Kaggle 上近日发布了一个时间序列方向的新赛:Optiver Realized Volatility Prediction,即“ 股票市场波动率预测 ”比赛。奖金10W美刀,要求参赛者构建模型预测不同行业数百只股票的短期波动。
这是一个 时间序列预测 的任务,整体难度不大,适合机器学习/深度学习初学者参加。此外,本次比赛还涉及到金融行业的 量化交易 知识,对此感兴趣的同学千万不要错过。
1 比赛简介
- 比赛名称:Optiver Realized Volatility Prediction
- 比赛链接:https://www.kaggle.com/c/optiver-realized-volatility-prediction/leaderboard
波动率是你在任何交易大厅都会听到的最重要的术语之一,高波动性与市场动荡时期和价格大幅波动有关,而低波动性则描述更平静和安静的市场。
对于像Optiver这样的交易公司来说,准确预测波动率对于期权交易至关重要,期权的价格与标的产品的波动率直接相关。
1.1 比赛目标
在本次比赛的前三个月,你将构建模型来预测不同行业数百只股票的短期波动。你将拥有触手可及的数亿行高度细化的财务数据,你将利用这些数据设计预测 10 分钟内波动率的模型。
你的模型将根据训练后三个月评估期内收集的真实市场数据进行评估。
1.2 比赛时间
- 2021年6月28日-开始报名比赛;
- 2021年9月20日-合并队伍截止日期;
- 2021年9月27日-最终提交日期.;
- 在最终提交截止日期之后,排行榜将定期更新,以测试比赛选手模型在真实交易市场的实时分数。
1.3 评估指标
**评估指标:**本次评估指标用的是RMSPE,如下所示:
RMSPE
=
1
n
∑
i
=
1
n
(
(
y
i
?
y
^
i
)
/
y
i
)
2
\text{RMSPE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} ((y_i - \hat{y}_i)/y_i)^2}
RMSPE=n1?i=1∑n?((yi??y^?i?)/yi?)2?
结果提交: 结果文件submission.csv中应该包括row_id和target两列,如下所示。并且必须通过Notebooks来提交代码,运行时间不能超过九个小时。提交示例文件如下:
row_id,target
0-0,0.003
0-1,0.002
0-2,0.001
...
2 数据分析
该数据集包括了在金融市场中实际交易执行相关的股票市场数据,包括了订单簿数据和交易数据。秒级的数据以更细的粒度描述了金融市场的微观结构。
数据集是不允许下载的,只有测试集的前几行可供下载,可在notebook中进行使用,隐藏的测试集大概有15w的数据需要预测,public leaderboard和private leaderboard所使用的的数据是完全没有重叠的。
这个比赛主要提供了book和trade的信息,下面直接结合这两部分信息来帮助大家快速了解比赛内容。
(https://img-blog.csdnimg.cn/59c342fe86934afa8a5e01bf818018f5.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5rex5bqm5LmL55y8,size_20,color_FFFFFF,t_70,g_se,x_16)
2.1 book数据
book_[train/test].parquet
book0 = util.load_book(0)
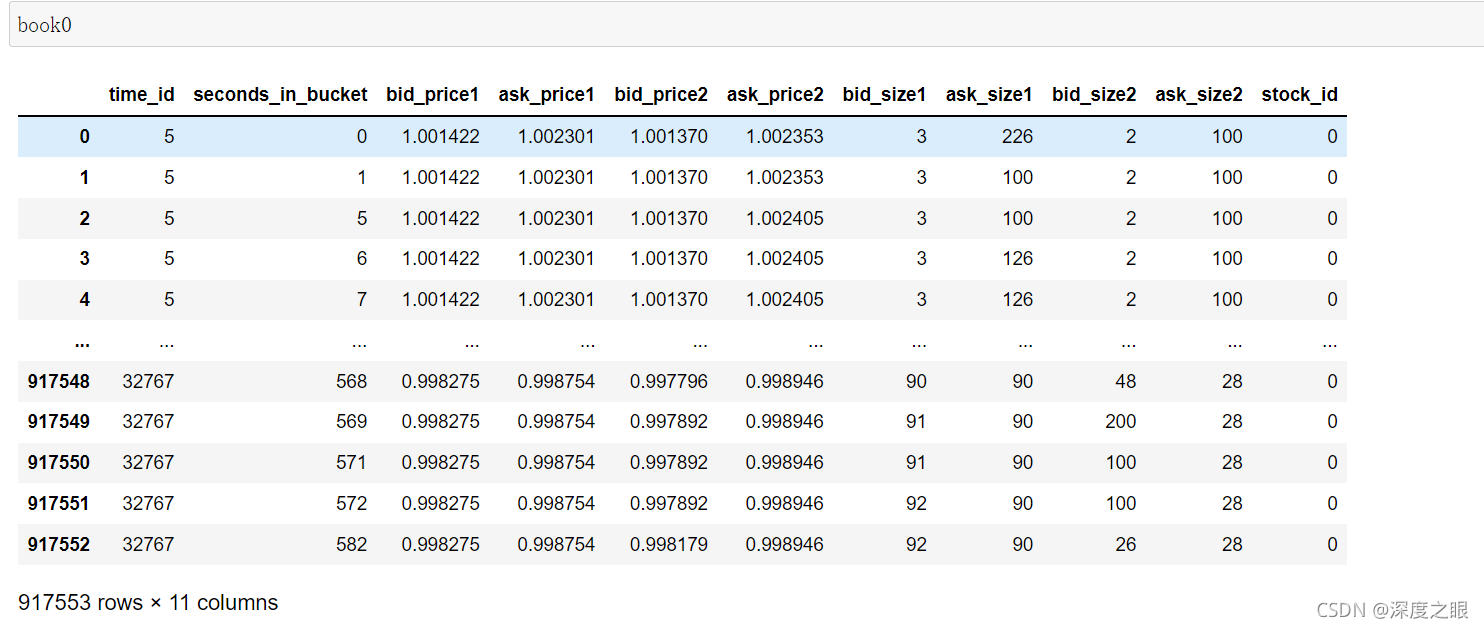
该文件中提供了进入市场的最具竞争力的买卖订单的订单簿数据,通俗来说,也就是买一,卖一,买二,卖二价格数据。一个stock_id对应了一个订单簿文件,test里面只有stock_id=0的数据。
| 变量名 | 变量含义 |
|---|---|
| stock_id | 股票的id代码,parquet文件中stock_id是类别变量,可能希望转换为int8类型 |
| time_id | 时间段的id代码,时间id不一定连续,但在所有股票中都是一致的。 |
| seconds_in_bucket | 开始的秒数,通常从0开始,每十分钟为一个时间段,相当于这十分钟里的秒数。 |
| bid_price[1/2] | 买一/买二价,已标准化 |
| ask_price[1/2] | 卖一/卖二价,已标准化 |
2.2 trade 数据
该表格提供了交易数据。通常来说,投资者被动买卖的交易意向比实际交易要多得多,所以实际的交易数据会比订单簿更加稀疏。(被动买卖:不着急出手,认为股票股价还有发展的潜力(或跌或涨),挂单的价格相比于买一卖一没有那么有竞争力;主动买卖:急于出手,以卖一价以上的价格成交或以买一以下的价格成交)。一个stock_id对应了一个交易数据文件,test里面只有stock_id=0的数据。
| 变量名 | 变量含义 |
|---|---|
| stock_id | 股票的id代码 |
| time_id | 时间段的id代码 |
| seconds_in_bucket | 同上,由于交易数据一般较为稀疏,因此该字段不一定从0开始 |
| price | 一秒钟内的平均交易价格,按照股票数量加权,并标准化。 |
| size | 交易的股票总数 |
| order_count | 交易订单的数量 |
trade0 = util.load_trade(0)
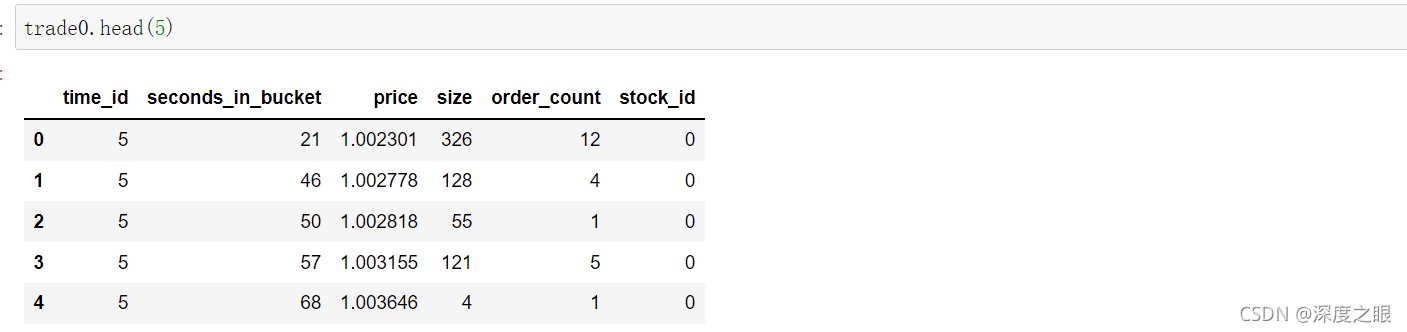
根据股票id和时间合并trade和book表格之后的数据如下:
book_trade = book0.merge(
trade0
, how='outer'
, on=['time_id', 'seconds_in_bucket', 'stock_id']
)
2.3 金融背景知识补充
这里先要对不熟悉背景的同学介绍一下什么叫做Order Book。现在主流的交易所一般都使用Order Book进行交易,交易所在内部的Order Book上记录所有买家和卖家的报价,比如像这样:
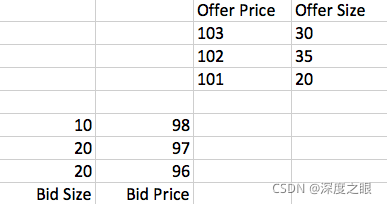
Bid表示买家,Offer表示卖家,这张报价单表示买卖双方发出的所有报价单(Limit Order)。这张表才是高频交易最关心的信息。任意时刻,买家的出价总是低于卖家(比如这里的98对101)。所以报价虽然一直在变化,但是只有报价是不会有任何成交的。
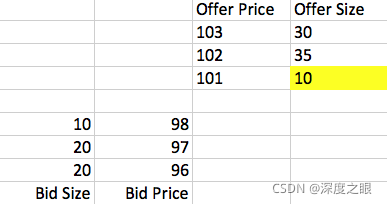
什么时候会产生交易呢?有两种情况,第一是任一方发出市价单(Market Order),比如一个买家发出一张单量为10的市价单,就可以买到卖方在101价格上挂的10份,这个交易成功之后,Order Book会变成这样:
3 基于特征工程与LGB的波动率基线模型
3.1 金融交易特征
def log_return(list_stock_prices):
"""收益率
"""
return np.log(list_stock_prices).diff()
def realized_volatility(series_log_return):
"""波动率
"""
return np.sqrt(np.sum(series_log_return**2))
def fix_jsonerr(df):
"""
"""
df.columns = [
"".join(c if c.isalnum() else "_" for c in str(x)) for x in df.columns
]
return df
def feature_row(book):
"""
"""
# book_wap1 生成标签
for i in [
1,
2,
]:
# wap
book[f'book_wap{i}'] = (book[f'bid_price{i}'] * book[f'ask_size{i}'] +
book[f'ask_price{i}'] *
book[f'bid_size{i}']) / (book[f'bid_size{i}'] +
book[f'ask_size{i}'])
# mean wap
book['book_wap_mean'] = (book['book_wap1'] + book['book_wap2']) / 2
# wap diff
book['book_wap_diff'] = book['book_wap1'] - book['book_wap2']
# other orderbook features
book['book_price_spread'] = (book['ask_price1'] - book['bid_price1']) / (
book['ask_price1'] + book['bid_price1'])
book['book_bid_spread'] = book['bid_price1'] - book['bid_price2']
book['book_ask_spread'] = book['ask_price1'] - book['ask_price2']
book['book_total_volume'] = book['ask_size1'] + book['ask_size2'] + book[
'bid_size1'] + book['bid_size2']
book['book_volume_imbalance'] = (book['ask_size1'] + book['ask_size2']) - (
book['bid_size1'] + book['bid_size2'])
return book
def feature_agg(book, trade):
"""
"""
# 聚合生成特征
book_feats = book.columns[book.columns.str.startswith('book_')].tolist()
trade_feats = ['price', 'size', 'order_count', 'seconds_in_bucket']
trade = trade.groupby(['time_id', 'stock_id'])[trade_feats].agg(
['sum', 'mean', 'std', 'max', 'min']).reset_index()
book = book.groupby(['time_id', 'stock_id'])[book_feats].agg(
[lambda x: realized_volatility(log_return(x))]).reset_index()
# 修改特征名称
book.columns = ["".join(col).strip() for col in book.columns.values]
trade.columns = ["".join(col).strip() for col in trade.columns.values]
df_ret = book.merge(trade, how='left', on=['time_id', 'stock_id'])
return df_ret
3.2 统计编码特征
def gen_data_encoding(df_ret, df_label, data_type='train'):
"""
test 不使用自己数据的 stock_id encoding
"""
# 对 stock_id 进行 encoding
vol_feats = [f for f in df_ret.columns if ('lambda' in f) & ('wap' in f)]
if data_type == 'train':
# agg
stock_df = df_ret.groupby('stock_id')[vol_feats].agg([
'mean',
'std',
'max',
'min',
]).reset_index()
# fix column names
stock_df.columns = ['stock_id'] + [
f'{f}_stock' for f in stock_df.columns.values.tolist()[1:]
]
stock_df = fix_jsonerr(stock_df)
# 对 time_id 进行 encoding
time_df = df_ret.groupby('time_id')[vol_feats].agg([
'mean',
'std',
'max',
'min',
]).reset_index()
time_df.columns = ['time_id'] + [
f'{f}_time' for f in time_df.columns.values.tolist()[1:]
]
# merge
df_ret = df_ret.merge(time_df, how='left', on='time_id')
# make sure to fix json error for lighgbm
df_ret = fix_jsonerr(df_ret)
