导读:bert性能优化的方法比较多,这一问题在NLP算法面试中时常被提起,平时做项目过程中,对bert模型进行优化也是经常遇到的。
对bert进行优化前,需要了解bert是个什么鬼,bert简言之是一个语言模型,它由Google公司所发明,英文全称是Bidirectional Transformer。架构图如下:
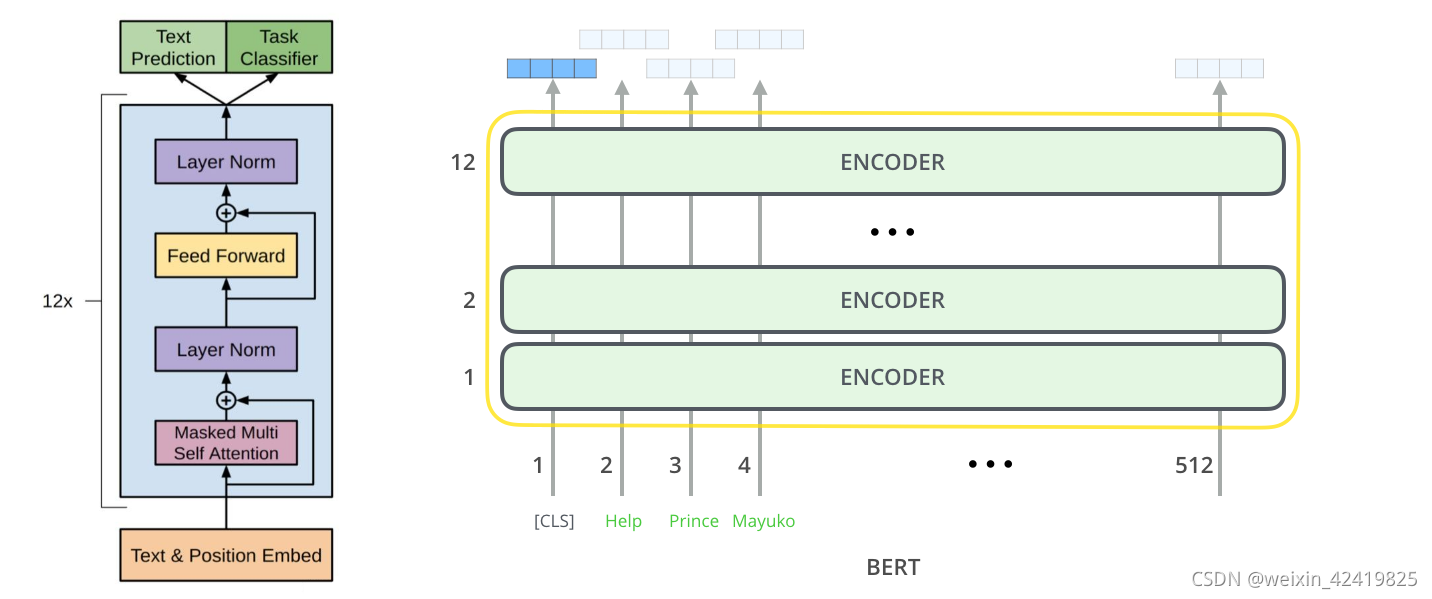
对其优化可从以下几点入手:
1 、压缩层数,然后蒸馏,直接复用12层bert的前4层或者前6层,效果能和12层基本持平,如果不蒸馏会差一些。
2 、双塔模型(短文本匹配任务),将bert作为一个encoder,输入query编码成向量,输入title编码成向量,最后加一个DNN网络计算打分即可。离线缓存编码后的向量,在线计算只需要计算DNN网络。
3 、int8预估,在保证模型精度的前提下,将Float32的模型转换成Int8的模型。
4 、提前结束,大致思想是简单的case前面几层就可以输出分类结果,比较难区分的case走完12层,但这个在batch里面计算应该怎么优化还没看明白,有的提前结束有的最后结束,如果在一个batch里面的话就不太好弄。
5 、ALBERT 做一些改进优化,主要是不同层之间共享参数,以及用矩阵分解降低embedding的参数。
6、BERT上面加一些网络结构,比如attention,rcnn等,个人得到的结果感觉和直接在上面加一层transformer layer的效果差不多,模型更加复杂,效果略好,计算时间略增加。
7、改进预训练,在特定的大规模数据上预训练,相比于开源的用百科,知道等数据训练的更适合你的任务(经过多方验证是一种比较有效的提升方案)。以及在预训练的时候去mask低频词或者实体词(听说过有人这么做有收益,但没具体验证)。
8、文本对抗,作者了解的不多。
9、最有效的方式还是数据。
10、经过验证降低参数量相对于优化效果以及计算速度来说,并不是特别重要。
bert相比LSTM优点:bert通过使用self-attention + position embedding对序列进行编码,lstm的计算过程是从左到右从上到下(如果是多层lstm的话),后一个时间节点的emb需要等前面的算完,而bert这种方式相当于并行计算,虽然模型复杂了很多,速度其实差不多。
说了这么多,需要使用bert进行实战。
**
目的
**:本文使用bert实现一个简单的文本分类任务。比如输入一句话,对其进行情感分类。(正向1,负向-1,中性为0)。
**
步骤
**:(1)数据加载;(2)数据预处理;(3)微调预训练模型:使用transformer中的Trainer接口对预训练模型进行微调;(4)超参数搜索。
-
数据加载
使用GLUE榜单数据集,GLUE榜单包含了9个句子级别的分类任务。具体可见(https://ifwind.github.io/2021/08/26/BERT%E5%AE%9E%E6%88%98%E2%80%94%E2%80%94%EF%BC%881%EF%BC%89%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB/). -
加载数据
可以使用 Datasets库来加载数据load_dataset的方法,加载官方库的数据;
也可以加载自己的数据或来自网络的数据:
csv格式;
json格式;
txt格式
pandas.DataFrame格式。 -
数据预处理
在将数据喂入模型之前,需要对数据进行预处理。之前我们已经知道了数据预处理的基本流程:
- 分词;
- 转化成对应任务输入模型的格式;
Tokenizer用于上面两步数据预处理工作:Tokenizer首先对输入进行tokenize,然后将tokens转化为预模型中需要对应的token ID,再转化为模型需要的输入格式。
初始化Tokenizer
使用AutoTokenizer.from_pretrained方法根据模型文件实例化tokenizer,这样可以确保:
得到一个与预训练模型一一对应的tokenizer。
使用指定的模型checkpoint对应的tokenizer时,同时下载了模型需要的词表库vocabulary,准确来说是tokens vocabulary.
- 微调预训练模型
- 加载预训练模型
既然是做seq2seq任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForSequenceClassification 这个类。和tokenizer相似,from_pretrained方法同样可以帮助下载并加载模型,同时也会对模型进行缓存,也可以填入一个包括模型相关文件的文件夹(比如自己预训练的模型),这样会从本地直接加载。理论上可以使用各种各样的transformer模型(模型面板),解决任何文本分类分类任务。 - 设定训练参数
为了能够得到一个Trainer训练工具,我们还需要训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
之后就可以训练模型,进行模型评估和模型验证等工作.
参考:
[1] bert实战-文本分类https://ifwind.github.io/2021/08/26/BERT%E5%AE%9E%E6%88%98%E2%80%94%E2%80%94%EF%BC%881%EF%BC%89%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB/