文章目录
1、简介
TensorFlow 2发布已经接近2年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。并且TensorFlow 2是真正整合了TensorFlow生态的其它组件,例如TensorFlow Serving、TensorFlow Lite等,这些可以帮助我们提升生产级AI的稳定性和可维护性。并且借助官方文档进行学习可以更加快速地进行学习。

2、设计思想
2.1、TensorFlow与Pytorch
PyTorch 采用的是动态图机制 (Dynamic Computational Graph),而 Tensorflow 采用的是静态图机制 (Static Computational Graph)。
动态图是运算和搭建同时进行,也就是可以先计算前面的节点的值,再根据这些值搭建后面的计算图。优点是灵活,易调节,易调试。PyTorch 里的很多写法跟其他 Python 库的代码的使用方法是完全一致的,没有任何额外的学习成本。
静态图是先搭建图,然后再输入数据进行运算。优点是高效,因为静态计算是通过先定义后运行的方式,之后再次运行的时候就不再需要重新构建计算图,所以速度会比动态图更快。但是不灵活。TensorFlow 每次运行的时候图都是一样的,是不能够改变的,所以不能直接使用 Python 的 while 循环语句,需要使用辅助函数 tf.while_loop 写成 TensorFlow 内部的形式。
2.2、TensorFlow 2 新特性
3大设计原则:简化概念,海纳百川,构建生态
- 简化概念:是相比于TensorFlow 1来说的,TensorFlow 1关注于模型的性能问题,可以自由定义各种算子与模型,牺牲了易用性,2相较于1砍掉了大量的API。
- 海纳百川:吸收了Keras以及Numpy等简单操作的特性。
- 构建生态:TF2的生态很丰富,例如,训练可视化的TensorBoard,部署到云端的TF Serving,到边缘设备的TF Lite。
2.3、TensorFlow 2 核心模块
- 数据处理模块 tf.data & tf.keras
- 负责数据的管理。
- 支持多种数据来源:本地文件、分布式文件系统、对象存储系统。
- 支持多种数据格式。
- tf.keras在分布式与高性能上有所提升
- 分布式策略模块 tf.distribute
- 用少量代码把原来的模型变成分布式训练的模型,提供许多的strategy,加速模型训练。
- 模型序列化 saved model
- 训练完成的模型通过模型保存模块可以保存成多种文件格式,并根据需求部署到不同设备上。
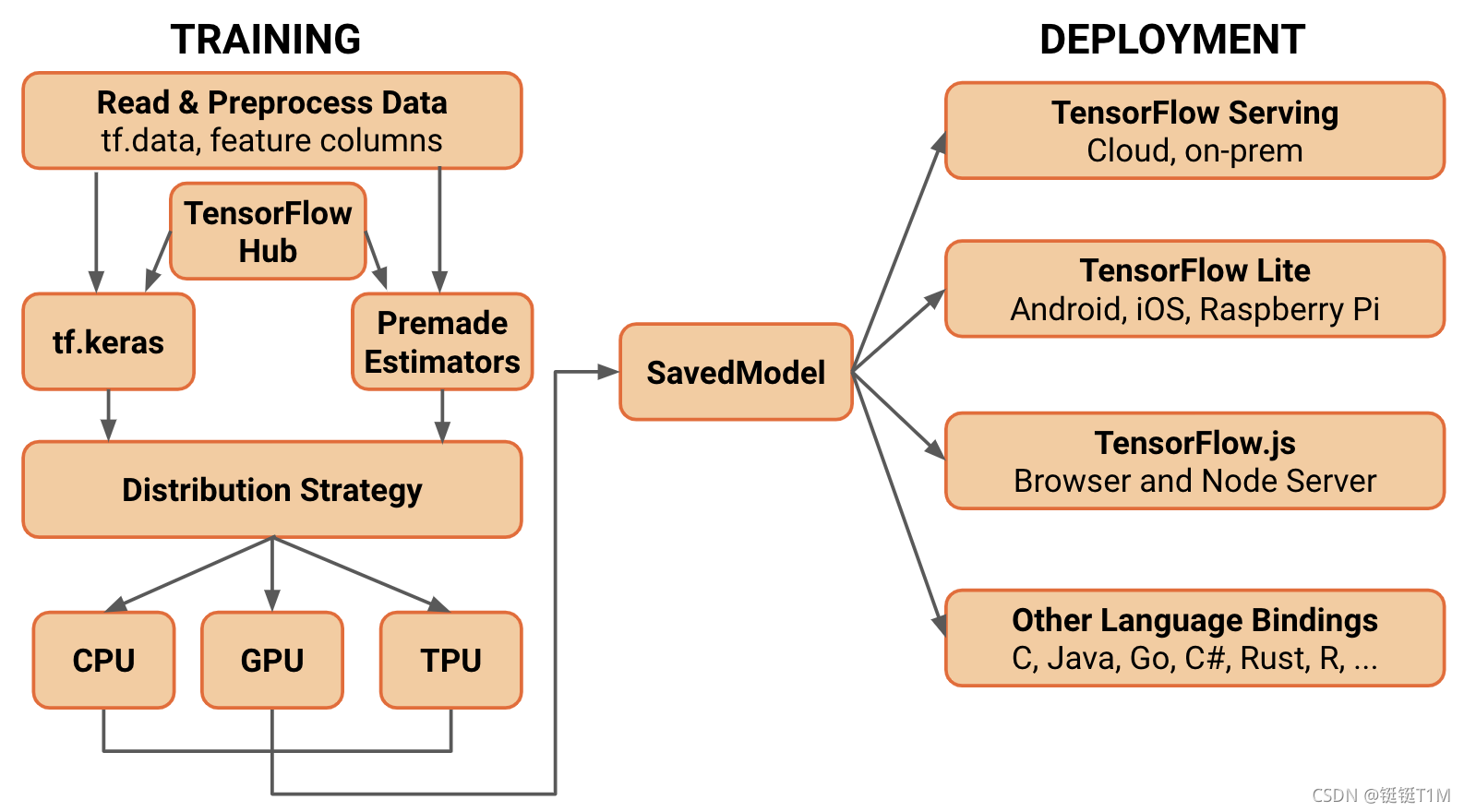
2.4、TensorFlow 2 vs. TensorFlow 1.x
可以从高层次API与低层次灵活性进行比较
- TensorFlow 1 最初考虑的可能是Google内部模型非常大,数据非常多,优先考虑性能问题,因此着重考虑分布式与性能的问题,它可以自由定义各种算子与模型。牺牲了易用性的特点。
- TensorFlow 2在1的基础上,既吸收了Keras这些易用性的API,并且进一步扩展到分布式与底层,用tf.functuion去做高性能的提升,同时也保留了TensorFlow 1 的一些底层特性:自定义的Training Loop,自定义的函数方法……
- TensorFlow2希望兼容架构层次API与模型训练API,或者是在易用性与灵活性之间做一个权衡。
3、快速上手:以Fasion MNIST为例
以下的学习基于Jupyter Lab,使用TensorFlow 2.2.0。
3.1、数据导入与使用
TensorFlow 2有3种加载数据的方法:List、Generator与文本文件
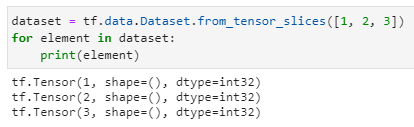
1、使用 tf.data.Dataset.from_tensor_slices 加载 List
- 核心是把各种来源的数据装成一个数据集
- tf.data.Dataset的后面就会接各种各样的方法
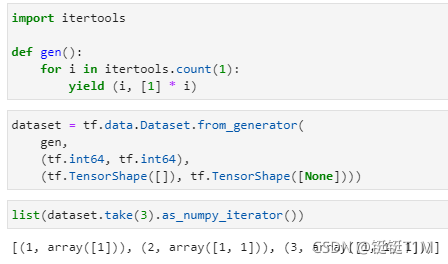
2、使用 tf.data.Dataset.from_generator 加载 Generator
- 加载Python生成器里面的数据
- TensorShape这么一个格式描述生成器生成出来的数据的张量形状