# out
if data_type == 'train':
df_ret = df_ret.merge(stock_df, how='left', on='stock_id').merge(
df_label, how='left',
on=['stock_id', 'time_id']).replace([np.inf, -np.inf],
np.nan).fillna(method='ffill')
return df_ret
if data_type == 'test':
stock_df = pd.read_pickle(os.path.join(input_dir, '20210805.pkl'))
df_ret = df_ret.merge(stock_df, how='left', on='stock_id').replace(
[np.inf, -np.inf], np.nan).fillna(method='ffill')
return df_ret
其他更多特征可以联系小编获取完整baseline代码
3.3 LGB模型构建
import pandas as pd
import numpy as np
import lightgbm as lgb
from imp import reload
import warnings
from utils import util
from sklearn import model_selection
reload(util)
warnings.filterwarnings('ignore')
df_all_stock = df_all[['stock_id']+df_all.columns[df_all.columns.str.endswith('_stock')].tolist()]
X_train = df_all[df_all.columns.difference(['target'])]
y_train = df_all['target']
features = df_all[df_all.columns.difference(['time_id','target'])].columns.tolist()
pd.DataFrame(features).to_pickle('../data/features_name.pkl')
oof_df = util.fit_model(params,X_train,y_train,features,cats=['stock_id'],n_fold=10,seed=66)
params = {
'n_estimators': 10000,
'objective': 'rmse',
'boosting_type': 'gbdt',
'max_depth': -1,
'learning_rate': 0.01,
'subsample': 0.72,
'subsample_freq': 4,
'feature_fraction': 0.8,
'lambda_l1': 1,
'lambda_l2': 1,
'seed': 66,
'early_stopping_rounds': 300,
'verbose': -1
}
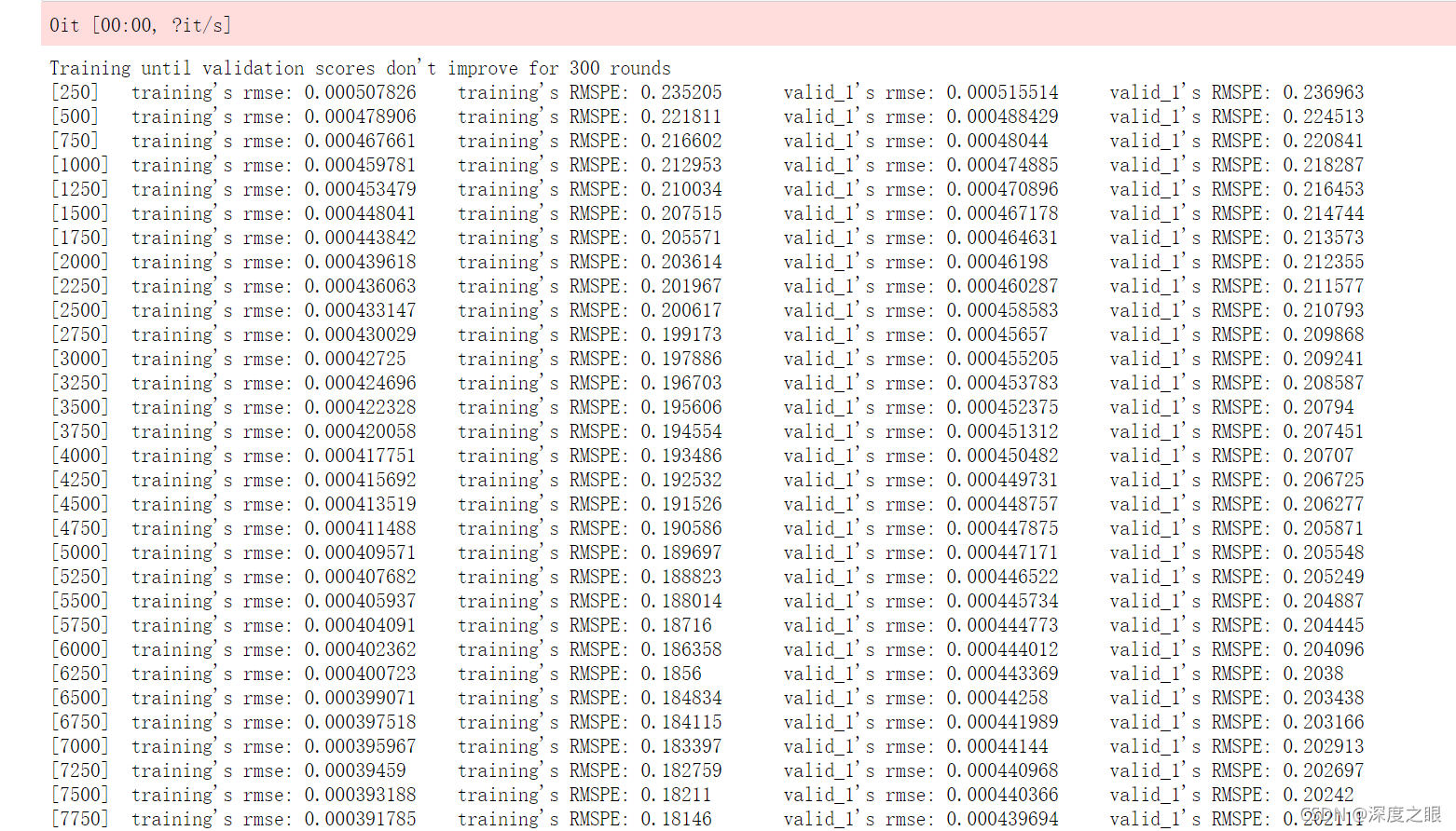
训练日志如下
4 金牌区开源代码
https://www.kaggle.com/alexioslyon/lgbm-baseline
特征工程:
# data directory
data_dir = '../input/optiver-realized-volatility-prediction/'
# Function to calculate first WAP
def calc_wap1(df):
wap = (df['bid_price1'] * df['ask_size1'] + df['ask_price1'] * df['bid_size1']) / (df['bid_size1'] + df['ask_size1'])
return wap
# Function to calculate second WAP
def calc_wap2(df):
wap = (df['bid_price2'] * df['ask_size2'] + df['ask_price2'] * df['bid_size2']) / (df['bid_size2'] + df['ask_size2'])
return wap
def calc_wap3(df):
wap = (df['bid_price1'] * df['bid_size1'] + df['ask_price1'] * df['ask_size1']) / (df['bid_size1'] + df['ask_size1'])
return wap
def calc_wap4(df):
wap = (df['bid_price2'] * df['bid_size2'] + df['ask_price2'] * df['ask_size2']) / (df['bid_size2'] + df['ask_size2'])
return wap
# Function to calculate the log of the return
# Remember that logb(x / y) = logb(x) - logb(y)
def log_return(series):
return np.log(series).diff()
# Calculate the realized volatility
def realized_volatility(series):
return np.sqrt(np.sum(series**2))
# Function to count unique elements of a series
def count_unique(series):
return len(np.unique(series))
# Function to read our base train and test set
def read_train_test():
train = pd.read_csv('../input/optiver-realized-volatility-prediction/train.csv')
test = pd.read_csv('../input/optiver-realized-volatility-prediction/test.csv')
