����Ŀ¼
1. ���ݻ�ȡ
1.1 �����ھ�Ķ���
(1)��ϵ�����ݿ⡢���������ݿ⡢�����������ݿ�;
(2)���ݲֿ�/��ά���ݿ�;
(3)�ռ�����(���ͼ��Ϣ)
(4)��������(�罨�������ɵ�·����Ϣ)
(5) �ı��Ͷ�ý������(���ı���ͼ����Ƶ����Ƶ����)
(6)ʱ����ص�����(����ʷ���ݻ��Ʊ��������)
(7)��ά��(���ṹ����HTML,�ṹ����XML�Լ�����������Ϣ)
1.2�����ھ�IJ���
(1)��������(����������һ������,��ȱ);
(2)���ݼ���((��������Դ���������һ��);
(3)����ѡ��(�����ݿ�����ȡ��ص�����);
(4)���ݱ任(�任���ʺ��ھ����ʽ);
(5)�����ھ�(ʹ�����ܷ�����ȡ����ģʽ);
(6)ģʽ����(ʶ���ṩ֪ʶ��������Ȥģʽ);
(7)֪ʶ��ʾ(���ӻ���֪ʶ��ʾ����)��
1.3֧�������ھ�Ĺؼ�����
(1)���ݿ�/���ݲֿ�/OLAP
(2) ��ѧ/ͳ��(�ع����:��Ԫ�ع顢�Իع�;�б����:Bayes�б�Fisher�б𡢷Dz����б�;���ɷַ���������Է���;ģ����;�ֲڼ�)
(3)����ѧϰ(�������;��������;������;��������;��Ҷ˹����;������;֧��������;�Ŵ��㷨)
(4)���ӻ�:�����ݡ�֪ʶ����ת��Ϊͼ�α��ֵ���ʽ��
1.4���ݲֿ�
(1)���ݲֿ���һ����������ġ����ɵġ���ʱ��仯�ġ�����ʧ�����ݵļ���,����֧�ֹ�����Ա�ľ��ߡ�
(2)���ݲֿ���һ�ֶ����������Դ�ڵ���վ����ͳһ��ģʽ��֯�Ĵ洢,��֧�ֹ������ߡ����ݲֿ⼼�������������������ݼ��ɺ�������������( OLAP) ��
(3)���ݲֿ�����ṹ�Ƕ�ά���ݿ⡣���ݲֿ��ʵ�������ṹ�����ǹ�ϵ���ݴ洢����ά���ݷ�(Cube) ��
(4)���ݷ�����ά��(Dimension)������(Measure)�����һ�����ݼ�,�����������ά�����������ݷ���Ԫ�С�ά�ȶ�Ӧ��ģʽ�е�������,������Ӧ����������ص���ʵ���ݡ����ݷ����ﻯ��ָԤ���㲢�洢ȫ���ֵ�Ԫ�еĶ�����
1.5���ݲֿ��ģ��
(1)**����ģʽ:**���ģ��;�������ݲֿ����һ����ġ������������ݡ�������������ı�(��ʵ��)�rһ��С�ĸ�����(ά��),ÿάһ����
(2)**ѩ��ģʽ:**ѩ��ģʽ������ģʽ�ı���,����ijЩά���ǹ淶����,��������ݽ�һ���ֽ���ӵı��С�
(3)**��ϵģʽ:**�����ʵ������ά��������ģʽ���Կ�������ģʽ��,��˳�Ϊ��ϵģʽ,����ʵ������
1.6���͵�OLAP����
(1) OLAP��һ�ֶ�ά���ݷ����������������ܡ��ϲ��;ۼ��ȹ���,�Լ��Ӳ�ͬ�ĽǶȹ۲���Ϣ��������
(2�Ͼ�: ��ijһά�ȵĸ��߸����ι۲����ݷ�,��ø���Ҫ�����ݡ���ͨ����ά�ĸ���ֲ����ϻ�ά��Լ��ʵ�֡�
(3)����: �������Ͼ��������������ijһά�ȵĸ������ι۲����ݷ�,��ø���ϸ�����ݡ��������ͨ����ά�ĸ�������»������µ�ά��ʵ�֡�
(4)��Ƭ���п�: ��Ƭ�����ڸ��������ݷ���ѡ��һ��ά�IJ�������,���һ����С�������ݷ����п����ͨ����ѡ����������ά�IJ�������,���һ����С�������ݷ�
(5)ת��: ��һ�ָı����ݷ���άչ����ʽ�IJ������������ݷ��Ķ�άչ���е�ijЩά�����и�Ϊ��,�����и�Ϊ�С�
2 ������
- ��ʵ�������������������(��Щ����Ȥ������ȱ������ֵ,��������ۼ�����),��������(��������,�����ƫ���������쳣ֵ),��һ�µ�(����,������Ʒ����IJ��ű�����ڲ���)��
- ��Ҫ�������������ݼ��ɡ�����ѡ�����ݱ任�ȼ��������ݽ��д�����
2.1 ά��Լ/������ȡ
2.1.1��������Լ
(1)��������Լ����һ������������ͼ�Ľṹ:��ÿ����Ҷ�ӽ���ʾһ�������ϵIJ���,ÿ����֦��Ӧ�Ӳ��Ե�һ�����;ÿ��Ҷ�ӽ���ʾһ�������ࡣ
(2)��ÿ�����,�㷨ѡ��ǰ�Է������а�����������,���������е������γɹ�Լ��������Ӽ���
2.1.2�ֲڼ���Լ
(1)�ֲڼ���������ѧ������������֪ʶ�IJ�ȷ����,�����ص��ǰ����ڷ����֪ʶǶ�뼯����,ʹ������֪ʶ��ϵ��һ��
(2)֪ʶ�����ȡ����ɷֱ��ϵ���Ͻ��ơ��½��ơ��߽�ȸ������ͼ��
(3)��Q�������Եļ��ϡ�
q
��
Q
q\in Q
q��Q��һ������,���IND(Q-q)= IND(Q),��q��S�в��Ƕ�����;�����q��s���Ƕ����ġ�
(4)����������IND?= IND(Q)��R�е�ÿһ�����Զ��Ƕ�����,��R����ΪQ��һ����Լ��,����R=RED(Q)��
(5)Լ�����ͨ��ɾ�������(��������)���Զ����,Լ����������Լ�Ϊ���Է����а����������ԡ�
2.2 ���ݱ任
2.2.1��һ����ģ����
��������Ĺ�һ��:
��������Ĺ�һ��:
2.2.2�˺���
(1)�˺����Ļ���˼���ǽ�����ά�����������Բ��ɷ�������ӳ�䵽���Կɷֵĸ�ά�����ռ���ȥ��
(2)ӳ���������ʽ��,Ҳ��������ʽ�ġ���ʽӳ�伴�ҵ�һ��ӳ���ϵf,ʹ��ά�ռ����������f (x)���Ա�ֱ�Ӽ��������
(3)��ʽӳ��,������һ���˺����������崦��,�ͱ����˶Ե�ֱ����f(x)�ļ������ѡ��˺�����ij��ά�����ռ����������ڻ�,�Ǻ˾����е�һ��Ԫ�ء�
(4)���������е�ʵֵ����f(x)��������Ϊ�ռ�ӳ��ĺ˺���,ֻ��f(x)��ijһ�����ռ���ڻ�ʱ,������Mercer����,�����ܳ�Ϊ�˺�����
- ����ʽ����
- ��˹(RBF)����
- ����֪������
- ��ά�ռ�����ӳ�䵽��ά�ռ�����
2.3 ����ѹ��
2.3.1 ��ɢ��
-
��ɢ������;:
- (1)��ӦijЩ��������ɢֵ���㷨;
- (2)��С���ݵij߶ȡ�
-
��ɢ���ķ����������¼��֡�
-
(1)�Ⱦ�ָ�;
-
(2)����ָ�;
-
(3)ֱ��ͼ�ָ�;
-
(4)���ڵյķָ�;
-
(5) ������Ȼ���Եķָ
2.3.2 �ع�
- �ع�Ͷ�������ģ�Ϳ����������Ƹ��������ݡ�
- �����Իع���,��һ��ֱ����ģ�����ݵ����ɹ���
- ��Ԫ�ع������Իع����չ,�漰���Ԥ�������
- ������ʽ�ع���,ͨ���Ա������б任,���Խ�������ģ��ת�������Ե�,Ȼ������Сƽ���ͷ���⡣
- �������Իع����Ϊ����ȡֵ�ĺ�����ģ����������ģ����������ڶ���ɢȡֵ�������лع齨ģ��
- �ڹ�������ģ����,�����Y�ı仯������Y��ֵ��һ������;��һ�������Իع鲻ͬ�������Ĺ�������ģ����:�����ع�Ͳ��ɻع顣
- �����ع�ģ��������һЩ�¼������ĸ�����Ϊ�Ա��������������Իع�ģ�͡�
- ���ɻع�ģ����Ҫ���������ݳ��ִ�����ģ��,��Ϊ���dz�������Ϊ���ɷֲ���
2.3.3 ���ɷַ���(PCA)
- PCA�㷨����c�����ܴ������ݵ�k-ά��������;����c��k������,ԭ��������ͶӰ��һ����С�Ŀռ�,��������ѹ������������:
(1)���������ݹ�һ��,ʹ��ÿ�����Զ�������ͬ�����䡣
(2)PCA����c���淶��������,��Ϊ��һ���������ݵĻ�����Щ�ǵ�λ����,ÿһ������ֱ����һ��:��Ϊ���ɷ֡�������������Ҫ�ɷֵ�������ϡ�
(3)�����ɷְ������塱��ǿ�Ƚ�������,ѡ�����ɷֳ䵱���ݵ�һ���������ᡣ
2.3.4 ��ɢС���任(DWT)
- ��ɢС���任��һ�������źŴ����������ü����������Խ�һ����������ת��Ϊ��һ����������(ΪС�����ϵ��);������������������
- ��������ת��������������е�һЩС�����ϵ�����������д����û�ָ����ֵ��С��ϵ��,��������С��ϵ����Ϊ0,����������ݴ���������Ч�ʡ�
- ��һ������������������������Ҫ�����������ȥ�����е�����,��˸÷���������Ч�ؽ���������ϴ��
- ����һ��С�����ϵ��,������ɢС���任�������㻹���Խ��ƻָ�ԭ��������
3 ����Ԥ����
�����ھ��ǰ��:��ʵ�����е�������Դ���ӡ������,�������Ա���ش���ȱʧ����������һ�µ����⡣Ϊ����������ھ������,����������Ԥ����������
���ݺ����������˻���ѧϰ������,����ѡģ�ͺ��㷨ֻ��ȥ�ƽ�������ޡ�
ͨ��������ȡ,�����ܵõ�δ������������,��ʱ��������������������:
- ������ͬһ����:�������Ĺ��һ��,���ܹ�����һ��Ƚϡ�
- ��Ϣ����:����ijЩ��������,���������Ч��ϢΪ���仮��,����ѧϰ�ɼ�,����ֻ���ġ���������,��ô��Ҫ�������Ŀ���,ת���ɡ�1�͡�o��ʾ�����δ����
- ������������ֱ��ʹ��:ijЩ����ѧϰ�㷨��ģ��ֻ�ܽ��ܶ�������������,��ô��Ҫ����������ת��Ϊ����������
- ����ȱʧֵ:ȱʧֵ��Ҫ���䡣
- ��Ϣ�����ʵ�:��ͬ�Ļ���ѧϰ�㷨��ģ�Ͷ���������Ϣ�������Dz�ͬ�ġ�
- �����ݵ�ά������ʱ���������ν�ġ�ά������(Curse of dimensionality)������,���ߵ�ά�Ȳ��������˼�����,�������ܻή���㷨��Ч����
����������Ԥ��������:
��������ϴ
�������ݵ�ijЩ��¼ֵȱʧ,ƽ�������е������������쳣ֵ,������һ�µȡ�
�������ں�
����ͬ��Դ�ġ����ʵ������ںϵ�һ�����õ������ںϿ��Լ��������е�����Ͳ��D����,����������������ľ��Ⱥ��ٶȡ�
������ת��
ͨ��ƽ���ۼ�,���ݸŻ�,�淶���ȷ�ʽ������ת���������������ھ����ʽ��
�����ݽ�ά
����ά�����ݻ�Ϊ��ά������,�Ա���ԭ���ݵĴ���Ϣ,ʹ�����ھ����뽵άǰ�����ͬ����ͬ��
3.1 ������ϴ
3.1.1 ȱʧֵ����
-
ȱʧֵ��ʵ���������Dz��ɱ��������,���ڲ�ͬ�����ݳ���Ӧ�ò�ȡ��ͬ�IJ���,����Ӧ���ж�ȱʧֵ�ķֲ����:
- ���ȱʧֵ���������ά����Ϣ����Ҫ,һ��ɾ�����Ƕ��������������Ӱ�첻��;
- ���ȱʧֵ�϶�����ά�ȵ���Ϣ������Ҫ��ʱ��,ֱ��ɾ����Ժ�����㷨�ܵĽ����ɲ��õ�Ӱ�졣
-
���dz��õ����������¼���:
-
ֱ��ɾ�������ʺ�ȱʧֵ������С,������������ֵ�,ɾ�����Ƕ���������Ӱ�첻������;
-
ʹ��һ��ȫ�ֳ�����䡪��Ʃ�罫ȱʧֵ�á�unknown�����,����Ч����һ����,��Ϊ�㷨���ܻ����ʶ��Ϊһ���µ����,һ�������;
-
ʹ�þ�ֵ����λ������:
- �ŵ�:�������������Ϣ,������
- ȱ��:��ȱʧ���ݲ����������ʱ�����ƫ��,���������ֲ������ݿ���ʹ�þ�ֵ����,�����������б��,ʹ����λ�����ܸ��á�
-
�岹��
- 1)����岹�������������������ȡij����������ȱʧ����
- 2)���ز岹������ͨ������֮��Ĺ�ϵ��ȱʧ���ݽ���Ԥ��,�����������ؿ��巽�����ɶ�����������ݼ�,�ڶ���Щ���ݼ����з���,���Է���������л��ܴ���
- 3)��ƽ̨�岹����ָ�ڷ�ȱʧ���ݼ����ҵ�һ����ȱʧֵ�����������Ƶ�����(ƥ������)�������еĹ۲�ֵ��ȱʧֵ���в岹��
- 4)�������ղ�ֵ����ţ�ٲ�ֵ��
-
5.��ģ�����������ûع顢ʹ�ñ�Ҷ˹��ʽ�������Ļ��������Ĺ������������ȷ��������,�������ݼ����������ݵ�����,���Թ���һ���ж���,��Ԥ��ȱʧֵ��ֵ��
���Ϸ���������ȱ��,�������Ҫ����ʵ�����ݷֲַ��������б�̶ȡ�ȱʧֵ��ռ�����ȵ���ѡ����һ�����,��ģ���DZȽϳ��õķ���,���������е�ֵ��Ԥ��ȱʧֵ,ȷ�ʸ��ߡ�
3.1.2 �쳣ֵ����
�쳣ֵ����ͨ��Ҳ��Ϊ����Ⱥ�㡱( outlier),���������ռ���,�������������һ����Ϊ��������һ�µĵ㡣һ���������������ԭ��:
- ����������߲����Ĵ�������,����:ij�˵�����-999��,���������������������µ���Ⱥ��;
- ���ݱ����Ŀɱ��Ի�������,����:һ����˾��CEO�Ĺ��ʿ϶������Ը���������ͨԱ���Ĺ���,����CEO���Ϊ���������ݱ����ɱ��������µ���Ⱥ�㡣
