] = 1
data.loc[data['insur_2']<0,'insur_2'] = 1
data.loc[data['insur_3']<0,'insur_3'] = 1
data.loc[data['insur_4']<0,'insur_4'] = 1
data.loc[data['insur_1']==0,'insur_1'] = 0
data.loc[data['insur_2']==0,'insur_2'] = 0
data.loc[data['insur_3']==0,'insur_3'] = 0
data.loc[data['insur_4']==0,'insur_4'] = 0
#�Լ�ͥ�������
family_income_mean = data['family_income'].mean()
data.loc[data['family_income']<0,'family_income'] = family_income_mean
data.loc[data['family_m']<0,'family_m'] = 2
data.loc[data['family_status']<0,'family_status'] = 3
data.loc[data['house']<0,'house'] = 1
data.loc[data['car']<0,'car'] = 0
data.loc[data['car']==2,'car'] = 0
data.loc[data['son']<0,'son'] = 1
data.loc[data['daughter']<0,'daughter'] = 0
data.loc[data['minor_child']<0,'minor_child'] = 0
#�ԡ�����������
data.loc[data['marital_1st']<0,'marital_1st'] = 0
data.loc[data['marital_now']<0,'marital_now'] = 0
#�ԡ���ż������
data.loc[data['s_birth']<0,'s_birth'] = 0
data.loc[data['s_edu']<0,'s_edu'] = 0
data.loc[data['s_political']<0,'s_political'] = 0
data.loc[data['s_hukou']<0,'s_hukou'] = 0
data.loc[data['s_income']<0,'s_income'] = 0
data.loc[data['s_work_type']<0,'s_work_type'] = 0
data.loc[data['s_work_status']<0,'s_work_status'] = 0
data.loc[data['s_work_exper']<0,'s_work_exper'] = 0
#�ԡ���ĸ���������
data.loc[data['f_birth']<0,'f_birth'] = 1945
data.loc[data['f_edu']<0,'f_edu'] = 1
data.loc[data['f_political']<0,'f_political'] = 1
data.loc[data['f_work_14']<0,'f_work_14'] = 2
data.loc[data['m_birth']<0,'m_birth'] = 1940
data.loc[data['m_edu']<0,'m_edu'] = 1
data.loc[data['m_political']<0,'m_political'] = 1
data.loc[data['m_work_14']<0,'m_work_14'] = 2
#��ͬ���������ᾭ�õ�λ
data.loc[data['status_peer']<0,'status_peer'] = 2
#��3��ǰ����ᾭ�õ�λ
data.loc[data['status_3_before']<0,'status_3_before'] = 2
#�ԡ��۵㡯����
data.loc[data['view']<0,'view'] = 4
#�����������봦��
data.loc[data['inc_ability']<=0,'inc_ability']= 2
inc_exp_mean = data['inc_exp'].mean()
data.loc[data['inc_exp']<=0,'inc_exp']= inc_exp_mean #ȡ��ֵ
#������������,ȡ����
for i in range(1,9+1):
data.loc[data['public_service_'+str(i)]<0,'public_service_'+str(i)] = data['public_service_'+str(i)].dropna().mode().values[0]
for i in range(1,13+1):
data.loc[data['trust_'+str(i)]<0,'trust_'+str(i)] = data['trust_'+str(i)].dropna().mode().values[0]
�鿴��ʱ����Ϊ146ά
data.shape
(10956, 146)
2.2�����݉���
#��һ�ν������ 147
data['marital_1stbir'] = data['marital_1st'] - data['birth']
#���������� 148
data['marital_nowtbir'] = data['marital_now'] - data['birth']
#�Ƿ��ٻ� 149
data['mar'] = data['marital_nowtbir'] - data['marital_1stbir']
#��ż���� 150
data['marital_sbir'] = data['marital_now']-data['s_birth']
#��ż����� 151
data['age_'] = data['marital_nowtbir'] - data['marital_sbir']
#����� 151+7 =158
data['income/s_income'] = data['income']/(data['s_income']+1)
data['income+s_income'] = data['income']+(data['s_income']+1)
data['income/family_income'] = data['income']/(data['family_income']+1)
data['all_income/family_income'] = (data['income']+data['s_income'])/(data['family_income']+1)
data['income/inc_exp'] = data['income']/(data['inc_exp']+1)
data['family_income/m'] = data['family_income']/(data['family_m']+0.01)
data['income/m'] = data['income']/(data['family_m']+0.01)
#����/����� 158+4=162
data['income/floor_area'] = data['income']/(data['floor_area']+0.01)
data['all_income/floor_area'] = (data['income']+data['s_income'])/(data['floor_area']+0.01)
data['family_income/floor_area'] = data['family_income']/(data['floor_area']+0.01)
data['floor_area/m'] = data['floor_area']/(data['family_m']+0.01)
#class 162+3=165
data['class_10_diff'] = (data['class_10_after'] - data['class'])
data['class_diff'] = data['class'] - data['class_10_before']
data['class_14_diff'] = data['class'] - data['class_14']
#����ָ�� 166
leisure_fea_lis = ['leisure_'+str(i) for i in range(1,13)]
data['leisure_sum'] = data[leisure_fea_lis].sum(axis=1) #skew
#����ָ�� 167
public_service_fea_lis = ['public_service_'+str(i) for i in range(1,10)]
data['public_service_sum'] = data[public_service_fea_lis].sum(axis=1) #skew
#����ָ�� 168
trust_fea_lis = ['trust_'+str(i) for i in range(1,14)]
data['trust_sum'] = data[trust_fea_lis].sum(axis=1) #skew
#province mean 168+13=181
data['province_income_mean'] = data.groupby(['province'])['income'].transform('mean').values
data['province_family_income_mean'] = data.groupby(['province'])['family_income'].transform('mean').values
data['province_equity_mean'] = data.groupby(['province'])['equity'].transform('mean').values
data['province_depression_mean'] = data.groupby(['province'])['depression'].transform('mean').values
data['province_floor_area_mean'] = data.groupby(['province'])['floor_area'].transform('mean').values
data['province_health_mean'] = data.groupby(['province'])['health'].transform('mean').values
data['province_class_10_diff_mean'] = data.groupby(['province'])['class_10_diff'].transform('mean').values
data['province_class_mean'] = data.groupby(['province'])['class'].transform('mean').values
data['province_health_problem_mean'] = data.groupby(['province'])['health_problem'].transform('mean').values
data['province_family_status_mean'] = data.groupby(['province'])['family_status'].transform('mean').values
data['province_leisure_sum_mean'] = data.groupby(['province'])['leisure_sum'].transform('mean').values
data['province_public_service_sum_mean'] = data.groupby(['province'])['public_service_sum'].transform('mean').values
data['province_trust_sum_mean'] = data.groupby(['province'])['trust_sum'].transform('mean').values
#city mean 181+13=194
data['city_income_mean'] = data.groupby(['city'])['income'].transform('mean').values
data['city_family_income_mean'] = data.groupby(['city'])['family_income'].transform('mean').values
data['city_equity_mean'] = data.groupby(['city'])['equity'].transform('mean').values
data['city_depression_mean'] = data.groupby(['city'])['depression'].transform('mean').values
data['city_floor_area_mean'] = data.groupby(['city'])['floor_area'].transform('mean').values
data['city_health_mean'] = data.groupby(['city'])['health'].transform('mean').values
data['city_class_10_diff_mean'] = data.groupby(['city'])['class_10_diff'].transform('mean').values
data['city_class_mean'] = data.groupby(['city'])['class'].transform('mean').values
data['city_health_problem_mean'] = data.groupby(['city'])['health_problem'].transform('mean').values
data['city_family_status_mean'] = data.groupby(['city'])['family_status'].transform('mean').values
data['city_leisure_sum_mean'] = data.groupby(['city'])['leisure_sum'].transform('mean').values
data['city_public_service_sum_mean'] = data.groupby(['city'])['public_service_sum'].transform('mean').values
data['city_trust_sum_mean'] = data.groupby(['city'])['trust_sum'].transform('mean').values
#county mean 194 + 13 = 207
data['county_income_mean'] = data.groupby(['county'])['income'].transform('mean').values
data['county_family_income_mean'] = data.groupby(['county'])['family_income'].transform('mean').values
data['county_equity_mean'] = data.groupby(['county'])['equity'].transform('mean').values
data['county_depression_mean'] = data.groupby(['county'])['depression'].transform('mean').values
data['county_floor_area_mean'] = data.groupby(['county'])['floor_area'].transform('mean').values
data['county_health_mean'] = data.groupby(['county'])['health'].transform('mean').values
data['county_class_10_diff_mean'] = data.groupby(['county'])['class_10_diff'].transform('mean').values
data['county_class_mean'] = data.groupby(['county'])['class'].transform('mean').values
data['county_health_problem_mean'] = data.groupby(['county'])['health_problem'].transform('mean').values
data['county_family_status_mean'] = data.groupby(['county'])['family_status'].transform('mean').values
data['county_leisure_sum_mean'] = data.groupby(['county'])['leisure_sum'].transform('mean').values
data['county_public_service_sum_mean'] = data.groupby(['county'])['public_service_sum'].transform('mean').values
data['county_trust_sum_mean'] = data.groupby(['county'])['trust_sum'].transform('mean').values
#ratio ���ͬʡ 207 + 13 =220
data['income/province'] = data['income']/(data['province_income_mean'])
data['family_income/province'] = data['family_income']/(data['province_family_income_mean'])
data['equity/province'] = data['equity']/(data['province_equity_mean'])
data['depression/province'] = data['depression']/(data['province_depression_mean'])
data['floor_area/province'] = data['floor_area']/(data['province_floor_area_mean'])
data['health/province'] = data['health']/(data['province_health_mean'])
