����Ŀ¼
ѧϰ�γ�: ��PyTorch���ѧϰʵ�������ϼ�
ע:���Ķ�ӦP9,��δʹ��CNN
����
import torch
from torchvision import transforms # ��ͼ�����ԭʼ�����ݴ����Ĺ���
from torchvision import datasets # ��ȡ����
from torch.utils.data import DataLoader # ��������
import torch.nn.functional as F # ��ȫ���Ӳ��е�relu����� �й�
import torch.optim as optim # ���Ż����й�
# prepare dataset
batch_size = 64
# GPU��2���ݴε�batch���Է��Ӹ��ѵ�����,������ó�16��32��64��128��ʱ����Ҫ������Ϊ��10����100�ı���ʱ���ָ���
# ��������ѵ��ʱ,������Ҫ�������������ݵķ���,Ϊ����Ҫ�趨ÿ������������ݴ�Сbatch_size
transform = transforms.Compose([ # ����ͼ��
transforms.ToTensor(), # Convert the PIL Image to Tensor
transforms.Normalize((0.1307,), (0.3081,)) # ��һ��;0.1307Ϊ��ֵ,0.3081Ϊ����
])
train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=False,
transform=transform) # download=True��ʾ�ֶ�����MNIST���ݼ�(�����ѧ����,��Ȼ�ٶȺ���,���ҿ��������ж�)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=False, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class Net(torch.nn.Module): # design model using class
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # -1��ʵ�����Զ���ȡmini_batch
# Tensor.view(*shape) �� Tensor:Returns a new tensor with the same data as the self tensor but of a different shape.
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # ���һ�㲻������,�����з����Ա任
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss() # ������ʧ����
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# lr (float) �C learning rateѧϰ�� ; momentum (float, optional) �C momentum factor (default: 0)�������� (Ĭ��: 0)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# ���һ�����ε����ݺͱ�ǩ
inputs, target = data
optimizer.zero_grad()
# ���ģ��Ԥ����(64, 10)
outputs = model(inputs)
# �����ش��ۺ���outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299: # batch_idx���ֵΪ937;937*64=59968 ��ζ�Ŷ����˲��ֵ�����
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
# ע:��python��,ͨ��ʹ��%,ʵ�ָ�ʽ���ַ�����Ŀ��;%d �з�������(ʮ����)
running_loss = 0.0
def test():
correct = 0 # ��ȷԤ�������
total = 0 # ������
with torch.no_grad(): # ���Ե�ʱ����Ҫ�����ݶ�(�����������ͼ)
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 ���ǵ�0��ά��,���ǵ�1��ά��
total += labels.size(0)
correct += (predicted == labels).sum().item() # ����֮��ıȽ�����
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw\train-images-idx3-ubyte.gz
100.1%
Extracting ./dataset/mnist/MNIST\raw\train-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw\train-labels-idx1-ubyte.gz
113.5%
Extracting ./dataset/mnist/MNIST\raw\train-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw\t10k-images-idx3-ubyte.gz
100.4%
Extracting ./dataset/mnist/MNIST\raw\t10k-images-idx3-ubyte.gz to ./dataset/mnist/MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw\t10k-labels-idx1-ubyte.gz
180.4%
Extracting ./dataset/mnist/MNIST\raw\t10k-labels-idx1-ubyte.gz to ./dataset/mnist/MNIST\raw
Processing...
Done!
