一、动机和贡献
- 动机
(1)从鸟瞰投影、Front投影和球面投影,或从RGB图像生成目标边界框建议,在量化过程中会遭受信息损失,我们直接从原始点云自下而上生成3D边界框建议;
(2)PointNet和PointNet++的性能严重依赖于二维检测性能,不能利用三维信息的优势来生成鲁棒的边界框建议。
(3)与二维图像中的目标检测不同,自动驾驶场景中的三维目标是自然、良好分离的,彼此之间没有重叠,而二维图像中目标之间可能存在重叠,这是3D检测和2D检测训练数据之间的关键区别。所有的三维目标分割掩码都可以通过其三维边界框标注直接获得,即将三维框内的三维点视为前景点。 - 贡献:基于动机(3),我们将基于点的特征提取器扩展到基于三维点云的目标检测,提出了一个两阶段的三维目标检测框架PointRCNN。
(1)第一个阶段是在自底向上的方案中生成三维边界框,逐点学习点云的逐点特征、分割原始点云,并同时从分割的前景点生成少量3D包围盒建议。该策略避免使用大量的三维锚盒,显著地限制了三维提案生成的搜索空间,节省了大量的计算量。
(2)第二个阶段是规范三维边界框的细调。将每个三维边界框内的点进行点云区域池化操作,并将池化的点转换为规范坐标,学习局部空间特征,这个过程与第一个阶段学习每个点的全局语义特征相结合,用于目标边界框优化和置信度预测。
二、PointRCNN模型
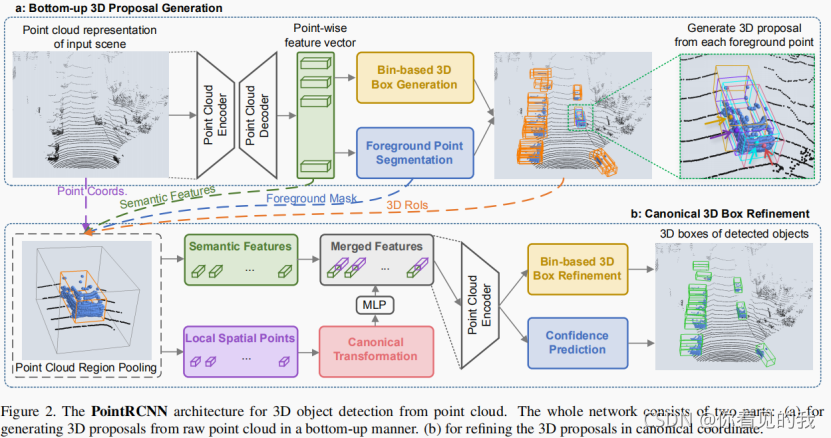
1) 通过点云分割自下而上生成3D提案
- 学习点云表示:为了学习区分的点特征来描述原始点云,我们利用带多尺度分组的PointNet++网络(点云编码【正卷积】、点云解码【反卷积】)作为点云特征提取backbone,得到编码的逐点特征。
【前景点提供了丰富的信息,以预测其相关的对象的位置和方向。我们设计了自底向上的3D边界框提案生成方法,直接从前景点生成3D边界框提案,即前景分割和3D box提案生成同时进行。经backbone处理后的每个点的特征,分别经过前景掩模预测分支和三维边界框回归分支完成相应任务。】
-
前景点分割:即前景掩模预测任务,点分割的真实掩模由3D边界框提供。对于大型的室外场景,前景点的数量通常比背景点的数量要少得多,我们利用焦点损失函数来处理类别(前景点和背景点二分类)不平衡问题。
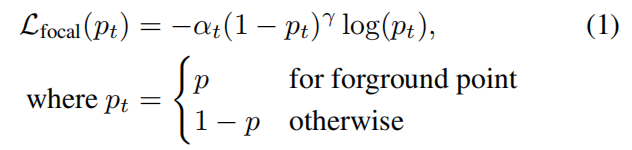
-
基于bin的三维边界框生成:即三维边界框回归任务,在训练过程中,三维边界框回归分支从前景点回归三维边界框位置,尽管盒子并没有从背景点回归,但由于点云网络的接受域,背景点也提供了生成边界框的支持信息。
三维边界框在激光雷达坐标系中表示为 ( x , y , z , h , w , l , θ ) (x,y,z,h,w,l,\theta) (x,y,z,h,w,l,θ),其中 ( x , y , z ) (x,y,z) (x,y,z)为目标中心位置, ( h , w , l ) (h,w,l) (h,w,l)为目标大小, θ \theta θ为鸟瞰目标方向。为了约束三维提案,作者提出了基于bin的回归损失估计目标的三维边界框,即预测3D边界框的中心坐标、目标方向与目标尺寸。本文采用bin-based方法去定位bounding box的中心点;采用Frustum PointNets中的方法回归bounding box的方向与尺寸。
① 目标中心点回归
我们沿着X轴和Z轴将每个前景点的周围区域分割成一系列离散的Bin锚盒,S表示每个前景点在X轴和Z轴方向上的最大搜索范围,每个方向上的搜索范围用等长的bins来表示X-Z平面上不同的目标中心(x, y),(x, y)表示每个锚盒在X-Z平面上的中心坐标,δ表示每个方向上锚盒的长度。
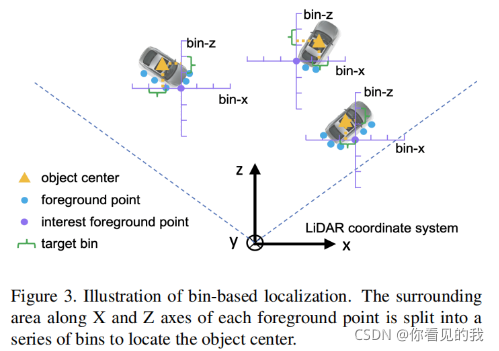
在X轴和Z轴上使用基于交叉熵损失的回归,可以获得更准确鲁棒的中心定位,X轴或Z轴的定位损失包括两项,第一项用于每个X轴和Z轴上的锚盒分类,第二项用于分类锚盒内的残差回归。【注意:前景点一定是锚盒中心,真实边界框的中心不一定是锚盒中心,因此在确定边界框中心点在哪一个锚盒后,还需要在锚盒内进行残差回归。】
由于大多数目标在Y轴方向上的跨越范围很小,在Y轴上直接使用Smoth L1损失的回归。定位目标可以表述为:
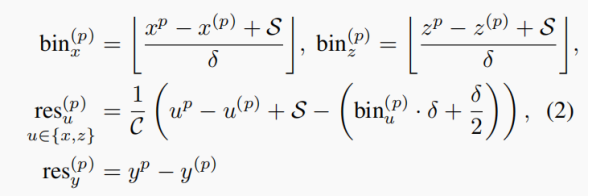

② 目标尺寸回归
直接进行残差回归,计算 ( r e s h ( p ) , r e s w ( p ) , r e s l ( p ) ) (res_h^{(p)}, res_w^{(p)}, res_l^{(p)}) (resh(p)?,resw(p)?,resl(p)?)。
③目标方向回归
将2π方向划分为n个bin,按照x或z预测的方法计算bin的分类 b i n θ ( p ) bin_{\theta}^{(p)} binθ(p)?,以及在bin中进行残差回归 r e s θ ( p ) res_{\theta}^{(p)} resθ(p)?。
- 训练阶段的3D边界框回归损失:

- 推理阶段:前景点与真实边界框进行拟合获得bin和残差,根据bin和残差可以回归前景,获得预测边界框。
对于基于bin的预测参数x、z、θ,我们首先选择预测置信度最高的bin中心,并添加预测残差,得到细化后的参数;
对于直接回归的参数y、h、w和l,我们将预测残差加到它们的初始值上。
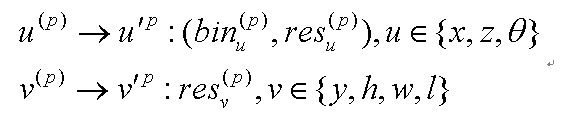
在推理阶段,为了去除冗余的预测边界框,使用IoU阈值为0.8的NMS,只保留前100个边界框,输入第二阶段进行细化。
2)点云区域池化
为了了解更具体的局部特征,我们对三维边界框内的点特征执行空间区域池化。轻微扩大该边界框,即中心点和方向不变,轻微扩大长宽高。
然后对所有点做一个判断,看看他有没有在这个扩大后的bbox当中,如果有的话,那么这个点的特征也会被加入到后续的细化中。
3)规范3D边框的细调
-
坐标规范变换
为了更好地学习每个目标边界框的局部空间特征,我们将全局特征图分割为若干个点云目标特征图,将每个目标边界框内的集合点转换为相应三维规范坐标系。
坐标系的x轴和z轴平行于地面,x轴是目标向前的方向,z轴与x轴平面内垂直,y轴垂直于地面;y轴与激光雷达坐标系的y轴保持一致;目标边界框的中心设置为三维坐标系的原点;通过适当的旋转和平移,将边界框的所有池化点坐标转换至规范坐标系中。

-
目标边界框的空间特征学习
虽然规范坐标变换能够实现鲁棒的局部空间特征学习,但它不可避免地丢失了每个目标的深度信息,将反应强度特征 r ( p ) ∈ [ 0 , 1 ] r^{(p)} \in [0,1] r(p)∈[0,1]、分割掩码特征 m ( p ) ∈ { 0 , 1 } m^{(p)} \in \{0,1\} m(p)∈{0,1}、目标至雷达的距离特征 d ( p ) = ( x ( p ) ) 2 + y ( p ) ) 2 + z ( p ) ) 2 d^{(p)} = \sqrt{(x^{(p)})^2 + y^{(p)})^2 + z^{(p)})^2} d(p)=(x(p))2+y(p))2+z(p))2?与目标的局部空间特征组合送入MLP全连接层,然后与全局语义特征进行连接,送入目标分类和回归网络,得到判别特征向量,用于随后的置信度分类和边界框回归。 -
目标边界框的损失
若提议的三维边界框与真实边界框的三维IoU大于0.55,则将该真实边界框分配给该提议,进一步细化该提议边界框。

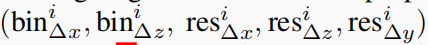
注意:由于聚集的稀疏点通常不能提供足够的建议大小信息(h, w, l),所以我们仍然直接回归大小残差,即训练集中每个类的平均目标大小。
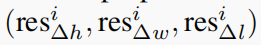
假设目标水平,提议边界框和真实边界框的夹角 θ i g t ? θ i \theta_i^{gt} - \theta_i θigt??θi?在[?π/4,π/4]之间(俩直线的夹角显然在0至90度之间),搜索范围S=π/4,每个bin尺寸为w,训练目标为:
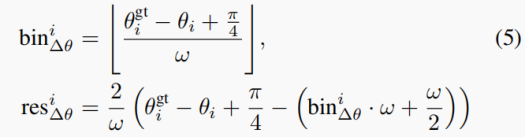
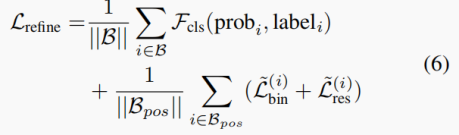
模型损失等于分类损失和回归损失之和,B是3D边界框提议集合,Bpos是用于回归的正边界框提议(前景点),prob_i是边界框的估计置信度,label_i是对应的真实标签。
最后采用采用阈值0.01执行NMS,去除重叠的包围盒,生成被检测目标的三维边界框。(0.01可以是极小的正数,因为三维空间中,目标不存在重叠)
参考文献
- PointRCNN:3D Object Proposal Generation and Detection from Point Cloud,CVPR,2019
- Pointnet++,NIPS,2017
- Focal loss for dense object detection.,IEEE TPAMI, 2018
- Frustum PointNets for 3D Object Detection from RGB-D Data,CVPR,2019