data['class_10_diff/province'] = data['class_10_diff']/(data['province_class_10_diff_mean'])
data['class/province'] = data['class']/(data['province_class_mean'])
data['health_problem/province'] = data['health_problem']/(data['province_health_problem_mean'])
data['family_status/province'] = data['family_status']/(data['province_family_status_mean'])
data['leisure_sum/province'] = data['leisure_sum']/(data['province_leisure_sum_mean'])
data['public_service_sum/province'] = data['public_service_sum']/(data['province_public_service_sum_mean'])
data['trust_sum/province'] = data['trust_sum']/(data['province_trust_sum_mean']+1)
#ratio ���ͬ�� 220 + 13 =233
data['income/city'] = data['income']/(data['city_income_mean'])
data['family_income/city'] = data['family_income']/(data['city_family_income_mean'])
data['equity/city'] = data['equity']/(data['city_equity_mean'])
data['depression/city'] = data['depression']/(data['city_depression_mean'])
data['floor_area/city'] = data['floor_area']/(data['city_floor_area_mean'])
data['health/city'] = data['health']/(data['city_health_mean'])
data['class_10_diff/city'] = data['class_10_diff']/(data['city_class_10_diff_mean'])
data['class/city'] = data['class']/(data['city_class_mean'])
data['health_problem/city'] = data['health_problem']/(data['city_health_problem_mean'])
data['family_status/city'] = data['family_status']/(data['city_family_status_mean'])
data['leisure_sum/city'] = data['leisure_sum']/(data['city_leisure_sum_mean'])
data['public_service_sum/city'] = data['public_service_sum']/(data['city_public_service_sum_mean'])
data['trust_sum/city'] = data['trust_sum']/(data['city_trust_sum_mean'])
#ratio ���ͬ������ 233 + 13 =246
data['income/county'] = data['income']/(data['county_income_mean'])
data['family_income/county'] = data['family_income']/(data['county_family_income_mean'])
data['equity/county'] = data['equity']/(data['county_equity_mean'])
data['depression/county'] = data['depression']/(data['county_depression_mean'])
data['floor_area/county'] = data['floor_area']/(data['county_floor_area_mean'])
data['health/county'] = data['health']/(data['county_health_mean'])
data['class_10_diff/county'] = data['class_10_diff']/(data['county_class_10_diff_mean'])
data['class/county'] = data['class']/(data['county_class_mean'])
data['health_problem/county'] = data['health_problem']/(data['county_health_problem_mean'])
data['family_status/county'] = data['family_status']/(data['county_family_status_mean'])
data['leisure_sum/county'] = data['leisure_sum']/(data['county_leisure_sum_mean'])
data['public_service_sum/county'] = data['public_service_sum']/(data['county_public_service_sum_mean'])
data['trust_sum/county'] = data['trust_sum']/(data['county_trust_sum_mean'])
#age mean 246+ 13 =259
data['age_income_mean'] = data.groupby(['age'])['income'].transform('mean').values
data['age_family_income_mean'] = data.groupby(['age'])['family_income'].transform('mean').values
data['age_equity_mean'] = data.groupby(['age'])['equity'].transform('mean').values
data['age_depression_mean'] = data.groupby(['age'])['depression'].transform('mean').values
data['age_floor_area_mean'] = data.groupby(['age'])['floor_area'].transform('mean').values
data['age_health_mean'] = data.groupby(['age'])['health'].transform('mean').values
data['age_class_10_diff_mean'] = data.groupby(['age'])['class_10_diff'].transform('mean').values
data['age_class_mean'] = data.groupby(['age'])['class'].transform('mean').values
data['age_health_problem_mean'] = data.groupby(['age'])['health_problem'].transform('mean').values
data['age_family_status_mean'] = data.groupby(['age'])['family_status'].transform('mean').values
data['age_leisure_sum_mean'] = data.groupby(['age'])['leisure_sum'].transform('mean').values
data['age_public_service_sum_mean'] = data.groupby(['age'])['public_service_sum'].transform('mean').values
data['age_trust_sum_mean'] = data.groupby(['age'])['trust_sum'].transform('mean').values
# ��ͬ�������259 + 13 =272
data['income/age'] = data['income']/(data['age_income_mean'])
data['family_income/age'] = data['family_income']/(data['age_family_income_mean'])
data['equity/age'] = data['equity']/(data['age_equity_mean'])
data['depression/age'] = data['depression']/(data['age_depression_mean'])
data['floor_area/age'] = data['floor_area']/(data['age_floor_area_mean'])
data['health/age'] = data['health']/(data['age_health_mean'])
data['class_10_diff/age'] = data['class_10_diff']/(data['age_class_10_diff_mean'])
data['class/age'] = data['class']/(data['age_class_mean'])
data['health_problem/age'] = data['health_problem']/(data['age_health_problem_mean'])
data['family_status/age'] = data['family_status']/(data['age_family_status_mean'])
data['leisure_sum/age'] = data['leisure_sum']/(data['age_leisure_sum_mean'])
data['public_service_sum/age'] = data['public_service_sum']/(data['age_public_service_sum_mean'])
data['trust_sum/age'] = data['trust_sum']/(data['age_trust_sum_mean'])
�˴����ù���һ�����������ظ��Դ���,��ʡ�ռ䷽���Ķ�
�鿴����Ϊ272ά
data.shape
shape (10956, 272)
data.head()

�õ�263ά����:
#272-9=263
#ɾ����ֵ�ر��ٵĺ�֮ǰ�ù�������
del_list=['id','survey_time','edu_other','invest_other','property_other','join_party','province','city','county']
use_feature = [clo for clo in data.columns if clo not in del_list]
data.fillna(0,inplace=True) #���Dz�0
train_shape = train.shape[0] #һ����������,ѵ����
features = data[use_feature].columns #ɾ�������е�����
X_train_263 = data[:train_shape][use_feature].values
y_train = target
X_test_263 = data[train_shape:][use_feature].values
X_train_263.shape #����һ��263������
(7988, 263)
ѡ������Ҫ��49������:
imp_fea_49 = ['equity','depression','health','class','family_status','health_problem','class_10_after',
'equity/province','equity/city','equity/county',
'depression/province','depression/city','depression/county',
'health/province','health/city','health/county',
'class/province','class/city','class/county',
'family_status/province','family_status/city','family_status/county',
'family_income/province','family_income/city','family_income/county',
'floor_area/province','floor_area/city','floor_area/county',
'leisure_sum/province','leisure_sum/city','leisure_sum/county',
'public_service_sum/province','public_service_sum/city','public_service_sum/county',
'trust_sum/province','trust_sum/city','trust_sum/county',
'income/m','public_service_sum','class_diff','status_3_before','age_income_mean','age_floor_area_mean',
'weight_jin','height_cm',
'health/age','depression/age','equity/age','leisure_sum/age'
]
train_shape = train.shape[0]
X_train_49 = data[:train_shape][imp_fea_49].values
X_test_49 = data[train_shape:][imp_fea_49].values
X_train_49.shape
(7988, 49)
ѡ����Ҫ����onehot�������ɢ��������one-hot����,�ٺϳ�Ϊ����������,��383ά:
cat_fea = ['survey_type','gender','nationality','edu_status','political','hukou','hukou_loc','work_exper','work_status','work_type',
'work_manage','marital','s_political','s_hukou','s_work_exper','s_work_status','s_work_type','f_political','f_work_14',
'm_political','m_work_14']
noc_fea = [clo for clo in use_feature if clo not in cat_fea]
onehot_data = data[cat_fea].values
enc = preprocessing.OneHotEncoder(categories = 'auto')
oh_data=enc.fit_transform(onehot_data).toarray()
oh_data.shape #��Ϊonehot�����ʽ
X_train_oh = oh_data[:train_shape,:]
X_test_oh = oh_data[train_shape:,:]
X_train_oh.shape #���е�ѵ����
X_train_383 = np.column_stack([data[:train_shape][noc_fea].values,X_train_oh])#����noc,����cat_fea
X_test_383 = np.column_stack([data[train_shape:][noc_fea].values,X_test_oh])
X_train_383.shape
(7988, 383)
�ġ�������ģ
1��ѡ��263άԭʼ�������н�ģ
1.1��lightGBM
##### lgb_263 #
#lightGBM������
lgb_263_param = {
'num_leaves': 7,
'min_data_in_leaf': 20, #Ҷ�ӿ��ܾ��е���С��¼��
'objective':'regression',
'max_depth': -1,
'learning_rate': 0.003,
"boosting": "gbdt", #��gbdt�㷨
"feature_fraction": 0.18, #���� 0.18ʱ,��ζ����ÿ�ε��������ѡ��18%�IJ���������
"bagging_freq": 1,
"bagging_fraction": 0.55, #ÿ�ε���ʱ�õ����ݱ���
"bagging_seed": 14,
"metric": 'mse',
"lambda_l1": 0.1005,
"lambda_l2": 0.1996,
"verbosity": -1}
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=4) #�����з�:5
oof_lgb_263 = np.zeros(len(X_train_263))
predictions_lgb_263 = np.zeros(len(X_test_263))
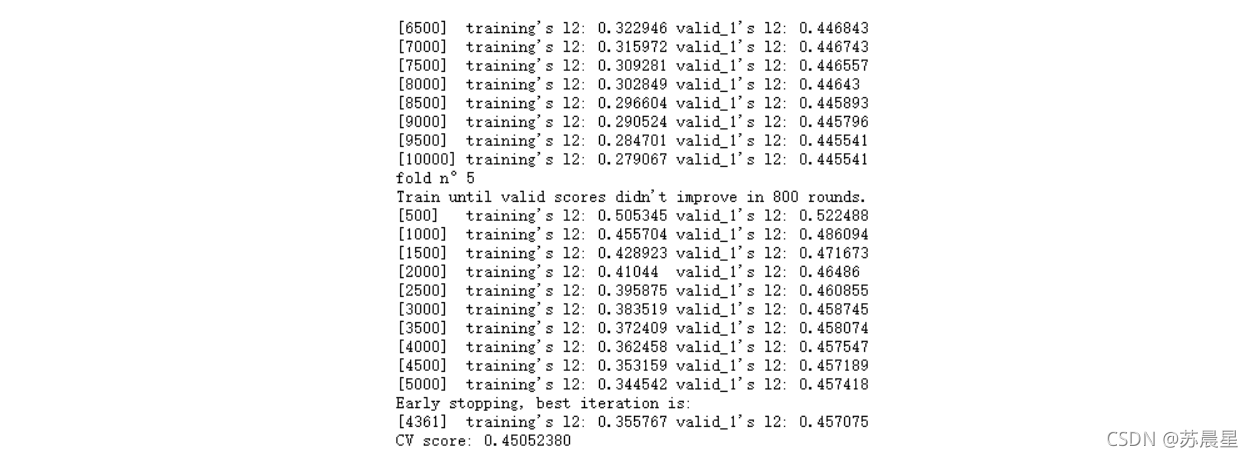
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_263, y_train)):
print("fold n��{}".format(fold_+1))
trn_data = lgb.Dataset(X_train_263[trn_idx], y_train[trn_idx])
val_data = lgb.Dataset(X_train_263[val_idx], y_train[val_idx])#train:val=4:1
num_round = 10000
lgb_263 = lgb.train(lgb_263_param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=500, early_stopping_rounds = 800)