- 生成器最终生成一个函数赋予了Dataset
- 最终使用dataset的take方法调用了3次生成器
- 适用于大批量数据集,可以一次次一批批加载数据
3、使用 tf.data.TextLineDataset 加载文本
- 专门为文本文件设计的数据集格式
3.2、模型管理
简单演示构建用于训练MNIST的神经网络,定义一个简单的全连接神经网络进行分类,来展示如何构建网络模型。
1、模型定义
在TensorFlow 2 中定义模型有两种方式,1种是Sequential,另一种是Functional API 。
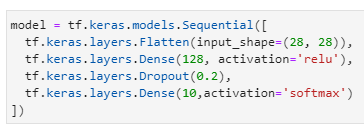
(1) Sequential
- Sequential核心思路:一层层往下叠加的序列的模型。
- 最后的Dense(10)需要激活,否则无法去做任何分类,因此通常会在FC的最后一层添加一个softmax作为分类器的输出。
(2) Functional API
与Sequential方式定义模型的差别在定义模型输入的时候,前者更为清晰简洁,后者更为自由与方便。

2、模型预览
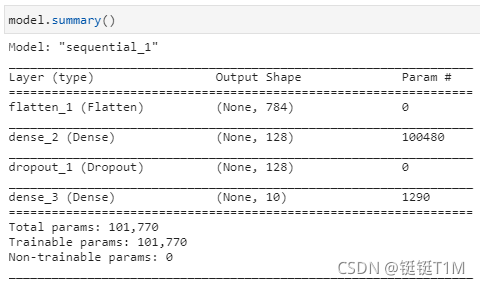
- 使用
model.summary打印模型
3、可视化模型结构
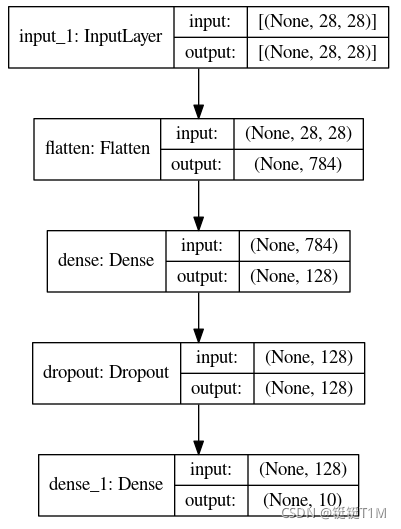
- 使用
plot_model tf.keras.utils.plot_model(model, model.name+'.png', show_shapes=True,show_layer_names=True)show_shapes可以显示数据形状,show_layer_names可以显示每层的名字。- 其中None可以理解为占位符,是每一批数据的个数。
4、训练与评估模型
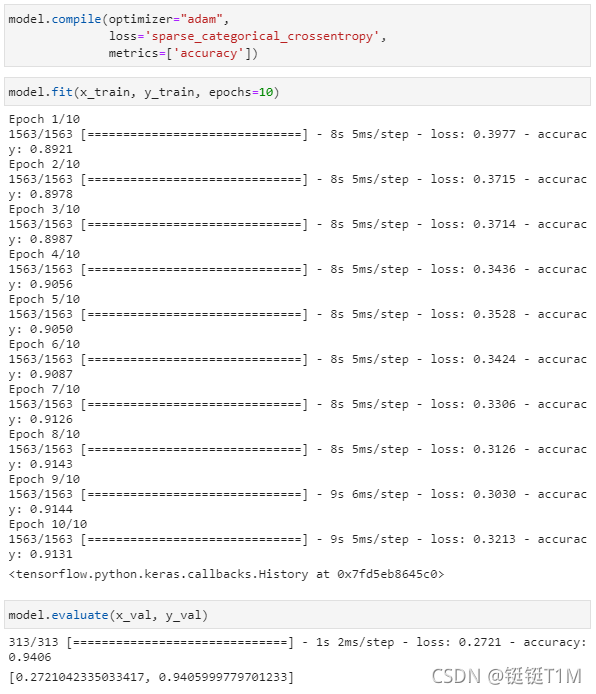
- 预设超参数:
model.compile,参数为优化器,损失函数,关注的优化指标 - 训练:
model.fit,参数为训练集图片,训练集标签,训练次数 - 评估:
model.evaluate,参数为验证集图片,验证集标签
5、保存模型