[1, 300] loss: 2.146
[1, 600] loss: 0.746
[1, 900] loss: 0.412
accuracy on test set: 89 %
[2, 300] loss: 0.311
[2, 600] loss: 0.264
[2, 900] loss: 0.231
accuracy on test set: 94 %
[3, 300] loss: 0.192
[3, 600] loss: 0.166
[3, 900] loss: 0.153
accuracy on test set: 96 %
[4, 300] loss: 0.132
[4, 600] loss: 0.122
[4, 900] loss: 0.120
accuracy on test set: 96 %
[5, 300] loss: 0.100
[5, 600] loss: 0.090
[5, 900] loss: 0.098
accuracy on test set: 96 %
[6, 300] loss: 0.077
[6, 600] loss: 0.078
[6, 900] loss: 0.076
accuracy on test set: 97 %
[7, 300] loss: 0.061
[7, 600] loss: 0.066
[7, 900] loss: 0.064
accuracy on test set: 97 %
[8, 300] loss: 0.049
[8, 600] loss: 0.051
[8, 900] loss: 0.055
accuracy on test set: 97 %
[9, 300] loss: 0.040
[9, 600] loss: 0.045
[9, 900] loss: 0.040
accuracy on test set: 97 %
[10, 300] loss: 0.033
[10, 600] loss: 0.035
[10, 900] loss: 0.034
accuracy on test set: 97 %
���˵��
Softmax Classifiter ������������������
1. ����MNIST���ݼ�
-
MNIST ���ݼ������������ұ��뼼���о���, National Institute of Standards and Technology (NIST). ѵ���� (training set) ������ 250 ����ͬ����д�����ֹ���, ���� 50% �Ǹ���ѧ��, 50% �����˿��ղ�� (the Census Bureau) �Ĺ�����Ա. ���Լ�(test set) Ҳ��ͬ����������д��������.
-
MNIST ����6����28x28��ѵ������,1���Ų�������,�ܶ�̶̳�����������֡�,������Ϊһ�� ���䷶��,����˵�����Ǽ�����Ӿ������Hello World
-
MNIST ���ݼ����� http://yann.lecun.com/exdb/mnist/ ��ȡ, ���������ĸ�����:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, ��ѹ�� 47 MB, ���� 60,000 ������)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, ��ѹ�� 60 KB, ���� 60,000 ����ǩ)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, ��ѹ�� 7.8 MB, ���� 10,000 ������)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, ��ѹ�� 10 KB, ���� 10,000 ����ǩ)
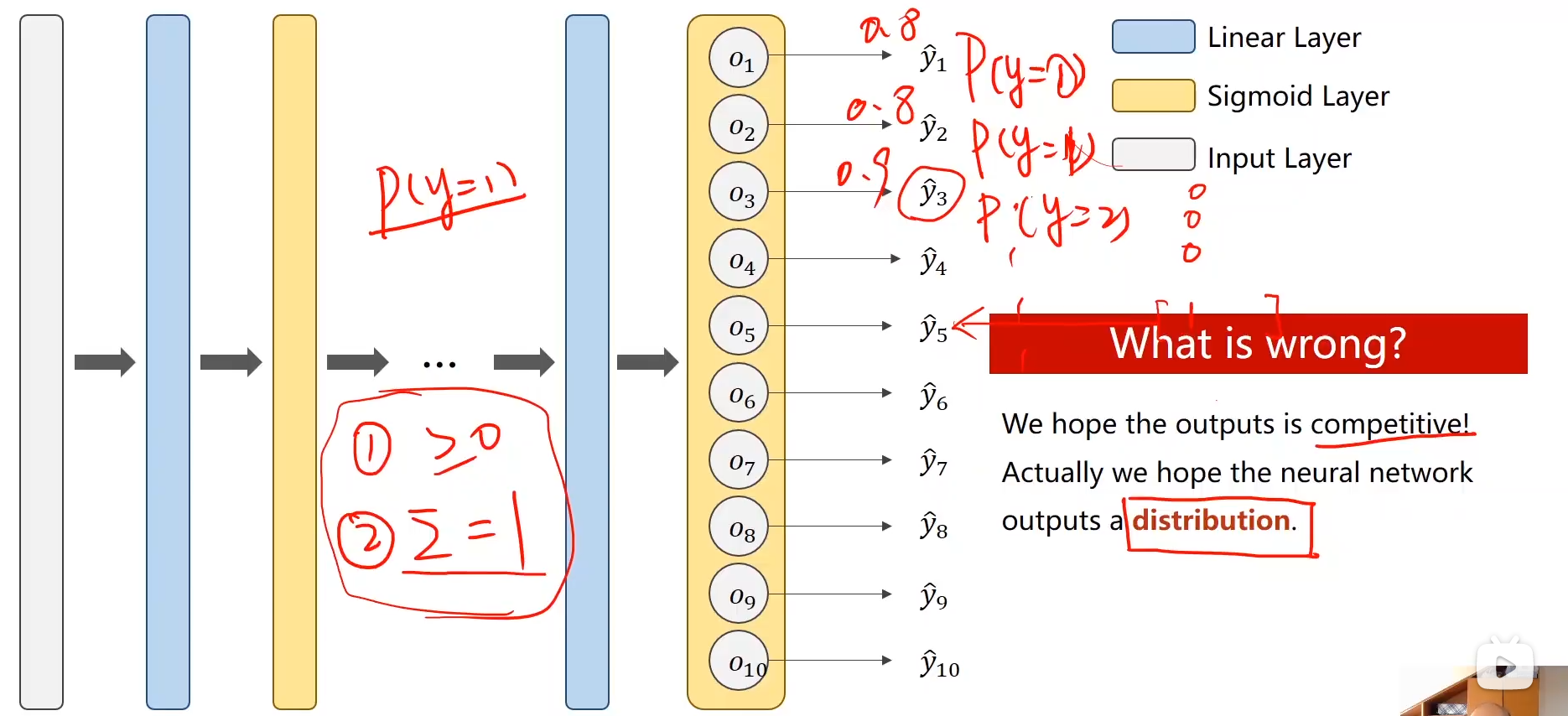
2. ���ڶ�����������
��ÿһ�������һ�������������,�����Ǹ���������Ŀ�����֮��Ҫ������ƵĹ���(���統Ϊ1�Ŀ������㹻���ʱ��,��ô�������ֵĿ����Ծͻ��С)
-
����ʮ�����������е����Ҫ��(����������ɢ�ֲ���Ҫ��):
-
������������0;
-
���е����֮��Ϊ1;
-
3. ���������紦������
������Ķ�Ӧ��������ǰ�����Щ���Ӧ�Ļ���ʹ��Sigmod����,����������һ�㲻ʹ��Sigmod(ʹ��Sigmod�ò�����Ҫ�Ľ��)