oof_lgb_263[val_idx] = lgb_263.predict(X_train_263[val_idx], num_iteration=lgb_263.best_iteration)
predictions_lgb_263 += lgb_263.predict(X_test_263, num_iteration=lgb_263.best_iteration) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_lgb_263, target)))
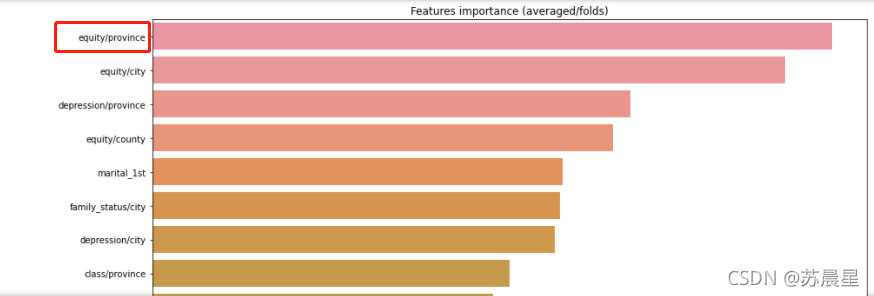
#---------------������Ҫ��
pd.set_option('display.max_columns', None)
#��ʾ������
pd.set_option('display.max_rows', None)
#����value����ʾ����Ϊ100,Ĭ��Ϊ50
pd.set_option('max_colwidth',100)
df = pd.DataFrame(data[use_feature].columns.tolist(), columns=['feature'])
df['importance']=list(lgb_263.feature_importance())
df = df.sort_values(by='importance',ascending=False)
plt.figure(figsize=(14,28))
sns.barplot(x="importance", y="feature", data=df.head(50))
plt.title('Features importance (averaged/folds)')
plt.tight_layout()
1.2��xgboost
##### xgb_263
#xgboost
xgb_263_params = {'eta': 0.02, #lr
'max_depth': 6,
'min_child_weight':3,#��СҶ�ӽڵ�����Ȩ�غ�
'gamma':0, #ָ���ڵ�����������С��ʧ�����½�ֵ��
'subsample': 0.7, #���ƶ���ÿ����,��������ı���
'colsample_bytree': 0.3, #��������ÿ�����������������ռ�� (ÿһ����һ������)��
'lambda':2,
'objective': 'reg:linear',
'eval_metric': 'rmse',
'silent': True,
'nthread': -1}
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
oof_xgb_263 = np.zeros(len(X_train_263))
predictions_xgb_263 = np.zeros(len(X_test_263))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_263, y_train)):
print("fold n��{}".format(fold_+1))
trn_data = xgb.DMatrix(X_train_263[trn_idx], y_train[trn_idx])
val_data = xgb.DMatrix(X_train_263[val_idx], y_train[val_idx])
watchlist = [(trn_data, 'train'), (val_data, 'valid_data')]
xgb_263 = xgb.train(dtrain=trn_data, num_boost_round=3000, evals=watchlist, early_stopping_rounds=600, verbose_eval=500, params=xgb_263_params)
oof_xgb_263[val_idx] = xgb_263.predict(xgb.DMatrix(X_train_263[val_idx]), ntree_limit=xgb_263.best_ntree_limit)
predictions_xgb_263 += xgb_263.predict(xgb.DMatrix(X_test_263), ntree_limit=xgb_263.best_ntree_limit) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_xgb_263, target)))
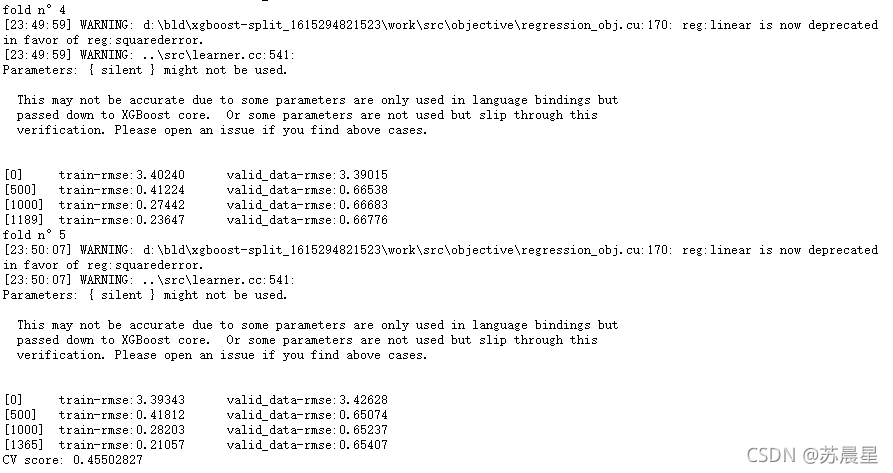
1.3��RandomForestRegressor���ɭ��
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
oof_rfr_263 = np.zeros(len(X_train_263))
predictions_rfr_263 = np.zeros(len(X_test_263))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_263, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_263[trn_idx]
tr_y = y_train[trn_idx]
rfr_263 = rfr(n_estimators=1600,max_depth=9, min_samples_leaf=9, min_weight_fraction_leaf=0.0,
max_features=0.25,verbose=1,n_jobs=-1)
#verbose = 0 Ϊ���ڱ�����������־��Ϣ
#verbose = 1 Ϊ�����������¼
#verbose = 2 Ϊÿ��epoch���һ�м�¼
rfr_263.fit(tr_x,tr_y)
oof_rfr_263[val_idx] = rfr_263.predict(X_train_263[val_idx])
predictions_rfr_263 += rfr_263.predict(X_test_263) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_rfr_263, target)))
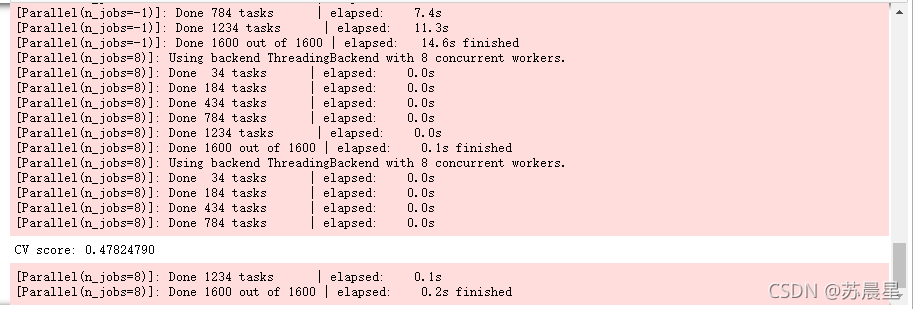
1.4��GradientBoostingRegressor�ݶ�����������
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=2018)
oof_gbr_263 = np.zeros(train_shape)
predictions_gbr_263 = np.zeros(len(X_test_263))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_263, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_263[trn_idx]
tr_y = y_train[trn_idx]
gbr_263 = gbr(n_estimators=400, learning_rate=0.01,subsample=0.65,max_depth=7, min_samples_leaf=20,
max_features=0.22,verbose=1)
gbr_263.fit(tr_x,tr_y)
oof_gbr_263[val_idx] = gbr_263.predict(X_train_263[val_idx])
predictions_gbr_263 += gbr_263.predict(X_test_263) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_gbr_263, target)))
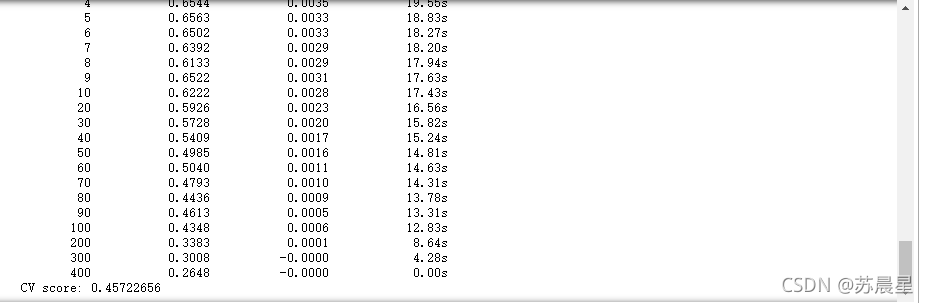
1.5��ExtraTreesRegressor �������ɭ�ֻع�
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_etr_263 = np.zeros(train_shape)
predictions_etr_263 = np.zeros(len(X_test_263))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_263, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_263[trn_idx]
tr_y = y_train[trn_idx]
etr_263 = etr(n_estimators=1000,max_depth=8, min_samples_leaf=12, min_weight_fraction_leaf=0.0,
max_features=0.4,verbose=1,n_jobs=-1)
etr_263.fit(tr_x,tr_y)
oof_etr_263[val_idx] = etr_263.predict(X_train_263[val_idx])
predictions_etr_263 += etr_263.predict(X_test_263) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_etr_263, target)))