ע��:��Ⱥ�㲻һ������������:��Ҳ�������û�����Ȥ��,��������թ�������,��Щ������������Ϊ��һ�µ���Ⱥ��,����Ԥʾ��Ƕթ��Ϊ,��˳�Ϊִ��������ע�ġ�
-
�����쳣ֵ��ⷽ��:
-
1.����ͳ�Ʒֲ�����Ⱥ����
�����ⷽ�����������ռ����������ݷ���ij���ֲ���������ģ��,Ȼ�����ģ�Ͳ��ò���гУ��( discordancy test )ʶ����Ⱥ�㡣����:-
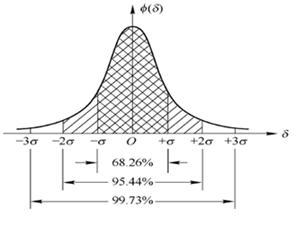
1)3 ? \partial ?ԭ��
������ݷ�����̬�ֲ�,��3 ? \partial ?ԭ����,�쳣ֵΪһ��ⶨֵ����ƽ��ֵ��ƫ���3�������ֵ��������ݷ�����̬�ֲ�,����ƽ��ֵ3 ? \partial ?֮���ֵ���ֵĸ���ΪP(|x-u] > 3 ? \partial ?)<=0.003,���ڼ������С�����¼���������ݲ������̬�ֲ�,Ҳ������Զ��ƽ��ֵ�Ķ��ٱ�������������
-
2)����ͼ����
����ͼ�ṩ��ʶ���쳣ֵ��һ����:���һ��ֵС��QL-1.5IQR�����QU-1.51QR��ֵ,��Ϊ�쳣ֵ��QLΪ���ķ�λ��,��ʾȫ���۲�ֵ�����ķ�֮һ������ȡֵ����С;QuΪ���ķ�λ��,��ʾȫ���۲�ֵ�����ķ�֮һ������ȡֵ������;IQRΪ�ķ�λ�����,�����ķ�λ��QU�����ķ�λ��QL�IJ�ֵ,������ȫ���۲�ֵ��һ�롣����ͼ�ж��쳣ֵ�ķ������ķ�λ�����ķ�λ��Ϊ����:�ķ�λ������³���ԡ�25%�����ݿ��Ա������Զ���Ҳ�������ķ�λ��,�����쳣ֵ���ܶ������ʩ��Ӱ�졣�������ͼʶ���쳣ֵ�ȽϿۡ���ʶ���쳣ֵʱ��һ������Խ�ԡ�
-
-
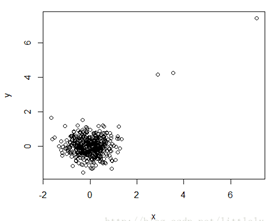
2.���ھ������Ⱥ����
ͨ�������ڶ���֮�䶨���ڽ��Զ���,�쳣��������ЩԶ����������Ķ�����������ռ�D��������N�������������O�ľ������dmin,��ô�ƶ���O����(����N��������}��dminΪ�����Ļ��ھ������Ⱥ�㡣
�ŵ�:��;
ȱ��:- �����ڽ������ķ�����Ҫo( m 2 m^2 m2)ʱ��,�����ݼ�������;
- �÷����Բ�����ѡ��Ҳ�����е�,��ͬ�ľ����������Ҳ��һ��;
- ���ܴ������в�ͬ�ܶ���������ݼ�,��Ϊ��ʹ��ȫ����ֵ,���ܿ��������ܶȵı仯��
-
3.�����ܶȵľֲ���Ⱥ����
��һ����ľֲ��ܶ������������Ĵֽ���ʱ�Ž������Ϊ��Ⱥ�㡣�ʺϷǾ��ȷֲ������ݡ���ͬ�ڻ��ھ���ķ���,�����ܶȵ���Ⱥ���ⲻ����Ⱥ�㿴��һ�ֶ�Ԫ����,��������Yes or No���϶�һ�����Ƿ�����Ⱥ��,������һ��Ȩֵ������������Ⱥ�ȡ����Ǿֲ���,��˼�Ǹó̶������ֶ�������ڻ�����Ĺ�����������ַ���������ʱ����ȫ����Ⱥ��;ֲ���Ⱥ�㡣
�ŵ�:�����˶�������Ⱥ��Ķ�������,���Ҽ�ʹ���ݾ��в�ͬ������Ҳ�ܹ��ܺõĴ���;
ȱ��û��ھ���ķ���һ��,����o( m 2 m^2 m2)��ʱ��ʱ�临�Ӷ�,���ڵ�ά����ʹ���ض������ݽṹ���Դﵽo(mlogm) ;
����ѡ�����ѡ���Ȼ��Ҫѡ����Щ��Ⱥ�ȵ����½硣
�쳣ֵ������������:
- ɾ���쳣ֵ�������Կ������쳣���������ٿ���ֱ��ɾ��
- ��������������㷨���쳣ֵ����������Բ�����,������㷨���쳣ֵ����,����ò�Ҫ��,����ھ�������һЩ�㷨,����kmeans,knn֮��ġ�
- ƽ��ֵ���������ʧ��ϢС,��Ч��
- ��Ϊȱʧֵ���������մ���ȱʧֵ�ķ���������
3.1.3 ����ȥ��
- ����ȥ��
�����ظ���ʵ�������кܳ���,��һЩ�����ھ�ģ����,��Щ��������ݼӴ������ݷ������ѶȺʹ����ٶ�,�����Ҫ������ȥ�ء� - ��������:
1.������������,���Ӷȸ�,�����������ݹ�ģ��С�����Ρ�
2.��ϣ��ʾ,��������ָ��,��Ч,�����ڴ��ģ����,�����㷨: - Bitmap:λͼ��
- SimHash:���ƹ�ϣ
- ��¡������
3.1.4 ����ȥ��
-
����ȥ��
����,�DZ������������������������������ᵽ���쳣��(��Ⱥ��),��ô��Ⱥ��������Dz���һ������? -
�۲���(Measurement)=��ʵ����(True Data)+����(Noise)
-
��Ⱥ��(Outlier)���ڹ۲���,���п�������ʵ���ݲ�����,Ҳ�п���������������,�����ܵ���˵�Ǻʹֹ۲���֮�������Բ�ͬ�Ĺ۲�ֵ��
-
������������ֵ��ƫ�������Ĺ�����ֵ,��Ҳ����˵�����������Ⱥ��,��Ȼ�������ھ�������Ⱥ����Ϊ�������쳣��������Ȼ��,��һЩӦ��(����:��թ���),�������Ⱥ������Ⱥ��������쳣�ھ�����Щ���ھֲ���������Ⱥ��,����ȫ�����������ġ�
3.2 �����ں�
3.3 ����ת��
�ڶ����ݽ���ͳ�Ʒ���ʱ,Ҫ�����ݱ�������һ��������,����ת�����ǽ����ݴ�һ�ֱ�ʾ��ʽ��Ϊ��һ�ֱ�����ʽ�Ĺ��̡�����������ת���������¿ɷ�Ϊ���¼���:
-
��ɢ��
��Щ�����ھ��㷨,�ر���ijЩ�����㷨,Ҫ�������Ƿ���������ʽ��������Ҫ���������Ա任�ɷ�������(��ɢ��,,discretization)�� -
��ֵ��
������ֵ���ǰ���ֵ����ת���ɲ���ֵ�Ĺ���,����������趨һ����ֵ,������ֵ�ĸ�ֵΪ1,С�ڵ���лֵ�ĸ�ֵΪ0����������Է��϶������Ŭ���ֲ����������ݽ���Ԥ����ʲ�������Ч��
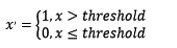
-
��һ��
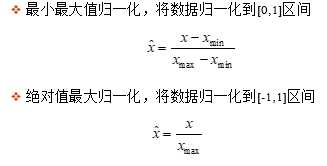
-
����
��ͬ�������в�ͬ��ȡֵ��Χ,������ģ��,������ȡֵ��Χ������յĽ�������ϴ��Ӱ��,ȡֵ��Χ��һ�»ᵼ��ģ�ͻ��ƫ��ȡֵ��Χ�ϴ������������ͨ����Ϊ��������ͬ���Ի�������IJ�����,ʹͬһ�����ڵIJ�ͬ���Լ��ͬһ�����ڲ�ͬ�����ڵķ����С���������ݵı���Ҳ��ӿ����ݵ������ٶȡ�����:
-
����
ͨ����Ϊ�����ݼ���ij������,ʹ������ijһ����,������:

-
��������
��[����",����������r�� ,ʹ��t�������]���Ա�ʾ��[0,1,3],[��Ů�ԡ�.���������ޡ�.,"ʹ��chrome�����]���Ա�ʾ��[1,2,1]����Щ����ʽ�ı�ʾ����ֱ����Ϊ����ѧϰģ�͵IJ���,��Ϊ������Ҫ���������͵������������ͨ��������ķ�����Щ����,���������е�������������.
����Щ�������ת���ɻ���ѧϰģ�͵IJ���,����ʹ�õķ�����:ʹ��one-of-K����one-hot����(���ȱ���OneHotEncoding)��������ÿһ����m����������ת����m�ֶ�ֵ������
3.4 ���ݽ�ά
- ������
ָ���漰�������ļ����������,����ά��������,��������ָ����������һ������ά��������ֱ�ӵĺ�����ǹ��������,�������������������ԭ����:- ά������ʱ,���������ռ��Խ��Խϡ�衣���ģ�ͳ�����ѵ�����ϱ�������,����������ȱ֥��������������
- ά������ʱ,ÿ����������Խ��Խ�����ܷ�������ά��(����),��ʹ�ô������������������
- ���ݽ�ά,�ֳ�������ά,�ǽ���ά�ռ�����ݼ�ӳ�䵽��ά�ȿռ�,ͬʱ�������ٵĶ�ʧ����,���߽�ά������ݵ㾡���ܵı����֡�
3.4.1 ����ѡ��
Ѱ�������Ӽ�,�������( irrelevant)������(redundant)������,�Ӷ��ﵽ���������ĸ���,���ģ�͵Ľ�ȱ��,��������ʱ��,����ѡ������µ�������ѡ��ǰ��û�б仯������������ѡ��ķ�����:
1)���˷�ʽ:�������������д��,ѡ������Ч������������,�������顢��Ϣ���桢���ϵ��(Ƥʾѷ��cos������Ϣ�ȡ��ȡ�
2)��װ��ʽ:��������ϵ�ѡ������һ���������ռ����������,��������ʽ�����������ȡ�
3)Ƕ�뷽ʽ:������ѡ��Ĺ���Ƕ�뵽ģ��ѵ���Ĺ�����,��ʵҲ�Ǿ������ķ���,����lasso�ع顢ridge�ع�ȡ�
3.4.2 ������ȡ
������ȡ��ָ�ı�ԭ�е������ռ�,������ӳ�䵽һ���µ������ռ䡣����ij��������һ��ͼƬ,������ͼƬ�еĵ�,��������ɫ��ȡ������������,����һ��������ȡ�Ĺ��̡�������������ȡ������:
- PCA���ɷַ�������˼���ǽ�nά����ӳ�䵽kά��(k<n),��kά��ȫ�µ�������������kά������Ϊ��Ԫ,�����¹��������kά����,�����Ǽش�nά������ȥ������n-kά������ͨ��Э������������ֵ�ֽ��ܹ��õ����ݵ����ɷ�,PCA��Ŀ���Ƿ�������֮������Թ�ϵ,��ȥ����������Ҫȥ���Ļ���
- LDA�����б�ʽ������ʹ�������Ϣ,ѡ��ʹ���ڷ���С����䷽���ķ�����ΪͶӰ����,������ͶӰ��ά�ȸ��͵Ŀռ���,ʹ��ͶӰ��ĵ����ֶȸ��ߡ�
- SVD����ֵ�ֽ⡣ֱ�Ӷ������������SVD�ֽ�,Ȼ����Ʊ�ʾԭ����ע��,SVD���Ի�ȡ��������ϵ����ɷ�,��PCAֻ�ܻ�õ��������ϵ����ɷ֡�
4 �����
4.1 K-means

