���ر�Ҷ˹�㷨������
���ලѧϰ�������㷨
���ر�Ҷ˹�㷨��ԭ��
- ���ڱ�Ҷ˹���ۺ�����������ļ���;��Ϊ�ٶ�����������������ļ�,��Ϊ��Ϊ����
- ���ر�Ҷ˹�㷨��Ϊ:��Ŭ�����ر�Ҷ˹,��˹���ر�Ҷ˹,����ʽ���ر�Ҷ˹��ƪ���ϳ�,�ɸ����Աߵ�Ŀ¼����

?
���ر�Ҷ˹�㷨��һվ:���ʹ�ʽ
�������ʹ�ʽ:
Ϊ(�����¼�B�����������,�¼�A�����ĸ���):

?��A,B�����ʱ?P(AB) = P(A)?P(B)
ȫ���ʹ�ʽ:


��Ҷ˹��ʽ:?
?
?���ر�Ҷ˹�㷨�ڶ�վ:���ر�Ҷ˹���㲽��
1.һ�����ݼ�������������(B1,B2, B3)��(C1,C2,C3)��һ����ǩ������(A1,A2)
2.����һ����������(D1,D2,D3),ʹ�ñ�Ҷ˹��ʽ���������������A1�黹��A2��


?3.������ʽ��ĸ������ͬ��,����ֻ��Ҫ���Ƿ��ӾͿ�����

4.��ʱ����һ������,�����ѡ������ѵ�����в�����P(�� �������OA1)?�������0,���յĸ���Ҳ�����0,��Ȼ�����Ľ������������Ҫ��
5.�����Ҫ������������������ļ�����

6.������ѵ�������ݾͿ��Լ����A1�ĸ����Լ�A1��������D1��D2��D3�����ĸ�����
7.��Ȼ���ܼ������,���ǿ��ܻ����D1�������û�г�����ѵ�������������,����D1=��,ǡ��A1����Ӧ����������Ӧ�����ݵ�,���ĸ���Ҳ����0
8.���Ǿͳ�����һ��������˹ϵ��,�����Լ�����������(Ϊ0��)ʱ,�������1,��Ӧ�ķ�ĸҲҪ��һ������,���Լ�ij������������,���ʱ�Ӧ���� 0 \ n? ,ʹ��������˹ϵ����ͱ����1\(n+1)
?,һ����һ�����Ҳ�����,���в��Լ�������Ҫ���ӷ�ĸ����һ
��Ŭ�����ر�Ҷ˹
��Ŭ���ֲ��ֳ�0-1�ֲ�,Ҳ�ж���ֲ�,���Բ�Ŭ�����ر�Ҷ˹ֻ�ܶԷ��϶��������ݵ�����
��Ŭ���ֲ���ʽ:

���������ر�Ҷ˹���㲽��������ͬ����,������˹ϵ����ͬ����Ŭ���е�������˹,��ĸ���㷽���Ƿ��ϼ����ǩ����������������ϱ�ǩ�����,���ӻ��Ǽ�1������,��ǩ�������û��,�����жϵ�����������������������ĸ���,����������ѵ����������4��,��ĸ����4+2=6
�������ʹ�ò�Ŭ�����ر�Ҷ˹
��Ŭ���ֲ�:�����������,�ɹ���ʧ��,��ȱ�ݻ�û��ȱ��,���˿�����δ������Ϊ�������,�����������ܵĽ��Ϊ0��1.
�����������ͱ�ǩ���ֲ�Ŭ���ֲ�ʱʹ��,Ҳ�������ı�����(��ʱ������ʾ�����Ƿ����,����ij������ij���Ϊ1,������Ϊ0)
�����������±��ֲ������ʽ�ֲ�,���е�ʱ��Ŭ���ֲ����ֵ�Ҫ�ȶ���ʽ�ֲ�Ҫ��,�����Ƕ���С���������ı�����
?sklearn�д���ʵ��
from sklearn.naive_bayes import BernoulliNB
# ʵ����
alg = BernoulliNB()
# ����:alpha,Ĭ���ǵ���������˹,��ֹ��������������
# ��� X_train,y_trainΪ��ǰ�зֺõIJ������ݵ������ͱ�ǩ
alg.fit(X_train, y_train)
# Ԥ����
y_pred = alg.predict(X_test)
print('Ԥ����:', y_pred)
# Ԥ�����
print('Ԥ�����:', alg.predict_proba(X_test))
# �鿴ȷ��
score = alg.score(X_test, y_test)
print('ȷ��:', score)
��˹���ر�Ҷ˹?
��˹���ر�Ҷ˹��Ҫ���������������������͵�����
�����ܶȺ���(�̴�����ֵ,�Ҵ�������):
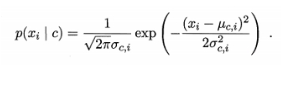
�������ʹ�ø�˹���ر�Ҷ˹
�����ݵ���������Ϊ��˹�ֲ����з���ʱʹ��(�����о�������)
sklearn�д���ʵ��
from sklearn.naive_bayes import GaussianNB
# ʵ����
alg = GaussianNB()
# ����:alpha,Ĭ���ǵ���������˹,��ֹ��������������
# ���
alg.fit(X_train, y_train)
# Ԥ����
y_pred = alg.predict(X_test)
print('Ԥ����:', y_pred)
# Ԥ�����
print('Ԥ�����:', alg.predict_proba(X_test))
# �鿴ȷ��
score = alg.score(X_test, y_test)
print('ȷ��:', score)
?����ʽ���ر�Ҷ˹
����ʽ���ر�Ҷ˹�����ڳ��ִ�����Ϊ����������,��������ֵ�����ǷǸ��ġ������ı����ݵĴ���,�ͷdz��ʺ��ö���ʽ���ر�Ҷ˹����ԭ��:
- ������һ��Ԥ��û����۵����ݼ�,�ڵ�һ��������good������2��,bad������0��,�Ǻ���;�ڵڶ���������good������0��,bad������2��,�Dz�����
g b
2 0 ����
0 2 ���� - ������һ���Լ� [ 5,0 ]
- �������ر�Ҷ˹��ʽ�ֱ����P ( �� �� �O �� �� ) �� P(�����O����)