# Create a key to merge with book and trade data
train['row_id'] = train['stock_id'].astype(str) + '-' + train['time_id'].astype(str)
test['row_id'] = test['stock_id'].astype(str) + '-' + test['time_id'].astype(str)
print(f'Our training set has {train.shape[0]} rows')
return train, test
# Function to preprocess book data (for each stock id)
def book_preprocessor(file_path):
df = pd.read_parquet(file_path)
# Calculate Wap
df['wap1'] = calc_wap1(df)
df['wap2'] = calc_wap2(df)
df['wap3'] = calc_wap3(df)
df['wap4'] = calc_wap4(df)
# Calculate log returns
df['log_return1'] = df.groupby(['time_id'])['wap1'].apply(log_return)
df['log_return2'] = df.groupby(['time_id'])['wap2'].apply(log_return)
df['log_return3'] = df.groupby(['time_id'])['wap3'].apply(log_return)
df['log_return4'] = df.groupby(['time_id'])['wap4'].apply(log_return)
# Calculate wap balance
df['wap_balance'] = abs(df['wap1'] - df['wap2'])
# Calculate spread
df['price_spread'] = (df['ask_price1'] - df['bid_price1']) / ((df['ask_price1'] + df['bid_price1']) / 2)
df['price_spread2'] = (df['ask_price2'] - df['bid_price2']) / ((df['ask_price2'] + df['bid_price2']) / 2)
df['bid_spread'] = df['bid_price1'] - df['bid_price2']
df['ask_spread'] = df['ask_price1'] - df['ask_price2']
df["bid_ask_spread"] = abs(df['bid_spread'] - df['ask_spread'])
df['total_volume'] = (df['ask_size1'] + df['ask_size2']) + (df['bid_size1'] + df['bid_size2'])
df['volume_imbalance'] = abs((df['ask_size1'] + df['ask_size2']) - (df['bid_size1'] + df['bid_size2']))
# Dict for aggregations
create_feature_dict = {
'wap1': [np.sum, np.std],
'wap2': [np.sum, np.std],
'wap3': [np.sum, np.std],
'wap4': [np.sum, np.std],
'log_return1': [realized_volatility],
'log_return2': [realized_volatility],
'log_return3': [realized_volatility],
'log_return4': [realized_volatility],
'wap_balance': [np.sum, np.max],
'price_spread':[np.sum, np.max],
'price_spread2':[np.sum, np.max],
'bid_spread':[np.sum, np.max],
'ask_spread':[np.sum, np.max],
'total_volume':[np.sum, np.max],
'volume_imbalance':[np.sum, np.max],
"bid_ask_spread":[np.sum, np.max],
}
create_feature_dict_time = {
'log_return1': [realized_volatility],
'log_return2': [realized_volatility],
'log_return3': [realized_volatility],
'log_return4': [realized_volatility],
}
# Function to get group stats for different windows (seconds in bucket)
def get_stats_window(fe_dict,seconds_in_bucket, add_suffix = False):
# Group by the window
df_feature = df[df['seconds_in_bucket'] >= seconds_in_bucket].groupby(['time_id']).agg(fe_dict).reset_index()
# Rename columns joining suffix
df_feature.columns = ['_'.join(col) for col in df_feature.columns]
# Add a suffix to differentiate windows
if add_suffix:
df_feature = df_feature.add_suffix('_' + str(seconds_in_bucket))
return df_feature
# Get the stats for different windows
df_feature = get_stats_window(create_feature_dict,seconds_in_bucket = 0, add_suffix = False)
df_feature_500 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 500, add_suffix = True)
df_feature_400 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 400, add_suffix = True)
df_feature_300 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 300, add_suffix = True)
df_feature_200 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 200, add_suffix = True)
df_feature_100 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 100, add_suffix = True)
# Merge all
df_feature = df_feature.merge(df_feature_500, how = 'left', left_on = 'time_id_', right_on = 'time_id__500')
df_feature = df_feature.merge(df_feature_400, how = 'left', left_on = 'time_id_', right_on = 'time_id__400')
df_feature = df_feature.merge(df_feature_300, how = 'left', left_on = 'time_id_', right_on = 'time_id__300')
df_feature = df_feature.merge(df_feature_200, how = 'left', left_on = 'time_id_', right_on = 'time_id__200')
df_feature = df_feature.merge(df_feature_100, how = 'left', left_on = 'time_id_', right_on = 'time_id__100')
# Drop unnecesary time_ids
df_feature.drop(['time_id__500','time_id__400', 'time_id__300', 'time_id__200','time_id__100'], axis = 1, inplace = True)
# Create row_id so we can merge
stock_id = file_path.split('=')[1]
df_feature['row_id'] = df_feature['time_id_'].apply(lambda x: f'{stock_id}-{x}')
df_feature.drop(['time_id_'], axis = 1, inplace = True)
return df_feature
# Function to preprocess trade data (for each stock id)
def trade_preprocessor(file_path):
df = pd.read_parquet(file_path)
df['log_return'] = df.groupby('time_id')['price'].apply(log_return)
df['amount']=df['price']*df['size']
# Dict for aggregations
create_feature_dict = {
'log_return':[realized_volatility],
'seconds_in_bucket':[count_unique],
'size':[np.sum, np.max, np.min],
'order_count':[np.sum,np.max],
'amount':[np.sum,np.max,np.min],
}
create_feature_dict_time = {
'log_return':[realized_volatility],
'seconds_in_bucket':[count_unique],
'size':[np.sum],
'order_count':[np.sum],
}
# Function to get group stats for different windows (seconds in bucket)
def get_stats_window(fe_dict,seconds_in_bucket, add_suffix = False):
# Group by the window
df_feature = df[df['seconds_in_bucket'] >= seconds_in_bucket].groupby(['time_id']).agg(fe_dict).reset_index()
# Rename columns joining suffix
df_feature.columns = ['_'.join(col) for col in df_feature.columns]
# Add a suffix to differentiate windows
if add_suffix:
df_feature = df_feature.add_suffix('_' + str(seconds_in_bucket))
return df_feature
# Get the stats for different windows
df_feature = get_stats_window(create_feature_dict,seconds_in_bucket = 0, add_suffix = False)
df_feature_500 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 500, add_suffix = True)
df_feature_400 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 400, add_suffix = True)