4.2 ������(ID3)
- �����������ԩr
- ��Ŀǰ�����ݱ�,����һ���ڵ�N
- ������ݿ��е����ݶ�����ͬһ����,N������Ҷ,����Ҷ�ϱ����������
- ������ݱ���û���������Կ��Կ���,��NҲ����Ҷ,�����������Ӷ�����ԭ������Ҷ�ϱ���������
- ����,����ƽ����Ϣ����ֵE��GAINֵѡ��һ�����������Ϊ�ڵ�N�IJ�������
- �ڵ�����ѡ����,���ڸ������е�ÿ��ֵ:
��N����һ����֧,�������ݱ�����÷�֧�йص������ռ��γɷ�֧�ڵ�����ݱ�,�ڱ���ɾ���ڵ�������һ��
�����֧���ݱ��ǿ�,�����������㷨�Ӹýڵ㽨��������
4.3 ��������
����1:������������������ȡֵ֮����ڵ�һ����Ҫ�Ŀɱ����ֵ�ij�ֹ����ԡ�
�����ɷ�Ϊ������ʱ����������������
��������Ŀ����Ѱ�Ҹ������ݼ�¼����������֮�����صĹ�����ϵ,��������֮������жȡ�
���������Ľ����������:�������������ģʽ��
������������Ѱ����ͬһ���¼��г��ֵ���ͬ���������;
����ģʽ�������,����Ѱ�ҵ����¼�֮��ʱ���ϵ�����ԡ�
����2:����������������һ����������Ʒ֮��ͬʱ���ֵĹ��ɵ�֪ʶģʽ,��ȷ�е�˵,����������ͨ������������������ƷX�ij��ֶ���ƷY�ij����ж���Ӱ�졣
���Ŷ�:
��������A->B��,A��Bͬʱ���ֵĴ���,����A���ֵĴ�����

���Ŷ����ֵ��ǹ�������Ŀɿ��̶�,���ù�������([A->B)�����ŶȽϸ�,��˵����A����ʱ,B�кܴ����Ҳ�ᷢ��,�����Ϳ��ܻ�����о���ֵ��
֧�ֶ�:
ij������ݼ��г��ֵ�Ƶ�ʡ�����ڼ�¼�г��ֵĴ���,�������ݼ������м�¼������.
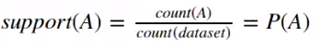
������:
�����ۼ�A->B��,��������ָA->B�����Ŷ�,����B��֧�ֶȡ�

���������ֵ������(Ӧ�ù�������)��Բ����(��Ӧ�ù�������)�ı�ֵ,��������ȴ���1,��˵��Ӧ�øù����������м�ֵ�ġ����������С��1,˵��Ӧ�øù����������˸���Ӱ�졣���,����Ӧ�þ������ù�������������ȴ���1,������Խ��,��Ӧ�øù��������Ч��Խ�á�
ͬʱ������С���Ŷ���ֵ����С֧�ֶ���ֵ�Ĺ�������Ϊǿ��������,���������м�ֵ��

�����������̹����������Է�Ϊ������������:
1.�����ݼ���ѰԮ�뷱���
2.��Ƶ��������ɹ�������
Ѱ��Ƶ���
����,������Ҫ�ܹ��ҵ����е�Ƶ���,������������һ��Ķ��ϡ�ʵ����,�ҵ�Ƶ�����������,����ֻ��Ҫ�������µIJ��������в�������:
1.��������֮�����п��ܵ����(���������������̨),ÿ����Ϲ���һ�����
2.���ÿһ���A,����A��֧�ֶ�[A���ֵĴ������Լ�¼����]
3.��������֧�ضȴ���ָ����ֵ���,
Apriori�㷨ԭ��:
1.���һ�����Ƶ���,���������Ӽ�(�ǿ�)Ҳ��Ƶ�����
2.���һ���(�ǿ�)�Ƿ�Ƶ���,�������и���Ҳ�Ƿ�Ƶ�����
Apriori�㷨���k=1��ʼ,ʹ������k��������,�Ӷ�����k+ 1������֮ǰ���ܵ��㷨ԭ��,���ǿ�֪,Ƶ��k+ 1���������k���϶���,������Ƶ��x+1���˵,�����е�K��Ӽ���Ȼ��Ƶ���,�����ζ��,Ƶ��K +1�ֻ���ܴ�����Ԥ��xk���ϲ���,���,����������ϵĹ�����,һ���������K�����Ƶ���(֧�ֶ�С��ָ������ֵ),�Ϳ��Խ����Ƴ�,�������ٲ����������X+1�����ϡ�����һ��,�Ϳ��Դ����ټ�����,
������ͼ��,����(2,3)�Ƿ��뷱�,�����Apriori�㷨ԭ��,�����и���Ҳ�Ƿ�Ƶ���,��(0.2.3),(1.2.3)��(1.2.3)Ҳ�Ƿ��뷱������,���Ǿ�����ʹ��(2,3)������2��������,ȥ����3���(��Ϊ���ɵ�����3����Ƿ�Ƶ���),

Apriori�㷨����:

���ɹ�������
������Ƶ�����,���ɹ����������Լ�����ֻ��Ҫ��ÿ��Ƶ�����ֳ������ǿ��Ӽ�,Ȼ��ʹ���������Ӽ�,�Ϳ��Թ��ɹ�������Ȼ,һ��Ƶ�����������ǿ��Ӽ������кܶ��ַ�ʽ,����Ҫ����ÿһ�ֲ�ͬ�Ŀ��ܡ���,Ƶ���({1,2.3)���Բ��Ϊ:

Ȼ��,�������ÿһ����������,�ֱ���������Ŷ�,������������С���ŶȵĹ�������
4.4 ������
ֱ������
4.4.1 ������
- ��Ϣ��
��Ϣ��������������Ϣ��ȷ���Ե�ָ��,��ȷ������һ���¼����ֲ�ͬ����Ŀ����ԡ����㷽��������ʾ:

����:P(X=i)Ϊ�������xȡֵΪi�ĸ���
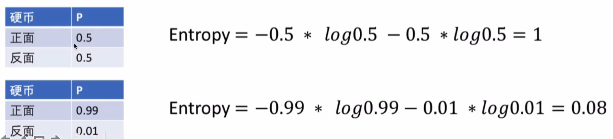
������:�ڸ����������Y��������,�������X�IJ�ȷ����
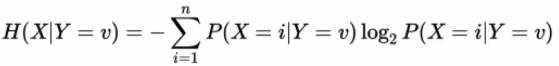
��Ϣ����:��-������,��������һ��������,��Ϣ��ȷ���Լ��ٵij̶�
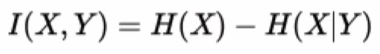

ID3 - ����ָ��(Gini)
����ָ��(Gini������)��ʾ������������һ�����ѡ�е��������ִ��ĸ��ʡ�
ע��:Giniָ��ԽС��ʾ�����б�ѡ�е��������ִ��ĸ���ԽС,Ҳ����˵���ϵĴ���Խ��,��֮,����Խ����������������������Ϊһ����ʱ,����ָ��Ϊ0.
����ָ���ļ��㷽��:
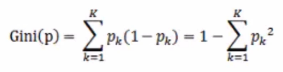
����,pk��ʾѡ�е��������ڵ�k�����ĸ���

CART���Ƕ�����,����һ�����ж��ȡֵ(����2��)������,��Ҫ������ÿһ��ȡֵ��Ϊ���ֵ�,������D����֮���Ӽ��Ĵ���Gini(D,Ai),Ȼ������еĿ��ܻ��ֵ�Gini(D,Ai)���ҳ�Giniָ����С�Ļ���,������ֵĻ��ֵ�,����ʹ������A����������D���л��ֵ���ѻ��ֵ㡣
4.4.2 �ع���
�ع������ǽ���ع�����ľ�������
�ع���(regression tree),��������ģ�����ع�����,ÿһƬҶ�Ӷ����һ��Ԥ��ֵ��Ԥ��ֵһ����Ҷ�ӽڵ�����ѵ����Ԫ������ľ�ֵ��ע��:����ʹ�þ�ֵ��ΪԤ��ֵ,Ҳ����ʹ����������,�������Իع�
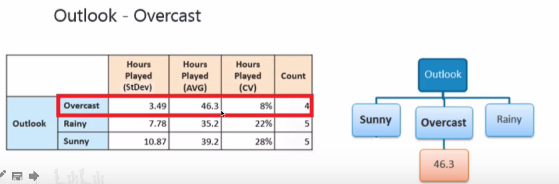
�ع����ķ�֧��:������(Standard Deviation)���ع���ʹ��ijһ������ԭ���Ϸ�Ϊ����Ӽ�,�ñ���������Ӽ��е�Ԫ���Ƿ����,ԽС��ʾԽ��������ȼ�����ڵ�ı�����:

ʹ�ñ�������ȷ����֧,�Լ���Outlook��֧��ı���Ϊ��:



������,�ظ��������,ʹ�ñ�����������������з�ֱ֧������ij��ֹͣ����,��:
1.��ij����֧�ı仯ϵ��С��ij��ֵ(10%)
2.��ǰ�ڵ������Ԫ�ظ���С��ij��ֵ(3)
ʹ�á�outlook����֧�Ժ�,ֵΪ��Overcast���ķ�֧�ı仯ϵ��(coefficientof variation)̫С(8%),С���������õ���Сֵ(10%),ֹͣ�����ڡ�Overcast"��Ӧ�ķ�֧�ϼ�����֧,����һ��Ҷ�ӽڵ�




4.5 ����ѧϰ
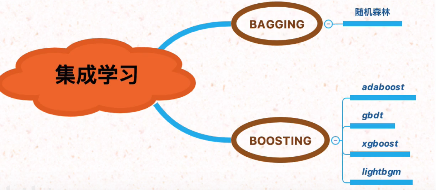
����ѧϰ��ͨ����������϶��ѧϰ�������ѧϰ������㷨.����ѧϰ���õ�������:
Bagging:��ѧϰ��֮����ǿ������ϵ,��ͬʱ���ɵIJ��л�����
Boosting:��ѧϰ��֮�����ǿ�ҵ�������ϵ,���봮�����ɻ��������ķ������ɭ��
4.5.1 bagging:���ɭ��
Bagging


���ɭ��=bagging+������
���ɭ��:ͬʱѵ�����������,Ԥ��ʱ�ۺϿ��Ƕ���������Ԥ��,����ȡ����ڵ�ľ�ֵ(�ع�),����������(����)��
����:
1.�����˾�����������ϵ�ȱ��
2��С��Ԥ��ķ���,Ԥ��ֵ������ѵ�����ݵ�С�仯�����ұ仯
���������������:
1.��ԭ����ѵ�����ݼ����(���Ż�bootstrap)ȡһ���Ӽ���Ϊɭ����ijһ����������ѵ�����ݼ�
2.ÿһ��ѡ��ֲ������ʱ,��Ϊ�����ѡ����������Ӽ���Ѱ��һ������
Ӧ��:
����ij��˾��Ա����ְ����,����ͨ�����������������ɭ����Ԥ��ijһԱ���Ƿ����ְ�����ҳ�Ӱ��Ա����ְ����Ҫ������
4.5.2 boosting:adaboost
boosting
Boosting�����ǽ�����ѧϰ�㷨������Ϊ��ǿѧϰ�㷨���Ĺ���,ͨ������ѧϰ�õ�һϵ����������(�����������ع�),�����Щ���������õ�һ��ǿ��������Boosting�㷨Ҫ�漰����������,�ӷ�ģ�ͺ�ǰ��ֲ��㷨��
�ӷ�ģ������˵ǿ��������һϵ����������������Ӷ��ɡ�һ�������ʽ����:
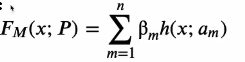
����,h(x,am)����������,am����������ѧϰ�������Ų���,��m����ѧϰ��ǿ����������ռ����,P������am�ͦ�m����ϡ���Щ������������������ǿ��������
ǰ��ֲ�����ѵ��������,��һ�ֵ��������ķ�����������һ�ֵĻ�����ѵ�������ġ���:
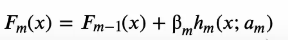
adaboost:
��Ȩ
Adaboost��˼���ǽ���ע����ڱ���������������,��С��һ�ֱ���ȷ���������Ȩֵ,��߱�������������Ȩֵ:
Adaboost���ü�ȨͶƱ�ķ���,�������С������������Ȩ�ش�,���������������������Ȩ��С:
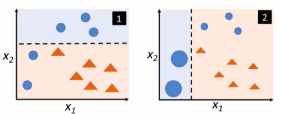
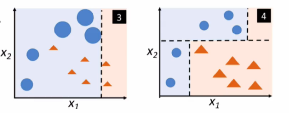
����:


yi����ʵֵ,Gm����������,��������Ҫ�Ŵ�,������ȷ����С

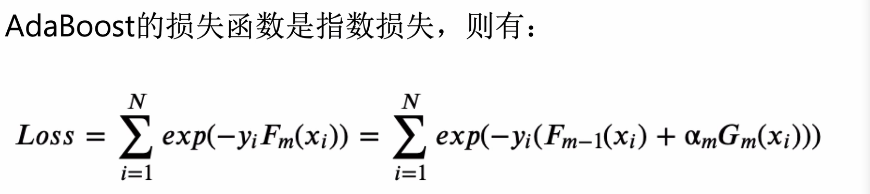
Adaboost���Կ����Ǽӷ�ģ�͡���ʧ����Ϊָ����ʧ������ѧϰ�㷨Ϊǰ��ֲ��㷨ʱ�Ķ�����ѧϰ����������������ʹ��sklearn��AdaBoost�Ľӿڽ���ʵ��:

base_estimator ��ѧϰ����ʲô,n_estimators�����������ĸ�����
4.5.3 GBDT
�ݶ�
4.5.3.1 BDT
�����ȿ��¼�������(Boosting Decision Tree),����������CART������Ϊ��ѧϰ���ļ���ѧϰ������

�ڶ�������������ѵ���������һ�����������IJв�(������Ϊû�б���һ�����������ֳ���������)��ѵ��


�òв�ѵ��T,T����ϲв�,T�Ͳв�Խ�ӽ�,lossԽС��

4.5.3.2 GBDT
GBDTȫ��Ϊ:Gradient Boosting Decision Tree,���ݶ�����������,����Ϊ�ݶ�����+��������Friedman��������������½��Ľ��Ʒ���,������ʧ�����ĸ��ݶ���ϻ�ѧϰ��:
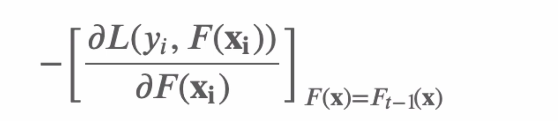
��ô�����������,����ͨ��ƽ����ʧ����������ҽ��н��ܡ�

�ݶ���������:

�Ż�loss����,�����ø��ݶ���ϲв�,ѵ������,

GBDT�����������������в�ʹ���ݶ����,����ÿ����ѧϰ���ж�Ӧ�IJ���Ȩ�ء�

GBDT������(�ع�)

GBDT������(����)


4.5.4 XGBoost
XGBoost��GBDT��һ��,Ҳ�Ǽӷ�ģ�ͺ�ǰ���Ż��㷨��
�ڼලѧϰ��,���Է�Ϊ:ģ��,����,Ŀ�꺯����ѧϰ����
- ģ��:��������x��Ԥ�����y�ķ���,����˵�ع�,����,����ȡ�
- ����:ģ���еIJ���,�������Իع��е�Ȩ�غ�ƫ��
- Ŀ�꺯��:����ʧ����,����������
- ѧϰ����:����Ŀ�꺯�������ģ�ͺͲ����ķ���,����:�ݶ��½���,��ѧ�Ƶ��ȡ�
���ķ��������Ҳָ����XGBoostϵͳ����ơ�
ģ����ʽ



Ŀ�꺯��




������






ѧϰ����-ȷ�����ṹ

��ȷ̰���㷨:


4.5.5 lightGBM
�����:
����ѧϰ:XGBoost, lightGBM