ЮФеТФПТМ
0.в§бд
\qquad БОЮФЪЧФцЧПЛЏбЇЯАЯЕСаЕФЕк2ЦЊ,ЦфгрВЉПЭДЋЫЭУХШчЯТ:
\qquad зюДѓьибЇЯАЪЧ2008ФъГіЯжЕФЗНЗЈ,дТлЮФ(СДНгМћЁОФцЧПЛЏбЇЯА0ЁПЕФВЉПЭ)ЪЙгУЕФRewardЕФКЏЪ§ШдШЛЪЧЯпадФЃаЭ,ЕЋЪЧгХЛЏЕФЫМЯыКЭжЎЧАЬИЕНЕФбЇЭНбЇЯАгаБОжЪВюБ№,гЩгкашвЊвЛаЉИХТЪТлКЭЫцЛњЙ§ГЬЗжЮіПЮГЬЕФжЊЪЖ,дpaperЕФРэТлвВЪЎЗжЛоЩЌФбЖЎЁЃБОШЫЦОНшДжЧГЕФРэНтИјДѓМввЛИіЧГЯдвзЖЎЕФНтЪЭЁЃ
дЛсвщЕФpresentation(PPT)гРОУУтЗб
дpaperМћВПЗж0- IntroductionВПЗж
\qquad
бЇЭНбЇЯА(APP)ЪЧзюДѓЛЏМфЯЖВпТд(MMP)ЕФвЛжжРЉеЙ,ЭЈЙ§ЧѓНтТњзузюДѓЛЏМфЯЖЕФRewardРДМЦЫуReward,ДгЖјЪЙЕУLeanЕФааЮЊдНРДдНЧїЯђгкExpert(ЕЋгжВЛКУгкExpert),етжжЗНЗЈЭљЭљНазіFeature MatchingЁЃЦфШБЕудкгкЖдгкДцдкЖржжКЯРэЕФRewardЕФКЏЪ§ЛђепExpertДцдкЖржжДЮгХЙьМЃЪБ,ИУЗНЗЈОЭЮоФмЮЊСІСЫЁЃAPPБОжЪЪЧгадМЪјгХЛЏЮЪЬт,ЖјгХЛЏБфСПЪЧfeatureЕФdiscount-expectationЛљЯђСПЕФзјБъ
ІШ
\theta
ІШЁЃШЛЖјЖдгкУПвЛИіВпТд
Іа
\pi
ІаЖјбд,ЖМПЩФмДцдкЖрИіRewardКЏЪ§ЪЙЦфзюгХЁЃЕБбнЪОСЫДЮгХааЮЊЪБ,ашвЊЖрИіВпТдЛьКЯРДЦЅХфЬиеїМЦЪ§,етОЭШУFeature MatchingетМўЪТдкExpertЙьМЃДцдкЖрИіFeatureЦкЭћжЕЪББфЕУЗЧГЃФЃК§ЁЃдкAPPжа,етЪЧЭЈЙ§ЧѓЦНОљЕФЗНЪННтОіЕФ,ШЛЖјетУїЯдВЛЪЧвЛИіКЯРэЕФНтОіЗНАИЁЃ
\qquad
зюДѓьибЇЯАЭЌбљЪЧFeature MatchingЕФЗНЗЈ,гыбЇЭНбЇЯАВЛЭЌЕФЪЧ,ЦфВЩгУСЫвЛжжгаддђЕФЗНЪНЯћГ§СЫетжжЦЅХфЦчвхЁЃЖјетжжддђОЭЪЧзюДѓьиддђ,ИУддђЛљгквЛжжМйЩшЁЊЁЊМДзЈМвЯЕЭГЙьМЃЩњГЩздМКЕФзЈМвЬиеїЦкЭћЕФВпТдЪЧзюгХЙьМЃ(МДЯТЮФЕФдМЪјЬѕМў1).
\qquad
ПЩвдМђЕЅЕФРэНтЮЊ,дкбЇЭНбЇЯАжазїЮЊЫ№ЪЇКЏЪ§ЕФЬиеїЦЅХф,дкзюДѓьибЇЯАжаБЛЗХШыСЫдМЪјЬѕМўжа,ЖјзюДѓьибЇЯАе§ЪЧдкТњзуетИідМЪјЬѕМўЕФЧщПіЯТ,вЊЧѓвд
ІШ
\theta
ІШЮЊRewardКЏЪ§ВЮЪ§ЪБ,ЙьМЃИХТЪЗжВМ
P
(
ІЦ
ЈO
ІШ
)
P(\zeta|\theta)
P(ІЦЈOІШ)ЕФаХЯЂьизюДѓЁЃ
\qquad
жСгкЮЊЪВУДвЊЧѓаХЯЂьизюДѓ,дpaperжаВЂЮоЯъЯИЫЕУї,жЛЪЧжИГіетвбОдкreferenceРяУцгаСЫЯрЙибаОП,БОШЫВщдФЯрЙизЪСЯ,ИјГівдЯТМИИіРэгЩЙЉДѓМвВЮПМ:
- ЮяРэЯЕЭГЕФЮШЖЈзДЬЌЭЈГЃЧїЯђгкьизюДѓ
- жЛгаPКуЮЊ0ЕФИХТЪЗжВМьиВХЮЊ0,е§ЬЌЗжВМЪЧЫљгаИХТЪЗжВМжаьизюДѓЕФ(ЛсвщpresentationРяУцЫЕОљдШЗжВМЕФаХЯЂьизюДѓ,ШЗШЯЙ§ЪЧИіДэЮѓНсТл,ЪдЯывЛЯТОљдШЗжВМЕФЗжВМЧјМфгаЯоЖје§ЬЌЮоЯо)
- ьидНДѓ,ЯШбщаХЯЂдНЩй,зюДѓьиЙРМЦвВЪЧЭГМЦОіВпРэТлжаГЃгУЕФвЛжжЙРМЦддђ
1.ЫуЗЈдРэ
ЯТУцОЭМђЕЅНщЩмвЛЯТетИіьи,ЖдгкСЌајБфСПЖјбд,аХЯЂьиЭЈГЃБэЪОЮЊ
E
n
t
=
Ёв
x
Ёз
Іа
?
p
(
x
)
l
o
g
p
(
x
)
Ent=\int_{x\backsim \pi}-p(x)logp(x)
Ent=ЁвxЁзІа??p(x)logp(x)
ЖдгкЧПЛЏбЇЯАШЮЮёЖјбд,зюДѓЛЏаХЯЂьиаДЮЊ:
max
?
ЁЦ
ІЦ
ЁЪ
D
?
P
(
ІЦ
ЈO
ІШ
)
l
o
g
P
(
ІЦ
ЈO
ІШ
)
s
.
t
.
{
ЁЦ
ІЦ
ЁЪ
D
P
(
ІЦ
ЈO
ІШ
)
f
ІЦ
=
f
~
ЁЦ
ІЦ
ЁЪ
D
P
(
ІЦ
ЈO
ІШ
)
=
1
\begin{aligned} & \max\sum_{\zeta \in D}-P(\zeta| \theta)logP(\zeta| \theta) \\ s.t. &\begin{cases} \sum_{\zeta\in D}P(\zeta| \theta)f_\zeta = \widetilde{f} \\[2ex] \sum_{\zeta \in D}P(\zeta | \theta)=1 \\ \end{cases} \end{aligned}
s.t.?maxІЦЁЪDЁЦ??P(ІЦЈOІШ)logP(ІЦЈOІШ)????ЁЦІЦЁЪD?P(ІЦЈOІШ)fІЦ?=f
?ЁЦІЦЁЪD?P(ІЦЈOІШ)=1??
ЙЙдьРИёРЪШеКЏЪ§
L
(
P
,
ІЫ
,
ІЬ
)
=
ЁЦ
ІЦ
ЁЪ
D
[
P
(
ІЦ
ЈO
ІШ
)
l
o
g
P
(
ІЦ
ЈO
ІШ
)
+
ІЫ
(
P
(
ІЦ
ЈO
ІШ
)
f
ІЦ
?
f
~
)
+
ІЬ
(
P
(
ІЦ
ЈO
ІШ
)
?
1
)
]
L(P,\lambda,\mu)= \sum_{\zeta \in D}[P(\zeta|\theta)logP(\zeta|\theta)+\lambda (P(\zeta|\theta)f_{\zeta}-\widetilde{f})+\mu(P(\zeta|\theta)-1)]
L(P,ІЫ,ІЬ)=ІЦЁЪDЁЦ?[P(ІЦЈOІШ)logP(ІЦЈOІШ)+ІЫ(P(ІЦЈOІШ)fІЦ??f
?)+ІЬ(P(ІЦЈOІШ)?1)]
гІгУРИёРЪШеКЏЪ§ЕФKKTЬѕМў
?
L
P
=
ЁЦ
ІЦ
ЁЪ
D
l
o
g
P
(
ІЦ
ЈO
ІШ
)
+
1
+
ІЫ
f
ІЦ
+
ІЬ
=
0
Ђй
?
L
ІЫ
=
ЁЦ
ІЦ
ЁЪ
D
P
(
ІЦ
ЈO
ІШ
)
f
ІЦ
?
f
~
=
0
Ђк
?
L
ІЬ
=
ЁЦ
ІЦ
ЁЪ
D
P
(
ІЦ
ЈO
ІШ
)
?
1
=
0
Ђл
\begin{array} {cl} \nabla L_P =& \sum_{\zeta \in D}logP(\zeta|\theta)+1+\lambda f_{\zeta}+\mu=0 &Ђй\\ \nabla L_{\lambda}=&\sum_{\zeta\in D}P(\zeta| \theta)f_\zeta - \widetilde{f} = 0 &Ђк\\ \nabla L_{\mu} =& \sum_{\zeta \in D}P(\zeta | \theta)-1=0 &Ђл \end{array}
?LP?=?LІЫ?=?LІЬ?=?ЁЦІЦЁЪD?logP(ІЦЈOІШ)+1+ІЫfІЦ?+ІЬ=0ЁЦІЦЁЪD?P(ІЦЈOІШ)fІЦ??f
?=0ЁЦІЦЁЪD?P(ІЦЈOІШ)?1=0?ЂйЂкЂл?
гЩЂйЂлЪНЕУ
P
(
ІЦ
ЈO
ІШ
)
=
e
x
p
(
?
1
?
ІЬ
?
ІЫ
f
ІЦ
)
ЁЦ
ІЦ
ЁЪ
D
e
x
p
(
?
1
?
ІЬ
?
ІЫ
f
ІЦ
)
P(\zeta|\theta)=\frac{exp(-1-\mu-\lambda f_{\zeta})}{\sum_{\zeta \in D}exp(-1-\mu-\lambda f_{\zeta})}
P(ІЦЈOІШ)=ЁЦІЦЁЪD?exp(?1?ІЬ?ІЫfІЦ?)exp(?1?ІЬ?ІЫfІЦ?)?
\qquad
ЙтППетИіЪНзгПЯЖЈЪЧНтВЛГізюгХЕФ
ІШ
\theta
ІШЕФ,етОЭвЊЬсЕНдpaperЕФСэвЛИіМйЩшЁЊЁЊЪЙгУ
ІШ
\theta
ІШВЮЪ§ЕФRewardКЏЪ§
R
ІШ
(
Іг
)
R_\theta(\tau)
RІШ?(Іг)ЪБ,
ІЦ
\zeta
ІЦЙьМЃЕФИХТЪ
P
(
ІЦ
ЈO
ІШ
)
P(\zeta|\theta)
P(ІЦЈOІШ)е§БШгк
R
ІШ
(
ІЦ
)
R_{\theta}(\zeta)
RІШ?(ІЦ)ЕФздШЛжИЪ§,дйМгЩЯИХТЪЙщвЛаддМЪј,ПЩЕУзЈМвЯЕЭГВпТдЕФЙьМЃИХТЪЮЊ:
P
(
ІЦ
ЈO
ІШ
)
=
e
x
p
(
R
ІШ
(
ІЦ
)
)
Ёв
Іг
ЁЪ
D
[
e
x
p
(
R
ІШ
(
Іг
)
)
d
Іг
]
P(\zeta|\theta)=\frac{exp(R_\theta(\zeta))}{\int_{\tau\in D}\left[{exp(R_{\theta}(\tau))}{\rm d}\tau \right]}
P(ІЦЈOІШ)=ЁвІгЁЪD?[exp(RІШ?(Іг))dІг]exp(RІШ?(ІЦ))?
ашвЊзЂвтЕФЪЧ,етРяЕФ
R
(
ІШ
)
R(\theta)
R(ІШ)жИЕФЪЧРлЛ§НБЩЭЖјЗЧЕЅВННБЩЭЁЃ

ЕЋЪЧдpaperжаИјГіЕФЫ№ЪЇКЏЪ§ВЛЪЧзюДѓаХЯЂьиЖјЪЧзюДѓЫЦШЛ,етгжЪЧЮЊЪВУДЁЃдpaperжаИјГіСЫвЛИіШУШЫФбвдРэНтЕФНтЪЭ:
Maximizing the entropy of the distribution over paths subject to the feature constraints from observed data implies that we maximize the likelihood of the observed data under the maximum entropy (exponential family) distribution derived above (Jaynes 1957).
ЁЊЁЊМДДгЙлВтЪ§ОнЩЯТњзуfeature matchingЕФдМЪј(дМЪј1)ЕФЬѕМўЯТзюДѓЛЏЙьМЃЗжВМЕФаХЯЂьиЕШМлгкдкзюДѓаХЯЂьиЗжВМЕФЬѕМўЯТДгЙлВтЪ§ОнзюДѓЛЏЫЦШЛЁЃБОЮФВЛЖдДЫЩюОП,ИааЫШЄЕФХѓгбПЩвдбаОПвЛЯТЯТУцетЦЊТлЮФ
Jaynes, E. T. 1957. Information theory and statistical mechanics. Physical Review 106:620ЈC630.
\qquad
ЖјМйЩшЪЧзЈМвЯЕЭГЪЧзюДѓьиЗжВМЕФ,вђДЫЖдзЈМвЙьМЃИХТЪЪЙгУзюДѓЫЦШЛ,ЕУЕН
L
(
ІШ
)
=
ЁЦ
ІЦ
ЁЪ
E
l
o
g
p
(
ІЦ
ЈO
ІШ
)
L(\theta)=\sum_{\zeta\in E}logp(\zeta|\theta)
L(ІШ)=ІЦЁЪEЁЦ?logp(ІЦЈOІШ)
МДЙьМЃИХТЪЕФзюДѓЫЦШЛЁЃДњШызюДѓьиЗжВМЯТЕФЙьМЃИХТЪЙЋЪН(ЦфжаEДњБэExpertЕФЙьМЃПеМф,ЖјDДњБэAgentЕФЙьМЃПеМф(ПЩвдШЯЮЊЪЧШЋВПЙьМЃПеМф)):
L
(
ІШ
)
=
ЁЦ
Іг
ЁЪ
E
l
o
g
p
(
Іг
ЈO
ІШ
)
=
ЁЦ
Іг
ЁЪ
E
l
o
g
1
Z
e
x
p
(
R
ІШ
(
Іг
)
)
=
ЁЦ
Іг
ЁЪ
E
R
ІШ
(
Іг
)
?
M
l
o
g
Z
=
ЁЦ
Іг
ЁЪ
E
R
ІШ
(
Іг
)
?
M
l
o
g
ЁЦ
Іг
ЁЪ
D
e
x
p
(
R
ІШ
(
Іг
)
)
?
ІШ
L
=
ЁЦ
Іг
ЁЪ
E
d
R
ІШ
(
Іг
)
d
ІШ
?
M
1
ЁЦ
Іг
ЁЪ
D
e
x
p
(
R
ІШ
(
Іг
)
)
ЁЦ
Іг
ЁЪ
D
[
e
x
p
(
R
ІШ
(
Іг
)
)
d
R
ІШ
(
Іг
)
d
ІШ
]
=
ЁЦ
Іг
ЁЪ
E
d
R
ІШ
(
Іг
)
d
ІШ
?
M
ЁЦ
Іг
ЁЪ
D
[
e
x
p
(
R
ІШ
(
Іг
)
)
ЁЦ
Іг
ЁЪ
D
e
x
p
(
R
ІШ
(
Іг
)
)
d
R
ІШ
(
Іг
)
d
ІШ
]
=
ЁЦ
Іг
ЁЪ
E
d
R
ІШ
(
Іг
)
d
ІШ
?
M
ЁЦ
Іг
ЁЪ
D
[
p
(
Іг
ЈO
ІШ
)
d
R
ІШ
(
Іг
)
d
ІШ
]
=
ЁЦ
Іг
ЁЪ
E
d
R
ІШ
(
Іг
)
d
ІШ
?
M
ЁЦ
s
i
ЁЪ
S
[
p
(
s
ЈO
ІШ
)
d
r
ІШ
(
s
)
d
ІШ
]
\begin{aligned} L(\theta) &=\sum_{\tau\in E}logp(\tau|\theta)\\ &=\sum_{\tau\in E}log\frac{1}{Z}exp(R_{\theta}(\tau))\\ &=\sum_{\tau\in E}R_{\theta}(\tau)-MlogZ\\ &=\sum_{\tau\in E}R_{\theta}(\tau)-Mlog\sum_{\tau\in D}exp(R_{\theta}(\tau))\\ \nabla _{\theta}L&=\sum_{\tau \in E}\frac{dR_{\theta}(\tau)}{d\theta}-M\frac{1}{\sum_{\tau\in D}exp(R_{\theta}(\tau))}\sum_{\tau\in D}\left[exp(R_{\theta}(\tau))\frac{dR_{\theta}(\tau)}{d\theta}\right]\\ &=\sum_{\tau \in E}\frac{dR_{\theta}(\tau)}{d\theta}-M\sum_{\tau\in D}\left[\frac{exp(R_{\theta}(\tau))}{\sum_{\tau\in D}exp(R_{\theta}(\tau))}\frac{dR_{\theta}(\tau)}{d\theta}\right]\\ &=\sum_{\tau \in E}\frac{dR_{\theta}(\tau)}{d\theta}-M\sum_{\tau\in D}\left[p(\tau|\theta)\frac{dR_{\theta}(\tau)}{d\theta} \right]\\ &=\sum_{\tau \in E}\frac{dR_{\theta}(\tau)}{d\theta}-M\sum_{s_i\in S}\left[p(s|\theta)\frac{dr_{\theta}(s)}{d\theta} \right]\\ \end{aligned}
L(ІШ)?ІШ?L?=ІгЁЪEЁЦ?logp(ІгЈOІШ)=ІгЁЪEЁЦ?logZ1?exp(RІШ?(Іг))=ІгЁЪEЁЦ?RІШ?(Іг)?MlogZ=ІгЁЪEЁЦ?RІШ?(Іг)?MlogІгЁЪDЁЦ?exp(RІШ?(Іг))=ІгЁЪEЁЦ?dІШdRІШ?(Іг)??MЁЦІгЁЪD?exp(RІШ?(Іг))1?ІгЁЪDЁЦ?[exp(RІШ?(Іг))dІШdRІШ?(Іг)?]=ІгЁЪEЁЦ?dІШdRІШ?(Іг)??MІгЁЪDЁЦ?[ЁЦІгЁЪD?exp(RІШ?(Іг))exp(RІШ?(Іг))?dІШdRІШ?(Іг)?]=ІгЁЪEЁЦ?dІШdRІШ?(Іг)??MІгЁЪDЁЦ?[p(ІгЈOІШ)dІШdRІШ?(Іг)?]=ІгЁЪEЁЦ?dІШdRІШ?(Іг)??Msi?ЁЪSЁЦ?[p(sЈOІШ)dІШdrІШ?(s)?]?
ЙщвЛЛЏЕФЫ№ЪЇКЏЪ§ЮЊ:
?
ІШ
L
Ѓў
=
1
M
ЁЦ
Іг
ЁЪ
E
d
R
ІШ
(
Іг
)
d
ІШ
?
ЁЦ
s
i
ЁЪ
S
[
p
(
s
ЈO
ІШ
)
d
r
ІШ
(
s
)
d
ІШ
]
\nabla _{\theta}\overline{L}=\frac{1}{M}\sum_{\tau \in E}\frac{dR_{\theta}(\tau)}{d\theta}-\sum_{s_i\in S}\left[p(s|\theta)\frac{dr_{\theta}(s)}{d\theta} \right]
?ІШ?L=M1?ІгЁЪEЁЦ?dІШdRІШ?(Іг)??si?ЁЪSЁЦ?[p(sЈOІШ)dІШdrІШ?(s)?]
ЦфжаMЪЧзЈМвЙьМЃЕФЬѕЪ§,ШчЙћзДЬЌПеМфЪЧЮоЯоЕФ,дђВЛФмжБНгЬзгУДЫЙЋЪНЁЃ
ЖдгкЯпадReward,ЙьМЃЕФРлЛ§RewardЮЊ
R
ІШ
(
ІЦ
)
=
ІШ
T
f
ІЦ
=
ЁЦ
s
j
ЁЪ
ІЦ
ІШ
T
f
s
j
R_{\theta}(\zeta)=\theta ^T f_{\zeta}=\sum_{s_j\in \zeta}\theta ^T f_{s_j}
RІШ?(ІЦ)=ІШTfІЦ?=sj?ЁЪІЦЁЦ?ІШTfsj??
ExpertВњЩњЕФFeature ExpectationЮЊ
f
~
=
1
m
ЁЦ
i
f
ІЦ
~
i
\widetilde{f}=\frac{1}{m}\sum_{i}f_{\widetilde{\zeta}_i}
f
?=m1?iЁЦ?fІЦ
?i??
Ы№ЪЇКЏЪ§ЬнЖШПЩБэЪОЮЊ:
?
ІШ
L
=
f
~
?
ЁЦ
s
i
ЁЪ
S
D
s
i
f
s
i
\nabla_{\theta}L=\widetilde{f}-\sum_{s_i\in S}D_{s_i}f_{si}
?ІШ?L=f
??si?ЁЪSЁЦ?Dsi??fsi?
ЦфжаDЮЊзДЬЌЗУЮЪЦЕДЮ(State Visitiation Frequency),ПЩвдЭЈЙ§ВЛЖЯгыЛЗОГЛЅЖЏНќЫЦГіЁЃ
змНсвЛЯТетИіЙЋЪНЕФЭЦЕМашвЊзЂвтвЛЯТМИЕу:
- зюДѓьиддђЪЧНЈСЂдкFeature MatchingЕФЛљДЁЩЯЕФ,ЖјЙьМЃИХТЪЗжВМЕФЙЋЪНдђЪЧгЩзюДѓьиддђ+дМЪјЭЦЕМГіЕФ
- зюДѓьиддђЕФЙьМЃИХТЪЗжВМЙЋЪН,ЮДжЊХфЗжКЏЪ§ЯюZЪЧдкШЋВПЙьМЃМЏЩЯЧѓКЭ,вђДЫЪЧЪЙгУAgentЕФЙьМЃНјааНќЫЦ
- зюДѓЛЏзЈМвЯЕЭГЕФЙьМЃИХТЪЫЦШЛЦфЪЕЪЧвЛИігыдЮЪЬтЕШМлЕФгХЛЏЮЪЬт,вђДЫЫ№ЪЇКЏЪ§ЕМЪ§ЕФЕквЛЯюЪЧдкExpertЕФDemonstrationsЩЯЧѓКЭ(ЛђЧѓЛ§Зж),ЖјВЛЪЧAgentЕФЁЃ
2.ЗТец
\qquad БОЮФЕФЗТецЦНЬЈВЮееСЫgithubЩЯЕФзЪдД,ВЂНјааСЫТдЮЂаоИФ(ЗТецЛЗОГдкбЇЭНбЇЯАФЧЦЊгаСЫЯъЯИНщЩм,дкДЫОЭВЛдйзИЪіСЫ):
ЪЙгУЗНЗЈШдШЛЪЧжБНгдЫааtrain.pyМДПЩ(зЂвташвЊдкmountaincar/maxent/ЕФФПТМЯТдЫаа)ЁЃКЭбЇЭНбЇЯАЕФДњТывЛбљ,вВЪЧЛљгкQ-TableЕФЁЃ
\qquad
дДДњТыжаЖдFeatureУЛгазіШЮКЮЕФЬсШЁ,жБНгНЋУПИізДЬЌ(20ИіЮЛжУВЩбљЁС20ИіЫйЖШВЩбљзмЙВ400ИіРыЩЂзДЬЌ)зїЮЊFeatureЁЃМйЩшВЛЭЌЬиеїжЎМфЪЧНтёюЕФ,Feature MatrixОЭЪЧЖдНЧОиеѓ,МДвђДЫзДЬЌЗУЮЪЦЕДЮЁСЬиеїМДЬиеїЗУЮЪЦЕДЮЁЃ
\qquad
дкдДДњТыжаlearner_feature_expectationsМДЬиеїЗУЮЪЦЕДЮ,ЖјЙщвЛЛЏжЎКѓМДЮЊЬнЖШЕФЕкЖўЯю
дДДњТыЕФЦфжавЛВПЗжШчЯТ:
expert = expert_feature_expectations(feature_matrix, demonstrations)
learner_feature_expectations = np.zeros(n_states)
theta = -(np.random.uniform(size=(n_states,)))
episodes, scores = [], []
for episode in range(30000):
state = env.reset()
score = 0
if (episode != 0 and episode == 10000) or (episode > 10000 and episode % 5000 == 0):
learner = learner_feature_expectations / episode
maxent_irl(expert, learner, theta, theta_learning_rate)
while True:
state_idx = idx_state(env, state)
action = np.argmax(q_table[state_idx])
next_state, reward, done, _ = env.step(action)
irl_reward = get_reward(feature_matrix, theta, n_states, state_idx)
next_state_idx = idx_state(env, next_state)
update_q_table(state_idx, action, irl_reward, next_state_idx)
learner_feature_expectations += feature_matrix[int(state_idx)]
ПДЭъдgithubЕФГЬађ,БОШЫЛЙгавЛИівЩЕу,МДЪЧmaxent.pyЮФМўжаЕФвЛЖЮ
def maxent_irl(expert, learner, theta, learning_rate):
gradient = expert - learner
theta += learning_rate * gradient
# Clip theta
for i in range(len(theta)):
if theta[i]>0:
theta[i]=0
\qquad дЮФжаЕФclip thetaЪЕМЪЩЯЪЧЗРжЙthetaГЌЙ§0,РрЫЦгкЩюЖШбЇЯАжаЕФЬнЖШНиЖЯВйзї,ШЛЖјетИіВйзїдкЮвГЂЪдЖрДЮжЎКѓВЂЮогУДІ,ЖјЧввВУЛгаШЮКЮвтвх(вђЮЊдкtheta>0Кѓ,вВЛсдкЯТвЛДЮЕќДњЪБЭЈЙ§бЇЯАЪЙЕУthetaжиаТ<0)ЁЃБОШЫЕФНЈвщЪЧдіМгвЛИібЇЯАТЪЕнМѕЕФschedule,ВЂЧвНЋclipЕФЗЖЮЇДг[-inf,0]аоИФЕН[-0.5,0.5],ПЩвдЛёЕУЯрЖдЮШЖЈЕФбЇЯАТЪЧњЯп,ЯТУцЗжБ№ЪЧclip(-0.5,0.5)КЭclip(-0.5,0)ЕФЖдБШ:
| clip(-0.5,0.5) | clip(-0.5,0) |
|---|---|
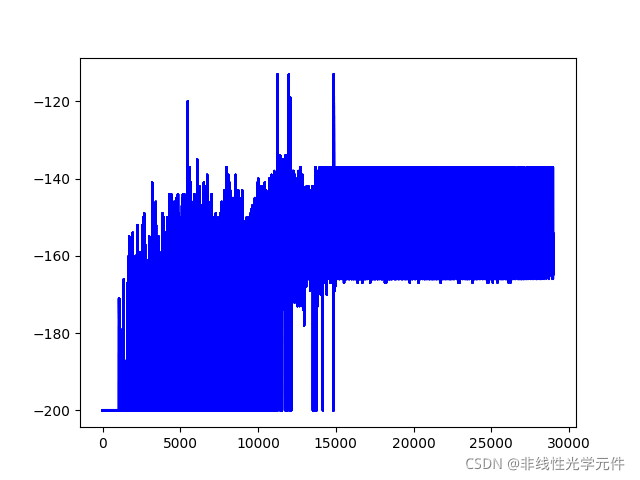 | 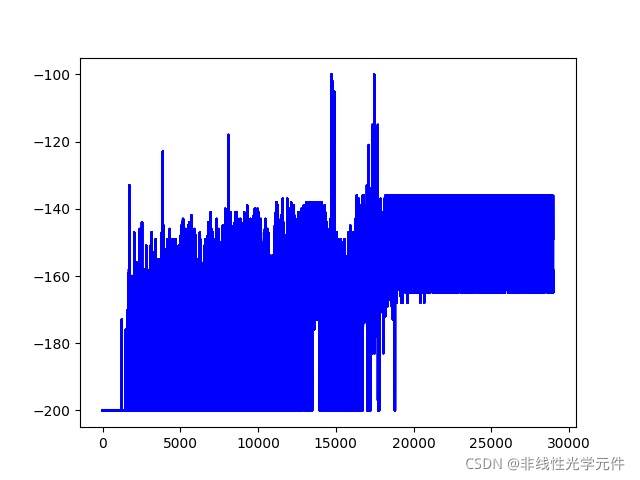 |
\qquad ПЩвдЗЂЯждіМгвЛВПЗжЬнЖШЕФе§ЯђЗЖЮЇЗДЖјИќгаРћгкбЇЯА,етЪЧгЩгкexpert-learnЕФМЋаЁжЕЪЧдк0ДІШЁЕУЕФ,ШЛЖјдкбЇЯАТЪЙЬЖЈЪБ,ИФКЏЪ§ЛсдкРыЩЂЕќДњЪБдк0ИННќе№ЕД,ЬнЖШШєдк0ДІНиЖЯЛсЕМжТбЇЯАТЪШёМѕЮЊ0(ПЩФме§ЪЧдзїепгУвт?)ЁЃ
ЯТУцЪЧtest.pyБЃДцЕФМИзщgifЕФЭМ
| Reward=-158 | Reward=-138 | Reward=-146 |
|---|---|---|
 |  |  |
ЯЃЭћБОЮФЖдФњгаАяжњ,аЛаЛдФЖС!