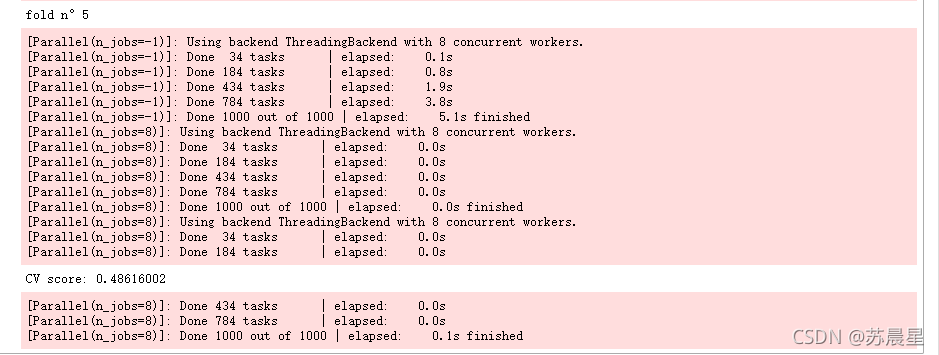
1.6�����ɽ�ģ-stack2
train_stack2 = np.vstack([oof_lgb_263,oof_xgb_263,oof_gbr_263,oof_rfr_263,oof_etr_263]).transpose()
# transpose()���������þ��ǵ���x,y,z��λ��,Ҳ�������������ֵ
test_stack2 = np.vstack([predictions_lgb_263, predictions_xgb_263,predictions_gbr_263,predictions_rfr_263,predictions_etr_263]).transpose()
#������֤:5��,�ظ�2��
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=7)
oof_stack2 = np.zeros(train_stack2.shape[0])
predictions_lr2 = np.zeros(test_stack2.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack2,target)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack2[trn_idx], target.iloc[trn_idx].values
val_data, val_y = train_stack2[val_idx], target.iloc[val_idx].values
#Kernel Ridge Regression
lr2 = kr()
lr2.fit(trn_data, trn_y)
oof_stack2[val_idx] = lr2.predict(val_data)
predictions_lr2 += lr2.predict(test_stack2) / 10
mean_squared_error(target.values, oof_stack2)
2��ѡ��49ά��Ҫ�������н�ģ
2.1��lightGBM
lgb_49_param = {
'num_leaves': 9,
'min_data_in_leaf': 23,
'objective':'regression',
'max_depth': -1,
'learning_rate': 0.002,
"boosting": "gbdt",
"feature_fraction": 0.45,
"bagging_freq": 1,
"bagging_fraction": 0.65,
"bagging_seed": 15,
"metric": 'mse',
"lambda_l2": 0.2,
"verbosity": -1}
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=9)
oof_lgb_49 = np.zeros(len(X_train_49))
predictions_lgb_49 = np.zeros(len(X_test_49))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_49, y_train)):
print("fold n��{}".format(fold_+1))
trn_data = lgb.Dataset(X_train_49[trn_idx], y_train[trn_idx])
val_data = lgb.Dataset(X_train_49[val_idx], y_train[val_idx])
num_round = 12000
lgb_49 = lgb.train(lgb_49_param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=1000, early_stopping_rounds = 1000)
oof_lgb_49[val_idx] = lgb_49.predict(X_train_49[val_idx], num_iteration=lgb_49.best_iteration)
predictions_lgb_49 += lgb_49.predict(X_test_49, num_iteration=lgb_49.best_iteration) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_lgb_49, target)))
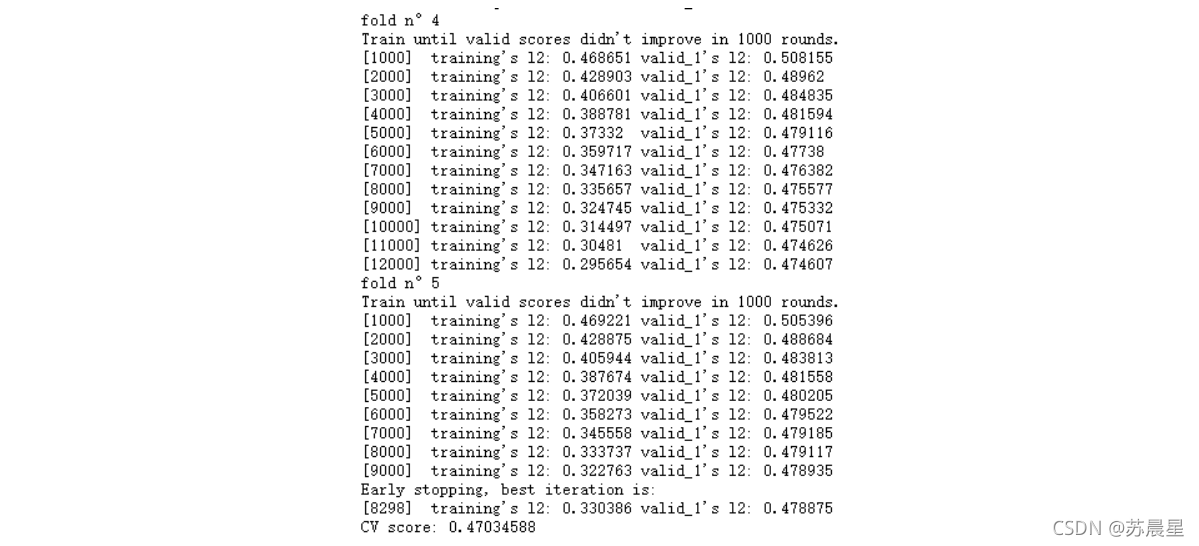
2.2��xgboost
xgb_49_params = {'eta': 0.02,
'max_depth': 5,
'min_child_weight':3,
'gamma':0,
'subsample': 0.7,
'colsample_bytree': 0.35,
'lambda':2,
'objective': 'reg:linear',
'eval_metric': 'rmse',
'silent': True,
'nthread': -1}
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
oof_xgb_49 = np.zeros(len(X_train_49))
predictions_xgb_49 = np.zeros(len(X_test_49))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_49, y_train)):
print("fold n��{}".format(fold_+1))
trn_data = xgb.DMatrix(X_train_49[trn_idx], y_train[trn_idx])
val_data = xgb.DMatrix(X_train_49[val_idx], y_train[val_idx])
watchlist = [(trn_data, 'train'), (val_data, 'valid_data')]
xgb_49 = xgb.train(dtrain=trn_data, num_boost_round=3000, evals=watchlist, early_stopping_rounds=600, verbose_eval=500, params=xgb_49_params)
oof_xgb_49[val_idx] = xgb_49.predict(xgb.DMatrix(X_train_49[val_idx]), ntree_limit=xgb_49.best_ntree_limit)
predictions_xgb_49 += xgb_49.predict(xgb.DMatrix(X_test_49), ntree_limit=xgb_49.best_ntree_limit) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_xgb_49, target)))
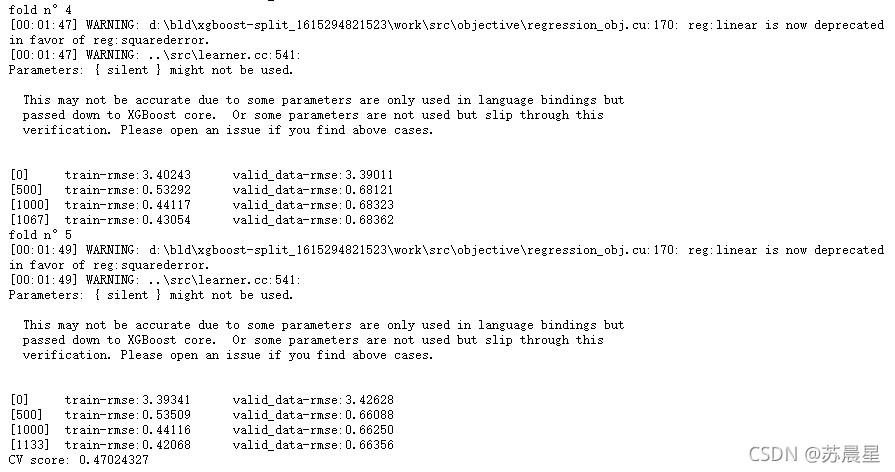
2.3��GradientBoostingRegressor�ݶ�����������
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=2018)
oof_gbr_49 = np.zeros(train_shape)
predictions_gbr_49 = np.zeros(len(X_test_49))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_49, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_49[trn_idx]
tr_y = y_train[trn_idx]
gbr_49 = gbr(n_estimators=600, learning_rate=0.01,subsample=0.65,max_depth=6, min_samples_leaf=20,
max_features=0.35,verbose=1)
gbr_49.fit(tr_x,tr_y)
oof_gbr_49[val_idx] = gbr_49.predict(X_train_49[val_idx])
predictions_gbr_49 += gbr_49.predict(X_test_49) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_gbr_49, target)))
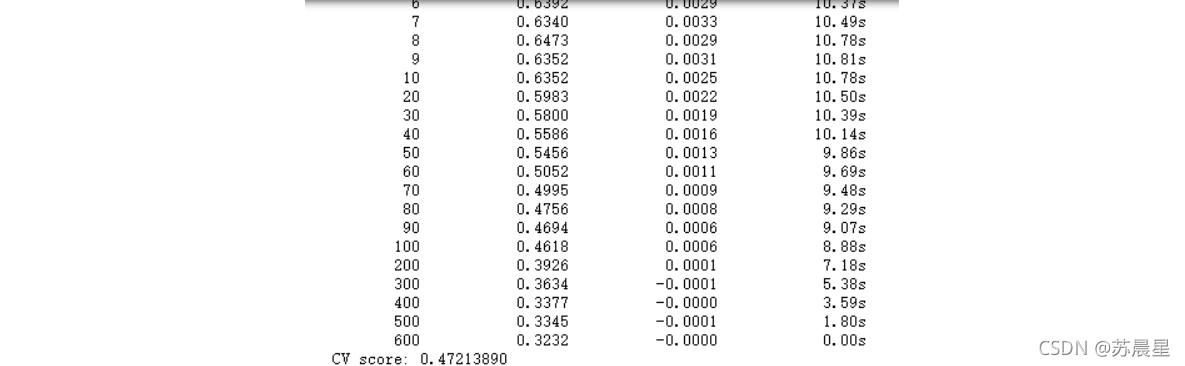
2.3�����ɽ�ģ-stack3
train_stack3 = np.vstack([oof_lgb_49,oof_xgb_49,oof_gbr_49]).transpose()
test_stack3 = np.vstack([predictions_lgb_49, predictions_xgb_49,predictions_gbr_49]).transpose()
#
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=7)
oof_stack3 = np.zeros(train_stack3.shape[0])
predictions_lr3 = np.zeros(test_stack3.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack3,target)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack3[trn_idx], target.iloc[trn_idx].values