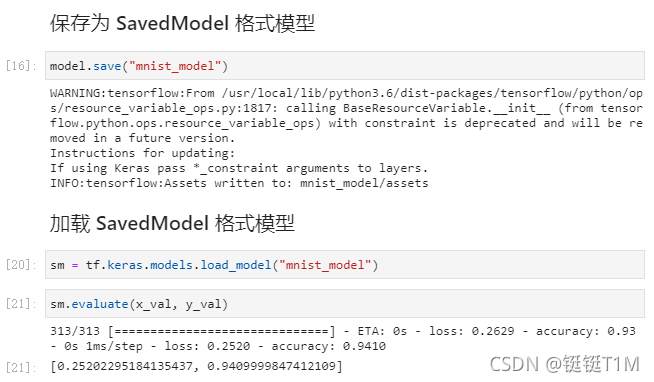
1、保存为 SavedModel 格式模型
- 保存的SavedModel模型文件格式,variables里面放了模型的参数,asserts里面放置自定义加载的附加的预置文件。
2、保存为Keras 的h5模型
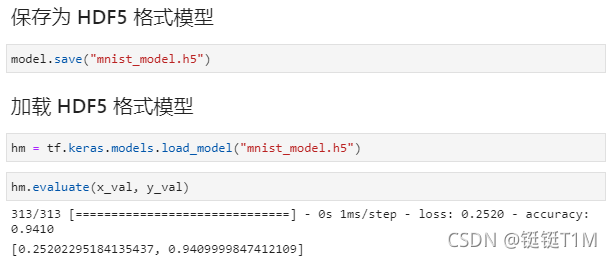
3.3、使用TensorFlow2训练分类网络
1、Fashion MNIST 数据集介绍
- Fashion MNIST 比MNIST的分类难度更大些,因为其特征不如手写数字明显,对分类器提出了新的挑战。
- 10类,70000图片,大小为28*28
- 一般网络在Fasioin MNIST上普遍会比MNIST低10个点

2、数据集获取
使用tf.keras.datasets预置数据集获取Fasion MNIST
from tensorflow import keras
import tensorflow as tf
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
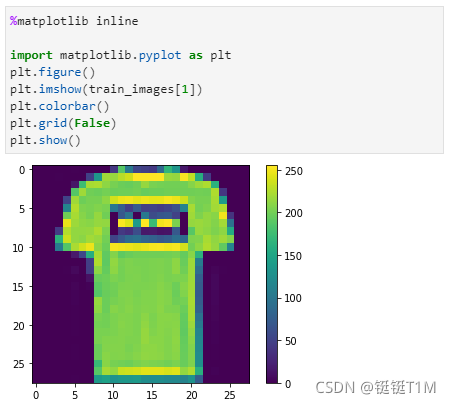
3、可视化
使用matplotlib检查数据集下载情况
4、数据预处理
- 确定分类类别
- 图像像素归一化
- 可视化检查数据集与标签是否对应


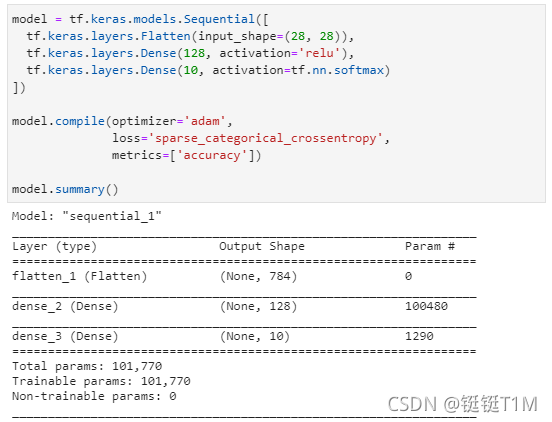
5、构建模型
构建简单的神经网络进行多分类
6、训练与评估
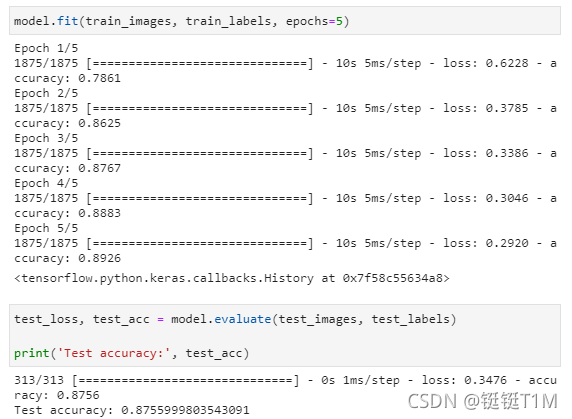
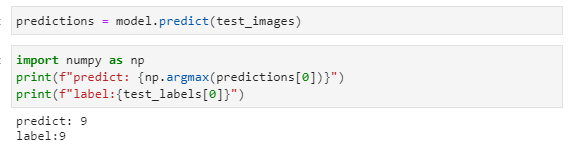
7、模型预测
- 通过比较预测标签与真实标签,来判断模型是否预测准确。
- 使用
model.predict,可以进行同时推理多张图片,输出与类别数目相同长度的数组
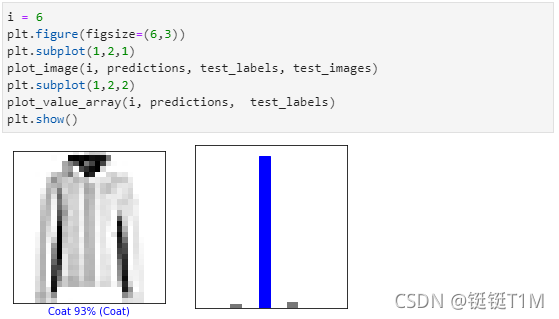
8、可视化预测结果
- 输入全部的prediction,然后以一个子图的形式去展现出当前预测的结果和它的置信度。
参考资料
极客时间《TensorFlow 2 项目进阶实战》