df_feature_300 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 300, add_suffix = True)
df_feature_200 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 200, add_suffix = True)
df_feature_100 = get_stats_window(create_feature_dict_time,seconds_in_bucket = 100, add_suffix = True)
def tendency(price, vol):
df_diff = np.diff(price)
val = (df_diff/price[1:])*100
power = np.sum(val*vol[1:])
return(power)
lis = []
for n_time_id in df['time_id'].unique():
df_id = df[df['time_id'] == n_time_id]
tendencyV = tendency(df_id['price'].values, df_id['size'].values)
f_max = np.sum(df_id['price'].values > np.mean(df_id['price'].values))
f_min = np.sum(df_id['price'].values < np.mean(df_id['price'].values))
df_max = np.sum(np.diff(df_id['price'].values) > 0)
df_min = np.sum(np.diff(df_id['price'].values) < 0)
# new
abs_diff = np.median(np.abs( df_id['price'].values - np.mean(df_id['price'].values)))
energy = np.mean(df_id['price'].values**2)
iqr_p = np.percentile(df_id['price'].values,75) - np.percentile(df_id['price'].values,25)
# vol vars
abs_diff_v = np.median(np.abs( df_id['size'].values - np.mean(df_id['size'].values)))
energy_v = np.sum(df_id['size'].values**2)
iqr_p_v = np.percentile(df_id['size'].values,75) - np.percentile(df_id['size'].values,25)
lis.append({'time_id':n_time_id,'tendency':tendencyV,'f_max':f_max,'f_min':f_min,'df_max':df_max,'df_min':df_min,
'abs_diff':abs_diff,'energy':energy,'iqr_p':iqr_p,'abs_diff_v':abs_diff_v,'energy_v':energy_v,'iqr_p_v':iqr_p_v})
df_lr = pd.DataFrame(lis)
df_feature = df_feature.merge(df_lr, how = 'left', left_on = 'time_id_', right_on = 'time_id')
# Merge all
df_feature = df_feature.merge(df_feature_500, how = 'left', left_on = 'time_id_', right_on = 'time_id__500')
df_feature = df_feature.merge(df_feature_400, how = 'left', left_on = 'time_id_', right_on = 'time_id__400')
df_feature = df_feature.merge(df_feature_300, how = 'left', left_on = 'time_id_', right_on = 'time_id__300')
df_feature = df_feature.merge(df_feature_200, how = 'left', left_on = 'time_id_', right_on = 'time_id__200')
df_feature = df_feature.merge(df_feature_100, how = 'left', left_on = 'time_id_', right_on = 'time_id__100')
# Drop unnecesary time_ids
df_feature.drop(['time_id__500','time_id__400', 'time_id__300', 'time_id__200','time_id','time_id__100'], axis = 1, inplace = True)
df_feature = df_feature.add_prefix('trade_')
stock_id = file_path.split('=')[1]
df_feature['row_id'] = df_feature['trade_time_id_'].apply(lambda x:f'{stock_id}-{x}')
df_feature.drop(['trade_time_id_'], axis = 1, inplace = True)
return df_feature
# Function to get group stats for the stock_id and time_id
def get_time_stock(df):
vol_cols = ['log_return1_realized_volatility', 'log_return2_realized_volatility', 'log_return1_realized_volatility_400', 'log_return2_realized_volatility_400',