val_data, val_y = train_stack3[val_idx], target.iloc[val_idx].values
#Kernel Ridge Regression
lr3 = kr()
lr3.fit(trn_data, trn_y)
oof_stack3[val_idx] = lr3.predict(val_data)
predictions_lr3 += lr3.predict(test_stack3) / 10
mean_squared_error(target.values, oof_stack3)
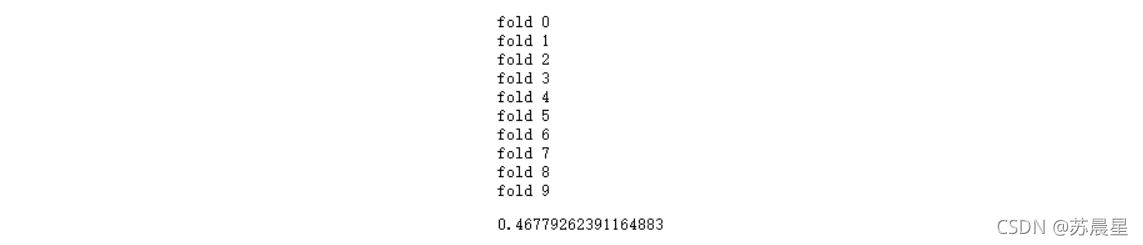
3.ѡ��383άone-hot��չ�������н�ģ
3.1��Kernel Ridge Regression ���ں˵���ع�
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_kr_383 = np.zeros(train_shape)
predictions_kr_383 = np.zeros(len(X_test_383))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_383, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_383[trn_idx]
tr_y = y_train[trn_idx]
#Kernel Ridge Regression ��ع�
kr_383 = kr()
kr_383.fit(tr_x,tr_y)
oof_kr_383[val_idx] = kr_383.predict(X_train_383[val_idx])
predictions_kr_383 += kr_383.predict(X_test_383) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_kr_383, target)))

3.2��ʹ����ͨ��ع�
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_ridge_383 = np.zeros(train_shape)
predictions_ridge_383 = np.zeros(len(X_test_383))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_383, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_383[trn_idx]
tr_y = y_train[trn_idx]
#ʹ����ع�
ridge_383 = Ridge(alpha=1200)
ridge_383.fit(tr_x,tr_y)
oof_ridge_383[val_idx] = ridge_383.predict(X_train_383[val_idx])
predictions_ridge_383 += ridge_383.predict(X_test_383) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_ridge_383, target)))

3.3��ʹ��ElasticNet ��������
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_en_383 = np.zeros(train_shape)
predictions_en_383 = np.zeros(len(X_test_383))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_383, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_383[trn_idx]
tr_y = y_train[trn_idx]
#ElasticNet ��������
en_383 = en(alpha=1.0,l1_ratio=0.06)
en_383.fit(tr_x,tr_y)
oof_en_383[val_idx] = en_383.predict(X_train_383[val_idx])
predictions_en_383 += en_383.predict(X_test_383) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_en_383, target)))

3.4��ʹ��BayesianRidge ��Ҷ˹��ع�
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_br_383 = np.zeros(train_shape)
predictions_br_383 = np.zeros(len(X_test_383))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_383, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_383[trn_idx]
tr_y = y_train[trn_idx]
#BayesianRidge ��Ҷ˹�ع�
br_383 = br()
br_383.fit(tr_x,tr_y)
oof_br_383[val_idx] = br_383.predict(X_train_383[val_idx])
predictions_br_383 += br_383.predict(X_test_383) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_br_383, target)))

3.5�����ɽ�ģ-stack1
train_stack1 = np.vstack([oof_br_383,oof_kr_383,oof_en_383,oof_ridge_383]).transpose()
test_stack1 = np.vstack([predictions_br_383, predictions_kr_383,predictions_en_383,predictions_ridge_383]).transpose()
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=7)
oof_stack1 = np.zeros(train_stack1.shape[0])
predictions_lr1 = np.zeros(test_stack1.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack1,target)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack1[trn_idx], target.iloc[trn_idx].values
val_data, val_y = train_stack1[val_idx], target.iloc[val_idx].values
# LinearRegression�����Իع�
lr1 = lr()
lr1.fit(trn_data, trn_y)
oof_stack1[val_idx] = lr1.predict(val_data)
predictions_lr1 += lr1.predict(test_stack1) / 10
mean_squared_error(target.values, oof_stack1)

4���ٴ�ѡ��49ά��Ҫ�������ж��⽨ģ
4.1��KernelRidge ����ع�
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_kr_49 = np.zeros(train_shape)
predictions_kr_49 = np.zeros(len(X_test_49))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_49, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_49[trn_idx]
tr_y = y_train[trn_idx]
kr_49 = kr()
kr_49.fit(tr_x,tr_y)
oof_kr_49[val_idx] = kr_49.predict(X_train_49[val_idx])
predictions_kr_49 += kr_49.predict(X_test_49) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_kr_49, target)))

4.2��Ridge ��ع�
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_ridge_49 = np.zeros(train_shape)
predictions_ridge_49 = np.zeros(len(X_test_49))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_49, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_49[trn_idx]
tr_y = y_train[trn_idx]
ridge_49 = Ridge(alpha=6)
