ǰ��ع�
- attention��transformers
- BERT��GPT
- ��дBERTģ��
- BERT��Ӧ�á�ѵ�����Ż�
- Transformers����ı���������������
- Transformers������б�ע����
- Transformers�����ȡʽ�ʴ�����
�����ٵ�
��ǰ��Ӧ��BERT������ͬ,�˴ε�������transformer�����Ӧ��,�������һ�������Seq2seq,�����������⡣
��������̻�����֮ǰ����,����������,����Ҫ��������tokenizeԤ����,������Seq2seq,��Ҫ��source��target��������Ӧ��Ԥ������������Ԥѵ��ģ��,����ģ��ѵ������Ҫ����ز���,�Լ�����������ģ����ʹ�õ�data collator,������Ҫ���崦�������Է���metric����ķ���(�˴���ֹʹ����Ԥѵ�������metric,��������һ�����metric)�����trainer,Ȼ�����ѵ������֤��
����ѵ����ʱ�Ƚϳ�,���ﳢ���˵���ѵ���õ�ģ�ͼ���������ķ�����
��������
1 ������������
1.1 ������
��������ʹ�õ���WMT dataset���ݼ���
������ݼ��漰���ķ��������кܶ�,��������������ŷ�������,�漰�������Լ�ķ���:

����ѡ���������Ӣ�������������ķ��롣
model_checkpoint = "Helsinki-NLP/opus-mt-en-ro"
# ѡ��һ��ģ��checkpoint
����������һ�����е����е�����,ʹ��BERT��Ȼ�Dz�����,������Ҫ�õ���������Transformer��
1.2 ������İ�װ��datasets��metric�ļ���
����ط���Ҫ��֤��װ��ȷһЩ�汾�Ŀ�,��Ȼ�ͻᱨ����
��Ҫ��֤�汾��ȷ�Ŀ������������
datasets==1.6.2
transformers==4.4.2
sacrebleu==1.5.1
tqdm==4.62.2
����sacrebleu�İ汾����Ҫ,��������datasets�ļ��ش���
datasets��metric�ļ��ط�������
from datasets import load_dataset, load_metric
raw_datasets = load_dataset("wmt16", "ro-en")
metric = load_metric("sacrebleu")
1.3 ���ݵ�չʾ
�����datasets��Ȼ�������������train,test,validation��
���Կ���ѵ������һ������
[IN]: raw_datasets["train"][0]
# ���ǿ��Կ���һ��Ӣ��en��Ӧһ��������������ro
[OUT]: {'translation': {'en': 'Membership of Parliament: see Minutes',
'ro': 'Componen?a Parlamentului: a se vedea procesul-verbal'}}
2 �������������ʵ��
2.1 ����Ԥ����
��һ����Ȼ��tokenize,�����������ͷ�ڵ�����û��ʮ���ر�ĵط���
����tokenizer��������һ���ص㡣
Ϊ�˴ﵽ����Ԥ������Ŀ��,����ʹ��
AutoTokenizer.from_pretrained����ʵ�������ǵ�tokenizer,��������ȷ��:
- ���ǵõ�һ����Ԥѵ��ģ��һһ��Ӧ��tokenizer��
- ʹ��ָ����ģ��checkpoint��Ӧ��tokenizer��ʱ��,����Ҳ������ģ����Ҫ�Ĵʱ���
vocabulary,ȷ��˵��tokens vocabulary��
from transformers import AutoTokenizer
# ��Ҫ��װ`sentencepiece`: pip install sentencepiece
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
��������ʹ�õ�mBARTģ����Ҫ��ȷ����source���Ժ�target���ԡ�
if "mbart" in model_checkpoint:
tokenizer.src_lang = "en-XX"
tokenizer.tgt_lang = "ro-RO"
�����������õ���,��Ӣ��뵽���������
����ط��ر���Ҫע�����,������Ҫ��ģ��������õ�targets,�������ʹ��as_target_tokenizer������targets����Ӧ������token��
with tokenizer.as_target_tokenizer():
print(tokenizer("Hello, this one sentence!"))
