? ? ? ? 在调制识别任务中使用空间转换网络引入注意力模型,并引入新的无线领域的合适的变换。这种注意力模型允许网络学习一个定位网络,该网络能够基于对网络进行分类精度、稀疏表示和正则化的优化,在对信号结构的零知识的情况下直接同步和规范化无线电信号。
I 介绍
? ? ? ? 以前的工作中没有注意力模型,而是让网络对每个信道效应不变地学习特征。在通信接收器或很多调制分类算法中,我们在信号处理前都要对信号执行同步,这种同步可以被看作一种注意力,估计了时间、频率、相位和采样时间偏移以生成信号标准化版本。
? ? ? ? 注意力模型可以去除输入数据中的大量差异和参数搜索空间,专注于提取规范形式注意力patch的任务,去除这些变化可以使下游任务更容易,复杂度更低。
? ? ? ? 空间transformer网络STN提供了一个端对端地前馈注意力模型,能够直接在每个训练样本的损失上训练并在新样本上评估,由执行参数回归的训练有素的定位网络、固定参数变换操作和训练有素的判别分类器组成,以选择类估计。
? ? ? ? 本文中,我们提出一个无线transformer网络RTN,使用STN结构的泛化,但是引入了无线域中的参数变换。可以用来直接学习无线系统中如何同步以及在分类前使我们的调制识别系统在收到信号归一化的前提下性能超过注意力模型本身的版本。
? ? ? ? 我们可以学习同步而不是依赖于专家和通过分析得到的估计。
II 学习分类信号
? ? ? ? 以前使用的网络结构如图:

? ? ? ? ?如下图是其性能提升:

III 使用注意力同步
? ? ? ? ? ? ? ? 为了实现同步,需要设计一种拥有正确参数,能够校正信道引起变化的变换。本文思考了由于时间偏移、时间膨胀、频率偏移和相位偏移引起的信道变化,这些存在于任何包含发送器和接收器的现实系统中(振荡器和时钟没有锁在一起),现在不考虑衰落问题,但相信均衡也有可能作为注意力模型来解决。
A?.时序和符号率恢复
? ? ? ? 时序和符号率恢复输入是相对简单的过程,涉及以正确的起始偏移和采样增量重新采样输入信号。这类似于一维仿射变换中在正确偏移处提取视觉像素,因此我们通过直接利用图像域中使用的仿射变换来处理它。把我们的信号看作2维图像,两行IQ,N列的时间数据样本。
????????完整的 2D 仿射变换允许在由 2x6 元素参数向量给出的二维中进行平移、旋转和缩放。为了限制它到时间维度的一维平移与缩放,我们引入下列掩码1,使能够轻松使用图像域的2D 仿射变换实现。

B 相位和频率偏移恢复
?????????我们将信号与由两个新的未知参数定义的有合适的初始相位和频率的复数正弦曲线混合进行恢复。
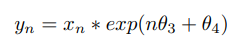
? ? ? ? ?我们把这种变换作为一个新层,在仿射变换前级联它。
C 参数估计
? ? ? ? 同步任务变成一个参数θi的估计任务,我们引入两种新的域的合适的层去估计。
1)?Complex Convolution 1D Layer:
? ? ? ? 复数神经网络面临很多理论问题特别是自动微分,所以我们使用2维的实值数据表示我们的信号IQ路,理论上实值卷积可以在某种程度上学到他们之间的关系,但是通过引入复值卷积操作,我们可以简化学习任务并确保我们能学习到我们用的滤波器。?????????????????
?????????对于复值输入向量X:2*N,定义M个复值滤波器的权重向量W:2*K,计算k个输出的每一个输出值为:

? ? ? ? ?我们使用实值卷积操作,获得一个获得可以用反向传播训练的可微操作。
2)Complex to Power and Phase:
????????创建可微分的笛卡尔到极坐标运算,使网络更容易直接对输入相位和幅度进行运算。计算幅度平方![]() ,但对于相位计算,我们使用 atan2 的简化和可微近似,它没有在 Theano 之上的 Keras 中实现的条件和张量流。
,但对于相位计算,我们使用 atan2 的简化和可微近似,它没有在 Theano 之上的 Keras 中实现的条件和张量流。

?3)网络结构
? ? ? ? 我们对十几个在层连接、卷积层和复值卷积层有轻微变化,使用不同激活函数的定位网络结构进行评估,使用下列网络得到了最好的性能。

? ? ? ? ?在定位网络内使用了复数卷积层和复数到极坐标层?,使用了一个我们以前使用的没有注意了模型的判别网络。
4)训练细节:
? ? ? ? 每层之间dropout 0.5为了正则化,SGD的Adam。batch size1024,最初的lr0.001,训练350epochs,每当验证损失停止减少时学习率降低一半。
?IV?DATA-SET AND METHODOLOGY
? ? ? ? 使用RadioM来016.04c,6:4划分训练和测试集,包含11种调制方式(8数字,3模拟),有随意的中心频率,采样时钟率,采样时钟偏移和最初相位,还有有限的多径衰落。
????????
?V 分类性能
? ? ? ? 评估模型,相比没有注意力,我们RTN获得了轻微增加的性能,在相对低的SNR(1dB)有相似的精确度,在高SNR有轻微的提升并且更稳定。

? ? ? ? ?我们猜测,若是输入更低复杂度的标准化信号,区分网络的复杂度应该会减少,但我们在此没有研究作为对比。
? ? ? ? 采用增加dr和RTN中更好的学习率的策略,我们以前的没有注意力的CNN的性能也会得到提升,如图6.
VI 注意力学习性能
? ? ? ? 观察变换前后信号样本已发生的任何归一化,绘制QPSK的眼图,其同步仍然有噪音并且时局部的,但如果我们50个测试样本在20次采样的星座密度,可以看到在星座点周围形成的密度比我们开始时的密度要高一些,这是一个好兆头。
????????
? ? ? ? ?所以我们进一步需要做的是提高同步性能,达到足够的归一化以使区分任务更简单。
VII 结论
? ? ? ? 设计一个无线电主义的前馈模型,我们能使用有具体变换和层配置的深度CNN有效地学习同步,使用学习估计器归一化时间膨胀、频率相位偏移能够提高调制分类的性能。
? ? ? ??虽然这种网络的训练复杂度很高,但它的前馈执行实际上非常紧凑,并且对于现实世界的使用和部署是可行的。具有高度并行、低时钟速率 GPGPU 架构的 TX1 等平台进一步支持这些算法的低 SWaP 部署,它们非常适合这些算法。