原文链接:http://tecdat.cn/?p=23616?
原文出处:拓端数据部落公众号
在这篇文章中,我们将回顾三种提高循环神经网络的性能和泛化能力的高级方法。我们将在一个温度预测问题上演示这三个概念,我们使用来自安装在建筑物屋顶的传感器的数据点的时间序列。
概述
安装在建筑物屋顶的传感器的数据点的时间序列,如温度、气压和湿度,你用这些数据点来预测最后一个数据点之后24小时的温度。这是一个相当具有挑战性的问题,它体现了在处理时间序列时遇到的许多常见困难。
我们将介绍以下方法。
- 递归剔除--这是一种特定的、内置的方式,使用剔除来对抗递归层中的过度拟合。
- 堆叠递归层--这增加了网络的表示能力(以较高的计算负荷为代价)。
- 双向递归层--这些层以不同的方式向递归网络呈现相同的信息,提高了准确性并缓解了遗忘问题。
温度预测的问题
到目前为止,我们所涉及的序列数据只有文本数据,如IMDB数据集和路透社数据集。但是,序列数据在许多问题中都能找到,而不仅仅是语言处理。在本节的所有例子中,你将分析一个天气时间序列数据集,该数据集来自生物地球化学研究所的气象站记录。
在这个数据集中,14个不同的量(如气温、大气压力、湿度、风向等)每10分钟被记录一次,历时数年。原始数据可以追溯到2003年,但这个例子仅限于2009-2016年的数据。这个数据集是学习处理数字时间序列的完美选择。你将用它来建立一个模型,把最近的一些数据(几天的数据点)作为输入,预测未来24小时的空气温度。
下载并解压数据如下。
unzip(
"~/Downloads/climate.csv.zip",
)我们来看看这些数据。
glimpse(data)
这里是温度(摄氏度)随时间变化的曲线图。在这个图上,你可以清楚地看到温度的年度周期性。
plot(data, geom_line)
下面是前10天的温度数据图(见图6.15)。因为数据是每10分钟记录一次,所以每天得到144个数据点。
plot(data[,], line()

在这个图上,你可以看到每天的周期性,特别是在过去的4天里很明显。还要注意的是,这10天的时间来自寒冷的冬季。
如果你根据过去几个月的数据来预测下个月的平均温度,问题就很容易了,因为数据具有可靠的年尺度的周期性。看一下过去的数据?
准备数据
问题的确切表述如下:给定的数据最远可追溯到回溯时间段(一个时间段是10分钟),并且每步时间段取样,你将使用以下参数值。
lookback = 1440?― 观察结果将回到10天前。steps = 6?― 观察结果将以每小时一个数据点的速度进行采样。delay = 144?―目标是未来的24小时。
准备工作。
- 将数据预处理成神经网络可以摄入的格式。这很容易:数据已经是数值化的,所以你不需要做任何矢量化。但是,数据中的每个时间序列都在不同的量纲上(例如,温度通常在-20和+30之间,但大气压力,以mbar为单位,大约是1000)。你将独立地对每个时间序列进行归一化处理,使它们都在一个类似的量纲上取小值。
- 编写一个生成器函数,获取当前的浮点数据数组,并产生最近的数据批,以及未来的目标温度。因为数据集中的样本是高度冗余的(样本N和样本N+1将有大部分共同的时间步长),明确分配每个样本是不合理的。取而代之的是,你将使用原始数据生成样本。
理解生成器函数
生成器函数是一种特殊类型的函数,你反复调用它来获取一连串的值。通常情况下,生成器需要保持内部状态,所以它们通常是通过调用另一个又一个返回生成器函数的函数来构造的(返回生成器的函数的环境随后被用来跟踪状态)。
例如,下面产生一个无限的数字序列。
generator <- function(start) {
value <- start - 1
value <<- value + 1
value
}
gen <- generator(10)
[1] 10gen()
[1] 11生成器的当前状态是定义在函数之外的值变量。注意,超级赋值(<<->)是用来从函数内部更新这个状态的。
生成器函数可以通过返回值NULL来表示完成。然而,传递给Keras训练方法(例如生成器函数应该总是无限地返回值(对生成器函数的调用次数由epochs和psych_per_epoch参数控制)。
首先,你要把我们之前读到的R数据帧转换为浮点值矩阵。
data <- data.matrix(data[,-1])然后,你将对数据进行预处理,减去每个时间序列的平均值并除以标准差。你将使用前20万个时间段作为训练数据,所以只对这部分数据计算均值和标准差进行归一化。
train_data <- data[1:200000,]
data <- scale(data, center = mean, scale = std)下面是你要使用的数据生成器的代码。它产生一个列表(samples, targets),其中samples是一批输入数据,target是相应的目标温度阵列。它需要以下参数。
data - 原始的浮点数据数组,你对其进行了标准化处理lookback?― 输入的数据应该回到多少个时间段。delay?―目标应该在未来多少个时间段.min_index?和?max_index?―数据数组中的索引,用来限定从哪个时间段提取。这对于保留一部分数据用于验证,另一部分用于测试很有用.shuffle?― 是否对样本进行随机打乱或按时间顺序抽取.batch_size?―每批样本的数量.step?― 你对数据进行采样的周期,以时间为单位。你将设置为6,以便每小时绘制一个数据点.
i变量包含跟踪下一个数据窗口返回的状态,所以它使用超级赋值进行更新(例如,i <<- i + length(rows))。
现在,让我们使用生成器函数来实例化三个生成器:一个用于训练,一个用于验证,还有一个用于测试。每个生成器将查看原始数据的不同时间段:训练生成器查看前20万个时间段,验证生成器查看随后的10万个时间段,而测试生成器查看剩余的时间段。
# 为了遍历整个验证集,要从val_gen中抽取多少步
val_steps <- (300000 - 200001 - lookback) / batch_size
# 为了遍历整个测试集,要从test_gen中抽取多少步
test_steps <- (nrow(data) - 300001 - lookback) / batch_size常识性、非机器学习的基准模型
在你开始使用黑盒深度学习模型来解决温度预测问题之前,让我们尝试一个简单的、常识性的方法。这将作为一种理智的检查,它将建立一个基准模型,以证明更先进的机器学习模型的有用性。当你在处理一个新的问题时,这种常识性的基线可能是有用的,因为目前还没有已知的解决方案。一个典型的例子是不平衡的分类任务,其中一些类别比其他类别要常见得多。如果你的数据集包含90%的A类实例和10%的B类实例,那么分类任务的一个常识性方法就是在遇到新样本时总是预测 "A"。这样的分类器总体上有90%的准确度,因此任何基于学习的方法都应该超过这个90%的分数,以证明其有用性。
在这种情况下,可以安全地假设温度时间序列是连续的(明天的温度可能与今天的温度接近),以及具有每日周期性的。因此,一个常识性的方法是始终预测24小时后的温度将与现在的温度相等。让我们使用平均绝对误差(MAE)指标来评估这种方法。
mean(abs(preds - targets))下面是评估循环。
for (step in 1:val_steps) {
c(samples, targets) %<-% val_gen()
preds <- samples[,dim(samples)[[2]],2]
mae <- mean(abs(preds - targets))
batch_maes <- c(batch_maes, mae)
}
这得出的MAE为0.29。因为温度数据已经被归一化,以0为中心,标准差为1。它转化为平均绝对误差为0.29 x temperature_std摄氏度:2.57?C。
这是一个相当大的平均绝对误差。现在利用深度学习来做得更好。
基本的机器学习方法
在尝试机器学习方法之前,建立一个常识性的基线是很有用的,同样,在研究复杂和计算昂贵的模型(如RNN)之前,尝试简单、便宜的机器学习模型(如小型、密集连接的网络)也是很有用的。这是确保你在这个问题上投入的任何进一步的复杂性都是合法的,并带来真正的好处的最好方法。
下面的列表显示了一个全连接模型,它从扁平化的数据开始,然后通过两个密集层运行。注意最后一个密集层上没有激活函数,这对于回归问题来说是典型的。你使用MAE作为损失函数。因为你用完全相同的数据和完全相同的指标来评估你的常识性方法,所以结果将是直接可比的。
model %>% compile(
optimizer = optimizer_rmsprop(),
loss = "mae"
)
验证和训练的损失曲线。
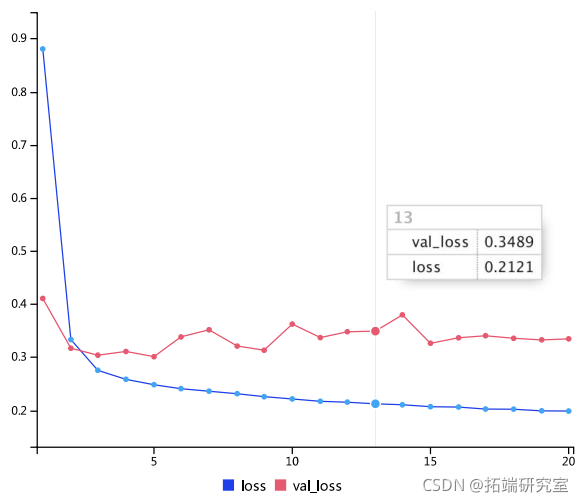
一些验证损失接近于无学习基线,但并不可靠。这就说明了首先要有这个基准的好处:事实证明,要超越它并不容易。你的常识包含了很多机器学习模型无法获得的宝贵信息。
你可能会想,如果存在一个简单的、表现良好的模型来从数据到目标(常识基准),为什么你正在训练的模型没有发现它并在此基础上进行改进?因为这个简单的解决方案并不是你的训练设置所要寻找的。你在其中寻找解决方案的模型空间--也就是你的假设空间--是所有可能的两层网络的空间,其配置由你定义。这些网络已经相当复杂了。当你用一个复杂的模型空间寻找解决方案时,简单的、表现良好的基线可能是不可学习的,即使它在技术上是假设空间的一部分。这是机器学习的一个相当重要的限制:除非学习算法被硬编码为寻找一种特定的简单模型,否则参数学习有时可能无法找到一个简单问题的简单解决方案。
第一个递归基准模型
第一个全连接方法做得不好,但这并不意味着机器学习不适用于这个问题。之前的方法首先对时间序列进行了扁平化处理,将时间的概念从输入数据中移除。相反,让我们把数据看成是:一个序列,其中因果关系和顺序很重要。你将尝试一个循环序列处理模型--它应该是最适合这种序列数据的,正是因为它利用了数据点的时间顺序,与第一种方法不同。
你将使用Chung等人在2014年开发的GRU层,而不是上一节中介绍的LSTM层。门控递归单元(GRU)层的工作原理与LSTM相同,但它们有些精简,因此运行成本更低(尽管它们可能没有LSTM那么多的表示能力)。在机器学习中,这种计算能力和表现能力之间的权衡随处可见。
layer_gru(units = 32, input_shape = list(NULL, dim(data)[[-1]])) %>%
layer_dense(units = 1)
结果绘制如下。好多了, 你可以大大超越常识性的基准模型,证明了机器学习的价值,以及在这种类型的任务上,递归网络比序列平坦的密集网络更有优势。

交互显示训练过程中的模型损失:?

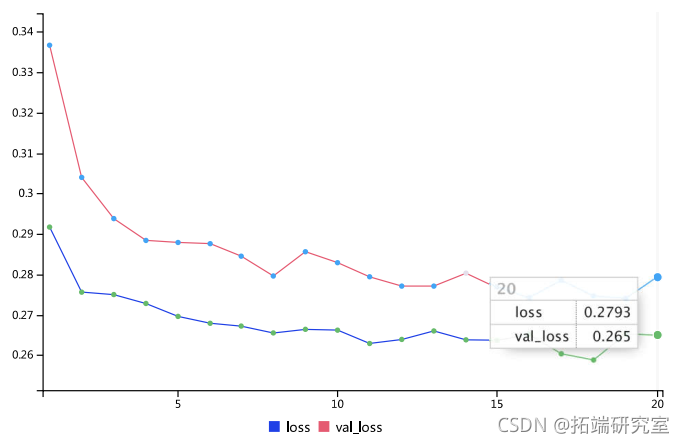
新的验证MAE为~0.265(在你开始明显过拟合之前),转化为去标准化后的平均绝对误差为2.35?C。与最初的2.57℃的误差相比,这是一个进步,但你可能仍有一点改进的余地。
使用递归丢弃dropout来对抗过拟合
从训练和验证曲线中可以看出,该模型正在过度拟合:训练和验证损失在几个 epochs之后开始出现明显的分歧。你已经熟悉了对抗这种现象的经典技术:dropout,它随机地将一个层的输入单元清零,以打破该层所接触的训练数据中的偶然相关性。
Yarin Gal使用Keras进行研究,并帮助将这一机制直接构建到Keras的递归层中。Keras中的每个递归层都有两个与dropout相关的参数:dropout,一个指定该层输入单元的dropout率的浮点数,以及recurrent_dropout,指定递归单元的dropout率。让我们在layer_gru中加入dropout和recurrent dropout,看看这样做对过拟合有什么影响。因为用dropout进行正则化的网络总是需要更长的时间来完全收敛,所以你将训练网络两倍的epochs。
layer_gru(dropout = 0.2))
下面的图显示了结果。 你在前20个 epochs中不再过度拟合。但是,尽管你有更稳定的评估分数,你的最佳分数并没有比以前低很多。
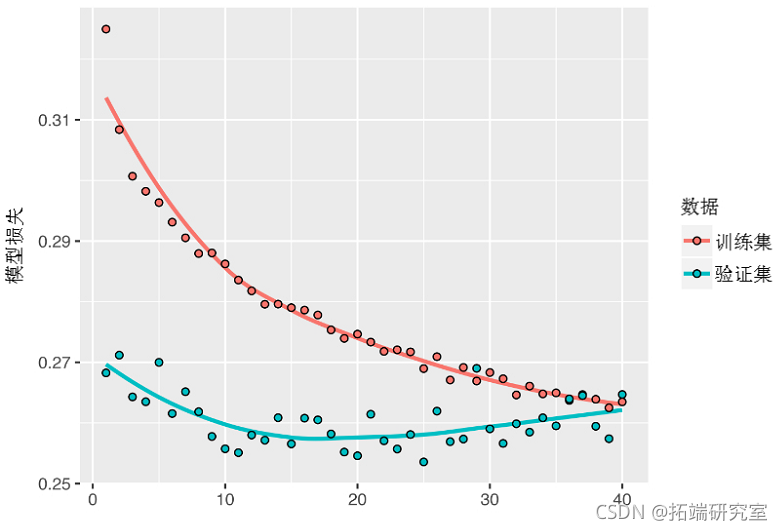
堆叠递归层
因为你不再过度拟合,但似乎遇到了性能瓶颈,你应该考虑增加网络的容量。回顾一下通用机器学习工作流程的描述:一般来说,增加网络的容量是个好主意,直到过拟合成为主要障碍(假设你已经采取了基本措施来减轻过拟合,比如使用dropout)。
增加网络容量通常是通过增加层中的单元数量或添加更多的层来实现的。递归层堆叠是建立更强大的递归网络的经典方法:例如,目前为谷歌翻译算法提供动力的是七个大型LSTM层的堆叠。
为了在Keras中把递归层堆叠起来,所有的中间层都应该返回它们的完整输出序列(一个三维张量),而不是它们在最后一个时间步的输出。这可以通过指定return_sequences = TRUE来实现。
?
layer_gru(
return_sequences = TRUE,
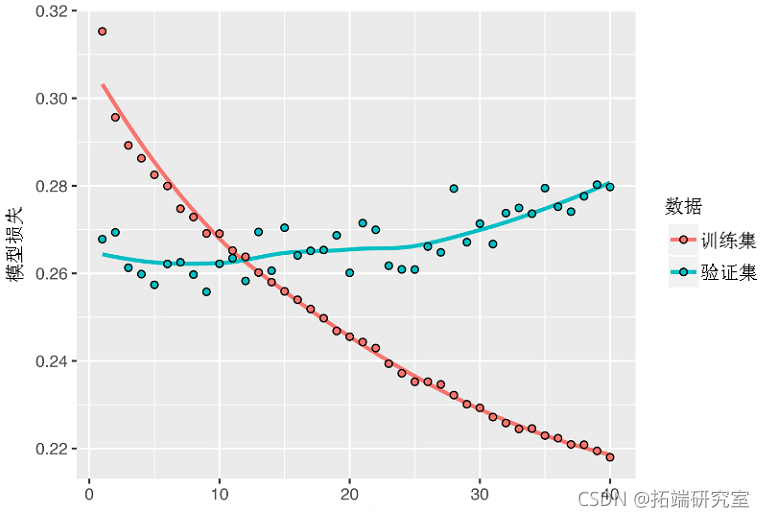
input_shape = list(NULL, dim(data)[[-1]])) %>% 下图显示了结果。你可以看到,添加的层确实改善了一些结果,尽管并不明显。你可以得出两个结论。
- 因为你的过拟合情况仍然不是很严重,所以你可以安全地增加层的大小以寻求验证损失的改善。不过,这有一个不可忽视的计算成本。
- 增加一个层并没有明显的帮助,所以在这一点上,你可能会看到增加网络容量的回报越来越少。
使用双向的RNNs
本节介绍的最后一项技术被称为双向RNNs。双向RNN是一种常见的RNN变体,在某些任务上可以提供比普通RNN更大的性能。它经常被用于自然语言处理--你可以把它称为用于自然语言处理的深度学习的瑞士军刀。
值得注意的是,RNN是顺序依赖的,或者说是时间依赖的:它们按顺序处理其输入序列的时间段颠倒时间段可以完全改变RNN从序列中提取的表示。这正是它们在顺序有意义的问题上表现良好的原因,如温度预测问题。双向RNN利用了RNN的顺序敏感性:它包括使用两个常规的RNN,比如你已经熟悉的layer_gru和layer_lstm,每个都从一个方向(按时间顺序和按反时间顺序)处理输入序列,然后合并它们的表示。通过双向处理一个序列,双向RNN可以识别到可能被单向RNN忽略的模式。
值得注意的是,本节中的RNN层按时间顺序处理了序列(较早的时间段在前),这可能是一个随意的决定。如果RNN按反时序处理输入序列,例如(较新的时间段在前),它们的表现是否足够好?让我们在实践中尝试一下,看看会发生什么。训练你在本节第一个实验中使用的相同的单层GRU网络,你会得到如下的结果。
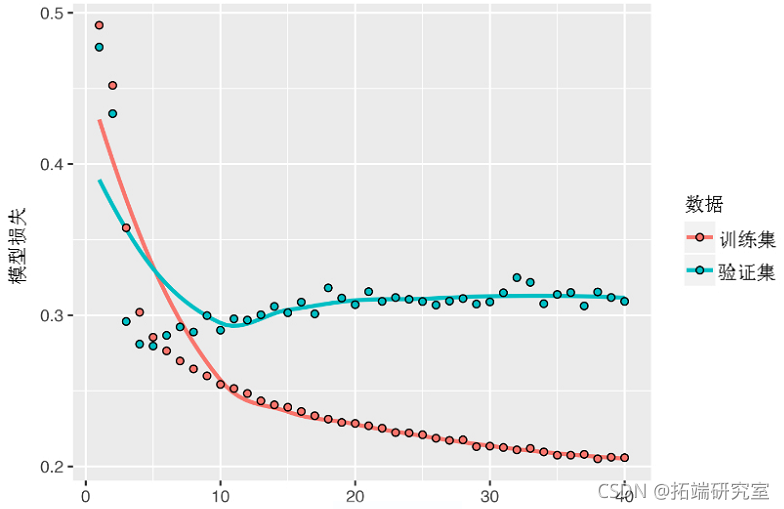
反序GRU的表现甚至低于常识性基线,表明在这种情况下,时间处理对你的方法的成功很重要。这是很有道理的:底层的GRU层通常会在记忆最近的过去方面比记忆遥远的过去方面做得更好,而对于这个问题来说,较近的天气数据点自然比较早的数据点更具预测性(这就是常识性基线相当强大的原因)。因此,按时间顺序排列的图层的表现必然会优于倒序的版本。重要的是,对于许多其他问题,包括自然语言,这并不正确:凭直觉,一个词在理解一个句子中的重要性通常并不取决于它在句子中的位置。
让我们在LSTM IMDB例子上尝试同样的技巧。
# 考虑作为特征的词的数量
max_features <- 10000
# 剔除超过这个字数的文本
maxlen <- 500
# 反转序列
x_train <- lapply(x_train, rev)
x_test <- lapply(x_test, rev)
layer_lstm(units = 32)
history <- model %>% fit(
x_train, y_train,
epochs = 10,
batch_size = 128,
)你得到的性能几乎与按时间顺序排列的LSTM相同。值得注意的是,在这样的文本数据集上,倒序处理与按时间顺序处理一样好,这证实了这样的假设:尽管词序在理解语言方面确实很重要,但你使用哪种顺序并不关键。重要的是,在颠倒的序列上训练的RNN将与在原始序列上训练的RNN学习不同的表征,就像在现实世界中,如果时间倒流,你会有不同的心理模型--如果你的生活中,你在第一天死亡,在最后一天出生。
在机器学习中,不同但有用的表征总是值得利用的,而且它们的差异越大越好:它们提供了一个新的角度来观察你的数据,识别到了其他方法所遗漏的数据方面,因此它们可以帮助提高任务的性能。
双向RNN利用这个想法来提高按时间顺序排列的RNN的性能。它从两个方面观察其输入序列,获得潜在的更丰富的表征,并识别到可能被单独的时间顺序版本所遗漏的模式。
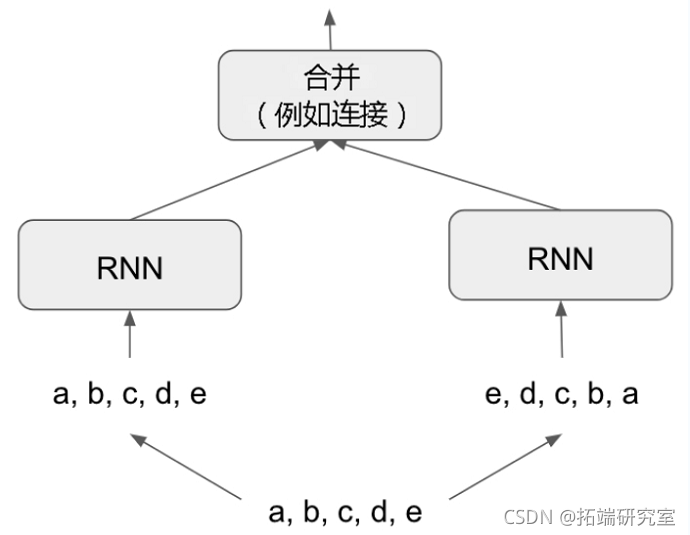
要在Keras中实例化一个双向RNN,它需要一个递归层实例作为参数。创建这个递归层的第二个独立实例,并使用一个实例来处理按时间顺序排列的输入序列,另一个实例来处理按相反顺序排列的输入序列。我们在IMDB情感分析任务上试试。
bidirectional(
lstm(units = 32)
)
它的表现比之前尝试的普通LSTM略好,取得了超过89%的验证准确性。它似乎也会更快地过拟合,这并不奇怪,因为双向层的参数是按时间顺序排列的LSTM的两倍。通过一些正则化,双向方法很可能在这个任务中表现出色。
现在让我们在温度上尝试同样的方法
bidirectional(
layer_gru(units = 32),
) %>%
layer_dense(units = 1)
和普通的layer_gru的表现差不多。这很容易理解:所有的预测能力必须来自于网络中按时间顺序排列的那一半,因为已知反时间顺序排列的那一半在这个任务上表现严重不足。
进一步
为了提高温度预测问题的性能,你还可以尝试许多其他事情。
- 调整堆叠设置中每个递归层的单元数量。目前的选择基本上是任意的,因此可能是次优的。
- 调整RMSprop优化器使用的学习率。
- 尝试使用layer_lstm而不是layer_gru。
- 尝试在递归层之上使用更大的密集连接回归器:也就是说,一个更大的密集层,甚至是密集层的堆叠。
- 最终在测试集上运行表现最好的模型(就验证MAE而言)。否则,你会开发出过度拟合的架构。
深度学习是一门艺术,而不是一门科学。我们可以提供指导方针,但最终,每个问题都是独一无二的;你必须根据经验来评估不同的策略。目前还没有任何理论能够事先准确地告诉你应该怎样做才能最有效地解决问题。你必须进行迭代。
总结
- 在处理一个新问题时,最好首先为你选择的指标建立常识性的基准。如果你没有一个基准,你就无法判断你是否取得了真正的进展。
- 先尝试简单的模型,以证明合理性。有时,一个简单的模型会成为你最好的选择。
- 当你的数据的时间顺序很重要时,递归网络是一个很好的选择。
- 为了在递归网络中使用dropout,你应该使用时间恒定的dropout mask和递归dropout mask。
- 堆叠的RNN比单一的RNN层提供更多的表示能力。虽然它们在复杂的问题(如机器翻译)上提供了明显较好的效果,但它们可能在较简单的问题表现一般。
- 双向的RNNs,从两个方面看一个序列,在自然语言处理问题上很有用。但它们在序列数据上的表现并不突出,因为在这些数据中,近期的信息量要比序列的初始数据大得多。
注意:股市和机器学习
一些读者一定会想把我们在这里介绍的技术,在预测股票市场上的证券(或货币汇率等)的未来价格问题上进行尝试。市场与自然现象(如天气模式)有着非常不同的统计特征,当涉及到股市时,过去的表现并不能很好地预测未来的回报--看后视镜是一种不好的驾驶方式。另一方面,机器学习适用于那些过去能很好地预测未来的数据集。

最受欢迎的见解
1.r语言用神经网络改进nelson-siegel模型拟合收益率曲线分析
3.python用遗传算法-神经网络-模糊逻辑控制算法对乐透分析
4.用于nlp的python:使用keras的多标签文本lstm神经网络分类