model_input = tokenizer("Hello, this one sentence!")
tokens = tokenizer.convert_ids_to_tokens(model_input['input_ids'])
# ��ӡ��һ��special toke
print('tokens: {}'.format(tokens))
��ӡ������������
{'input_ids': [10334, 1204, 3, 15, 8915, 27, 452, 59, 29579, 581, 23, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
tokens: ['�xHel', 'lo', ',', '�x', 'this', '�xo', 'ne', '�xse', 'nten', 'ce', '!', '</s>']
����Ԥ����������������
max_input_length = 128
max_target_length = 128
source_lang = "en"
target_lang = "ro"
if model_checkpoint in ["t5-small", "t5-base", "t5-larg", "t5-3b", "t5-11b"]:
prefix = "translate English to Romanian: "
else:
prefix = ""
def preprocess_function(examples):
inputs = [prefix + ex[source_lang] for ex in examples["translation"]]
targets = [ex[target_lang] for ex in examples["translation"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
����һ����������,������truncation=True��ȷ�������ľ��ӱ��ضϡ�
prefix��������,������T5��Ԥѵ��ģ��,��Ҫ���ض���ǰ������ģ��Ҫ��������
������Ȼ����map�����������е���������Ԥ������
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
2.2 ��ģ��
2.2.1 ����Ԥѵ��ģ��
���Ȼ����ȼ���Ԥѵ��ģ��
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
������Ȼ��Ҫ�趨ѵ���IJ���,��Ҫע�����������һ�����е����е�����,�����õ���������Transformer,��֮ǰ������������ͬ,���Զ�Ӧ��ѵ������Ҳ������ͬSeq2SeqTrainingArguments��
batch_size = 16
args = Seq2SeqTrainingArguments(
"test-translation",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True,
fp16=False,
)
�������ǵ����ݼ��Ƚϴ�,ͬʱSeq2SeqTrainer��ϱ���ģ��,����������Ҫ���������ౣ��save_total_limit=3��ģ�͡�
���Բ鿴model�����ݡ�
���Կ���model�ɱ�����encoder �ͽ�����decoder��ɡ�encoderһ����6��MarianEncoderLayer,ÿ��layer��һ��selfattention��,�Լ�����ȫ���Ӳ㹹��,attention��ȫ���Ӳ��ֵĺ��涼��normalization��
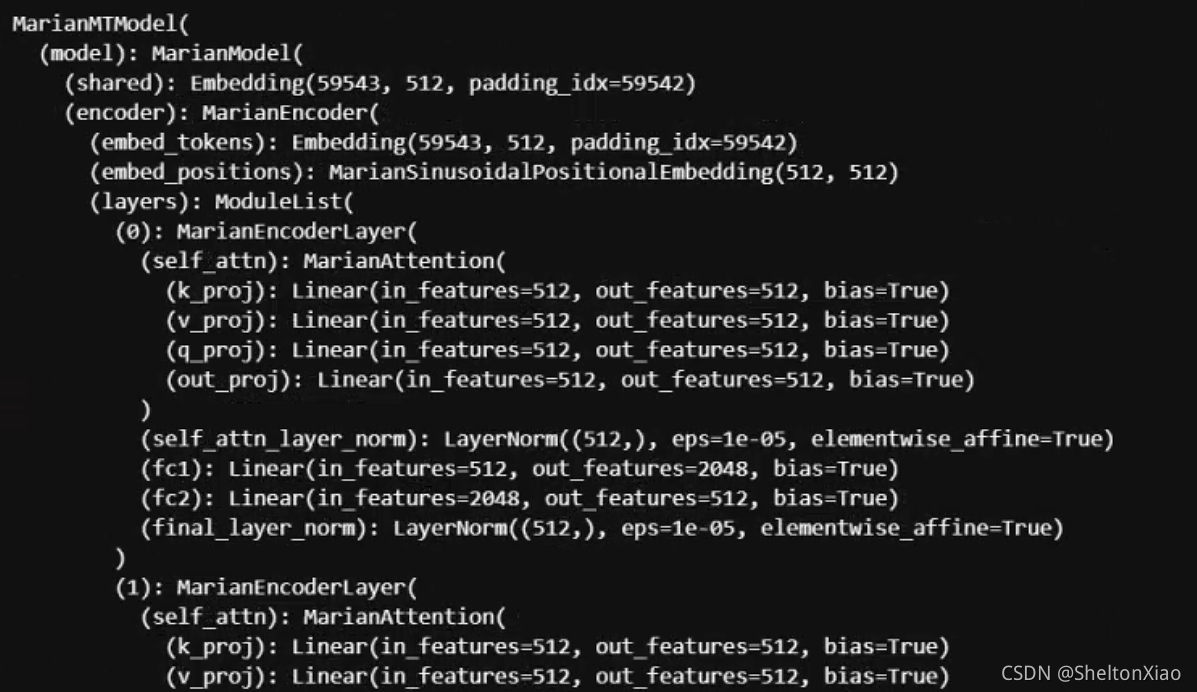
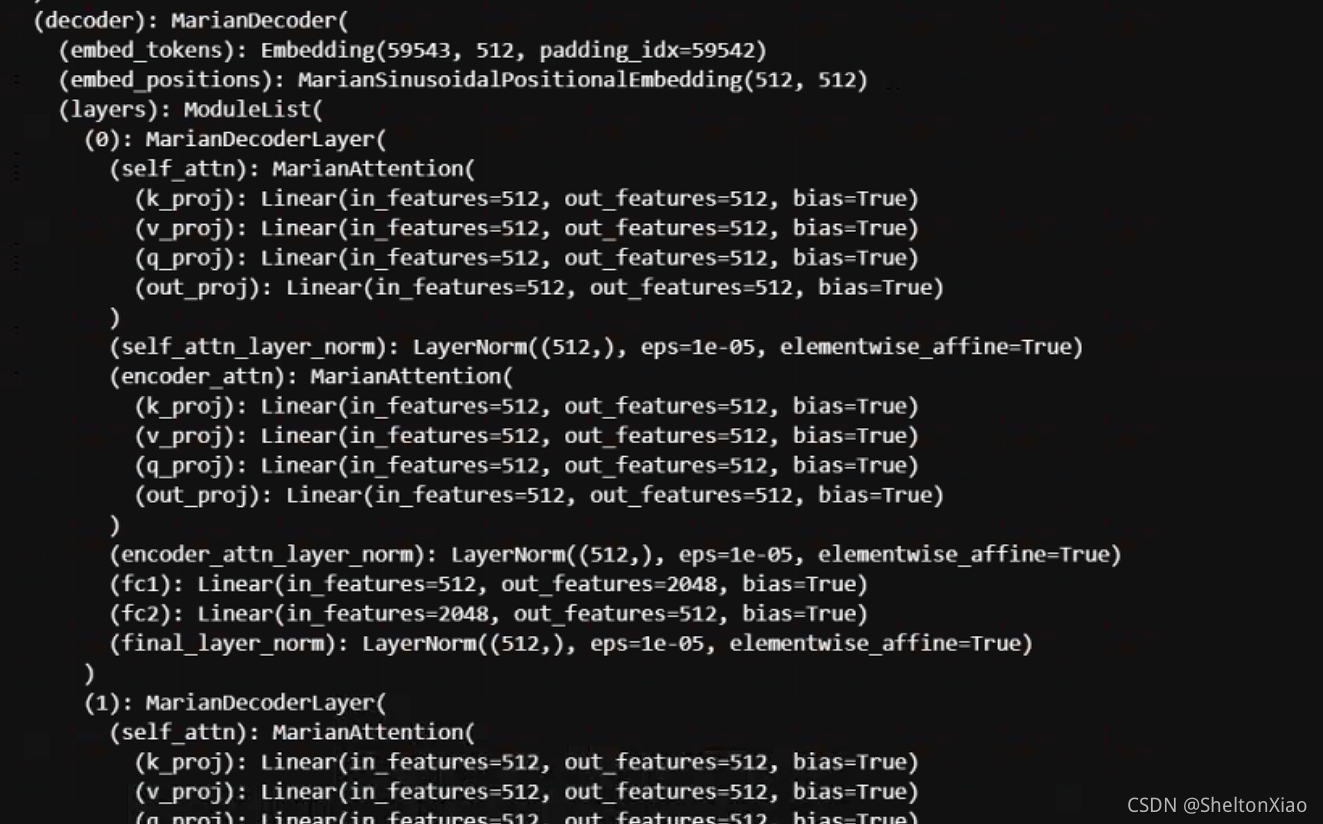