ridge_49.fit(tr_x,tr_y)
oof_ridge_49[val_idx] = ridge_49.predict(X_train_49[val_idx])
predictions_ridge_49 += ridge_49.predict(X_test_49) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_ridge_49, target)))

4.3��BayesianRidge ��Ҷ˹��ع�
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_br_49 = np.zeros(train_shape)
predictions_br_49 = np.zeros(len(X_test_49))
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_49, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_49[trn_idx]
tr_y = y_train[trn_idx]
br_49 = br()
br_49.fit(tr_x,tr_y)
oof_br_49[val_idx] = br_49.predict(X_train_49[val_idx])
predictions_br_49 += br_49.predict(X_test_49) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_br_49, target)))

4.4��ElasticNet ��������
folds = KFold(n_splits=5, shuffle=True, random_state=13)
oof_en_49 = np.zeros(train_shape)
predictions_en_49 = np.zeros(len(X_test_49))
#
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train_49, y_train)):
print("fold n��{}".format(fold_+1))
tr_x = X_train_49[trn_idx]
tr_y = y_train[trn_idx]
en_49 = en(alpha=1.0,l1_ratio=0.05)
en_49.fit(tr_x,tr_y)
oof_en_49[val_idx] = en_49.predict(X_train_49[val_idx])
predictions_en_49 += en_49.predict(X_test_49) / folds.n_splits
print("CV score: {:<8.8f}".format(mean_squared_error(oof_en_49, target)))

4.5�����ɽ�ģ-stack4
train_stack4 = np.vstack([oof_br_49,oof_kr_49,oof_en_49,oof_ridge_49]).transpose()
test_stack4 = np.vstack([predictions_br_49, predictions_kr_49,predictions_en_49,predictions_ridge_49]).transpose()
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=7)
oof_stack4 = np.zeros(train_stack4.shape[0])
predictions_lr4 = np.zeros(test_stack4.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack4,target)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack4[trn_idx], target.iloc[trn_idx].values
val_data, val_y = train_stack4[val_idx], target.iloc[val_idx].values
#LinearRegression
lr4 = lr()
lr4.fit(trn_data, trn_y)
oof_stack4[val_idx] = lr4.predict(val_data)
predictions_lr4 += lr4.predict(test_stack1) / 10
mean_squared_error(target.values, oof_stack4)
�塢ģ���ں�
5.1�����Լ�Ȩ
mean_squared_error(target.values, 0.7*(0.6*oof_stack2 + 0.4*oof_stack3)+0.3*(0.55*oof_stack1+0.45*oof_stack4))
0.4527515432292745
5.2��������ѧϰģ���ٴν��м���ѧϰѵ��
train_stack5 = np.vstack([oof_stack1,oof_stack2,oof_stack3,oof_stack4]).transpose()
test_stack5 = np.vstack([predictions_lr1, predictions_lr2,predictions_lr3,predictions_lr4]).transpose()
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=7)
oof_stack5 = np.zeros(train_stack5.shape[0])
predictions_lr5= np.zeros(test_stack5.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack5,target)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack5[trn_idx], target.iloc[trn_idx].values
val_data, val_y = train_stack5[val_idx], target.iloc[val_idx].values
#LinearRegression
lr5 = lr()
lr5.fit(trn_data, trn_y)
oof_stack5[val_idx] = lr5.predict(val_data)
predictions_lr5 += lr5.predict(test_stack5) / 10
mean_squared_error(target.values, oof_stack5)
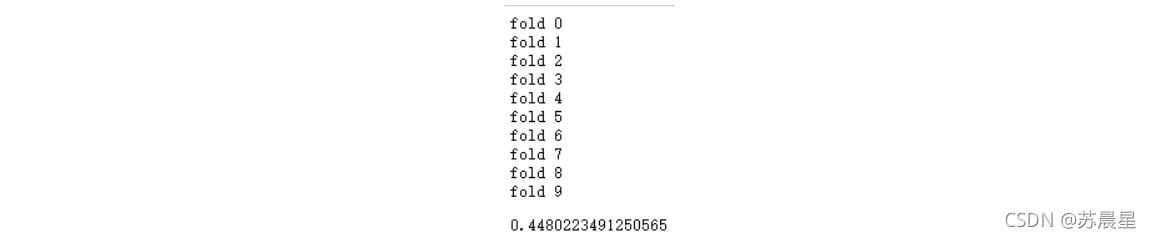
��������Ԥ����
submit_example = pd.read_csv('submit_example.csv',sep=',',encoding='latin-1')
submit_example['happiness'] = predictions_lr5
submit_example.happiness.describe()
count 2968.000000
mean 3.879776
std 0.463997
min 1.644653
25% 3.662051
50% 3.953215
75% 4.187563
max 5.058825
Name: happiness, dtype: float64
���н������,��������Ԥ�����ֵ��1-5������ֵ,�������ǵ�ground truth������ֵ,����Ϊ�˽�һ���Ż����ǵĽ��,���Ƕ��ڽ��������������Ľ���,�����浽��csv�ļ���:
submit_example.loc[submit_example['happiness']<=1.04,'happiness']= 1
submit_example.loc[(submit_example['happiness']>1.96)&(submit_example['happiness']<2.04),'happiness']= 2
submit_example.loc[(submit_example['happiness']>2.96)&(submit_example['happiness']<3.04),'happiness']= 3
submit_example.loc[(submit_example['happiness']>3.96)&(submit_example['happiness']<4.04),'happiness']= 3
submit_example.loc[submit_example['happiness']>4.96,'happiness']= 5
submit_example.to_csv("submision.csv",index=False)
submit_example.happiness.describe()
count 2968.000000
mean 3.797191
std 0.520707
min 1.644653
25% 3.512802
50% 3.874427
75% 4.187563
max 5.000000
Name: happiness, dtype: float64
�ο�:
��1���̰�:https://github.com/datawhalechina/ensemble-learning
��2��datawhale��Դѧϰ����:http://datawhale.club/