4. softmax����

-
����(�Լ�softmax �� NLLLoss �� CrossEntropyLoss()��������ʧ ֮�������):
-
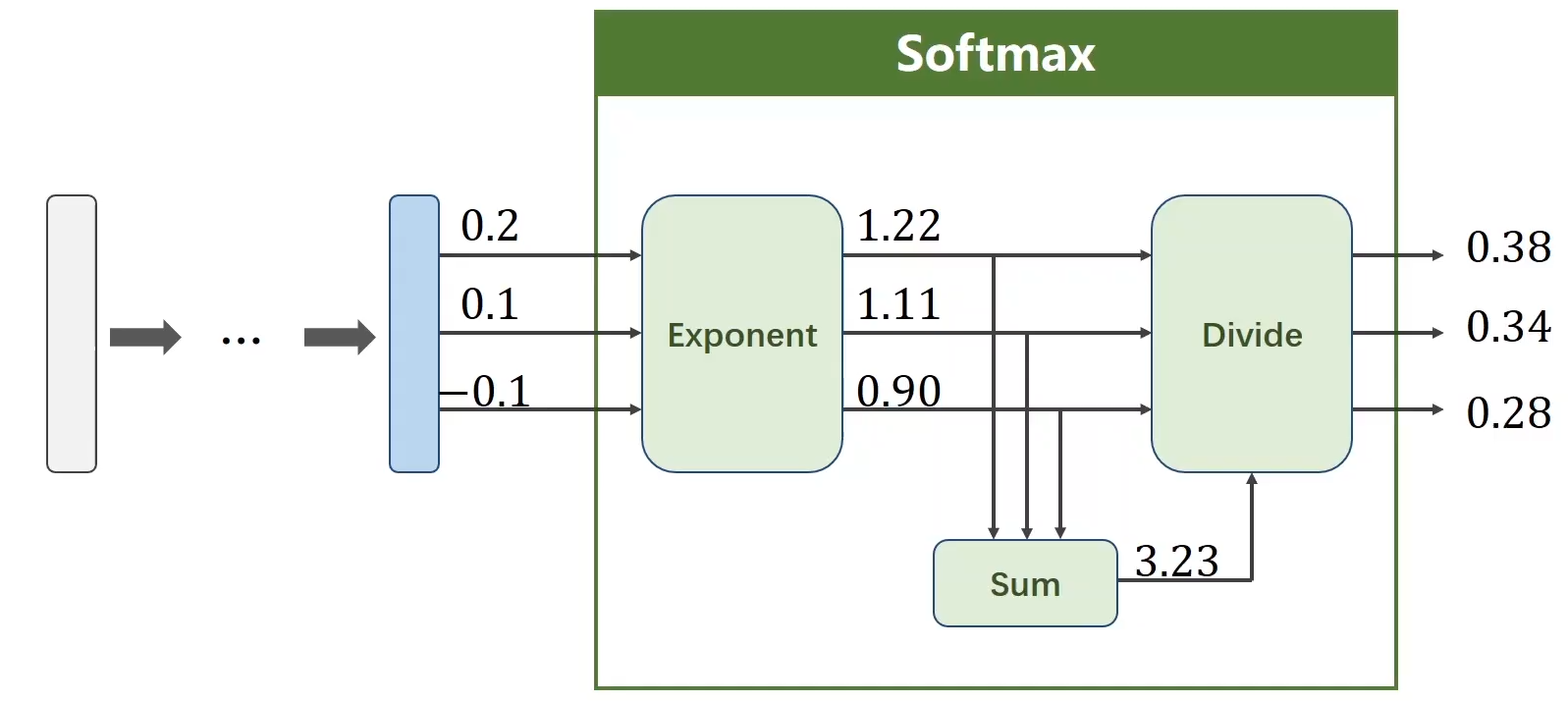
-

-
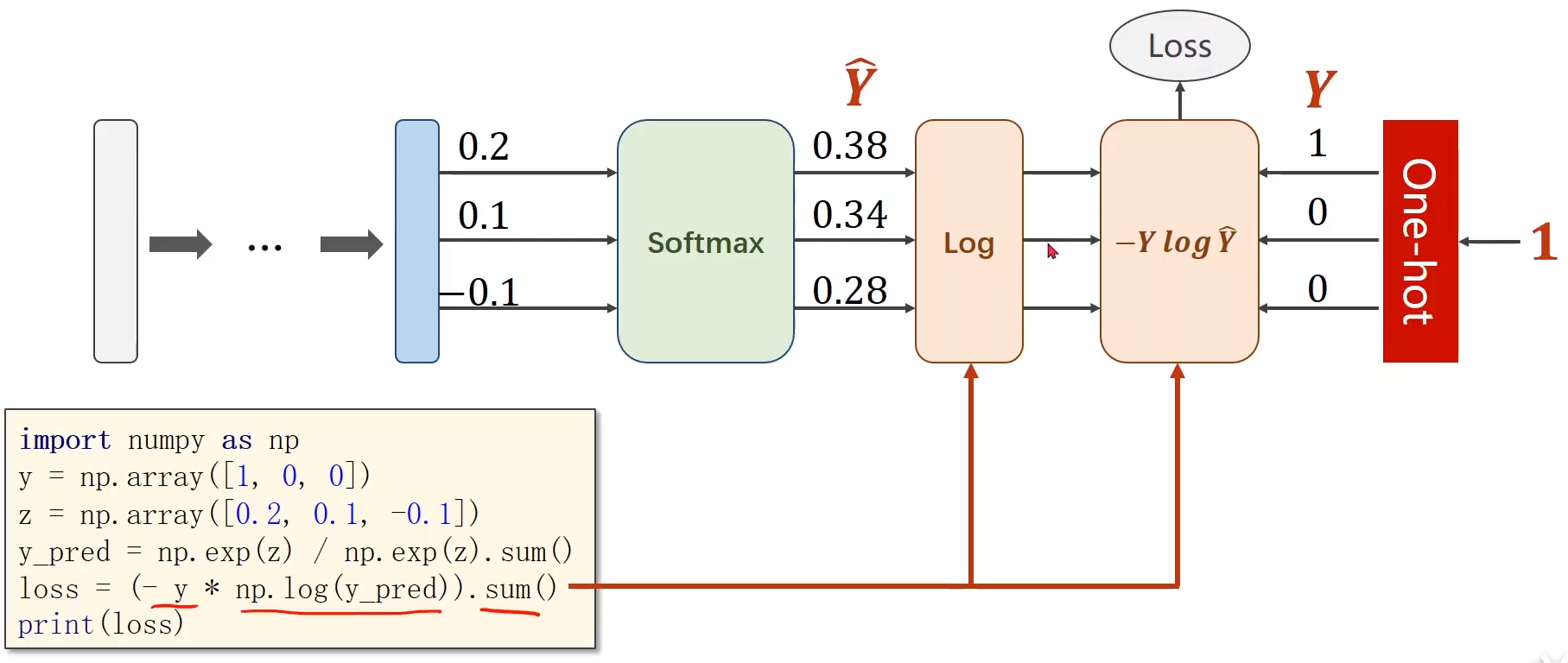
-
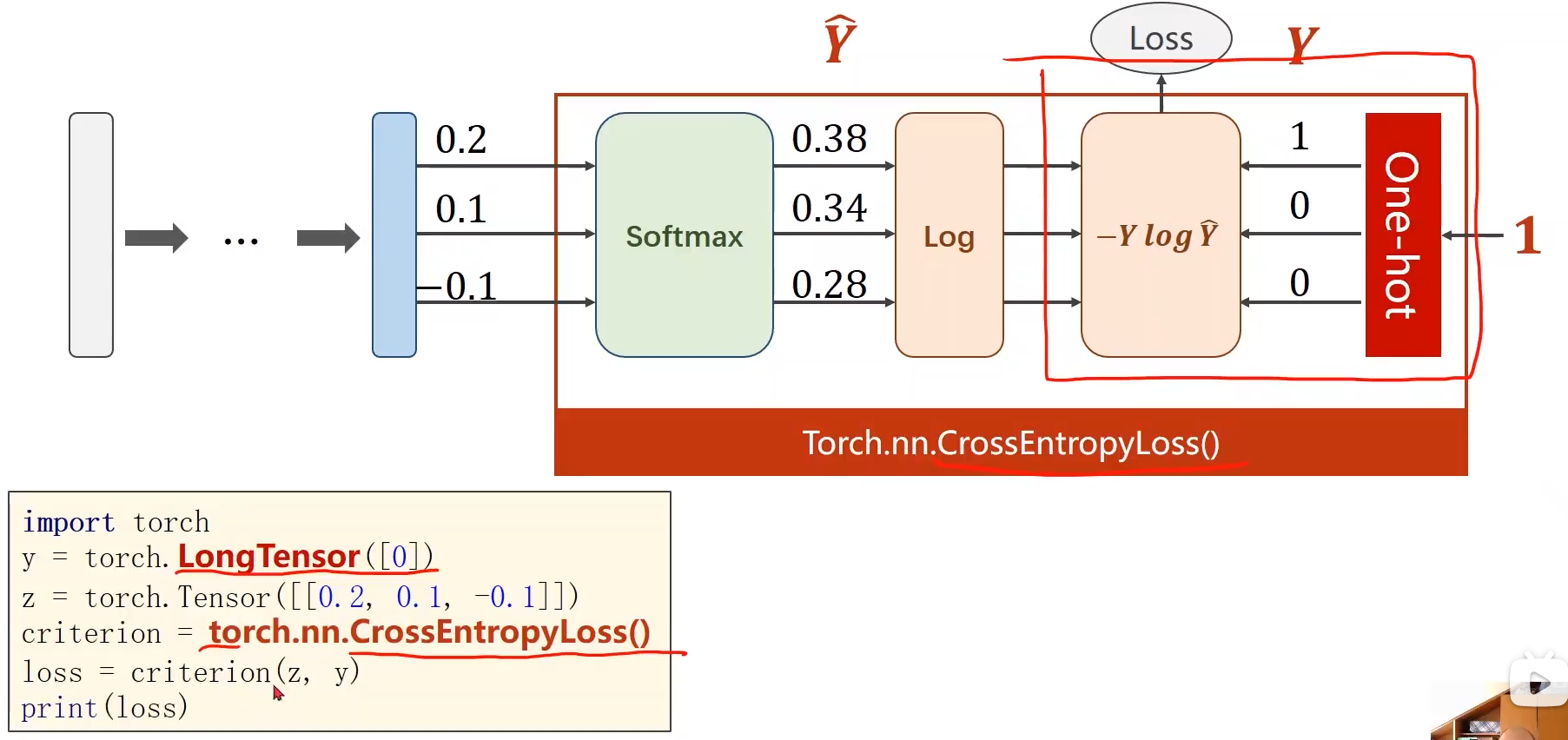
-
����ʾ��:
-
torch.Tensor([0.1,0.2,0.9],��) ��ʾԭʼ�����Բ�����,��û�о���softmax,�����Ǹ��ʷֲ�;��ʾ��һ������������2 �ġ������ԡ���0.9,������1�ġ������ԡ���0.2,������0�ġ������ԡ���0.1;(����mini-batch �е�batch_size��3,��ʾ����������Ϊһ��һ�����)

5. ����MNIST���ݼ��Ĵ�������
ÿһ��ͼƬ����28*28������,ÿһ������ֵ��ȡֵ��0255;���0255ӳ�䵽0~1������,��Ӧ��28 * 28�ľ���;