decoder��6��MariaDecoderLayer����,ÿ��Layer��һ��SelfAttention,һ��EncoderAttention������ȫ���Ӳ㹹��,SelfAttention��EncoderAttention��ȫ���Ӳ��ֵĺ��涼��normalization��
2.2.2 �����ռ����Ĵ���
���ǻ���Ҫһ�������ռ���data collator,�����Ǵ����õ�����ι��ģ�͡�
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
2.2.3 ��������
���ú�Seq2SeqTrainer��ʣ���һ������,�Ǿ���������Ҫ�������������������ʹ��metric�����������
��������Ҫ�Ȱ����ݽ��к���,���ܹ�����������
import numpy as np
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
���ά������ôȷ������?
��ʲô�ط�����-100����,���ʵ����ȡ��ά�ȵĶ��롣
����ط����Կ���������result��ͷ����������,һ��������bleu,����metric��Ӧ�Ľ����gen_len�Ǽ��㲻��ȵ�token������
2.2.4 ѵ��
������еIJ���/����/ģ�ʹ���Seq2SeqTrainer��
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
����train��������ѵ��
trainer.train()
��colab pro��ͷѵ���������

�ڱ�������(RTX 3080)ѵ���������

��ģ�ͽ���evaluate
trainer.evaluate()
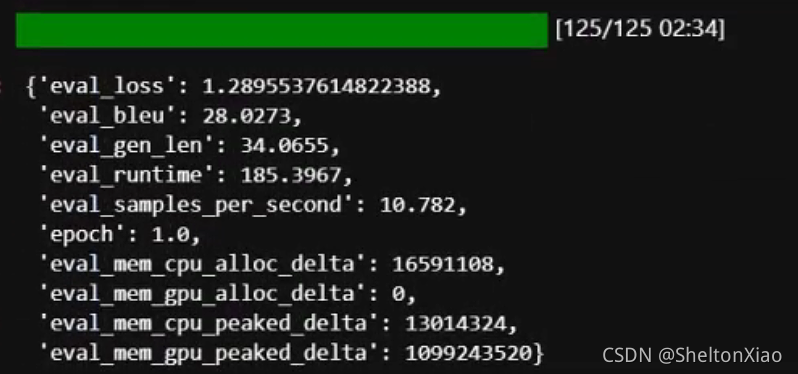
2.2.5 ģ�͵ĵ���������
����ģ�͵�ѵ����ʱ�ϳ�,Ϊ��ֹѵ����ʧ,���ǿ��Խ�ģ�͵����洢
trainer.save_model("test-ml-trained")
�����colab ��,����Ҫ����GoogleDrive���ܽ�ģ������������
��������GoogleDrive
from google.colab import drive
drive.mount('/content/drive')
���ŵ�½�˺���д��Ӧ�Ĵ��롣
trainer.save_model("/content/drive/MyDrive/test-ml-trained")
�洢��ʱ��ע����Ҫ��õ�ַ,�����drive����ַ��,����ʾû��Ȩ�ޡ�
�洢�õ�ģ�ͳ�������
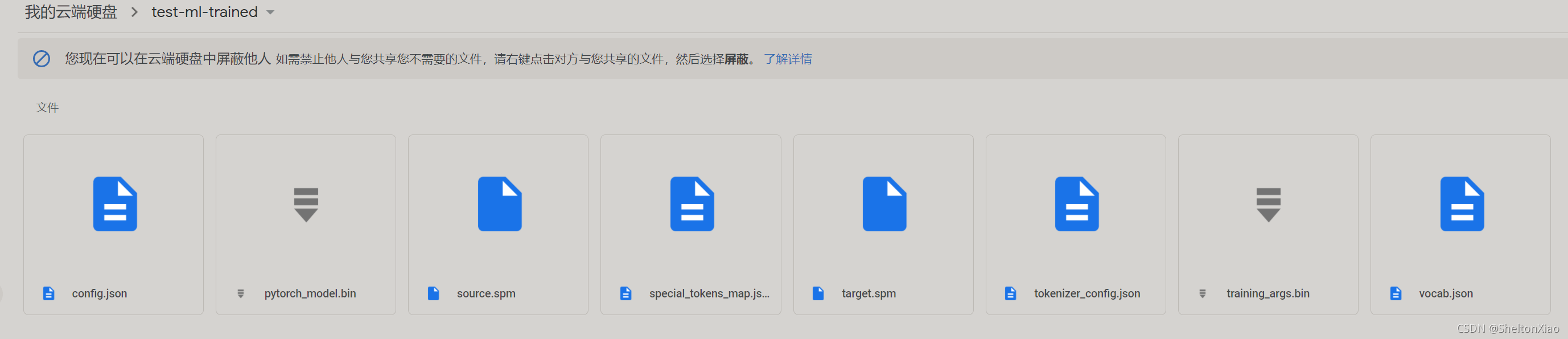
�ο���ƪ����,����ע�trainer�����û�ж�Ӧ��from_pretrained������
�������ģ���õ���model�����
model = AutoModelForSeq2SeqLM.from_pretrained("/content/drive/MyDrive/test-ml-trained")
tokenizerҲ��������,����Ϊ����ѵ������û����,���Կ���ֱ�Ӵ�checkpoints�����ء�
������ģ��֮��,һ����Ҫ����trainer,�������ǰ��һ����
���ǽ��������ģ��ͬ��Ҳevaluateһ��,��ʾ�Ľ���������ġ�
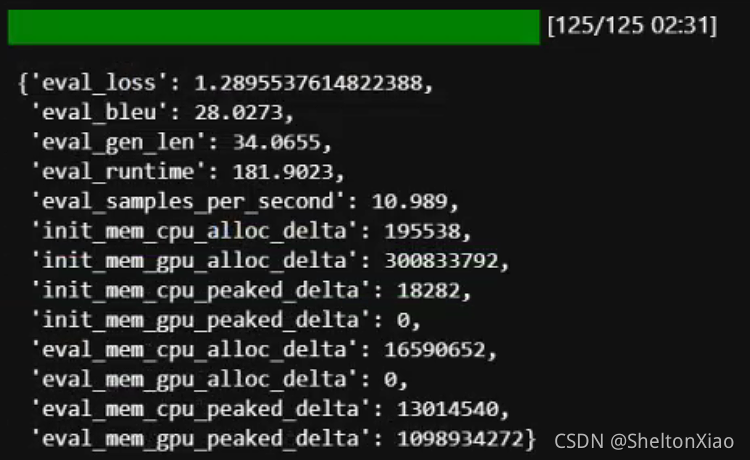
���Կ��������epoch��Ϊ1����Ϣû�б����ؽ���,����ģ�ͻ���ԭ���Ǹ�ģ��,��֤���ϵļ�����û�з������ġ