- ��ʵ���Ϊ�����Ͳ����Ķ���0,������Ҫ����������˹,��ĸ���ڴ��������������+�����,���Ӽ�1

- ��Ҫ�ڸ��������Ӳ��Լ���Ӧ�������ִ����η�

- �������յó�����,[ 5, 0 ]�IJ��Խ���Ǻ���
��ʱʹ�ö���ʽ���ر�Ҷ˹�㷨
1.�������ı�����(������ʾ���Ǵ���,����ij������ij��ִ���
2.����������������������
sklearn�д���ʵ��
from sklearn.naive_bayes import MultionmialNB
# ʵ����
alg = MultionmialNB()
# ���
alg.fit(X_train, y_train)
# �鿴Ԥ����
y_pred = alg.predict(X_test)
print('Ԥ����:', y_pred)
# �鿴Ԥ�����
print('����:', alg.predict_proba(X_test))
ʹ�ö���ʽ���ر�Ҷ˹�����ı���Ƶͳ��
������������
1.ʹ��jieba��,�������зֺ���ʻ�ĺ���?
import jieba # ��ͷִ�
from sklearn.navie_state import MultionmialNB
# ------------------------------�ִʴ���----------------------------
def get_word(val):
return ' '.join(list(jieba.cut(val)))
X = X.transform(get_word)
2.��Ƶ������
��Ƶ������,�ǶԷִʺ�����ݽ���ͳ�������г��ֵĴ���,��Ϊ��ͨ��Ƶ�������� TF-IDF��Ƶ������
��ͨ��Ƶ��������ͳ�Ƴ��ִ���,��������ͨ��Ƶ�������Ĵ���ʵ��
from sklearn.feature_extraction.text import CountVectorizer
# ʵ����
cv = CountVectorizer()
# ����:stop_words:ͣ�ô�,ͨ���Ƕ�ȡһ��ͣ�ô��ı��ļ���Ϊͣ�ôʴʵ�
# �鿴����������ݴʵ�
print('�ʵ�:', cv.get_feature_names())
# �鿴�ʵ��ֵ�,����Ϊ��,��Ӧ�ʵ��������Ϊֵ
print('�ʵ��ֵ�:', cv.vocabulary_)
# ���,һ�㶼����ѵ���������
cv.fit(X_train)
# ����������
X_train = cv.transform(X_train).toarray()
X_test = cv.transform(X_test).toarray()
?3.TF-IDF��Ƶ������
��Ƶ:TF,ָ����ijһ�������Ĵ����ڸ��ļ��г��ֵ�Ƶ��
�����ļ�Ƶ��:IDF,��һ�������ձ���Ҫ�ԵĶ���
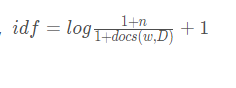 ?
?
TF-IDF = TF*IDF
TF-IDF��Ƶ��������ͳ�ƵĴʵ���Ҫ��,�����Ǵ���ʵ��
from sklearn.feature_extraction.text import TfidfVectorizer
# ʵ����
tv = TfidfVectorizer()
# ���,һ�㶼����ѵ���������
tv.fit(X_train)
# ����������
X_train = tv.transform(X_train).toarray()
X_test = tv.transform(X_test).toarray()
"""
TF-IDF���صĽ���Ǹ��ʵ���ʽ
���һ�����ڵ�ǰ����г����˶��,����������г��ֵĴ�����------��Ҫ�Ĵ�
���һ�����ڵ�ǰ����г����˶��,����������г��ֵĴ���Ҳ��------��Ҫ�Ĵ�
"""
?4.TD-IDF�ļ��㷽��

����ѧϰ
����ѧϰ:�����������ݽ���ѧϰ,��������ѵ����������ѵ��,������������������̫��,��Ҫ����ѵ��ʱʹ��
ֻ�����ر�Ҷ˹���Խ�������ѧϰ?
sklearnʵ��
import joblib
from sklearn.naive_bayes import GaussianNB # ����ʹ�ø�˹���ر�Ҷ˹
# ----------������ݼ�----------------
# ----------���ֳ�����������-----------
X_train1, y_train1
X_train2, y_train2
# ---------ʹ���㷨-------------------
# ʵ����
alg = GaussianNB()
# �����ʹ�ò������,��һ��ʹ�ò��������Ҫ��classes
alg.partial_fit(X_train1, y_train1, classes=[0, 1])
# ����:X_train, y_train, classes:��ǩȥ�غ��ֵ
# -----------����ģ��-----------------
joblib.dump(�㷨����, '�ļ���.model')
# ����һ��Ϻͱ���ģ��ע�͵�,������ȡģ�ͽ������
alg = joblib.load('�ļ���.model')
alg.partial_fit(X_train2, y_train2)
print('�鿴ȷ��:', alg.score(X_test, y_test))
���ر�Ҷ˹�㷨�ܽ�
- �����ٶȿ졾ԭ��:�ٶ������������
- ���ó��������ı�����
- ����������Ȼ���Խ���ѵ��,ʹ�ý�С���ݼ�
- ��������Ҫ����
- ���Խ�������ѧϰ
������������ͬ
��Ŭ�����ر�Ҷ˹:����ֵ�����0��1;ֻ���������Ƿ����
��˹���ر�Ҷ˹:����ֵ����̬�ֲ�,�����д������ǽ�����̬�ֲ�
����ʽ���ر�Ҷ˹:����ֵ�����Ǹ��� ��Ҫ>=0�ı����ೣ���ö���ʽ���ر�Ҷ˹
����ֵ:
? ? ? ?�ٴʳ��ֵĴ���,����Ƶ ?�ʴ�ģ��û�п��Ǵ���ʵĹ�ϵ
? ? ? ?��TF-IDF;��ʾ�ĺ���,�ʵ���Ҫ��(һ�����ڵ�ǰ�ı����ִ�����,�����ı��г��ִ�����TF-IDF��ֵ�ϴ�)
?