'log_return1_realized_volatility_300', 'log_return2_realized_volatility_300', 'log_return1_realized_volatility_200', 'log_return2_realized_volatility_200',
'trade_log_return_realized_volatility', 'trade_log_return_realized_volatility_400', 'trade_log_return_realized_volatility_300', 'trade_log_return_realized_volatility_200']
# Group by the stock id
df_stock_id = df.groupby(['stock_id'])[vol_cols].agg(['mean', 'std', 'max', 'min', ]).reset_index()
# Rename columns joining suffix
df_stock_id.columns = ['_'.join(col) for col in df_stock_id.columns]
df_stock_id = df_stock_id.add_suffix('_' + 'stock')
# Group by the stock id
df_time_id = df.groupby(['time_id'])[vol_cols].agg(['mean', 'std', 'max', 'min', ]).reset_index()
# Rename columns joining suffix
df_time_id.columns = ['_'.join(col) for col in df_time_id.columns]
df_time_id = df_time_id.add_suffix('_' + 'time')
# Merge with original dataframe
df = df.merge(df_stock_id, how = 'left', left_on = ['stock_id'], right_on = ['stock_id__stock'])
df = df.merge(df_time_id, how = 'left', left_on = ['time_id'], right_on = ['time_id__time'])
df.drop(['stock_id__stock', 'time_id__time'], axis = 1, inplace = True)
return df
# Funtion to make preprocessing function in parallel (for each stock id)
def preprocessor(list_stock_ids, is_train = True):
# Parrallel for loop
def for_joblib(stock_id):
# Train
if is_train:
file_path_book = data_dir + "book_train.parquet/stock_id=" + str(stock_id)
file_path_trade = data_dir + "trade_train.parquet/stock_id=" + str(stock_id)
# Test
else:
file_path_book = data_dir + "book_test.parquet/stock_id=" + str(stock_id)
file_path_trade = data_dir + "trade_test.parquet/stock_id=" + str(stock_id)
# Preprocess book and trade data and merge them
df_tmp = pd.merge(book_preprocessor(file_path_book), trade_preprocessor(file_path_trade), on = 'row_id', how = 'left')
# Return the merge dataframe
return df_tmp
# Use parallel api to call paralle for loop
df = Parallel(n_jobs = -1, verbose = 1)(delayed(for_joblib)(stock_id) for stock_id in list_stock_ids)
# Concatenate all the dataframes that return from Parallel
df = pd.concat(df, ignore_index = True)
return df
# Function to calculate the root mean squared percentage error
def rmspe(y_true, y_pred):
return np.sqrt(np.mean(np.square((y_true - y_pred) / y_true)))
# Function to early stop with root mean squared percentage error
def feval_rmspe(y_pred, lgb_train):
y_true = lgb_train.get_label()
return 'RMSPE', rmspe(y_true, y_pred), False
模型1-LGB
def feval_rmspe(y_pred, lgb_train):
y_true = lgb_train.get_label()
return 'RMSPE', rmspe(y_true, y_pred), False
def train_and_evaluate_lgb(train, test, params):
# Hyperparammeters (just basic)
features = [col for col in train.columns if col not in {"time_id", "target", "row_id"}]
y = train['target']
# Create out of folds array
oof_predictions = np.zeros(train.shape[0])
# Create test array to store predictions
test_predictions = np.zeros(test.shape[0])
# Create a KFold object
kfold = KFold(n_splits = 5, random_state = 2021, shuffle = True)
# Iterate through each fold
for fold, (trn_ind, val_ind) in enumerate(kfold.split(train)):
print(f'Training fold {fold + 1}')
x_train, x_val = train.iloc[trn_ind], train.iloc[val_ind]
y_train, y_val = y.iloc[trn_ind], y.iloc[val_ind]
# Root mean squared percentage error weights
train_weights = 1 / np.square(y_train)
val_weights = 1 / np.square(y_val)
train_dataset = lgb.Dataset(x_train[features], y_train, weight = train_weights)
val_dataset = lgb.Dataset(x_val[features], y_val, weight = val_weights)
model = lgb.train(params = params,
num_boost_round=1000,
train_set = train_dataset,
valid_sets = [train_dataset, val_dataset],
verbose_eval = 250,
early_stopping_rounds=50,
feval = feval_rmspe)
# Add predictions to the out of folds array
oof_predictions[val_ind] = model.predict(x_val[features])
# Predict the test set
test_predictions += model.predict(test[features]) / 5
rmspe_score = rmspe(y, oof_predictions)
print(f'Our out of folds RMSPE is {rmspe_score}')
lgb.plot_importance(model,max_num_features=20)
# Return test predictions
return test_predictions
# Traing and evaluate
predictions_lgb= train_and_evaluate_lgb(train, test,params0)
test['target'] = predictions_lgb
test[['row_id', 'target']].to_csv('submission.csv',index = False)
模型2-NN模型
#https://bignerdranch.com/blog/implementing-swish-activation-function-in-keras/
from keras.backend import sigmoid
def swish(x, beta = 1):
return (x * sigmoid(beta * x))
from keras.utils.generic_utils import get_custom_objects
from keras.layers import Activation
get_custom_objects().update({'swish': Activation(swish)})
hidden_units = (128,64,32)
stock_embedding_size = 24
cat_data = train_nn['stock_id']
def base_model():
# Each instance will consist of two inputs: a single user id, and a single movie id
stock_id_input = keras.Input(shape=(1,), name='stock_id')
num_input = keras.Input(shape=(244,), name='num_data')
#embedding, flatenning and concatenating
stock_embedded = keras.layers.Embedding(max(cat_data)+1, stock_embedding_size,
input_length=1, name='stock_embedding')(stock_id_input)
stock_flattened = keras.layers.Flatten()(stock_embedded)
out = keras.layers.Concatenate()([stock_flattened, num_input])
# Add one or more hidden layers
for n_hidden in hidden_units:
out = keras.layers.Dense(n_hidden, activation='swish')(out)
#out = keras.layers.Concatenate()([out, num_input])
# A single output: our predicted rating
out = keras.layers.Dense(1, activation='linear', name='prediction')(out)
model = keras.Model(
inputs = [stock_id_input, num_input],
outputs = out,
)
return model
5 总结
希望大家可以在金牌大神开源代码基础之上,继续深化特征,结合量化交易的一些业务领域特征应该能够取得不错的成绩,加油~
完整代码可通过私信联系小编获取
署名作者:小李飞刀