6. ��������
7. ����transforms.ToTensor
Ϊ����pytorch�н��и��Ӹ�Ч��ͼ�����;������������е�ת��
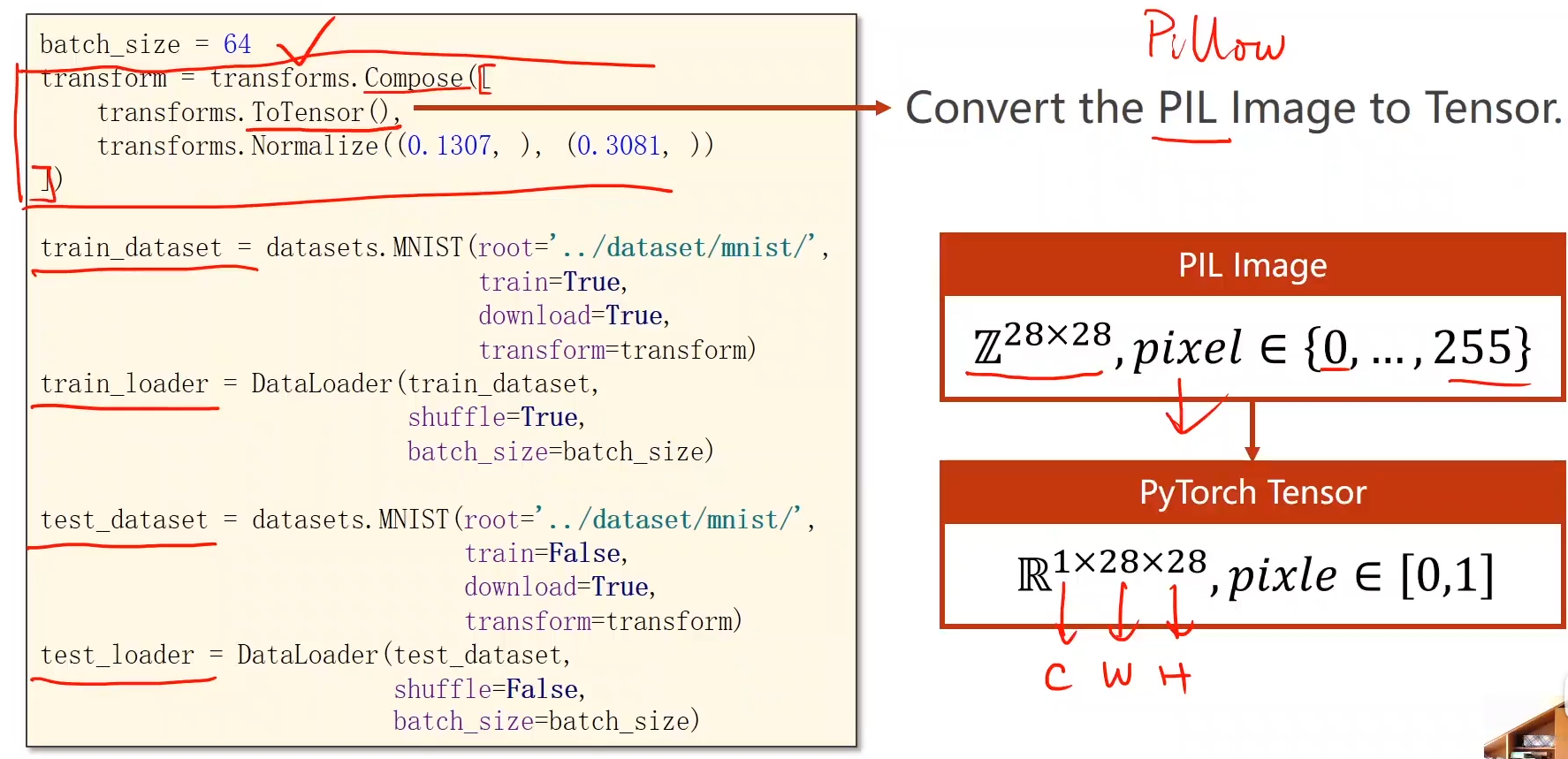
8. ����transforms.Normalize

9.������transform�Ķ�Ӧ��ϵ

10. ����x.view
x.view���ڸı���������״
���������(N,1,28,28):4������,ÿ������N������,ÿ��������һά,���س�����28 * 28��ͼ��;�����N��������Ϊmini-batch��batch_size�Ĵ�С;
11. ���ģ��
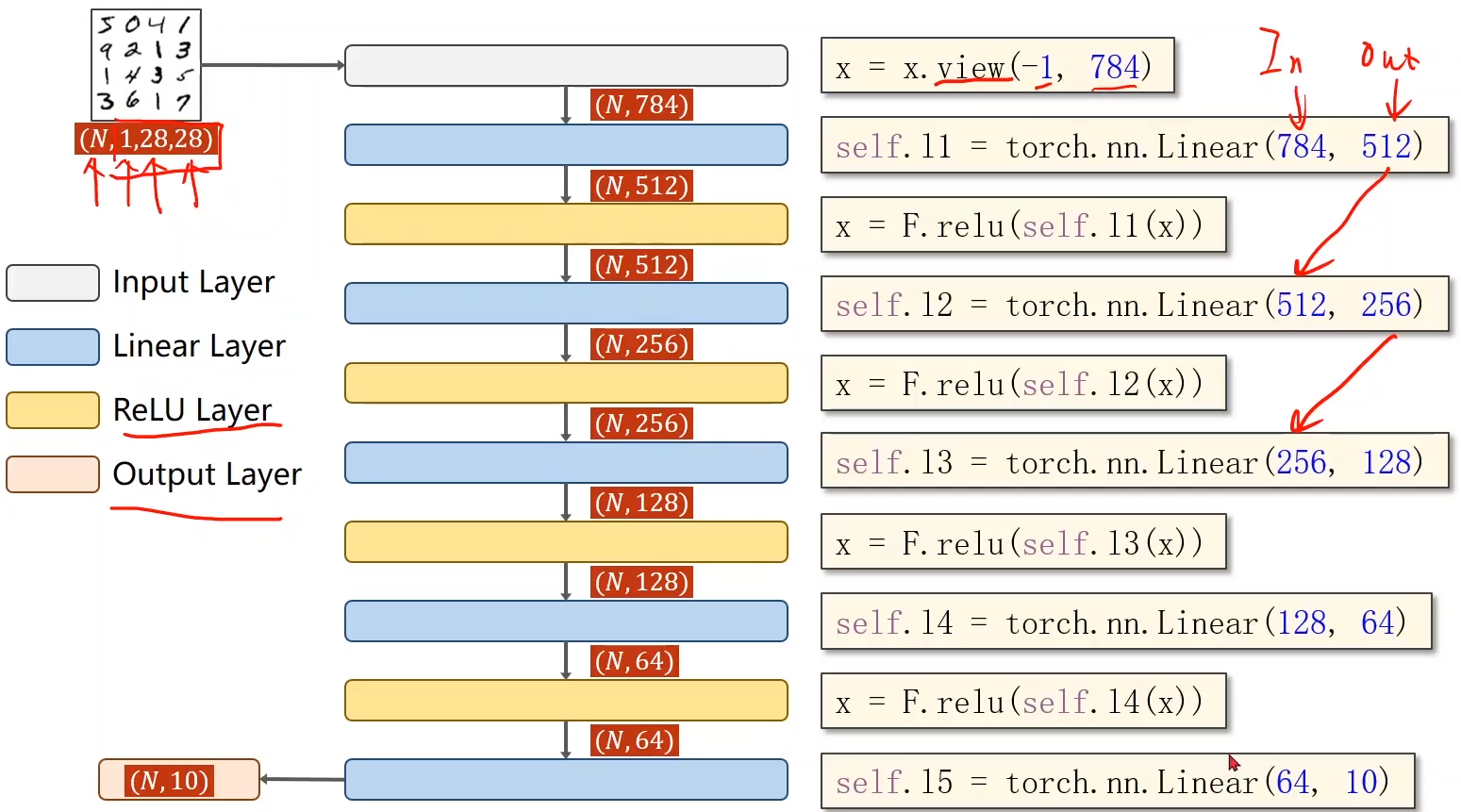
ע�����һ�㲻������,ֱ�����Բ������ӵ������softmax����

12. batch size���ü��� ̸̸batchsize����
�ο�:batch size���ü��� ̸̸batchsize����
- batch��size���õIJ���̫��Ҳ����̫С,���ʵ�ʹ�������õľ���mini-batch,һ��size����Ϊ��ʮ�����١�
- ���ڶ����Ż��㷨,��Сbatch�����������ٶ�����Զ������������������µ������½�,�����ʹ�ö����Ż��㷨ʱ,����Ҫ���ô�batchŶ����ʱ����batch���óɼ�ǧ����һ������ܷ��ӳ�������ܡ�
- GPU��2���ݴε�batch���Է��Ӹ��ѵ�����,������ó�16��32��64��128��ʱ����Ҫ������Ϊ��10����100�ı���ʱ���ָ���
13. ����x.view(-1, 784)
����˵��view()������:
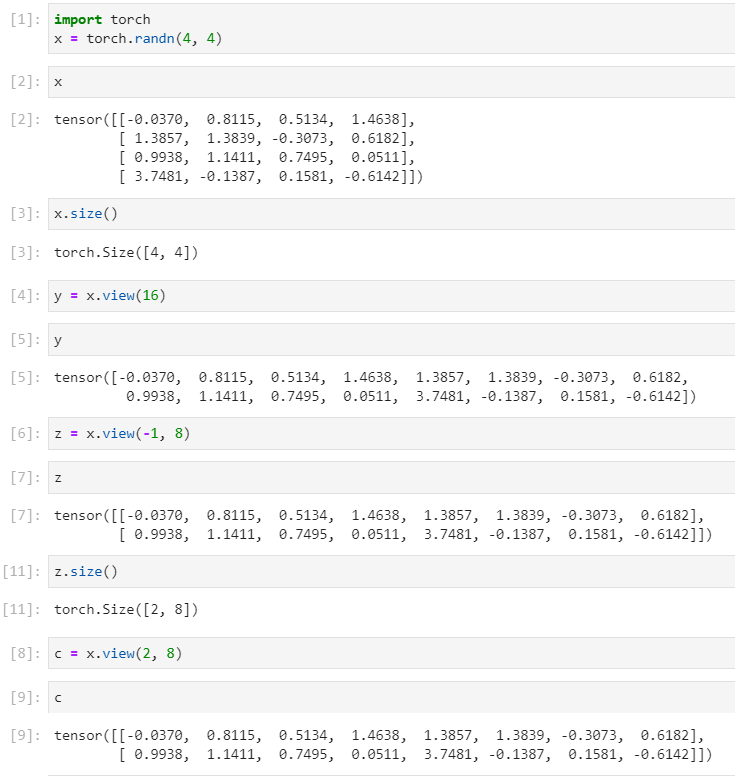
�����е�inputs:
����������ÿ��inputs����������:

���һ�ε�ʱ��(forѭ��������Ϻ�)���Թ���inputs�IJ���:

